Тема по улучшению взаимодействия машин и человека сейчас актуальна как никогда. Появились технические возможности для перехода от модели «100 кликов» к парадигме «скажи, что ты хочешь». Да, я имею в виду различные боты, которые уже несколько лет разрабатывают все кому не лень. К примеру, многие крупные компании, не только технологические, но и retail, logistics, банки в данный момент ведут активный Research&Design в этой области.
Простой пример, как, например, происходит процесс выбора товаров в каком-либо интернет магазине? Куча списков, категорий, в которых я роюсь и что-то выбираю. It suck's. Или, допустим, заходя в интернет банк, я сталкиваюсь с различными меню, если я хочу сделать перевод, то я должен выбрать соответствующие пункты в меню и ввести кучу данных, если же я хочу посмотреть список транзакций, то опять таки, я должен напрягать как мозг, так и указательный палец. Гораздо проще и удобнее было бы зайти на страницу, и просто сказать: «Я хочу купить литр молока и пол-литра водки», или просто спросить у банка: «Что с деньгами?».
В список профессий, которым грозит вымирание в достаточно близкой перспективе, добавляются: теллеры, операторы call центров, и многие другие. И на простом примере, реализовать который у меня заняло часов 7, я покажу, как можно достаточно просто сделать интеграцию распознавания речи, и выявления сущностей, на примере открытого Wit.Ai (Google Speech API интеграция также включена).

Существует достаточно много API по распознаванию речи, некоторые из них платные, некоторые открыты для разработки своих систем. Например, Google Speech API предлагает бесплатно 60 минут распознавания в месяц, при превышение этого лимита, плата взымается из расчета за 0,006 центов за минуту, с шагом в 15 секунд. Напротив, Wit.ai позиционирует себя, как открытый API для разработчиков, но будет ли с их стороны тот же уровень сервиса, если к примеру количество обращений к сервису вырастет до сотен тысяч, а то и миллионов в месяц, остается вопросом.
Пару недель назад, у нас в Тарту проводились семинары по Data Science и Искусственному Интеллекту, и многие выступающие обращались, так или иначе, к теме взаимодействия человека и машины, на понятном для человека языке. И на следующих, после мероприятий, выходных, я решил реализовать распознавание речи с помощью общедоступных сервисов. Ну и конечно, я бы хотел, чтобы бот понимал, что я хочу выпить пива, и какого пива именно. Темного или светлого, а также возможно и разбирался бы в сортах.
В общем, задача сводится к тому, чтобы записать на стороне клиента то, что он сказал, переслать на сервер, сделать некие преобразования, сделать вызов стороннему API, и получить результат.
Поначалу, я спланировал обратиться к Google Speech API, чтобы получить транскрипцию аудио файла, и затем строку текста я хотел послать на Wit.AI, чтобы получить набор сущностей и намерений.
Выбор для backend для меня был тривиальным, это Spring Boot. И не только потому, что Java stack для меня родной, но и потому, что я хотел создать небольшой сервис, который будет служить посредником между сторонними API и клиентом. Дополнительную функциональность можно реализовать введением дополнительного сервиса.
