
Всем разработчикам известна ситуация, когда приложение заглючило и пользователь не может сделать то, что ему нужно. Причины разные: пользователь ввёл неправильные данные, у него медленный интернет и многое другое. Без системы логирования разобрать эти ошибки сложно, а порой невозможно. С другой стороны, система логирования — хороший индикатор проблемных мест в работе системы. Я расскажу, как построить систему логирования в своём проекте (да, ещё раз). В статье расскажу об Elasticsearch + Logstash + Kibana и Prometheus и как их заинтегрировать со своим приложением.
2ГИС — это веб-карта и справочник организаций. У фирмы может быть дополнительный контент — фотографии, скидки, логотип и прочее. И чтобы владельцам бизнеса было удобно управлять этим добром, был создан Личный кабинет. С помощью Личного кабинета можно:
- Добавлять или изменять контакты организации
- Загружать фотографии, логотип
- Смотреть, что делают пользователи при открытии организации и многое другое.
Личный кабинет состоит из двух проектов: бэкенд и фронтенд. Бэкенд написан на PHP версии 5.6, используется фреймворк Yii 1 (да, да). Активно используем Сomposer для управления зависимостями в проекте, автозагрузку классов в соответствии PSR-4, namespace, trait. В будущем планируем обновлять версию PHP до семёрки. В качестве веб-сервера используем Nginx, данные храним в MongoDB и PostgreSQL. Фронтенд написан на JavaScript, используем фреймворк нашего приготовления Catbee. Бэкенд предоставляет API для фронтенда. Далее в докладе буду говорить исключительно про бэкенд.
Вот схема наших интеграций. Нам это напоминает звёздное небо. Если приглядеться, можно увидеть Большую медведицу:
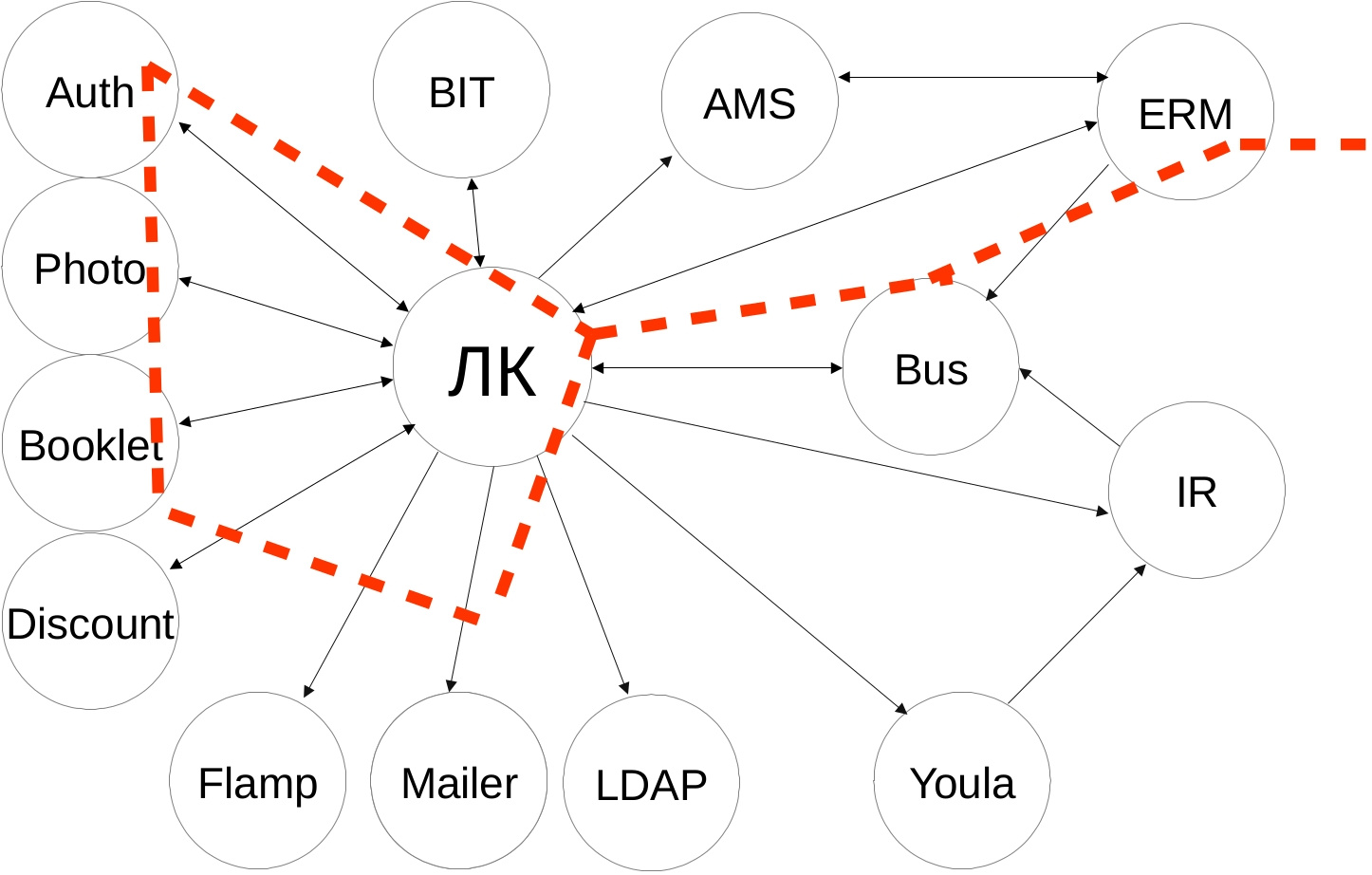
Внешние сервисы разнородные — разрабатываются дюжиной команд, со своим стеком технологий и API. Сценарии интеграции получаются нетривиальными — сначала ходим в один сервис, получаем данные, накладываем свою бизнес-логику, идём ещё в несколько сервисов с новыми данным, объединяем ответы и отдаём результат на фронтенд. И если у пользователя возникает проблема и он не может осуществить желаемое, например, продлить рекламную кампанию, то без системы логирования нам не понять, где была проблема — либо неправильно отправляем данные во внешний сервис, либо неправильно интерпретируем ответ, либо внешний сервис недоступен, либо неправильно накладываем свою бизнес-логику.
