Во время моего первого опыта работы с распределенными системами я постоянно сталкивался с некой CAP-теоремой, пришлось изрядно покопать, чтобы изучить и осознать её со всех сторон. Я не являюсь мастером баз данных, но надеюсь, что мое маленькое исследование мира распределённых систем будет полезно для обычных разработчиков. В статье я расскажу о том, что такое CAP, его проблемы и альтернативы, а также рассмотрим некоторые популярные системы баз данных через CAP призму.
Эта теорема была представлена на симпозиуме по принципам распределенных вычислений в 2000 году Эриком Брюером. В 2002 году Сет Гилберт и Нэнси Линч из MIT опубликовали формальное доказательство гипотезы Брюера, сделав ее теоремой.
По словам Брюера, он хотел, чтобы сообщество начало дискуссию о компромиссах в распределённых системах и уже спустя некоторое количество лет начал вносить в неё поправки и оговорки.
В CAP говорится, что в распределенной системе возможно выбрать только 2 из 3-х свойств:
Уже есть достаточно наглядных доказательств этой теоремы, поэтому дам ссылки на университет Баумана и доказательство в виде сервиса «Позвони, напомню!».
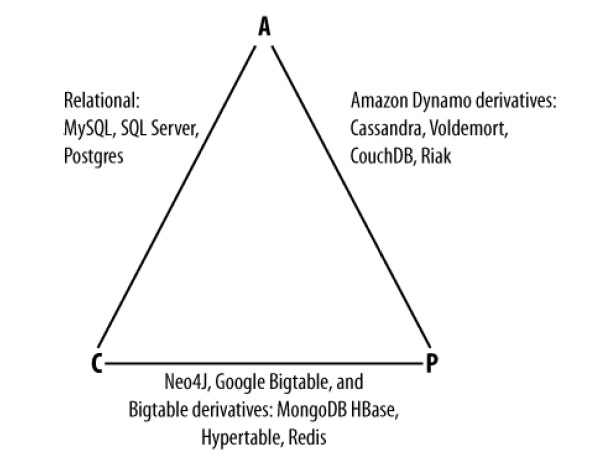
Многие статьи сводятся к вот такому вот простому треугольнику.
Для применения CAP теоремы на практике, я выбрал 3 наиболее, на мой взгляд, подходящие и достаточно популярные системы баз данных: Postgresql, MongoDB, Cassandra.
Следующие пункты относятся к абстрактной распределенной БД Postgresql.
Таким образом, система не может продолжать работу в случае partition, но обеспечивает strong consistency и availability. Это система CA!
Следующие пункты относятся к абстрактной распределенной БД MongoDB.
Таким образом, система может продолжать работу в случае разделения сети, но теряется CAP-availability всех узлов. Это CP система!
Cassandra использует схему репликации master-master, что фактически означает AP систему, в которой разделение сети приводит к самодостаточному функционированию всех узлов.
Казалось бы всё просто… Но это не так.
На тему проблем в CAP теореме написано множество подробных и интересных статей, здесь, на Хабре, поэтому я оставлю ссылку на CAP больше не актуален и мифы о CAP теореме. Обязательно почитайте их, но относитесь к каждой статье, как к своего рода новому взгляду и не принимайте слишком близко к сердцу, потому что одни ругают, другие хвалят. Сам же я не буду слишком углублятся, а постараюсь выдать некоторую необходимую компиляцию.