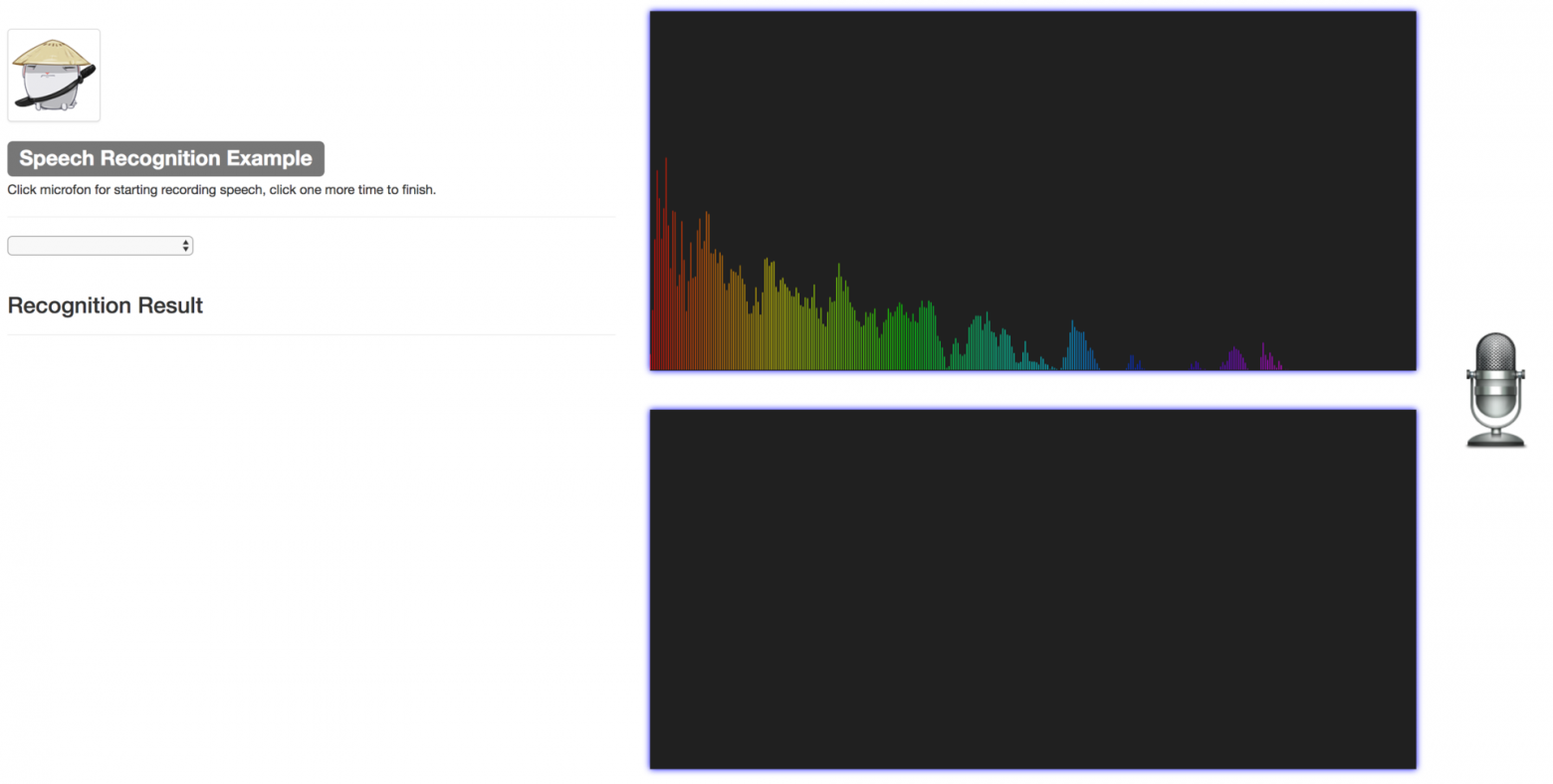
Исходный код я выложил на GitHub. Рабочее же приложение, я развернул на Heroku — https://speechbotpoc.herokuapp.com/. Перед использованием, разрешите использование микрофона. Далее, нажмите иконку микрофона и скажите что-либо, после чего, еще раз нажмите иконку. Сказанное вамибудет использовано против вас будет отправлено на распознавание, и через некоторое время, вы получите результат в панели слева. Я отключил выбор языка перевода, поскольку этот пример могут использовать несколько человек, то во избежании race condition, выбор языка распознавания отключен.
Итак, для начала, мы создаем пустой проект с помощью Spring Initializr или Spring Boot CLI, кому как нравится, я выбрал Spring Initializr. Необходимые зависимости — Spring MVC, Lombok(если вы не хотите писать много шаблонного кода), Log4j. Импортируем созданный каркас проекта в предпочитаемую IDE (кто-то еще использует Eclipse?).
