В этой статье мы детально разберем атомарные операции и барьеры памяти C++11 и генерируемые ими ассемблерные инструкции на процессорах x86_64.
Далее мы покажем как ускорить работу contfree_safe_ptr<std::map> до уровня сложных и оптимизированных lock-free структур данных аналогичных по функциональности std::map<>, например: SkipListMap и BronsonAVLTreeMap из библиотеки libCDS (Concurrent Data Structures library): github.com/khizmax/libcds
И такую многопоточную производительность мы сможем получить для любого вашего изначально потоко-небезопасного класса T используемого как contfree_safe_ptr<T>. Нас интересуют оптимизации повышающие производительность на ~1000%, поэтому мы не будем уделять внимание слабым и сомнительным оптимизациям.
Три связанные статьи:
→ Моя статья на английском
→ Примеры и тесты из всех трех статей
contfree_safe_ptr<T> — это класс safe_ptr<T, contention_free_shared_mutex>, где contention_free_shared_mutex – это собственный оптимизированный shared-mutex. А safe_ptr — это потокобезопасный указатель из прошлой статьи.
По порядку покажем, как реализовать собственный высокопроизводительный contention-free shared-mutex, почти не конфликтующий на чтениях. Реализуем собственные активные блокировки spinlock и recursive-spinlock для блокирования строк(rows) на операциях update. Создадим RAII-блокирующие указатели, чтобы избежать затрат на многократное блокирование. Приведем результаты тестов производительности.
И как бонус «Just for fun» покажем, как реализовывать собственный класс упрощенного секционированного типа partitioned_map, ещё сильнее оптимизированного для многопоточности, состоящего из нескольких std::map, по аналогии с partition table из СУБД, когда границы каждой секции известны изначально.
Рассмотрим основы многопоточности, атомарности и барьеров памяти. Если мы изменяем одни и те же данные из множества потоков, т.е. если мы запускаем функцию thread_func() одновременно в нескольких потоках:
То каждый поток вызывающий функцию thread_func() прибавляет 1 к обычной разделяемой переменной int a; Такой код в общем случае не будет потоко-безопасным, т.к. составные операции (RMW – read-modify-write) над обычными переменными состоят из множества маленьких операций, между которыми другой поток может изменить данные. Операция a = a+1; состоит как минимум из трех мини-операций:
Например, если int a=0; и 2 потока выполнят операцию a=a+1; то в результате должно быть a=2; Но может произойти следующее – пошагово:
Два потока прибавили к одной и той же глобальной переменной +1, но в итоге переменная a = 1 – такая проблема называется Data-Races.
Чтобы избежать этой проблемы есть 3 способа:
Для std::atomic<int> a; если изначально a=0; и 2 потока выполняют операцию a+=1; то результат всегда будет a=2;
Следующее всегда будет происходить на процессорах x86_64 (пошагово):
На процессорах с поддержкой LL/SC, например на ARM или PowerPC, будут происходить другие шаги, но с тем же самым результатом a = 2.
Атомарные переменные введены в стандарт C++11: en.cppreference.com/w/cpp/atomic/atomic
Функции члены шаблона класса std::atomic<> всегда являются атомарными.
Приведем 3 фрагмента правильного кода идентичного по смыслу:
1. Пример:
2. Это идентично примеру 1:
3. И это идентично примеру 1:
Это значит, что для std::atomic:
Отметим отличия std::atomic и volatile в C++11: www.drdobbs.com/parallel/volatile-vs-volatile/212701484
Здесь есть 5 основных отличий:
Есть и одно общее правило для переменных std::atomic и volatile: каждая операция чтения или записи всегда обращается к памяти/кэшу, т.е. значения никогда не кэшируются в регистрах процессора.
Так же отметим, что для обычных(ordinary) переменных и объектов (non-atomic/non-volatile) – возможны любые оптимизации и любые переупорядочивания независимых инструкций относительно друг друга компилятором или процессором.
Напомним, что операции записи в память над atomic-переменными с барьерами памяти std::memory_order_release, std::memory_order_acq_rel и std::memory_order_seq_cst гарантируют spilling (запись из регистров в память) сразу всех non-atomic/non-volatile переменных находящихся на данный момент в регистрах процессора: en.wikipedia.org/wiki/Register_allocation#Spilling
Компилятор и процессор меняют порядок инструкций для оптимизации программы и повышения производительности.
Приведем пример оптимизаций, которые делают компилятор GCC и процессор x86_64: godbolt.org/g/n91hpt
Картинка в полном размере:
hsto.org/files/3d2/18b/c7b/3d218bc7b3584f82820f92077096d7a0.jpg
Какие происходят оптимизации на картинке:
Процессоры семейства x86_64 имеют strong memory model. А процессоры имеющие weak memory model, например, PowerPC и ARM v7 / v8 могут выполнять ещё больше переупорядочиваний.
Приведем примеры возможного переупорядочивание записи в память обычных ordinary-переменных, volatile-переменных и atomic-переменных.
Переупорядочивание обычных переменных:
Этот код с обычными переменными может быть переупорядочен компилятором или процессором, т.к. в рамках одного потока его смысл не изменяется. Но в рамках множества потоков такие переупорядочивания могут повлиять на логику программы.
Если 2 переменных будут volatile, то возможны следующие переупорядочивания. Компилятор не может переупорядочить операции над volatile-переменными во время компиляции, но компилятор позволяет процессору выполнять это переупорядочение во время выполнения.
Чтобы предотвратить все или только некоторые из таких переупорядочиваний – существуют атомарные операции (напомним, что по умолчанию atomic-операции используют самый строгий барьер памяти std::memory_order_seq_cst):
Другой поток может увидеть изменения переменных в памяти именно в таком измененном порядке.
Если мы не указываем барьер памяти для атомарной операции, то по умолчанию используется самый строгий барьер std::memory_order_seq_cst, и никакие атомарные или не атомарные операции не могут переупорядочиваться с такими операциями (но есть исключения – которые мы рассмотрим дальше).
В приведенном выше случае, сначала идет запись в обычные переменные a и b, а затем в атомарные-переменные a_at и b_at, и этот порядок не может измениться. Так же запись в память b_at не может произойти раньше, чем запись в память a_at. А вот запись в переменные a и b могут переупорядочиваться относительно друг друга.
Когда мы говорим «могут переупорядочиваться» — это значит могут, но не обязательно. Это зависит от того как решит оптимизировать код C++-компилятор во время компиляции или CPU во время выполнения.
Ниже мы рассмотрим более слабые барьеры памяти, которые позволяют переупорядочиваться инструкциям в разрешенных направлениях – это позволяет компилятору и процессору лучше оптимизировать код и больше повышать производительность.
Модель памяти стандарта C++11 предоставляет нам 6 типов барьеров памяти, которые соответствуют возможностям современных CPU для внеочередного исполнения операций (speculative execution), используя их мы не полностью запрещаем изменение порядка, а только в необходимых направлениях. Это оставляет возможность компилятору и процессору максимально оптимизировать код. А запрещенные направления переупорядочивания позволяют сохранить корректность нашего кода. en.cppreference.com/w/cpp/atomic/memory_order
Остальные 4 барьера памяти могут использоваться для любых операций, за исключением: acquire – не используется для store(), а release — не используется для load().

В зависимости от выбранного барьера памяти – компилятору и процессору запрещается перемещать исполняемый код относительно барьера в разных направлениях.
Теперь покажем, что именно обозначают данные стрелочки – покажем что с чем может меняться местами, а что не может:
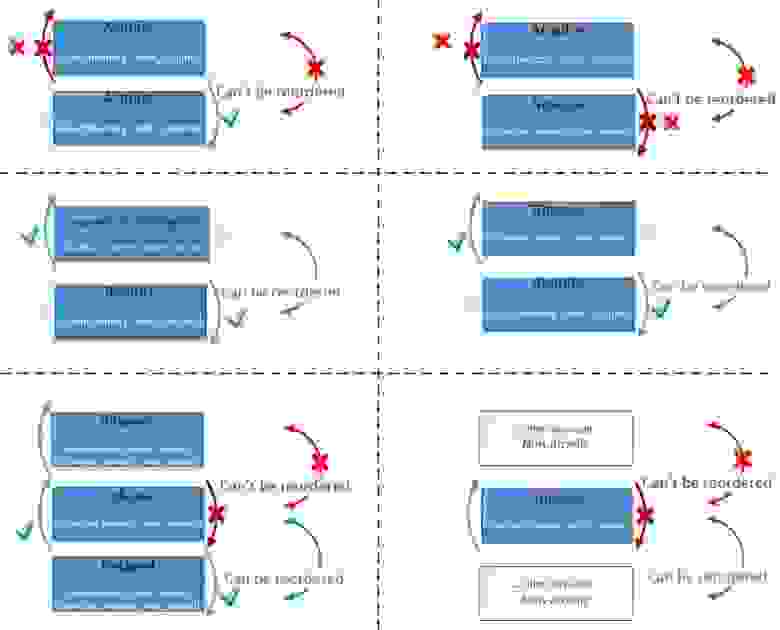
Чтобы 2 инструкции могли поменяться местами – необходимо, чтобы барьеры обеих этих инструкций разрешали такой обмен. Т.к. «Other any code» – это обычные неатомарные переменные у которых нет барьеров, то они разрешают любые изменения порядка. На левом-нижнем примере Relaxed-Release-Relaxed, как вы видите – возможность изменения порядка одних и тех же барьеров памяти зависит от того в какой последовательности они идут.
Давайте рассмотрим, что означают эти барьеры памяти и какие преимущества они дают нам на примере реализации простейшей блокировки «spin-lock», которая требует самую распространенную семантику переупорядочивания Acquire-Release. Spin-lock – это блокировка по способу использования похожая на std::mutex.
Для начала мы реализуем концепцию spin-lock непосредственно в теле нашей программы. А потом уже реализуем отдельный класс spin-lock. Для реализации блокировок (mutex, spinlock…) необходимо использовать Acquire-Release семантику, C++11 Standard § 1.10.1 (3): www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606.pdf
Основной смысл Acquire-Release семантики в том, что: поток-2 «Thread-2» после выполнения операции flag.load(std::memory_order_acquire) должен увидеть все изменения любых переменных/структур/классов (даже не атомарных), которые были сделаны потоком-1 «Thread-1» до выполнения им операции flag.store(0, std::memory_order_release).
Основной смысл блокировок (mutex, spinlock…) – это создание участка кода, который может исполняться только одним потоком в одно и тоже время, т.е. не может исполняться двумя и более потоками параллельно. Такой участок кода называется – критической секцией. Внутри неё можно использовать любой обычный код, в том числе без std::atomic.
Барьеры памяти (memory fences) – препятствуют оптимизации программы компилятором, чтобы ни одна операция из критической секции не вышла за её пределы.
Поток который первым захватывает блокировку – исполняет этот блок кода, а остальные потоки ждут в цикле (возможно временно засыпая). Когда первый поток отпустил блокировку, то процессор решает какой следующий из ожидающих потоков захватит её. И так далее.
Приведем 2 идентичных по смыслу примера:
Пример-1 предпочтительнее, поэтому для него схематически покажем смысл использования барьеров памяти – сплошным синим цветом показаны атомарные операции:
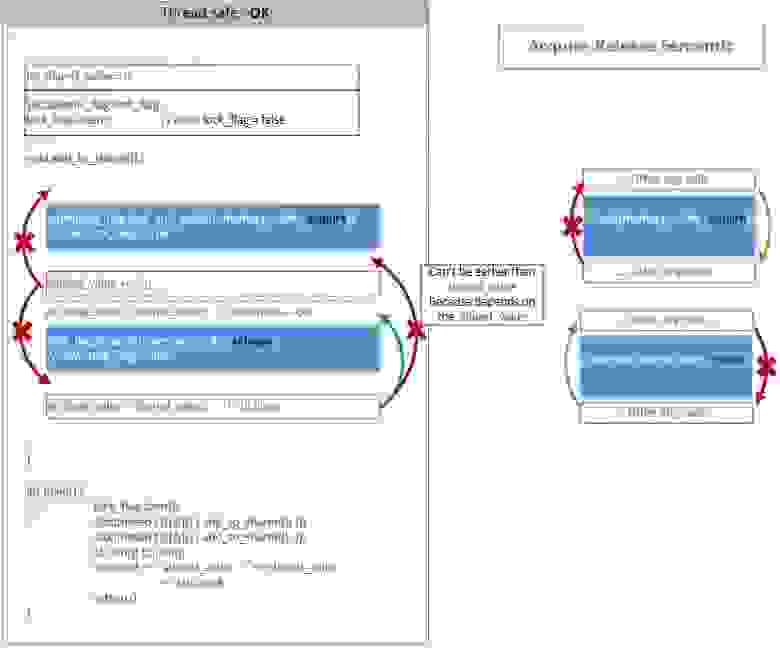
[19] coliru.stacked-crooked.com/a/1ec9a0c2b10ce864
Смысл барьеров очень простой – оптимизатору компилятора запрещается перемещать инструкции из критической секции наружу:
Любые другие изменения порядка исполнения независимых инструкций могут быть выполнены компилятором (compile-time) или процессором (run-time) – в целях оптимизации производительности.
Например, строка int new_shared_value = shared_value; может быть выполнена до lock_flag.clear(std::memory_order_release);. Такое переупорядочивание приемлемо и не создает data-races, т.к. весь код, который обращается к общим для множества потоков данным всегда заключен внутри двух барьеров acquire и release. А снаружи находится код, который работает только с локальными для потока данными – и не важно в каком порядке он будет выполнен. Локальные для потока зависимости всегда сохраняются также, как это происходит при однопоточном исполнении, поэтому int new_shared_value = shared_value; не может быть выполнен раньше, чем shared_value += 25;
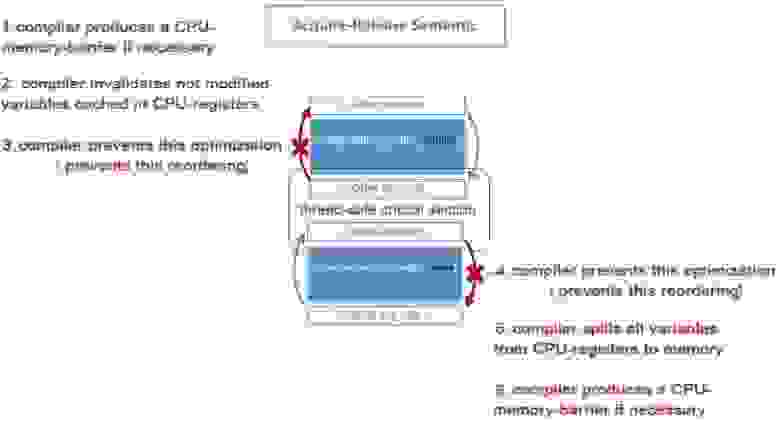
Так что же запрещают, и что разрешают барьеры acquire-release для критической секции:
Какие конкретно действия выполняет компилятор на std::memory_order:
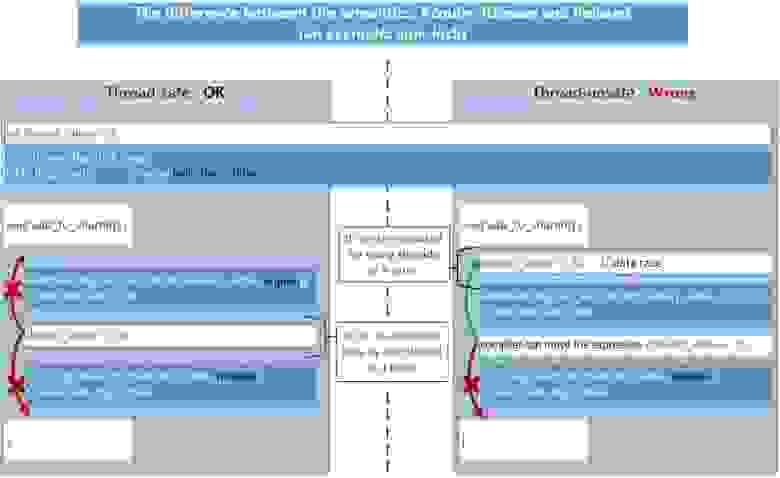
А теперь давайте посмотрим, чтобы получилось, если бы мы использовали Relaxed-Release семантику вместо Acquire-Release:
Заметим, что обычно невозможно реализовать всю логику над общими данными только с помощью атомарных операций, так как их очень мало и они достаточно медленные если их много. Поэтому проще и быстрее: одной атомарной операцией установить флаг «закрыто», выполнить все неатомарные операции над общими для потоков данными, и установить флаг «открыто».
Покажем схематически этот процесс во времени:
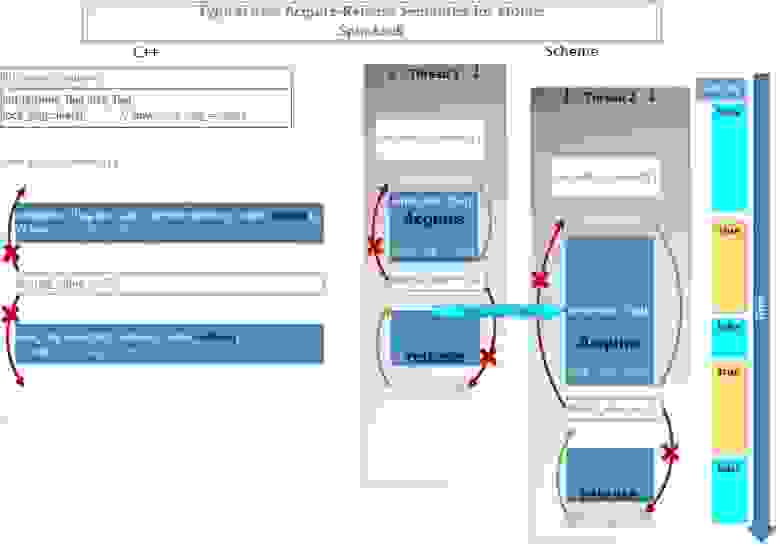
Например, два потока начинают исполнение функции add_to_shared().
Вначале этой главы мы привели 2 примера:
Подробнее об этих операциях по ссылке: en.cppreference.com/w/cpp/atomic/atomic
Давайте посмотрим, как отличается ассемблерный код для x86_64 генерируемый компилятором GCC для этих двух примеров:
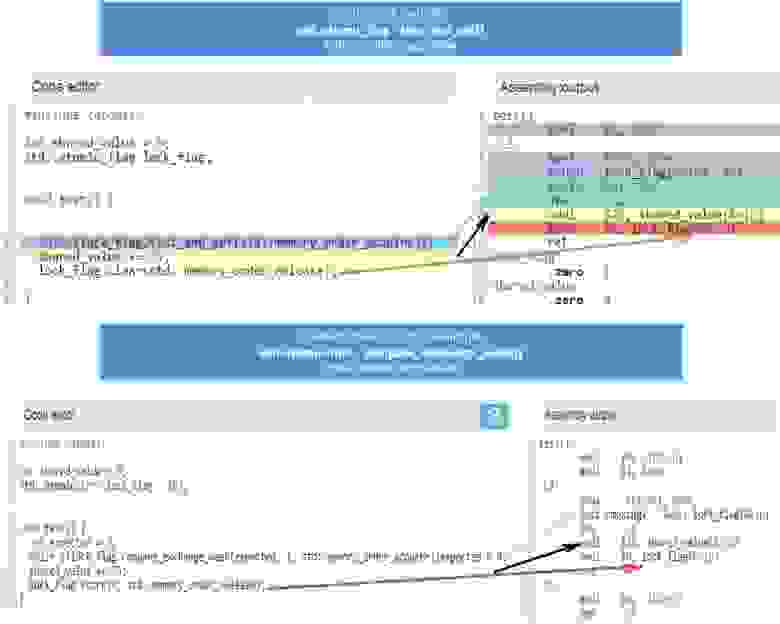
Чтобы было удобно использовать, его можно объединить в один класс:
Пример использования класса spinlock_t по ссылке: [23] coliru.stacked-crooked.com/a/92b8b9a89115f080
Чтобы вы всегда могли понять какой барьер вам использовать и во что он будет скомпилирован на x86_64, я приведу следующую таблицу:
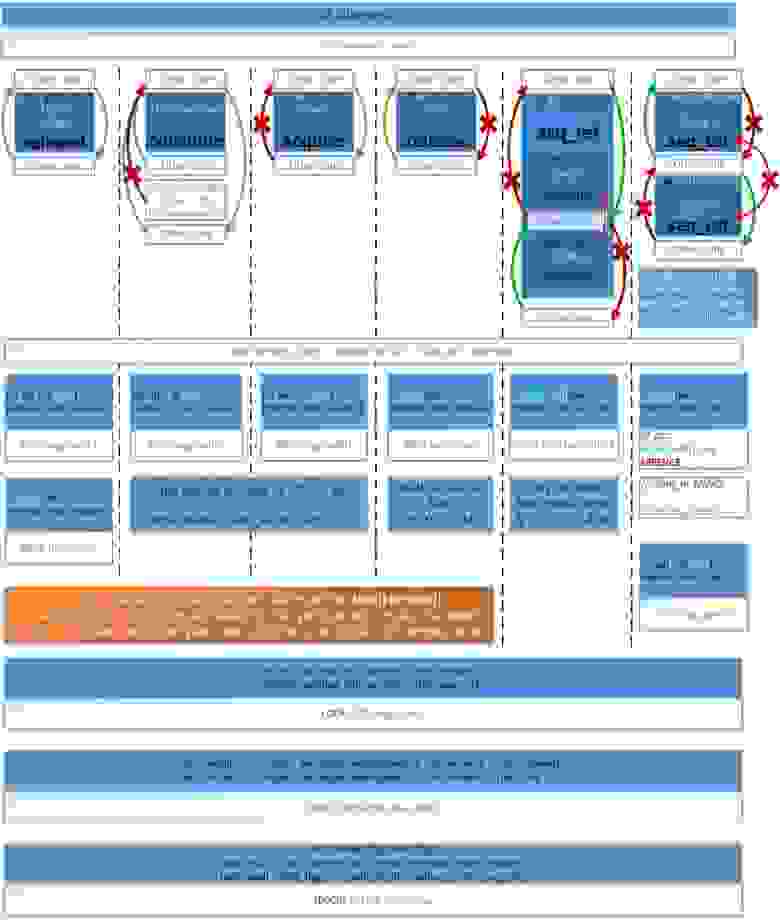
Картинку можно посмотреть в полном размере по ссылке: hsto.org/files/4f8/7b4/1b6/4f87b41b64a54549afca679af1028f84.jpg
Следующее необходимо знать, только если вы пишете код на ассемблере x86_64, когда компилятор не может менять местами ассемблерные инструкции для оптимизации:
Как мы знаем нигде и никогда не могут быть переупорядочены зависимые операции, например: (Read-X, Write-X) или (Write-X, Read-X)
Слайды с выступления Herb Sutter для x86_64: https://onedrive.live.com/view.aspx?resid=4E86B0CF20EF15AD!24884&app=WordPdf&authkey=!AMtj_EflYn2507c
• На x86_64 не могут быть переупорядочены любые:
• На x86_64 может быть переупорядочены любые: Write-X <–> Read-Y. Чтобы это предотвратить используется барьер std::memory_order_seq_cst, который может генерировать 4 варианта кода на x86_64 в зависимости от компилятора:
Сводная таблица соответствия барьеров памяти инструкциям процессора для архитектур (x86_64, PowerPC, ARMv7, ARMv8, AArch64, Itanium) по ссылке: www.cl.cam.ac.uk/~pes20/cpp/cpp0xmappings.html
Посмотреть реальный ассемблерный код для разных компиляторов вы можете по ссылкам. А также можете выбрать другие архитектуры: ARM, ARM64, AVR, PowerPC.
GCC 6.1 (x86_64):
Clang 3.8 (x86_64):
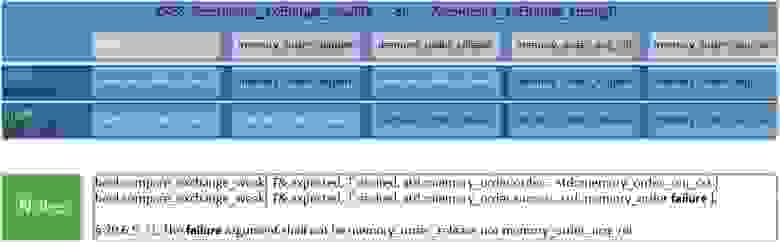
Так же кратко покажем в таблице, какой эффект оказывают различные барьеры памяти на порядок относительно CAS (Compare-and-swap)-инструкций: en.cppreference.com/w/cpp/atomic/atomic/compare_exchange
Теперь покажем более сложные примеры переупорядочивания из 4-ех последовательных операций: LOAD, STORE, LOAD, STORE.
Приведем 4 примера в каждом из которых покажем возможное переупорядочивание операций с обычными переменными вокруг операций с атомарными переменными. Но только в примерах 1 и 3 также возможно некоторое переупорядочивание атомарных операций между собой.
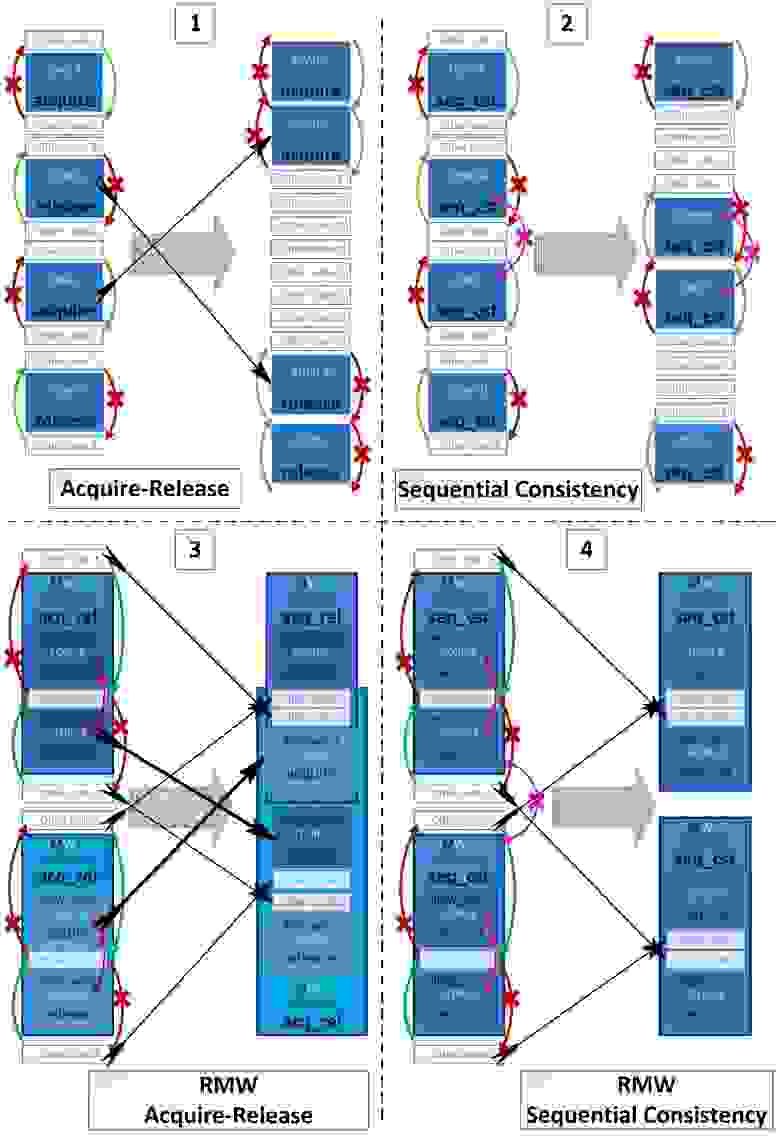
1-й случай – интересен тем, что несколько критических секций могут быть слиты (fused) в одну.
Компилятор не может выполнить такое переупорядочение во время компиляции, но компилятор позволяет процессору выполнять это переупорядочение во время выполнения. Поэтому слияние критических секций, которые выполняются в разных последовательностях в разных потоках, не может привести к взаимной блокировке (deadlock), потому что начальная последовательность инструкций будет видна процессору. Следовательно процессор попытается заранее войти в вторую критическую секцию, но если он не сможет, он продолжит выполнение первой критической секции и после полного её завершения будет ожидать входа во вторую критическую секцию.
3-й случай – интересен тем, что части двух составных атомарных инструкций могут быть переупорядочены: STORE A <--> LOAD B.
2й случай – интересен тем, что std::memory_order_seq_cst самый сильный барьер и казалось бы должен запрещать любые переупорядочивания атомарных или неатомарных операций вокруг себя. Но seq_cst-барьеры обладают только одним дополнительным свойством по сравнению с acquire/release – только если обе атомарные операции имеют seq_cst-барьер, то последовательность операций STORE-A(seq_cst); LOAD-B(seq_cst); не может быть переупорядочена. Приведем 2 цитаты стандарта C++:
Разрешенные направления для переупорядочивания не–seq_cst операций (атомарных и неатомарных) вокруг seq_cst-операций такие же как и у acquire/release:
Более строгий порядок возможен, но не гарантируется.
В случае seq_cst также, как для acquire и release: ничто идущее до STORE(seq_cst) не может быть выполнено после него, и ничто идущее после LOAD(seq_cst) не может быть выполнено до него.
Но в обратном направлении переупорядочивание возможно.
Теперь покажем какие изменения порядка инструкций разрешают компиляторы для процессоров, на примере GCC для x86_64 и PowerPC — примеры кода на C++ и сгенерированного кода на Assembler x86_64 и PowerPC.
Возможны следующие изменения порядка вокруг memory_order_seq_cst–операций:
Покажем подробнее на примере из 3 переменных с семантикой: seq_cst и relaxed.