Итак, проблемы CAP теоремы:
Consistency в CAP фактически означает линеаризуемость (и ее действительно трудно достичь). Чтобы объяснить, что такое линеаризуемость, давайте посмотрим на следующую картинку:
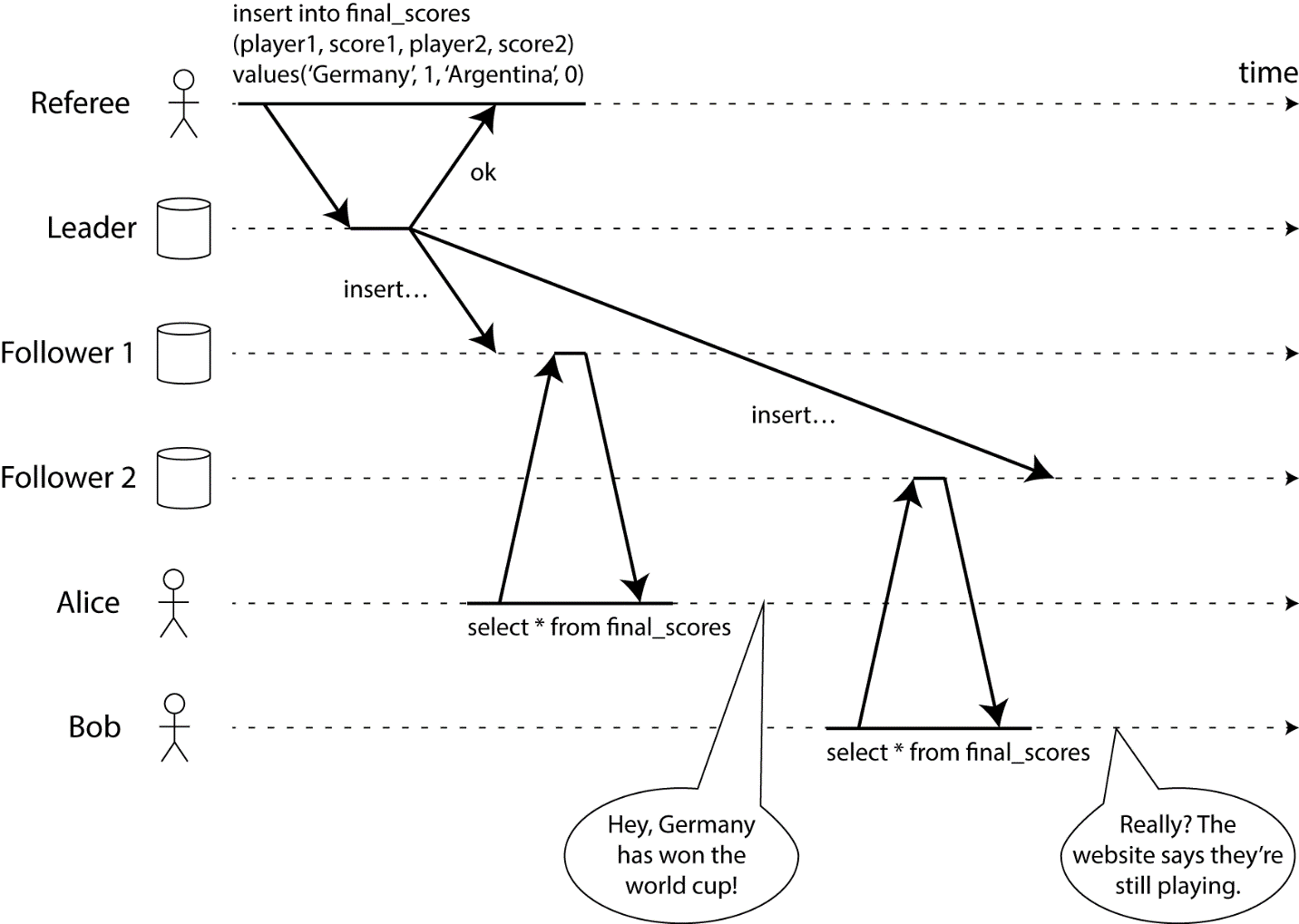
В описанном случае рефери закончил игру, но не каждый клиент получает один и тот же результат. Чтобы сделать его систему линеаризованной, нам нужно мгновенно синхронизировать данные между рефери и другими источниками данных, чтобы, когда рефери закончит игру, каждый клиент получил правильную информацию.
Availability в CAP, исходя из определения имеет две серьёзные проблемы. Первая — нет понятия частичной доступности, или какой-то её степени (проценты например), а есть только полная доступность. Вторая проблема — неограниченное время ответа на запросы, т.е. даже если система отвечает час, она всё ещё доступна.
Устойчивость к распределению не включает в себя упавшие узлы, и вот почему:
Поэтому, нужно помнить про способность системы восстанавливаться, но за рамками CAP теоремы.
Коммуникация узлов между собой обычно происходит через асинхронную сеть, которая может задерживать или удалять сообщения. Интернет и все наши центры обработки данных обладают этим свойством, и это не маловероятные инциденты, поэтому CA системы в рамках разработки рассматриваются крайне редко.