Для начала, нам необходимо сделать запись аудио файла на стороне клиента. HTML5 предоставляет все возможности для этого, (MediaRecorder интерфейс), но существует отличная реализация от Matt Diamond, которая распространяется по MIT лицензии, и я решил взять её, поскольку Мэтт разработал, также, неплохую визуализацию на стороне клиента. Больше всего времени, по сути, заняла не разработка серверной части, а реализация на стороне клиента. Я не стал использовать AngularJS или ReactJS, поскольку, мне была интересна именно общая интеграция, и мой выбор остановился на jQuery, дешево и сердито.
Что касается серверной части, то поначалу я хотел использовать Google Speech API для первоначальной транскрипции аудио файла в текст, а поскольку данный API требует перекодировки записанной речи в Base64, то на стороне клиента, получив аудио данные, я производил перекодировку в Base64, и далее отправлял на сервер.
В нашем каркасе создаем контроллер, который будет принимать наш аудио файл.
Все достаточно просто, мы принимаем данные и передаем их сервису, который производит всю дальнейшую работу.
Сервис WitAiService также достаточно простой.
Все необходимые параметры, такие как ключ и токен для Wit.AI берутся из файла application.properties. (да, я открыл токены для своего приложения). Если вы хотите зарегистрировать свое приложение на Wit.AI, то вам необходимо будет поменять токены и App.ID в файлах настроек. Регистрация на Wit.AI достаточно простая, токен можно получить в разделе Settings.
Spring Boot подтягивает настройки с помощью аннотаций. Аннотации Data и Setter это аннотации проекта Lombok, которые помогают избегать написания шаблонного кода, в виде сеттеров, геттеров, конструкторов по умолчанию и т.п.
Файлы модели, и вспомогательный конвертер я не привожу сюда, все это можно посмотреть в исходниках.
Если вы откроете Developer Console в Chrome, то увидите, что после того, как вы записали сказанное, происходит REST вызов сервиса, где аудио данные, закодированные в Base64, передаются на сервер в поле content. У меня были некоторые проблемы с Google биллингом (биллинг зарегистрирован на старую кредитку, которая закрыта, а новую еще не оформил), и после того, как я написал взаимодействие с Google Speech API, я решил отправлять на распознавание напрямую на Wit.AI. Но Wit.AI принимает данные в потоковом виде как есть, и поэтому на сервере происходит перекодировка из Base64 обратно в wav формат.
Небольшие моменты касаемо распознавания. Обратите внимание на уровень микрофона, поскольку, если он очень чувствителен, вы получите срезанный звук, который негативно отразится на качестве распознавания.
Теперь, когда мы получили распознавание сказанного нами, давайте научим понимать приложение, что мы конкретно хотим. В разделе Understanding Wit.AI (Для этого вам надо зарегистрировать на Wit.AI свое приложение, то есть, пройти регистрацию, это несложно.) мы можем задавать так называемые intent, или намерения. Выглядит это довольно логично, мы пишем строку, например, «Пойдем пить пиво» и выделяем нужное нам слово, в данном случае «Пиво», и нажимаем на Add a new entity(Добавить новую сущность), далее мы выбираем intent, и создаем намерение «Пиво». Идем далее, мы хотим понимать хотим ли мы пить пиво, и тогда мы создаем новую сущность «Пить» или «Пьем». Далее, рекомендуется ввести еще несколько примеров, наподобие: «Может по пиву сегодня», «Попьем пиво завтра» и т.д. Тогда система будет все точнее и точнее выделять intent — Пиво.
Теперь, допустим, мы хотим понимать, какое пиво мы хотим пить, светлое или темное. Точно так же вводим новую фразу, «Попьем завтра темного пива», и на слове «темного» нам над опять нажать Add a new entity, но далее, нам надо не использовать уже имеющееся, а создать свою сущность, у меня в приложении она так и названа beer_type. Далее повторяем для светлого пива, только выбираем уже созданную сущность beer_type. В итоге, система начинает понимать, что я хочу попить пива, и какого пива конкретно. Все вышеперечисленное также возможно задавать не вручную, а автоматически, используя REST интерфейс Wit.AI. Категории легко перевести в сущности в batch режиме.
