

19 марта закончился третий чемпионат по машинному обучению на платформе ML Boot Camp. 614 человек прислали решения и поборолись за главный приз ー MacBook Air. Для нас это важный проект: мы хотим расширить сообщество ML-специалистов России. Поэтому в наших задачах сможет разобраться даже новичок. Теоретически… Профи же соревнуются благодаря сложности метрик и большому ряду параметров задачи.
Со второго контеста многое изменилось. Мы увеличили количество участников вдвое, прикрутили к серверу новую метрику, пофиксили баги и создали ML-комьюнити в Телеграме. Рассказываем, как проводили третий контест.
Придумали задачу
В первом контесте мы определяли класс последовательности из нулей и единиц. Во втором — оценивали производительность машин для реальной задачи, опираясь на список параметров системы.
Всё это здорово, но со стороны не всегда понятно, зачем это делать. На третьем чемпионате мы хотели показать максимальную применимость машинного обучения в реальных проектах. Поэтому приблизили задачу к продуктам Mail.Ru Group ー играм. Мы предложили предсказать поведение пользователя по его данным за последние две недели. Участники получали на входе 12 игровых признаков:
- максимальный уровень игры
- количество уровней, которые игрок попытался пройти
- число попыток на самом высоком уровне
- общее число попыток
- среднее количество ходов на пройденных уровнях
- количество использованных бустеров
- количество бустеров, использованных во время успешных попыток (игрок прошёл уровень)
- количество набранных очков
- количество бонусных очков
- количество звёзд
- количество дней, когда пользователь играл в игру
- возвращался ли игрок к уже пройденным уровням
По этим признакам участники контеста угадывали, останется человек в игре или уйдёт из неё. Данные были собраны с 25 тысяч реальных пользователей одной из онлайн-игр Mail.Ru Group и анонимизированы. Эта задача намного лучше практически применяется. Она выглядит фактурно. Мы любим такие задачи, поэтому:

Выбрали метрику
И ошиблись с ней
Изначально мы предложили участникам прислать нам файл, в котором хранился бы дискретный ответ для каждого пользователя, останется ли он в игре: 0 (нет) или 1 (да). В этот момент мы слегка облажались и перепутали метрику. Получилось, что мы собирались измерять успешность выборки с помощью средней ошибки (MAE). Эта метрика считает разности между каждым предложенным ответом и верным ответом, затем складывает их вместе и делит на количество ответов.

Дело в том, что MAE не предназначена для дискретных величин, о чём нам тут же сообщили участники. По сути, она даёт тот же результат, что и accuracy (количество правильных ответов, разделённое на количество вопросов).
Мы могли бы просто поменять название метрики на accuracy или предложить присылать вероятность ухода пользователя. Но, пообщавшись с участниками, решили двигаться дальше, чтобы избежать взлома лидерборда.
Испугались взлома лидерборда
Ситуацию, в которой участник добивается «идеального» ответа на тестовой выборке, можно назвать взломом лидерборда. На тестовой выборке взлом не гарантирует победы. С метрикой accuracy можно просто подбором вычислить все правильные ответы и получить 1. Очевидно, что это не прокатит на итоговой выборке, где шансы угадать при подборе будут 50/50.
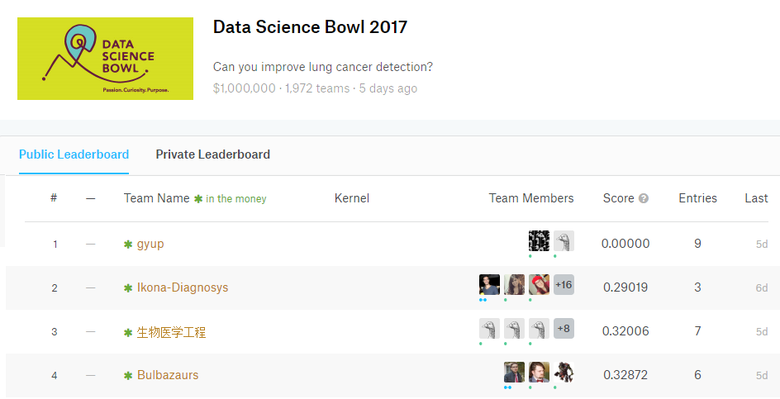
Взломанный лидерборд на чемпионате на Kaggle с призовым фондом 1 млн долларов. У gyup идеальный результат — 0 при логарифмической функции потерь (LogLoss) в качестве метрики. Это боль для любого организатора подобных чемпионатов
Взломанный лидерборд отпугивает потенциальных участников от чемпионата. Они смотрят и думают: «Зачем мне тратить свои силы, если тот тип уже сделал идеально». Они не знают, скрывается ли за его оценкой реально мощный алгоритм.
Подумали о чувствительности метрики
Насколько сильно одна ошибка влияет на весь результат — примем это за чувствительность метрики. В случае с accuracy мы могли получить слишком малый отрыв топовых игроков от остальных участвующих, поскольку ошибка влияет на результат линейно. А это крайне обидно и для топов (всегда приятно побеждать с большим отрывом), и для остальных (досадно, когда кажется, что ты чуть-чуть не дожал, хотя между вами пропасть). Кроме того, была опасность, что в топе окажутся люди с абсолютно одинаковым score. И что тогда делать? Призов-то ограниченное количество :)
С другими метриками ошибка влияет на результат сильнее. При среднеквадратичной ошибке, например, она возводится в квадрат. Мы постарались подобрать достаточно чувствительную метрику, чтобы участникам было где развернуться.
Выбрали логарифмическую функцию потерь
Пометавшись некоторое время между ROC, среднеквадратичной ошибкой (RMSE) и логарифмической функцией потерь, мы выбрали последнюю в качестве критерия:

