Обычный будний день в одной организации перестал быть обычным после того, как несколько десятков человек не смогли продолжать свою деятельность, так как замерли все привычные процессы. Прекратила свою работу CRM, перестала откликаться база менеджеров, аналогичная картина была с бухгалтерскими базами. На системного администратора обрушился шквал звонков пользователей с сообщениями о проблемах и требованиями срочного вмешательства. Системный администратор, который сравнительно недавно начал карьеру в этой компании, попытался подключиться к NAS и обнаружил, что устройство не откликается. После отключения питания и повторного включения NAS вернулся к жизни, но запуска виртуальных машин не произошло. Для пользователей оказалось доступным только общее хранилище файлов. Анализ проблем системным администратором показал, что один из двух RAID массивов не содержит томов и является чистым неразмеченным пространством. Какими были дальнейшие действия системного администратора, история умалчивает, но достаточно быстро он осознал, что у него нет четкого плана действий по восстановлению данных и рабочей среды компании. На данном этапе шесть накопителей на жестких магнитных дисках (2 HDD – 3 TB HDS5C3030ALA630, 4 HDD – 4 TB WD4000FYYZ-01UL1B1) из этого NAS поступают в наше распоряжение. В техническом задании нам предлагается «восстановить таблицу разделов».

Разумеется, при таких объемах дисков ни о какой классической таблице разделов не может идти и речи. Для безопасного проведения работ нам необходимо оценить состояние каждого из накопителей, чтобы выбрать оптимальные методики создания посекторных копий. Для этого анализируем показания SMART, также проверяем состояние БМГ посредством чтения небольших участков каждой из головок в зонах разной плотности. В нашем случае все накопители оказались исправными.
Для оптимизации времени выполнения работ создадим копии по 100 000 000 секторов от начала диска. Эти 50-гигабайтные образы нам потребуются для проведения анализа в то время, как будут создаваться посекторные копии накопителей (создание полных копий – обязательная страховка, хотя порой кажется не таким важным мероприятием, которое только задерживает процедуру восстановления данных).
Необходимо понять, каким образом NAS работает с дисками, и какие средства логической разметки используются. Для этого посмотрим в LBA 0 и 1 каждого из дисков.

рис. 2
На двух накопителях по 3ТБ по смещению 0x01C2 записан тип раздела 0xEE, берущий начало с LBA 0x00000001 и размер его 0xFFFFFFFF секторов. Данная запись является типичной защитной записью для накопителей, где используется GPT. Полагая, что использовалась GPT, оценим содержимое сектора 1, который в образе берет начало с 0x200. Регулярное выражение 0x45 0x46 0x49 0x20 0x50 0x41 0x52 0x54 (в текстовом виде: EFI PART) информирует нас о том, что перед нами заголовок GPT.
В секторе 2 обнаруживаем записи о разделах GPT

рис. 3
В первой записи описан раздел с 0x0000000000000022 сектора по 0x0000000000040021 сектор, который имеет GUID, не соответствующий стандарту. В нем содержится восклицание от разработчика, который в слегка сжатом виде вещает “Hah! I don’t Need EFI“. Метка тома “BIOS boot partition“.
Во второй записи описан раздел с 0x0000000000040022 сектора по 0x0000000000140021, идентификатор этого раздела A19D880F-05FC-4D3B-A006-743F0F84911E. Метка тома “Linux RAID”.
В третьей записи описана раздел с 0x0000000000140022сектора по 0x000000015D509B4D сектор, которые также имеет GUID A19D880F-05FC-4D3B-A006-743F0F84911E. Метка тома “Linux RAID”.
Исходя из размеров разделов, можно пренебречь первым и вторым, так как очевидно, что данные разделы созданы для нужд NAS. Третий раздел – это то, что нас на данные момент интересует. Согласно идентификатора имеет признак участника RAID массива, созданного средствами Linux. Исходя из этого, нам необходимо найти суперблок конфигурации RAID. Ожидаемое место его расположения через 8 секторов от начала раздела.

рис. 4
В нашем случае по смещению 0x0 обнаружено регулярное выражение 0xFC 0x4E 0x2B 0xA9, которое является маркером суперблока конфигурации RAID. По смещению 0x48 видим значение 0x00000001, что говорит о том, что в данном блоке описан массив RAID 1 (зеркало), значение 0x00000002 по смещению 0x5C сообщает нам, что в составе данного массива 2 участника. По смещению 0x80 сообщается, что область данных массива начнется через 0x00000800 (2048) секторов (отсчет ведется от начала раздела с суперблоком). По смещению 0x88 в QWORD прописано количество секторов 0x000000015D3C932C (5 859 218 220), которое на данном разделе принимает участие в RAID массиве.
Перейдя к области начала данных находим признак LVM