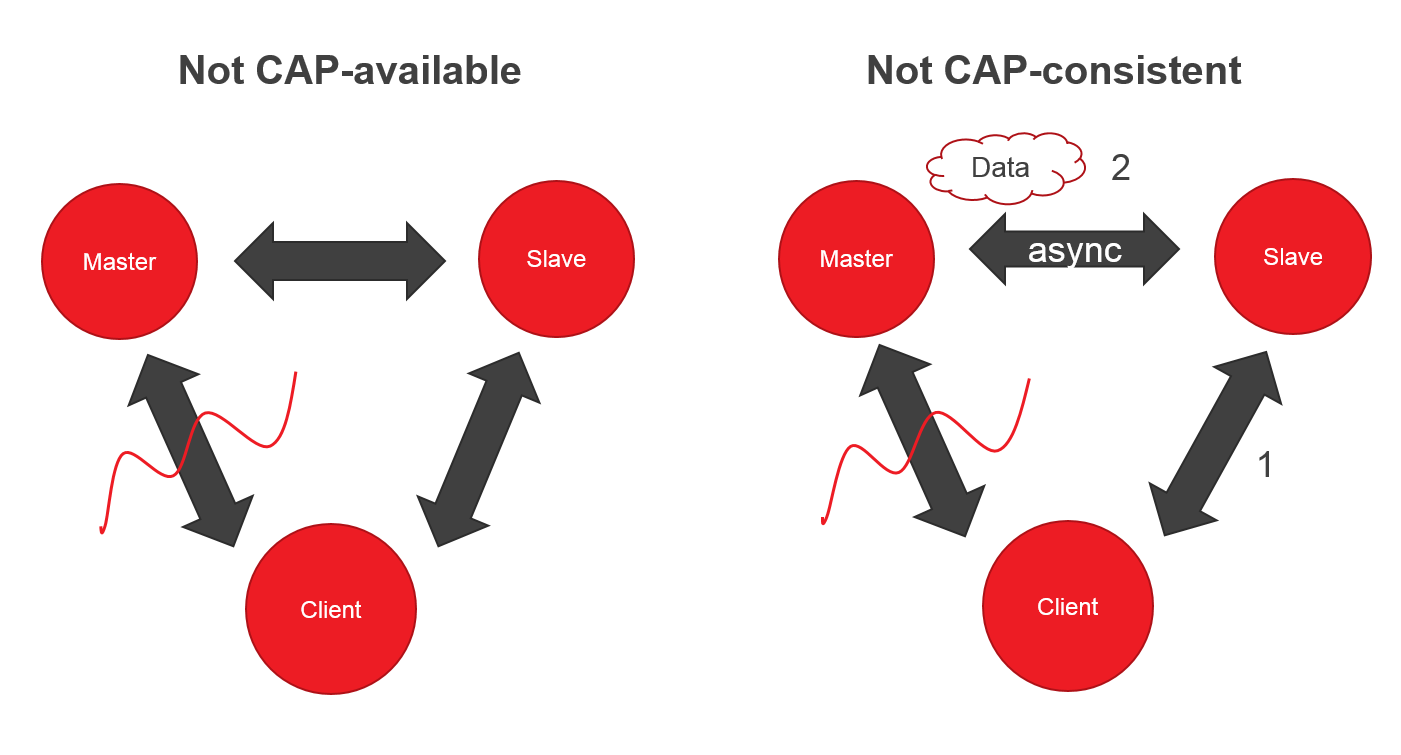
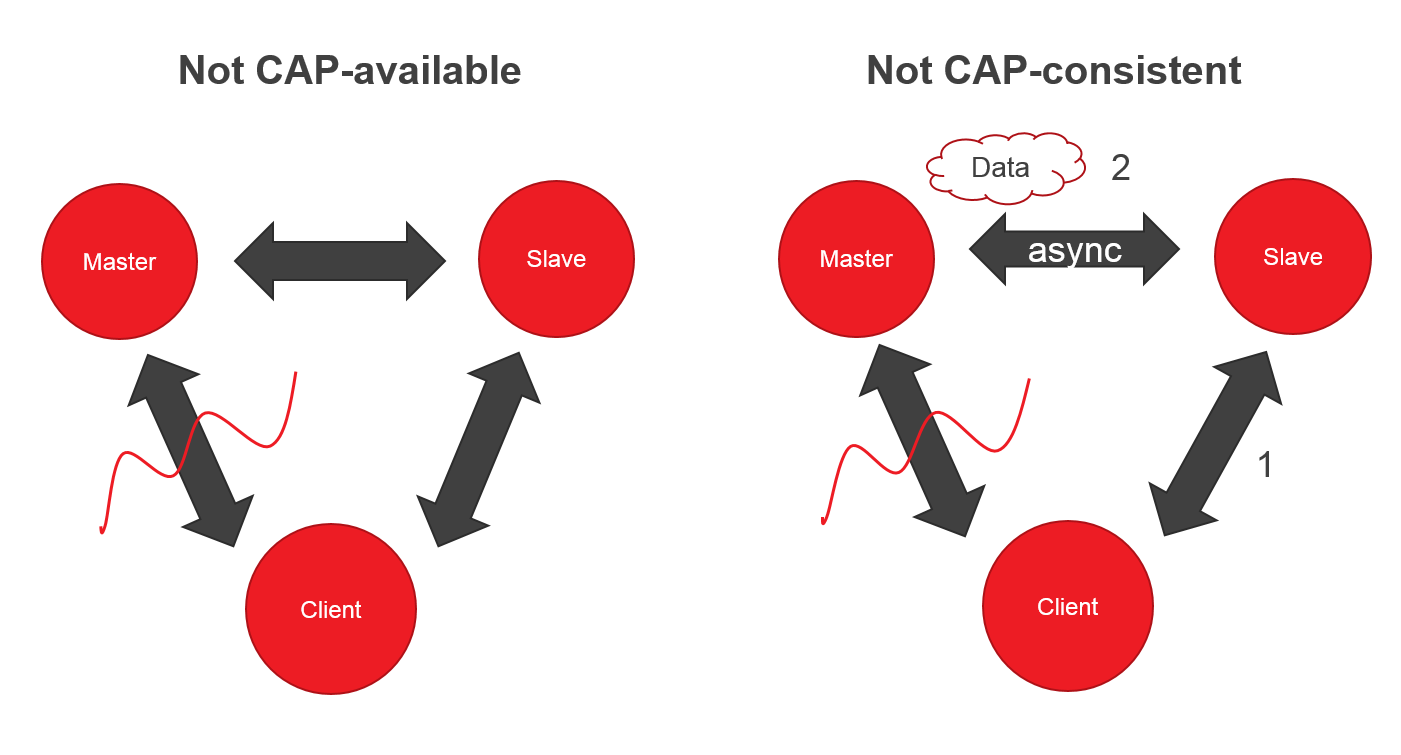
Представьте систему, в которой два узла (Master, Slave) и клиент. Если вдруг вы потеряли связь с Master, клиент может читать из Slave, но не может писать — нет CAP-availability.
Ок, вроде CP система, но если Master и Slave синхронизируются асинхронно, то клиент, может запросить данные от Slave раньше успешной синхронизации — теряем CAP-consistency.
Чистые AP системы, могут включать в себя просто 2 генератора чисел. Чистые CP системы, могут вообще не быть доступны, т.к. буду пытаться придти к согласованному состоянию и не будут нам отвечать. Идём дальше, CP системы дают нам не ожидаемый нами strong consistency, а eventual consistency. О нём поговорим чуть позже.
В конце концов, это всего лишь попытка классифицировать что-то абстрактное, поэтому вам не нужно изобретать велосипед. Я рекомендую использовать следующий подход при попытке работать с распределенными БД:
Теорема PACELC была впервые описана и формализована Даниелом Дж. Абади из Йельского университета в 2012 году. Поскольку теорема PACELC основана на CAP, она также использует его определения.
Вся теорема сводится к IF P -> (C or A), ELSE (C or L).
Latency — это время, за которое клиент получит ответ и которое регулируется каким-либо уровнем consistency. Latency (задержка), в некотором смысле представляет собой степень доступности.

BASE — это своеобразный контраст ACID, который говорит нам, что истинная согласованность не может быть достигнута в реальном мире и не может быть смоделирована в высокомасштабируемых системах.
Что стоит за BASE:
Меня несколько раз спрашивали о том, что лучше ACID или BASE — это зависит от вашего проекта. Например, если ваши данные не критичны, и пользователь действительно заботится о скорости взаимодействия, BASE будет лучшим вариантом. Если всё наоборот — ACID поможет вам сделать систему максимально надежной с точки зрения данных.
Теперь, когда мы знаем о большинстве подводных камней, давайте попробуем рассмотреть те же самые популярные системы баз данных через призму полученных знаний.
Postgresql действительно допускает множество различных конфигураций системы, поэтому их очень сложно описать. Давайте просто возьмем классическую Master-Slave репликацию с реализацией через Slony.
Давайте узнаем что-то новое о MongoDB:
Спасибо за внимание!
CAP теорема
Эта теорема была представлена на симпозиуме по принципам распределенных вычислений в 2000 году Эриком Брюером. В 2002 году Сет Гилберт и Нэнси Линч из MIT опубликовали формальное доказательство гипотезы Брюера, сделав ее теоремой.
По словам Брюера, он хотел, чтобы сообщество начало дискуссию о компромиссах в распределённых системах и уже спустя некоторое количество лет начал вносить в неё поправки и оговорки.
Что стоит за CAP
В CAP говорится, что в распределенной системе возможно выбрать только 2 из 3-х свойств:
- C (consistency) — согласованность. Каждое чтение даст вам самую последнюю запись.
- A (availability) — доступность. Каждый узел (не упавший) всегда успешно выполняет запросы (на чтение и запись).
- P (partition tolerance) — устойчивость к распределению. Даже если между узлами нет связи, они продолжают работать независимо друг от друга.