Эта функция не линейна, имеет большую область значений и очень чувствительно реагирует на грубые ошибки. Если ты говоришь, что пользователь 100% уйдет, а он вдруг не уходит ー ты в глубокой… «Пробить» ее гораздо сложнее.
Поведение Loglossa по сравнению с MAE можно прикинуть на графиках:
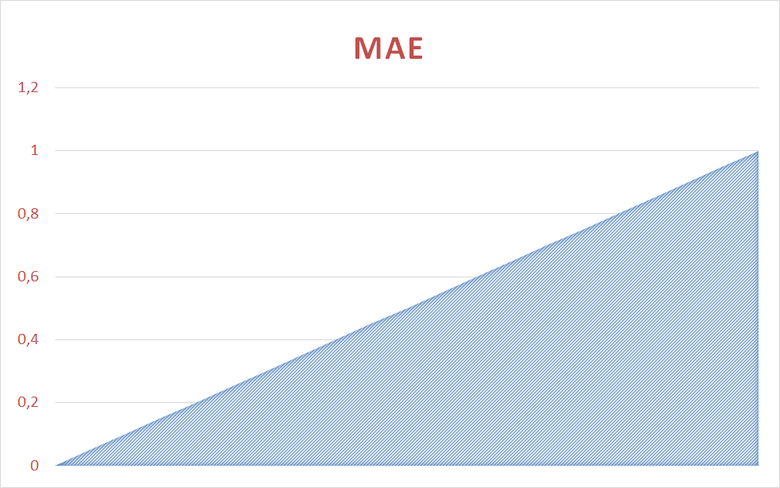
Средняя ошибка изменяется линейно от 0 до 1
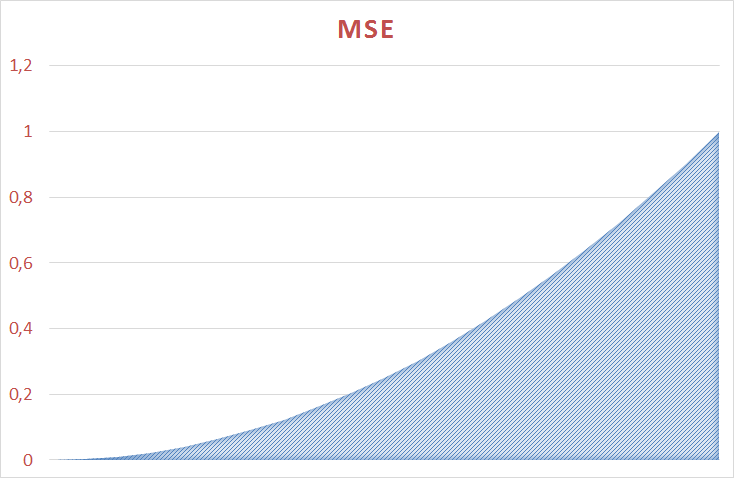
Средняя ошибка изменяется нелинейно от 0 до 1
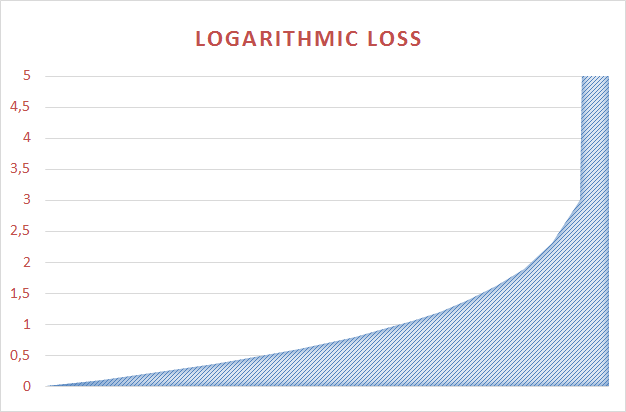
Функция логарифмических потерь изменяется нелинейно от 0 до 34,6
Мониторили результаты
С новыми критериями работа участников кипела, но результат выдавала средний. Score большинства быстро достиг 0,38 и встал. Метрика не давала сдвинуться с этой точки.
В определённый момент я ради мотивации бросил вызов участникам, сказав, что побреюсь налысо, если они смогут подняться хотя бы на 0,36 :). За время чемпионата этого не произошло.
Михаил Карачун (победитель) с третьей попытки добился критерия 0,3856 на тестовой выборке и 0,3869 на итоговой. К финишу чемпионата он получил результат 0,3808 на тестовой и 0,3814 на итоговой. Для этого ему потребовалось ещё 125 отправок.
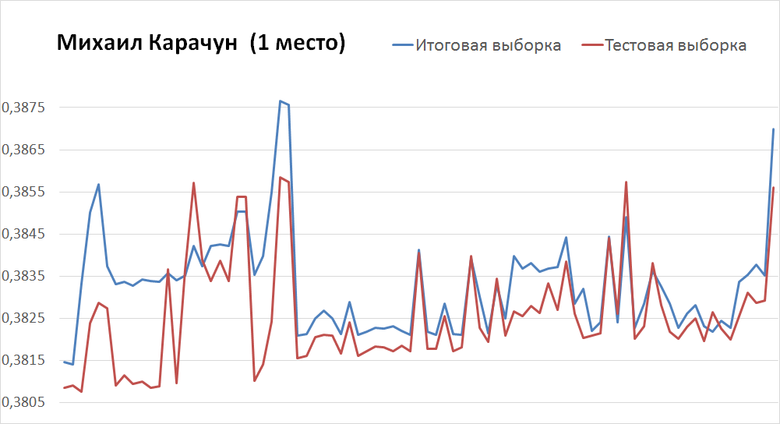
Самые последние отправки ー слева
Евгений Цацорин же стартовал с бодрых 0,3832 (тест) и 0,3851 (итог) и за 40 отправок пришёл к финальным 0,3818 (тест) и 0,3816 (итог). Заметьте, что его финальное решение дало на итоговой выборке результат лучше, чем на тестовой. График выглядит очень ровно, приятно; возникает ощущение, что ещё через пару дней Евгений мог бы выйти на первое место.