рис. 5
переходим к последней версии конфигурации.
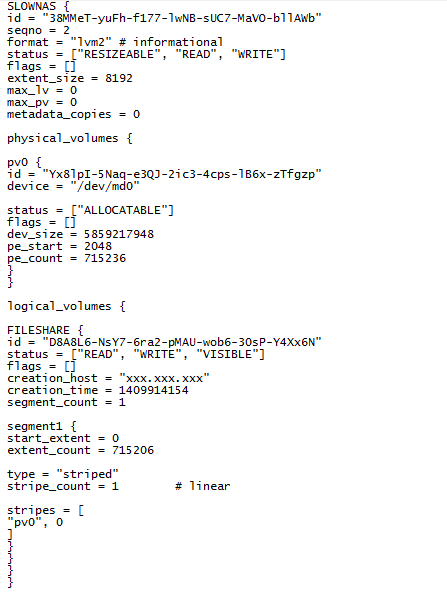
рис. 6
В конфигурации видим, что на данном массиве один том, состоящий из одного сегмента, с именем «FILESHARE», который занимает практически всю емкость массива (количество экстентов*размер экстента=емкость в секторах 715 206*8 192=5 858 967 552. Проверив раздел, описанный в этом томе, обнаруживаем файловую систему Ext4, записи в которой явно свидетельствуют о соответствии имени раздела содержимому.
Анализируя содержимое второго накопителя емкостью 3ТБ, обнаруживаем наличие идентичных структур и полное соответствие в области данных для RAID 1, что подтверждает, что этот диск также был в составе данного массива. Зная, что файлообменник с именем FILESHARE был доступен пользователям, исключаем эти два диска из дальнейшего рассмотрения.
Переходим к анализу накопителей емкостью 4ТБ. Для этого рассмотрим содержимое нулевого сектора каждого из накопителей на предмет наличия защитной таблицы разделов.

рис. 7
Но вместо этого обнаруживаем некое мусорное содержимое, которое не может претендовать на звание таблицы разделов. Аналогичная картина с 1 по 33 секторы. Признаки таблицы разделов (защитной MBR) и GPT отсутствуют на всех дисках. При анализе RAID 1, описанном выше, мы получили информацию, какие области этот NAS отводит для служебных целей, на основании этого мы предполагаем, с какого смещения может начинаться раздел с областью, участвующей в другом массиве с пользовательскими данными.
Выполним поиск суперблоков конфигурации RAID (по регулярному выражению 0xFC 0x4E 0x2B 0xA9) на данных накопителях в окрестностях смещения 0x28000000. На каждом из дисков находится суперблок по смещению 0x28101000 (адрес несколько отличается от того, что на первой паре дисков, вероятно из-за того, что в данном случае было учтено, что данные 4ТБ диски с физическим сектором 4096 байт с эмуляцией 512 байтного сектора).