У нас было логирование ошибок, но с появлением новых сервисов стало всё труднее отслеживать интеграции и отвечать на запросы техподдержки о возникающей проблеме. Поэтому мы выработали новые требования к нашей системе логирования:
- Нужно больше контекста об ошибках — что произошло и у какого пользователя.
- Собирать входящие запросы в удобном виде.
- Если методы долго отвечают, то нужно уведомить команду об этом.
Логирование ошибок
Исторически сложилось, что в нашей компании для сбора и просмотра логов используется стэк технологий Elasticsearch + Logstash + Kibana, сокращённо ELK. Elasticsearch — NoSQL-хранилище документов, с возможностью полнотекстового поиска. Logstash настроен на приём логов по TCP/UDP-протоколам, читает сообщения из Redis и сохраняет в Elasticsearch. Kibana предоставляет визуальный интерфейс для поиска и отображения собранных данных.
Если у клиента идёт что-то не так, то он обращается в техподдержку из своего аккаунта с описанием проблемы. У нас было логирование ошибок, но не было ни email пользователя, ни вызванного API-метода, ни стэка вызова. В сообщениях была лишь строка из необработанного Exception вида "Запрос вернул некорректный результат". Из-за этого мы искали проблему по времени обращения клиента и ключевым словам, что не всегда было точно — клиент мог обратиться через день, и помочь было очень сложно.
Помучавшись, мы решили, что надо что-то делать и добавили необходимую информацию — email пользователя, API-метод, тело запроса, стэк вызова и наши контроллер и экшен, которые обрабатывали запрос. В итоге мы упростили жизнь техподдержке и себе — ребята нам скидывают email пользователя, а мы по нему находим записи в логах и разбираемся с проблемой. Мы точно знаем, у какого пользователя была проблема, какой метод был вызван и какая часть нашего кода обработала его. Никаких сравнений по времени обращения!
Сообщения об ошибках отправляем во время работы приложения по протоколу UDP в формате Graylog Extended Log Format, или сокращенно GELF. Формат хорош тем, что сообщения могут быть сжаты популярными алгоритмами и разделены на части, тем самым снижая объем передаваемого трафика из нашего приложения в Logstash. Протокол UDP пусть и не гарантирует доставку сообщений, но накладывает минимум накладных расходов на время ответа, поэтому такой вариант нас устраивает. В приложении используем библиотеку gelf-php, которая предоставляет возможности по отправке логов в разных форматах и протоколах. Рекомендую использовать её в своих PHP-приложениях.
