
Меня зовут Пётр Ромов, я — data scientist в Yandex Data Factory. В этом посте я предложу сравнительно простой и надежный способ начать карьеру аналитика данных.
Многие из вас наверняка знают или хотя бы слышали про Kaggle. Для тех, кто не слышал: Kaggle — это площадка, на которой компании проводят конкурсы по созданию прогнозирующих моделей. Её популярность столь велика, что часто под «кэглами» специалисты понимают сами конкурсы. Победитель каждого соревнования определяется автоматически — по метрике, которую назначил организатор. Среди прочих, Kaggle в разное время опробовали Facebook, Microsoft и нынешний владелец площадки — Google. Яндекс тоже несколько раз отметился. Как правило, Kaggle-сообществу дают решать задачи, довольно близкие к реальным: это, с одной стороны, делает конкурс интересным, а с другой — продвигает компанию как работодателя с солидными задачами. Впрочем, если вам скажут, что компания-организатор конкурса задействовала в своём сервисе алгоритм одного из победителей, — не верьте. Обычно решения из топа слишком сложны и недостаточно производительны, а погони за тысячными долями значения метрики не настолько и нужны на практике. Поэтому организаторов больше интересуют подходы и идейная часть алгоритмов.

Kaggle — не единственная площадка с соревнованиями по анализу данных. Существуют и другие: DrivenData, DataScience.net, CodaLab. Кроме того, конкурсы проводятся в рамках научных конференций, связанных с машинным обучением: SIGKDD, RecSys, CIKM.
Для успешного решения нужно, с одной стороны, изучить теорию, а с другой — начать практиковать использование различных подходов и моделей. Другими словами, участие в «кэглах» вполне способно сделать из вас аналитика данных. Вопрос — как научиться в них участвовать?
Три года назад несколько студентов ШАД начали собираться и решать разные интересные задания, в том числе взятые с Kaggle. Например, среди этих ребят был нынешний обладатель второго места и недавний лидер рейтинга Kaggle Станислав Семёнов. Со временем встречи получили название тренировок по машинному обучению. Они набирали популярность, участники стали регулярно занимать призовые места и рассказывать друг другу о своих решениях, делиться опытом.
Чтобы было понятно, чем именно мы занимаемся на тренировках, я приведу несколько примеров. В каждом примере сначала идёт видео с рассказом, а затем — текст, составленный по мотивам видео.
Ссылка на MachineLearning.ru.
В прошлом году компания «Авито» провела целый ряд конкурсов. В том числе — конкурс по распознаванию марок автомобилей, победитель которого, Евгений Нижибицкий, рассказал на тренировке о своём решении.
Постановка задачи. По изображениям автомобилей необходимо определить марку и модель. Метрикой служила точность предсказаний, то есть доля правильных ответов. Выборка состояла из трёх частей: первая часть была доступна для обучения изначально, вторая была дана позже, а на третьей требовалось показать финальные предсказания.


Вычислительные ресурсы. Я воспользовался домашним компьютером, который обогревал мою комнату всё это время, и предоставленными на работе серверами.

Обзор моделей. Раз наша задача — на распознавание, то первым делом хочется воспользоваться прогрессом в уровне качества классификации изображений на всем известном ImageNet. Как известно, современные архитектуры позволяют достигнуть даже более высокого качества, чем у человека. Поэтому я начал с обзора свежих статей и собрал сводную таблицу архитектур, реализаций и качеств на основе ImageNet.
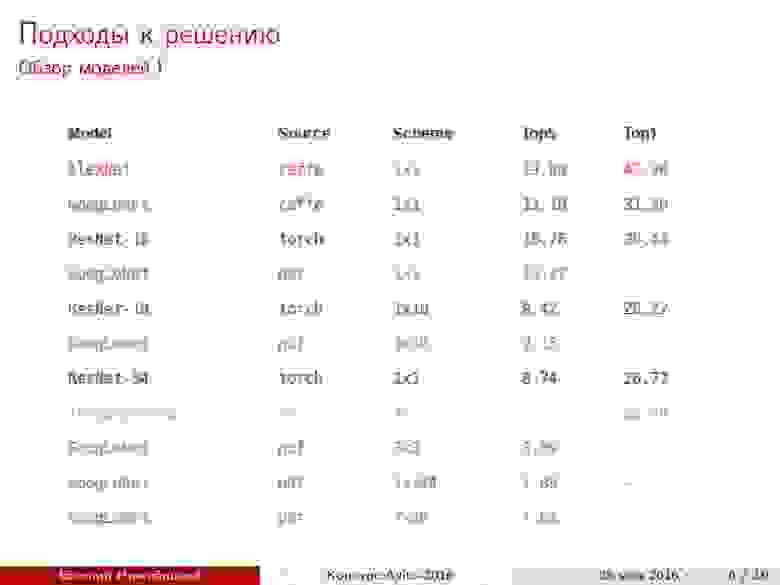

Заметим, что наилучшее качество достигается на архитектурах Inception и ResNet.
Fine-tuning сетей. Обучать глубокую нейронную сеть с нуля — довольно затратное по времени занятие, к тому же не всегда эффективное с точки зрения результата. Поэтому часто используется техника дообучения сетей: берётся уже обученная на ImageNet сеть, последний слой заменяется на слой с нужным количеством классов, а потом продолжается настройка сети с низким темпом обучения, но уже на данных из конкурса. Такая схема позволяет обучить сеть быстрее и с более высоким качеством.
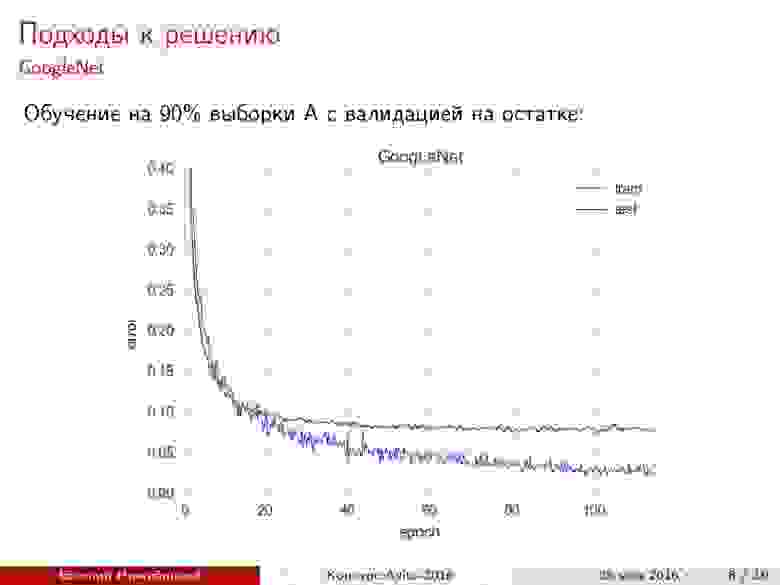
Первый подход к дообучению GoogLeNet показал примерно 92% точности при валидации.
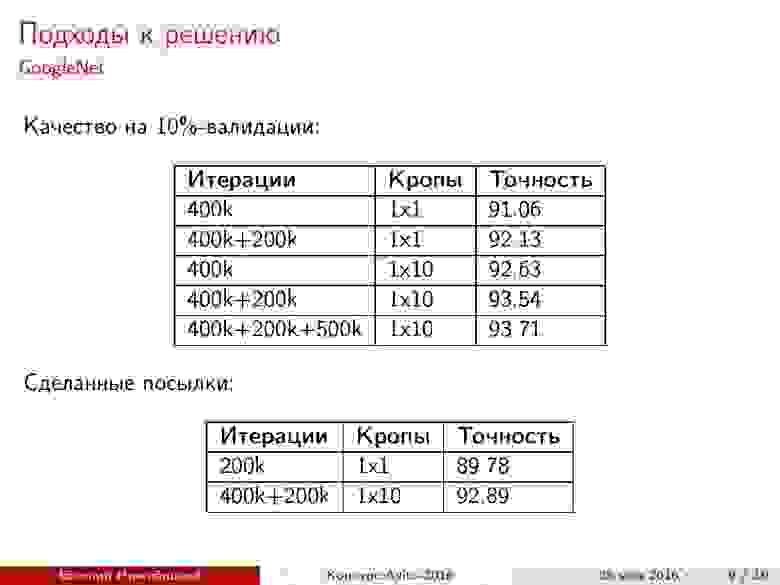
Предсказания на кропах. Используя нейронную сеть для предсказания на тестовой выборке, можно улучшить качество. Для этого следует выреза́ть фрагменты подходящего размера в разных местах исходной картинки, после чего усреднять результаты. Кроп 1x10 означает, что взят центр изображения, четыре угла, а потом всё то же самое, но отражённое по горизонтали. Как видно, качество возрастает, однако время предсказания увеличивается.
Валидация результатов. После появления выдачи второй части выборки я разбил выборку на несколько частей. Все дальнейшие результаты показаны на этом разбиении.

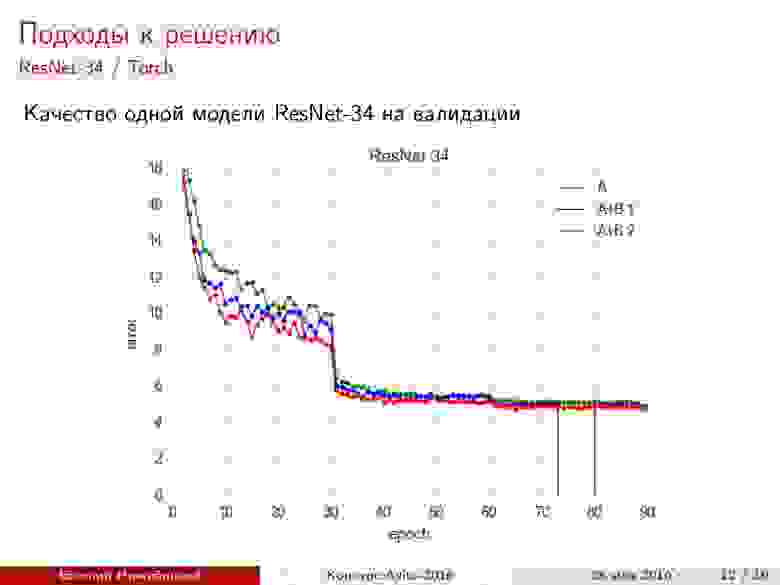
ResNet-34 Torch. Можно воспользоваться готовым репозиторием авторов архитектуры, но, чтобы получить предсказания на тесте в нужном формате, приходится исправлять некоторые скрипты. Кроме того, нужно решать проблемы большого потребления памяти дампами. Точность при валидации — около 95%.

Inception-v3 TensorFlow. Тут тоже использовалась готовая реализация, но была изменена предобработка изображений, а также ограничена обрезка картинок при генерации батча. Итог — почти 96% точности.

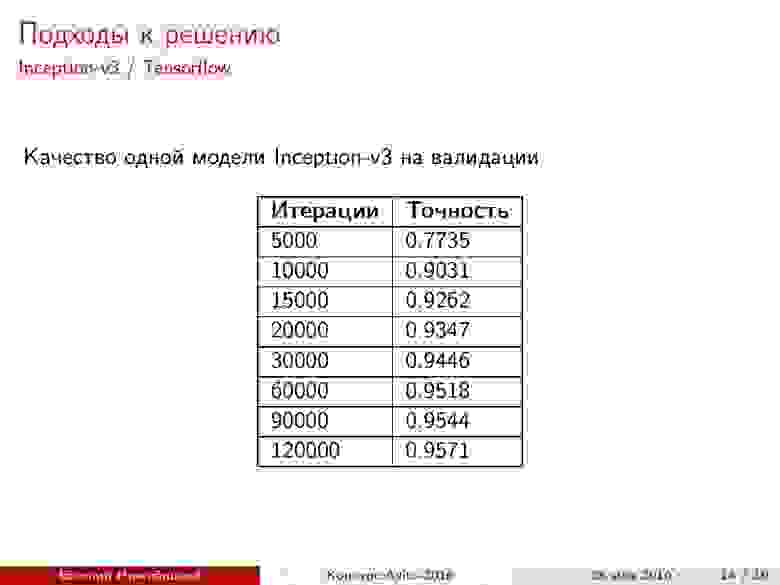
Ансамбль моделей. В итоге получилось две модели ResNet и две модели Inception-v3. Какое качество при валидации можно получить, смешивая модели? Вероятности классов усреднялись с помощью геометрического среднего. Веса (в данном случае — степени) подбирались на отложенной выборке.


Результаты. Обучение ResNet на GTX 980 занимало 60 часов, а Inception-v3 на TitanX — 48 часов. За время конкурса удалось опробовать новые фреймворки с новыми архитектурами.

Ссылка на Kaggle.
Станислав Семёнов рассказывает, как он и другие участники топа Kaggle объединились и заняли призовое место в соревновании по классификации заявок клиентов крупного банка — BNP Paribas.
Постановка задачи. По обфусцированным данных из заявок на страхование необходимо предсказать, можно ли без дополнительных ручных проверок подтвердить запрос. Для банка это процесс автоматизации обработки заявок, а для аналитиков данных — просто задача машинного обучения по бинарной классификации. Имеется около 230 тысяч объектов и 130 признаков. Метрика — LogLoss. Стоит отметить, что команда-победитель расшифровала данные, что помогло им выиграть соревнование.
Избавление от искусственного шума в признаках. Первым делом стоит посмотреть на данные. Cразу бросаются в глаза несколько вещей. Во-первых, все признаки принимают значения от 0 до 20. Во-вторых, если посмотреть на распределение любого из признаков, то можно увидеть следующую картинку:
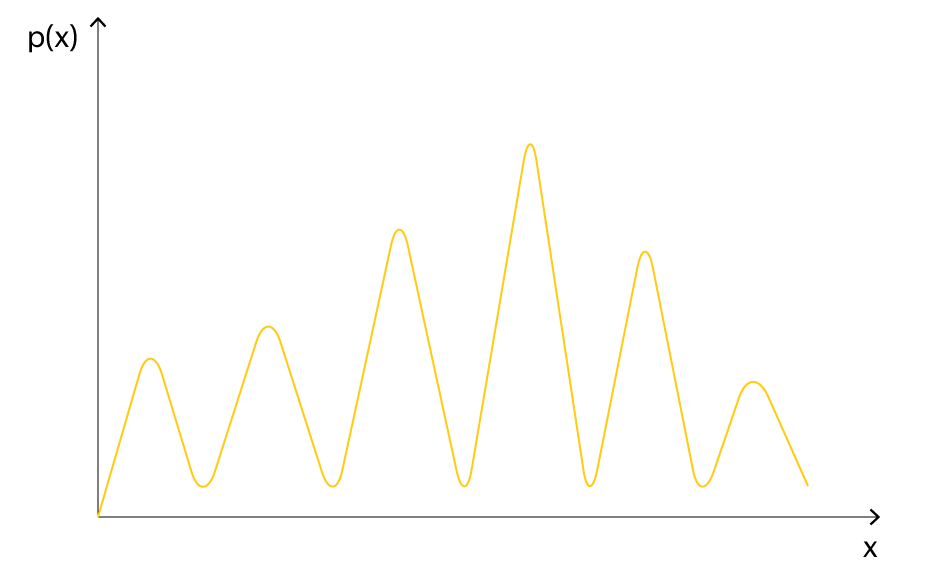
Почему так? Дело в том, что на этапе анонимизации и зашумления данных ко всем значениям прибавлялся случайный шум, а потом проводилось масштабирование на отрезок от 0 до 20. Обратное преобразование было проведено в два шага: сначала значения округлялись до некоторого знака после запятой, а потом подбирался деноминатор. Требовалось ли это, если дерево всё равно подбирает порог при разбиении? Да, после обратного преобразования разности переменных начинают нести больший смысл, а для категориальных переменных появляется возможность провести one-hot кодирование.
Удаление линейно зависимых признаков. Ещё мы заметили, что некоторые признаки являются суммой других. Понятно, что они не нужны. Для их определения брались подмножества признаков. На таких подмножествах строилась регрессия для предсказания некоторой другой переменной. И если предсказанные значения были близки к истинным (стоит учесть искусственное зашумление), то признак можно было удалить. Но команда не стала с этим возиться и воспользовалась уже готовым набором фильтрованных признаков. Набор подготовил кто-то другой. Одна из особенностей Kaggle — наличие форума и публичных решений, с помощью которых участники делятся своими находками.
Как понять, что нужно использовать? Есть небольшой хак. Предположим, вы знаете, что кто-то в старых соревнованиях использовал некоторую технику, которая помогла ему занять высокое место (на форумах обычно пишут краткие решения). Если в текущем конкурсе этот участник снова в числе лидеров — скорее всего, такая же техника выстрелит и здесь.
Кодирование категориальных переменных. Бросилось в глаза то, что некая переменная V22 имеет большое число значений, но при этом, если взять подвыборку по некоторому значению, число уровней (различных значений) других переменных заметно уменьшается. В том числе имеет место хорошая корреляция с целевой переменной. Что можно сделать? Самое простое решение — построить для каждого значения V22 отдельную модель, но это всё равно что в первом сплите дерева сделать разбиение по всем значениям переменной.
Есть другой способ использования полученной информации — кодирование средним значением целевой переменной. Другими словами, каждое значение категориальной переменной заменяется средним значением таргета по объектам, у которых данный признак принимает то же самое значение. Произвести такое кодирование напрямую для всего обучающего множества нельзя: в процессе мы неявно внесём в признаки информацию о целевой переменной. Речь идёт об информации, которую почти любая модель обязательно обнаружит.
Поэтому такие статистики считают по фолдам. Вот пример:
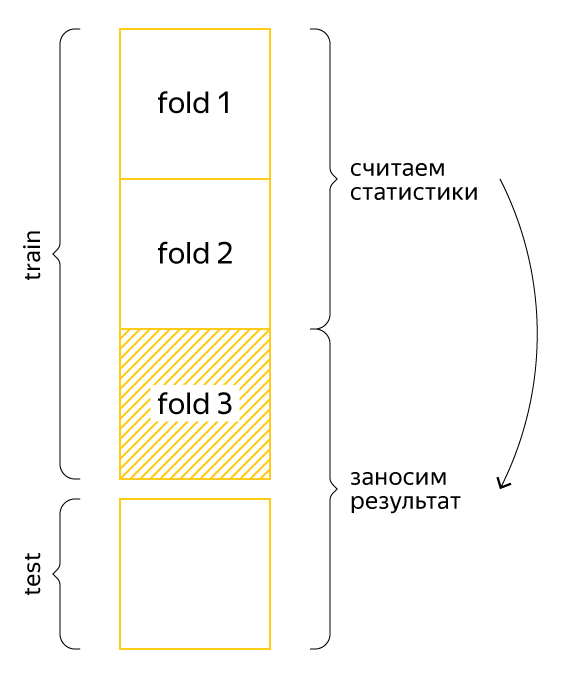
Предположим, что данные разбиты на три части. Для каждого фолда обучающей выборки будем считать новый признак по двум другим фолдам, а для тестовой выборки — по всему обучающему множеству. Тогда информация о целевой переменной будет внесена в выборку не так явно, и модель сможет использовать полученные знания.
Останутся ли проблемы ещё с чем-нибудь? Да — с редко встречающимися категориями и с кросс-валидацией.
Редко встречающиеся категории. Допустим, некоторая категория встретилась всего несколько раз и соответствующие объекты относятся к классу 0. Тогда среднее значение целевой переменной тоже будет нулевым. Однако на тестовой выборке может возникнуть совсем другая ситуация. Решение — сглаженное среднее (или smoothed likelihood), которое вычисляется по следующей формуле:

