Завершаем рассказ, начатый в первой части. Сегодня рассмотрим еще несколько граблей, на которые довелось наступить за годы использования SObjectizer-а в повседневной работе.
Продолжаем перечислять грабли
Народ хочет синхронности...
Акторы в Модели Акторов и агенты у нас в SObjectizer общаются посредством асинхронных сообщений. И в этом кроется одна из причин привлекательности Модели Акторов для некоторых типов задач. Казалось бы, асинхронность — это один из краеугольных камней, один из бонусов, поэтому пользуйся себе на здоровье и получай удовольствие.
Ан нет. На практике быстро начались просьбы сделать в SObjectizer возможность синхронного взаимодействия агентов. Очень долго я этим просьбам сопротивлялся. Но в конце-концов сдался. Пришлось добавить в SObjectizer возможность выполнить синхронный запрос от одного агента к другому.
Выглядит в коде это вот так:
// Тип запроса.
struct get_messages final : public so_5::signal_t {};
...
// Инициация синхронного запроса...
auto msgs = request_value<std::vector<message>, get_messages>(mbox, so_5::infinite_wait);
// ...обработка его результатов.
for(const auto & m : msgs) ...Здесь показан вызов функции request_value, которая выполняет синхронный запрос, приостанавливая выполнение текущей нити до того момента, пока результат запроса будет получен.
В данном случае мы отсылаем запрос типа get_messages дабы получить в ответ вектор объектов message. И ждать ответа мы будем без ограничения времени.
Однако, в SObjectizer-е реализовано это все-таки через сообщение. Внутри request_value отсылается сообщение целевому агенту, который получает и обрабатывает его обычным образом. Т.е. получатель даже не знает, что к нему пришел синхронный запрос, для него все выглядит как обычное асинхронное сообщение.
class collector : public so_5::agent_t {
public :
...
virtual void so_define_agent() override {
// Подписываемся на запрос.
so_subscribe(mbox).event<get_messages>(&collector::on_get_messages);
...
}
private :
std::vector<messages> collected_messages_;
// Обработчик запроса, вызывается при получении сигнала get_messages.
std::vector<messages> on_get_messages() {
std::vector<messages> r;
std::swap(r, collected_messages_);
return r;
}
};Т.е. внутри collector::on_get_messages агент-получатель сообщения не может определить, получил ли он get_messages в виде обычного асинхронного сообщения или же это часть синхронного запроса.
А вот под капотом упрятана не очень сложная механика, построенная на основе std::promise и std::future из стандартной библиотеки C++11.
Во-первых, при отсылке синхронного запроса к получателю приходит не обычное сообщение, а хитрое, вместе с объектом std::promise внутри:
struct special_message : public so_5::message_t {
std::promise<std::vector<messages>> promise_;
...
};Это сообщение попадает в специальный обработчик, который генерируется автоматически SObjectizer-ом при подписке:
collector * collector_agent = ...;
auto actual_message_handler = [collector_agent](special_message & cmd) {
try {
cmd.promise_.set_value(collector_agent->on_get_messages());
}
catch(...) {
cmd.promise_.set_exception(std::current_exception());
}
};
do_special_subscribe<get_messages, special_message>(mbox, actual_message_handler);Этот хитрый обработчик вызывает заданный пользователем обработчик сообщения, после чего сохраняет возвращенное значение (или выпущенное наружу исключение) в объект std::promise из хитрого сообщения. Это приведет к срабатыванию std::future, на котором спит отправитель запроса. Соответственно, произойдет возврат из request_value.
Очевидно, что синхронное взаимодействие между агентами — это прямой путь к получению дедлоков. Поэтому request_value в SObjectizer есть, но мы рекомендуем использовать его с большой осторожностью.
Самое забавное лично для меня оказалось в том, что очень быстро нашлось полезное применение для request_value. Как раз в механизмах защиты агентов от перегрузки. Если эта защита делается посредством пары collector/performer, то performer-у удобно обращаться за следующей порцией сообщений именно через request_value. А так как агенты collector и performer в принципе должны работать на разных нитях, то опасность получить тут дедлок сведена к минимуму.