Какие переупорядочивания позволяет делать компилятор C++
Почему такие изменения порядка возможны? Потому что C++-компилятор генерирует assembler-код, которые позволяет делать такие переупорядочивание процессорам x86_64 и PowerPC:
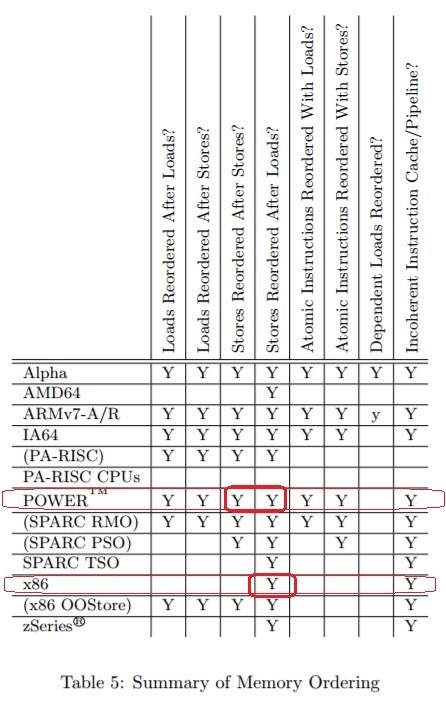
Какие переупорядочивания позволяют делать разные CPU при отсутствии assembler-барьеров между инструкциями. “Memory Barriers: a Hardware View for Software Hackers” Paul E. McKenney June 7, 2010 — Table 5: www.rdrop.com/users/paulmck/scalability/paper/whymb.2010.06.07c.pdf
Есть ещё одна особенность обмена данными между потоками, которая проявляется при взаимодействии 4 потоков или больше. Если хотя бы в одной из следующих операций не используется самый строгий барьер memory_order_seq_cst, то разные потоки могут видеть одни и те же изменения в разном порядке. Например:
Это возможно из-за аппаратных особенностей работы кэш-когерентного протокола, дополнительных Load/Store-буферов и топологии расположения ядер в процессорах. В этом случае некоторые два ядра могут увидеть изменения сделанные друг другом раньше, чем увидят изменения сделанные другими ядрами. Чтобы все потоки видели изменения в одном и том же порядке, т.е. имели single total order (C++11 § 29.3 (3)) – необходимо чтобы все операции (LOAD, STORE, RMW) выполнялись с барьером памяти memory_order_seq_cst: en.cppreference.com/w/cpp/atomic/memory_order
В следующем примере программа никогда не завершится с ошибкой assert(z.load() != 0); т.к. во всех операциях применяется самый строгий барьер памяти memory_order_seq_cst: coliru.stacked-crooked.com/a/52726a5ad01f6529
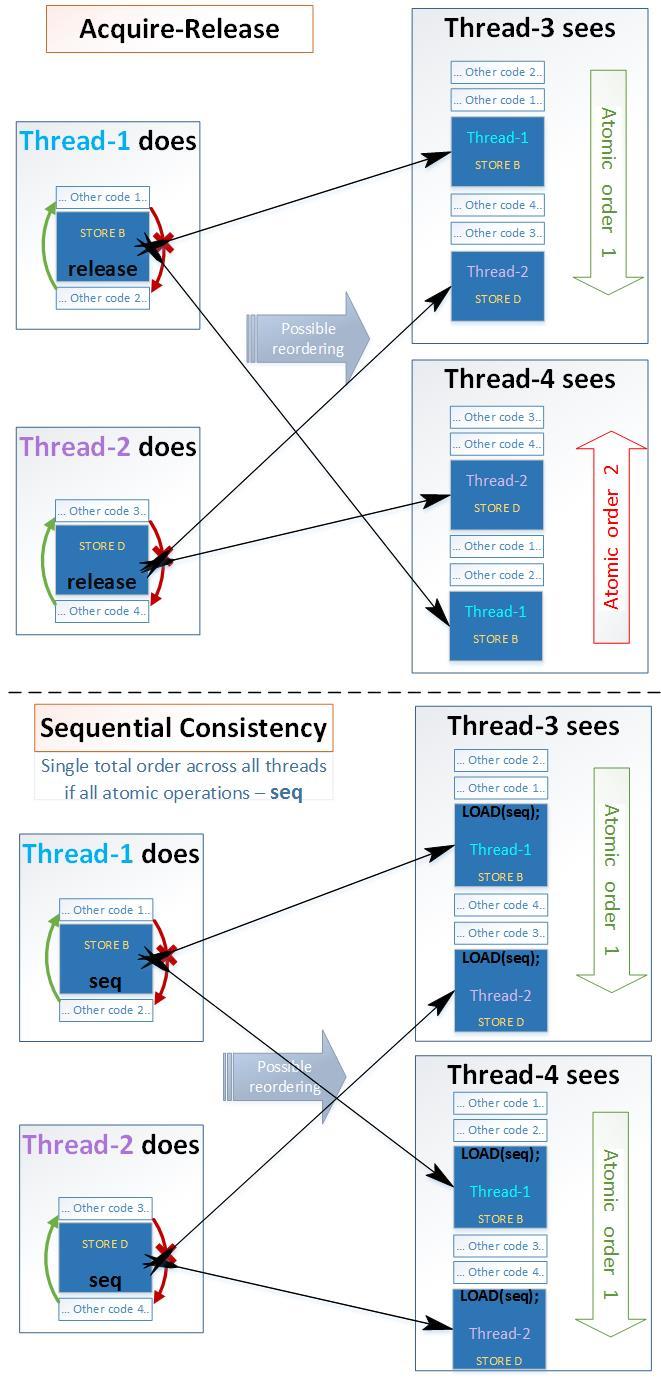
На рисунке покажем какое изменение порядка возможно для Acquire-Release семантики и для Sequential семантики на примере из 4-ех потоков:
Покажем, как применяются барьеры памяти для атомарных операций на примере реализации собственных активных блокировок: spin-lock и recursive-spin-lock.
Далее эти блокировки понадобятся нам для блокирования отдельных строк (row-lock) таблицы вместо блокирования всей таблицы (table-lock) – это повысит степень параллелизма и увеличит производительность, т.к. разные потоки смогут работать с разными строками параллельно, не блокируя всю таблицу.
Количество объектов синхронизации предоставляемых операционной системой может быть ограничено. Количество строк в таблице может составлять миллионы или миллиарды, многие ОС не позволяют создавать столько мьютексов. А количество spin-lock может быть любым, насколько это позволяет оперативная память – поэтому их можно использовать для блокирования каждой отдельной строки.
Фактически spinlock – это + 1 байт к каждой строке(row), или +17 байт при использовании recursive-spin-lock (1 байт для флага + 8 байт для счетчика рекурсии + 8 байт для номера потока thread_id).
Основное отличие recursive_spinlock от обычного spinlock в том, что recursive_spinlock может быть многократно заблокирован одним и тем же потоком, т.е. поддерживает рекурсивные вложенные блокировки. Точно так же отличаются std::recursive_mutex и std::mutex.
Пример вложенных блокировок:
Давайте разберемся как работает recursive_spinlock_t.
Если вы попробуете запустить этот код в компиляторе MSVC 2013, то получите очень сильное замедление из-за функции std::this_thread::get_id(): connect.microsoft.com/VisualStudio/feedback/details/1558211
Мы доработаем класс recursive_spinlock_t, чтобы он кешировал thread-id в переменной __declspec(thread) – это аналог thread_local из стандарта С++11. Этот пример покажет хорошую производительность и в MSVC 2013: [28] coliru.stacked-crooked.com/a/3090a9778d02f6ea
Это временное исправление для старого MSVC 2013, поэтому о красоте такого решения мы думать не будем.
Считается, что в большинстве случаев повторное (рекурсивное) блокирование мьютекса – это ошибка проектирования, но в нашем случае это может быть медленным, но рабочим кодом. Во-вторых все ошибаются, и при вложенных рекурсивных блокировках recursive_spinlock_t отработает заметно медленнее, а spinlock_t зависнет навечно – что лучше, решать вам.
В случае использования нашего потоко-безопасного указателся safe_ptr<T> – оба примера вполне логичны, но второй сработает только с recursive_spinlock:
Как известно, в новых стандартах C++ постепенно появлялись новые типы мьютексов: en.cppreference.com/w/cpp/thread

shared_mutex – это мьютекс позволяющий одновременно многим потокам читать одни и те же данные, если в этот момент нет потоков изменяющих эти данные. shared_mutex появился не сразу, т.к. шли споры о его производительности по сравнению с обычным std::mutex.
Классическая реализация shared_mutex со счетчиком количества читателей показывала преимущество в скорости только когда много читателей долго удерживали блокировку – т.е. когда долго читали. При коротких чтениях shared_mutex только замедлял программу и усложнял код.
Но все ли реализации shared_mutex столь медленные при коротких чтениях?
Основная причина медленной работы std::shared_mutex и boost::shared_mutex – это атомарный счетчик читателей. Каждый читающий поток инкрементирует счетчик при блокировании и декрементирует его при разблокировании. В итоге потоки постоянно гоняют между ядрами одну кэш-линию (а именно гоняют её exclusive-state (E)). По логике такой реализации, каждый читающий поток подсчитывает сколько всего сейчас читателей, но это абсолютно не важно для читающего потока, т.к. ему важно только, чтобы не было ни одного писателя. Причем, т.к. инкремент и декремент – это RMW операции, то они всегда генерируют очистку Store-Buffer (MFENCE x86_64) и на уровне x86_64 asm фактически соответствуют самой медленной семантике Sequential Consistency.
Попробуем решить эту проблему.
Есть тип алгоритмов, который классифицируется как write contention-free – когда нет ни одной ячейки памяти в которую могли бы писать более одного потока. А в более общем случае – нет ни одной кэш-линии в которую могли бы писать более одного потока. Чтобы наш shared-mutex при наличии только читателей классифицировался как write contention-free, необходимо, чтобы читатели не мешали друг другу – т.е. чтобы каждый читатель писал флаг (что он читает) в свою отдельную ячейку, и снимал флаг в этой же ячейке по окончанию чтения – без RMW-операций.
Write contention-free – это максимально производительная гарантия, которая производительнее, чем wait-free и чем lock-free.
Возможно, чтобы каждая ячейка располагалась в отдельной кэш-линии для исключения false-sharing, а возможно, и чтобы ячейки лежали плотно по 16 в одной кэш-линии – потеря производительности будет зависеть от CPU и количества потоков. Для устранения false-sharing — каждую переменную следует размещать в отдельной кэш-линии, для этого в C++17 существует коснтрукция alignas(std::hardware_destructive_interference_size), а в более ранних можно использовать процессор-зависимое решение char tmp[60]; (на x86_64 размер кэш-линии 64 байта):
Перед установкой флага, читатель проверяет есть ли писатель – т.е. есть ли эксклюзивная блокировка. А т.к. shared-mutex применяется в случаях, когда очень мало писателей, то все используемые ядра могут иметь копию этого значения у себя в кэш-L1 в shared-state (S) откуда за 3 такта получат значение флага писателя, пока он не изменится.
Для всех писателей, как обычно, есть один и тот же флаг want_x_lock – он означает, что в данный момент есть писатель. Потоки писатели его устанавливают и снимают, используя RMW-операции.
Но чтобы читатели не мешали друг другу, для этого они должны писать информацию о своих shared-блокировках в разные ячейки памяти. Выделим массив под эти блокировки, размер которого мы будем задавать параметром шаблона, по умолчанию равным 20. При первом вызове lock_shared() поток автоматически будет регистрироваться – занимая определенное место в этом массиве. Если потоков больше, чем размер массива, то остальные потоки при вызове lock_shared() будут вызывать эксклюзивную блокировку писателя. Потоки создаются редко, а время, затраченное операционной системой на их создание настолько велико, что время на регистрацию нового потока в нашем объекте будет ничтожно мало.
Удостоверимся, что нет очевидных ошибок – на примерах покажем, что все работает верно, а далее схематически докажем правильность нашего подхода.
Приведем пример такой быстрой разделяемой блокировки, в которой читатели не мешают друг другу: [30] coliru.stacked-crooked.com/a/b78467b7a3885e5b
Основная задача – добиться, чтобы в одно и тоже время могло быть только одно из двух состояний:
Схематически таблица совместимых состояний выглядит так.
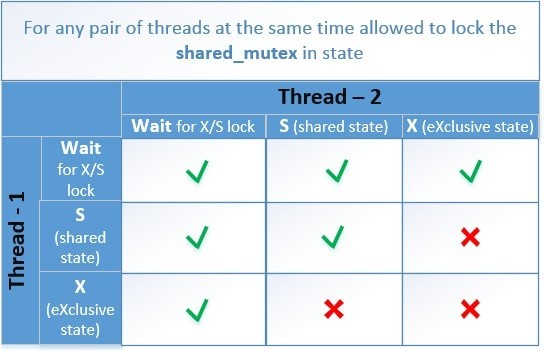
Рассмотрим алгоритм нашего contention_free_shared_mutex для случаев, когда 2 потока пытаются одновременно выполнить операции:
Поток-писатель T2 устанавливает флаг (want_x_lock = true), а затем ждет пока все потоки-читатели снимут флаги блокировок из своих ячеек.
Поток-писатель в нашей схеме имеет выше приоритет, чем читатель. И если они одновременно установили свои флаги блокировок, то поток-читатель следующей операцией проверяет есть ли поток-писатель (want_x_lock == true), и если есть, то читатель отменяет свою блокировку. Поток-писатель видит, что больше нет блокировок от читателей и успешно завершает функцию блокирования. Глобальный порядок этих блокировок соблюдается благодаря семантике Sequential Consistency (std::memory_order_seq_cst).
Схематически взаимодействие двух потоков (читателя и писателя) выглядит следующим образом.