Здесь global mean — среднее значение целевой переменной по всей выборке, nrows — то, сколько раз встретилось конкретное значение категориальной переменной, alpha — параметр регуляризации (например, 10). Теперь, если некоторое значение встречается редко, больший вес будет иметь глобальное среднее, а если достаточно часто, результат окажется близким к начальному среднему по категории. Кстати, эта формула позволяет обрабатывать и неизвестные ранее значения категориальной переменной.
Кросс-валидация. Допустим, мы посчитали все сглаженные средние для категориальных переменных по другим фолдам. Можем ли мы оценить качество модели по стандартной кросс-валидации k-fold? Нет. Давайте рассмотрим пример.
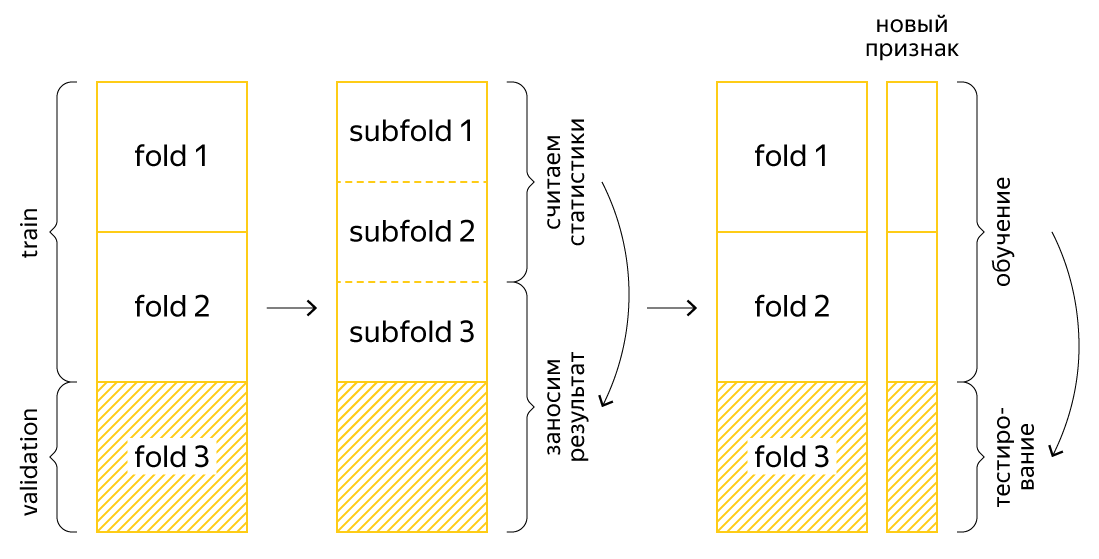
К примеру, мы хотим оценить модель на третьем фолде. Мы обучаем модель на первых двух фолдах, но в них есть новая переменная со средним значением целевой переменной, при подсчёте которой мы уже использовали третий тестовый фолд. Это не позволяет нам корректно оценивать результаты, но возникшая проблема решается подсчётом статистик по фолдам внутри фолдов. Снова обратимся к примеру:
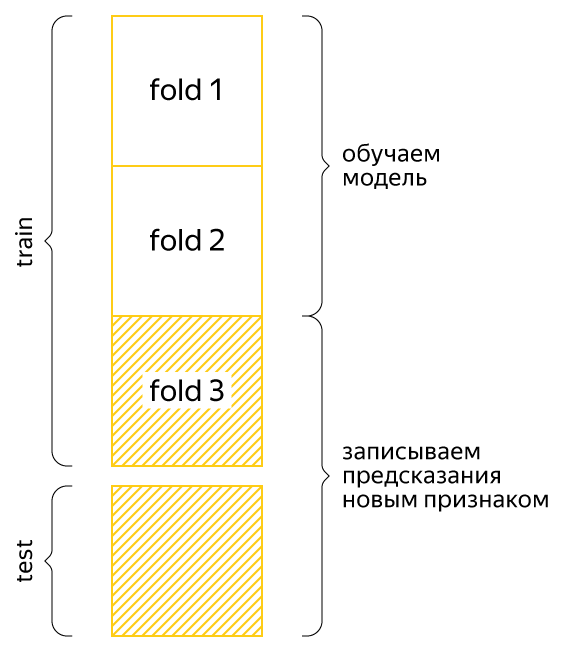
Мы по-прежнему хотим оценить модель на третьем фолде. Разобьём первые два фолда (обучающую выборку нашей оценки) на некоторые другие три фолда, в них посчитаем новый признак по уже разобранному сценарию, а для третьего фолда (это тестовая выборка нашей оценки) посчитаем по первым двум фолдам вместе. Тогда никакая информация из третьего фолда при обучении модели использоваться не будет и оценка получится честной. В соревновании, которое мы обсуждаем, корректно оценить качество модели позволяла только такая кросс-валидация. Разумеется, «внешнее» и «внутреннее» число фолдов может быть любым.
Построение признаков. Мы использовали не только уже упомянутые сглаженные средние значения целевой переменной, но и weights of evidence. Это почти то же самое, но с логарифмическим преобразованием. Кроме того, полезными оказались фичи вида разности количества объектов положительного и отрицательного классов в группе без какой-либо нормировки. Интуиция тут следующая: масштаб показывает степень уверенности в классе, но что делать с количественными признаками? Ведь если их обработать похожим образом, то все значения «забьются» регуляризацией глобальным средним. Одним из вариантов является разделение значений на бины, которые потом считаются отдельными категориями. Другой способ заключается просто в построении некой линейной модели на одном признаке с тем же таргетом. Всего получилось около двух тысяч признаков из 80 отфильтрованных.
Стекинг и блендинг. Как и в большинстве соревнований, важной частью решения является стекинг моделей. Если кратко, то суть стекинга в том, что мы передаём предсказания одной модели как признак в другую модель. Однако важно в очередной раз не переобучиться. Давайте просто разберём пример:

Взято из блога Александра Дьяконова
К примеру, мы решили разбить нашу выборку на три фолда на этапе стекинга. Аналогично подсчёту статистик мы должны обучать модель на двух фолдах, а предсказанные значения добавлять для оставшегося фолда. Для тестовой выборки можно усреднить предсказания моделей с каждой пары фолдов. Каждым уровнем стекинга называют процесс добавления группы новых признаков-предсказаний моделей на основе имеющегося датасета.
На первом уровне у команды было 200-250 различных моделей, на втором — ещё 20-30, на третьем — ещё несколько. Результат — блендинг, то есть смешивание предсказаний различных моделей. Использовались разнообразные алгоритмы: градиентные бустинги с разными параметрами, случайные леса, нейронные сети. Главная идея — применить максимально разнообразные модели с различными параметрами, даже если они дают не самое высокое качество.
Работа в команде. Обычно участники объединяются в команды перед завершением конкурса, когда у каждого уже имеются свои наработки. Мы объединились в команду с другими «кэглерами» ещё в самом начале. У каждого участника команды была папка в общем облаке, где размещались датасеты и скрипты. Общую процедуру кросс-валидации утвердили заранее, чтобы можно было сравнивать между собой. Роли распределялись следующим образом: я придумывал новые признаки, второй участник строил модели, третий — отбирал их, а четвёртый управлял всем процессом.
Откуда брать мощности. Проверка большого числа гипотез, построение многоуровневого стекинга и обучение моделей могут занимать слишком большое время, если использовать ноутбук. Поэтому многие участники пользуются вычислительными серверами с большим количеством ядер и оперативной памяти. Я обычно пользуюсь серверами AWS, а участники моей команды, как оказалось, используют для конкурсов машины на работе, пока те простаивают.
Общение с компанией-организатором. После успешного выступления в конкурсе происходит общение с компанией в виде совместного конференц-звонка. Участники рассказывают о своём решении и отвечают на вопросы. В BNP людей не удивил многоуровневый стекинг, а интересовало их, конечно же, построение признаков, работа в команде, валидация результатов — всё, что может им пригодиться в улучшении собственной системы.
Нужно ли расшифровывать датасет. Команда-победитель заметила в данных одну особенность. Часть признаков имеет пропущенные значения, а часть не имеет. То есть некоторые характеристики не зависели от конкретных людей. Кроме того, получилось 360 уникальных значений. Логично предположить, что речь идёт о неких временных отметках. Оказалось, если взять разность между двумя такими признаки и отсортировать по ней всю выборку, то сначала чаще будут идти нули, а потом единицы. Именно этим и воспользовались победители.
Наша команда заняла третье место. Всего участвовало почти три тысячи команд.
Ссылка на DataRing.
Это ещё один конкурс «Авито». Он проходил в несколько этапов, первый из которых (как, впрочем, ещё и третий) выиграл Артур Кузин N01Z3.
Постановка задачи. По фотографиям из объявления необходимо определить категорию. Каждому объявлению соответствовало от одного до пяти изображений. Метрика учитывала совпадения категорий на разных уровнях иерархии — от общих к более узким (последний уровень содержит 194 категории). Всего в обучающей выборке был почти миллион изображений, что близко к размеру ImageNet.


Сложности распознавания. Казалось бы, надо всего лишь научиться отличать телевизор от машины, а машину от обуви. Но, например, есть категория «британские кошки», а есть «другие кошки», и среди них встречаются очень похожие изображения — хотя отличить их друг от друга всё-таки можно. А как насчёт шин, дисков и колёс? Тут и человек не справится. Указанные сложности — причина появления некоторого предела результатов всех участников.


Ресурсы и фреймворк. У меня в распоряжении оказались три компьютера с мощными видеокартами: домашний, предоставленный лабораторией в МФТИ и компьютер на работе. Поэтому можно было (и приходилось) обучать по несколько сетей одновременно. В качестве основного фреймворка обучения нейронных сетей был выбран MXNet, созданный теми же ребятами, которые написали всем известный XGBoost. Одно это послужило поводом довериться их новому продукту. Преимущество MXNet в том, что прямо из коробки доступен эффективный итератор со штатной аугментацией, которой достаточно для большинства задач.


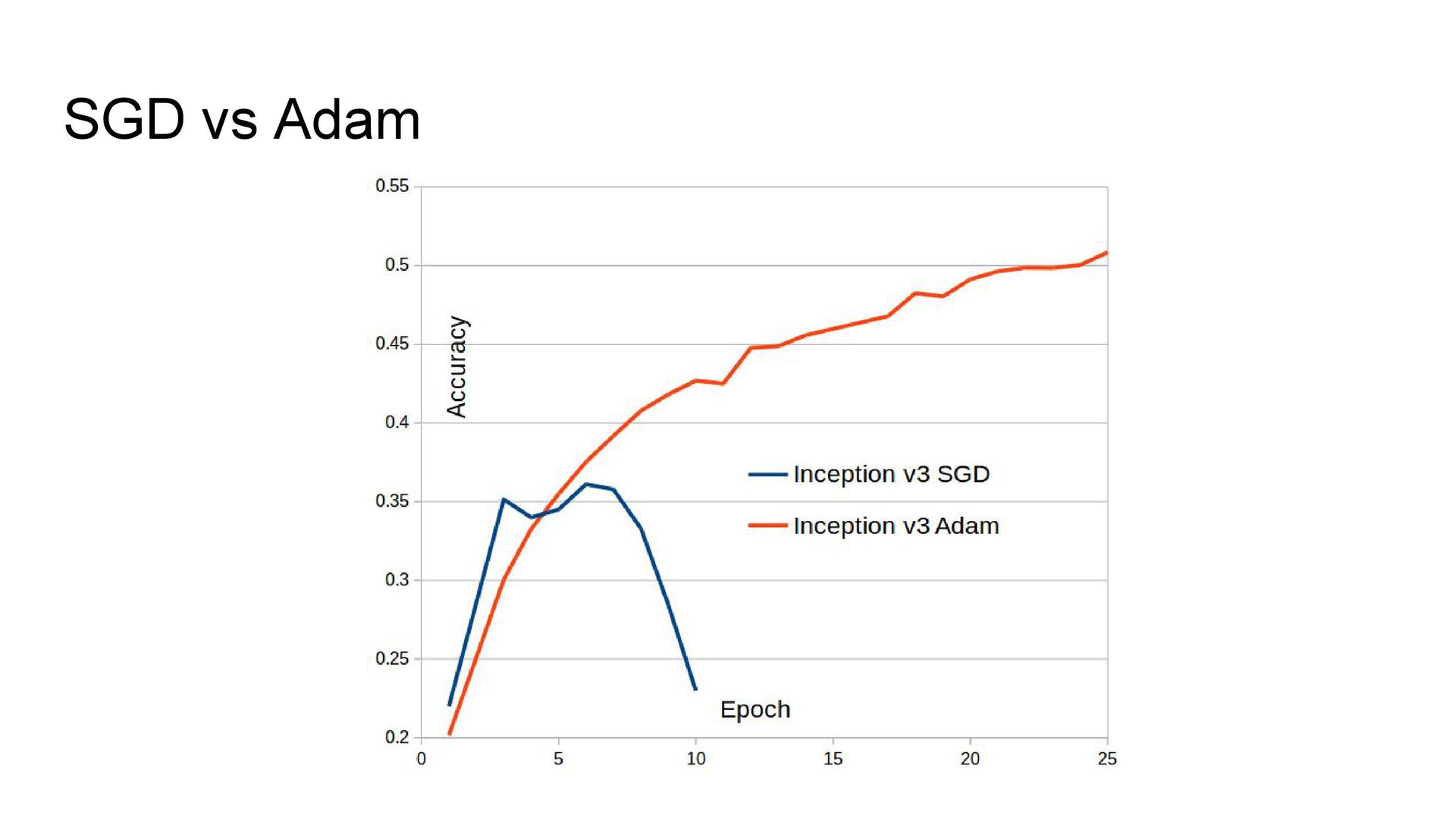
Архитектуры сетей. Опыт участия в одном из прошлых соревнований показал, что лучшее качество показывают архитектуры серии Inception. Их я и задействовал здесь. В GoogLeNet была добавлена батч-нормализация, поскольку она ускоряла обучение модели. Также использовались архитектуры Inception-v3 и Inception BN из библиотеки моделей Model Zoo, в которые был добавлен дропаут перед последним полносвязным слоем. Из-за технических проблем не удавалось обучать сеть с помощью стохастического градиентного спуска, поэтому в качестве оптимизатора использовался Adam.