Самые последние отправки ー слева
Иван Тямгин с третьей попытки пришёл к 0,3984 (тест) и 0,3995 (итог) и за 100 отправок поднялся к 0,3807 (тест) и 0,3816 (итог).
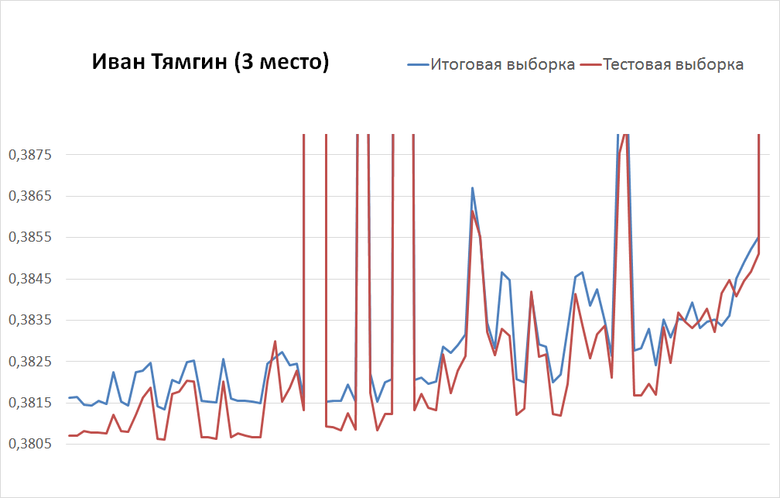
Самые последние отправки ー слева
Подвели итоги
После открытия итоговой выборки в лидерборде произошли изменения. Одним из самых стабильных оказался Иван Тямгин: он сохранил своё третье место и потерял при смене выборки всего 0,009.
Андрей Селиванов, обладатель лучшего решения на тестовой выборке (0,3796), оказался аж на 261-м месте (0,3844). Михаил Карачун и Евгений Цацорин же взлетели в топ, соответственно, с 5-го и 37-го места. Михаил стал двукратным победителем нашего чемпионата!