Вывод — если ваше приложение работает с внешними пользователями и вам нужно искать ответы на возникающие вопросы техподдержки, смело добавляйте информацию, которая поможет идентифицировать клиента и его действия.
Пример нашего сообщения:
{
"user_email": "test@test.ru",
"api_method": "orgs/124345/edit",
"method_type": "POST",
"payload": "{'name': 'Новое название'}",
"controller": "branches/update",
"message": "Undefined index: 'name'
File: /var/www/protected/controllers/BranchesController.php
Line: 50"
}Логирование запросов
Логирования запросов в структурированном виде и сбор статистики отсутствовали, поэтому было непонятно, какие методы чаще всего вызываются и сколько по времени отвечают. Это привело к тому, что мы не могли:
- оценить допустимое время ответа методов.
- причину возникновения тормозов — на нашей стороне или на стороне внешнего сервиса (помните схему со звёздным небом?)
- как можно оптимизировать наш код, чтобы уменьшить время ответа.
В рамках данной задачи нам предстояло решить вопросы:
- выбор параметров ответа для логирования
- отправка параметров в Logstash
Мы используем веб-сервер Nginx, и он умеет писать access-логи в файл. Для решения первой задачи указали новый формат сохранения логов в конфигурации:
log_format main_logstash
'{'
'"time_local": "$time_local",'
'"request_method": "$request_method",'
'"request_uri": "$request_uri",'
'"request_time": "$request_time",'
'"upstream_response_time": "$upstream_response_time",'
'"status": "$status",'
'"request_id": "$request_id"'
'}';
server {
access_log /var/log/nginx/access.log main_logstash;
}Большинство метрик, думаю, вопросов не вызывает, расскажу подробнее про наиболее интересную — $request_id. Это уникальный идентификатор, UUID версии 4, который генерируется Nginx для каждого запроса. Данный заголовок мы пробрасываем в запросе во внешние сервисы и можем отследить ответ запроса в логах других сервисах. Очень удобно при поиске проблем в других сервисах — никаких сравнений по времени, урлу вызванного метода.
Для отправки логов в Logstash используем утилиту Beaver. Устанавливается на все ноды приложения, с которых планируется отправка логов. В конфигурации указывается файл, который будет парситься для получения новых логов, указываются поля, которые будут отправляться с каждым сообщением. Сообщения отправляются в Redis-кластер, из которого Logstash забирает данные. Вот наша конфигурация Beaver:
[/var/log/nginx/access.log]
type: nginx_accesslog
add_field: team,lk,project,backend
tags: nginx_jsonПо полям type и tags в Logstash по нашим значениям сделана фильтрация и обработка логов, у вас эти значения могут быть свои. Кроме того, добавляем поля team и project, чтобы можно было идентифицировать команду и проект, которым принадлежат логи.
Научившись собирать access-логи, мы перешли к определению SLA методов. SLA, договор на уровень оказания услуг, в нашем случае мы гарантируем, что 95-ый перцентиль по времени ответа методов будет не более 0.4 секунд. Если не укладываемся в допустимое время, то значит, что в приложении либо одна из интеграций тормозит и обращаемся к связанной команде, либо что-то не так в нашем коде и необходима оптимизация.
Вывод по сбору access-логов — мы определили наиболее часто вызываемые методы и их допустимое время ответа.
Вот примеры наших отчётов на одном из измеряемых методов. Первый — чему равны 50, 95 и 99 перцентили времени ответа и среднее время ответа:

Диаграмма статусов ответа:
Среднее время ответа за промежуток времени:

Оповещения команды о падении SLA
После сбора логов нам пришла идея, что нужно оперативно узнавать о падении скорости. Постоянно держать открытым браузер с Kibana, нажимать F5, сравнивать в уме текущее значение 95-ого перцентиля с допустимым оказалось не очень практично — есть много других интересных задач в проекте. Поэтому для формирования оповещений мы добавили интеграцию с системой Prometheus. Prometheus — это система с открытым исходным кодом для сбора, хранения и анализа метрик работающего приложения. Официальный сайт с документацией.