Аугментация данных. Для повышения качества сети использовалась аугментация — добавление искажённых изображений в выборку с целью увеличения разнообразия данных. Были задействованы такие преобразования, как случайное обрезание фотографии, отражение, поворот на небольшой угол, изменение соотношения сторон и сдвиг.
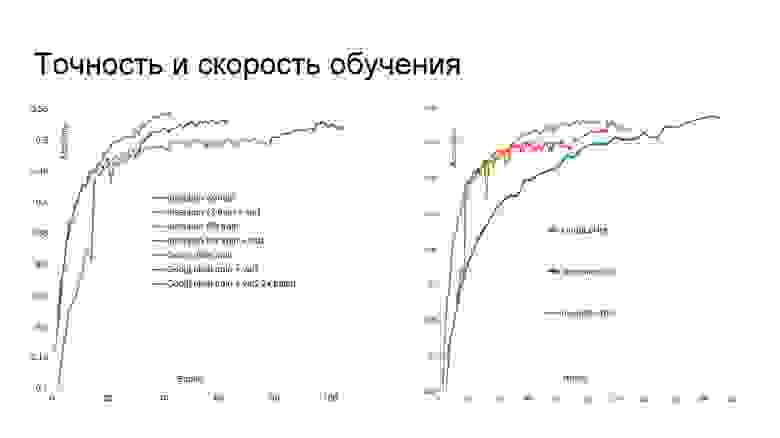
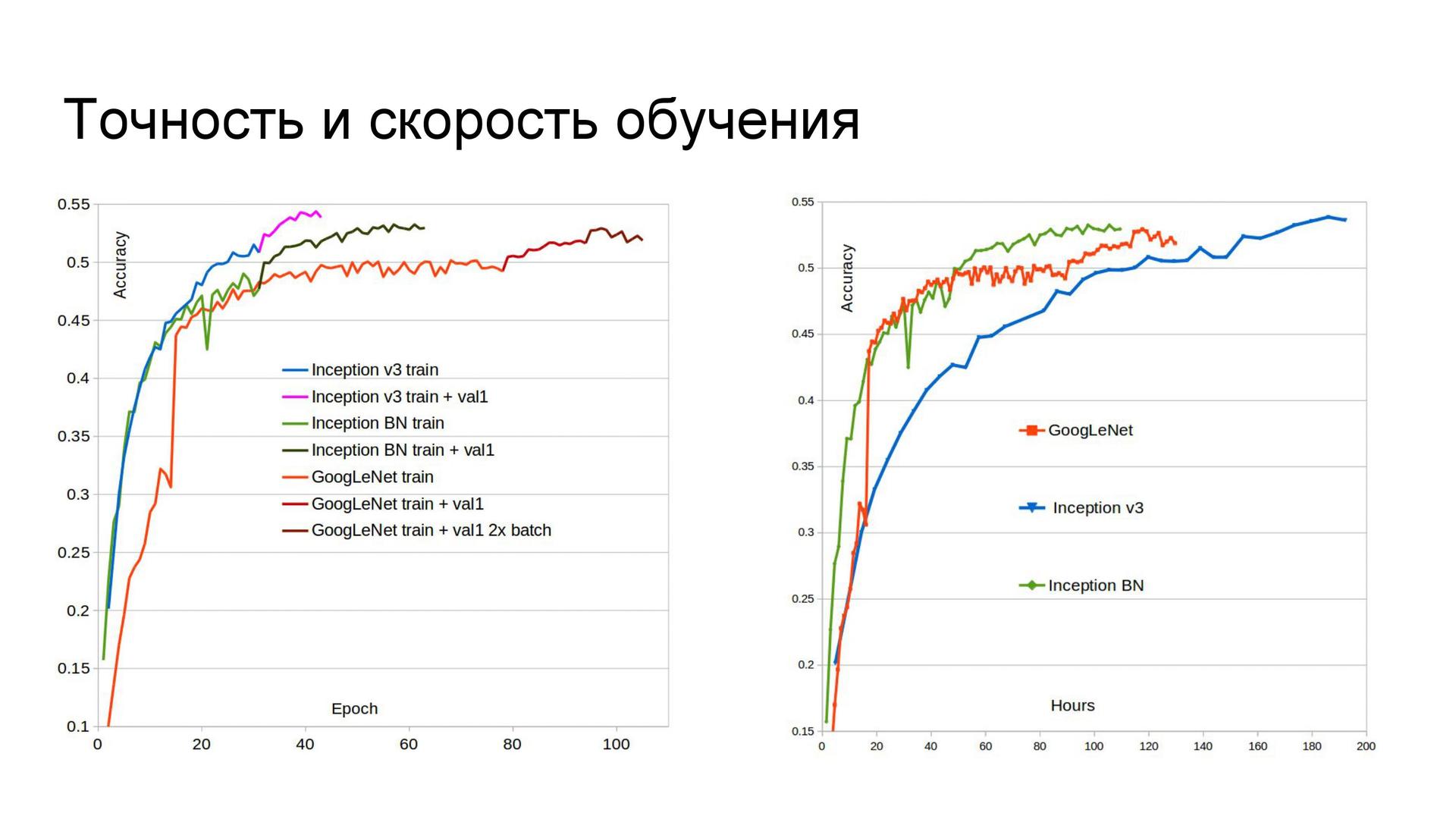
Точность и скорость обучения. Сначала я разделил выборку на три части, но потом отказался от одного из этапов валидации для смешивания моделей. Поэтому впоследствии вторая часть выборки была добавлена в обучающее множество, что улучшило качество сетей. Кроме того, GoogLeNet изначально обучался на Titan Black, у которого вдвое меньше памяти по сравнению с Titan X. Так что эта сеть была дообучена с большим размером батча, и её точность возросла. Если посмотреть на время обучения сетей, можно сделать вывод, что в условиях ограниченных сроков не стоит использовать Inception-v3, поскольку с двумя другими архитектурами обучение идёт заметно быстрее. Причина в числе параметров. Быстрее всех учится Inception BN.
Построение предсказаний.
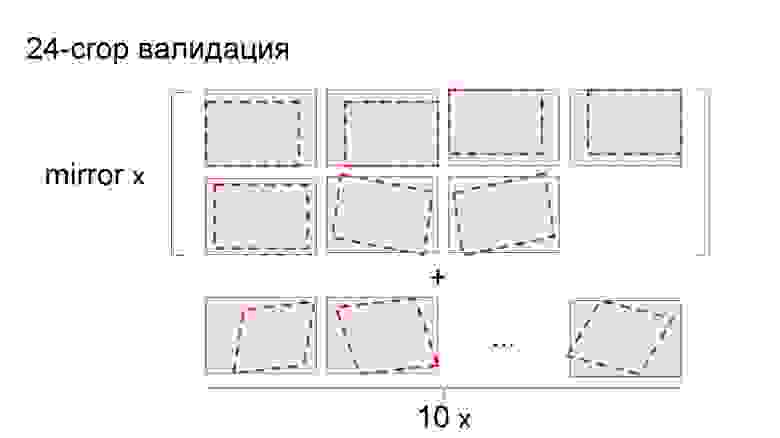
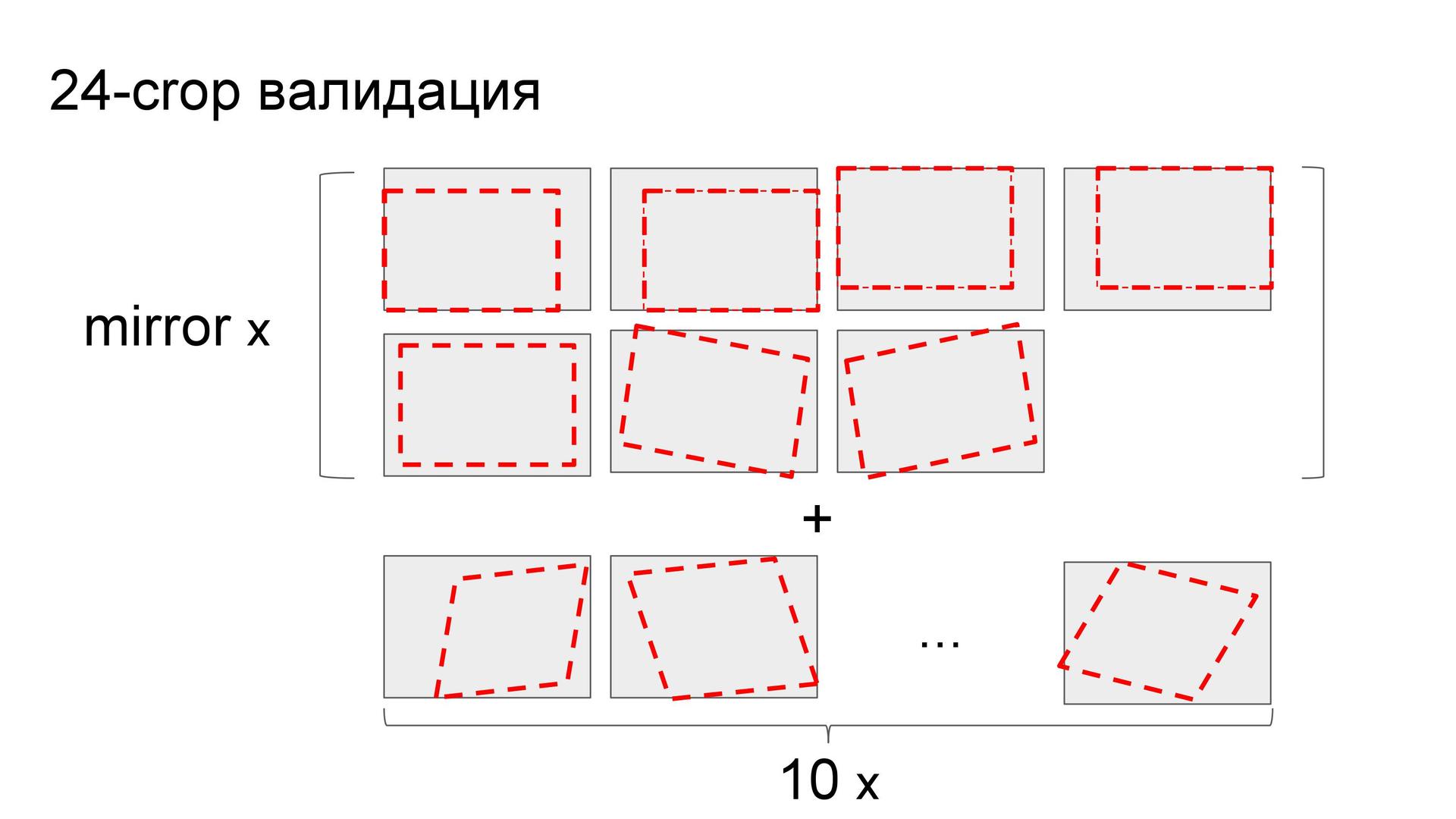
Как и Евгений в конкурсе с марками автомобилей, Артур использовал предсказания на кропах — но не на 10 участках, а на 24. Участками послужили углы, их отражения, центр, повороты центральных частей и ещё десять случайных.
Если сохранять состояние сети после каждой эпохи, в результате образуется множество различных моделей, а не только финальная сеть. С учётом оставшегося до конца соревнования времени я мог использовать предсказания 11 моделей-эпох — поскольку построение предсказаний с помощью сети тоже длится немало. Все указанные предсказания усреднялись по следующей схеме: сначала с помощью арифметического среднего в рамках групп по кропам, далее с помощью геометрического среднего с весами, подобранными на валидационном множестве. Эти три группы смешиваются, потом повторяем операцию для всех эпох. В конце вероятности классов всех картинок одного объявления усредняются с помощью геометрического среднего без весов.

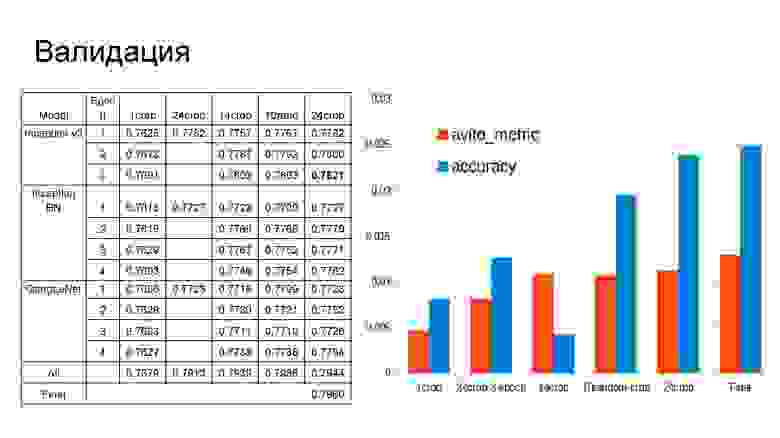
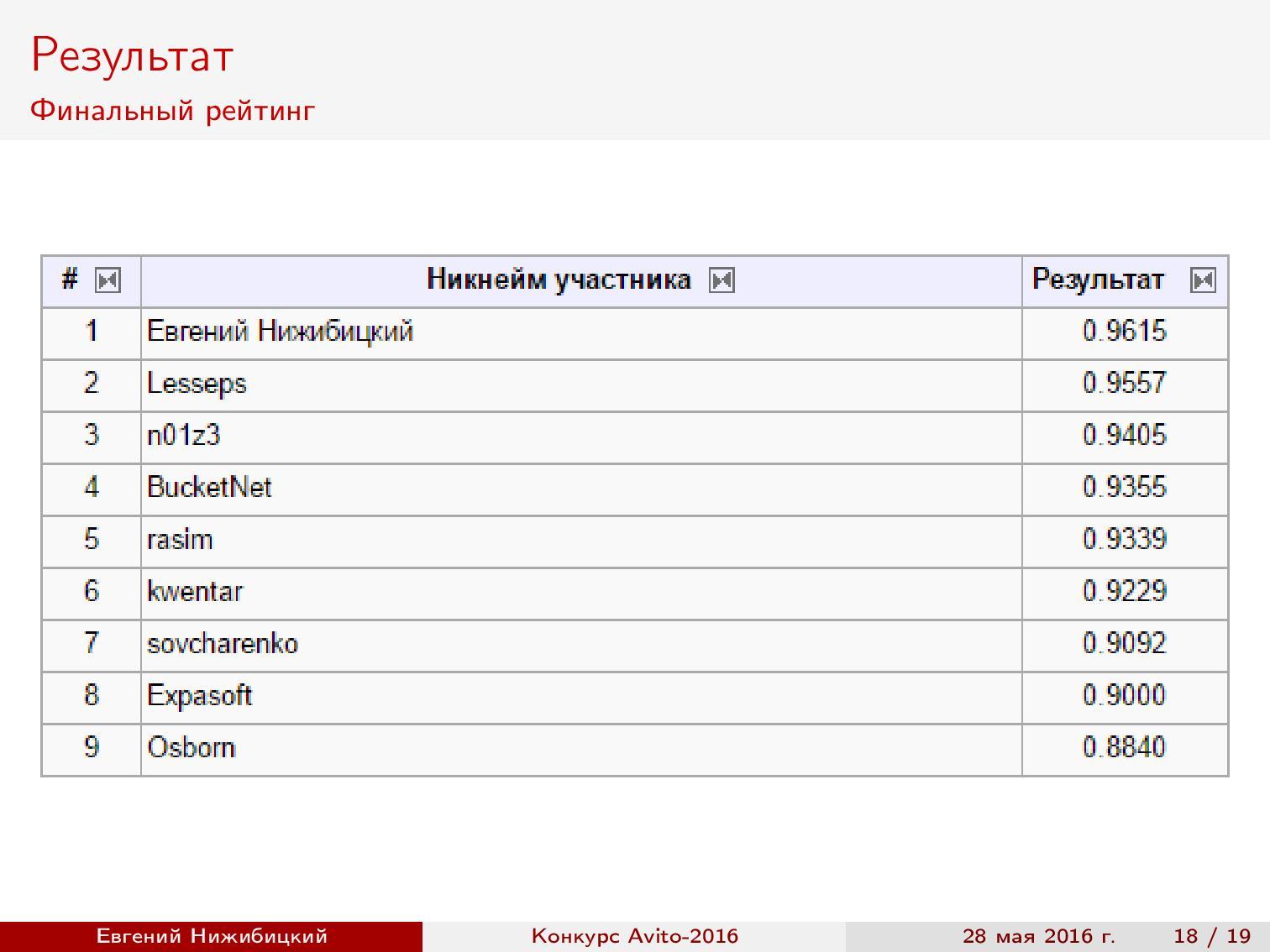
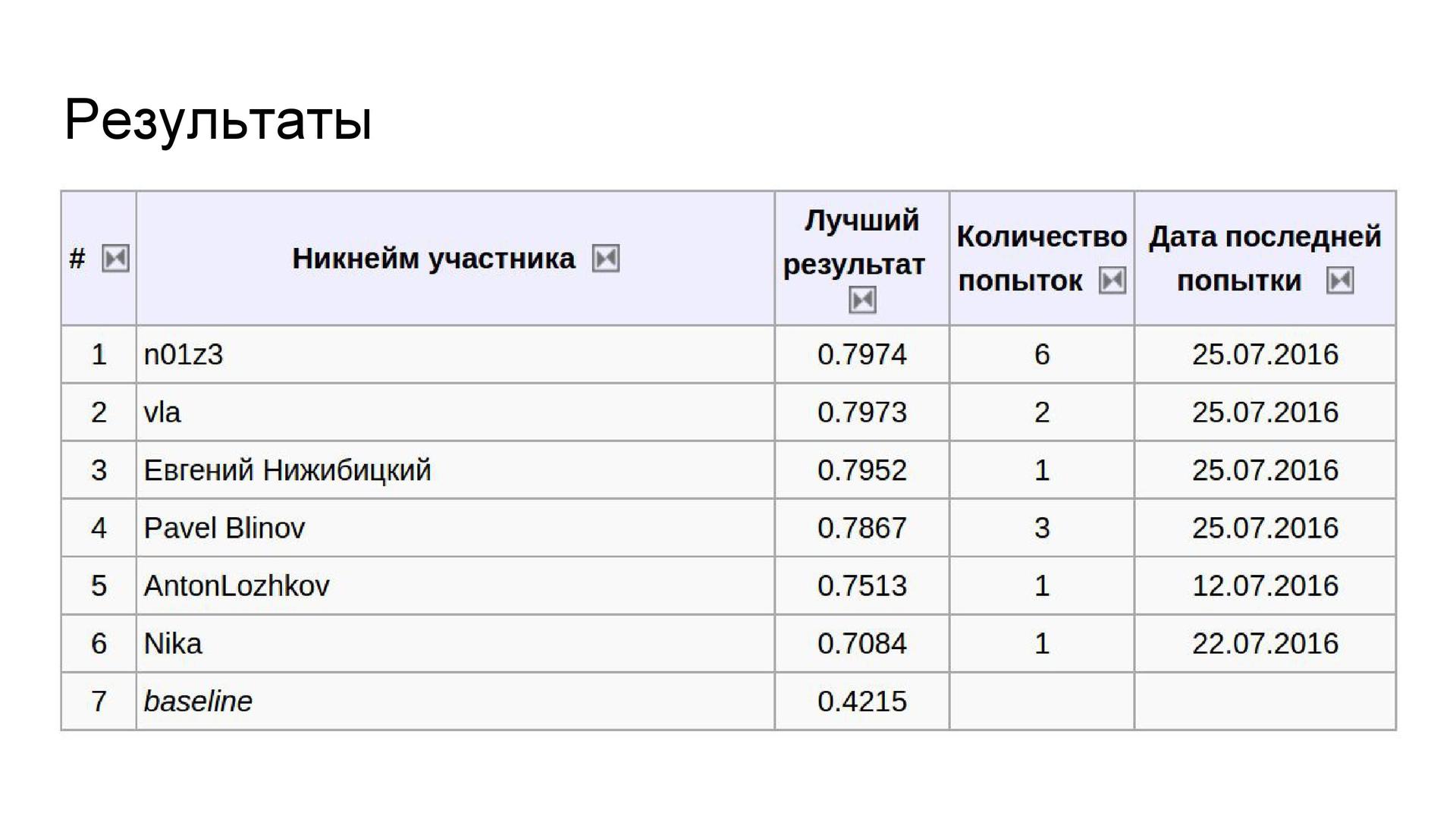
Результаты. При подборе весов на этапе валидации использовалась метрика соревнования, поскольку она не слишком коррелировала с обычной точностью. Предсказание на разных участках изображений даёт лишь малую часть качества по сравнению с единым предсказанием, но именно за счёт этого прироста удаётся показать лучший результат. По окончании конкурса выяснилось, что первые три места отличаются в результатах на тысячные доли. Например, у Женя Нижибицкого была единственная модель, которая совсем немного уступила моему ансамблю моделей.
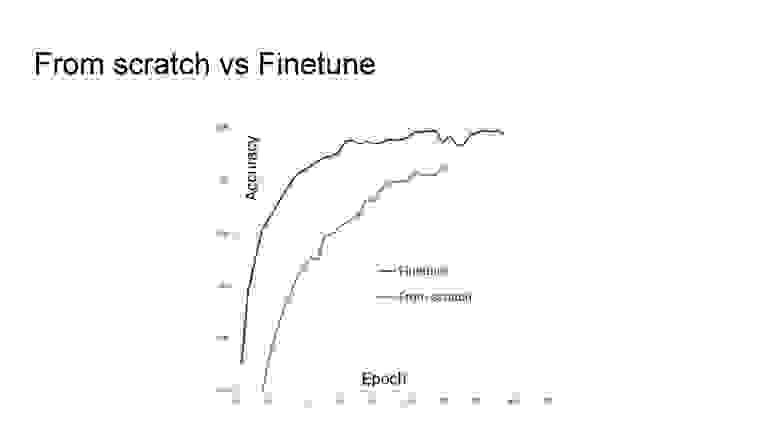
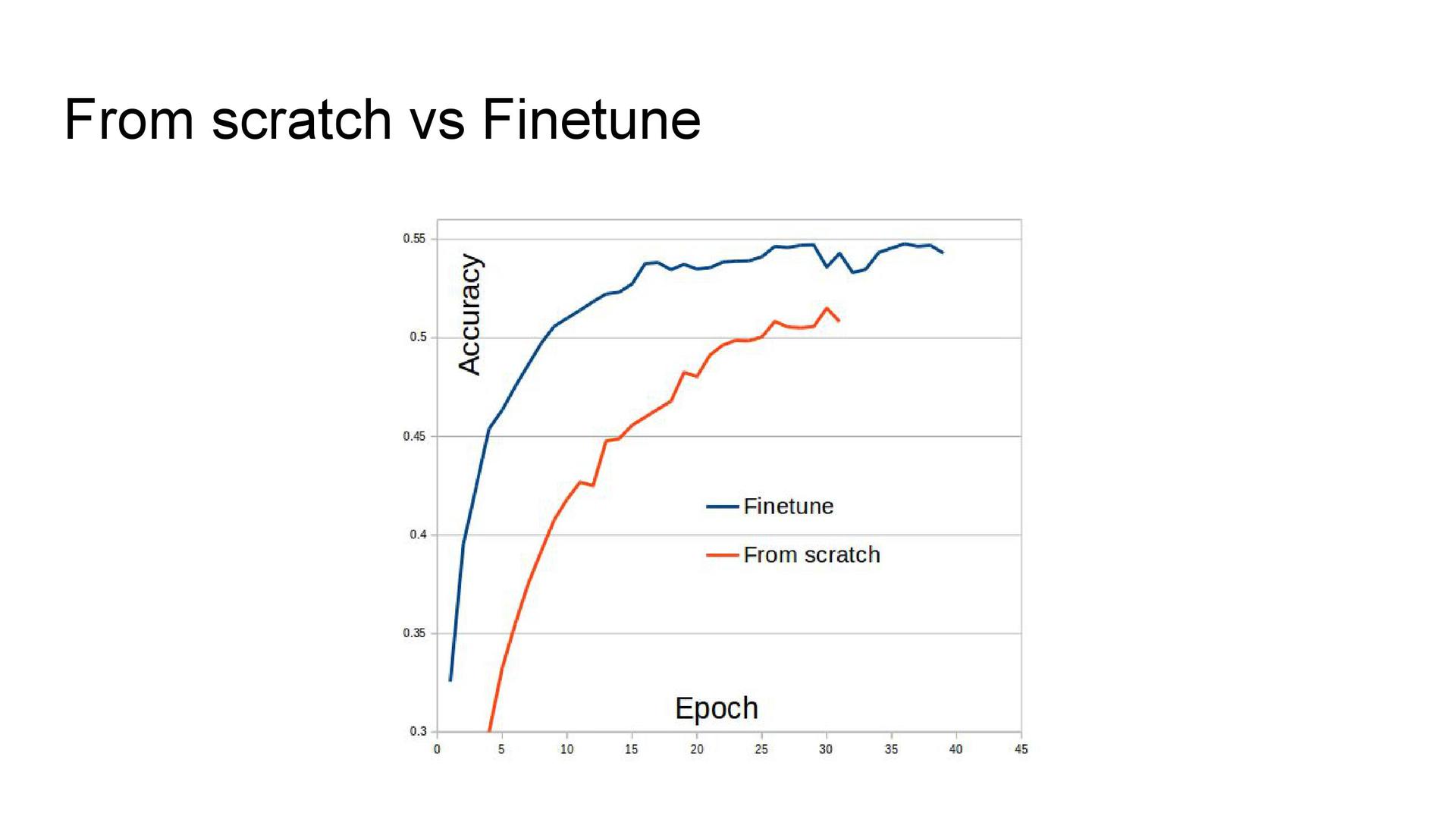
Обучение с нуля vs. fine-tuning. Уже после завершения конкурса выяснилось, что несмотря на большой размер выборки стоило обучать сеть не с нуля, а при помощи предобученной сети. Этот подход демонстрирует более высокие результаты.
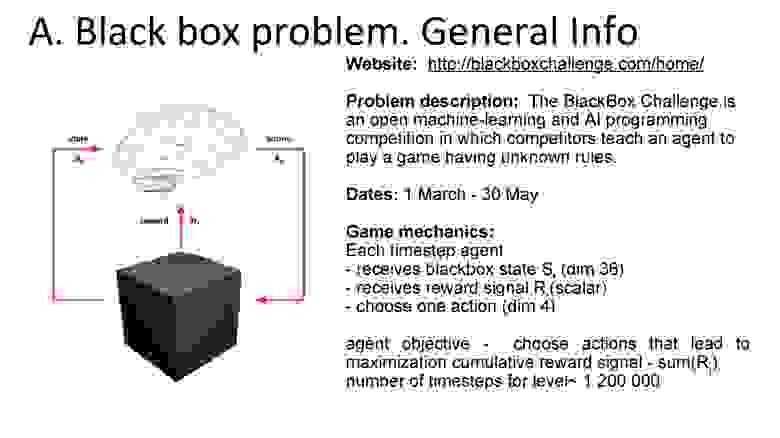
Соревнование Black Box Challenge, о котором писали на Хабрахабре, было не совсем похоже на обычный «кэгл». Дело в том, что для решения было недостаточно разметить некоторую «тестовую» выборку. Требовалось запрограммировать и загрузить в систему код «агента», который помещался в неизвестную участнику среду и самостоятельно принимал в ней решения. Такие задачи относятся к области обучения с подкреплением — reinforcement learning.
О подходах к решению рассказал Михаил Павлов из компании 5vision. В конкурсе он занял второе место.
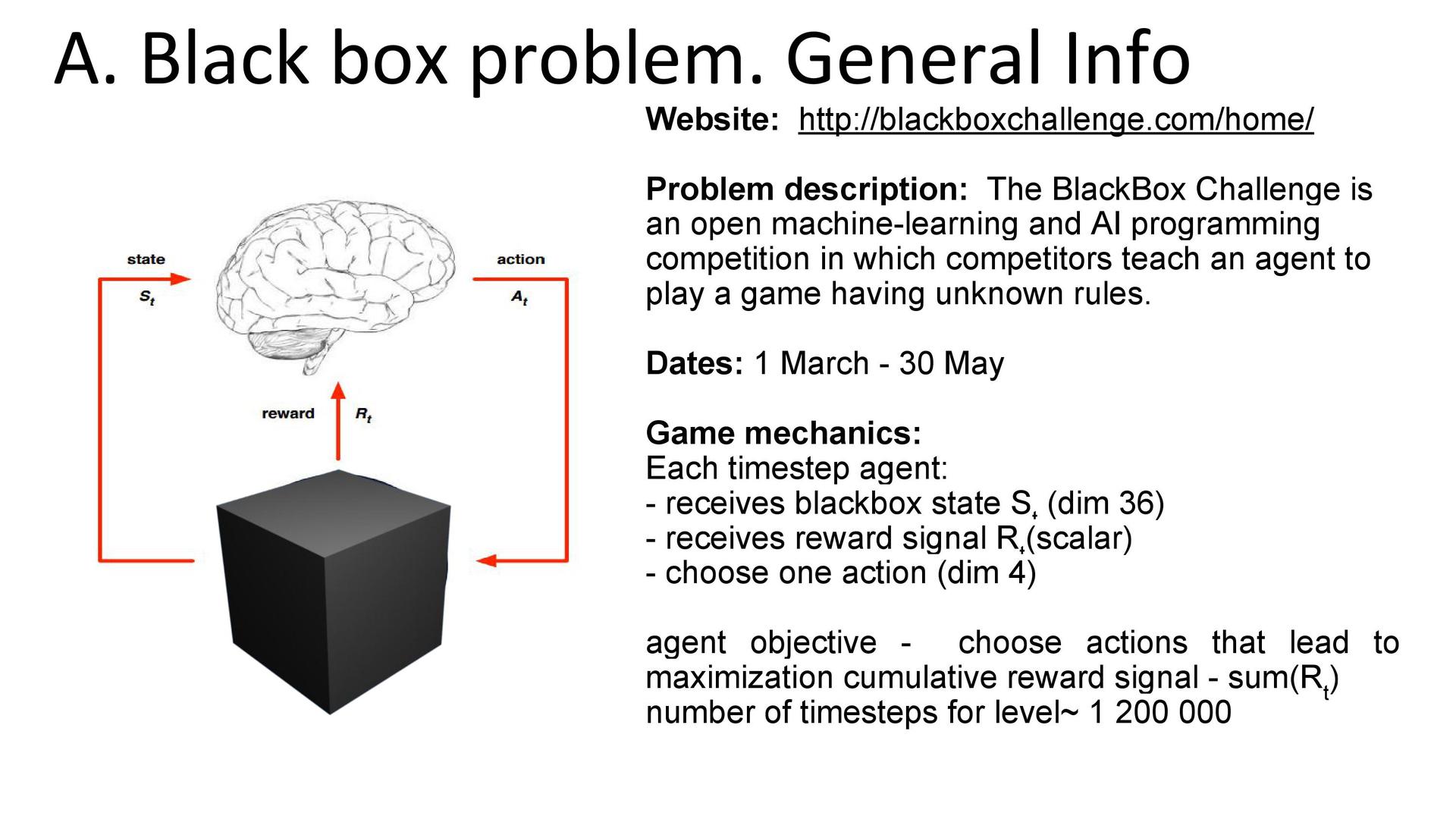
Постановка задачи. Для среды с неизвестными правилами нужно было написать «агента», который взаимодействовал бы с указанной средой. Схематично это некий мозг, который получает от чёрного ящика информацию о состоянии и награде, принимает решение о действии, после чего получает новое состояние и награду за совершённое действие. Действия повторяются друг за другом в течение игры. Текущее состояние описывается вектором из 36 чисел. Агент может совершить четыре действия. Цель — максимизировать сумму наград за всю игру.

