В последнее время имена GridGain и Apache Ignite нередко мелькают в интернетах. Однако, судя по комментариям (например, здесь), мало кто понимает, что же это за продукт и с чем его едят.
В этой статье я попытаюсь доступным языком объяснить, и на примерах кода показать, что умеет Apache Ignite.

Ignite vs GridGain
Краткий ликбез: компания GridGain выпустила первую версию одноимённого продукта в 2007 году. В 2014 году GridGain пожертвовала большую часть кода в пользу Apache Software Foundation, в результате чего родился проект Apache Ignite. GridGain предоставляет платную поддержку и дополнительную функциональность в виде плагина.
Важно понимать: Apache Ignite не принадлежит GridGain и является свободным программным обеспечением под лицензией Apache 2.0.
Отличие от "обычных" open-source проектов (расположенных на GitHub, например) здесь в том, что нет возможности "передумать", закрыть код, поменять лицензию, и так далее.
Ignite принадлежит Apache Software Foundation.
Ignite.NET
Ignite написан на Java, а так же предоставляет API на .NET и C++. В данной статье будет идти речь именно о .NET API, в котором есть примерно 90% функционала жавовского АПИ, плюс свои собственные плюшки (LINQ).
Что это такое и зачем?
Самый простой и ёмкий ответ — это база данных. В основе которой — хранилище "ключ-значение"; грубо говоря, ConcurrentDictionary, в котором данные расположены на нескольких машинах.
При этом поддерживаются распределённые транзакции, SQL с индексами, полнотекстовый поиск Lucene, map-reduce вычисления, и многое другое. Но обо всём по порядку.
Как запустить?
В одну строчку! Это самая простая в установке и использовании база данных, которую я знаю.
Плохая новость: нам потребуется установленный Java Runtime 7+. Хорошая новость: с этого момента про Java можно забыть.
Создадим в Visual Studio простой Console Application, установим NuGet пакет Apache.Ignite, добавим в метод Main одну строчку Ignition.Start();. Готово, можно запускать. Через пару секунд в консоли появится "Topology snapshot [ver=1, servers=1". Запустим программу ещё раз и увидим в обеих консолях "Topology snapshot [ver=2, servers=2". Распределённая база данных запущена на двух узлах.
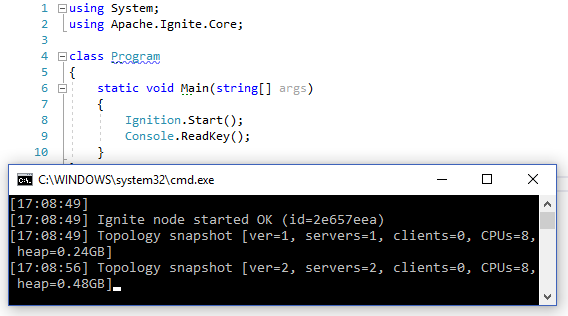
- Узел или Нода — это результат команды
Ignition.Start(). Можно запустить несколько узлов на одной машине или даже в одном процессе. - Кластер — набор нод, соединённых между собой. Ноды видят или не видят друг друга в зависимости от конфигурации. Таким образом, можно запустить несколько отдельных кластеров даже в пределах одного процесса.
Работа с данными
Хорошо, базу данных мы стартовали, теперь неплохо бы создать таблицы и наполнить их.
Таблица в Apache Ignite — это кэш, ICache<K, V>. Работа идёт напрямую с пользовательскими типами данных, так что у нас здесь и ORM в одном флаконе (хотя есть возможность работать с данными напрямую, без маппинга в объекты).
class Car
{
public string Model { get; set; }
public int Power { get; set; }
public override string ToString() => $"Model: {Model}, Power: {Power} hp";
}
static void Main()
{
using (var ignite = Ignition.Start())
{
ICache<int, Car> cache = ignite.GetOrCreateCache<int, Car>("cars");
cache[1] = new Car {Model = "Pagani Zonda R", Power = 740};
foreach (ICacheEntry<int, Car> entry in cache)
Console.WriteLine(entry);
}
}Как видим, базовая работа с кэшем ничем не отличается от всем знакомого Dictionary<,>. При этом данные немедленно доступны на всех узлах кластера.
Эту часть функционала можно сравнивать с Redis.
SQL
Данные можно добавлять и запрашивать через SQL. Для этого требуется явно указать, какие поля объекта принимают участие в запросах (атрибут [QuerySqlField]), и указать типы ключа и значения в конфигурации кэша:
class Car
{
[QuerySqlField] public string Model { get; set; }
[QuerySqlField] public int Power { get; set; }
}
...