В полном размере: habrastorage.org/getpro/habr/post_images/5b2/3a3/23b/5b23a323b6a1c9e13ade90bbd82ed98b.jpg
В обеих функциях lock_shared() и lock(), для обеих операций 1. и 2. используется std::memory_order_seq_cst — т.е. для этих операций гарантируется единый порядок для всех потоков (single total order).
Когда поток впервые обращается к нашей блокировке, то он регистрируется. А когда этот поток завершается или блокировка удаляется, то должна происходить отмена регистрации.
Но теперь давайте посмотрим, что будет, если с нашим мьютексом поработают 20 потоков, затем эти потоки завершатся, и попробуют зарегистрироваться новые 20 потоков, при условии, что массив блокировок равен 20: [33] coliru.stacked-crooked.com/a/f1ac55beedd31966
Как видно первые 20 потоков успешно зарегистрировались, но следующие 20 потоков зарегистрироваться не смогли (register_thread = -1) и вынуждены были использовать эксклюзивную блокировку писателя, несмотря на то что предыдущие 20 потоков уже удалились и уже не используют блокировку.
Чтобы решить эту проблему – добавим автоматическую отмену регистрации потока, когда поток удаляется. Если поток работал с множеством таких блокировок, то в момент завершения потока должна произойти отмена регистрации во всех таких блокировках. А если в момент удаления потока есть блокировки, которые на данный момент уже удалены, то не должно произойти ошибки из-за попытки отменить регистрацию в несуществующей блокировке.
Пример: [34] coliru.stacked-crooked.com/a/4172a6160ca33a0f
Как видим сначала зарегистрировались 20 потоков, а после их удаления и создания новых 20 потоков, они также смогли зарегистрироваться – под теми же номерами register_thread = 0 – 19 (смотрите вывод(output) примера).
Теперь покажем, что даже если потоки работали с блокировкой, а затем блокировка была удалена, то при завершении потоков не произойдет ошибки из-за попытки отменить регистрацию в несуществующем объекте блокировки: [35] coliru.stacked-crooked.com/a/d2e5a4ba1cd787da
Мы установили таймеры так, чтобы создались 20 потоков, выполнили чтение используя нашу блокировку и заснули на 500ms, а в это время через 100ms удалился объект contfree_safe_ptr содержащий внутри себя нашу блокировку contention_free_shared_mutex, и только после этого проснулись 20 потоков и завершились. При завершении их не произошло ошибки из-за отмены регистрации в удаленном объекте блокировки.
Как небольшое дополнение сделаем поддержку MSVS2013, чтобы владельцы старого компилятора тоже смогли ознакомиться с примером. Добавим упрощенную поддержку регистрации потоков, но без возможности отмены регистрацию потока.
Конечный результат покажем в виде примера, в котором учтены все перечисленные выше мысли.
Пример: [36] coliru.stacked-crooked.com/a/0a1007765f13aa0d
Выше мы провели тесты, которые показали отсутствие очевидных ошибок. Но чтобы доказать работоспособность необходимо создать схему возможных изменений порядка операций и возможных состояний переменных.
Эксклюзивная блокировка lock() / unlock() почти такая же простая, как и в случае с recursive_spinlock_t, поэтому её детально рассматривать не будем.
Конкуренцию потока-читателя за lock_shared() и потока писателя за lock() мы детально рассмотрели выше.
Сейчас основная задача показать, что lock_shared() во всех случаях использует как минимум Acquire-semantic, а unlock_shared() во всех случаях использует как минимум Release-semantic. Но это не обязательное условие при повторном рекурсивном блокировкии/разблокировании.
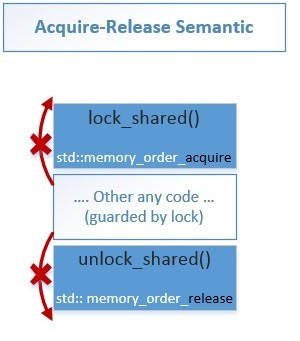
Теперь покажем, как эти барьеры реализуются в нашем коде.
Схематически барьеры для lock_shared() – красными перечеркнутыми стрелками показаны направления в которых изменение порядка запрещено:

Схематически барьеры для unlock_shared():

В полный размер: hsto.org/files/065/9ce/bd7/0659cebd72424256b6254c57d35c7d07.jpg
В полный размер с размеченными условными переходами: hsto.org/files/fa7/4d2/2b7/fa74d22b7cda4bf4b1015ee263cad9ee.jpg
Приведем также блок-схему этой же самой функции lock_shared()
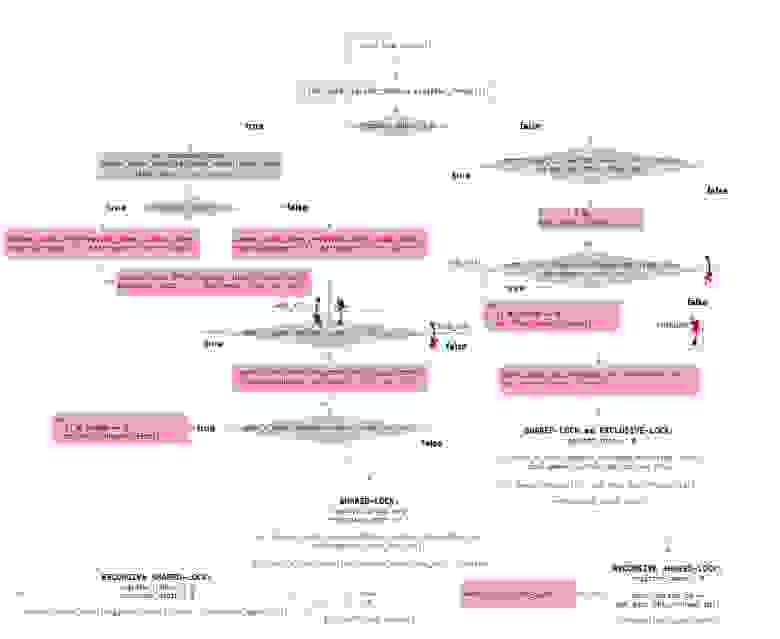
Картинка в полном размере: hsto.org/files/c3a/abd/4e7/c3aabd4e7cfa4e9db55b2843467d878f.jpg
В овальных блоках обозначены строгие последовательности исполнения операций:
Зеленым цветом обозначены изменения, которые могут исполняться в любом порядке, т.к. эти изменения не блокируют наш «shared-mutex», а только увеличивают счетчик вложенности рекурсии – эти изменения важны только для локального использования. Т.е. эти зеленые операции не являются фактическим входом в блокировку.
Т.к. выполняются 2 условия – то считается, что все необходимые side-effects от многопоточности учтены:
Далее корректность алгоритма может быть проверена простым сопоставлением результатов данных операций и их последовательности с логикой работы алгоритма.
Все остальные функции нашей блокировки «contention_free_shared_mutex» более очевидны с точки зрения логики многопоточного исполнения.
Так же отмечу, что при повторном (рекурсивном) блокировании, атомарным операциям не обязательно иметь барьер std::memory_order_acquire (как показано на рисунке), достаточно установить std::memory_order_relaxed, потому что это не фактический вход в блокировку — мы уже находимся в блокировке. Но это не добавляет большой скорости и может усложнить понимание.
Покажем пример использования contention_free_shared_mutex<> на C++ в качестве высоко-оптимизированного shared_mutex.
Скачать этот код для Linux (GCC 6.3.0) и Windows (MSVS 2015/13) можно по ссылке: github.com/AlexeyAB/object_threadsafe/tree/master/contfree_shared_mutex
Чтобы скомпилировать данный пример на Clang++ 3.8.0 под Linux вы должны изменить Makefile.
Этот код в онлайн компиляторе: coliru.stacked-crooked.com/a/11c191b06aeb5fb6
Как вы видите наш мьютекс sf::contention_free_shared_mutex<> используется точно таким же образом, как и стандартный std::shared_mutex.
Приведем пример тестирования на 16 потоках для одного серверного процессора Intel Xeon E5-2660 v3 2.6 GHz. В первую очередь нас интересует голубая и фиолетовая линии:
Исходный код данного теста: github.com/AlexeyAB/object_threadsafe/tree/master/bench_contfree
Командная строка для запуска:
numactl --localalloc --cpunodebind=0 ./benchmark 16
Если у вас только один CPU на материнской плате, то запускайте: ./benchmark
Производительность различных блокировок для разного соотношения блокировок чтения (shared-lock) и блокировок записи (exclusive-lock).
(в случае std::mutex – всегда работает блокировка exclusive-lock)

Performance (the bigger – the better), MOps — millions operations per second
Наша блокировка «contention-free shared-mutex» работает для любого количества потоков: для первых 36 потоков как contention-free, а для последующих как exclusive-lock. Как видим из графиков, даже «exclusive-lock» std::mutex работает быстрее, чем std::shared_mutex при 15% изменений.
Количество потоков 36 для contention-free задается параметром шаблона и может быть изменено.
Теперь покажем медианную задержку для разного соотношения типа блокировок: чтения (shared-lock) и записи (exclusive-lock).
В коде теста main.cpp необходимо установить: const bool measure_latency = true;
Командная строка для запуска:
numactl --localalloc --cpunodebind=0 ./benchmark 16
Если у вас только один CPU на материнской плате, то запускайте: ./benchmark
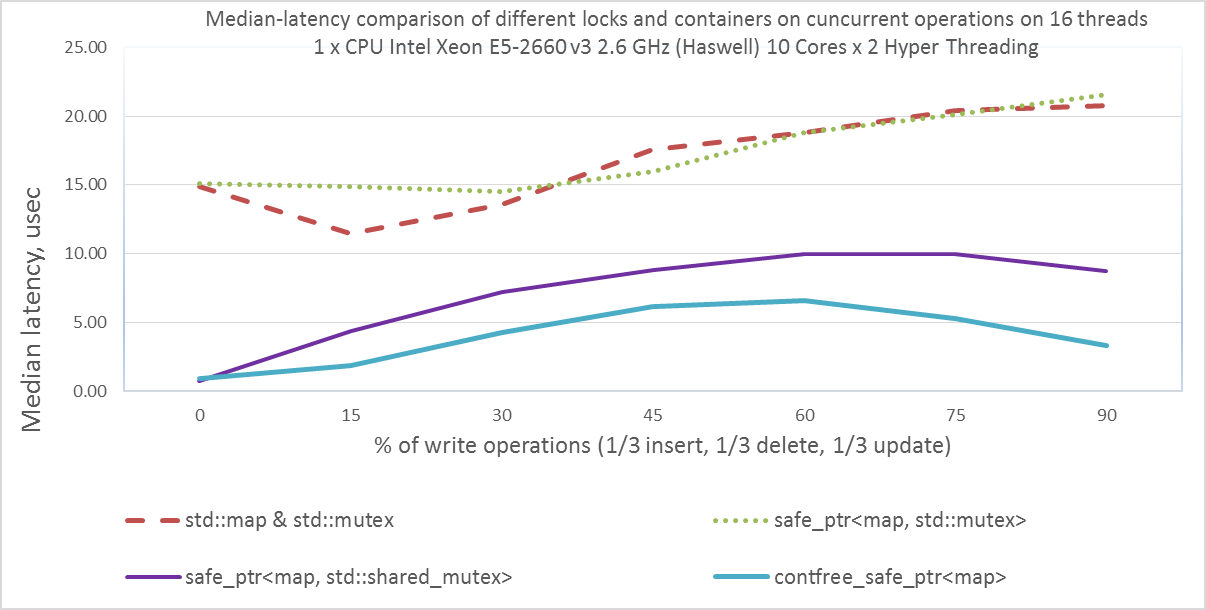
Median-latency (the lower – the better), microseconds
Таким образом мы создали разделяемую блокировку, в которой читатели не мешают друг другу во время блокирования и разблокирования, в отличие от std::shared_timed_mutex и boost::shared_mutex. Но у нас для каждого потока дополнительно выделяется: 64 байта в массиве блокировок + 24 байта занимает структура unregister_t для отмены регистрации + элемент, указывающий на эту структуру из hash_map. В сумме около 100 байт на поток.
Более глубокая проблема – это возможность масштабироваться. Например, если у вас есть 8 CPU (Intel Xeon Processor E7-8890 v4) по 24 ядра (по 48 потоков HyperThreading), то это в сумме 384 логических ядра. Каждый поток-писатель перед записью должен прочитать по 24576 байт (по 64 байт от каждого из 384 ядер), но читать их можно параллельно, это конечно лучше, чем ждать пока одна кэш-линия последовательно перейдет от каждого из 384 потока к каждому, как в обычных std::shared_timed_mutex и boost::shared_mutex (при любом типе блокировки unique/shared). Но распараллеливание на 1000 ядер и более обычно реализуется через другой подход, а не через вызов атомарной операции на обработку каждого сообщения. Все обсуждаемые выше варианты: атомарные операции, активные блокировки, lock-free структуры данных – это все необходимо для низких задержек (0,5 – 5 usec) отдельных сообщений.
Для высоких показателей количества операций в секунду, т.е. для высокой производительности системы в целом и масштабируемости на десятки тысяч логических ядер используют подходы массового параллелизма, «hide latency» и «batch processing» — пакетной обработки, когда сообщения сортируются (для map) или группируются (для hash_map) и сливаются с уже имеющимся отсортированным или сгруппированным массивом за 50 – 500 usec. В итоге у каждой операции задержка в 10-100 раз больше, но эти задержки происходят в одно и тоже время в огромном количестве потоков, в результате происходит сокрытие задержек «hide latency» за счет использования «Fine-grained Temporal multithreading».
Если предположим: у каждого сообщения задержка в 100 раз больше, но сообщений обрабатывается в 10000 раз больше. Это на единицу времени в 100 раз эффективней. Такие принципы применяются при разработке на GPU. Возможно в следующих статьях мы разберем это подробней.
Далее мы покажем как ускорить работу contfree_safe_ptr<std::map> до уровня сложных и оптимизированных lock-free структур данных аналогичных по функциональности std::map<>, например: SkipListMap и BronsonAVLTreeMap из библиотеки libCDS (Concurrent Data Structures library): github.com/khizmax/libcds
И такую многопоточную производительность мы сможем получить для любого вашего изначально потоко-небезопасного класса T используемого как contfree_safe_ptr<T>. Нас интересуют оптимизации повышающие производительность на ~1000%, поэтому мы не будем уделять внимание слабым и сомнительным оптимизациям.
Три связанные статьи:
- Делаем любой объект потокобезопасным
- Ускоряем std::shared_mutex в 10 раз
- Потокобезопасный std::map с производительностью lock-free map
→ Моя статья на английском
→ Примеры и тесты из всех трех статей
Высокая производительность lock-based структур данных
contfree_safe_ptr<T> — это класс safe_ptr<T, contention_free_shared_mutex>, где contention_free_shared_mutex – это собственный оптимизированный shared-mutex. А safe_ptr — это потокобезопасный указатель из прошлой статьи.
По порядку покажем, как реализовать собственный высокопроизводительный contention-free shared-mutex, почти не конфликтующий на чтениях. Реализуем собственные активные блокировки spinlock и recursive-spinlock для блокирования строк(rows) на операциях update. Создадим RAII-блокирующие указатели, чтобы избежать затрат на многократное блокирование. Приведем результаты тестов производительности.
И как бонус «Just for fun» покажем, как реализовывать собственный класс упрощенного секционированного типа partitioned_map, ещё сильнее оптимизированного для многопоточности, состоящего из нескольких std::map, по аналогии с partition table из СУБД, когда границы каждой секции известны изначально.
Основы атомарных операций
Рассмотрим основы многопоточности, атомарности и барьеров памяти. Если мы изменяем одни и те же данные из множества потоков, т.е. если мы запускаем функцию thread_func() одновременно в нескольких потоках:
int a;
void thread_func() { a = a + 1; } // wrong: data-raceТо каждый поток вызывающий функцию thread_func() прибавляет 1 к обычной разделяемой переменной int a; Такой код в общем случае не будет потоко-безопасным, т.к. составные операции (RMW – read-modify-write) над обычными переменными состоят из множества маленьких операций, между которыми другой поток может изменить данные. Операция a = a+1; состоит как минимум из трех мини-операций:
- Загрузить значение переменной «a» в регистр процессора
- Прибавить 1 к значению в регистре
- Записать значение регистра обратно в переменную «a»
Например, если int a=0; и 2 потока выполнят операцию a=a+1; то в результате должно быть a=2; Но может произойти следующее – пошагово:
int a = 0; // register1 = ?, register2 = ?, a = 0
Thread 1: register1 = a; // register1 = 0, register2 = ?, a = 0
Thread 2: register2 = a; // register1 = 0, register2 = 0, a = 0
Thread 1: register1++; // register1 = 1, register2 = 0, a = 0
Thread 2: register2++; // register1 = 1, register2 = 1, a = 0
Thread 1: a = register1; // register1 = 1, register2 = 1, a = 1
Thread 2: a = register2; // register1 = 1, register2 = 1, a = 1Два потока прибавили к одной и той же глобальной переменной +1, но в итоге переменная a = 1 – такая проблема называется Data-Races.
Чтобы избежать этой проблемы есть 3 способа:
- Использовать атомарные инструкции над атомарными переменными – но есть один минус, количество атомарных функций очень мало – поэтому реализовать сложную логику с помощью них затруднительно: en.cppreference.com/w/cpp/atomic/atomic
- Разрабатывать собственные сложные lock-free алгоритмы для каждого нового контейнера.
- Использовать блокировки (std::mutex, std::shared_timed_mutex, spinlock…) – они допускают к заблокированному коду по очереди по 1 потоку, поэтому проблемы data-races не возникает и мы можем использовать сколь угодно сложную логику, используя любые обычные потоко-небезопасные объекты.
Для std::atomic<int> a; если изначально a=0; и 2 потока выполняют операцию a+=1; то результат всегда будет a=2;
std::atomic<int> a;
void thread_func() { a += 1; } // correct: no data-raceСледующее всегда будет происходить на процессорах x86_64 (пошагово):
std::atomic<int> a = 0; // register1 = ?, register2 = ?, a = 0
Thread 1: register1 = a; // register1 = 0, register2 = ?, a = 0
Thread 1: register1++; // register1 = 1, register2 = ?, a = 0
Thread 1: a = register1; // register1 = 1, register2 = ?, a = 1
Thread 2: register2 = a; // register1 = 1, register2 = 1, a = 1
Thread 2: register2++; // register1 = 1, register2 = 2, a = 1
Thread 2: a = register2; // register1 = 1, register2 = 2, a = 2На процессорах с поддержкой LL/SC, например на ARM или PowerPC, будут происходить другие шаги, но с тем же самым результатом a = 2.
Атомарные переменные введены в стандарт C++11: en.cppreference.com/w/cpp/atomic/atomic
Функции члены шаблона класса std::atomic<> всегда являются атомарными.
Приведем 3 фрагмента правильного кода идентичного по смыслу:
1. Пример:
std::atomic<int> a;
a = 20;
a += 50;2. Это идентично примеру 1:
std::atomic<int> a;
a.store( 20 );
a.fetch_add( 50 );3. И это идентично примеру 1:
std::atomic<int> a;
a.store( 20, std::memory_order_seq_cst );
a.fetch_add( 50, std::memory_order_seq_cst );Это значит, что для std::atomic:
- load() и store() – тоже самое что operator T и operator= и
- fetch_add() и fetch_sub() – тоже самое что operator+= и operator-=
- Sequential Consistency (std::memory_order_seq_cst) – это барьер памяти по умолчанию (самый строгий и надежный, но и самый медленный относительно других).
Отметим отличия std::atomic и volatile в C++11: www.drdobbs.com/parallel/volatile-vs-volatile/212701484
Здесь есть 5 основных отличий:
- Оптимизации: Для std::atomic<T> a; возможны две оптимизации, которые невозможны для volatile T a;
• Оптимизация слияния: a = 10; a = 20; может быть заменена компилятором на a = 20;
• Оптимизация замены константой: a = 1; local = a; может быть заменена компилятором a = 1; local = 1; - Переупорядочивание: Операции над std::atomic<T> a; могут ограничивать переупорядочивание вокруг себя для операций с обычными переменными и операций с другими атомарными переменными в соответствии с используемым барьером памяти std::memory_order_… Напротив, volatile T a; не влияет на порядок обычных переменных (non-atomic/non-volatile), но обращения ко всем volatile-переменным всегда сохраняют строгий взаимный порядок, т.е. порядок выполнения любых двух volatile-операций не может быть изменен компилятором, но не процессором.
- Spilling: Барьеры памяти std::memory_order_release, std::memory_order_acq_rel, std::memory_order_seq_cst указываемые для операций над std::atomic<T> a; инициируют spilling всех обычных переменных до исполнения атомарной операции. Т.е. эти барьеры выгружают обычные переменные из регистров процессора в оперативную память/кэш, за исключением случаев, когда компилятор может на 100% гарантировать, что эта локальная переменная не может использоваться в других потоках.
- Атомарность / выравнивание: Операции над std::atomic<T> a; видны другим потокам либо полностью, либо не видны вовсе. Для интегральных типов T это достигается за счет выравнивания расположения атомарных переменных в памяти компилятором — по крайней мере переменная должна лежать в одной кэш-линии, таким образом, атомарная переменная может быть изменена или прочитана всего одной операцией CPU. И наоборот, компилятор не гарантирует выравнивание volatile-переменных и атомарность операций над ними. Volatile-переменные обычно используются для доступа к памяти устройств или в других случаях, но не для обмена данными между потоками. API драйвера устройства возвращает указатель на volatile-переменные, и при необходимости этот API обеспечивает выравнивание.
- Атомарность RMW-операций (read-modify-write): Операции над std::atomic<T> a; такие как ( ++, --, +=, -=, *=, /=, CAS, exchange) выполняются атомарно, т.е. если два потока выполняют операцию ++a; то эта переменная гарантированно будет увеличена на 2. Это достигается за счет блокировки кэш-линий (x86_64) или за счет маркировки отсутствия изменений в кэш-линии на процессорах поддерживающих LL/SC (ARM, PowerPC) на все время выполнения RMW-операции. Volatile-переменные не обеспечивают атомарность составных RMW-операций.
Есть и одно общее правило для переменных std::atomic и volatile: каждая операция чтения или записи всегда обращается к памяти/кэшу, т.е. значения никогда не кэшируются в регистрах процессора.
Так же отметим, что для обычных(ordinary) переменных и объектов (non-atomic/non-volatile) – возможны любые оптимизации и любые переупорядочивания независимых инструкций относительно друг друга компилятором или процессором.
Напомним, что операции записи в память над atomic-переменными с барьерами памяти std::memory_order_release, std::memory_order_acq_rel и std::memory_order_seq_cst гарантируют spilling (запись из регистров в память) сразу всех non-atomic/non-volatile переменных находящихся на данный момент в регистрах процессора: en.wikipedia.org/wiki/Register_allocation#Spilling
Изменение порядка выполнения инструкций
Компилятор и процессор меняют порядок инструкций для оптимизации программы и повышения производительности.
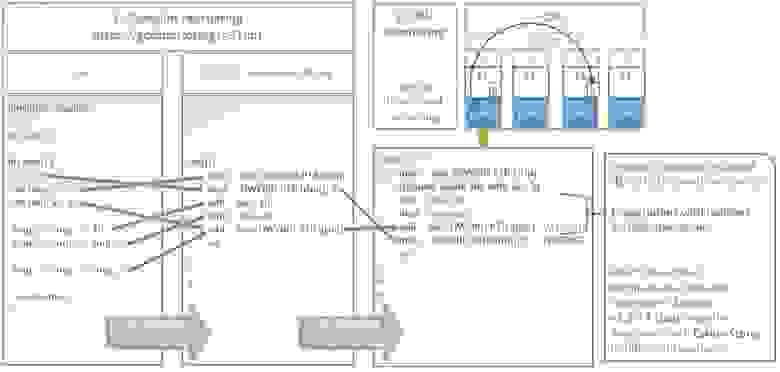
Приведем пример оптимизаций, которые делают компилятор GCC и процессор x86_64: godbolt.org/g/n91hpt

