Перевод внезапно удачно попал в струю других датасайенсных туториалов на хабре. :)
Этот написан Виком Паручури, основателем Dataquest.io, где как раз и занимаются подобного рода интерактивным обучением data science и подготовкой к реальной работе в этой области. Каких-то эксклюзивных ноу-хау здесь нет, но очень подробно рассказан процесс от сбора данных до первичных выводов о них, что может быть интересно не только желающим составить резюме на data science, но и тем, кто просто хочет попробовать себя в практическом анализе, но не знает, с чего начать.
Data science-компании всё чаще смотрят портфолио, когда принимают решение о приёме на работу. Это, в частности, из-за того, что лучший способ судить о практических навыках — именно портфолио. И хорошая новость в том, что оно полностью в вашем распоряжении: если постараетесь – сможете собрать отличное портфолио, которым будут впечатлены многие компании.
Первый шаг в высококачественному портфолио – это понимание, какие умения в нём надо продемонстрировать.
Основные навыки, которые компании хотят видеть в data scientist-ах, и, соответственно, продемонстрированными в их портфолио, это:
- Способность общаться
- Способность сотрудничать с другими
- Техническая компетенция
- Способность делать заключения на основе данных
- Мотивация и способность проявить инициативу.
Всякое хорошее портфолио содержит несколько проектов, каждый из которых может демонстрировать 1-2 данных пункта. Это первый пост из цикла, который будет рассматривать получение гармоничного data science-портфолио. Мы рассмотрим, как сделать первый проект для портфолио, и как рассказать хорошую историю через данные. В конце будет проект, который поможет раскрыть вашу способность общаться и способность делать заключения на основе данных.
Я точно не буду переводить весь цикл, но планирую коснуться интересного туториала о машинном обучении оттуда же.
История через данные
В принципе, Data science вся состоит из общения. Вы видите в данных какую-то закономерность, потом ищете эффективный способ объяснить эту закономерность другим, потом убеждаете их предпринять те действия, которые вы считаете нужными. Одно из важнейших умений в data science — наглядно рассказать историю через данные. Удачная история может лучше преподнести ваши догадки и помочь другим понять ваши идеи.
История в контексте data science — это изложение всего того, что вы нашли и того, что это значит. Примером может служить открытие того, что прибыль вашей компании снизилась на 20% за последний год. Просто указать на этот факт недостаточно: надо объяснить, почему прибыль упала и что с этим делать.
Основные компоненты историй в данных это:
- Понимание и формирование контекста
- Исследование под разными ракурсами
- Использование подходящих визуализаций
- Использование различных источников данных
- Связное изложение.
Лучшее средство доходчиво рассказать историю через данные — это Jupyter notebook. Если вы с ним незнакомы — тут хороший туториал. Jupyter notebook позволяет интерактивно исследовать данные и публиковать их на различных сайтах, включая гитхаб. Публикация результатов полезна для сотрудничества — ваш анализ смогут расширить другие люди.
Мы в этом посте будем использовать Jupyter notebook вместе с питоновскими библиотеками типа Pandas и matplotlib.
Выбор темы вашего data science-проекта
Первый шаг к созданию проекта — это определиться с темой. Стоит выбрать что-то, что вам интересно и что есть желание поисследовать. Всегда видно, когда люди сделали проект просто чтобы было, а когда потому, что им действительно интересно было покопаться в данных. На этом шаге имеет смысл потратить время, чтобы точно найти что-то увлекающее.
Хороший способ найти тему — полазить по разным датасетам и посмотреть, что есть интересного. Вот хорошие места для начала:
- Data.gov — содержит данные правительства
- /r/datasets — сабреддит с сотнями интересных датасетов
- Awesome datasets — список датасетов, хостится на гитхабе
- 17 places to find datasets -пост 17-ю источниками данных и образцами датасетов из каждого
В реальной data science часто не получается найти полностью подготовленный для ваших изысканий датасет. Возможно, придётся агрегировать различные источники данных или серьёзно их чистить. Если тема вам очень интересна — имеет смысл сделать то же и здесь: лучше покажете себя в итоге.
Мы для поста будем использовать данные о Нью-Йоркских общеобразовательных школах, отсюда.
На всякий случай, приведу пример более близких к нам (россиянам) аналогичных датасетов:
- Всякие правительственные датасеты.