рис. 8
По смещению 0x48 значение 0x00000005 (RAID5)
По смещению 0x58 значение 0x00000400 (1024) – размер блока чередования 1024 сектора (512КБ)
По смещению 0x5C значение 0x00000003 – количество участников в массиве. Учитывая, что дисков с одинаковыми суперблоками 4, а, согласно записи, участвует 3 диска, можно сделать вывод, что одному из дисков отведена роль диска горячей замены (hot spare). Также уточняем, что данный массив был RAID 5E.
По смещению 0x80 значение 0x0000000000000800 (2048) – количество секторов от начала раздела до области, принимающей участие в массиве.
По смещению 0x88 значение 0x00000001D1ACAE8F (7 812 722 319) секторов – размер области, принимающей участие в массиве.
Если накопитель, задействованный в качестве диска горячей замены, не вступил в работу, и не была произведена операция rebuild, то его содержимое будет сильно отличаться от содержимого остальных трех дисков. В нашем случае при пролистывании дисков в hex редакторе легко обнаруживается практически пустой накопитель. Его также исключаем их рассмотрения.
Полагая, что суперблок конфигурации RAID находился по стандартному смещению от начала раздела, можем получить адрес начала раздела 0x28101000-0x1000=0x208100000. Соответственно, область начала данных с учетом содержимого по смещению:
0x208100000+(0x0000000000000800*0x200)=0x208200000.
Перейдя по данному смещению, видим, что на протяжении 1024 (0x800) секторов на каждом из дисков не обнаруживается ничего похожего на LVM либо какой-то иной вариант логической разметки. При выполнении теста корректности данных со смещения 0x208200000 посредством XOR операции над содержимым трех накопителей стабильно получаем 0, что свидетельствует о целостности RAID 5 и подтверждает, что ни один накопитель не был исключен из массива (и не была проведена операция Rebuild). Исходя из содержимого массива RAID 1 предположим, что и в массиве RAID 5 область 0x100000 в начале, которая на данный момент заполнена мусорными данными, предназначалась для размещения LVM.
Учитывая, что данный RAID является чередующимся массивом с блоком четности, то отступив на 0x100000 от начала массива, нам необходимо на каждом диске переместиться на позицию 0x208280000, предположительно с этого адреса начнется область данных в LVM. Проверим это предположение посредством анализа данных по этому смещению. Если это не том, используемый для свопа, то должны быть признаки либо какой-то логической разметки внутри раздела, описанного в LVM, либо признаки какой-либо файловой системы.
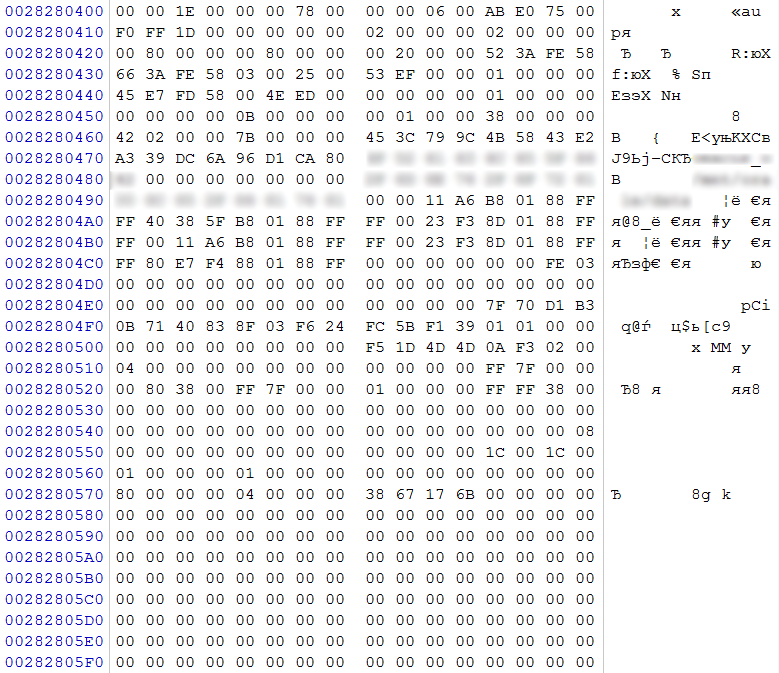
рис. 9
По характерному смещению 0x0400 на одном из дисков (согласно нумерации клиента – №2) обнаруживаем суперблок Ext4. В нем по смещению 0x04 DWORD – количество блоков в данной файловой системе, по смещению 0x18 в неявном виде указывается размер блока (для вычисления размера блока необходимо возвести 2 в степень (10+Х), где Х – значение по смещению 0x18). На основании этих значений выполним расчет размера раздела, с которым оперирует данная файловая система 0x00780000*0x1000=0x780000000 байт (30ГБ). Видим, что размер раздела существенно меньше емкости массива. Полагаем, что это лишь один из разделов, который был описан в LVM, и, исходя из смещения относительно начала массива, можем полагать, что он начинался с нулевого экстента.
Хоть и первичные предположения о расположении данных оказались верны, но для сборки массива мы не будем использовать информацию из суперблока конфигурации RAID, а проведем анализ данных внутри раздела и на основании этого установим параметры массива. Данный метод позволит нам подтвердить корректность параметров в суперблоке конфигурации RAID применительно к этому массиву или опровергнуть и установить правильные.
Для определения размера блока и параметров чередования блока четности удобно использовать монотонно возрастающие последовательности. На разделах Ext2, Ext 3, Ext 4 их можно найти в Group Descriptors (не во всех случаях). Возьмем удобную область для каждого из дисков:

рис. 10 (HDD 2)

рис. 11 (HDD 1)