Картинка в полном размере:
hsto.org/files/3d2/18b/c7b/3d218bc7b3584f82820f92077096d7a0.jpg
Какие происходят оптимизации на картинке:
- Переупорядочивание компилятором GCC 7.0:
• Меняет местами запись в память b = 5; и загрузку из памяти в регистр int tmp_c = c;. Это позволяет как можно раньше запросить значение «c», а пока процессор ожидает выполнение этой долгой операции, конвейер (pipeline) процессора позволяет параллельно запустить выполнение операции b = 5;, т.к. эти 2 операции не зависят друг от друга.
• Совмещает загрузку из памяти в регистр int tmp_a = a; и операцию сложения tmp_c = tmp_c + tmp_a; – в результате вместо двух инструкций получается одна add eax, a[rip] - Переупорядочивание процессором x86_64:
Процессор может менять местами фактическую запись в память mov b[rip], 5 и чтение из памяти совмещенное со сложением add eax, a[rip].
Инициировав запись в память инструкцией mov b[rip], 5 происходит следующее – сначала значение 5 и адрес b[rip] помещаются в аппаратную очередь Store-buffer, ожидается инвалидация кэш-линий содержащих адрес b[rip] во всех ядрах процессора и получение от них ответа, затем CPU-Core-0 устанавливает статус «eXclusive» для кэш-линии содержащей b[rip], и только после этого происходит фактическая запись значения 5 из Store-buffer в эту кэш-линию по адресу b[rip]. Подробнее о протоколах кэш-когерентности на x86_64 MOESI/MESIF – изменения в котором видны всем ядрам моментально: en.wikipedia.org/wiki/MESIF_protocol
Чтобы не ждать все это время – сразу после того как 5 помещено в Store-Buffre, не дожидаясь фактической записи в кэш, мы можем начать выполнять следующие инструкции: чтение из памяти или операции с регистрами. Именно так поступает процессор x86_64.
Intel 64 and IA-32 Architectures Software Developer’s Manual Volume 3 (3A, 3B, 3C & 3D): System Programming Guide: www-ssl.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-software-developer-system-programming-manual-325384.pdf
8.2.3.4 Loads May Be Reordered with Earlier Stores to Different Locations
The Intel-64 memory-ordering model allows a load to be reordered with an earlier store to a different location. However, loads are not reordered with stores to the same location.
Процессоры семейства x86_64 имеют strong memory model. А процессоры имеющие weak memory model, например, PowerPC и ARM v7 / v8 могут выполнять ещё больше переупорядочиваний.
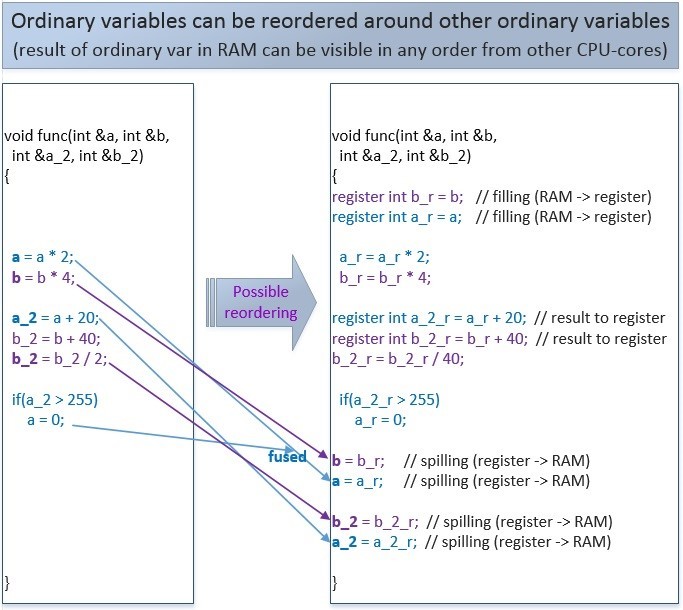
Приведем примеры возможного переупорядочивание записи в память обычных ordinary-переменных, volatile-переменных и atomic-переменных.
Переупорядочивание обычных переменных:
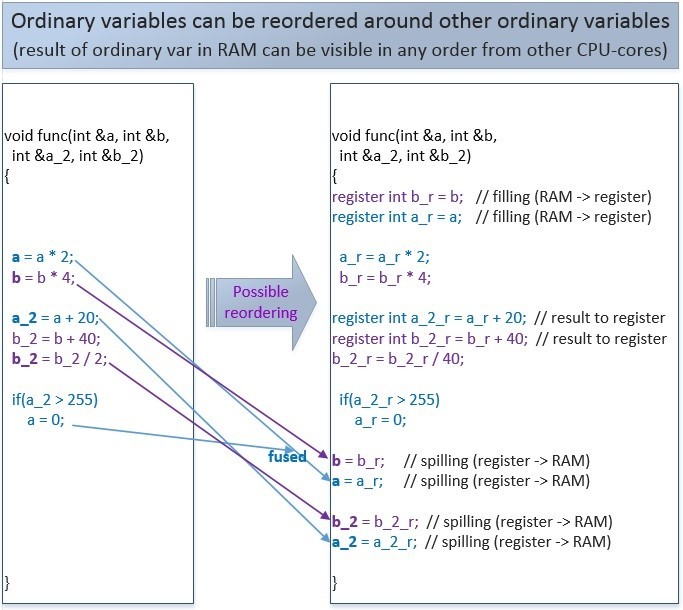
Этот код с обычными переменными может быть переупорядочен компилятором или процессором, т.к. в рамках одного потока его смысл не изменяется. Но в рамках множества потоков такие переупорядочивания могут повлиять на логику программы.
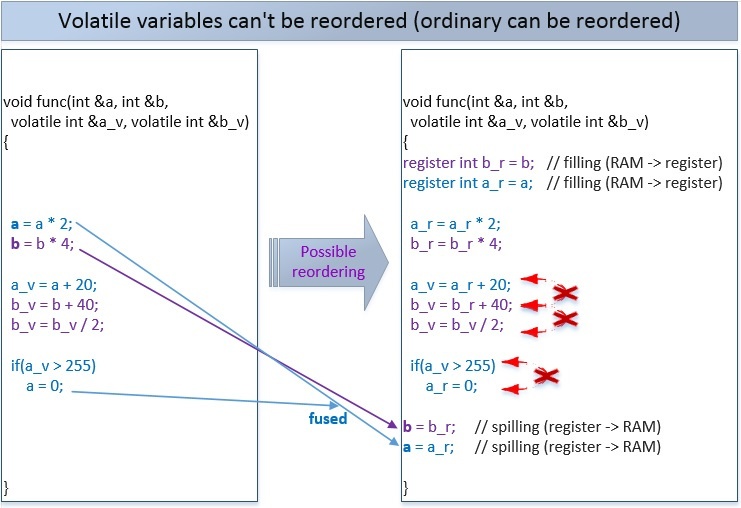
Если 2 переменных будут volatile, то возможны следующие переупорядочивания. Компилятор не может переупорядочить операции над volatile-переменными во время компиляции, но компилятор позволяет процессору выполнять это переупорядочение во время выполнения.
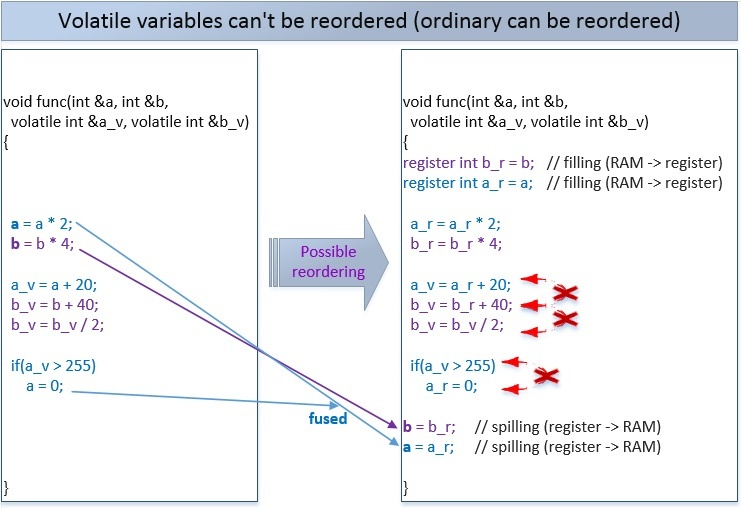
Чтобы предотвратить все или только некоторые из таких переупорядочиваний – существуют атомарные операции (напомним, что по умолчанию atomic-операции используют самый строгий барьер памяти std::memory_order_seq_cst):