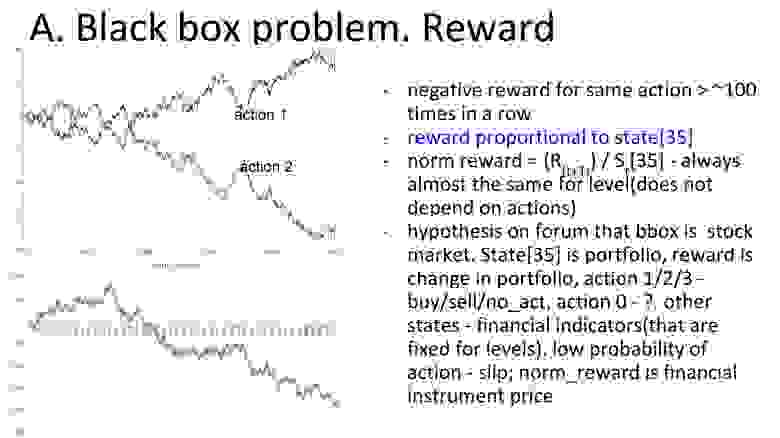
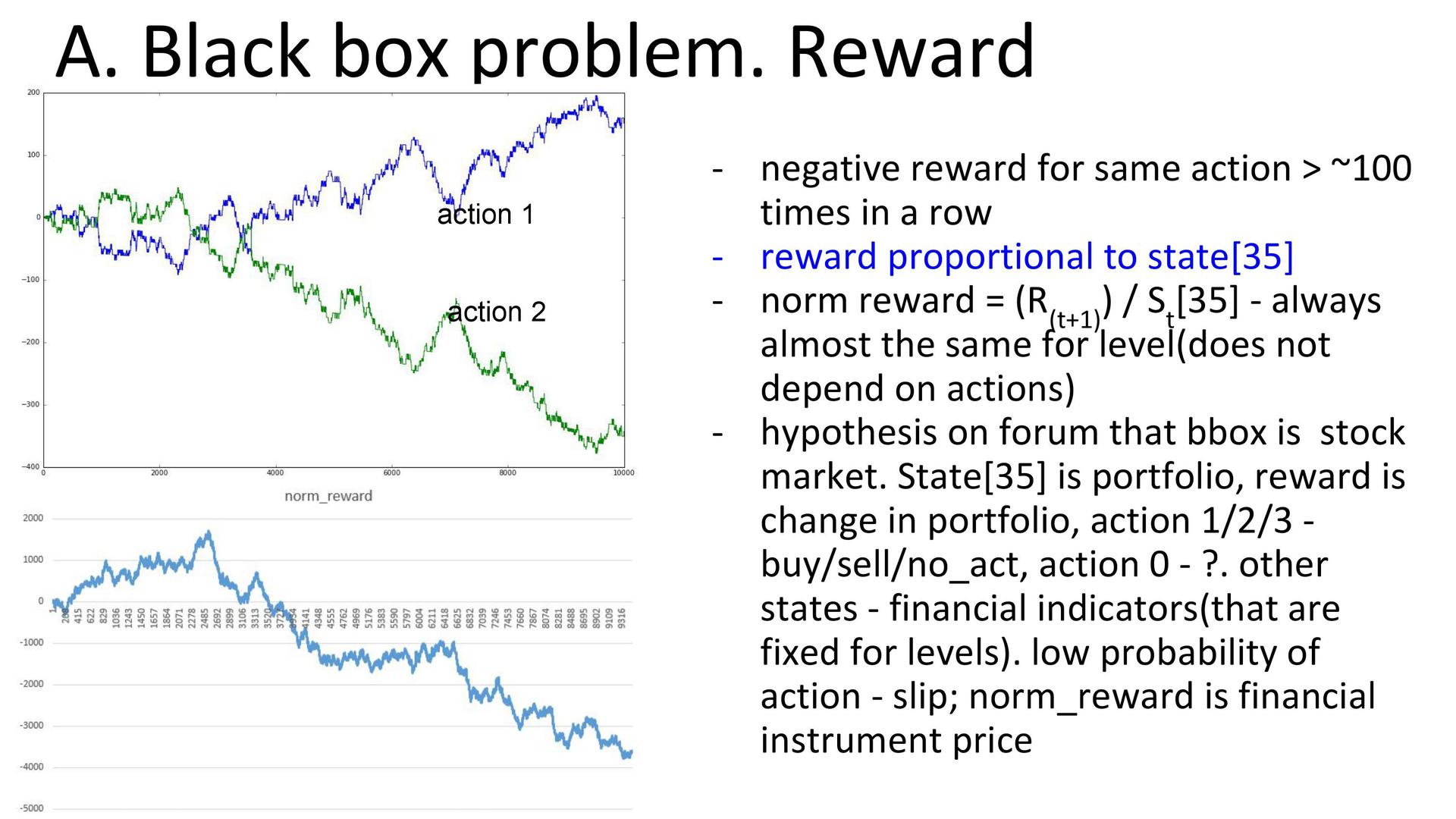
Анализ среды. Изучение распределения переменных состояния среды показало, что первые 35 компонент не зависят от выбранного действия и только 36-я компонента меняется в зависимости от него. При этом разные действия влияли по-разному: некоторые увеличивали или уменьшали, некоторые никак не меняли. Но нельзя сказать, что вся среда зависит от одной компоненты: в ней могут быть и некие скрытые переменные. Кроме того, эксперимент показал, что если совершать более 100 одинаковых действий подряд, то награда становится отрицательной. Так что стратегии вида «совершать только одно действие» отпадали сразу. Кто-то из участников соревнования заметил, что награда пропорциональна всё той же 36-й компоненте. На форуме прозвучало предположение, что чёрный ящик имитирует финансовый рынок, где портфелем является 36-я компонента, а действиями — покупка, продажа и решение ничего не делать. Эти варианты соотносились с изменением портфеля, а смысл одного действия понятен не был.

Q-learning. Во время участия основной целью было попробовать различные техники обучения с подкреплением. Одним из самых простых и известных методов является q-learning. Его суть в попытке построить функцию Q, которая зависит от состояния и выбранного действия. Q оценивает, насколько «хорошо» выбирать конкретное действие в конкретном состоянии. Понятие «хорошо» включает в себя награду, которую мы получим не только сейчас, но и будущем. Обучение такой функции происходит итеративно. Во время каждой итерации мы пытаемся приблизить функцию к самой себе на следующем шаге игры с учётом награды, полученной сейчас. Подробнее можно почитать в ещё одной статье на Хабрхабре. Применение q-learning предполагает работу с полностью наблюдаемыми марковскими процессами (другими словами, в текущем состоянии должна содержаться вся информация от среды). Несмотря на то, что среда, по заявлению организаторов, не удовлетворяла этому требованию, применять q-learning можно было достаточно успешно.

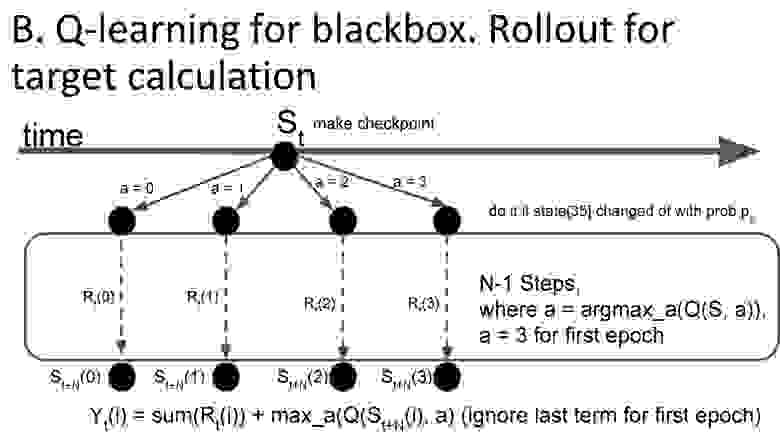
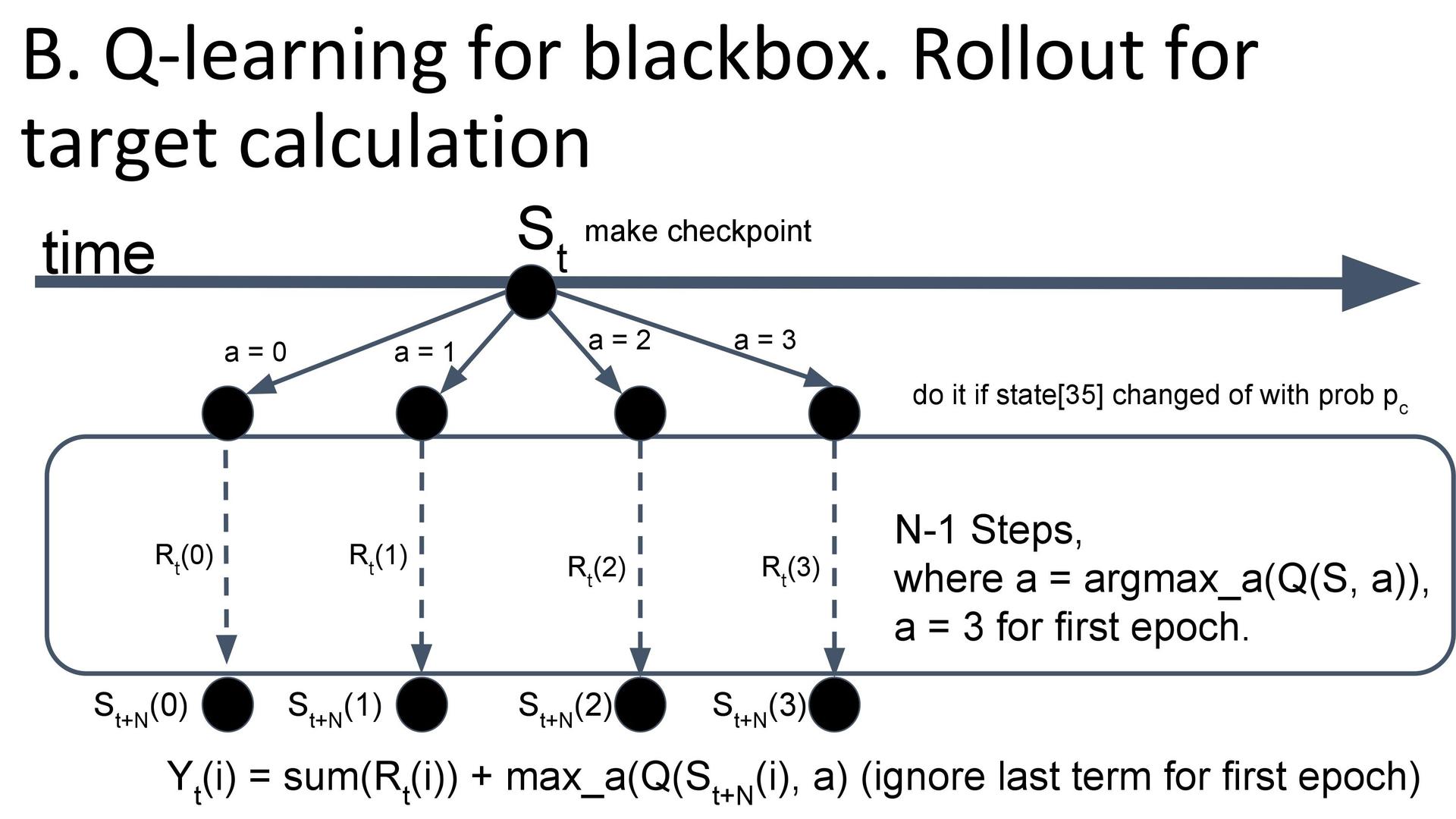
Адаптация к black box. Опытным путём было установлено, что для среды лучше всего подходил n-step q-learning, где использовалась награда не за одно последнее действие, а за n действий вперёд. Среда позволяла сохранять текущее состояние и откатываться к нему, что облегчало сбор выборки — можно было из одного состояния попробовать совершить каждое действие, а не какое-то одно. В самом начале обучения, когда q-функция ещё не умела оценивать действия, использовалась стратегия «совершать действие 3». Предполагалось, что оно ничего не меняло и можно было начать обучаться на данных без шума.
Процесс обучения. Обучение происходило так: с текущей политикой (стратегией агента) играем весь эпизод, накапливая выборку, потом с помощью полученной выборки обновляем q-функцию и так далее — последовательность повторяется в течение некоторого количества эпох. Результаты получались лучше, чем при обновлении q-функции в процессе игры. Другие способы — техника replay memory (с общим банком данных для обучения, куда заносятся новые эпизоды игры) и одновременное обучение нескольких агентов, играющих асинхронно, — тоже оказалось менее эффективными.