рис. 12 (HDD 0)
Листая в hex редакторе c шагом 0x1000 каждый из дисков, заметим, что возрастание чисел по внутрисекторным смещениям 0x00, 0x04, 0x08 и т.д. идет на протяжении 1024 секторов или 0x80000 байт (справедливо только для блоков с данными, но не для блоков с результатами XOR операции), что достаточно явно подтверждает размер блока, описанный в суперблоке конфигурации RAID.
Глядя на рис. 10, рис. 11, рис. 12, легко определим роли дисков на данном месте и порядок их использования. Для построения полной матрицы будем пролистывать образы всех дисков с шагом 0x80000 и вписывать значения со смещений 0x00 в таблицу. Для заполнения таблицы использования дисков впишем названия дисков согласно возрастанию значений, вписанных нами в первую таблицу.
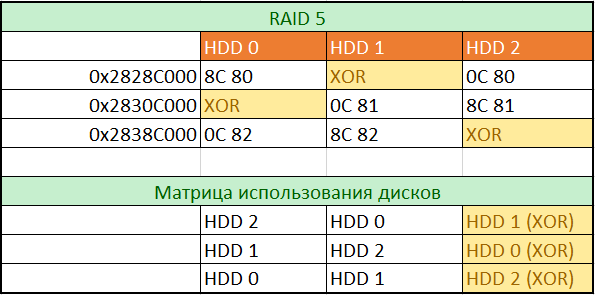
рис. 13
Согласно матрице использования дисков, проведем сбор массива RAID 5 с 0x28280000 в рамках первых 30 ГБ. Этот адрес был выбран, исходя из отсутствия LVM и того, что начало обнаруженного нами EXT4 раздела приходится на это смещение. В полученном образе мы сможем полностью проверить файловую систему и соответствие типов файлов, описанных в ней, фактически размещенным данным. В нашем случае эта проверка не выявила каких-либо недостатков, что подтверждает корректность всех предыдущих выводов. Теперь можно приступить к полному сбору массива.
Из-за отсутствия LVM нам предстоит процедура поиска разделов в собранном массиве. Для разделов, состоящих из одного сегмента, эта процедура не будет ничем отличаться от поиска разделов на обычном накопителе с очищенной таблицей разделов (MBR) или GPT. Все сведется к поиску признаков начала разделов различных файловых систем и таблиц разделов.
В случае же томов, которые принадлежали утерянной LVM, и состоящих из 2 и более фрагментов, потребуется дополнительный комплекс мероприятий:
– построение карты логических томов, состоящих из одного сегмента посредством записи диапазона секторов, занимаемых томом на разделе;
– построение карты разделов первых сегментов фрагментированных томов. Предстоит точно определить место обрыва раздела. Эта процедура намного проще, если известен точный размер экстента, используемого в утерянной LVM. Порядок размера экстента можно предположить, исходя из местоположения начала томов. К сожалению, данная методика не всегда применима.

Рис. 14
В пустых участках карты предстоит поиск сегментов, которые необходимо приращивать к первому сегменту какого-либо из фрагментированных томов. Следует обратить внимание, что таких фрагментов томов может быть достаточно много. Проверять корректность приращений можно посредством анализа файловых записей в файловой системе тома с сопоставлением фактическим данным.
Выполнив весь комплекс мероприятий, получим все образы логических томов, находившихся в RAID массиве.
Также обращаю внимание, что в данной публикации намеренно не упомянуты профессиональные комплексы для восстановления данных, которые позволяют упростить некоторые этапы работ.
Следующая публикация: Немного реверс-инжиниринга USB flash на контроллере SK6211
Предыдущая публикация: Восстановление файлов после трояна-шифровальщика

Разумеется, при таких объемах дисков ни о какой классической таблице разделов не может идти и речи. Для безопасного проведения работ нам необходимо оценить состояние каждого из накопителей, чтобы выбрать оптимальные методики создания посекторных копий. Для этого анализируем показания SMART, также проверяем состояние БМГ посредством чтения небольших участков каждой из головок в зонах разной плотности. В нашем случае все накопители оказались исправными.
Для оптимизации времени выполнения работ создадим копии по 100 000 000 секторов от начала диска. Эти 50-гигабайтные образы нам потребуются для проведения анализа в то время, как будут создаваться посекторные копии накопителей (создание полных копий – обязательная страховка, хотя порой кажется не таким важным мероприятием, которое только задерживает процедуру восстановления данных).
Необходимо понять, каким образом NAS работает с дисками, и какие средства логической разметки используются. Для этого посмотрим в LBA 0 и 1 каждого из дисков.
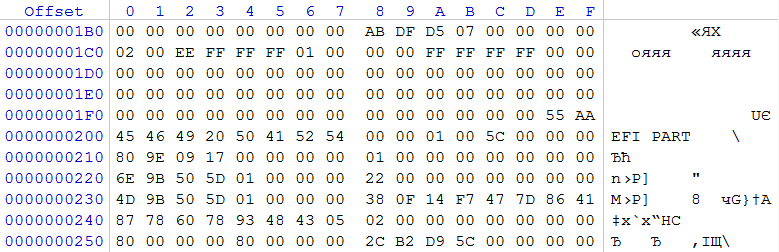
рис. 2
На двух накопителях по 3ТБ по смещению 0x01C2 записан тип раздела 0xEE, берущий начало с LBA 0x00000001 и размер его 0xFFFFFFFF секторов. Данная запись является типичной защитной записью для накопителей, где используется GPT. Полагая, что использовалась GPT, оценим содержимое сектора 1, который в образе берет начало с 0x200. Регулярное выражение 0x45 0x46 0x49 0x20 0x50 0x41 0x52 0x54 (в текстовом виде: EFI PART) информирует нас о том, что перед нами заголовок GPT.
В секторе 2 обнаруживаем записи о разделах GPT