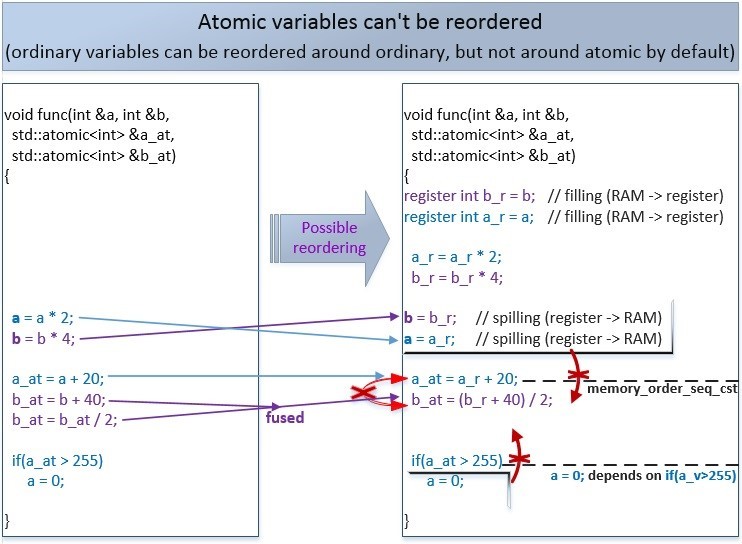
Другой поток может увидеть изменения переменных в памяти именно в таком измененном порядке.
Если мы не указываем барьер памяти для атомарной операции, то по умолчанию используется самый строгий барьер std::memory_order_seq_cst, и никакие атомарные или не атомарные операции не могут переупорядочиваться с такими операциями (но есть исключения – которые мы рассмотрим дальше).
В приведенном выше случае, сначала идет запись в обычные переменные a и b, а затем в атомарные-переменные a_at и b_at, и этот порядок не может измениться. Так же запись в память b_at не может произойти раньше, чем запись в память a_at. А вот запись в переменные a и b могут переупорядочиваться относительно друг друга.
Когда мы говорим «могут переупорядочиваться» — это значит могут, но не обязательно. Это зависит от того как решит оптимизировать код C++-компилятор во время компиляции или CPU во время выполнения.
Ниже мы рассмотрим более слабые барьеры памяти, которые позволяют переупорядочиваться инструкциям в разрешенных направлениях – это позволяет компилятору и процессору лучше оптимизировать код и больше повышать производительность.
Барьеры переупорядочивания операций обращения к памяти
Модель памяти стандарта C++11 предоставляет нам 6 типов барьеров памяти, которые соответствуют возможностям современных CPU для внеочередного исполнения операций (speculative execution), используя их мы не полностью запрещаем изменение порядка, а только в необходимых направлениях. Это оставляет возможность компилятору и процессору максимально оптимизировать код. А запрещенные направления переупорядочивания позволяют сохранить корректность нашего кода. en.cppreference.com/w/cpp/atomic/memory_order
enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
};- memory_order_consume. Сразу заметим, что барьер memory_order_consume мы практически не будем использовать, т.к. в стандарте есть сомнения о целесообразности его использования – цитата из стандарта: www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606.pdf
§29.3
(1.3) — memory_order_consume: a load operation performs a consume operation on the affected memory location. [ Note: Prefer memory_order_acquire, which provides stronger guarantees than memory_order_consume. Implementations have found it infeasible to provide performance better than that of memory_order_acquire. Specification revisions are under consideration. — end note ] - memory_order_acq_rel. Так же заметим, что барьер memory_order_acq_rel используется только для атомарных составных операций RMW (Read-Modify-Write) таких как: compare_exchange_weak()/_strong(), exchange(), fetch_(add, sub, and, or, xor) или соответствующих им операторов: en.cppreference.com/w/cpp/atomic/atomic
Остальные 4 барьера памяти могут использоваться для любых операций, за исключением: acquire – не используется для store(), а release — не используется для load().
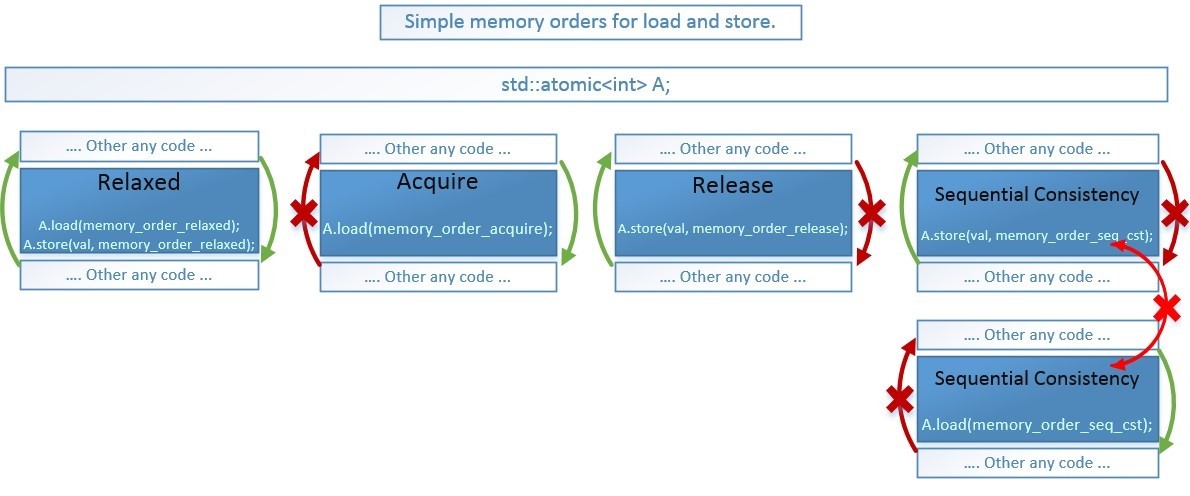
В зависимости от выбранного барьера памяти – компилятору и процессору запрещается перемещать исполняемый код относительно барьера в разных направлениях.
Теперь покажем, что именно обозначают данные стрелочки – покажем что с чем может меняться местами, а что не может:
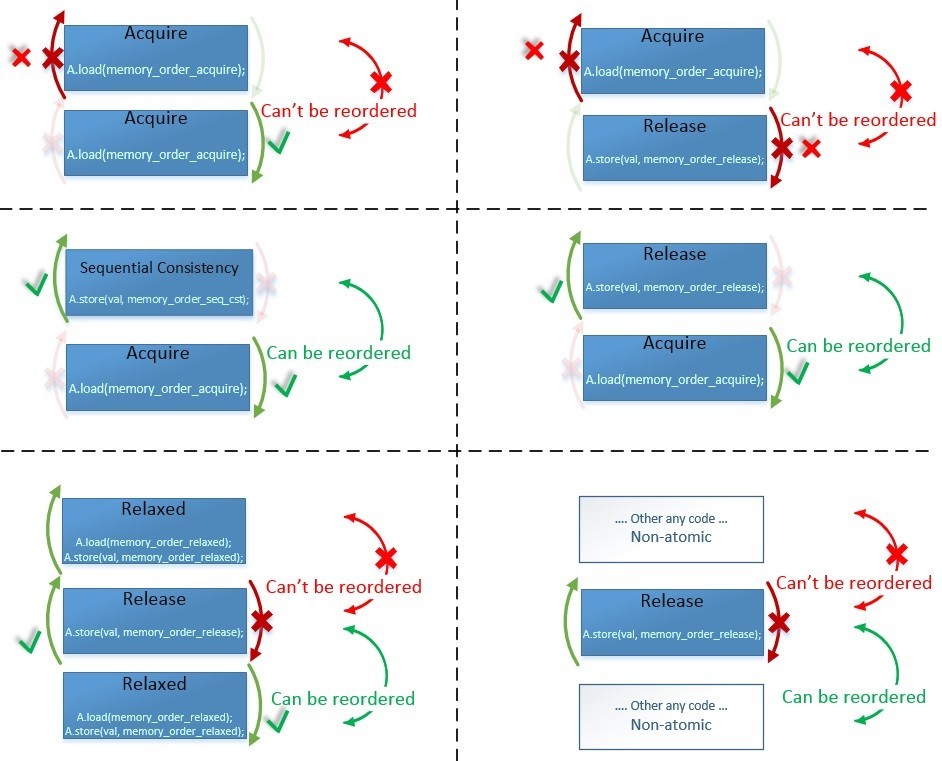
Чтобы 2 инструкции могли поменяться местами – необходимо, чтобы барьеры обеих этих инструкций разрешали такой обмен. Т.к. «Other any code» – это обычные неатомарные переменные у которых нет барьеров, то они разрешают любые изменения порядка. На левом-нижнем примере Relaxed-Release-Relaxed, как вы видите – возможность изменения порядка одних и тех же барьеров памяти зависит от того в какой последовательности они идут.
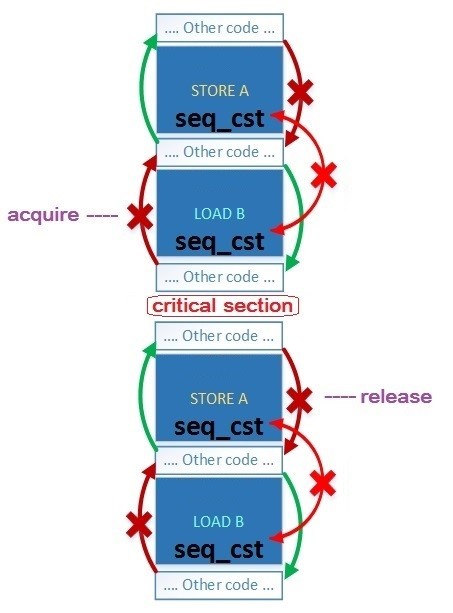
Давайте рассмотрим, что означают эти барьеры памяти и какие преимущества они дают нам на примере реализации простейшей блокировки «spin-lock», которая требует самую распространенную семантику переупорядочивания Acquire-Release. Spin-lock – это блокировка по способу использования похожая на std::mutex.
Для начала мы реализуем концепцию spin-lock непосредственно в теле нашей программы. А потом уже реализуем отдельный класс spin-lock. Для реализации блокировок (mutex, spinlock…) необходимо использовать Acquire-Release семантику, C++11 Standard § 1.10.1 (3): www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606.pdf
… For example, a call that acquires a mutex will perform an acquire operation on the locations comprising the mutex. Correspondingly, a call that releases the same mutex will perform a release operation on those same locations. Informally, performing a release operation on A forces prior side effects on other memory locations to become visible to other threads that later perform a consume or an acquire operation on A.
Основной смысл Acquire-Release семантики в том, что: поток-2 «Thread-2» после выполнения операции flag.load(std::memory_order_acquire) должен увидеть все изменения любых переменных/структур/классов (даже не атомарных), которые были сделаны потоком-1 «Thread-1» до выполнения им операции flag.store(0, std::memory_order_release).
Основной смысл блокировок (mutex, spinlock…) – это создание участка кода, который может исполняться только одним потоком в одно и тоже время, т.е. не может исполняться двумя и более потоками параллельно. Такой участок кода называется – критической секцией. Внутри неё можно использовать любой обычный код, в том числе без std::atomic.
Барьеры памяти (memory fences) – препятствуют оптимизации программы компилятором, чтобы ни одна операция из критической секции не вышла за её пределы.
Поток который первым захватывает блокировку – исполняет этот блок кода, а остальные потоки ждут в цикле (возможно временно засыпая). Когда первый поток отпустил блокировку, то процессор решает какой следующий из ожидающих потоков захватит её. И так далее.
Приведем 2 идентичных по смыслу примера:
- используя std::atomic_flag:[19] coliru.stacked-crooked.com/a/1ec9a0c2b10ce864
- используя std::atomic<int>:[20] coliru.stacked-crooked.com/a/03c019596b65199a
Пример-1 предпочтительнее, поэтому для него схематически покажем смысл использования барьеров памяти – сплошным синим цветом показаны атомарные операции:
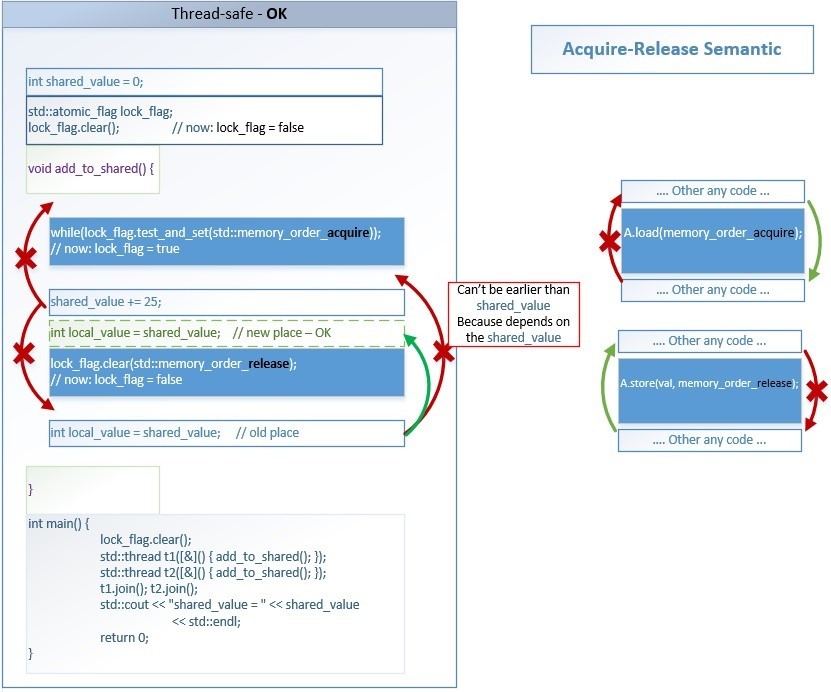
[19] coliru.stacked-crooked.com/a/1ec9a0c2b10ce864
Смысл барьеров очень простой – оптимизатору компилятора запрещается перемещать инструкции из критической секции наружу:
- Ни одна инструкция, расположенная после memory_order_acquire не может быть исполнена раньше него.
- Ни одна инструкция, расположенная до memory_order_release не может быть исполнена позднее него.
Любые другие изменения порядка исполнения независимых инструкций могут быть выполнены компилятором (compile-time) или процессором (run-time) – в целях оптимизации производительности.
Например, строка int new_shared_value = shared_value; может быть выполнена до lock_flag.clear(std::memory_order_release);. Такое переупорядочивание приемлемо и не создает data-races, т.к. весь код, который обращается к общим для множества потоков данным всегда заключен внутри двух барьеров acquire и release. А снаружи находится код, который работает только с локальными для потока данными – и не важно в каком порядке он будет выполнен. Локальные для потока зависимости всегда сохраняются также, как это происходит при однопоточном исполнении, поэтому int new_shared_value = shared_value; не может быть выполнен раньше, чем shared_value += 25;
Так что же запрещают, и что разрешают барьеры acquire-release для критической секции:
- Любой операции находящейся внутри критической секции запрещено исполняться вне критической секции.
- Любой операции находящейся снаружи критической секции разрешено исполняться внутри критической секции (если нет дополнительных барьеров памяти).
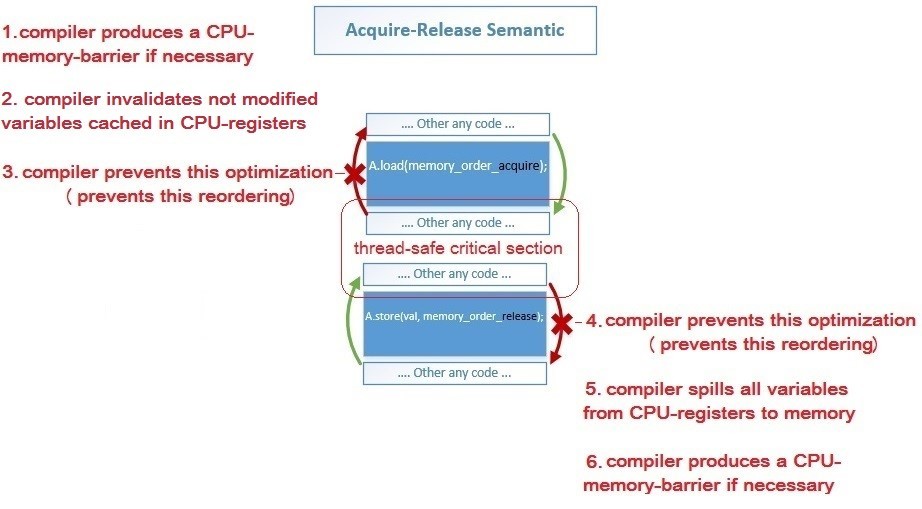
Какие конкретно действия выполняет компилятор на std::memory_order:
- 1, 6: Компилятор генерирует Assembler-инструкции acquire-барьера для load-операции и release-барьера для store-операции, если эти барьеры необходимы для данной архитектуры процессора
- 2: Компилятор отменяет предыдущее кэширование переменных в регистрах процессора, чтобы заново загрузить значения этих переменных изменённые другим потоком – после операции load(acquire)
- 5: Компилятор сохраняет значения всех переменных из регистров процессора в память, чтобы они стали видны другим потокам, т.е. выполняет spilling (link) – до store(release)
- 3, 4: Компилятор предотвращает изменение порядка инструкций оптимизатором в запрещенных направлениях – обозначены красными стрелками
А теперь давайте посмотрим, чтобы получилось, если бы мы использовали Relaxed-Release семантику вместо Acquire-Release:
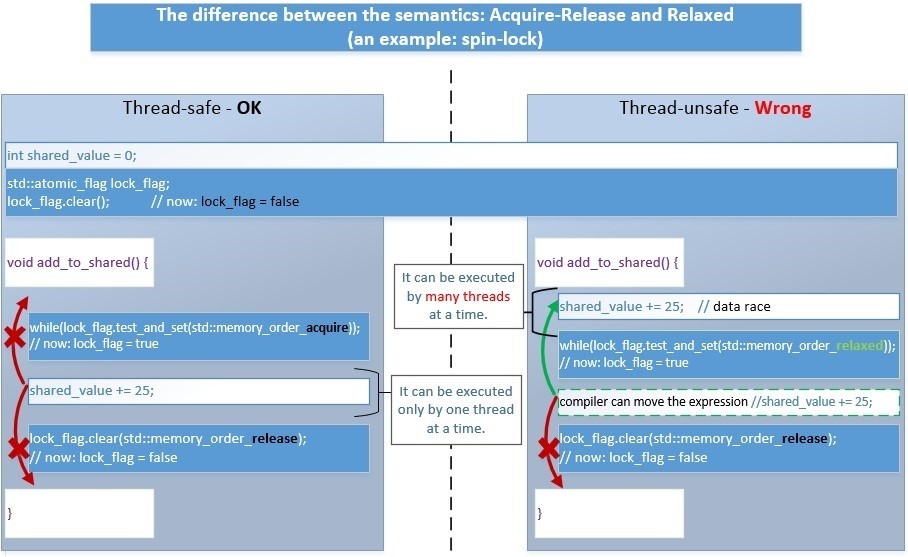
- Слева. В случае Acquire-Release все исполняется корректно.
- Справа. В случае Relaxed-Release – будет неверная работа алгоритма, т.к. часть кода внутри critical section, защищаемой блокировкой может быть перемещена наружу компилятором или процессором. Тогда возникнет проблема Data Races – множество потоков ещё до блокировки начнут одновременно работать с данными, над которыми выполняются не атомарные операции — мы можем получить ошибочный результат.
Заметим, что обычно невозможно реализовать всю логику над общими данными только с помощью атомарных операций, так как их очень мало и они достаточно медленные если их много. Поэтому проще и быстрее: одной атомарной операцией установить флаг «закрыто», выполнить все неатомарные операции над общими для потоков данными, и установить флаг «открыто».
Покажем схематически этот процесс во времени:
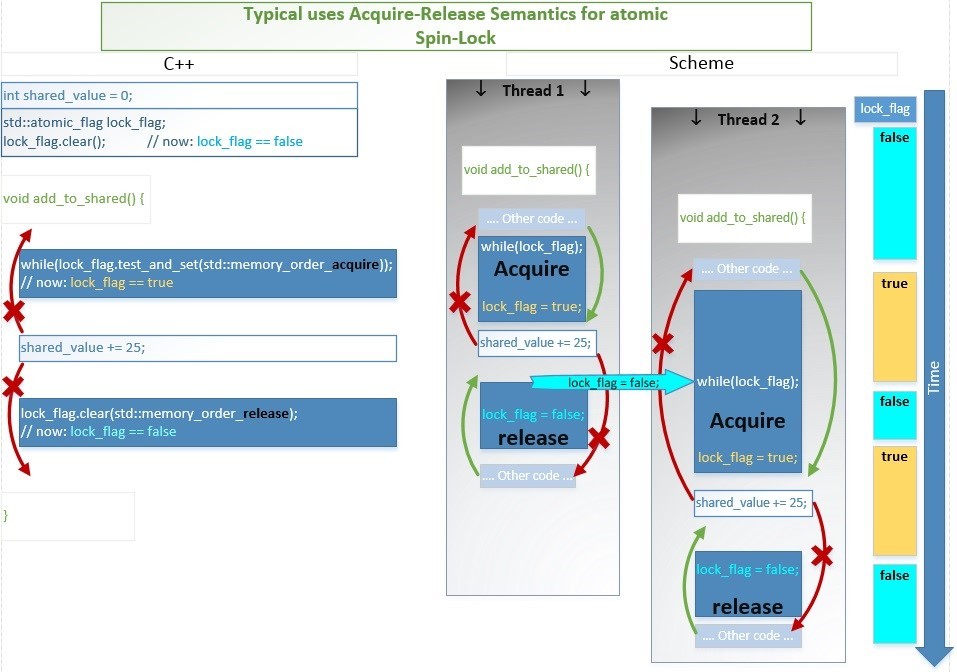
Например, два потока начинают исполнение функции add_to_shared().
- Поток-1 заходит чуть раньше, и одной атомарной инструкцией test_and_set() выполняет сразу 2 операции: проверят если lock_flag == false, то присваивает ему значение true (т.е. блокирует spin-lock), и возвращает false. Следовательно, выражение while(lock_flag.test_and_set()); тут же завершается и начинает исполняться код критической секции.
- Поток-2 в этот момент тоже начинает выполнять эту атомарную инструкцию test_and_set(): проверяет если lock_flag == false, то присваивает значение true, а иначе ничего не изменяет и возвращает текущее значение true. Следовательно, выражение while(lock_flag.test_and_set()); будет исполняться до тех пор, пока while(lock_flag);
- Поток-1 выполняет операцию сложения shared_value += 25; и затем атомарной операцией устанавливает значение lock_flag = false (т.е. разблокирует spin-lock).
- Поток-2 наконец дождавшись условия lock_flag == false присваивает lock_flag = true, возвращает false и завершает цикл. Затем выполняет сложение shared_value += 25; и присваивает lock_flag = false (разблокирует spin-lock).
Вначале этой главы мы привели 2 примера:
- используя std::atomic_flag и test_and_set():[21] coliru.stacked-crooked.com/a/1ec9a0c2b10ce864
- используя std::atomic<int> и compare_exchange_weak():[22] coliru.stacked-crooked.com/a/03c019596b65199a
Подробнее об этих операциях по ссылке: en.cppreference.com/w/cpp/atomic/atomic
Давайте посмотрим, как отличается ассемблерный код для x86_64 генерируемый компилятором GCC для этих двух примеров:
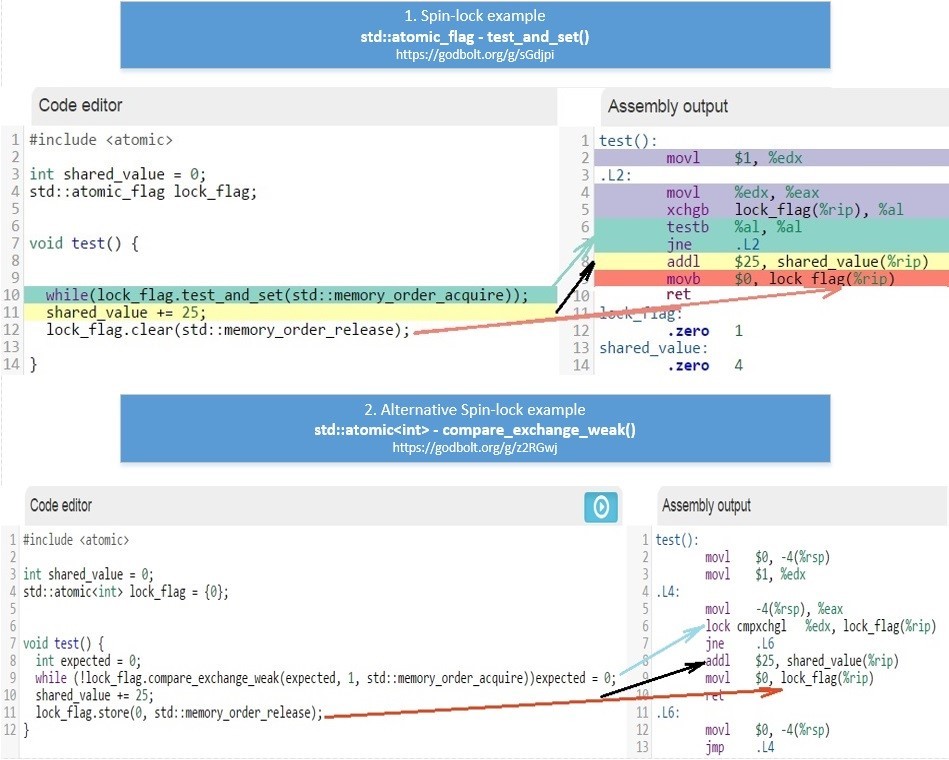
Чтобы было удобно использовать, его можно объединить в один класс:
class spinlock_t {
std::atomic_flag lock_flag;
public:
spinlock_t() { lock_flag.clear(); }
bool try_lock() { return !lock_flag.test_and_set(std::memory_order_acquire); }
void lock() { for (size_t i = 0; !try_lock(); ++i) if (i % 100 == 0) std::this_thread::yield(); }
void unlock() { lock_flag.clear(std::memory_order_release); }
};Пример использования класса spinlock_t по ссылке: [23] coliru.stacked-crooked.com/a/92b8b9a89115f080
Чтобы вы всегда могли понять какой барьер вам использовать и во что он будет скомпилирован на x86_64, я приведу следующую таблицу:
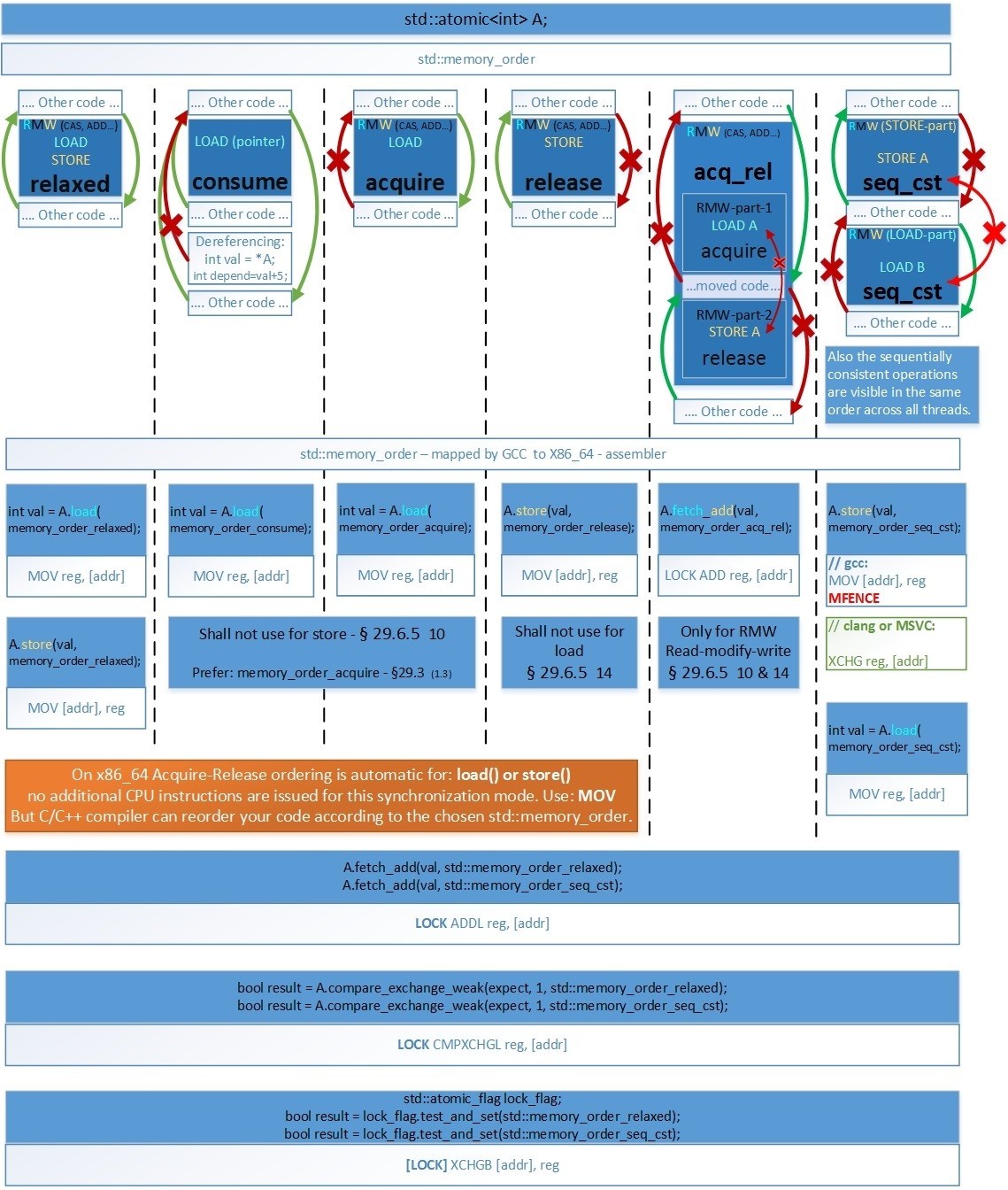
Картинку можно посмотреть в полном размере по ссылке: hsto.org/files/4f8/7b4/1b6/4f87b41b64a54549afca679af1028f84.jpg
Следующее необходимо знать, только если вы пишете код на ассемблере x86_64, когда компилятор не может менять местами ассемблерные инструкции для оптимизации:
- seq_cst. Основное отличие (Clang и MSVC) от GCC – при использовании операции Store для семантики Sequential Consistency, а именно: a.store(val, memory_order_seq_cst); — в этом случае Clang и MSVC генерируют инструкцию [LOCK] XCHG reg, [addr], которая очищает CPU-Store-buffer так же, как и барьер MFENCE. А GCC в этом случае использует две инструкции MOV [addr], reg и MFENCE.
- RMW (CAS, ADD…) always seq_cst. Т.к. все атомарные RMW (Read-Modify-Write) инструкции на x86_64 имеют префикс LOCK, который очищает Store-Buffer, то они все соответствуют семантике Sequential-Consistency на уровне ассемблерного кода. Любые memory_order для RMW генерируют идентичный код, в том числе и memory_order_acq_rel.
- LOAD(acquire), STORE(release). Как видно, на x86_64 первые 4 барьера памяти (relaxed, consume, acquire, release) генерируют идентичный ассемблерный код – т.е. архитектура x86_64 обеспечивает семантику acquire-release автоматически – в том числе это обеспечивается протоколами кэш-когерентности MESIF(Intel) / MOESI (AMD). Это справедливо только для памяти выделенной обычными средствами компилятора которая по умолчанию помечена как Write Back (но не справедливо для памяти, помеченной как Un-cacheable или Write Combined – которая применяется для работы с Mapped Memory Area from Device – в ней автоматически обеспечивается только Acquire-semantic).
Как мы знаем нигде и никогда не могут быть переупорядочены зависимые операции, например: (Read-X, Write-X) или (Write-X, Read-X)
Слайды с выступления Herb Sutter для x86_64: https://onedrive.live.com/view.aspx?resid=4E86B0CF20EF15AD!24884&app=WordPdf&authkey=!AMtj_EflYn2507c
• На x86_64 не могут быть переупорядочены любые:
- Read-X – Read-Y
- Read-X – Write-Y
- Write-X – Write-Y
• На x86_64 может быть переупорядочены любые: Write-X <–> Read-Y. Чтобы это предотвратить используется барьер std::memory_order_seq_cst, который может генерировать 4 варианта кода на x86_64 в зависимости от компилятора:
- load: MOV (from memory) store: MOV (to memory), MFENCE
- load: MOV (from memory) store: LOCK XCHG (to memory)
- load: MFENCE + MOV (from memory) store: MOV (to memory)
- load: LOCK XADD ( 0, from memory ) store: MOV (to memory)
Сводная таблица соответствия барьеров памяти инструкциям процессора для архитектур (x86_64, PowerPC, ARMv7, ARMv8, AArch64, Itanium) по ссылке: www.cl.cam.ac.uk/~pes20/cpp/cpp0xmappings.html
Посмотреть реальный ассемблерный код для разных компиляторов вы можете по ссылкам. А также можете выбрать другие архитектуры: ARM, ARM64, AVR, PowerPC.
GCC 6.1 (x86_64):
- Load / Store: godbolt.org/g/xq9ulH
- RMW (fetch_add): godbolt.org/g/dp1zZ0
- CAS (compare_exchange_weak() / compare_exchange_strong()): godbolt.org/g/OMuXmz
- std::atomic_flag::test_and_set(): godbolt.org/g/7ksl0J
Clang 3.8 (x86_64):
- Load / Store: godbolt.org/g/gfpeZW
- RMW (fetch_add): godbolt.org/g/afoIQW
- CAS (compare_exchange_weak() / compare_exchange_strong()): godbolt.org/g/kYXzK6
- std::atomic_flag::test_and_set(): godbolt.org/g/RD5fJG
Так же кратко покажем в таблице, какой эффект оказывают различные барьеры памяти на порядок относительно CAS (Compare-and-swap)-инструкций: en.cppreference.com/w/cpp/atomic/atomic/compare_exchange