Нам система понравилась тем, что в случае срабатывания триггера можно отправить оповещение на почту. Возможность предоставляется из коробки, без заморочек с доступами к серверам и без написания кастомных скриптов для формирования оповещения. Система написана на языке Go, создатели — компания SoundCloud. Существуют библиотеки для сбора метрик на разными языками — Go, PHP, Python, Lua, C#, Erlang, Haskell и другие.
Я не буду рассказывать, как установить и запустить Prometheus. Если вам интересно это, предлагаю почитать статью. Я сделаю упор на тех моментах, которые имели практическое значение для нас.
Схема интеграции выглядит так — клиентское приложение по адресу отдаёт набор метрик, Prometheus заходит на данный адрес, забирает и сохраняет метрики в своём хранилище.
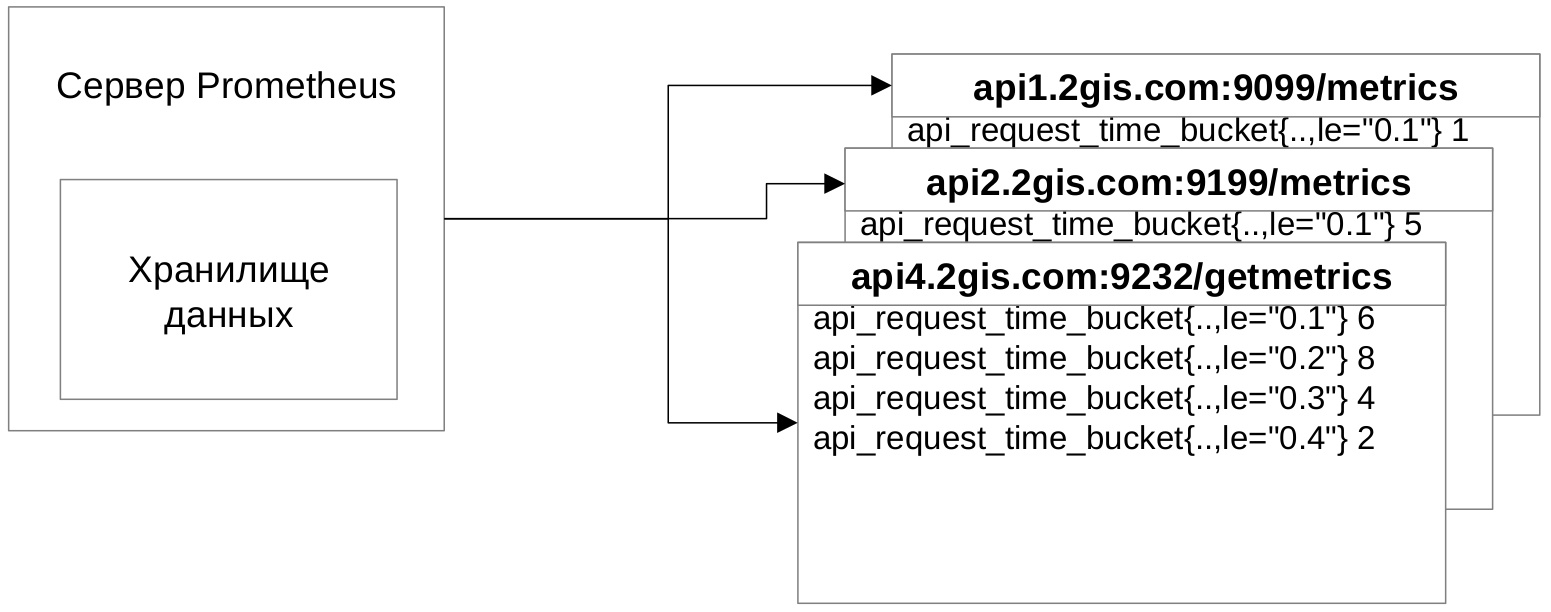
Давайте разберёмся, как выглядят метрики.