// Конфигурируем кэш для работы с SQL:
var queryEntity = new QueryEntity(typeof(int), typeof(Car));
var cacheConfig = new CacheConfiguration("cars", queryEntity);
ICache<int, Car> cache = ignite.GetOrCreateCache<int, Car>(cacheConfig);
// Вставка данных (_key - предопределённое поле):
var insertQuery = new SqlFieldsQuery("INSERT INTO Car (_key, Model, Power) VALUES " +
"(1, 'Ariel Atom', 350), " +
"(2, 'Reliant Robin', 39)");
cache.QueryFields(insertQuery).GetAll();
// Запрос данных:
var selQuery = new SqlQuery(typeof(Car), "SELECT * FROM Car ORDER BY Power");
foreach (ICacheEntry<int, Car> entry in cache.Query(selQuery))
Console.WriteLine(entry);Эти два подхода, key-value и SQL, можно смешивать по вкусу. Получить или вставить одно значение проще и быстрее через cache[key], а обновить множество значений по условию — через SQL.
LINQ
Запрос из примера выше можно переписать на LINQ (потребуется NuGet пакет Apache.Ignite.Linq):
var linqSelect = cache.AsCacheQueryable().OrderBy(c => c.Value.Power);
foreach (ICacheEntry<int, Car> entry in linqSelect)
Console.WriteLine(entry);Этот запрос будет транслирован в SQL, в чём можно убедиться, приведя тип linqSelect к ICacheQueryable.
Обратите внимание на AsCacheQueryable() — это важно! Забыв этот вызов, мы превратим распределённый SQL запрос в LINQ-To-Objects, который приведёт к загрузке всех данных на локальный узел, чего мы обычно не хотим.
Как это работает?
По умолчанию кэши в Ignite работают в Partitioned режиме, в котором данные равномерно распределяются между узлами. SQL запрос отсылается на каждый узел и выполняется, результаты затем агрегируются на вызывающей ноде. Каждый узел параллельно с другими обрабатывает только свою часть данных. Добавляя больше узлов в кластер мы можем увеличить производительность и объём хранимых данных.
Для обеспечения отказоустойчивости можно указать одну или несколько резервных копий, то есть количество узлов, хранящих каждый элемент данных.
В некоторых случаях имеет смысл Replicated режим, где каждый узел хранит полную копию всех данных.
Map-Reduce, Locks, Atomics...
Предположим, нам необходимо перевести огромный текст, или распознать большое количество изображений. Такие задачи можно легко распараллелить между несколькими серверами:
class Translator : IComputeFunc<string, string>
{
public string Invoke(string text) => TranslateText(text);
}
...
IEnumerable<string> pages = GetTextPages();
ICollection<string> translated = ignite.GetCompute().Apply(new Translator(), pages);Синхронизировать различные процессы между узлами можно при помощи распределённых блокировок. Функционал аналогичен lock {} / Monitor, с той лишь разницей, что распространяется на весь кластер:
var cache = ignite.GetOrCreateCache<int, int>("foo");
using (ICacheLock lck = cache.Lock(1))
{
lck.Enter();
// делай дело
lck.Exit();
}Знакомы с классом Interlocked? Ignite предоставляет аналогичный неблокирующий функционал, только операции атомарны в пределах всего кластера.
var atomic = ignite.GetAtomicLong(name: "myVal", initialValue: 1, create: true);
atomic.Increment();
atomic.CompareExchange(10, 20);Эту группу фич можно сравнивать с Akka.
Заключение
Я работаю в GridGain, но пишу этот пост от лица контрибьютора Apache Ignite. Мне кажется, продукт заслуживает внимания. Особенно в .NET мире, где вся тема Big Data и распределенных вычислений слабо раскрыта. Мало таких проектов нормально поддерживают .NET, ещё меньше на нём написано.
Ignite.NET действительно легко попробовать, он запускается даже в LINQPad (примеры кода для LINQPad включены в NuGet!). Способов использования может быть масса. Есть интеграция с ASP.NET (output cache, session state cache), с Entity Framework (second level cache). Можно использовать как платформу для (микро)сервисов. В любом проекте, где требуется более одного сервера, Ignite может тем или иным образом облегчить жизнь.
Да, есть другие проекты, которые имеют ту или иную фичу Ignite, но нет другого проекта, где всё это объединено и интегрировано в один продукт.
Ссылки
- Сайт ignite.apache.org
- Код на GitHub github.com/apache/ignite
- Код .NET github.com/apache/ignite/tree/master/modules/platforms/dotnet
- NuGet nuget.org/packages/Apache.Ignite
- Примеры кода на GitHub
P. S. Мы в Apache Ignite всегда рады новым контрибьюторам! Есть множество интересных задач на .NET, C++, Java. Поучаствовать проще, чем кажется!