Примеры переупорядочивания операций обращения к памяти
Теперь покажем более сложные примеры переупорядочивания из 4-ех последовательных операций: LOAD, STORE, LOAD, STORE.
- Синие прямоугольники – это атомарные операции
- Темно-синие прямоугольники внутри светло-синих (в примерах 3 и 4) – это части составных атомарных инструкций Read-Modify-Write(RMW) состоящие из нескольких атомарных операций
- Белые прямоугольники – это обычные неатомарные операции
Приведем 4 примера в каждом из которых покажем возможное переупорядочивание операций с обычными переменными вокруг операций с атомарными переменными. Но только в примерах 1 и 3 также возможно некоторое переупорядочивание атомарных операций между собой.
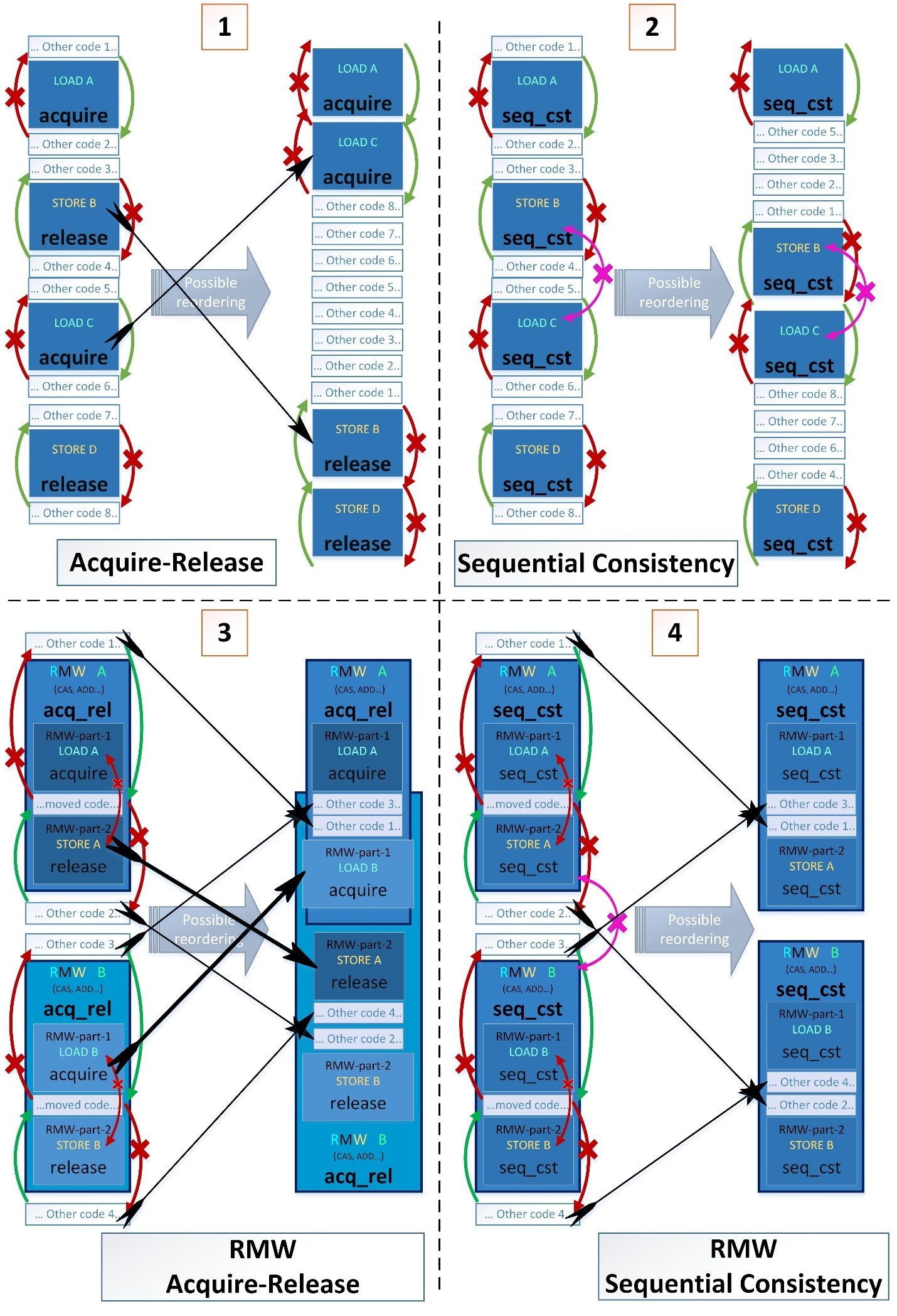
1-й случай – интересен тем, что несколько критических секций могут быть слиты (fused) в одну.
Компилятор не может выполнить такое переупорядочение во время компиляции, но компилятор позволяет процессору выполнять это переупорядочение во время выполнения. Поэтому слияние критических секций, которые выполняются в разных последовательностях в разных потоках, не может привести к взаимной блокировке (deadlock), потому что начальная последовательность инструкций будет видна процессору. Следовательно процессор попытается заранее войти в вторую критическую секцию, но если он не сможет, он продолжит выполнение первой критической секции и после полного её завершения будет ожидать входа во вторую критическую секцию.
3-й случай – интересен тем, что части двух составных атомарных инструкций могут быть переупорядочены: STORE A <--> LOAD B.
- Это возможно в случае с архитектурами, где составные операции состоят из 3-ёх отдельных ASM-инструкций (lwarx, add, stwcx), а их атомарность достигается за счет техники LL/SC (wiki-link), ассемблерный код по ссылке: godbolt.org/g/j8uw7n Компилятор не может выполнить такое переупорядочение во время компиляции, но компилятор позволяет процессору выполнять это переупорядочение во время выполнения.
2й случай – интересен тем, что std::memory_order_seq_cst самый сильный барьер и казалось бы должен запрещать любые переупорядочивания атомарных или неатомарных операций вокруг себя. Но seq_cst-барьеры обладают только одним дополнительным свойством по сравнению с acquire/release – только если обе атомарные операции имеют seq_cst-барьер, то последовательность операций STORE-A(seq_cst); LOAD-B(seq_cst); не может быть переупорядочена. Приведем 2 цитаты стандарта C++:
- Строгий единый взаимный порядок выполнения сохраняется только для операций c барьером memory_order_seq_cst, Standard C++11 § 29.3 (3): www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606.pdf
There shall be a single total order S on all memory_order_seq_cst operations, consistent with the “happens before” order and modification orders for all affected locations, such that each memory_order_seq_cst operation B that loads a value from an atomic object M observes one of the following values: …
- Если атомарная операция имеет барьер отличный от memory_order_seq_cst то она может переупорядочиваться с memory_order_seq_cst–операциями в разрешенных направлениях, Standard C++11 § 29.3 (8): www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606.pdf
[ Note: memory_order_seq_cst ensures sequential consistency only for a program that is free of data races and uses exclusively memory_order_seq_cst operations. Any use of weaker ordering will invalidate this guarantee unless extreme care is used. In particular, memory_order_seq_cst fences ensure a total order only for the fences themselves. Fences cannot, in general, be used to restore sequential consistency for atomic operations with weaker ordering specifications. — end note ]
Разрешенные направления для переупорядочивания не–seq_cst операций (атомарных и неатомарных) вокруг seq_cst-операций такие же как и у acquire/release:
- a.load(memory_order_seq_cst) – гарантирует для не seq_cst-операций такой же порядок, как a.load(memory_order_acquire)
- b.store(memory_order_seq_cst) – гарантирует для не seq_cst-операций такой же порядок, как b.store(memory_order_release)
Более строгий порядок возможен, но не гарантируется.
В случае seq_cst также, как для acquire и release: ничто идущее до STORE(seq_cst) не может быть выполнено после него, и ничто идущее после LOAD(seq_cst) не может быть выполнено до него.
Но в обратном направлении переупорядочивание возможно.
Теперь покажем какие изменения порядка инструкций разрешают компиляторы для процессоров, на примере GCC для x86_64 и PowerPC — примеры кода на C++ и сгенерированного кода на Assembler x86_64 и PowerPC.
Возможны следующие изменения порядка вокруг memory_order_seq_cst–операций:
- На x86_64 на уровне процессора разрешено переупорядочивание Store-Load. Т.е. может быть переупорядочена следующая последовательность:
STORE-C(release); LOAD-B(seq_cst); ==> LOAD-B(seq_cst); STORE-C(release);
т.к. на архитектуре x86_64, добавляется MFENCE только после STORE(seq_cst), но для LOAD(seq_cst) инструкции ассемблера идентичны для LOAD(release) и LOAD(relaxed): godbolt.org/g/BsLqas - На PowerPC на уровне процессора разрешены переупорядочивания Store-Load, Store-Store и другие. Т.е. может быть переупорядочена следующая последовательность:
STORE-A(seq_cst); STORE-C(relaxed); LOAD-C(relaxed); ==>
т.к. на архитектуре PowerPC, для seq_cst-барьера добавляется sync (hwsync) только до STORE(seq_cst) и до LOAD(seq_cst), таким образом все инструкции которые находятся между STORE(seq_cst) и LOAD(seq_cst) могут исполниться до STORE(seq_cst): godbolt.org/g/dm7tWd
LOAD-C(relaxed); STORE-C(relaxed); STORE-A(seq_cst);
Покажем подробнее на примере из 3 переменных с семантикой: seq_cst и relaxed.
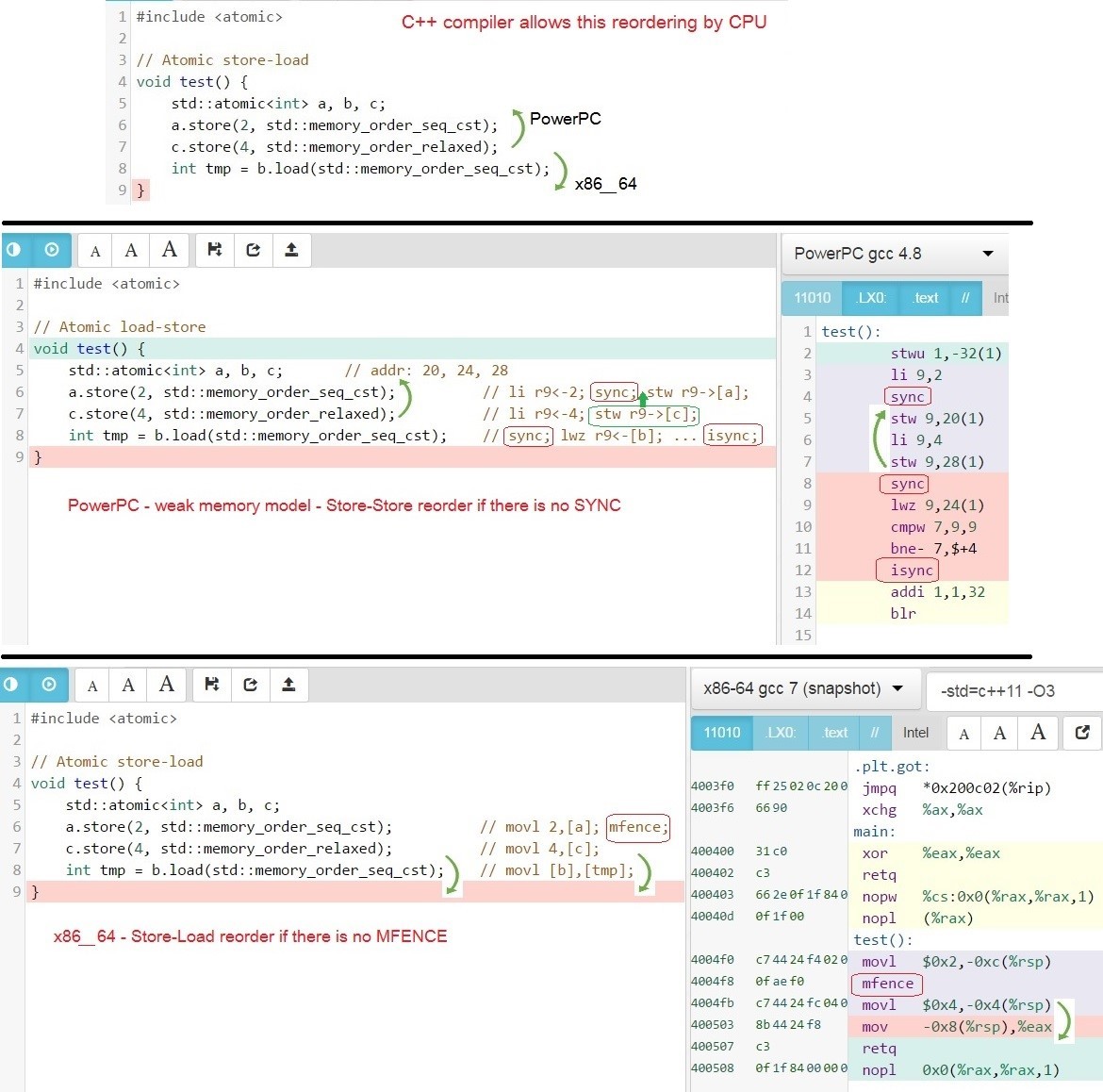
Какие переупорядочивания позволяет делать компилятор C++
- C++ to ASM for PowerPC: godbolt.org/g/mEM8T8
- C++ to ASM for x86_64: godbolt.org/g/lTNMJ2
Почему такие изменения порядка возможны? Потому что C++-компилятор генерирует assembler-код, которые позволяет делать такие переупорядочивание процессорам x86_64 и PowerPC:
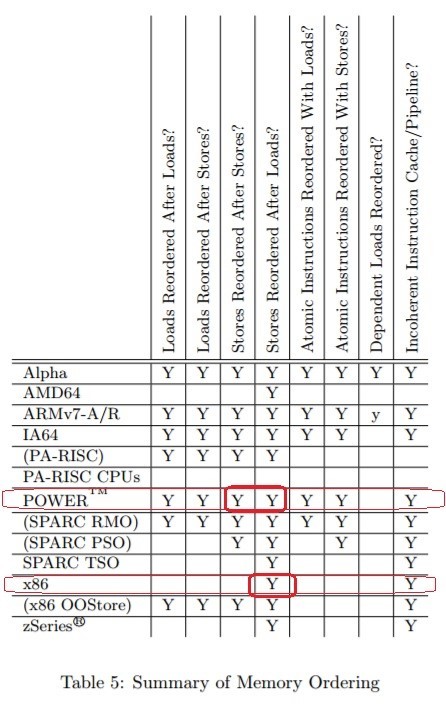
Какие переупорядочивания позволяют делать разные CPU при отсутствии assembler-барьеров между инструкциями. “Memory Barriers: a Hardware View for Software Hackers” Paul E. McKenney June 7, 2010 — Table 5: www.rdrop.com/users/paulmck/scalability/paper/whymb.2010.06.07c.pdf
Есть ещё одна особенность обмена данными между потоками, которая проявляется при взаимодействии 4 потоков или больше. Если хотя бы в одной из следующих операций не используется самый строгий барьер memory_order_seq_cst, то разные потоки могут видеть одни и те же изменения в разном порядке. Например:
- Если поток-1 изменил некоторое значение первым
- А поток-2 изменил некоторое значение вторым
- То поток-3 может сначала увидеть изменения сделанные потоком-2, и только затем увидит изменения сделанные потоком-1
- А поток-4 наоборот может сначала увидеть изменения сделанные потоком-1, и только затем увидит изменения сделанные потоком-2
Это возможно из-за аппаратных особенностей работы кэш-когерентного протокола, дополнительных Load/Store-буферов и топологии расположения ядер в процессорах. В этом случае некоторые два ядра могут увидеть изменения сделанные друг другом раньше, чем увидят изменения сделанные другими ядрами. Чтобы все потоки видели изменения в одном и том же порядке, т.е. имели single total order (C++11 § 29.3 (3)) – необходимо чтобы все операции (LOAD, STORE, RMW) выполнялись с барьером памяти memory_order_seq_cst: en.cppreference.com/w/cpp/atomic/memory_order
В следующем примере программа никогда не завершится с ошибкой assert(z.load() != 0); т.к. во всех операциях применяется самый строгий барьер памяти memory_order_seq_cst: coliru.stacked-crooked.com/a/52726a5ad01f6529
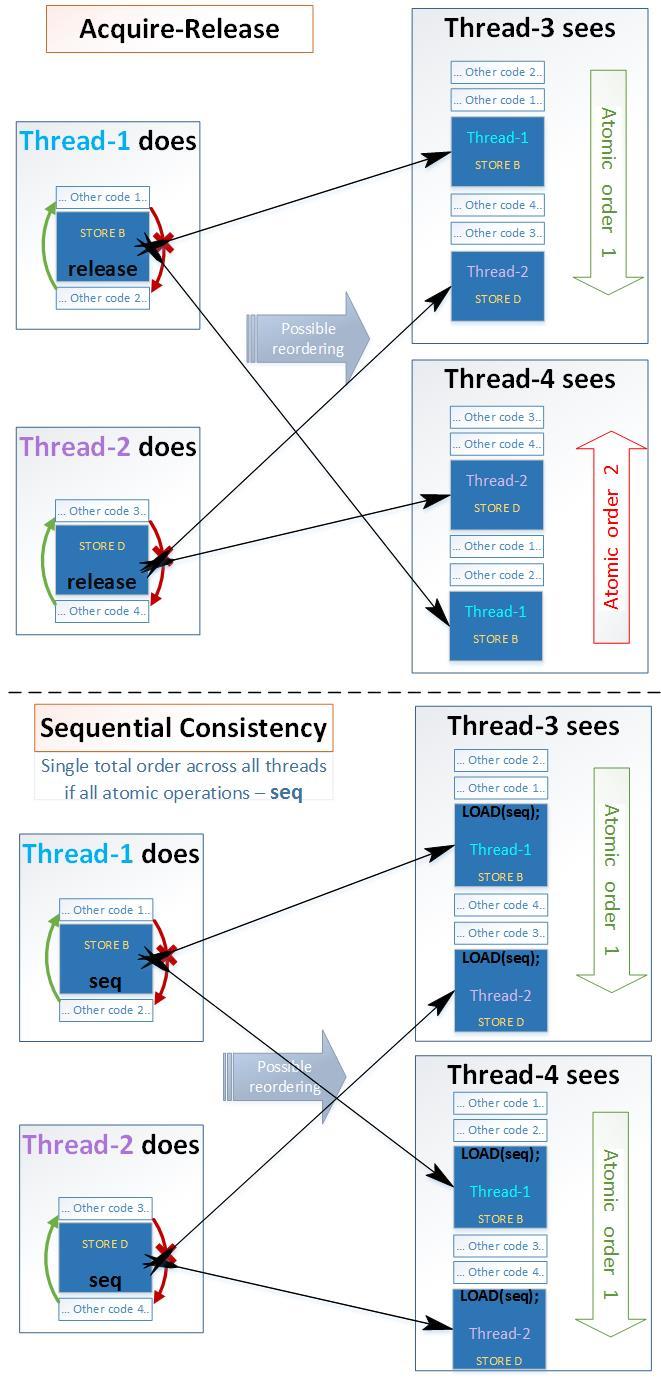
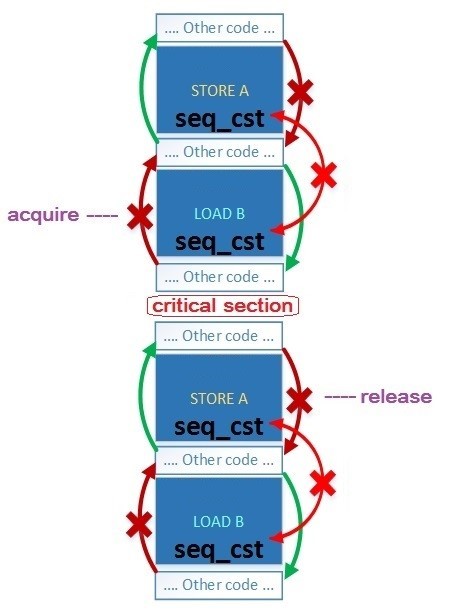
На рисунке покажем какое изменение порядка возможно для Acquire-Release семантики и для Sequential семантики на примере из 4-ех потоков:
- Acuire-Release:
• Возможно изменение порядка обычных переменных в разрешенных направлениях
• Возможно изменение порядка атомарных переменных с Acquire-Release-семантикой - Sequential:
• Возможно изменение порядка обычных переменных в разрешенных направлениях
• Невозможно изменение порядка атомарных переменных с Sequential-семантикой
Активные блокировки spin-lock и recursive-spin-lock
Покажем, как применяются барьеры памяти для атомарных операций на примере реализации собственных активных блокировок: spin-lock и recursive-spin-lock.
Далее эти блокировки понадобятся нам для блокирования отдельных строк (row-lock) таблицы вместо блокирования всей таблицы (table-lock) – это повысит степень параллелизма и увеличит производительность, т.к. разные потоки смогут работать с разными строками параллельно, не блокируя всю таблицу.
Количество объектов синхронизации предоставляемых операционной системой может быть ограничено. Количество строк в таблице может составлять миллионы или миллиарды, многие ОС не позволяют создавать столько мьютексов. А количество spin-lock может быть любым, насколько это позволяет оперативная память – поэтому их можно использовать для блокирования каждой отдельной строки.
Фактически spinlock – это + 1 байт к каждой строке(row), или +17 байт при использовании recursive-spin-lock (1 байт для флага + 8 байт для счетчика рекурсии + 8 байт для номера потока thread_id).
- Мы уже приводили пример реализации и использования spinlock: [24] coliru.stacked-crooked.com/a/92b8b9a89115f080
- Теперь покажем пример реализации и использования recursive_spinlock: [25] coliru.stacked-crooked.com/a/eae6b7da971810a3
Основное отличие recursive_spinlock от обычного spinlock в том, что recursive_spinlock может быть многократно заблокирован одним и тем же потоком, т.е. поддерживает рекурсивные вложенные блокировки. Точно так же отличаются std::recursive_mutex и std::mutex.
Пример вложенных блокировок:
- spinlock_t – происходит вечная взаимоблокировка (deadlock) – не выводит результат: [26] coliru.stacked-crooked.com/a/d3b93315270fd367
- recursive_spinlock_t – работает нормально – выводит результат shared_value = 50: [27] coliru.stacked-crooked.com/a/875ad2754a007037
Давайте разберемся как работает recursive_spinlock_t.
Если вы попробуете запустить этот код в компиляторе MSVC 2013, то получите очень сильное замедление из-за функции std::this_thread::get_id(): connect.microsoft.com/VisualStudio/feedback/details/1558211
Мы доработаем класс recursive_spinlock_t, чтобы он кешировал thread-id в переменной __declspec(thread) – это аналог thread_local из стандарта С++11. Этот пример покажет хорошую производительность и в MSVC 2013: [28] coliru.stacked-crooked.com/a/3090a9778d02f6ea
Это временное исправление для старого MSVC 2013, поэтому о красоте такого решения мы думать не будем.
Считается, что в большинстве случаев повторное (рекурсивное) блокирование мьютекса – это ошибка проектирования, но в нашем случае это может быть медленным, но рабочим кодом. Во-вторых все ошибаются, и при вложенных рекурсивных блокировках recursive_spinlock_t отработает заметно медленнее, а spinlock_t зависнет навечно – что лучше, решать вам.
В случае использования нашего потоко-безопасного указателся safe_ptr<T> – оба примера вполне логичны, но второй сработает только с recursive_spinlock:
safe_int_spin_recursive->second++; // spinlock & recursive_spinlock
safe_int_spin_recursive->second = safe_int_spin->second + 1; // only recursive_spinlockРеализация собственного высокопроизводительного shared-mutex
Как известно, в новых стандартах C++ постепенно появлялись новые типы мьютексов: en.cppreference.com/w/cpp/thread
- C++11: mutex, timed_mutex, recursive_mutex, recursive_timed_mutex
- C++14: shared_timed_mutex
- C++17: shared_mutex