Мораль сей истории такова: строгая приверженность принципам какой-то теоретической модели — это хорошо. Но если на практике вас настоятельно просят сделать что-то, что вступает в противоречие с этими самыми принципами, то имеет смысл прислушаться. Может получится что-нибудь полезное.
Распределенность из коробки: все не так радужно
В SObjectizer-4 разработчику «из коробки» была доступна возможность создания распределенных приложений. У нас был свой протокол поверх TCP/IP, свой способ сериализации C++ных структур данных.
С одной стороны, это было очень классно и прикольно. С помощью несложных телодвижений можно было заставить сообщения автоматически летать между узлами, на которых работали части распределенного приложения. SObjectizer брал на себя сериализацию и десериализацию данных, контроль транспортных каналов, переподключения при разрывах и т.д.
В общем, по началу все было круто.
Но с течением времени, по мере того, как расширялся круг решаемых на SObjectizer-е задач, по мере роста нагрузки на приложения, мы поимели довольно много неприятностей:
- во-первых, под каждый тип задачи желательно иметь свой протокол. Потому что, скажем, распространение телеметрии, т.е. обмен большим количеством мелких сообщений, потеря части которых не страшна, сильно отличается от обмена большими бинарными файлами. Например, приложение, где нужно обмениваться большими архивами или кусками видеофайлов, должно использовать какой-то другой протокол, нежели приложение, в котором передаются тысячи сообщений с датчиков текущей температуры воздуха;
- во-вторых, реализация back-pressure для асинхронных агентов — это сама по себе непростая штука. А когда сюда еще и примешивается общение по сети, ситуация становится гораздо хуже. Какие-нибудь задержки в сети или притормаживание на одном из узлов приводит к накоплению больших объемов недоставленных сообщений на остальных узлах и это изрядно портит жизнь;
- в-третьих, времена, когда большие распределенные системы можно было писать только на одном C++, закончились давным-давно. Сегодня обязательно какие-то компоненты будут написаны на других языках программирования. А это означает, что требуется интероперабильность. Что автоматически ведет к тому, что наш собственный протокол, заточенный под C++ и SObjectizer, не помогает, а мешает разработке распределенных приложений.
Поэтому в SObjectizer-5 нет инструментов для поддержки распределенности. Мы больше смотрим в сторону того, чтобы облегчить агентам общение с внешним миром посредством де-факто стандартных протоколов. Это лучше, чем изобретение собственных велосипедов.
Много агентов – это проблема, а не решение. SEDA-вэй форева!
Ну а эта тема очень сильно нравится лично мне. Ибо лишний раз подчеркивают, что маркетинг и здравый смысл могут противоречить друг другу :)
Практически все акторные фреймворки в своих маркетинговых материалах обязательно говорят о том, что акторы — это легковесные сущности и в приложении можно создать хоть сто тысяч акторов, хоть миллион, хоть десять миллионов акторов.
Когда неподготовленный программист сталкивается с возможностью создать в программе миллион акторов, у него может слегка снести крышу. Это ведь так заманчиво — оформить каждую активность внутри приложения в виде актора.
Программист поддается такому соблазну, начинает создавать акторов на каждый чих и вскоре обнаруживает, что у него в программе одновременно работают десятки тысяч, а то и сотни тысяч акторов… Что может приводить к возникновению, как минимум, одной из двух проблем.
Что творится внутри приложения с миллионом акторов?
Первая проблема, с которой можно столкнуться создавая большое количество акторов — это непонимание того, что происходит в программе, почему программа работает именно так и как программа поведет себя дальше.
Происходит то, что я называю эффектом птичьей стаи: поведение отдельной птицы в стае может быть описано набором из нескольких простых правил, конфигурация же всей стаи оказывается сложной и практически непредсказуемой.