Лидерборд: топ-6 участников
Наградили победителей
Пятьдесят лучших участников чемпионата получили футболки с логотипом ML Boot Camp. Лидеров же мы наградили призами от компании Apple. За шестое, пятое и четвёртое место — iPod нано, за второе и третье — iPad, а за первое — MacBook Air.
Мы попросили лидеров чемпионата рассказать, как им удалось добиться таких результатов, и собрали их истории.

Михаил Карачун использовал в своём решении семь различных моделей — от регрессии до нейронных сетей.
Прочитать полный разбор решения Михаила можно в его публикации на Хабре.

Евгений Цацорин использовал в качестве основы алгоритм «случайный лес». Сначала Евгений опирался на топ-10 самых важных (по мнению алгоритма) фич, далее компоновал из них различные наборы, чтобы оценить их эффективность.
Полный разбор его решения также есть на Хабре.

Иван Тямгин в качестве основного инструмента выбрал xgboost. Иван воспользовался техникой Bootstrap aggregating. Делил выборку 200 раз случайным образом на обучающую и контрольную (оптимальным оказалось соотношение 0,95/0,05) и запускал xgboost. Итоговый классификатор — голосование (среднее) всех 200 базовых классификаторов. Это дало лучший результат, нежели самописный Random Forest или AdaBoost.
Полную историю можно найти в этой публикации.
Кроме того, рекомендуем к прочтению историю седьмого места от Александра Киселева. Отличный мотиватор для тех, кто ещё не разбирался с ML, но хочет попробовать ;)
Подготовили ништяки
Песочница
Сразу после финиша соревнований мы открыли Песочницу. Теперь участники могут продолжать совершенствовать своих ботов. А те, кто не участвовал в чемпионате, — присоединиться и попробовать свои силы.

В песочнице можно решать задачи старых контестов, в том числе закрытого студенческого чемпионата
По ссылке доступен полный набор материалов этого чемпионата и двух предыдущих контестов. Для участников в реальном времени формируется отдельный лидерборд Песочницы под каждую задачу.
Группа в Telegram
Ещё во время Russian AI Cup мы заметили, что участники с удовольствием собираются в мессенджерах, и решили поддержать эту тенденцию. Официальная группа чемпионата помогла нам быстро реагировать на замечания. А участники смогли обсудить волнующие их моменты. Получилось круто.
В группе участвуют опытные машинлёрнеры, включая победителей чемпионата
Даже после окончания контеста в группе идут обсуждения по теме ML — и не только. Добавляйтесь, если решаете задачи Песочницы. Здесь вам помогут советом и добрым словом.
Благодарности
От имени Mail.Ru Group выражаем огромную благодарность ННГУ им. Н.И.Лобачевского и лично Николаю Юрьевичу Золотых и Олегу Дурандину за неоценимую помощь в подготовке таких интересных задач и экспертное сопровождение чемпионата! Николай и Олег участвовали в проведении каждого нашего ML чемпионата, без них мы не осилили бы и половины того, что сделано сейчас.
Выбор нескольких решений
Во время чемпионата многие просили разрешить выбор нескольких вариантов в качестве финальных. Например, один с более устойчивой моделью, второй — с большим score на паблике.
Мы так и сделаем. В следующем чемпионате участники будут предлагать два финальных решения вместо одного. А мы сформируем финальный лидерборд по лучшему из выбранных.
ML Boot Camp IV
Мы довольны итогами третьего состязания и 21-го числа откроем четвёртый контест! Присоединяйтесь к нашему чемпионату, следите за новостями, попробуйте задачи в Песочнице, и да пребудет с вами сила!