- Датасеты по Москве
- Хаб-агрегатор открытых данных. Есть там данные и из выше перечисленных, но не все, зато есть много других.
Выбор темы
Важно сделать весь проект от начала до конца. Для этого полезно ограничить область изучения так, чтобы точно знать, что вы закончите. Проще добавить что-то к уже завершённому проекту, чем пытаться закончить то, что уже попросту надоело доводить до конца.
В нашем случае, мы будем изучать оценки ЕГЭ старшеклассников вместе с различной демографической и прочей информацией о них. ЕГЭ или Единый Государственный экзамен — это тест, который старшеклассники сдают перед поступлением в колледж. Колледжи учитывают оценки, когда принимают решение о зачислении, так что хорошо сдать его — весьма важно. Экзамен состоит из трёх частей, каждая из которых оценивается в 800 баллов. Общий балл в итоге 2400 (хотя иногда это плавало туда-сюда - в датасете всё по 2400). Старшие школы часто оцениваются по среднему баллу ЕГЭ и высокий средний балл обычно является показателем того, насколько хорош школьный округ.
Были определённые жалобы на несправедливость оценок некоторым нацменьшинствам в США, поэтому анализ по Нью-Йорку поможет пролить свет на справедливость ЕГЭ.
Датасет с оценками ЕГЭ — здесь, а датасет с информацией по каждой школе — здесь. Это будет основой нашего проекта, но нам понадобится ещё информация, чтобы сделать полноценный анализ.
В оригинале экзамен называется SAT — Scholastic Aptitude Test. Но поскольку он практически по смыслу идентичен нашему ЕГЭ — решил так его и переводить.
Собираем данные
Как только есть хорошая тема — полезно просмотреть другие датасеты, которые могут расширить тему или помочь углубить исследование. Лучше делать это в начале, чтобы было как можно больше данных для исследования по мере создания проекта. Если данных будет мало — есть шанс, что вы сдадитесь слишком рано.
В нашем случае, есть ещё несколько датасетов по этой теме на том же сайте, которые освещают демографическую информацию и результаты экзаменов.
Вот ссылки на все датасеты, что будем использовать:
- Оценки ЕГЭ по школам– оценки за ЕГЭ по каждой школе в Нью-Йорке.
- Школьная посещаемость – информация о посещаемости по каждой школе Нью-Йорка.
- Результаты экзамена по математике – результаты экзамена по математике по каждой школе Нью-Йорка.
- Размер класса – информация о размере класса по каждой школе Нью-Йорка.
- Результаты экзамена УП – Результаты экзамена по углублённой программе. Прохождение этой программы может дать преимущества при поступлении.
- Информация о выпускниках –процент выпустившихся учеников и прочая сопутствующая информация.
- Демография – демографическая информация по каждой школе.
- Школьные опросы – опросы родителей, учителей и учеников в каждой школе.
- Карта школьных округов – содержит информацию о форме школьных округов, так что мы сможем нанести их на карту.
Все эти данные связаны между собой, и мы сможем их объединить прежде, чем начнём анализ.
Сбор вводной информации
Прежде, чем погружаться в анализ данных, полезно выяснить общую информацию о предмете. В нашем случае, мы знаем кое-что, что может оказаться полезным:
- Нью-Йорк поделен на 5 районов, которые являются практически отдельными областями.
- Школы в Нью-Йорке поделены на несколько школьных округов, каждый может содержать десятки школ.
- Не все школы в датасете — старшие, так что, возможно, потребуется предварительно почистить данные
- Каждая школа в Нью-Йорке имеет уникальный код DBN или районно-окружной номер.
- Агрегируя данные по округам, мы сможем использовать их картографическую информацию, чтобы на карте изобразить отличия между ними.
То, что я перевёл как "Районы" на самом деле называется в NYC "боро", и столбцы, соответственно, называются Borough.
Понимаем данные
Чтобы действительно понять контекст данных, нужно потратить время и об этих данных почитать. В нашем случае, каждая вышеприведённая ссылка содержит описание данных для каждой колонки. Похоже, у нас есть данные по оценкам ЕГЭ старшеклассников, вместе с другими датасетами, которые содержат демографическую и прочую информацию.