Точно так же и в приложении с большим количеством агентов. Каждый агент может работать по простым и понятным правилам, а вот поведение всего приложения может оказаться сложнопредсказуемым.
Например, часть агентов вдруг перестанет подавать признаки жизни. Вроде как они есть, а их работы не видно. А потом вдруг они «проснутся» и начнут работать так активно, что не хватит ресурсов другим агентам.
Вообще, следить за тем, что происходит внутри приложения с десятью тысячами агентов гораздо сложнее, чем в приложении, где работает всего сто агентов. Представьте себе, что у вас десять тысяч агентов и вам захотелось узнать, насколько сильно загружен один из них. Думаю, это уже будет проблема.
Кстати говоря, одна из киллер-фич Erlang-а как раз в том, что Erlang предоставляет инструментарий для интроспекции. Разработчик хотя бы может посмотреть, что у него внутри Erlang-овой виртуальной машины происходит. Сколько процессов, сколько жрет каждый из процессов, какие размеры очередей и т.д. Но в Erlang-е своя виртуальная машина и там это возможно.
Если мы говорим о C++, то C++ные фреймворки, насколько я знаю, в этой области очень сильно отстают от Erlang-а. С одной стороны это объективно. Все-таки C++ компилируется в нативный код и мониторить куски нативного кода гораздо сложнее. С другой стороны, реализация такого мониторинга — это задача нетривиальная, требующая изрядных трудозатрат и вложений. Поэтому сложно ожидать продвинутых возможностей в OpenSource-фреймворках, которые разрабатываются лишь на чистом энтузиазме.
Так что создавая в C++ном приложении большое количество агентов и не имея таких же продвинутых инструментов мониторинга, как в Erlang-е, следить за приложением и понимать, что и как там работает, сложно.
Внезапные всплески активности
Вторая возможная проблема — это внезапные всплески активности, когда часть ваших акторов вдруг начинает потреблять все имеющиеся в наличии ресурсы.
Представьте себе, что у вас в приложении 100 тысяч агентов. Каждый из них инициирует какую-то операцию и взводит таймер для контроля тайм-аута выполнения операции.
Допустим, какой-то кусок приложения начал подтормаживать, ранее начатые операции стали отваливаться по тайм-ауту и отложенные сообщения об истечении тайм-аутов стали приходить пачками. Например, в течении 2-х секунд сработало 10 тысяч таймеров. Это означает вызов 10 тысяч обработчиков отложенных сообщений.
И вот тут может оказаться, что каждый такой обработчик почему-то тратит по 10ms. Значит, на обработку всех 10 тысяч отложенных сообщений уйдет 100 секунд. Пусть даже эти сообщения будут обрабатываться в четыре параллельных потока. Но это все равно 25 секунд.
Получится, что часть нашего приложения на эти 25 секунд тупо замрет. И пока не обработает эти самые 10 тысяч отложенных сообщений, ни на что другое реагировать не будет.
Беда не приходит одна...
Самое печальное в том, что обе вышеперечисленные проблемы прекрасно накладываются друг на друга. Из-за внезапного всплеска активности мы сталкиваемся со незапланированным поведением своего приложения, а из-за эффекта птичьей стаи мы не можем понять, что же происходит. Приложение вроде как работает, но как-то не так. И непонятно, что с этим делать. Можно, конечно, тупо прибить приложение и рестартовать его. Но это означает пересоздание 100 тысяч агентов, восстановление их в каком-то состоянии, возобновление подключений к каким-то внешним сервисам и т.д. Безболезненно такой рестарт, к сожалению, не обойдется.
Так что к возможности создать в своем приложении кучу агентов следует относиться не как к способу решения своих проблем. А как к способу нажить себе еще больше проблем.
Выход, естественно, прост: нужно обходиться меньшим количеством агентов. Но как это сделать?