Попробуйте в примере предложить попить темного или светлого пива, вы увидите, что система возвращает объект, в котором есть, как намерение пиво, так и beer_type — темное или светлое.
Этот пример немного игрушечен, НО… Добавление сущностей можно производить и через REST интерфейс, таким образом, перевести каталог товаров в сущности бота можно довольно легко, также в Wit.AI существуют многие сущности контекста, такие как время/дата, место и так далее. То есть, можно получать информацию из таких контекстных слов, как сегодня-завтра(дата), тут(место) и т.д. Подробная документация находится тут.
Сам по себе код достаточно простой, и все понятно исходя из него самого. Логика интеграции с другими сервисами такая же. После получения транскрипции, можно передавать данную строку другим сервисам, например написать сервис, который будет добавлять в корзину желаемые товары, или просто передавать строку на перевод нейросервису (http://xn--neurotlge-v7a.ee/# пока с эстонского на английский и обратно, но можно натренировать модель и на другие языки). То есть, данный пример может служить небольшим кирпичиком, для построения более сложного потока взаимодействий. Например, я могу, допустим, заказывать пиво на дом, соединив данный пример, с сервисом заказа пищи, получив их токен или cookie. Или напротив посылать друзьям предложения о пиве по мессенджеру. Вариантов использования огромное количество.
Возможные пути использования: интернет-магазины, интернет-банки, системы перевода и т.д.
Если есть вопросы, то можете обращаться.
Простой пример, как, например, происходит процесс выбора товаров в каком-либо интернет магазине? Куча списков, категорий, в которых я роюсь и что-то выбираю. It suck's. Или, допустим, заходя в интернет банк, я сталкиваюсь с различными меню, если я хочу сделать перевод, то я должен выбрать соответствующие пункты в меню и ввести кучу данных, если же я хочу посмотреть список транзакций, то опять таки, я должен напрягать как мозг, так и указательный палец. Гораздо проще и удобнее было бы зайти на страницу, и просто сказать: «Я хочу купить литр молока и пол-литра водки», или просто спросить у банка: «Что с деньгами?».
В список профессий, которым грозит вымирание в достаточно близкой перспективе, добавляются: теллеры, операторы call центров, и многие другие. И на простом примере, реализовать который у меня заняло часов 7, я покажу, как можно достаточно просто сделать интеграцию распознавания речи, и выявления сущностей, на примере открытого Wit.Ai (Google Speech API интеграция также включена).

Существует достаточно много API по распознаванию речи, некоторые из них платные, некоторые открыты для разработки своих систем. Например, Google Speech API предлагает бесплатно 60 минут распознавания в месяц, при превышение этого лимита, плата взымается из расчета за 0,006 центов за минуту, с шагом в 15 секунд. Напротив, Wit.ai позиционирует себя, как открытый API для разработчиков, но будет ли с их стороны тот же уровень сервиса, если к примеру количество обращений к сервису вырастет до сотен тысяч, а то и миллионов в месяц, остается вопросом.
Пару недель назад, у нас в Тарту проводились семинары по Data Science и Искусственному Интеллекту, и многие выступающие обращались, так или иначе, к теме взаимодействия человека и машины, на понятном для человека языке. И на следующих, после мероприятий, выходных, я решил реализовать распознавание речи с помощью общедоступных сервисов. Ну и конечно, я бы хотел, чтобы бот понимал, что я хочу выпить пива, и какого пива именно. Темного или светлого, а также возможно и разбирался бы в сортах.
В общем, задача сводится к тому, чтобы записать на стороне клиента то, что он сказал, переслать на сервер, сделать некие преобразования, сделать вызов стороннему API, и получить результат.
Поначалу, я спланировал обратиться к Google Speech API, чтобы получить транскрипцию аудио файла, и затем строку текста я хотел послать на Wit.AI, чтобы получить набор сущностей и намерений.
Выбор для backend для меня был тривиальным, это Spring Boot. И не только потому, что Java stack для меня родной, но и потому, что я хотел создать небольшой сервис, который будет служить посредником между сторонними API и клиентом. Дополнительную функциональность можно реализовать введением дополнительного сервиса.