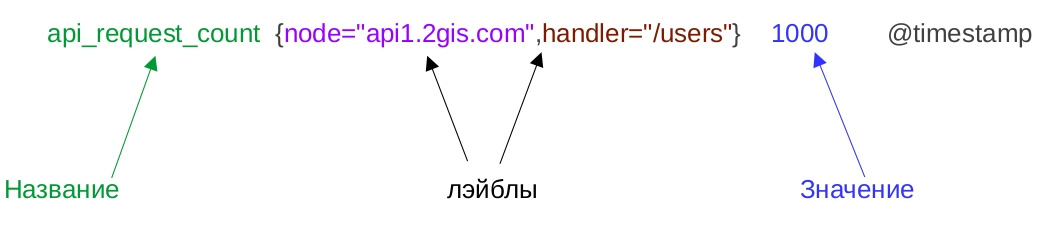
- Название — это идентификатор изучаемой характеристики. Например, количество входящих запросов.
- У метрики в момент времени есть определённое значение. Время проставляет Prometheus при сборе метрик.
- У метрики могут быть лейблы. Они содержат дополнительную информацию о собранном числе. В примере указана нода приложения и API-метод. Основная фишка лейблов в том, что по ним можно осуществлять поиск и делать необходимые выборки данных.
Хранилища данных формата "время — значение" называются Базами данных временных рядов. Это узкоспециализированные NoSQL-хранилище для хранения изменяющихся во времени показателей. Например, количество пользователей на сайте в 10 часов утра, за день, за неделю и так далее. Из-за особенностей решаемых задач и способа хранения такие БД обеспечивают высокую производительность и компактное хранение данных.
Prometheus поддерживает несколько типов метрик. Рассмотрим первый тип, называется Счётчик. Значение Счётчика при новых измерениях всегда растёт вверх. Идеально подходит для измерения общего количества входящих запросов за всю историю — не может быть такого, чтобы сегодня было 100 суммарно запросов, а завтра количество уменьшилось до 80.
Но как быть с измерением времени ответа? Оно не обязательно растёт вверх, более того, может упасть вниз, быть какое-то время на одном уровне, а потом вырасти вверх. Изменение может произойти менее чем за 10 секунд, и нам хочется видеть динамику изменения времени ответа для каждого запроса. К счастью, есть тип Гистограмма. Для формирования необходимо определить интервал измерения времени ответа. В примере возьмём от 0.1 до 0.5 секунды, всё что больше будем считать как Бесконечность.
Вот как выглядит начальное состояние Гистограммы:
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.1"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.2"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.3"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.4"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.5"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="+Inf"} 0
api_request_time_sum{node="api1.2gis.com",handler="/users"} 0
api_request_time_count{node="api1.2gis.com",handler="/users"} 0На каждое значение из интервала мы создаём Счётчик по определённым правилам:
- В названии обязательно должен быть постфикс _bucket
- Должен быть лейбл le, в котором указывается значение из интервала. Плюс должен быть Счётчик со значением +Inf.
- Должны быть Счётчики с постфиксом _sum и _count. В них сохраняется суммарное общее время всех ответов и количество запросов. Нужны для удобного подсчёта 95-ого перцентиля средствами Prometheus.
Давайте разберёмся, как правильно заполнять Гистограмму временем ответа. Для этого нужно найти серии, у которых значение лейбла le больше либо равно времени ответа, и их увеличить на единицу. Предположим, что наш метод ответил за 0.4 секунды. Мы находим те Счётчики, у которых лейбл le больше либо равен 0.4, и к значению добавляем единицу:
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.1"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.2"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.3"} 0
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.4"} 1
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="0.5"} 1
api_request_time_bucket{node="api1.2gis.com",handler="/users",le="+Inf"} 1
api_request_time_sum{node="api1.2gis.com",handler="/users"} 0.4
api_request_time_count{node="api1.2gis.com",handler="/users"} 1
Если метод отвечает за 0.1 секунду, то мы увеличиваем все серии. Если отвечает за 0.6 секунд, то увеличиваем лишь счётчик со значением "+Inf". Не забываем увеличивать счётчики api_request_time_sum и api_request_time_count. С помощью Гистограммы можно измерять время ответа, которое за короткий промежуток может часто меняться.
Prometheus поддерживает ещё два типа метрик — Шкала и Сводка результатов. Шкала описывает характеристику, значение которой может как увеличиваться, так и уменьшаться. В задачах не используем, так как такие показатели у нас не измеряются. Сводка результатов — это расширенная Гистограмма, которая сохраняет вычисляемые на стороне приложения квантили. Теоретически можно было бы рассчитывать 95-процентный перцентиль, или 0.95 квантиль, но это добавило бы кода по подсчёту на клиентской стороне и лишило бы гибкости в отчётах — могли бы использовать только вычисленные нами квантили. Поэтому свой выбор остановили на Гистограмме.