Подход SEDA
Очень хорошо вставляет на место мозги знакомство с подходом SEDA (Staged Event-Driven Architecture). В начале 2000-х маленькая группа исследователей разработала одноименный фреймворк на Java и с его помощью доказала состоятельность положенной в основу идеи: разбить выполнение сложных операций на стадии, под каждую стадию выделить свой поток выполнения (или группу потоков), а взаимодействие между стадиями организовать через асинхронные очереди сообщений.
Представим себе, что нам нужно обслужить платежный запрос. Мы получаем запрос, проверяем его параметры, затем проверяем возможность проведения платежа для данного клиента (например, не превысил ли он суточные лимиты по своим платежам), затем оцениваем рискованность платежа (например, если клиент из Белоруссии, а платеж почему-то инициируется из Бангладеш, то это подозрительно), затем уже производим списание средств и формируем результат платежа. Тут можно явно увидеть несколько стадий обработки одной операции.
Возможность создать в приложении миллион агентов толкает нас к тому, чтобы на каждый платеж создавать одного агента, который сам, последовательно бы выполнял все стадии. Т.е. сам бы валидировал параметры платежа, сам бы определял суточные лимиты и их превышение, сам бы делал запросы в систему фрод-мониторинга и т.д. Схематично это могло бы выглядеть вот так:

В случае же SEDA-подхода мы могли бы сделать по одному агенту на каждую стадию. Один агент принимает платежные запросы от клиентов и передает их второму агенту. Второй агент проверяет параметры запросов и отдает валидные запросы третьему агенту. Третий агент проверяет лимиты и т.д. Схематично это выглядит вот так:
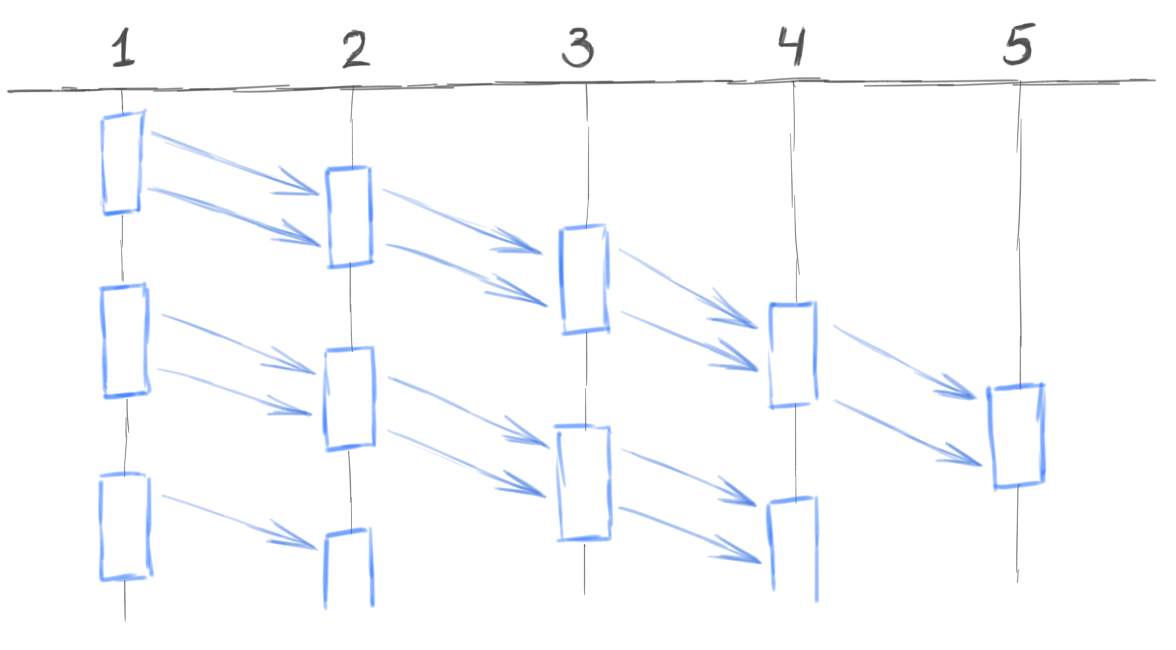
Количество агентов сокращается на порядки. Контролировать этих агентов становится намного проще. Значительно упрощается защита таких агентов от перегрузок. Эти агенты, если они работают с СУБД, получают возможность использовать bulk-операции. Т.е. агент накапливает, скажем, 1000 сообщений, затем обслуживает их все 2-3 bulk-обращениями к БД. У нас появляется возможность дозировать активность агентов. Например, если внешная система фрод-мониторинга вдруг отваливается и нам нужно сгенерировать 10 тысяч отрицательных ответов, то мы может не сразу отослать все эти 10 тысяч ответов, а размазать их равномерно, скажем, на десять секунд. Тем самым мы защитим от перегрузки другие части системы.