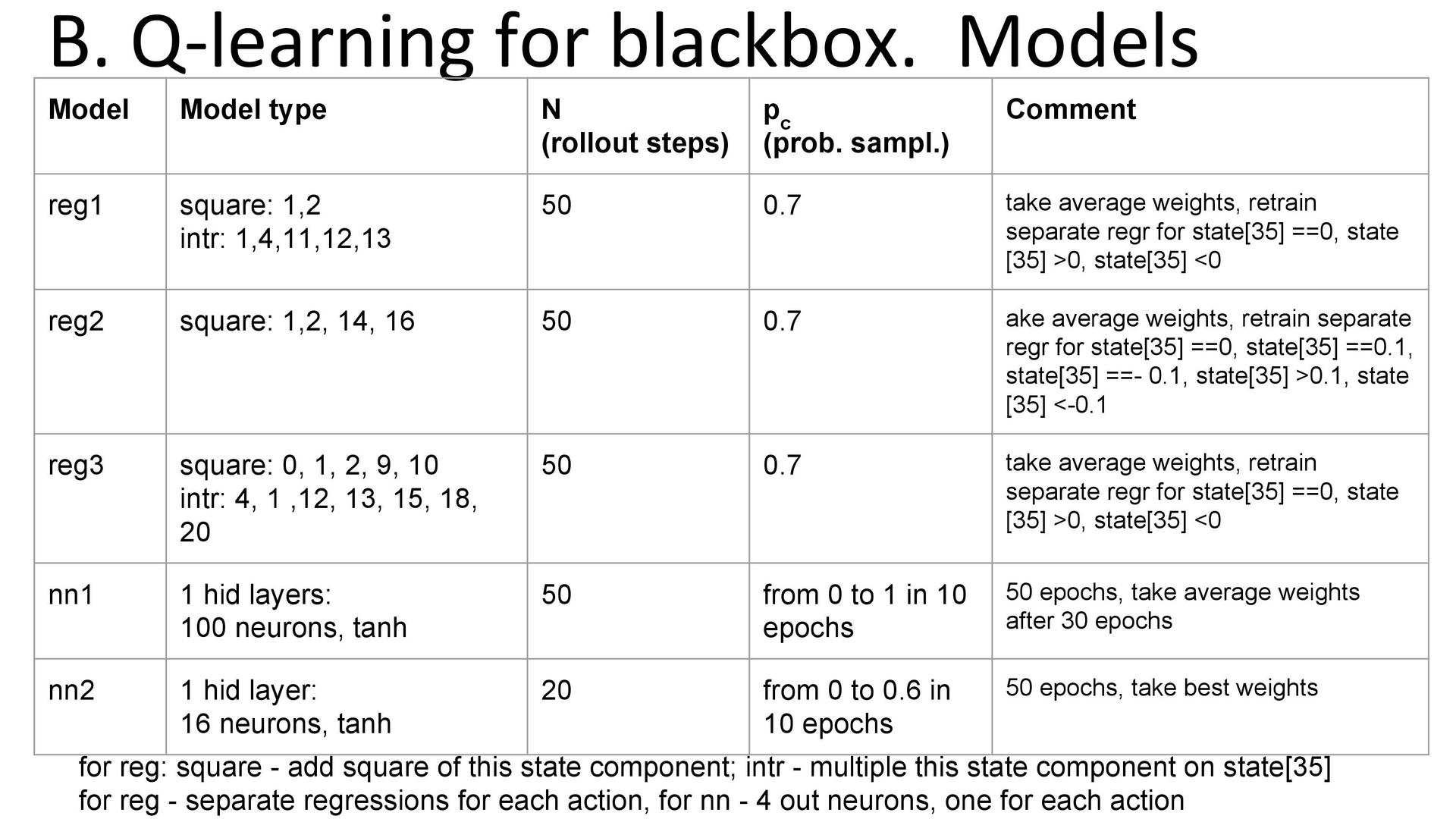
Модели. В решении использовались три регрессии (каждая по одному разу в расчёте на каждое действие) и две нейронных сети. Были добавлены некоторые квадратичные признаки и взаимодействия. Итоговая модель представляет собой смесь всех пяти моделей (пяти Q-функций) с равными весами. Кроме того, использовалось онлайн-дообучение: в процессе тестирования веса́ старых регрессий подмешивались к новым весам, полученным на тестовой выборке. Это делалось только для регрессий, поскольку их решения можно выписывать аналитически и пересчитывать достаточно быстро.


Другие идеи. Естественно, не все идеи улучшали итоговый результат. Например, дисконтирование награды (когда мы не просто максимизируем суммарную награду, а считаем каждый следующий ход менее полезным), глубокие сети, dueling-архитектура (с оценкой полезности состояния и каждого действия в отдельности) не дали роста результатов. Из-за технических проблем не получилось применить рекуррентные сети — хотя в ансамбле с другими моделями они, возможно, обеспечили бы некоторую пользу.


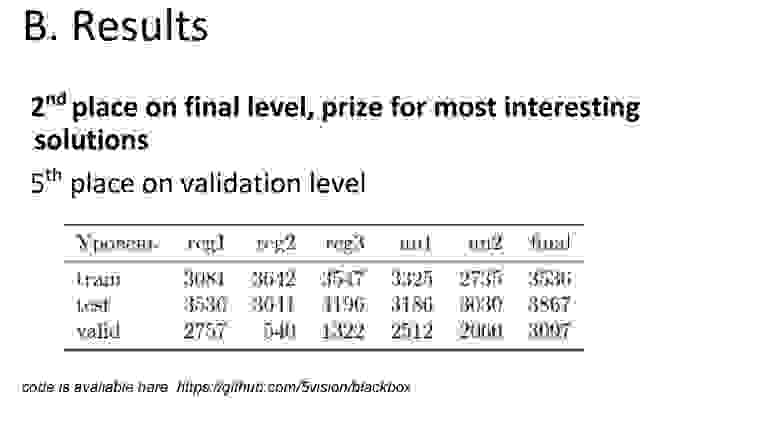
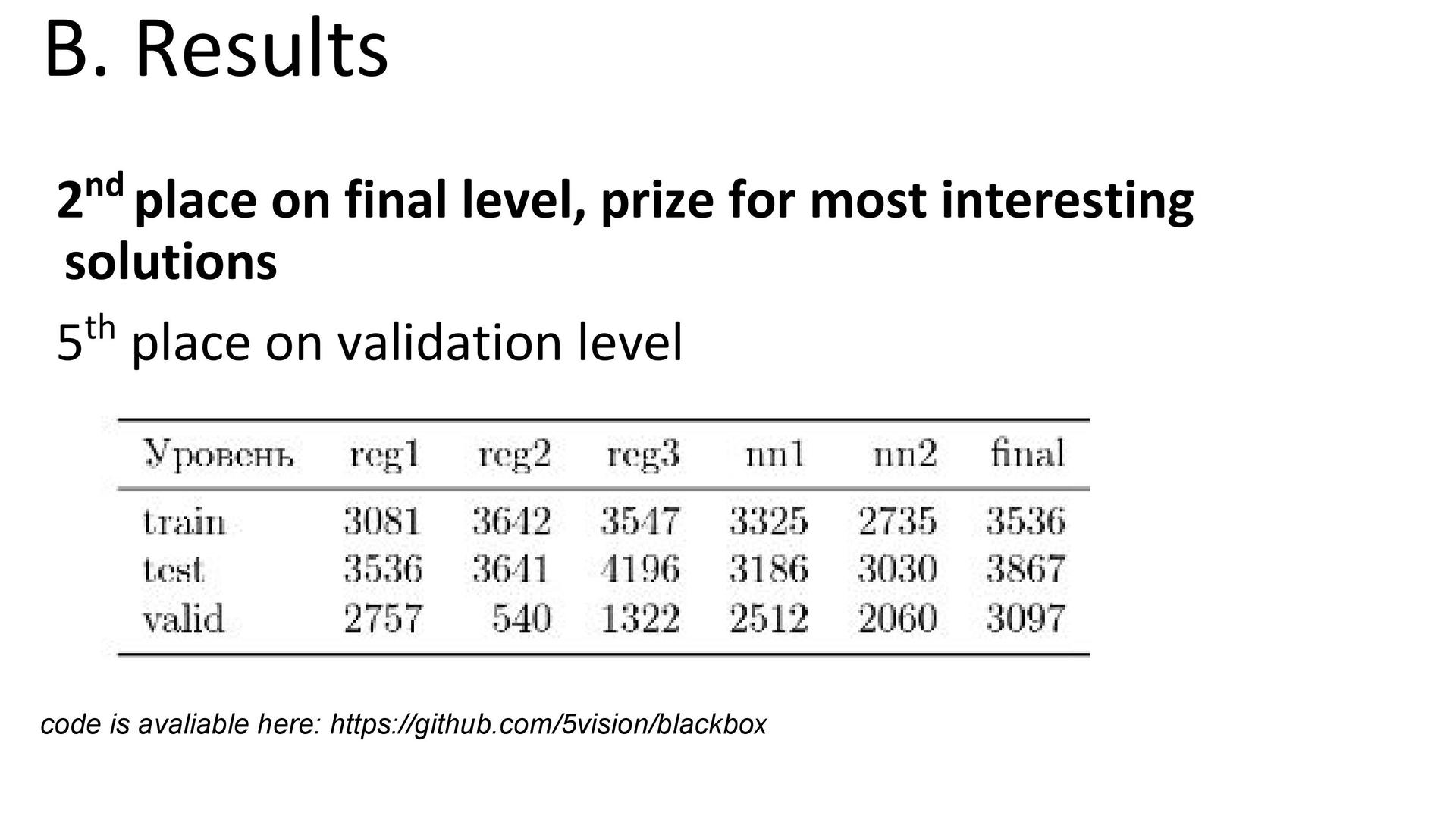
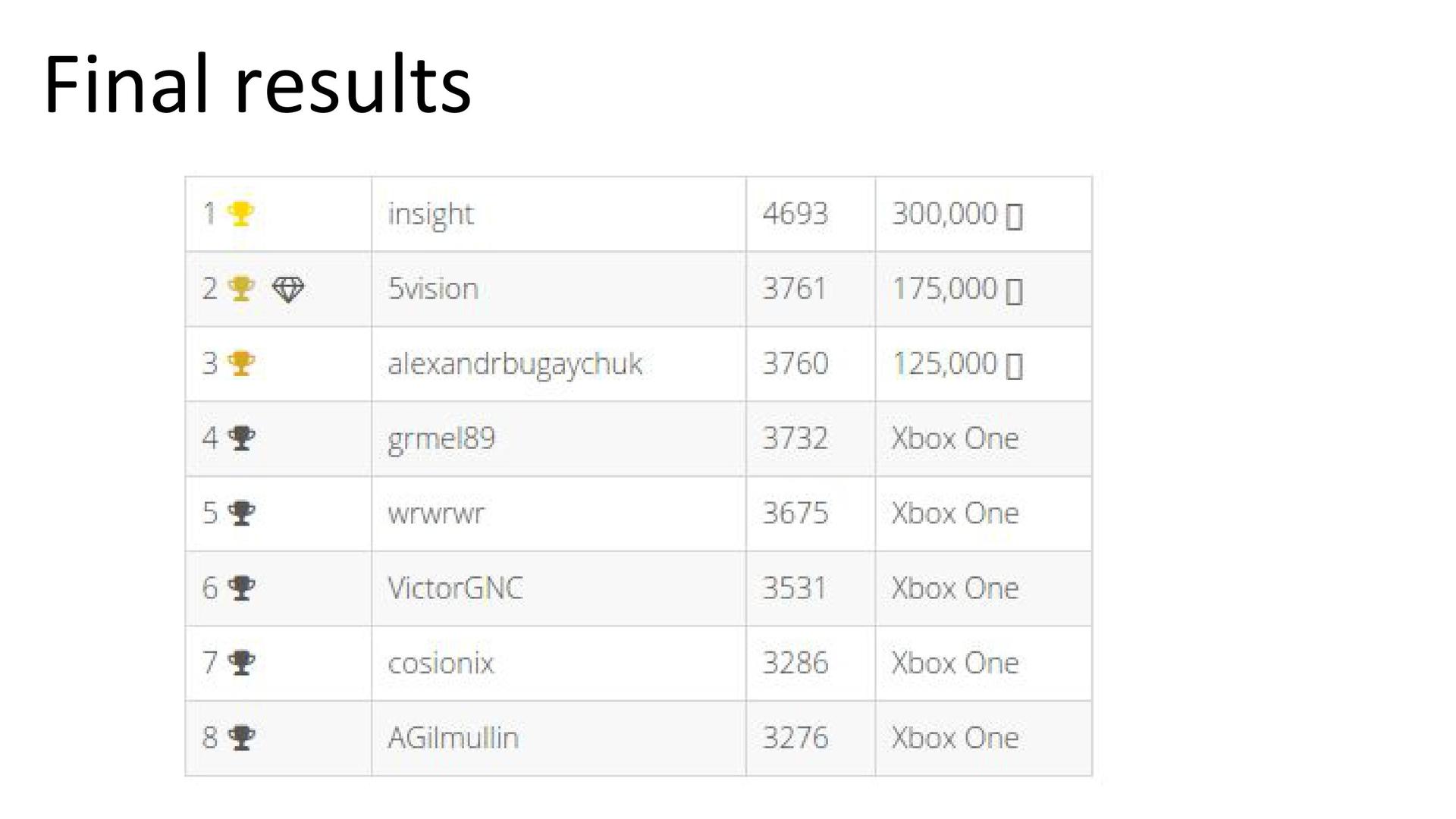
Итоги. Команда 5vision заняла второе место, но с совсем небольшим отрывом от обладателей «бронзы».

Итак, зачем нужно участвовать в соревнованиях по анализу данных?

Сейчас тренировки по машинному обучению проводятся по субботам каждую вторую неделю. Место проведения — московский офис Яндекса, стандартное число гостей (гости плюс яндексоиды) — 60-80 человек. Главным свойством тренировок служит их злободневность: всякий раз разбирается конкурс, завершившийся одну-две недели назад. Это мешает всё точно спланировать, но зато конкурс ещё свеж в памяти и в зале собирается много людей, попробовавших в нём свои силы. Курирует тренировки Эмиль Каюмов, который, кстати, помог с написанием этого поста.
Кроме того, есть другой формат: зарешивания, где начинающие специалисты совместными усилиями участвуют в действующих конкурсах. Зарешивания проводятся по тем субботам, когда нет тренировок. На мероприятия обоих типов может прийти любой, анонсы публикуются в группах на Фейсбуке и ВКонтакте, есть YouTube-канал с прямыми трансляциями. Кстати, зарешивания также проходят в Санкт-Петербурге, Новосибирске, Екатеринбурге и Калининграде. Если вашего города нет в списке, а небольшое сообщество уже сформировалось — попробуйте организовать несколько встреч самостоятельно.

Вот и всё. Посещаете тренировки, слушаете, пробуете участвовать, занимаете какие-нибудь далёкие места, начинаете ходить на зарешивания, снова пробуете — замечая или не замечая, что из вас вырастает data scientist. Если сейчас вы разработчик или devops, то пройти подобный путь реально и, что самое главное, не так уж и сложно. Например — проще, чем пробовать стать аналитиком данных каким-нибудь другим способом.
Полезные ссылки, или как начать решать:
Многие из вас наверняка знают или хотя бы слышали про Kaggle. Для тех, кто не слышал: Kaggle — это площадка, на которой компании проводят конкурсы по созданию прогнозирующих моделей. Её популярность столь велика, что часто под «кэглами» специалисты понимают сами конкурсы. Победитель каждого соревнования определяется автоматически — по метрике, которую назначил организатор. Среди прочих, Kaggle в разное время опробовали Facebook, Microsoft и нынешний владелец площадки — Google. Яндекс тоже несколько раз отметился. Как правило, Kaggle-сообществу дают решать задачи, довольно близкие к реальным: это, с одной стороны, делает конкурс интересным, а с другой — продвигает компанию как работодателя с солидными задачами. Впрочем, если вам скажут, что компания-организатор конкурса задействовала в своём сервисе алгоритм одного из победителей, — не верьте. Обычно решения из топа слишком сложны и недостаточно производительны, а погони за тысячными долями значения метрики не настолько и нужны на практике. Поэтому организаторов больше интересуют подходы и идейная часть алгоритмов.

Kaggle — не единственная площадка с соревнованиями по анализу данных. Существуют и другие: DrivenData, DataScience.net, CodaLab. Кроме того, конкурсы проводятся в рамках научных конференций, связанных с машинным обучением: SIGKDD, RecSys, CIKM.
Для успешного решения нужно, с одной стороны, изучить теорию, а с другой — начать практиковать использование различных подходов и моделей. Другими словами, участие в «кэглах» вполне способно сделать из вас аналитика данных. Вопрос — как научиться в них участвовать?
Три года назад несколько студентов ШАД начали собираться и решать разные интересные задания, в том числе взятые с Kaggle. Например, среди этих ребят был нынешний обладатель второго места и недавний лидер рейтинга Kaggle Станислав Семёнов. Со временем встречи получили название тренировок по машинному обучению. Они набирали популярность, участники стали регулярно занимать призовые места и рассказывать друг другу о своих решениях, делиться опытом.
Чтобы было понятно, чем именно мы занимаемся на тренировках, я приведу несколько примеров. В каждом примере сначала идёт видео с рассказом, а затем — текст, составленный по мотивам видео.
Задача классификации изображений автомобилей
Ссылка на MachineLearning.ru.
В прошлом году компания «Авито» провела целый ряд конкурсов. В том числе — конкурс по распознаванию марок автомобилей, победитель которого, Евгений Нижибицкий, рассказал на тренировке о своём решении.
Постановка задачи. По изображениям автомобилей необходимо определить марку и модель. Метрикой служила точность предсказаний, то есть доля правильных ответов. Выборка состояла из трёх частей: первая часть была доступна для обучения изначально, вторая была дана позже, а на третьей требовалось показать финальные предсказания.


Вычислительные ресурсы. Я воспользовался домашним компьютером, который обогревал мою комнату всё это время, и предоставленными на работе серверами.