рис. 3
В первой записи описан раздел с 0x0000000000000022 сектора по 0x0000000000040021 сектор, который имеет GUID, не соответствующий стандарту. В нем содержится восклицание от разработчика, который в слегка сжатом виде вещает “Hah! I don’t Need EFI“. Метка тома “BIOS boot partition“.
Во второй записи описан раздел с 0x0000000000040022 сектора по 0x0000000000140021, идентификатор этого раздела A19D880F-05FC-4D3B-A006-743F0F84911E. Метка тома “Linux RAID”.
В третьей записи описана раздел с 0x0000000000140022сектора по 0x000000015D509B4D сектор, которые также имеет GUID A19D880F-05FC-4D3B-A006-743F0F84911E. Метка тома “Linux RAID”.
Исходя из размеров разделов, можно пренебречь первым и вторым, так как очевидно, что данные разделы созданы для нужд NAS. Третий раздел – это то, что нас на данные момент интересует. Согласно идентификатора имеет признак участника RAID массива, созданного средствами Linux. Исходя из этого, нам необходимо найти суперблок конфигурации RAID. Ожидаемое место его расположения через 8 секторов от начала раздела.
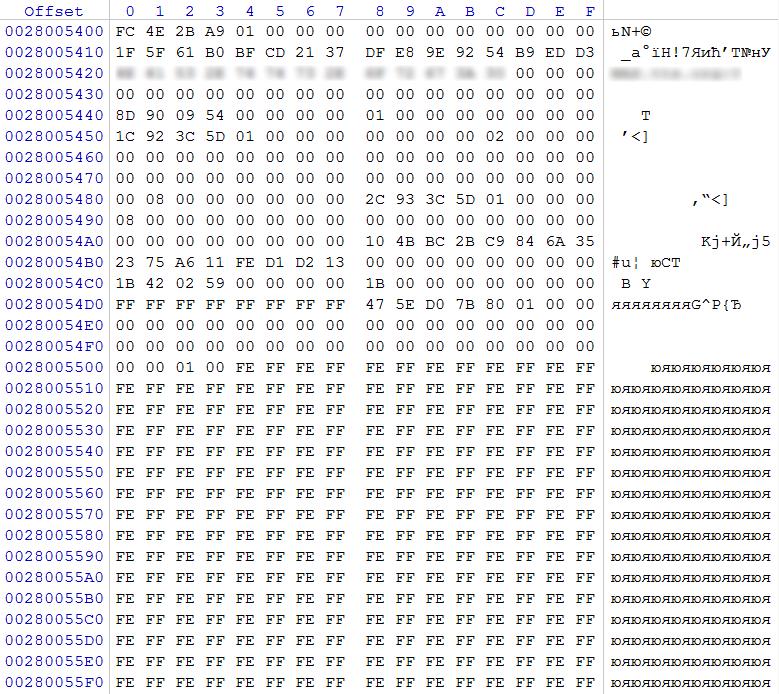
рис. 4
В нашем случае по смещению 0x0 обнаружено регулярное выражение 0xFC 0x4E 0x2B 0xA9, которое является маркером суперблока конфигурации RAID. По смещению 0x48 видим значение 0x00000001, что говорит о том, что в данном блоке описан массив RAID 1 (зеркало), значение 0x00000002 по смещению 0x5C сообщает нам, что в составе данного массива 2 участника. По смещению 0x80 сообщается, что область данных массива начнется через 0x00000800 (2048) секторов (отсчет ведется от начала раздела с суперблоком). По смещению 0x88 в QWORD прописано количество секторов 0x000000015D3C932C (5 859 218 220), которое на данном разделе принимает участие в RAID массиве.
Перейдя к области начала данных находим признак LVM
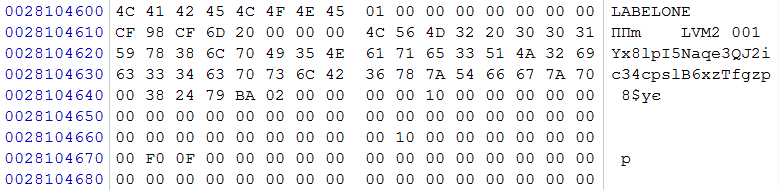
рис. 5
переходим к последней версии конфигурации.
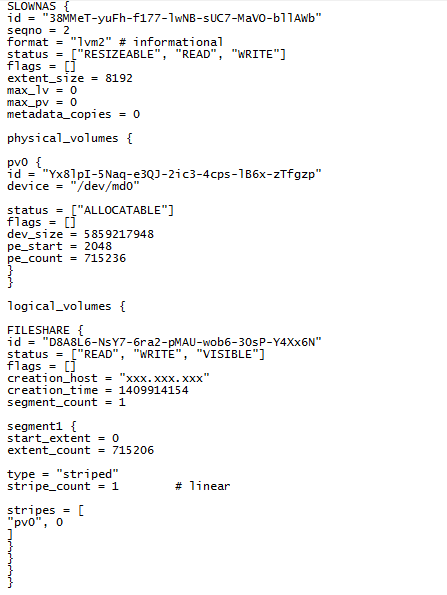
рис. 6
В конфигурации видим, что на данном массиве один том, состоящий из одного сегмента, с именем «FILESHARE», который занимает практически всю емкость массива (количество экстентов*размер экстента=емкость в секторах 715 206*8 192=5 858 967 552. Проверив раздел, описанный в этом томе, обнаруживаем файловую систему Ext4, записи в которой явно свидетельствуют о соответствии имени раздела содержимому.
Анализируя содержимое второго накопителя емкостью 3ТБ, обнаруживаем наличие идентичных структур и полное соответствие в области данных для RAID 1, что подтверждает, что этот диск также был в составе данного массива. Зная, что файлообменник с именем FILESHARE был доступен пользователям, исключаем эти два диска из дальнейшего рассмотрения.
Переходим к анализу накопителей емкостью 4ТБ. Для этого рассмотрим содержимое нулевого сектора каждого из накопителей на предмет наличия защитной таблицы разделов.