shared_mutex – это мьютекс позволяющий одновременно многим потокам читать одни и те же данные, если в этот момент нет потоков изменяющих эти данные. shared_mutex появился не сразу, т.к. шли споры о его производительности по сравнению с обычным std::mutex.
Классическая реализация shared_mutex со счетчиком количества читателей показывала преимущество в скорости только когда много читателей долго удерживали блокировку – т.е. когда долго читали. При коротких чтениях shared_mutex только замедлял программу и усложнял код.
Но все ли реализации shared_mutex столь медленные при коротких чтениях?
Основная причина медленной работы std::shared_mutex и boost::shared_mutex – это атомарный счетчик читателей. Каждый читающий поток инкрементирует счетчик при блокировании и декрементирует его при разблокировании. В итоге потоки постоянно гоняют между ядрами одну кэш-линию (а именно гоняют её exclusive-state (E)). По логике такой реализации, каждый читающий поток подсчитывает сколько всего сейчас читателей, но это абсолютно не важно для читающего потока, т.к. ему важно только, чтобы не было ни одного писателя. Причем, т.к. инкремент и декремент – это RMW операции, то они всегда генерируют очистку Store-Buffer (MFENCE x86_64) и на уровне x86_64 asm фактически соответствуют самой медленной семантике Sequential Consistency.
Попробуем решить эту проблему.
Есть тип алгоритмов, который классифицируется как write contention-free – когда нет ни одной ячейки памяти в которую могли бы писать более одного потока. А в более общем случае – нет ни одной кэш-линии в которую могли бы писать более одного потока. Чтобы наш shared-mutex при наличии только читателей классифицировался как write contention-free, необходимо, чтобы читатели не мешали друг другу – т.е. чтобы каждый читатель писал флаг (что он читает) в свою отдельную ячейку, и снимал флаг в этой же ячейке по окончанию чтения – без RMW-операций.
Write contention-free – это максимально производительная гарантия, которая производительнее, чем wait-free и чем lock-free.
Возможно, чтобы каждая ячейка располагалась в отдельной кэш-линии для исключения false-sharing, а возможно, и чтобы ячейки лежали плотно по 16 в одной кэш-линии – потеря производительности будет зависеть от CPU и количества потоков. Для устранения false-sharing — каждую переменную следует размещать в отдельной кэш-линии, для этого в C++17 существует коснтрукция alignas(std::hardware_destructive_interference_size), а в более ранних можно использовать процессор-зависимое решение char tmp[60]; (на x86_64 размер кэш-линии 64 байта):
//struct cont_free_flag_t {
// alignas(std::hardware_destructive_interference_size) std::atomic<int> value; // C++17
// };
struct cont_free_flag_t {
char tmp[60]; std::atomic<int> value; // tmp[] to avoid false sharing
};Перед установкой флага, читатель проверяет есть ли писатель – т.е. есть ли эксклюзивная блокировка. А т.к. shared-mutex применяется в случаях, когда очень мало писателей, то все используемые ядра могут иметь копию этого значения у себя в кэш-L1 в shared-state (S) откуда за 3 такта получат значение флага писателя, пока он не изменится.
Для всех писателей, как обычно, есть один и тот же флаг want_x_lock – он означает, что в данный момент есть писатель. Потоки писатели его устанавливают и снимают, используя RMW-операции.
lock(): while(!want_x_lock.compare_exchange_weak(flag, true, std::memory_order_acquire))unlock(): want_x_lock.store(false, std::memory_order_release);Но чтобы читатели не мешали друг другу, для этого они должны писать информацию о своих shared-блокировках в разные ячейки памяти. Выделим массив под эти блокировки, размер которого мы будем задавать параметром шаблона, по умолчанию равным 20. При первом вызове lock_shared() поток автоматически будет регистрироваться – занимая определенное место в этом массиве. Если потоков больше, чем размер массива, то остальные потоки при вызове lock_shared() будут вызывать эксклюзивную блокировку писателя. Потоки создаются редко, а время, затраченное операционной системой на их создание настолько велико, что время на регистрацию нового потока в нашем объекте будет ничтожно мало.
Удостоверимся, что нет очевидных ошибок – на примерах покажем, что все работает верно, а далее схематически докажем правильность нашего подхода.
Приведем пример такой быстрой разделяемой блокировки, в которой читатели не мешают друг другу: [30] coliru.stacked-crooked.com/a/b78467b7a3885e5b
- Во время разделяемой блокировки не может быть изменений объекта. Эта строка из двух рекурсивных shared-lock показывает это: assert(readonly_safe_map_string->at(«apple») == readonly_safe_map_string->at(«potato»)); — значения обоих строк всегда должны быть равны, т.к. мы меняем 2 строки в std::map под одной eXclusive-блокировкой std::lock_guard
- Во время чтения мы действительно вызываем функцию lock_shared(). Давайте уменьшим цикл до двух итераций, уберем строчки модифицирующие данные, оставим только первые две вставки в std::map в функции main(). Теперь добавим вывод буквы S в функцию lock_shared(), и буквы X в функцию lock(). Видим, что сначала идут две вставки X, а затем только буквы S – значит действительно, при чтениях const-объекта мы вызываем shared_lock():[31] coliru.stacked-crooked.com/a/515ba092a46135ae
- Во время изменений мы действительно вызываем функцию lock(). Теперь закомментируем чтение и оставим только операции изменения массива, теперь выводятся только буквы X: [32] coliru.stacked-crooked.com/a/882eb908b22c98d6
Основная задача – добиться, чтобы в одно и тоже время могло быть только одно из двух состояний:
- Любое количество потоков успешно выполнили lock_shared(), при этом все потоки пытающиеся выполнить lock() должны перейти в ожидание
- Один из потоков успешно выполнил lock(), а все остальные потоки пытающиеся выполнить lock_shared() или lock() должны перейти в ожидание
Схематически таблица совместимых состояний выглядит так.
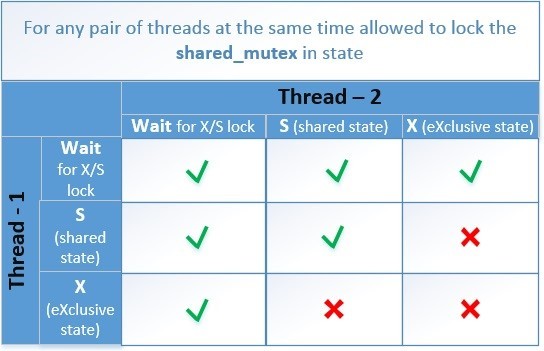
Рассмотрим алгоритм нашего contention_free_shared_mutex для случаев, когда 2 потока пытаются одновременно выполнить операции:
- T1-read & T2-read: Потоки-читатели блокируют мьютекс используя lock_shared() – эти потоки друг другу не мешают, т.к. пишут состояния о блокировках в отдельные для каждого потока ячейки памяти, и в этом время не должно быть эксклюзивной блокировки потока-писателя (want_x_lock == false). За исключением случаев, когда потоков больше, чем выделенных ячеек – тогда даже потоки-читатели блокируют эксклюзивно, используя CAS-функцию: want_x_lock = true.
- T1-write & T2-write: Потоки-писатели конкурируют друг с другом за один и тот же флаг (want_x_lock) и пытаются установить его в true, используя атомарную CAS-функцию: want_x_lock.compare_exchange_weak(); Здесь все просто, как и в обычном recursive_spinlock_t, который мы рассмотрели выше.
- T1-read & T2-write: Поток-читатель T1 пишет флаг блокировки в свою ячейку, и только после этого проверяет установлен ли флаг (want_x_lock), и если установлен (true), то отменяет свою блокировку, затем ожидает состояния (want_x_lock == false) и повторяет этот алгоритм сначала.
Поток-писатель T2 устанавливает флаг (want_x_lock = true), а затем ждет пока все потоки-читатели снимут флаги блокировок из своих ячеек.
Поток-писатель в нашей схеме имеет выше приоритет, чем читатель. И если они одновременно установили свои флаги блокировок, то поток-читатель следующей операцией проверяет есть ли поток-писатель (want_x_lock == true), и если есть, то читатель отменяет свою блокировку. Поток-писатель видит, что больше нет блокировок от читателей и успешно завершает функцию блокирования. Глобальный порядок этих блокировок соблюдается благодаря семантике Sequential Consistency (std::memory_order_seq_cst).
Схематически взаимодействие двух потоков (читателя и писателя) выглядит следующим образом.
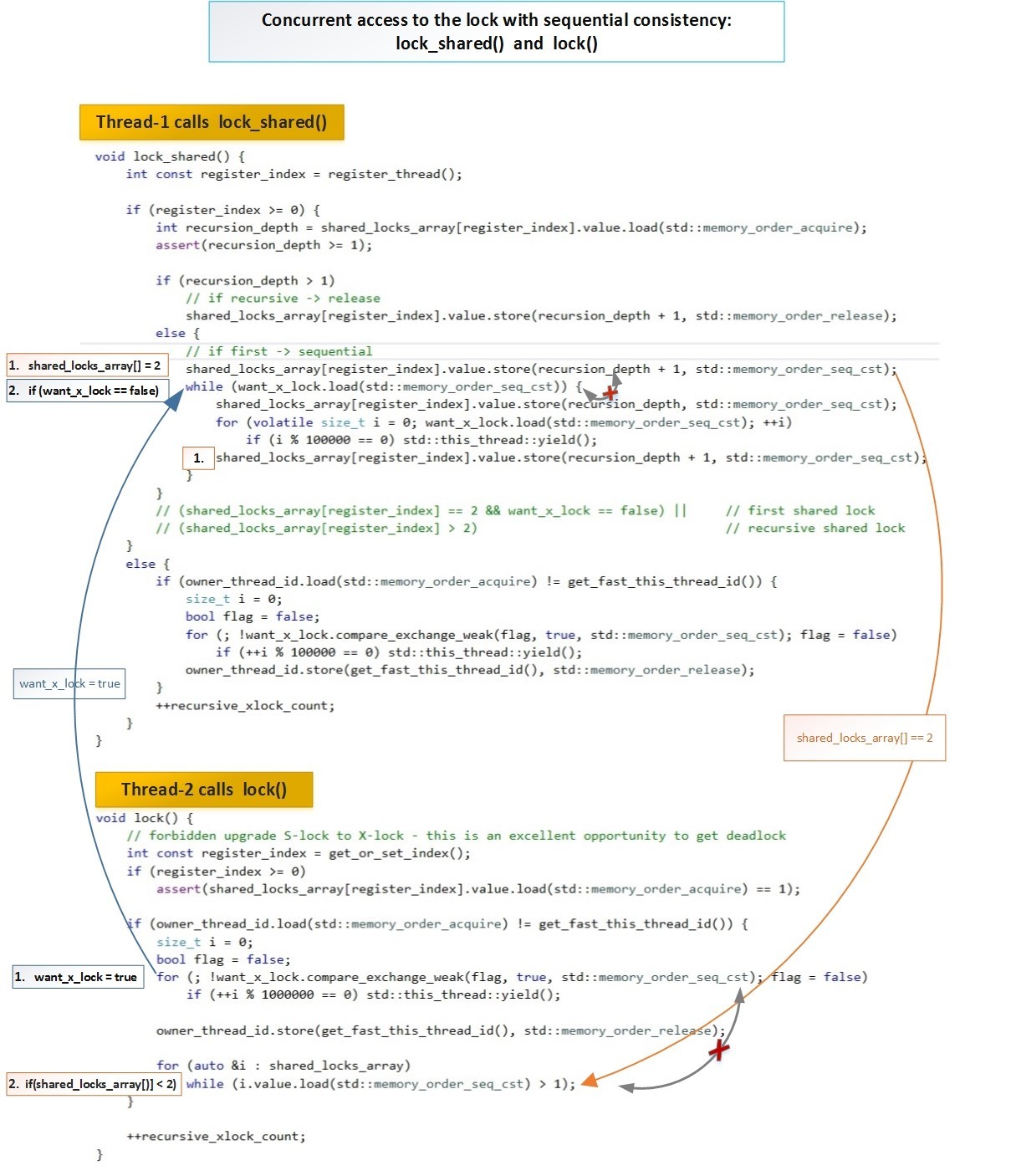
В полном размере: habrastorage.org/getpro/habr/post_images/5b2/3a3/23b/5b23a323b6a1c9e13ade90bbd82ed98b.jpg
В обеих функциях lock_shared() и lock(), для обеих операций 1. и 2. используется std::memory_order_seq_cst — т.е. для этих операций гарантируется единый порядок для всех потоков (single total order).
Автоматическая отмена регистрации потока в cont-free shared-mutex
Когда поток впервые обращается к нашей блокировке, то он регистрируется. А когда этот поток завершается или блокировка удаляется, то должна происходить отмена регистрации.
Но теперь давайте посмотрим, что будет, если с нашим мьютексом поработают 20 потоков, затем эти потоки завершатся, и попробуют зарегистрироваться новые 20 потоков, при условии, что массив блокировок равен 20: [33] coliru.stacked-crooked.com/a/f1ac55beedd31966
Как видно первые 20 потоков успешно зарегистрировались, но следующие 20 потоков зарегистрироваться не смогли (register_thread = -1) и вынуждены были использовать эксклюзивную блокировку писателя, несмотря на то что предыдущие 20 потоков уже удалились и уже не используют блокировку.
Чтобы решить эту проблему – добавим автоматическую отмену регистрации потока, когда поток удаляется. Если поток работал с множеством таких блокировок, то в момент завершения потока должна произойти отмена регистрации во всех таких блокировках. А если в момент удаления потока есть блокировки, которые на данный момент уже удалены, то не должно произойти ошибки из-за попытки отменить регистрацию в несуществующей блокировке.
Пример: [34] coliru.stacked-crooked.com/a/4172a6160ca33a0f
Как видим сначала зарегистрировались 20 потоков, а после их удаления и создания новых 20 потоков, они также смогли зарегистрироваться – под теми же номерами register_thread = 0 – 19 (смотрите вывод(output) примера).
Теперь покажем, что даже если потоки работали с блокировкой, а затем блокировка была удалена, то при завершении потоков не произойдет ошибки из-за попытки отменить регистрацию в несуществующем объекте блокировки: [35] coliru.stacked-crooked.com/a/d2e5a4ba1cd787da
Мы установили таймеры так, чтобы создались 20 потоков, выполнили чтение используя нашу блокировку и заснули на 500ms, а в это время через 100ms удалился объект contfree_safe_ptr содержащий внутри себя нашу блокировку contention_free_shared_mutex, и только после этого проснулись 20 потоков и завершились. При завершении их не произошло ошибки из-за отмены регистрации в удаленном объекте блокировки.
Как небольшое дополнение сделаем поддержку MSVS2013, чтобы владельцы старого компилятора тоже смогли ознакомиться с примером. Добавим упрощенную поддержку регистрации потоков, но без возможности отмены регистрацию потока.
Конечный результат покажем в виде примера, в котором учтены все перечисленные выше мысли.
Пример: [36] coliru.stacked-crooked.com/a/0a1007765f13aa0d
Правильное функционирование алгоритма и выбранных барьеров
Выше мы провели тесты, которые показали отсутствие очевидных ошибок. Но чтобы доказать работоспособность необходимо создать схему возможных изменений порядка операций и возможных состояний переменных.
Эксклюзивная блокировка lock() / unlock() почти такая же простая, как и в случае с recursive_spinlock_t, поэтому её детально рассматривать не будем.
Конкуренцию потока-читателя за lock_shared() и потока писателя за lock() мы детально рассмотрели выше.
Сейчас основная задача показать, что lock_shared() во всех случаях использует как минимум Acquire-semantic, а unlock_shared() во всех случаях использует как минимум Release-semantic. Но это не обязательное условие при повторном рекурсивном блокировкии/разблокировании.

Теперь покажем, как эти барьеры реализуются в нашем коде.
Схематически барьеры для lock_shared() – красными перечеркнутыми стрелками показаны направления в которых изменение порядка запрещено:

Схематически барьеры для unlock_shared():
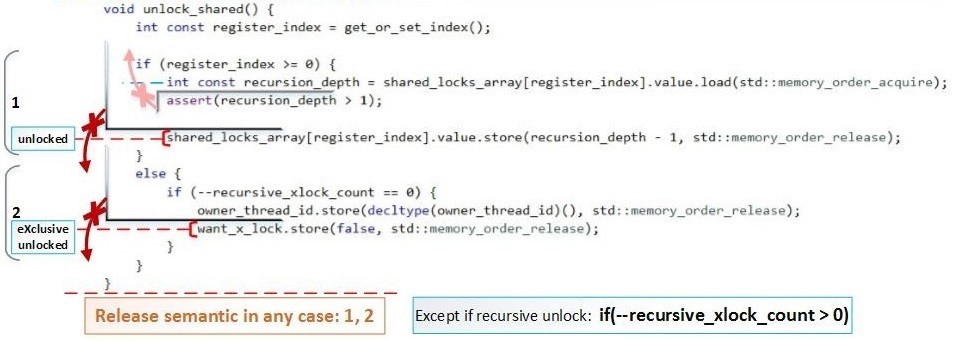
В полный размер: hsto.org/files/065/9ce/bd7/0659cebd72424256b6254c57d35c7d07.jpg
В полный размер с размеченными условными переходами: hsto.org/files/fa7/4d2/2b7/fa74d22b7cda4bf4b1015ee263cad9ee.jpg
Приведем также блок-схему этой же самой функции lock_shared()

Картинка в полном размере: hsto.org/files/c3a/abd/4e7/c3aabd4e7cfa4e9db55b2843467d878f.jpg
В овальных блоках обозначены строгие последовательности исполнения операций:
- Сначала исполняется операция – красным цветом
- Затем исполняется операция – фиолетовым цветом
Зеленым цветом обозначены изменения, которые могут исполняться в любом порядке, т.к. эти изменения не блокируют наш «shared-mutex», а только увеличивают счетчик вложенности рекурсии – эти изменения важны только для локального использования. Т.е. эти зеленые операции не являются фактическим входом в блокировку.
Т.к. выполняются 2 условия – то считается, что все необходимые side-effects от многопоточности учтены:
- Момент принятия решения о входе в блокировку всегда имеет семантику не ниже «acquire»:
• want_x_lock.load(std::memory_order_seq_cst)
• want_x_lock.compare_exchange_weak(flag, true, std::memory_order_seq_cst) - Всегда сначала блокируем (1-красным), и только после этого проверяем (2-фиолетовым) можем ли мы войти в блокировку. И в нашей схеме эти две операции никогда не могут быть переупорядочены.
Далее корректность алгоритма может быть проверена простым сопоставлением результатов данных операций и их последовательности с логикой работы алгоритма.
Все остальные функции нашей блокировки «contention_free_shared_mutex» более очевидны с точки зрения логики многопоточного исполнения.
Так же отмечу, что при повторном (рекурсивном) блокировании, атомарным операциям не обязательно иметь барьер std::memory_order_acquire (как показано на рисунке), достаточно установить std::memory_order_relaxed, потому что это не фактический вход в блокировку — мы уже находимся в блокировке. Но это не добавляет большой скорости и может усложнить понимание.
Как использовать
Покажем пример использования contention_free_shared_mutex<> на C++ в качестве высоко-оптимизированного shared_mutex.
Скачать этот код для Linux (GCC 6.3.0) и Windows (MSVS 2015/13) можно по ссылке: github.com/AlexeyAB/object_threadsafe/tree/master/contfree_shared_mutex
Чтобы скомпилировать данный пример на Clang++ 3.8.0 под Linux вы должны изменить Makefile.
#include < iostream >
#include < thread >
#include < vector >
#include "safe_ptr.h"
template < typename T >
void func(T &s_m, int &a, int &b)
{
for (size_t i = 0; i < 100000; ++i)
{
// x-lock for modification
{
s_m.lock();
a++;
b++;
s_m.unlock();
}
// s-lock for reading
{
s_m.lock_shared();
assert(a == b); // will never happen
s_m.unlock_shared();
}
}
}
int main() {
int a = 0;
int b = 0;
sf::contention_free_shared_mutex< > s_m;
// 19 threads
std::vector< std::thread > vec_thread(20);
for (auto &i : vec_thread) i = std::move(std::thread([&]() { func(s_m, a, b); }));
for (auto &i : vec_thread) i.join();
std::cout << "a = " << a << ", b = " << b << std::endl;
getchar();
return 0;
}Этот код в онлайн компиляторе: coliru.stacked-crooked.com/a/11c191b06aeb5fb6
Как вы видите наш мьютекс sf::contention_free_shared_mutex<> используется точно таким же образом, как и стандартный std::shared_mutex.
Тест: std::shared_mutex VS contention_free_shared_mutex
Приведем пример тестирования на 16 потоках для одного серверного процессора Intel Xeon E5-2660 v3 2.6 GHz. В первую очередь нас интересует голубая и фиолетовая линии:
- safe_ptr<std::map, std::shared_mutex>
- contfree_safe_ptr<std::map>
Исходный код данного теста: github.com/AlexeyAB/object_threadsafe/tree/master/bench_contfree
Командная строка для запуска:
numactl --localalloc --cpunodebind=0 ./benchmark 16
Если у вас только один CPU на материнской плате, то запускайте: ./benchmark
Производительность различных блокировок для разного соотношения блокировок чтения (shared-lock) и блокировок записи (exclusive-lock).
- % exclusive locks = (% of write operations)
- % shared locks = 100 — (% of write operations)
(в случае std::mutex – всегда работает блокировка exclusive-lock)