Уже есть достаточно наглядных доказательств этой теоремы, поэтому дам ссылки на университет Баумана и доказательство в виде сервиса «Позвони, напомню!».
В основном это всё треугольник
Многие статьи сводятся к вот такому вот простому треугольнику.
Применяем на практике
Для применения CAP теоремы на практике, я выбрал 3 наиболее, на мой взгляд, подходящие и достаточно популярные системы баз данных: Postgresql, MongoDB, Cassandra.
Посмотрим на Postgresql
Следующие пункты относятся к абстрактной распределенной БД Postgresql.
- Репликация Master-Slave — одно из распространенных решений
- Синхронизация с Master в асинхронном / синхронном режиме
- Система транзакций использует двухфазный коммит для обеспечения consistency
- Если возникает partition, вы не можете взаимодейстовать с системой (в основном случае)
Таким образом, система не может продолжать работу в случае partition, но обеспечивает strong consistency и availability. Это система CA!
Посмотрим на MongoDB
Следующие пункты относятся к абстрактной распределенной БД MongoDB.
- MongoDB обеспечивает strong consistency, потому что это система с одним Master узлом, и все записи идут по умолчанию в него.
- Автоматическая смена мастера, в случае отделения его от остальных узлов.
- В случае разделения сети, система прекратит принимать записи до тех пор, пока не убедится, что может безопасно завершить их.
Таким образом, система может продолжать работу в случае разделения сети, но теряется CAP-availability всех узлов. Это CP система!
Посмотрим на Cassandra
Cassandra использует схему репликации master-master, что фактически означает AP систему, в которой разделение сети приводит к самодостаточному функционированию всех узлов.
Казалось бы всё просто… Но это не так.
Проблемы CAP
На тему проблем в CAP теореме написано множество подробных и интересных статей, здесь, на Хабре, поэтому я оставлю ссылку на CAP больше не актуален и мифы о CAP теореме. Обязательно почитайте их, но относитесь к каждой статье, как к своего рода новому взгляду и не принимайте слишком близко к сердцу, потому что одни ругают, другие хвалят. Сам же я не буду слишком углублятся, а постараюсь выдать некоторую необходимую компиляцию.
Итак, проблемы CAP теоремы:
- Далёкие от реального мира определения
- В рамках разработки, выбор в основном лежит между CP и AP
- Множество систем — просто P
- Чистые AP и CP системы могут быть не тем, что ожидаешь
Что не так с определениями?
Consistency в CAP фактически означает линеаризуемость (и ее действительно трудно достичь). Чтобы объяснить, что такое линеаризуемость, давайте посмотрим на следующую картинку:
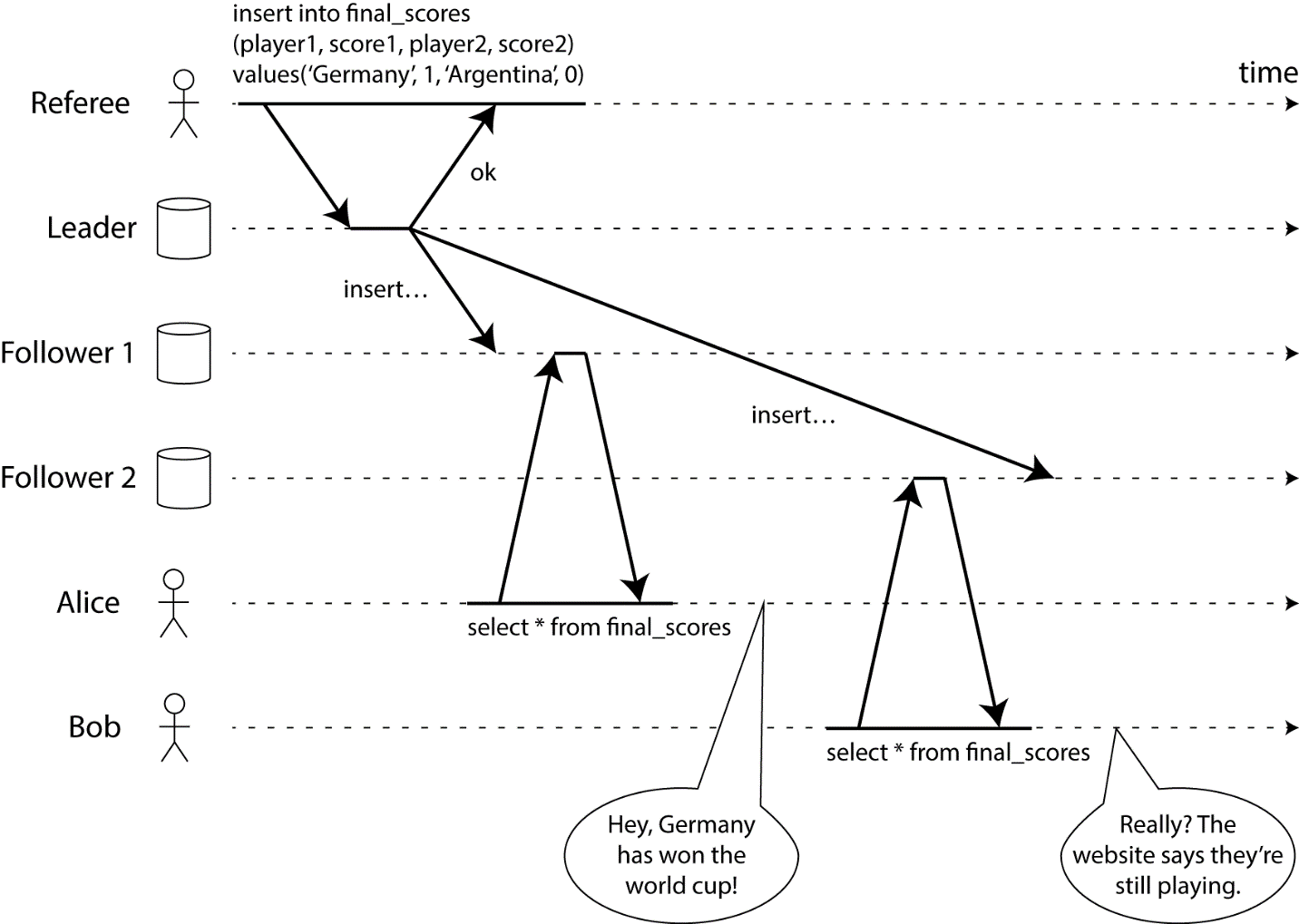