Обзор моделей. Раз наша задача — на распознавание, то первым делом хочется воспользоваться прогрессом в уровне качества классификации изображений на всем известном ImageNet. Как известно, современные архитектуры позволяют достигнуть даже более высокого качества, чем у человека. Поэтому я начал с обзора свежих статей и собрал сводную таблицу архитектур, реализаций и качеств на основе ImageNet.
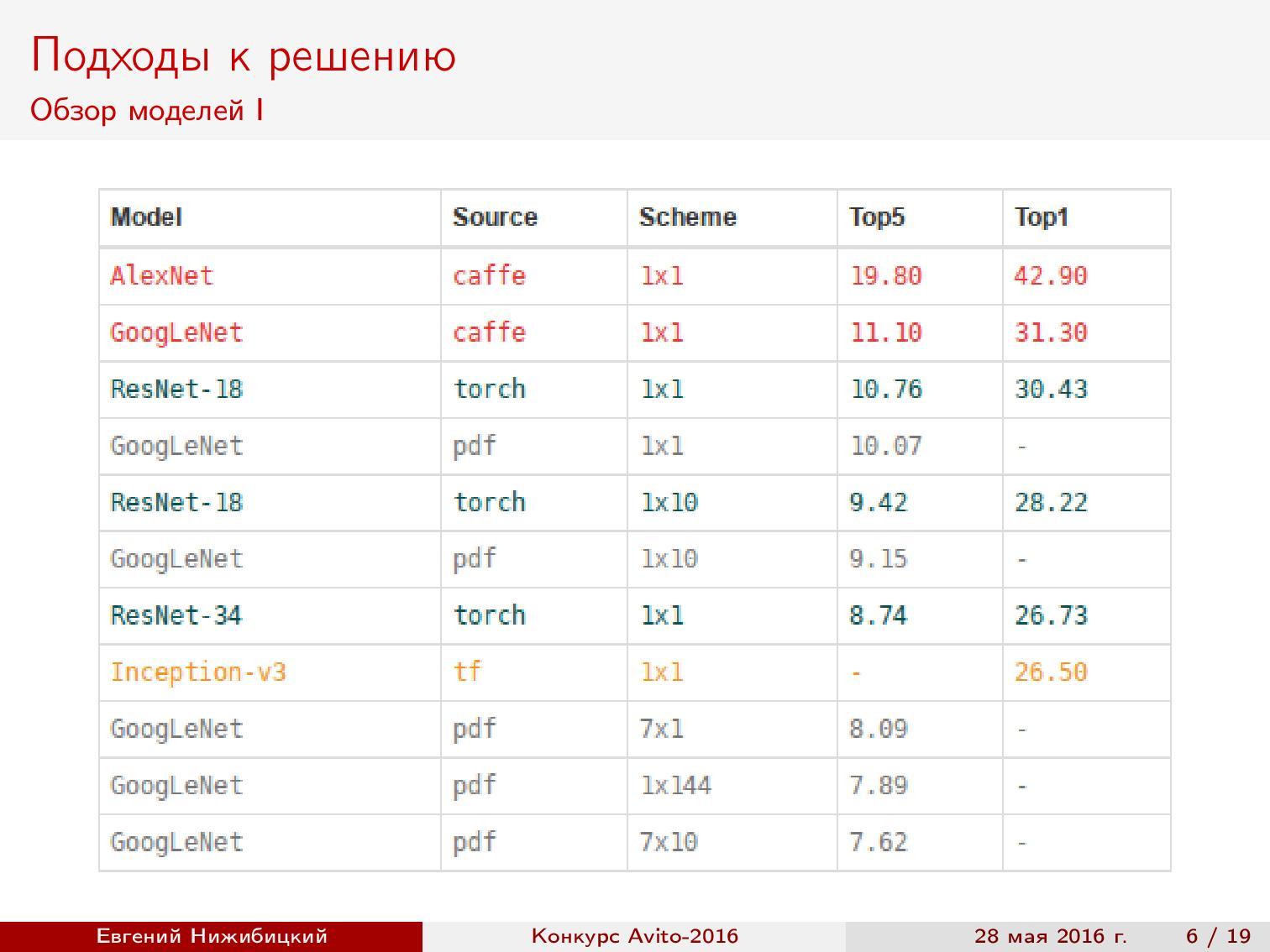
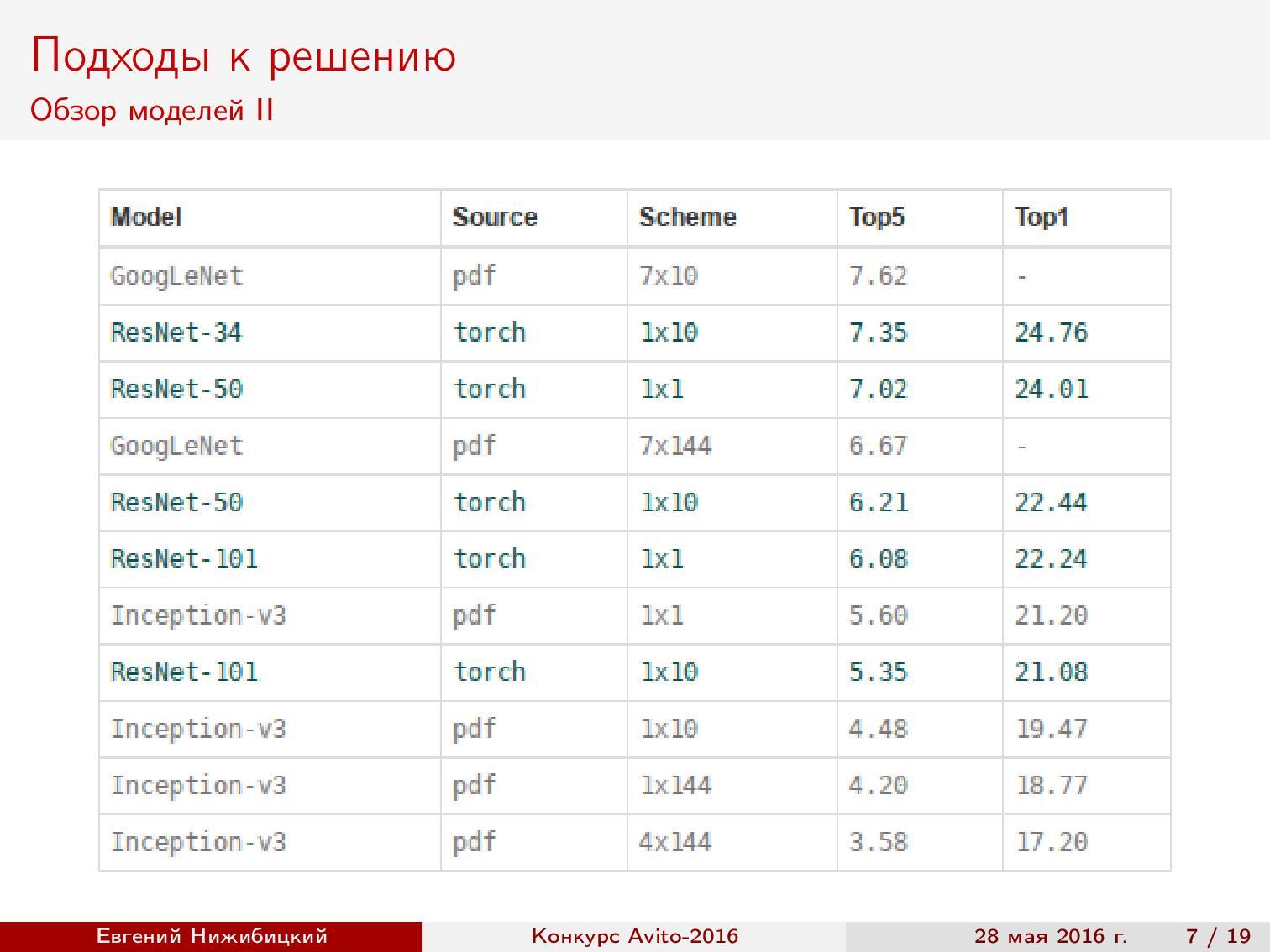
Заметим, что наилучшее качество достигается на архитектурах Inception и ResNet.
Fine-tuning сетей. Обучать глубокую нейронную сеть с нуля — довольно затратное по времени занятие, к тому же не всегда эффективное с точки зрения результата. Поэтому часто используется техника дообучения сетей: берётся уже обученная на ImageNet сеть, последний слой заменяется на слой с нужным количеством классов, а потом продолжается настройка сети с низким темпом обучения, но уже на данных из конкурса. Такая схема позволяет обучить сеть быстрее и с более высоким качеством.
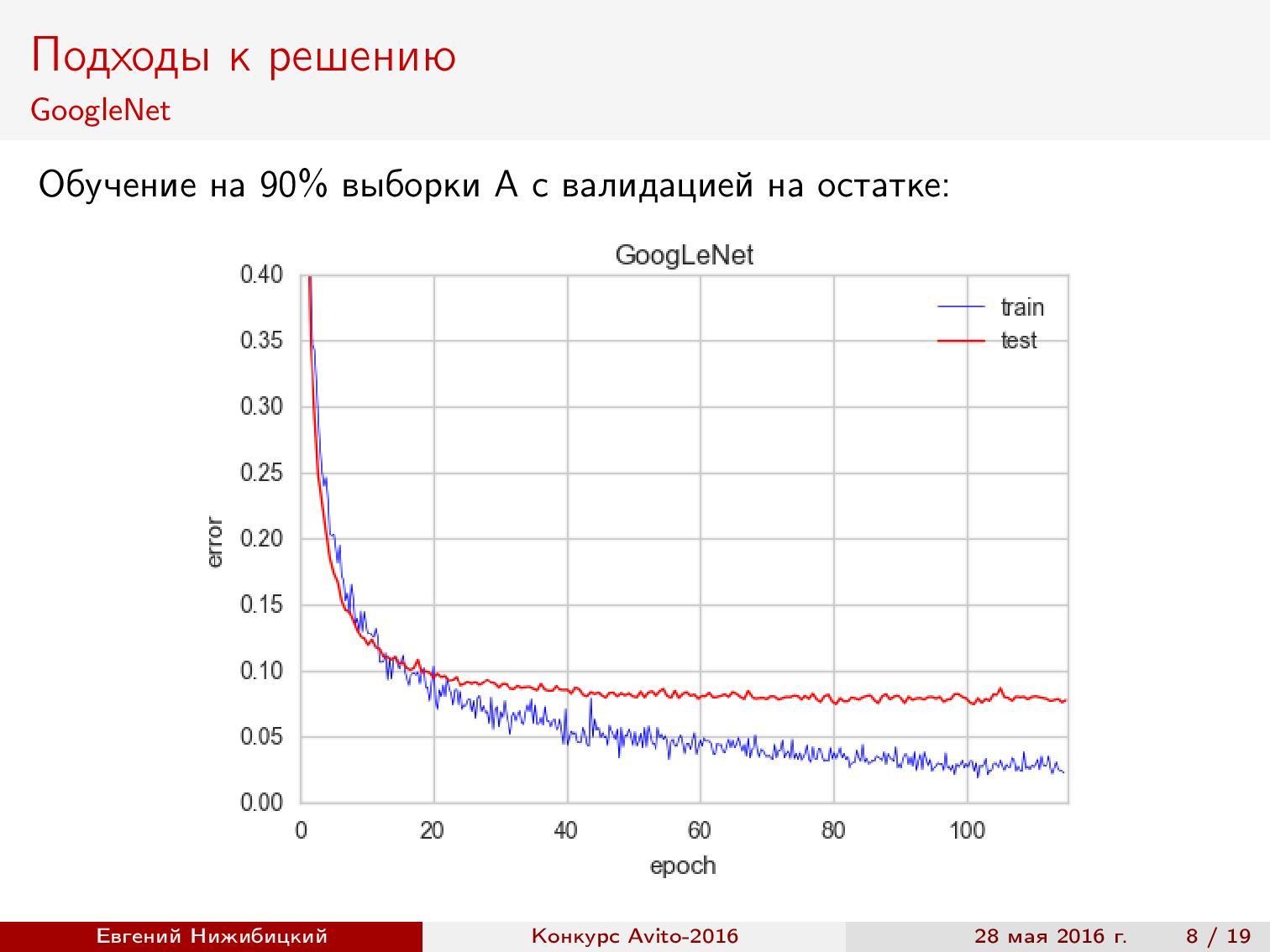
Первый подход к дообучению GoogLeNet показал примерно 92% точности при валидации.
Предсказания на кропах. Используя нейронную сеть для предсказания на тестовой выборке, можно улучшить качество. Для этого следует выреза́ть фрагменты подходящего размера в разных местах исходной картинки, после чего усреднять результаты. Кроп 1x10 означает, что взят центр изображения, четыре угла, а потом всё то же самое, но отражённое по горизонтали. Как видно, качество возрастает, однако время предсказания увеличивается.
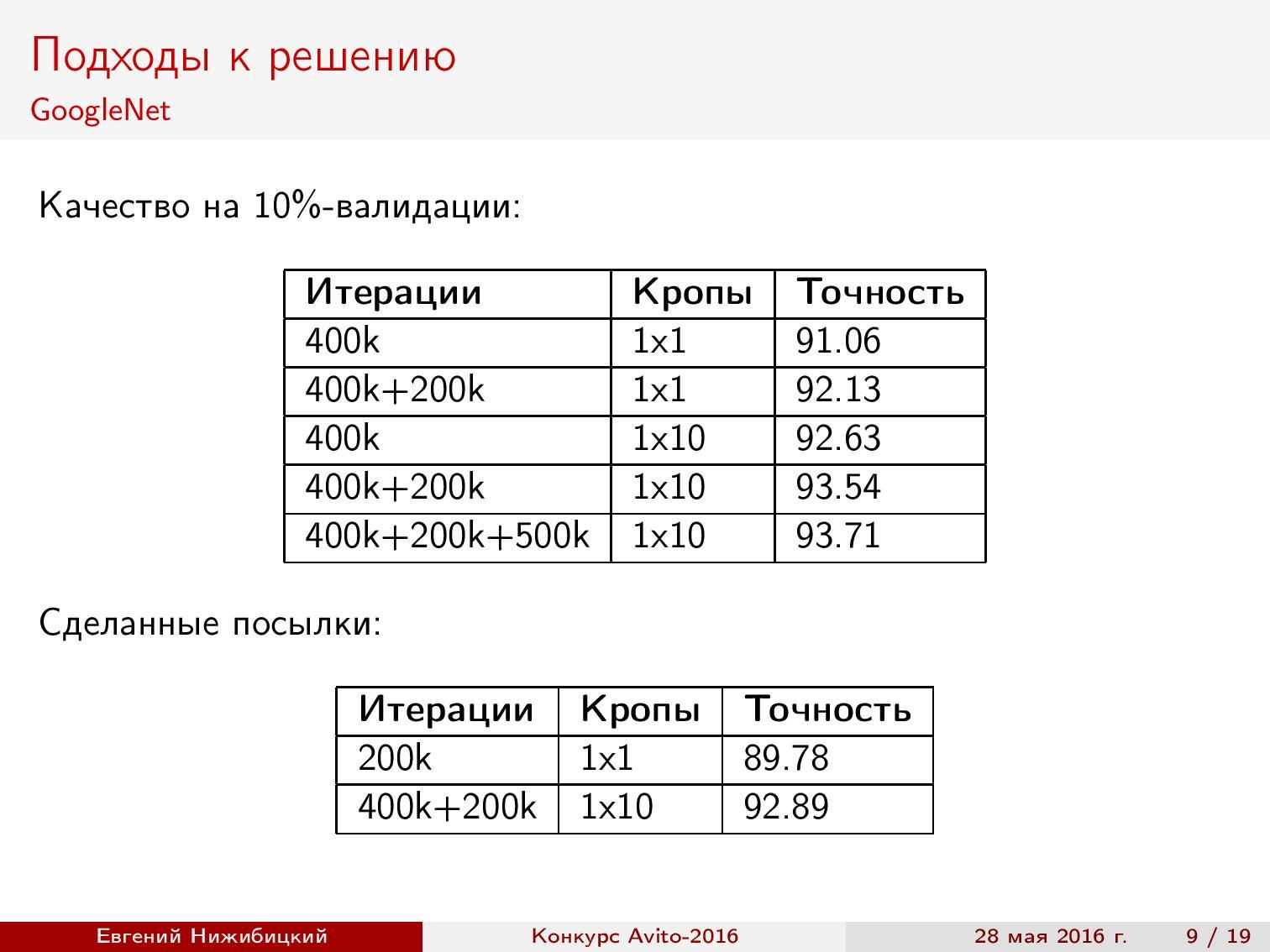
Валидация результатов. После появления выдачи второй части выборки я разбил выборку на несколько частей. Все дальнейшие результаты показаны на этом разбиении.

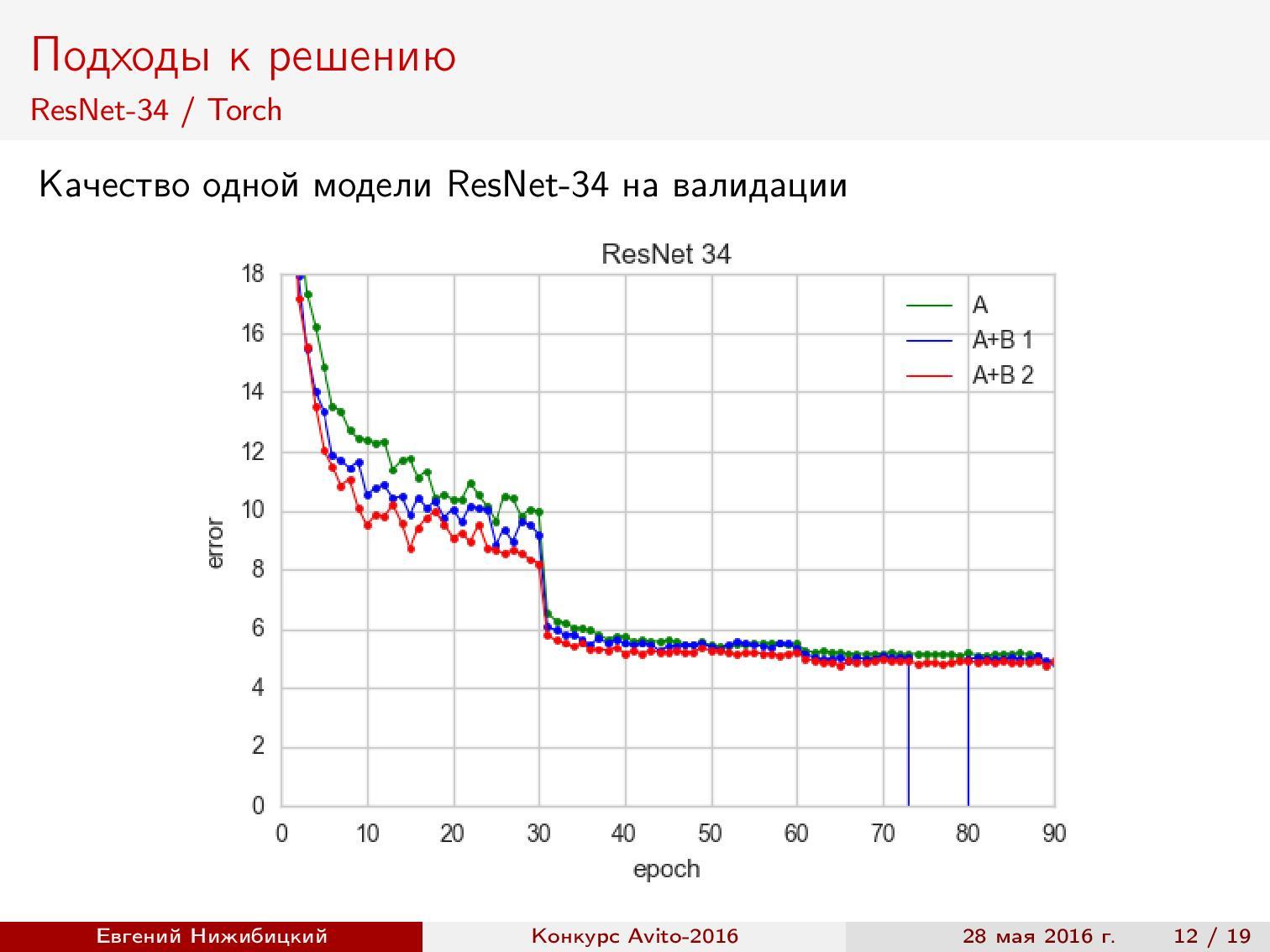
ResNet-34 Torch. Можно воспользоваться готовым репозиторием авторов архитектуры, но, чтобы получить предсказания на тесте в нужном формате, приходится исправлять некоторые скрипты. Кроме того, нужно решать проблемы большого потребления памяти дампами. Точность при валидации — около 95%.