Исходный код я выложил на GitHub. Рабочее же приложение, я развернул на Heroku — https://speechbotpoc.herokuapp.com/. Перед использованием, разрешите использование микрофона. Далее, нажмите иконку микрофона и скажите что-либо, после чего, еще раз нажмите иконку. Сказанное вами

Итак, для начала, мы создаем пустой проект с помощью Spring Initializr или Spring Boot CLI, кому как нравится, я выбрал Spring Initializr. Необходимые зависимости — Spring MVC, Lombok(если вы не хотите писать много шаблонного кода), Log4j. Импортируем созданный каркас проекта в предпочитаемую IDE (кто-то еще использует Eclipse?).
Для начала, нам необходимо сделать запись аудио файла на стороне клиента. HTML5 предоставляет все возможности для этого, (MediaRecorder интерфейс), но существует отличная реализация от Matt Diamond, которая распространяется по MIT лицензии, и я решил взять её, поскольку Мэтт разработал, также, неплохую визуализацию на стороне клиента. Больше всего времени, по сути, заняла не разработка серверной части, а реализация на стороне клиента. Я не стал использовать AngularJS или ReactJS, поскольку, мне была интересна именно общая интеграция, и мой выбор остановился на jQuery, дешево и сердито.
Что касается серверной части, то поначалу я хотел использовать Google Speech API для первоначальной транскрипции аудио файла в текст, а поскольку данный API требует перекодировки записанной речи в Base64, то на стороне клиента, получив аудио данные, я производил перекодировку в Base64, и далее отправлял на сервер.
В нашем каркасе создаем контроллер, который будет принимать наш аудио файл.
@RestController
public class ReceiveAudioController {
@Autowired
@Setter
private WitAiService service;
private static final Logger logger = LogManager.getLogger(ReceiveAudioController.class);
@RequestMapping(value = "/save", method = RequestMethod.POST)
public @ResponseBody String saveAudio(@RequestBody Audio data, HttpServletRequest request) throws IOException {
logger.info("Request from:" + request.getRemoteAddr());
return service.processAudio(data);
}
}
Все достаточно просто, мы принимаем данные и передаем их сервису, который производит всю дальнейшую работу.
Сервис WitAiService также достаточно простой.
@Data
@Component
@ConfigurationProperties(prefix="witai")
public class WitAiService {
private static final Logger logger = LogManager.getLogger(WitAiService.class);
private String url;
private String key;
private String version;
private String command;
private String charset;
public String processAudio(Audio audio) throws IOException {
URLConnection connection = getUrlConnection();
OutputStream outputStream = connection.getOutputStream();
byte[] decoded;
decoded = Base64.getDecoder().decode(audio.getContent());
outputStream.write(decoded);
BufferedReader response = new BufferedReader(new InputStreamReader(connection.getInputStream()));
StringBuilder sb = new StringBuilder();
String line;
while((line = response.readLine()) != null) {
sb.append(line);
}
logger.info("Received from Wit.ai: " + sb.toString());
return sb.toString();
}
private URLConnection getUrlConnection() {
String query = null;
try {
query = String.format("v=%s", URLEncoder.encode(version, charset));
logger.info("Query string for wit.ai: " + query);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
URLConnection connection = null;
try {
connection = new URL(url + "?" + query).openConnection();
} catch (IOException e) {
e.printStackTrace();
}
connection.setRequestProperty ("Authorization","Bearer " + key);
connection.setRequestProperty("Content-Type", "audio/wav");
connection.setDoOutput(true);
return connection;
}
}
Все необходимые параметры, такие как ключ и токен для Wit.AI берутся из файла application.properties. (да, я открыл токены для своего приложения). Если вы хотите зарегистрировать свое приложение на Wit.AI, то вам необходимо будет поменять токены и App.ID в файлах настроек. Регистрация на Wit.AI достаточно простая, токен можно получить в разделе Settings.
Spring Boot подтягивает настройки с помощью аннотаций. Аннотации Data и Setter это аннотации проекта Lombok, которые помогают избегать написания шаблонного кода, в виде сеттеров, геттеров, конструкторов по умолчанию и т.п.