В описанном случае рефери закончил игру, но не каждый клиент получает один и тот же результат. Чтобы сделать его систему линеаризованной, нам нужно мгновенно синхронизировать данные между рефери и другими источниками данных, чтобы, когда рефери закончит игру, каждый клиент получил правильную информацию.
Availability в CAP, исходя из определения имеет две серьёзные проблемы. Первая — нет понятия частичной доступности, или какой-то её степени (проценты например), а есть только полная доступность. Вторая проблема — неограниченное время ответа на запросы, т.е. даже если система отвечает час, она всё ещё доступна.
Устойчивость к распределению не включает в себя упавшие узлы, и вот почему:
- По определению. В availability так и прописано "...every node (if not failed) always..."
- Исходя из доказательства. Доказательства CAP теоремы гласят что на узлах должен исполняться некоторый код.
- Ну и немного моих (и не только) домыслов. В случае падения узла, система может восстановиться, пообщаться с другими узлами и продолжить работу как ни в чем ни бывало. В случае разделения сети — придётся ждать восстановления соединения.
Поэтому, нужно помнить про способность системы восстанавливаться, но за рамками CAP теоремы.
AP / CP выбор
Коммуникация узлов между собой обычно происходит через асинхронную сеть, которая может задерживать или удалять сообщения. Интернет и все наши центры обработки данных обладают этим свойством, и это не маловероятные инциденты, поэтому CA системы в рамках разработки рассматриваются крайне редко.
Многие системы — просто P
Представьте систему, в которой два узла (Master, Slave) и клиент. Если вдруг вы потеряли связь с Master, клиент может читать из Slave, но не может писать — нет CAP-availability.
Ок, вроде CP система, но если Master и Slave синхронизируются асинхронно, то клиент, может запросить данные от Slave раньше успешной синхронизации — теряем CAP-consistency.
Чистые AP и CP системы
Чистые AP системы, могут включать в себя просто 2 генератора чисел. Чистые CP системы, могут вообще не быть доступны, т.к. буду пытаться придти к согласованному состоянию и не будут нам отвечать. Идём дальше, CP системы дают нам не ожидаемый нами strong consistency, а eventual consistency. О нём поговорим чуть позже.
Как с этим жить
В конце концов, это всего лишь попытка классифицировать что-то абстрактное, поэтому вам не нужно изобретать велосипед. Я рекомендую использовать следующий подход при попытке работать с распределенными БД:
- Помните об определениях CAP и об их ограничениях.
- Используйте теорему PACELC вместо CAP, она позволяет взглянуть на систему ещё с одного ракурса.
- Помните про принципы ACID / BASE и насколько они применимы к вашей системе.
- Любые телодвижения следует делать, учитывая проект, над которым вы работаете.