Формирование Гистограммы мы реализовали в Nginx на языке Lua. Нашли готовый проект на GitHub, который подключается в конфигурации Nginx и формирует Гистограмму описанным выше способом. Собирать данные нам необходимо с наиболее часто вызываемых методов, которые, как вы помните, мы определили после отправки access-логов в Logstash. Поэтому потребовалось добавить бизнес-логики по проверке, нужно запрос логировать или нет.
В итоге интеграция заняла неделю, вместе с изучением матчасти Prometheus и основ языка Lua. На наш взгляд, это отличный результат. Ещё очень здорово, что на время ответа добавляется незначительный, порядка 5-10 мс, оверхеад из-за формирования Гистограмм и проверки нашей бизнес-логики, что меньше, чем предполагали.
Но есть и минусы у этого решения — не учитываем время запросов, у которых статус не 200. Причина — директива log_by_lua, в которую мы добавили логирование, в таком случае не вызывается. Вот подтверждение. С другой стороны, нам время ответа таких запросов неинтересно, потому что это ошибка. Ещё один минус — Гистограмма хранится в shared-памяти Nginx. При перезапуске Nginx память очищается, и собранные метрики теряются. С этим тоже можно жить — перезапускать Nginx командой reload, и настроить Prometheus, чтобы он чаще забирал метрики.
Вот конфигурация Nginx для создания Гистограммы:
lua_shared_dict prometheus_metrics 10M;
init_by_lua '
prometheus = require("prometheus").init("prometheus_metrics")
prometheusHelper = require("prometheus_helper")
metric_request_time = prometheus:histogram("nginx_http_request_time", {"api_method_end_point", "request_method"})
'Здесь мы выделяем общую память, подключаем библиотеку и хэлпер с нашей бизнес-логикой и инициализируем Гистограмму — присваиваем имя и лейблы.
За логирование запроса отвечает данная конфигурация:
location / {
log_by_lua '
api_method_end_point = prometheusHelper.convert_request_uri_to_api_method_end_point(ngx.var.request_uri, ngx.var.request_method)
if (api_method_end_point ~= nil) then
metric_request_time:observe(tonumber(ngx.var.request_time),{api_method_end_point, ngx.var.request_method})
'
}Здесь мы в директиве log_by_lua проверяем, нужно ли логировать запрос, и если да, то добавляем его время ответа в Гистограмму.
Метрики отдаются через Nginx по endpoint:
server {
listen 9099;
server_name api1.2gis.com;
location /metrics {
content_by_lua 'prometheus:collect()';
}
}Теперь нужно в конфигурации Prometheus указать ноды нашего приложения для сбора метрик:
- targets:
- api1.2gis.com:9099
- api2.2gis.com:9199
labels:
job: bizaccount
type: nginx
role: monitoring-api-methods
team: lk
project: backendВ разделе targets указываются endpoint наших нод, в разделе labels — лейблы, которые добавляются к собираемым метрикам. По ним определяем назначение метрики и отправителя.
Сбор метрик у нас настроен каждые 15 секунд — Prometheus заходит на указанные ноды и сохраняет себе метрики.