Файлы модели, и вспомогательный конвертер я не привожу сюда, все это можно посмотреть в исходниках.
Если вы откроете Developer Console в Chrome, то увидите, что после того, как вы записали сказанное, происходит REST вызов сервиса, где аудио данные, закодированные в Base64, передаются на сервер в поле content. У меня были некоторые проблемы с Google биллингом (биллинг зарегистрирован на старую кредитку, которая закрыта, а новую еще не оформил), и после того, как я написал взаимодействие с Google Speech API, я решил отправлять на распознавание напрямую на Wit.AI. Но Wit.AI принимает данные в потоковом виде как есть, и поэтому на сервере происходит перекодировка из Base64 обратно в wav формат.
byte[] decoded;
decoded = Base64.getDecoder().decode(audio.getContent());
outputStream.write(decoded);
Небольшие моменты касаемо распознавания. Обратите внимание на уровень микрофона, поскольку, если он очень чувствителен, вы получите срезанный звук, который негативно отразится на качестве распознавания.
Теперь, когда мы получили распознавание сказанного нами, давайте научим понимать приложение, что мы конкретно хотим. В разделе Understanding Wit.AI (Для этого вам надо зарегистрировать на Wit.AI свое приложение, то есть, пройти регистрацию, это несложно.) мы можем задавать так называемые intent, или намерения. Выглядит это довольно логично, мы пишем строку, например, «Пойдем пить пиво» и выделяем нужное нам слово, в данном случае «Пиво», и нажимаем на Add a new entity(Добавить новую сущность), далее мы выбираем intent, и создаем намерение «Пиво». Идем далее, мы хотим понимать хотим ли мы пить пиво, и тогда мы создаем новую сущность «Пить» или «Пьем». Далее, рекомендуется ввести еще несколько примеров, наподобие: «Может по пиву сегодня», «Попьем пиво завтра» и т.д. Тогда система будет все точнее и точнее выделять intent — Пиво.
Теперь, допустим, мы хотим понимать, какое пиво мы хотим пить, светлое или темное. Точно так же вводим новую фразу, «Попьем завтра темного пива», и на слове «темного» нам над опять нажать Add a new entity, но далее, нам надо не использовать уже имеющееся, а создать свою сущность, у меня в приложении она так и названа beer_type. Далее повторяем для светлого пива, только выбираем уже созданную сущность beer_type. В итоге, система начинает понимать, что я хочу попить пива, и какого пива конкретно. Все вышеперечисленное также возможно задавать не вручную, а автоматически, используя REST интерфейс Wit.AI. Категории легко перевести в сущности в batch режиме.
Попробуйте в примере предложить попить темного или светлого пива, вы увидите, что система возвращает объект, в котором есть, как намерение пиво, так и beer_type — темное или светлое.
Этот пример немного игрушечен, НО… Добавление сущностей можно производить и через REST интерфейс, таким образом, перевести каталог товаров в сущности бота можно довольно легко, также в Wit.AI существуют многие сущности контекста, такие как время/дата, место и так далее. То есть, можно получать информацию из таких контекстных слов, как сегодня-завтра(дата), тут(место) и т.д. Подробная документация находится тут.
Сам по себе код достаточно простой, и все понятно исходя из него самого. Логика интеграции с другими сервисами такая же. После получения транскрипции, можно передавать данную строку другим сервисам, например написать сервис, который будет добавлять в корзину желаемые товары, или просто передавать строку на перевод нейросервису (http://xn--neurotlge-v7a.ee/# пока с эстонского на английский и обратно, но можно натренировать модель и на другие языки). То есть, данный пример может служить небольшим кирпичиком, для построения более сложного потока взаимодействий. Например, я могу, допустим, заказывать пиво на дом, соединив данный пример, с сервисом заказа пищи, получив их токен или cookie. Или напротив посылать друзьям предложения о пиве по мессенджеру. Вариантов использования огромное количество.
Возможные пути использования: интернет-магазины, интернет-банки, системы перевода и т.д.
Если есть вопросы, то можете обращаться.