PACELC
Теорема PACELC была впервые описана и формализована Даниелом Дж. Абади из Йельского университета в 2012 году. Поскольку теорема PACELC основана на CAP, она также использует его определения.
Вся теорема сводится к IF P -> (C or A), ELSE (C or L).
Latency — это время, за которое клиент получит ответ и которое регулируется каким-либо уровнем consistency. Latency (задержка), в некотором смысле представляет собой степень доступности.
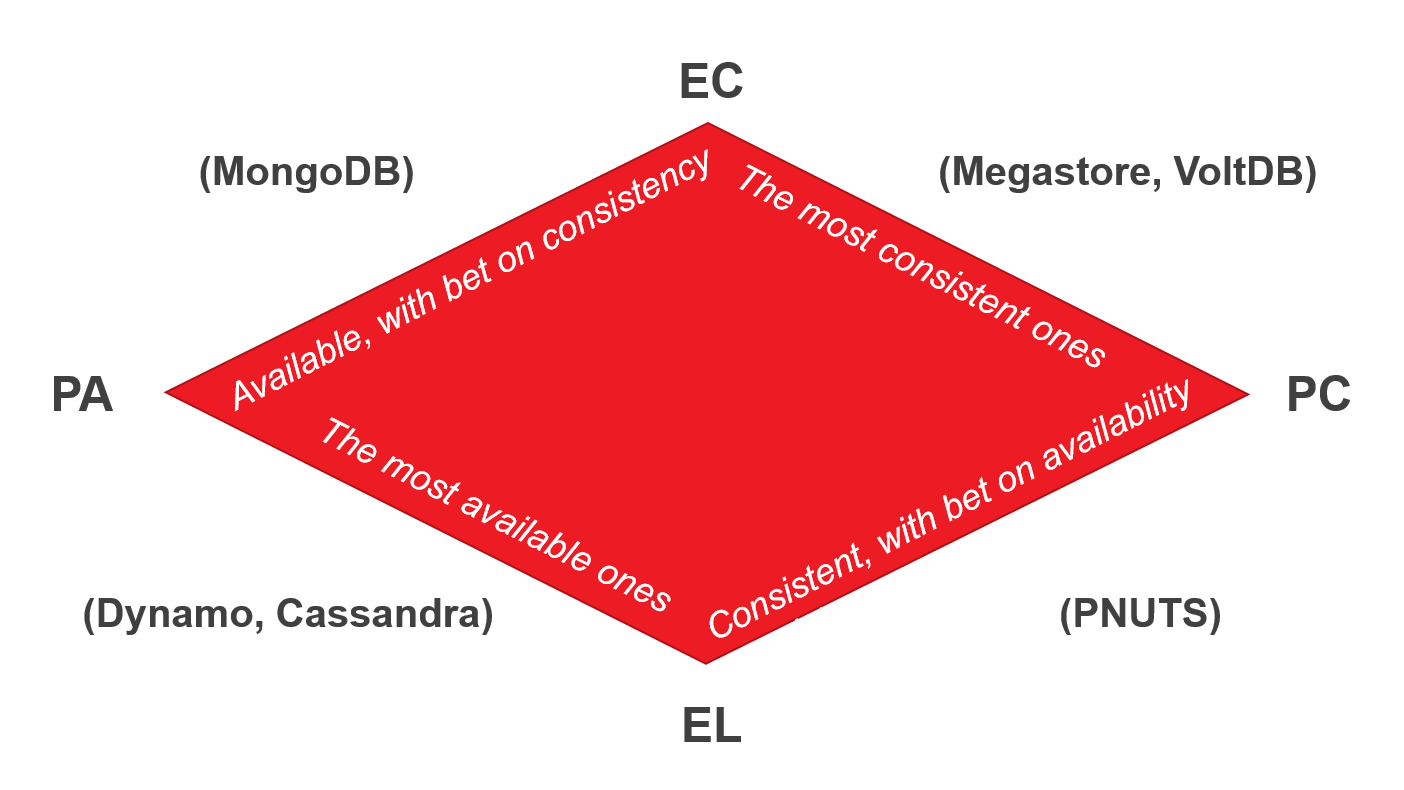
Немного о BASE
BASE — это своеобразный контраст ACID, который говорит нам, что истинная согласованность не может быть достигнута в реальном мире и не может быть смоделирована в высокомасштабируемых системах.
Что стоит за BASE:
- Basic Availability. Система отвечает на любой запрос, но этот ответ может быть содержать ошибку или несогласованные данные.
- Soft-state. Состояние системы может меняться со временем из-за изменений конечной согласованности.