Запустим кое-какой код, чтобы прочесть данные. Используем Jupyter notebook для наших исследований. Нижеприведённый код:
- Пробежится по каждому скачанному файлу
- Прочитает каждый в датафрейм Pandas
- Положит каждый датафрейм в python-словарь.
import pandas
import numpy as np
files = ["ap_2010.csv", "class_size.csv", "demographics.csv", "graduation.csv", "hs_directory.csv", "math_test_results.csv", "sat_results.csv"]
data = {}
for f in files:
d = pandas.read_csv("schools/{0}".format(f))
data[f.replace(".csv", "")] = d
Как только мы всё прочитали, можно использовать на датафреймах метод head, чтобы вывести первые 5 строк каждого:
for k,v in data.items():
print("\n" + k + "\n")
print(v.head())Уже можно видеть в датасетах определённые особенности:
math_test_results
| DBN | Grade | Year | Category | Number Tested | Mean Scale Score | Level 1 # | \ | |
|---|---|---|---|---|---|---|---|---|
| 0 | 01M015 | 3 | 2006 | All Students | 39 | 667 | 2 | |
| 1 | 01M015 | 3 | 2007 | All Students | 31 | 672 | 2 | |
| 2 | 01M015 | 3 | 2008 | All Students | 37 | 668 | 0 | |
| 3 | 01M015 | 3 | 2009 | All Students | 33 | 668 | 0 | |
| 4 | 01M015 | 3 | 2010 | All Students | 26 | 677 | 6 |
| Level 1 % | Level 2 # | Level 2 % | Level 3 # | Level 3 % | Level 4 # | Level 4 % | \ | |
|---|---|---|---|---|---|---|---|---|
| 0 | 5.1% | 11 | 28.2% | 20 | 51.3% | 6 | 15.4% | |
| 1 | 6.5% | 3 | 9.7% | 22 | 71% | 4 | 12.9% | |
| 2 | 0% | 6 | 16.2% | 29 | 78.4% | 2 | 5.4% | |
| 3 | 0% | 4 | 12.1% | 28 | 84.8% | 1 | 3% | |
| 4 | 23.1% | 12 | 46.2% | 6 | 23.1% | 2 | 7.7% |
| Level 3+4 # | Level 3+4 % | |
|---|---|---|
| 0 | 26 | 66.7% |
| 1 | 26 | 83.9% |
| 2 | 31 | 83.8% |
| 3 | 29 | 87.9% |
| 4 | 8 | 30.8% |
ap_2010
| DBN | SchoolName | AP Test Takers | Total Exams Taken | Number of Exams with scores 3 4 or 5 | |
|---|---|---|---|---|---|
| 0 | 01M448 | UNIVERSITY NEIGHBORHOOD H.S. | 39 | 49 | 10 |
| 1 | 01M450 | EAST SIDE COMMUNITY HS | 19 | 21 | s |
| 2 | 01M515 | LOWER EASTSIDE PREP | 24 | 26 | 24 |
| 3 | 01M539 | NEW EXPLORATIONS SCI,TECH,MATH | 255 | 377 | 191 |
| 4 | 02M296 | High School of Hospitality Management | s | s | s |
sat_results
| DBN | SCHOOL NAME | Num of SAT Test Takers | SAT Critical Reading Avg. Score | SAT Math Avg. Score | SAT Writing Avg. Score | |
|---|---|---|---|---|---|---|
| 0 | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL STUDIES | 29 | 355 | 404 | 363 |
| 1 | 01M448 | UNIVERSITY NEIGHBORHOOD HIGH SCHOOL | 91 | 383 | 423 | 366 |
| 2 | 01M450 | EAST SIDE COMMUNITY SCHOOL | 70 | 377 | 402 | 370 |
| 3 | 01M458 | FORSYTH SATELLITE ACADEMY | 7 | 414 | 401 | 359 |
| 4 | 01M509 | MARTA VALLE HIGH SCHOOL | 44 | 390 | 433 | 384 |
class_size
| CSD | BOROUGH | SCHOOL CODE | SCHOOL NAME | GRADE | PROGRAM TYPE | CORE SUBJECT (MS CORE and 9-12 ONLY) | CORE COURSE (MS CORE and 9-12 ONLY) | \ | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | GEN ED | - | - | |
| 1 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | CTT | - | - | |
| 2 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | GEN ED | - | - | |