Performance (the bigger – the better), MOps — millions operations per second
- При 0% изменений, наш shared-mutex (в составе contfree_safe_ptr<map>) показывает производительность 34.60 Mops, что в 14 раз быстрее, чем стандартный std::shared_mutex (в составе safe_ptr<map, std::shared_mutex>), который показывает только 2.44 Mops.
- При 15% изменений, наш shared-mutex (в составе contfree_safe_ptr<map>) показывает производительность 5.16 Mops, что в 7 раз быстрее, чем стандартный std::shared_mutex (в составе safe_ptr<map, std::shared_mutex>), который показывает только 0.74 Mops.
Наша блокировка «contention-free shared-mutex» работает для любого количества потоков: для первых 36 потоков как contention-free, а для последующих как exclusive-lock. Как видим из графиков, даже «exclusive-lock» std::mutex работает быстрее, чем std::shared_mutex при 15% изменений.
Количество потоков 36 для contention-free задается параметром шаблона и может быть изменено.
Теперь покажем медианную задержку для разного соотношения типа блокировок: чтения (shared-lock) и записи (exclusive-lock).
В коде теста main.cpp необходимо установить: const bool measure_latency = true;
Командная строка для запуска:
numactl --localalloc --cpunodebind=0 ./benchmark 16
Если у вас только один CPU на материнской плате, то запускайте: ./benchmark

Median-latency (the lower – the better), microseconds
Таким образом мы создали разделяемую блокировку, в которой читатели не мешают друг другу во время блокирования и разблокирования, в отличие от std::shared_timed_mutex и boost::shared_mutex. Но у нас для каждого потока дополнительно выделяется: 64 байта в массиве блокировок + 24 байта занимает структура unregister_t для отмены регистрации + элемент, указывающий на эту структуру из hash_map. В сумме около 100 байт на поток.
Более глубокая проблема – это возможность масштабироваться. Например, если у вас есть 8 CPU (Intel Xeon Processor E7-8890 v4) по 24 ядра (по 48 потоков HyperThreading), то это в сумме 384 логических ядра. Каждый поток-писатель перед записью должен прочитать по 24576 байт (по 64 байт от каждого из 384 ядер), но читать их можно параллельно, это конечно лучше, чем ждать пока одна кэш-линия последовательно перейдет от каждого из 384 потока к каждому, как в обычных std::shared_timed_mutex и boost::shared_mutex (при любом типе блокировки unique/shared). Но распараллеливание на 1000 ядер и более обычно реализуется через другой подход, а не через вызов атомарной операции на обработку каждого сообщения. Все обсуждаемые выше варианты: атомарные операции, активные блокировки, lock-free структуры данных – это все необходимо для низких задержек (0,5 – 5 usec) отдельных сообщений.
Для высоких показателей количества операций в секунду, т.е. для высокой производительности системы в целом и масштабируемости на десятки тысяч логических ядер используют подходы массового параллелизма, «hide latency» и «batch processing» — пакетной обработки, когда сообщения сортируются (для map) или группируются (для hash_map) и сливаются с уже имеющимся отсортированным или сгруппированным массивом за 50 – 500 usec. В итоге у каждой операции задержка в 10-100 раз больше, но эти задержки происходят в одно и тоже время в огромном количестве потоков, в результате происходит сокрытие задержек «hide latency» за счет использования «Fine-grained Temporal multithreading».
Если предположим: у каждого сообщения задержка в 100 раз больше, но сообщений обрабатывается в 10000 раз больше. Это на единицу времени в 100 раз эффективней. Такие принципы применяются при разработке на GPU. Возможно в следующих статьях мы разберем это подробней.

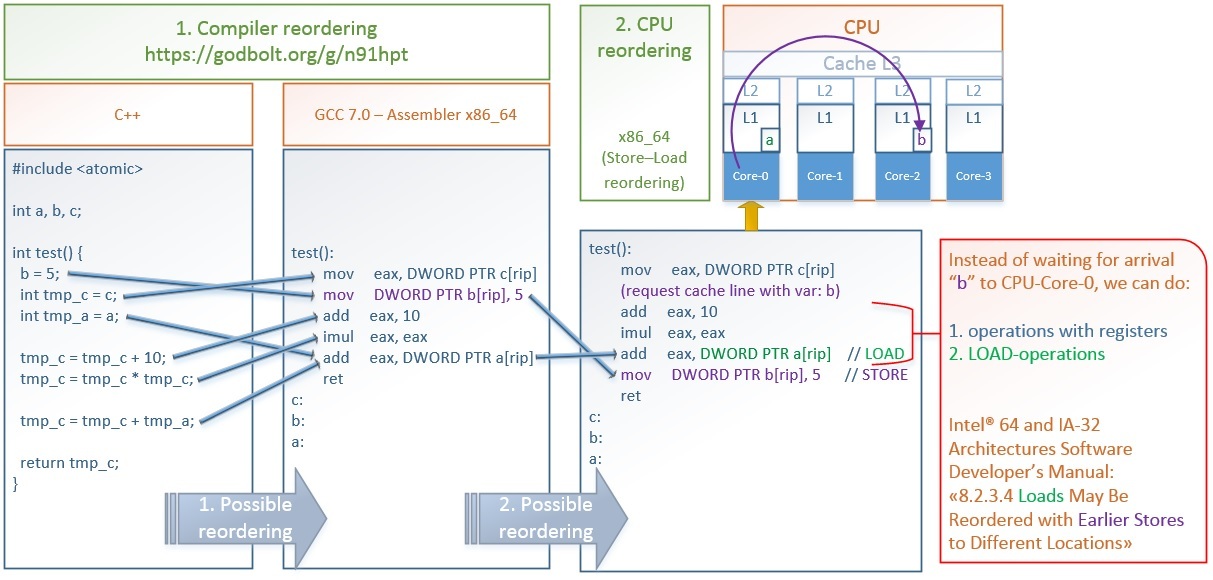{kind=link}
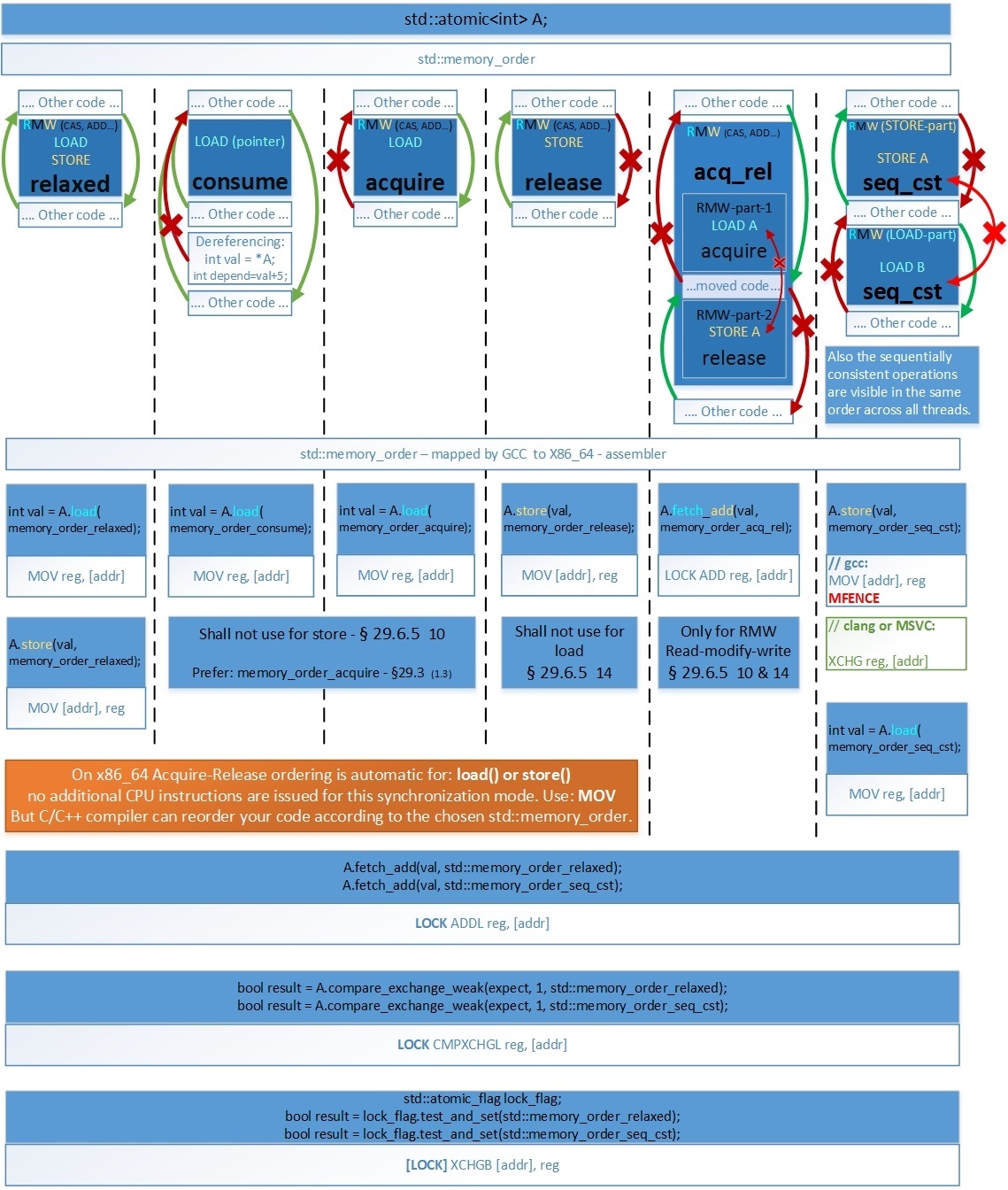{kind=link}
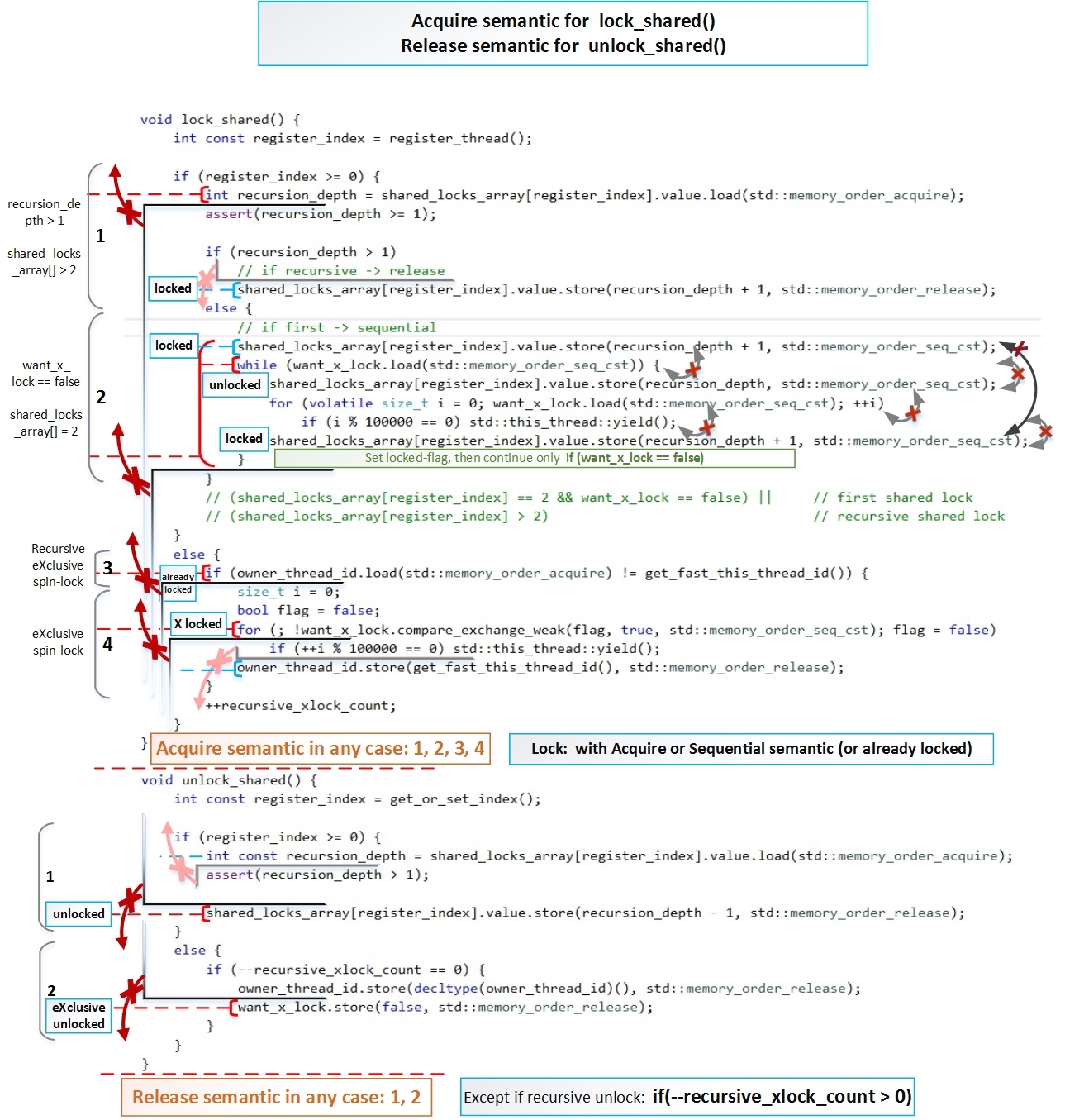{kind=link}
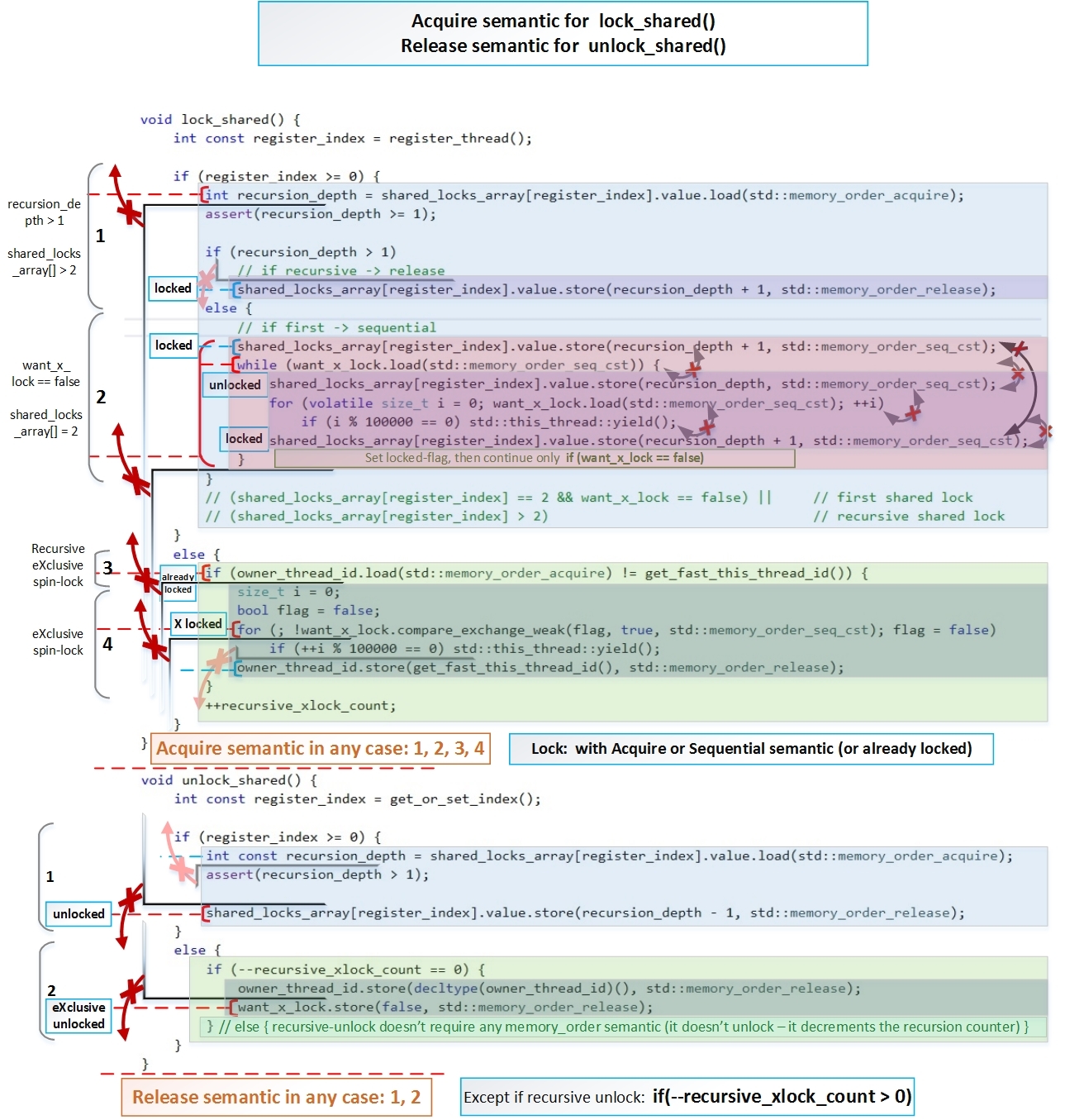{kind=link}
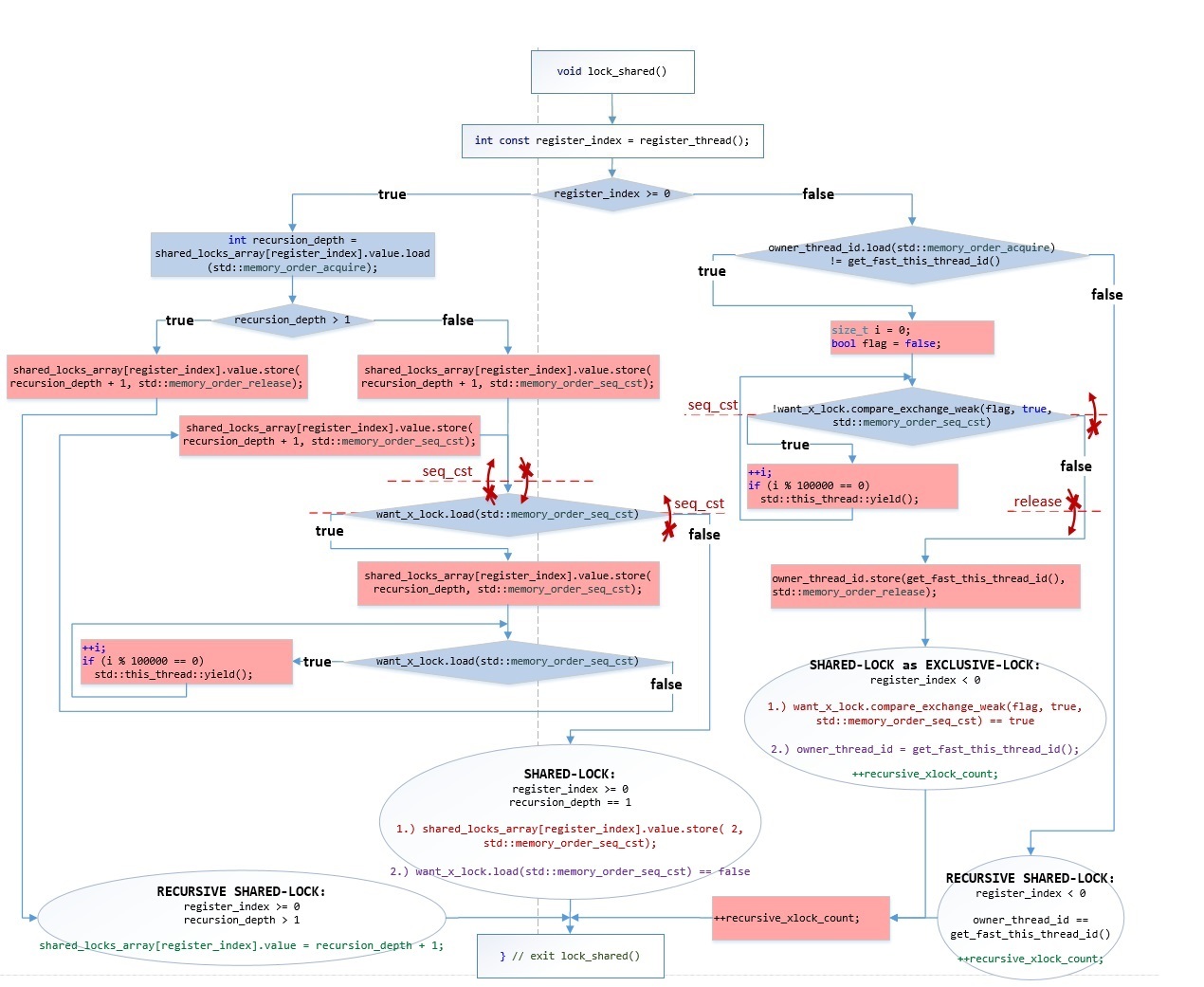{kind=link}