Дополнительный бонус: если всего один агент обслуживает какую-то стадию, то значительно упрощается задача приоритизации обработки транзакций на этой стадии. Например, если нужно транзакции от находящихся в он-лайне клиентов обрабатывать с большим приоритетом, чем транзакции, выполняемые по расписанию. В случае SEDA-подхода это реализуется проще, чем когда за каждую транзакцию отвечает свой, агент.
При этом даже в рамках SEDA-подхода мы все так же пользуемся преимуществами, которые дает нам Модель Акторов. Но ограничиваемся буквально несколькими десятками акторов, вместо десятков тысяч.
Заключение
В заключение хочется сказать, что Модель Акторов — это классная шутка, но совсем не серебряная пуля. В каких-то задачах Модель Акторов работает хорошо, в каких-то не очень, в каких-то совсем не работает.
Но даже если Модель Акторов подходит под задачу, то все равно очень бы не помешала парочка вещей:
- во-первых, сам разработчик должен иметь голову на плечах. Если же разработчик бездумно создает сотни тысяч акторов в своем приложении, не думает о проблеме перегрузки, не имеет представления о том, что такое спонтанный всплеск активности и т.д., то и с Моделью Акторов можно нажить себе не меньше неприятностей, чем на «голых» нитях;
- во-вторых, было бы хорошо, чтобы акторный фреймворк оказывал разработчику посильную помощь. В частности, в таких вещах, как защита акторов от перегрузки, обработке ошибок и интроспекции происходящего внутри приложения. Как раз поэтому мы постепенно расширяем функциональность SObjectizer-а в этом направлении. Мы уже добавили такие вещи, как лимиты для сообщений, реакцию на исключения, сбор статистики и мониторинговой информации, а также средства для трассировки механизма доставки сообщений.
Кстати говоря, как раз набор подобных вспомогательных инструментов в акторном фреймворке, на мой взгляд, является некоторым признаком, который определяет зрелость фреймворка. Ибо реализовать в своем фреймворке какую-то идею и показать ее работоспособность — это не так уж и сложно. Можно потратить несколько месяцев труда и получить вполне себе работающий и интересный инструмент. Это все делается на чистом энтузиазме. Буквально: понравилась идея, захотел и сделал.
А вот оснащение того, что получилось, всякими вспомогательными средствами, вроде сбора статистики или трассировки сообщений — это уже скучная рутина, на которую не так то и просто найти время и желание.
Поэтому мой совет тем, кто ищет готовый акторный фреймворк: обратите внимание не только на оригинальность идей и красоту примеров. Посмотрите также на всякие вспомогательные вещи, которые помогут вам разобраться, что же происходит в вашем приложении: например, узнать, сколько сейчас внутри акторов вообще, какие у них размеры очередей, если сообщение не доходит до получателя, то куда оно девается… Если фреймворк что-то подобное предоставляет, то вам же будет проще. Если не предоставляет, то значит у вас будет больше работы.
Ну и добавлю от себя: если вам захотелось взять и сделать с нуля свой собственный акторный фреймворк, который бы защищал разработчика от обсуждавщихся выше граблей, то это не самая хорошая идея. Занятие абсолютно неблагодарное. Да и вряд ли окупаемое. Это уже проверено. На людях.