рис. 7
Но вместо этого обнаруживаем некое мусорное содержимое, которое не может претендовать на звание таблицы разделов. Аналогичная картина с 1 по 33 секторы. Признаки таблицы разделов (защитной MBR) и GPT отсутствуют на всех дисках. При анализе RAID 1, описанном выше, мы получили информацию, какие области этот NAS отводит для служебных целей, на основании этого мы предполагаем, с какого смещения может начинаться раздел с областью, участвующей в другом массиве с пользовательскими данными.
Выполним поиск суперблоков конфигурации RAID (по регулярному выражению 0xFC 0x4E 0x2B 0xA9) на данных накопителях в окрестностях смещения 0x28000000. На каждом из дисков находится суперблок по смещению 0x28101000 (адрес несколько отличается от того, что на первой паре дисков, вероятно из-за того, что в данном случае было учтено, что данные 4ТБ диски с физическим сектором 4096 байт с эмуляцией 512 байтного сектора).
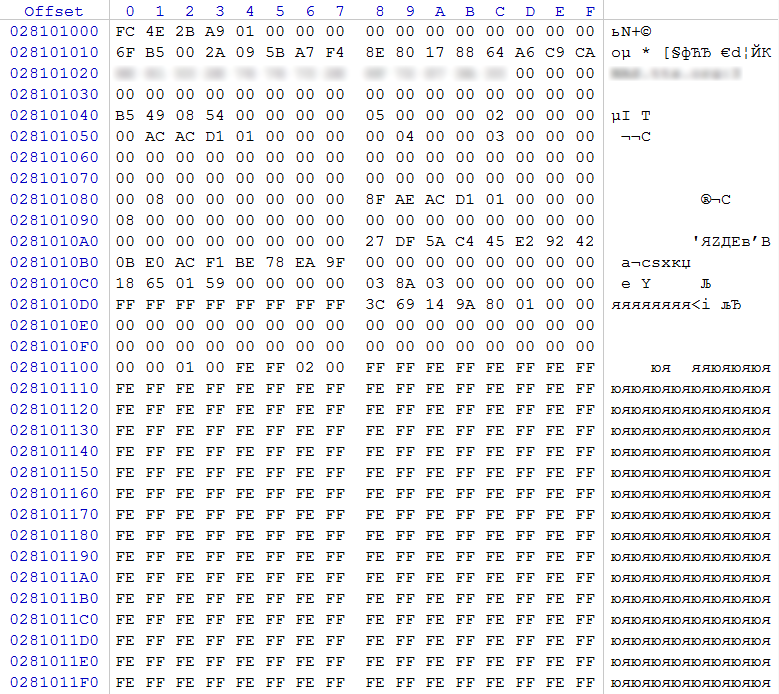
рис. 8
По смещению 0x48 значение 0x00000005 (RAID5)
По смещению 0x58 значение 0x00000400 (1024) – размер блока чередования 1024 сектора (512КБ)
По смещению 0x5C значение 0x00000003 – количество участников в массиве. Учитывая, что дисков с одинаковыми суперблоками 4, а, согласно записи, участвует 3 диска, можно сделать вывод, что одному из дисков отведена роль диска горячей замены (hot spare). Также уточняем, что данный массив был RAID 5E.
По смещению 0x80 значение 0x0000000000000800 (2048) – количество секторов от начала раздела до области, принимающей участие в массиве.
По смещению 0x88 значение 0x00000001D1ACAE8F (7 812 722 319) секторов – размер области, принимающей участие в массиве.
Если накопитель, задействованный в качестве диска горячей замены, не вступил в работу, и не была произведена операция rebuild, то его содержимое будет сильно отличаться от содержимого остальных трех дисков. В нашем случае при пролистывании дисков в hex редакторе легко обнаруживается практически пустой накопитель. Его также исключаем их рассмотрения.
Полагая, что суперблок конфигурации RAID находился по стандартному смещению от начала раздела, можем получить адрес начала раздела 0x28101000-0x1000=0x208100000. Соответственно, область начала данных с учетом содержимого по смещению:
0x208100000+(0x0000000000000800*0x200)=0x208200000.