- Eventual consistency (конечная согласованность). Система, в конечном итоге, станет согласованной. Она будет продолжать принимать данные и не будет проверять каждую транзакцию на согласованность.
Меня несколько раз спрашивали о том, что лучше ACID или BASE — это зависит от вашего проекта. Например, если ваши данные не критичны, и пользователь действительно заботится о скорости взаимодействия, BASE будет лучшим вариантом. Если всё наоборот — ACID поможет вам сделать систему максимально надежной с точки зрения данных.
Свежий взгляд
Теперь, когда мы знаем о большинстве подводных камней, давайте попробуем рассмотреть те же самые популярные системы баз данных через призму полученных знаний.
Postgresql
Postgresql действительно допускает множество различных конфигураций системы, поэтому их очень сложно описать. Давайте просто возьмем классическую Master-Slave репликацию с реализацией через Slony.
- Система работает в соответствии с ACID (существует пара проблем с двухфазным коммитом, но это вне рамок статьи).
- В случае разрыва связи, Slony попытается переключиться на новый Master, и у нас есть новый мастер с его согласованностью.
- Когда система функционирует в нормальном режиме, Slony делает все, чтобы достичь strong consistency. На самом деле, ACID — причина большой задержки в этой системе.
- Классификация системы — PC / EC (A).
MongoDB
Давайте узнаем что-то новое о MongoDB:
- Это ACID в ограниченном смысле на уровне документа.
- В случае распределенной системы — it's all about that BASE.
- В случае отсутствия разделений сети, система гарантирует, что чтение и запись будут согласованными.
- Если Master узел упадёт или потеряет связь с остальной системой, некоторые данные не будут реплицированы. Система выберет нового мастера, чтобы оставаться доступной для чтения и записи. (Новый мастер и старый мастер несогласованы).
- Система рассматривается как PA / EC (A), так как большинство узлов остаются CAP-available в случае разрыва. Помните, что в CAP MongoDB обычно рассматривается как CP. Создателль PACELC, Даниэль Дж. Абади, говорит, что существует гораздо больше проблем с согласованностью, чем с доступностью, поэтому PA.
Cassandra
- Предназначена для «скоростного» взаимодействия (low-latency interactions).
- ACID на уровне записи.
- В случае распределенной системы — it's all about that BASE.
- Если возникает разрыв связи, остальные узлы продолжают функционировать.
- В случае нормального функционирования — система использует уровни согласованности для уменьшения задержки.
- Система рассматривается как PA / EL (A).
Выводы
- Компромиссы распределённых систем — это то, с чего стоит начинать процесс проектирования.
- Достаточно трудно классифицировать абстрактную систему, гораздо лучше сначала сформировать требования исходя из технического задания, а уже затем правильно сконфигурировать нужную систему баз данных.
- Не перетруждайтесь, мы ведь просто любопытные разработчики, если в чем-то есть сомнения — обратитесь к эксперту.
Спасибо за внимание!
Полезные источники
dzone.com/articles/better-explaining-cap-theorem
blog.thislongrun.com/2015/03/the-confusing-cap-and-acid-wording.html
neo4j.com/blog/acid-vs-base-consistency-models-explained
databases.about.com/od/databasetraining/a/databasesbegin.htm
brooker.co.za/blog/2014/07/16/pacelc.html
www.postgresql.org/files/developer/transactions.pdf
www.airpair.com/postgresql/posts/sql-vs-nosql-ko-postgres-vs-mongo
jennyxiaozhang.com/nosql-hbase-vs-cassandra-vs-mongodb
blog.thislongrun.com/2015/04/the-unclear-cp-vs-ca-case-in-cap.html
www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
cs-www.cs.yale.edu/homes/dna/papers/abadi-pacelc.pdf
blog.thislongrun.com/2015/03/dead-nodes-dont-bite.html
queue.acm.org/detail.cfm?id=2462076
blog.thislongrun.com/2015/03/the-confusing-cap-and-acid-wording.html
neo4j.com/blog/acid-vs-base-consistency-models-explained
databases.about.com/od/databasetraining/a/databasesbegin.htm
brooker.co.za/blog/2014/07/16/pacelc.html
www.postgresql.org/files/developer/transactions.pdf
www.airpair.com/postgresql/posts/sql-vs-nosql-ko-postgres-vs-mongo
jennyxiaozhang.com/nosql-hbase-vs-cassandra-vs-mongodb
blog.thislongrun.com/2015/04/the-unclear-cp-vs-ca-case-in-cap.html
www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
cs-www.cs.yale.edu/homes/dna/papers/abadi-pacelc.pdf
blog.thislongrun.com/2015/03/dead-nodes-dont-bite.html
queue.acm.org/detail.cfm?id=2462076