| 3 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | CTT | - | - | |
| 4 | 1 | M | M015 | P.S. 015 Roberto Clemente | 02 | GEN E | - | - |
| SERVICE CATEGORY(K-9* ONLY) | NUMBER OF STUDENTS / SEATS FILLED | NUMBER OF SECTIONS | AVERAGE CLASS SIZE | SIZE OF SMALLEST CLASS | \ | |
|---|---|---|---|---|---|---|
| 0 | - | 19.0 | 1.0 | 19.0 | 19.0 | |
| 1 | - | 21.0 | 1.0 | 21.0 | 21.0 | |
| 2 | - | 17.0 | 1.0 | 17.0 | 17.0 | |
| 3 | - | 17.0 | 1.0 | 17.0 | 17.0 | |
| 4 | - | 15.0 | 1.0 | 15.0 | 15.0 |
| SIZE OF LARGEST CLASS | DATA SOURCE | SCHOOLWIDE PUPIL-TEACHER RATIO | |
|---|---|---|---|
| 0 | 19.0 | ATS | NaN |
| 1 | 21.0 | ATS | NaN |
| 2 | 17.0 | ATS | NaN |
| 3 | 17.0 | ATS | NaN |
| 4 | 15.0 | ATS | NaN |
demographics
| DBN | Name | schoolyear | fl_percent | frl_percent | \ | |
|---|---|---|---|---|---|---|
| 0 | 01M015 | P.S. 015 ROBERTO CLEMENTE | 20052006 | 89.4 | NaN | |
| 1 | 01M015 | P.S. 015 ROBERTO CLEMENTE | 20062007 | 89.4 | NaN | |
| 2 | 01M015 | P.S. 015 ROBERTO CLEMENTE | 20072008 | 89.4 | NaN | |
| 3 | 01M015 | P.S. 015 ROBERTO CLEMENTE | 20082009 | 89.4 | NaN | |
| 4 | 01M015 | P.S. 015 ROBERTO CLEMENTE | 20092010 | 96.5 |
| total_enrollment | prek | k | grade1 | grade2 | ... | black_num | black_per | \ | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 281 | 15 | 36 | 40 | 33 | ... | 74 | 26.3 | |
| 1 | 243 | 15 | 29 | 39 | 38 | ... | 68 | 28.0 | |
| 2 | 261 | 18 | 43 | 39 | 36 | ... | 77 | 29.5 | |
| 3 | 252 | 17 | 37 | 44 | 32 | ... | 75 | 29.8 | |
| 4 | 208 | 16 | 40 | 28 | 32 | ... | 67 | 32.2 |
| hispanic_num | hispanic_per | white_num | white_per | male_num | male_per | female_num | female_per | \ | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 189 | 67.3 | 5 | 1.8 | 158.0 | 56.2 | 123.0 | 43.8 | |
| 1 | 153 | 63.0 | 4 | 1.6 | 140.0 | 57.6 | 103.0 | 42.4 | |
| 2 | 157 | 60.2 | 7 | 2.7 | 143.0 | 54.8 | 118.0 | 45.2 | |
| 3 | 149 | 59.1 | 7 | 2.8 | 149.0 | 59.1 | 103.0 | 40.9 | |
| 4 | 118 | 56.7 | 6 | 2.9 | 124.0 | 59.6 | 84.0 | 40.4 |
graduation
| Demographic | DBN | School Name | Cohort | \ | |
|---|---|---|---|---|---|
| 0 | Total Cohort | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL | 2003 | |
| 1 | Total Cohort | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL | 2004 | |
| 2 | Total Cohort | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL | 2005 | |
| 3 | Total Cohort | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL | 2006 | |
| 4 | Total Cohort | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL | 2006 Aug |
| Total Cohort | Total Grads — n | Total Grads — % of cohort | Total Regents — n | \ | |
|---|---|---|---|---|---|
| 0 | 5 | s | s | s | |
| 1 | 55 | 37 | 67.3% | 17 | |
| 2 | 64 | 43 | 67.2% | 27 | |
| 3 | 78 | 43 | 55.1% | 36 | |
| 4 | 78 | 44 | 56.4% | 37 |
| Total Regents — % of cohort | Total Regents — % of grads | ... | Regents w/o Advanced — n | \ | |
|---|---|---|---|---|---|
| 0 | s | s | ... | s | |
| 1 | 30.9% | 45.9% | ... | 17 | |