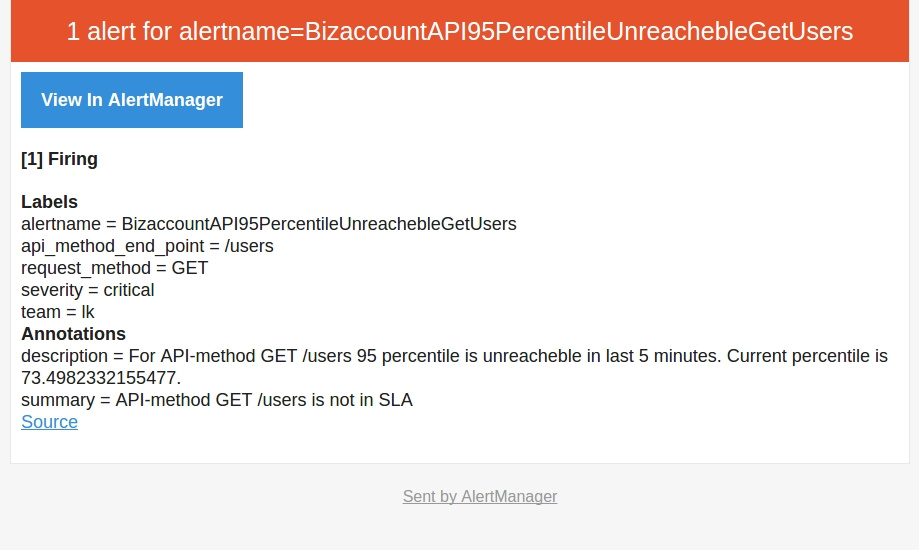
После того, как мы разобрались с метриками, научились их собирать, отдавать в Prometheus, мы перешли к тому, ради чего затевалась интеграция — оповещения на командную почту при падении скорости работы нашего приложения. Вот пример оповещения:
ALERT BizaccountAPI95PercentileUnreachebleGetUsers
IF (sum(rate(nginx_http_request_time_bucket{le="0.4",api_method_end_point="/users",request_method="GET"}[5m])) by (api_method_end_point, request_method)
/
sum(rate(nginx_http_request_time_count{api_method_end_point="/users",request_method="GET"}[5m])) by (api_method_end_point, request_method)) * 100 < 95
FOR 5m
LABELS { severity = "critical", team = "lk"}
ANNOTATIONS {
summary = "API-method {{ $labels.request_method}} {{ $labels.api_method_end_point}} is not in SLA",
description = "For API-method {{ $labels.request_method}} {{ $labels.api_method_end_point }} 95 percentile is unreacheble in last 5 minutes. Current percentile is {{ $value }}.",
}У Prometheus лаконичный язык формирования запросов, при помощи которого можно выбирать значения метрик за период и фильтровать по лейблам. В директиве IF с помощью конструкций языка указываем условие срабатывания триггера — если за 0.4 секунды отвечают менее 95 процентов запросов за последние 5 минут. Считается это отношением. В числителе мы высчитываем, сколько запросов укладываются за 0.4 секунды за последние 5 минут:
sum(rate(nginx_http_request_time_bucket{le="0.4",api_method_end_point="/users",request_method="GET"}[5m])) by (api_method_end_point, request_method)В знаменателе считаем общее количество запросов за последние 5 минут:
sum(rate(nginx_http_request_time_count{api_method_end_point="/users",request_method="GET"}[5m])) by (api_method_end_point, request_method)Полученную дробь умножаем на 100 и получаем процент запросов, которые отвечают за 0.4 секунды. Функция rate здесь возвращает время ответа за каждый момент в указанный интервале. Функция sum суммирует полученный ряд. Оператор by — это аналог оператора GROUP BY, который выполняет группировку по указанным лейблам.
В разделе FOR указывается интервал между первым срабатываем триггера и моментом, когда нужно отправить оповещения. У нас интервал равен 5 минутам — если за 5 минут ситуация не меняется, то нужно отправить оповещение. В разделе LABELS указываются лейблы с указанием команды и критичности проблемы. В разделе ANNOTATIONS указывается проблемный метод и какой процент запросов отвечает за 0.4 секунды.
В случае возникновения повторяющихся оповещений Prometheus умеет делать дедупликацию, и отправит одно оповещение на командную почту. И это всё из коробки, нам нужно лишь указать правила и интервал срабатывания триггера.
Оповещения в Prometheus получились именно такими, какими мы и хотели — с понятной конфигурацией, без своих велосипедов с дедупликацией оповещений и без реализации логики срабатывания оповещения на каком-либо языке.
Вот как выглядит сообщение:
Заключение
Мы улучшили нашу систему логирования и теперь у нас не возникает проблем с недостатком информации.
- При возникновении ошибки мы обладаем достаточной информацией о проблеме. Теперь на 99 процентов запросов техподдержки мы имеет представление, что произошло у пользователя и точно сориентировать техподдержку о проблеме и возможных сроках исправления.
- С помощью оповещений мы определяем проблемные места в производительности приложения и оптимизируем их, делая приложение быстрее и надёжнее.
- Через Prometheus мы оперативно узнаём о падении скорости, а уже после смотрим в ELK и начинаем детально изучать, что случилось. У связки ELK + Prometheus мы видим большой потенциал, планируем добавить оповещения в случае увеличения ошибок и мониторинг внешних сервисов.