Перейдя по данному смещению, видим, что на протяжении 1024 (0x800) секторов на каждом из дисков не обнаруживается ничего похожего на LVM либо какой-то иной вариант логической разметки. При выполнении теста корректности данных со смещения 0x208200000 посредством XOR операции над содержимым трех накопителей стабильно получаем 0, что свидетельствует о целостности RAID 5 и подтверждает, что ни один накопитель не был исключен из массива (и не была проведена операция Rebuild). Исходя из содержимого массива RAID 1 предположим, что и в массиве RAID 5 область 0x100000 в начале, которая на данный момент заполнена мусорными данными, предназначалась для размещения LVM.
Учитывая, что данный RAID является чередующимся массивом с блоком четности, то отступив на 0x100000 от начала массива, нам необходимо на каждом диске переместиться на позицию 0x208280000, предположительно с этого адреса начнется область данных в LVM. Проверим это предположение посредством анализа данных по этому смещению. Если это не том, используемый для свопа, то должны быть признаки либо какой-то логической разметки внутри раздела, описанного в LVM, либо признаки какой-либо файловой системы.
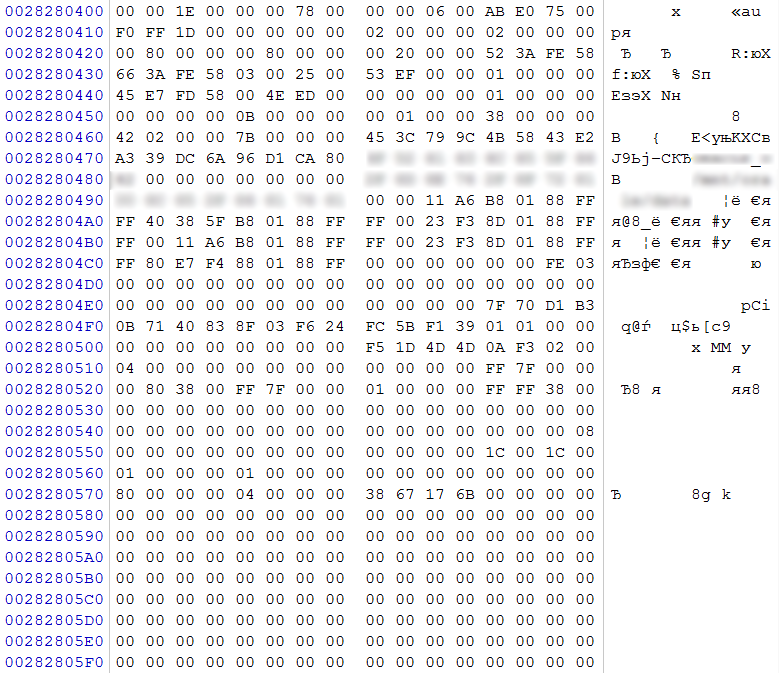
рис. 9
По характерному смещению 0x0400 на одном из дисков (согласно нумерации клиента – №2) обнаруживаем суперблок Ext4. В нем по смещению 0x04 DWORD – количество блоков в данной файловой системе, по смещению 0x18 в неявном виде указывается размер блока (для вычисления размера блока необходимо возвести 2 в степень (10+Х), где Х – значение по смещению 0x18). На основании этих значений выполним расчет размера раздела, с которым оперирует данная файловая система 0x00780000*0x1000=0x780000000 байт (30ГБ). Видим, что размер раздела существенно меньше емкости массива. Полагаем, что это лишь один из разделов, который был описан в LVM, и, исходя из смещения относительно начала массива, можем полагать, что он начинался с нулевого экстента.
Хоть и первичные предположения о расположении данных оказались верны, но для сборки массива мы не будем использовать информацию из суперблока конфигурации RAID, а проведем анализ данных внутри раздела и на основании этого установим параметры массива. Данный метод позволит нам подтвердить корректность параметров в суперблоке конфигурации RAID применительно к этому массиву или опровергнуть и установить правильные.
Для определения размера блока и параметров чередования блока четности удобно использовать монотонно возрастающие последовательности. На разделах Ext2, Ext 3, Ext 4 их можно найти в Group Descriptors (не во всех случаях). Возьмем удобную область для каждого из дисков:

рис. 10 (HDD 2)

рис. 11 (HDD 1)

рис. 12 (HDD 0)
Листая в hex редакторе c шагом 0x1000 каждый из дисков, заметим, что возрастание чисел по внутрисекторным смещениям 0x00, 0x04, 0x08 и т.д. идет на протяжении 1024 секторов или 0x80000 байт (справедливо только для блоков с данными, но не для блоков с результатами XOR операции), что достаточно явно подтверждает размер блока, описанный в суперблоке конфигурации RAID.
Глядя на рис. 10, рис. 11, рис. 12, легко определим роли дисков на данном месте и порядок их использования. Для построения полной матрицы будем пролистывать образы всех дисков с шагом 0x80000 и вписывать значения со смещений 0x00 в таблицу. Для заполнения таблицы использования дисков впишем названия дисков согласно возрастанию значений, вписанных нами в первую таблицу.
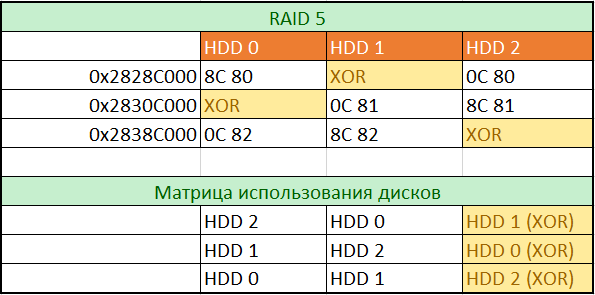
рис. 13
Согласно матрице использования дисков, проведем сбор массива RAID 5 с 0x28280000 в рамках первых 30 ГБ. Этот адрес был выбран, исходя из отсутствия LVM и того, что начало обнаруженного нами EXT4 раздела приходится на это смещение. В полученном образе мы сможем полностью проверить файловую систему и соответствие типов файлов, описанных в ней, фактически размещенным данным. В нашем случае эта проверка не выявила каких-либо недостатков, что подтверждает корректность всех предыдущих выводов. Теперь можно приступить к полному сбору массива.
Из-за отсутствия LVM нам предстоит процедура поиска разделов в собранном массиве. Для разделов, состоящих из одного сегмента, эта процедура не будет ничем отличаться от поиска разделов на обычном накопителе с очищенной таблицей разделов (MBR) или GPT. Все сведется к поиску признаков начала разделов различных файловых систем и таблиц разделов.
В случае же томов, которые принадлежали утерянной LVM, и состоящих из 2 и более фрагментов, потребуется дополнительный комплекс мероприятий:
– построение карты логических томов, состоящих из одного сегмента посредством записи диапазона секторов, занимаемых томом на разделе;
– построение карты разделов первых сегментов фрагментированных томов. Предстоит точно определить место обрыва раздела. Эта процедура намного проще, если известен точный размер экстента, используемого в утерянной LVM. Порядок размера экстента можно предположить, исходя из местоположения начала томов. К сожалению, данная методика не всегда применима.
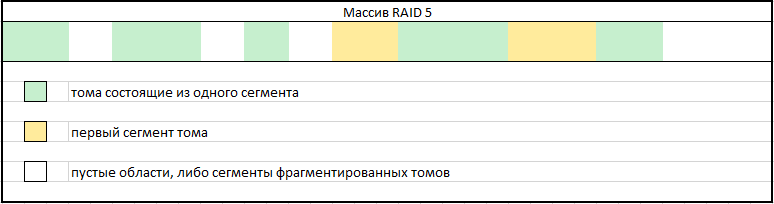
Рис. 14
В пустых участках карты предстоит поиск сегментов, которые необходимо приращивать к первому сегменту какого-либо из фрагментированных томов. Следует обратить внимание, что таких фрагментов томов может быть достаточно много. Проверять корректность приращений можно посредством анализа файловых записей в файловой системе тома с сопоставлением фактическим данным.
Выполнив весь комплекс мероприятий, получим все образы логических томов, находившихся в RAID массиве.
Также обращаю внимание, что в данной публикации намеренно не упомянуты профессиональные комплексы для восстановления данных, которые позволяют упростить некоторые этапы работ.
Следующая публикация: Немного реверс-инжиниринга USB flash на контроллере SK6211
Предыдущая публикация: Восстановление файлов после трояна-шифровальщика