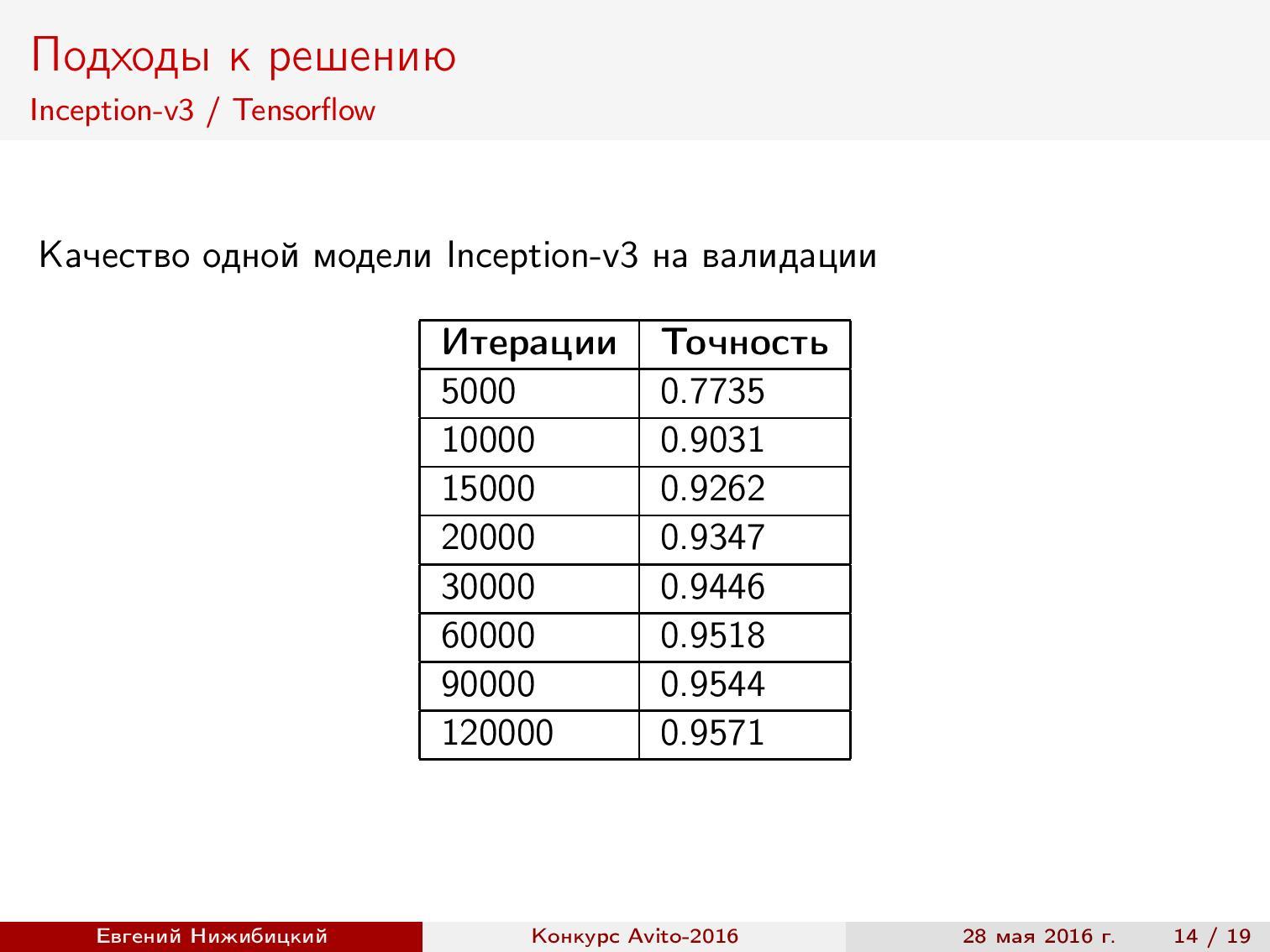
Inception-v3 TensorFlow. Тут тоже использовалась готовая реализация, но была изменена предобработка изображений, а также ограничена обрезка картинок при генерации батча. Итог — почти 96% точности.

Ансамбль моделей. В итоге получилось две модели ResNet и две модели Inception-v3. Какое качество при валидации можно получить, смешивая модели? Вероятности классов усреднялись с помощью геометрического среднего. Веса (в данном случае — степени) подбирались на отложенной выборке.


Результаты. Обучение ResNet на GTX 980 занимало 60 часов, а Inception-v3 на TitanX — 48 часов. За время конкурса удалось опробовать новые фреймворки с новыми архитектурами.

Задача классификации клиентов банка
Ссылка на Kaggle.
Станислав Семёнов рассказывает, как он и другие участники топа Kaggle объединились и заняли призовое место в соревновании по классификации заявок клиентов крупного банка — BNP Paribas.
Постановка задачи. По обфусцированным данных из заявок на страхование необходимо предсказать, можно ли без дополнительных ручных проверок подтвердить запрос. Для банка это процесс автоматизации обработки заявок, а для аналитиков данных — просто задача машинного обучения по бинарной классификации. Имеется около 230 тысяч объектов и 130 признаков. Метрика — LogLoss. Стоит отметить, что команда-победитель расшифровала данные, что помогло им выиграть соревнование.
Избавление от искусственного шума в признаках. Первым делом стоит посмотреть на данные. Cразу бросаются в глаза несколько вещей. Во-первых, все признаки принимают значения от 0 до 20. Во-вторых, если посмотреть на распределение любого из признаков, то можно увидеть следующую картинку:

Почему так? Дело в том, что на этапе анонимизации и зашумления данных ко всем значениям прибавлялся случайный шум, а потом проводилось масштабирование на отрезок от 0 до 20. Обратное преобразование было проведено в два шага: сначала значения округлялись до некоторого знака после запятой, а потом подбирался деноминатор. Требовалось ли это, если дерево всё равно подбирает порог при разбиении? Да, после обратного преобразования разности переменных начинают нести больший смысл, а для категориальных переменных появляется возможность провести one-hot кодирование.
Удаление линейно зависимых признаков. Ещё мы заметили, что некоторые признаки являются суммой других. Понятно, что они не нужны. Для их определения брались подмножества признаков. На таких подмножествах строилась регрессия для предсказания некоторой другой переменной. И если предсказанные значения были близки к истинным (стоит учесть искусственное зашумление), то признак можно было удалить. Но команда не стала с этим возиться и воспользовалась уже готовым набором фильтрованных признаков. Набор подготовил кто-то другой. Одна из особенностей Kaggle — наличие форума и публичных решений, с помощью которых участники делятся своими находками.
Как понять, что нужно использовать? Есть небольшой хак. Предположим, вы знаете, что кто-то в старых соревнованиях использовал некоторую технику, которая помогла ему занять высокое место (на форумах обычно пишут краткие решения). Если в текущем конкурсе этот участник снова в числе лидеров — скорее всего, такая же техника выстрелит и здесь.
Кодирование категориальных переменных. Бросилось в глаза то, что некая переменная V22 имеет большое число значений, но при этом, если взять подвыборку по некоторому значению, число уровней (различных значений) других переменных заметно уменьшается. В том числе имеет место хорошая корреляция с целевой переменной. Что можно сделать? Самое простое решение — построить для каждого значения V22 отдельную модель, но это всё равно что в первом сплите дерева сделать разбиение по всем значениям переменной.
Есть другой способ использования полученной информации — кодирование средним значением целевой переменной. Другими словами, каждое значение категориальной переменной заменяется средним значением таргета по объектам, у которых данный признак принимает то же самое значение. Произвести такое кодирование напрямую для всего обучающего множества нельзя: в процессе мы неявно внесём в признаки информацию о целевой переменной. Речь идёт об информации, которую почти любая модель обязательно обнаружит.
Поэтому такие статистики считают по фолдам. Вот пример:
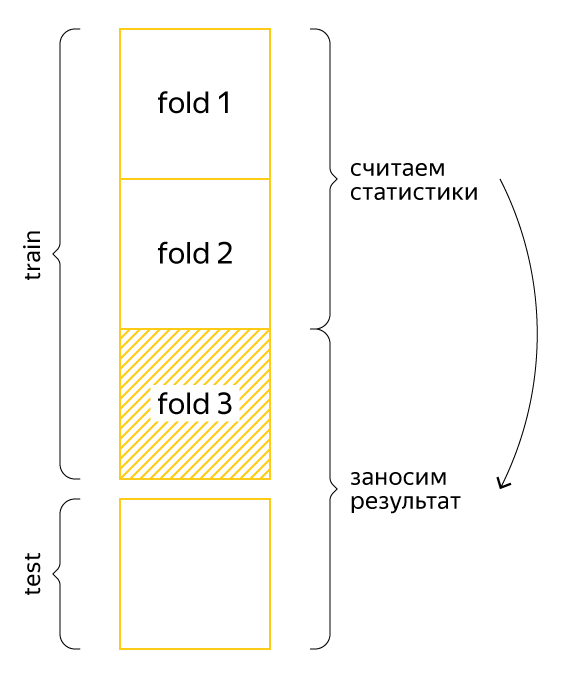
Предположим, что данные разбиты на три части. Для каждого фолда обучающей выборки будем считать новый признак по двум другим фолдам, а для тестовой выборки — по всему обучающему множеству. Тогда информация о целевой переменной будет внесена в выборку не так явно, и модель сможет использовать полученные знания.
Останутся ли проблемы ещё с чем-нибудь? Да — с редко встречающимися категориями и с кросс-валидацией.
Редко встречающиеся категории. Допустим, некоторая категория встретилась всего несколько раз и соответствующие объекты относятся к классу 0. Тогда среднее значение целевой переменной тоже будет нулевым. Однако на тестовой выборке может возникнуть совсем другая ситуация. Решение — сглаженное среднее (или smoothed likelihood), которое вычисляется по следующей формуле:
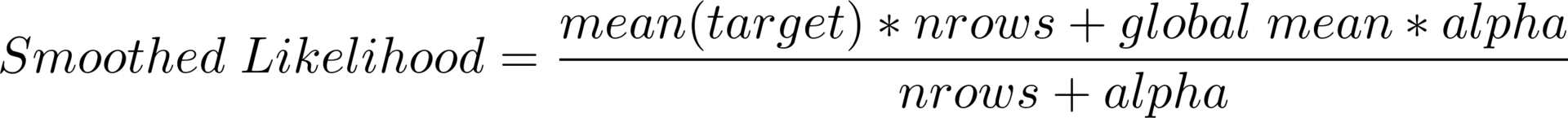
Здесь global mean — среднее значение целевой переменной по всей выборке, nrows — то, сколько раз встретилось конкретное значение категориальной переменной, alpha — параметр регуляризации (например, 10). Теперь, если некоторое значение встречается редко, больший вес будет иметь глобальное среднее, а если достаточно часто, результат окажется близким к начальному среднему по категории. Кстати, эта формула позволяет обрабатывать и неизвестные ранее значения категориальной переменной.
Кросс-валидация. Допустим, мы посчитали все сглаженные средние для категориальных переменных по другим фолдам. Можем ли мы оценить качество модели по стандартной кросс-валидации k-fold? Нет. Давайте рассмотрим пример.

К примеру, мы хотим оценить модель на третьем фолде. Мы обучаем модель на первых двух фолдах, но в них есть новая переменная со средним значением целевой переменной, при подсчёте которой мы уже использовали третий тестовый фолд. Это не позволяет нам корректно оценивать результаты, но возникшая проблема решается подсчётом статистик по фолдам внутри фолдов. Снова обратимся к примеру:
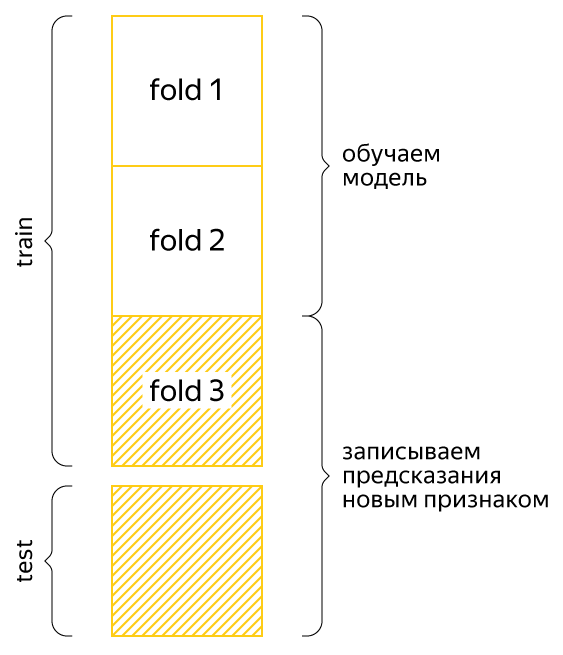
Мы по-прежнему хотим оценить модель на третьем фолде. Разобьём первые два фолда (обучающую выборку нашей оценки) на некоторые другие три фолда, в них посчитаем новый признак по уже разобранному сценарию, а для третьего фолда (это тестовая выборка нашей оценки) посчитаем по первым двум фолдам вместе. Тогда никакая информация из третьего фолда при обучении модели использоваться не будет и оценка получится честной. В соревновании, которое мы обсуждаем, корректно оценить качество модели позволяла только такая кросс-валидация. Разумеется, «внешнее» и «внутреннее» число фолдов может быть любым.
Построение признаков. Мы использовали не только уже упомянутые сглаженные средние значения целевой переменной, но и weights of evidence. Это почти то же самое, но с логарифмическим преобразованием. Кроме того, полезными оказались фичи вида разности количества объектов положительного и отрицательного классов в группе без какой-либо нормировки. Интуиция тут следующая: масштаб показывает степень уверенности в классе, но что делать с количественными признаками? Ведь если их обработать похожим образом, то все значения «забьются» регуляризацией глобальным средним. Одним из вариантов является разделение значений на бины, которые потом считаются отдельными категориями. Другой способ заключается просто в построении некой линейной модели на одном признаке с тем же таргетом. Всего получилось около двух тысяч признаков из 80 отфильтрованных.
Стекинг и блендинг. Как и в большинстве соревнований, важной частью решения является стекинг моделей. Если кратко, то суть стекинга в том, что мы передаём предсказания одной модели как признак в другую модель. Однако важно в очередной раз не переобучиться. Давайте просто разберём пример:
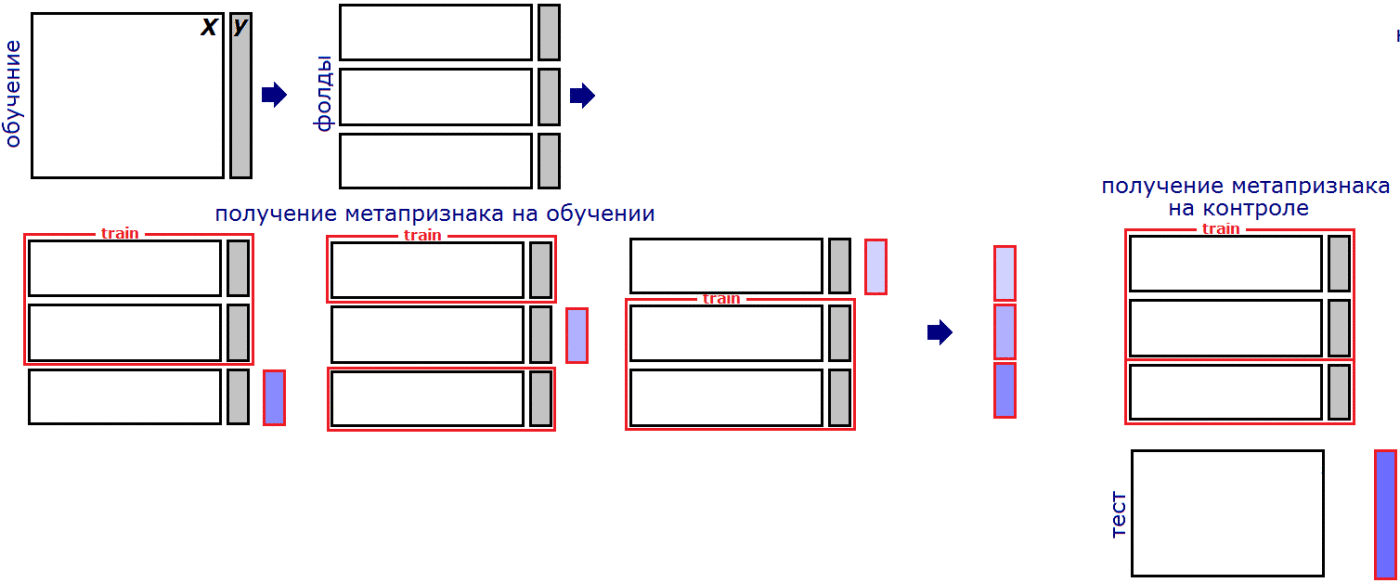
Взято из блога Александра Дьяконова
К примеру, мы решили разбить нашу выборку на три фолда на этапе стекинга. Аналогично подсчёту статистик мы должны обучать модель на двух фолдах, а предсказанные значения добавлять для оставшегося фолда. Для тестовой выборки можно усреднить предсказания моделей с каждой пары фолдов. Каждым уровнем стекинга называют процесс добавления группы новых признаков-предсказаний моделей на основе имеющегося датасета.
На первом уровне у команды было 200-250 различных моделей, на втором — ещё 20-30, на третьем — ещё несколько. Результат — блендинг, то есть смешивание предсказаний различных моделей. Использовались разнообразные алгоритмы: градиентные бустинги с разными параметрами, случайные леса, нейронные сети. Главная идея — применить максимально разнообразные модели с различными параметрами, даже если они дают не самое высокое качество.
Работа в команде. Обычно участники объединяются в команды перед завершением конкурса, когда у каждого уже имеются свои наработки. Мы объединились в команду с другими «кэглерами» ещё в самом начале. У каждого участника команды была папка в общем облаке, где размещались датасеты и скрипты. Общую процедуру кросс-валидации утвердили заранее, чтобы можно было сравнивать между собой. Роли распределялись следующим образом: я придумывал новые признаки, второй участник строил модели, третий — отбирал их, а четвёртый управлял всем процессом.
Откуда брать мощности. Проверка большого числа гипотез, построение многоуровневого стекинга и обучение моделей могут занимать слишком большое время, если использовать ноутбук. Поэтому многие участники пользуются вычислительными серверами с большим количеством ядер и оперативной памяти. Я обычно пользуюсь серверами AWS, а участники моей команды, как оказалось, используют для конкурсов машины на работе, пока те простаивают.
Общение с компанией-организатором. После успешного выступления в конкурсе происходит общение с компанией в виде совместного конференц-звонка. Участники рассказывают о своём решении и отвечают на вопросы. В BNP людей не удивил многоуровневый стекинг, а интересовало их, конечно же, построение признаков, работа в команде, валидация результатов — всё, что может им пригодиться в улучшении собственной системы.
Нужно ли расшифровывать датасет. Команда-победитель заметила в данных одну особенность. Часть признаков имеет пропущенные значения, а часть не имеет. То есть некоторые характеристики не зависели от конкретных людей. Кроме того, получилось 360 уникальных значений. Логично предположить, что речь идёт о неких временных отметках. Оказалось, если взять разность между двумя такими признаки и отсортировать по ней всю выборку, то сначала чаще будут идти нули, а потом единицы. Именно этим и воспользовались победители.
Наша команда заняла третье место. Всего участвовало почти три тысячи команд.
Задача распознавания категории объявления
Ссылка на DataRing.
Это ещё один конкурс «Авито». Он проходил в несколько этапов, первый из которых (как, впрочем, ещё и третий) выиграл Артур Кузин N01Z3.
Постановка задачи. По фотографиям из объявления необходимо определить категорию. Каждому объявлению соответствовало от одного до пяти изображений. Метрика учитывала совпадения категорий на разных уровнях иерархии — от общих к более узким (последний уровень содержит 194 категории). Всего в обучающей выборке был почти миллион изображений, что близко к размеру ImageNet.


Сложности распознавания. Казалось бы, надо всего лишь научиться отличать телевизор от машины, а машину от обуви. Но, например, есть категория «британские кошки», а есть «другие кошки», и среди них встречаются очень похожие изображения — хотя отличить их друг от друга всё-таки можно. А как насчёт шин, дисков и колёс? Тут и человек не справится. Указанные сложности — причина появления некоторого предела результатов всех участников.


Ресурсы и фреймворк. У меня в распоряжении оказались три компьютера с мощными видеокартами: домашний, предоставленный лабораторией в МФТИ и компьютер на работе. Поэтому можно было (и приходилось) обучать по несколько сетей одновременно. В качестве основного фреймворка обучения нейронных сетей был выбран MXNet, созданный теми же ребятами, которые написали всем известный XGBoost. Одно это послужило поводом довериться их новому продукту. Преимущество MXNet в том, что прямо из коробки доступен эффективный итератор со штатной аугментацией, которой достаточно для большинства задач.

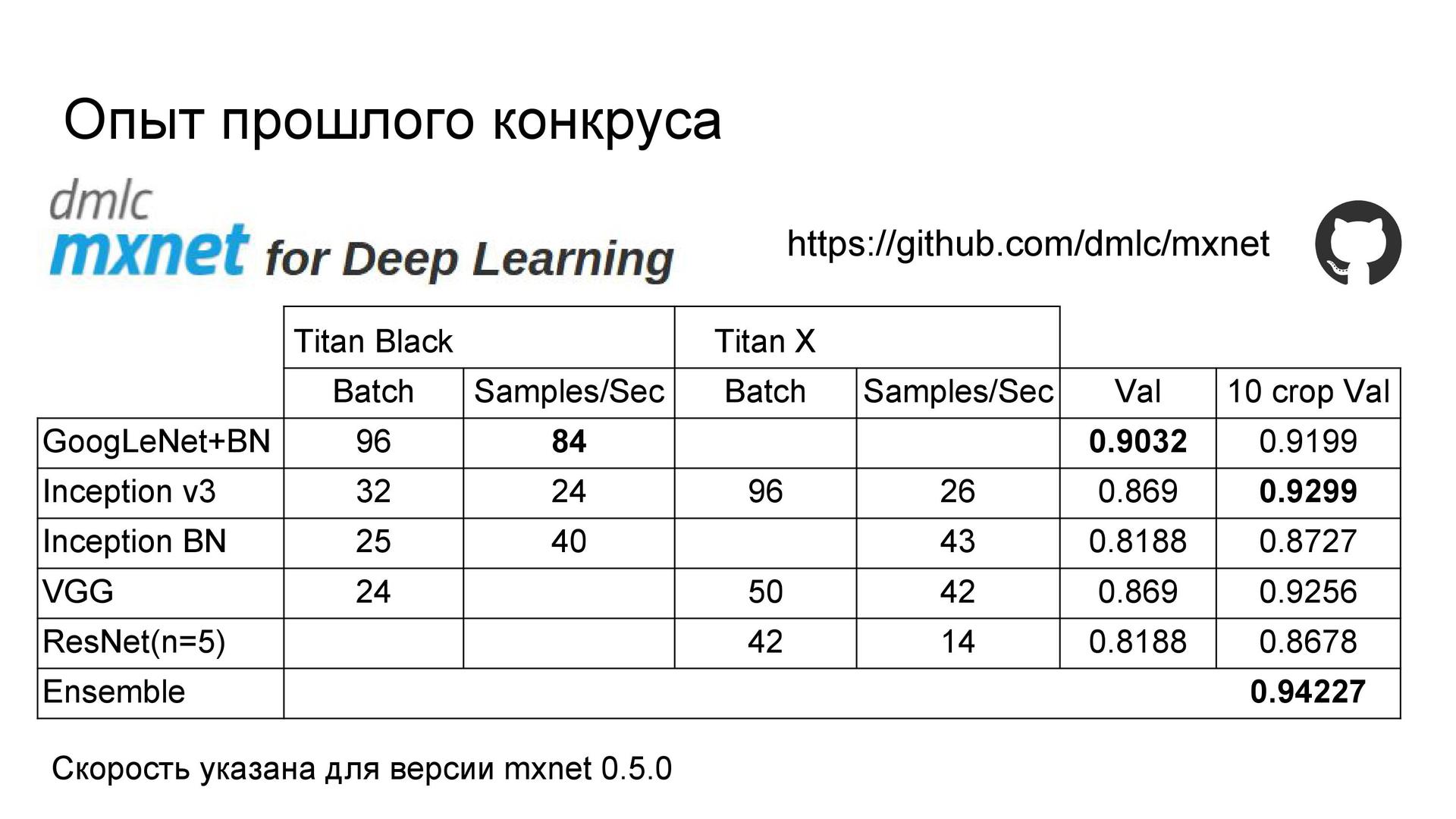
Архитектуры сетей. Опыт участия в одном из прошлых соревнований показал, что лучшее качество показывают архитектуры серии Inception. Их я и задействовал здесь. В GoogLeNet была добавлена батч-нормализация, поскольку она ускоряла обучение модели. Также использовались архитектуры Inception-v3 и Inception BN из библиотеки моделей Model Zoo, в которые был добавлен дропаут перед последним полносвязным слоем. Из-за технических проблем не удавалось обучать сеть с помощью стохастического градиентного спуска, поэтому в качестве оптимизатора использовался Adam.

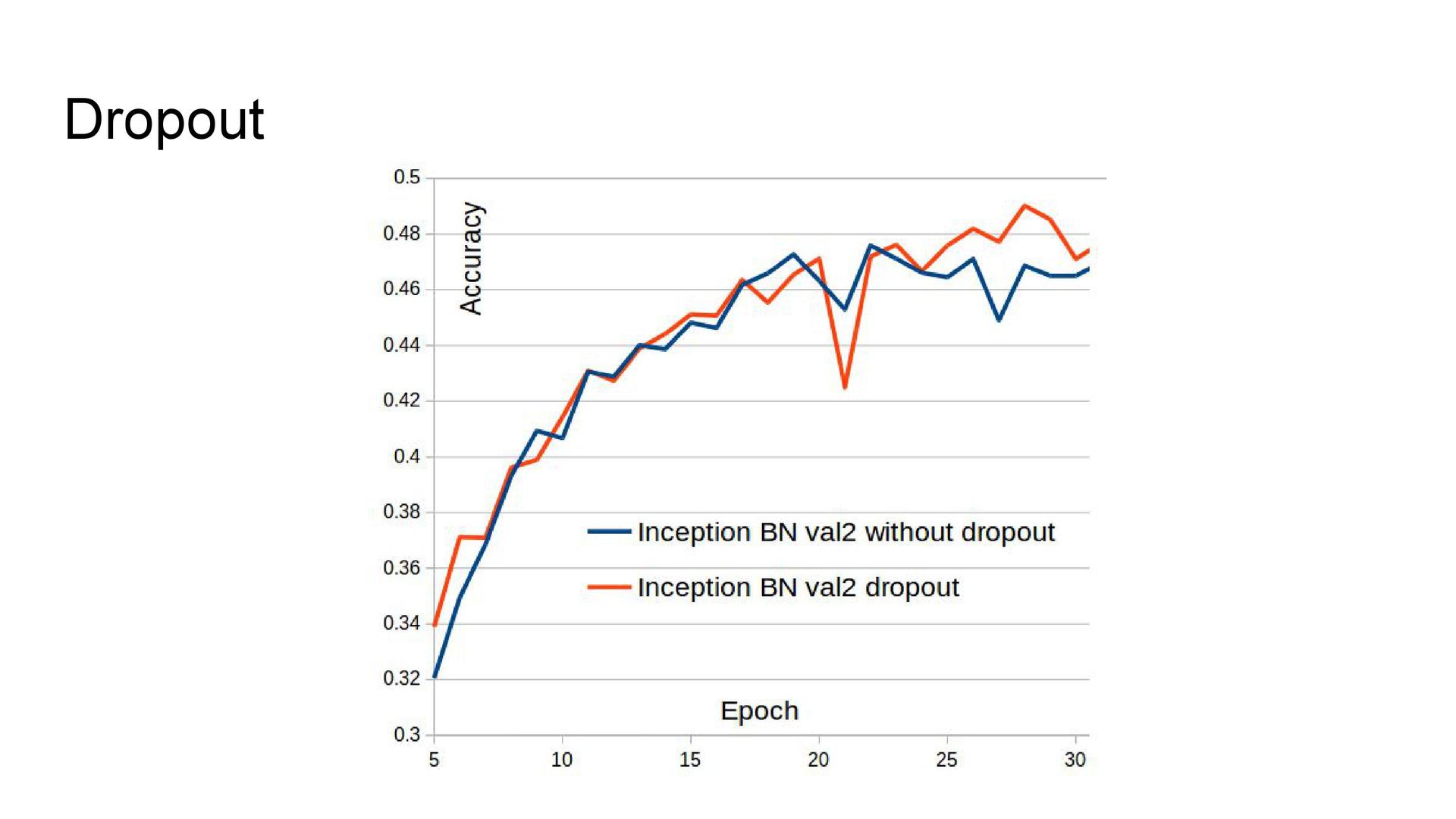
Аугментация данных. Для повышения качества сети использовалась аугментация — добавление искажённых изображений в выборку с целью увеличения разнообразия данных. Были задействованы такие преобразования, как случайное обрезание фотографии, отражение, поворот на небольшой угол, изменение соотношения сторон и сдвиг.

Точность и скорость обучения. Сначала я разделил выборку на три части, но потом отказался от одного из этапов валидации для смешивания моделей. Поэтому впоследствии вторая часть выборки была добавлена в обучающее множество, что улучшило качество сетей. Кроме того, GoogLeNet изначально обучался на Titan Black, у которого вдвое меньше памяти по сравнению с Titan X. Так что эта сеть была дообучена с большим размером батча, и её точность возросла. Если посмотреть на время обучения сетей, можно сделать вывод, что в условиях ограниченных сроков не стоит использовать Inception-v3, поскольку с двумя другими архитектурами обучение идёт заметно быстрее. Причина в числе параметров. Быстрее всех учится Inception BN.
Построение предсказаний.
Как и Евгений в конкурсе с марками автомобилей, Артур использовал предсказания на кропах — но не на 10 участках, а на 24. Участками послужили углы, их отражения, центр, повороты центральных частей и ещё десять случайных.
Если сохранять состояние сети после каждой эпохи, в результате образуется множество различных моделей, а не только финальная сеть. С учётом оставшегося до конца соревнования времени я мог использовать предсказания 11 моделей-эпох — поскольку построение предсказаний с помощью сети тоже длится немало. Все указанные предсказания усреднялись по следующей схеме: сначала с помощью арифметического среднего в рамках групп по кропам, далее с помощью геометрического среднего с весами, подобранными на валидационном множестве. Эти три группы смешиваются, потом повторяем операцию для всех эпох. В конце вероятности классов всех картинок одного объявления усредняются с помощью геометрического среднего без весов.

Результаты. При подборе весов на этапе валидации использовалась метрика соревнования, поскольку она не слишком коррелировала с обычной точностью. Предсказание на разных участках изображений даёт лишь малую часть качества по сравнению с единым предсказанием, но именно за счёт этого прироста удаётся показать лучший результат. По окончании конкурса выяснилось, что первые три места отличаются в результатах на тысячные доли. Например, у Женя Нижибицкого была единственная модель, которая совсем немного уступила моему ансамблю моделей.

Обучение с нуля vs. fine-tuning. Уже после завершения конкурса выяснилось, что несмотря на большой размер выборки стоило обучать сеть не с нуля, а при помощи предобученной сети. Этот подход демонстрирует более высокие результаты.
Задача обучения с подкреплением
Соревнование Black Box Challenge, о котором писали на Хабрахабре, было не совсем похоже на обычный «кэгл». Дело в том, что для решения было недостаточно разметить некоторую «тестовую» выборку. Требовалось запрограммировать и загрузить в систему код «агента», который помещался в неизвестную участнику среду и самостоятельно принимал в ней решения. Такие задачи относятся к области обучения с подкреплением — reinforcement learning.
О подходах к решению рассказал Михаил Павлов из компании 5vision. В конкурсе он занял второе место.
Постановка задачи. Для среды с неизвестными правилами нужно было написать «агента», который взаимодействовал бы с указанной средой. Схематично это некий мозг, который получает от чёрного ящика информацию о состоянии и награде, принимает решение о действии, после чего получает новое состояние и награду за совершённое действие. Действия повторяются друг за другом в течение игры. Текущее состояние описывается вектором из 36 чисел. Агент может совершить четыре действия. Цель — максимизировать сумму наград за всю игру.

Анализ среды. Изучение распределения переменных состояния среды показало, что первые 35 компонент не зависят от выбранного действия и только 36-я компонента меняется в зависимости от него. При этом разные действия влияли по-разному: некоторые увеличивали или уменьшали, некоторые никак не меняли. Но нельзя сказать, что вся среда зависит от одной компоненты: в ней могут быть и некие скрытые переменные. Кроме того, эксперимент показал, что если совершать более 100 одинаковых действий подряд, то награда становится отрицательной. Так что стратегии вида «совершать только одно действие» отпадали сразу. Кто-то из участников соревнования заметил, что награда пропорциональна всё той же 36-й компоненте. На форуме прозвучало предположение, что чёрный ящик имитирует финансовый рынок, где портфелем является 36-я компонента, а действиями — покупка, продажа и решение ничего не делать. Эти варианты соотносились с изменением портфеля, а смысл одного действия понятен не был.

Q-learning. Во время участия основной целью было попробовать различные техники обучения с подкреплением. Одним из самых простых и известных методов является q-learning. Его суть в попытке построить функцию Q, которая зависит от состояния и выбранного действия. Q оценивает, насколько «хорошо» выбирать конкретное действие в конкретном состоянии. Понятие «хорошо» включает в себя награду, которую мы получим не только сейчас, но и будущем. Обучение такой функции происходит итеративно. Во время каждой итерации мы пытаемся приблизить функцию к самой себе на следующем шаге игры с учётом награды, полученной сейчас. Подробнее можно почитать в ещё одной статье на Хабрхабре. Применение q-learning предполагает работу с полностью наблюдаемыми марковскими процессами (другими словами, в текущем состоянии должна содержаться вся информация от среды). Несмотря на то, что среда, по заявлению организаторов, не удовлетворяла этому требованию, применять q-learning можно было достаточно успешно.

Адаптация к black box. Опытным путём было установлено, что для среды лучше всего подходил n-step q-learning, где использовалась награда не за одно последнее действие, а за n действий вперёд. Среда позволяла сохранять текущее состояние и откатываться к нему, что облегчало сбор выборки — можно было из одного состояния попробовать совершить каждое действие, а не какое-то одно. В самом начале обучения, когда q-функция ещё не умела оценивать действия, использовалась стратегия «совершать действие 3». Предполагалось, что оно ничего не меняло и можно было начать обучаться на данных без шума.
Процесс обучения. Обучение происходило так: с текущей политикой (стратегией агента) играем весь эпизод, накапливая выборку, потом с помощью полученной выборки обновляем q-функцию и так далее — последовательность повторяется в течение некоторого количества эпох. Результаты получались лучше, чем при обновлении q-функции в процессе игры. Другие способы — техника replay memory (с общим банком данных для обучения, куда заносятся новые эпизоды игры) и одновременное обучение нескольких агентов, играющих асинхронно, — тоже оказалось менее эффективными.

Модели. В решении использовались три регрессии (каждая по одному разу в расчёте на каждое действие) и две нейронных сети. Были добавлены некоторые квадратичные признаки и взаимодействия. Итоговая модель представляет собой смесь всех пяти моделей (пяти Q-функций) с равными весами. Кроме того, использовалось онлайн-дообучение: в процессе тестирования веса́ старых регрессий подмешивались к новым весам, полученным на тестовой выборке. Это делалось только для регрессий, поскольку их решения можно выписывать аналитически и пересчитывать достаточно быстро.

Другие идеи. Естественно, не все идеи улучшали итоговый результат. Например, дисконтирование награды (когда мы не просто максимизируем суммарную награду, а считаем каждый следующий ход менее полезным), глубокие сети, dueling-архитектура (с оценкой полезности состояния и каждого действия в отдельности) не дали роста результатов. Из-за технических проблем не получилось применить рекуррентные сети — хотя в ансамбле с другими моделями они, возможно, обеспечили бы некоторую пользу.


Итоги. Команда 5vision заняла второе место, но с совсем небольшим отрывом от обладателей «бронзы».
Итак, зачем нужно участвовать в соревнованиях по анализу данных?
- Призы. Успешное выступление в большинстве соревнований вознаграждается денежными призами или другими ценными подарками. На Kaggle за семь лет разыграли более семи миллионов долларов.
- Карьера. Иногда призовое место выливается в смену работы.
- Опыт. Это, конечно, самое главное. Можно изучить новую область и начать решать задачи, с которыми вы раньше не сталкивались.

Сейчас тренировки по машинному обучению проводятся по субботам каждую вторую неделю. Место проведения — московский офис Яндекса, стандартное число гостей (гости плюс яндексоиды) — 60-80 человек. Главным свойством тренировок служит их злободневность: всякий раз разбирается конкурс, завершившийся одну-две недели назад. Это мешает всё точно спланировать, но зато конкурс ещё свеж в памяти и в зале собирается много людей, попробовавших в нём свои силы. Курирует тренировки Эмиль Каюмов, который, кстати, помог с написанием этого поста.
Кроме того, есть другой формат: зарешивания, где начинающие специалисты совместными усилиями участвуют в действующих конкурсах. Зарешивания проводятся по тем субботам, когда нет тренировок. На мероприятия обоих типов может прийти любой, анонсы публикуются в группах на Фейсбуке и ВКонтакте, есть YouTube-канал с прямыми трансляциями. Кстати, зарешивания также проходят в Санкт-Петербурге, Новосибирске, Екатеринбурге и Калининграде. Если вашего города нет в списке, а небольшое сообщество уже сформировалось — попробуйте организовать несколько встреч самостоятельно.

Вот и всё. Посещаете тренировки, слушаете, пробуете участвовать, занимаете какие-нибудь далёкие места, начинаете ходить на зарешивания, снова пробуете — замечая или не замечая, что из вас вырастает data scientist. Если сейчас вы разработчик или devops, то пройти подобный путь реально и, что самое главное, не так уж и сложно. Например — проще, чем пробовать стать аналитиком данных каким-нибудь другим способом.
Полезные ссылки, или как начать решать:
- Если вы уже не новичок и хотите в сжатые сроки «прокачаться» по основным темам — пройдите курc Яндекса «Введение в машинное обучение» на Coursera.
- Желающим изучать предмет постепенно больше подойдёт специализация «Машинное обучение и анализ данных».
- Сообщество Open Data Science (каналы #mltrainings_beginners, #mltrainings_live).