| 2 | 42.2% | 62.8% | ... | 27 | |
| 3 | 46.2% | 83.7% | ... | 36 | |
| 4 | 47.4% | 84.1% | ... | 37 |
| Regents w/o Advanced — % of cohort | Regents w/o Advanced — % of grads | \ | |
|---|---|---|---|
| 0 | s | s | |
| 1 | 30.9% | 45.9% | |
| 2 | 42.2% | 62.8% | |
| 3 | 46.2% | 83.7% | |
| 4 | 47.4% | 84.1% |
| Local — n | Local — % of cohort | Local — % of grad | s Still Enrolled — n | \ | |
|---|---|---|---|---|---|
| 0 | s | s | s | s | |
| 1 | 20 | 36.4% | 54.1% | 15 | |
| 2 | 16 | 25% | 37.200000000000003% | 9 | |
| 3 | 7 | 9% | 16.3% | 16 | |
| 4 | 7 | 9% | 15.9% | 15 |
| Still Enrolled — % of cohort | Dropped Out — n | Dropped Out — % of cohort | |
|---|---|---|---|
| 0 | s | s | s |
| 1 | 27.3% | 3 | 5.5% |
| 2 | 14.1% | 9 | 14.1% |
| 3 | 20.5% | 11 | 14.1% |
| 4 | 19.2% | 11 | 14.1% |
hs_directory
| dbn | school_name | boro | \ | |
|---|---|---|---|---|
| 0 | 17K548 | Brooklyn School for Music & Theatre | Brooklyn | |
| 1 | 09X543 | High School for Violin and Dance | Bronx | |
| 2 | 09X327 | Comprehensive Model School Project M.S. 327 | Bronx | |
| 3 | 02M280 | Manhattan Early College School for Advertising | Manhattan | |
| 4 | 28Q680 | Queens Gateway to Health Sciences Secondary Sc... | Queens |
| building_code | phone_number | fax_number | grade_span_min | grade_span_max | \ | |
|---|---|---|---|---|---|---|
| 0 | K440 | 718-230-6250 | 718-230-6262 | 9 | 12 | |
| 1 | X400 | 718-842-0687 | 718-589-9849 | 9 | 12 | |
| 2 | X240 | 718-294-8111 | 718-294-8109 | 6 | 12 | |
| 3 | M520 | 718-935-3477 | NaN | 9 | 10 | |
| 4 | Q695 | 718-969-3155 | 718-969-3552 | 6 | 12 |
| expgrade_span_min | expgrade_span_max | ... | priority02 | \ | |
|---|---|---|---|---|---|
| 0 | NaN | NaN | ... | Then to New York City residents | |
| 1 | NaN | NaN | ... | Then to New York City residents who attend an ... | |
| 2 | NaN | NaN | ... | Then to Bronx students or residents who attend... | |
| 3 | 9 | 14.0 | ... | Then to New York City residents who attend an ... | |
| 4 | NaN | NaN | ... | Then to Districts 28 and 29 students or residents |
| priority03 | priority04 | priority05 | \ | |
|---|---|---|---|---|
| 0 | NaN | NaN | NaN | |
| 1 | Then to Bronx students or residents | Then to New York City residents | NaN | |
| 2 | Then to New York City residents who attend an ... | Then to Bronx students or residents | Then to New York City residents | |
| 3 | Then to Manhattan students or residents | Then to New York City residents | NaN | |
| 4 | Then to Queens students or residents | Then to New York City residents | NaN |
| priority06 | priority07 | priority08 | priority09 | priority10 | Location 1 | |
|---|---|---|---|---|---|---|
| 0 | NaN | NaN | NaN | NaN | NaN | 883 Classon Avenue\nBrooklyn, NY 11225\n(40.67... |
| 1 | NaN | NaN | NaN | NaN | NaN | 1110 Boston Road\nBronx, NY 10456\n(40.8276026... |
| 2 | NaN | NaN | NaN | NaN | NaN | 1501 Jerome Avenue\nBronx, NY 10452\n(40.84241... |
| 3 | NaN | NaN | NaN | NaN | NaN | 411 Pearl Street\nNew York, NY 10038\n(40.7106... |
| 4 | NaN | NaN | NaN | NaN | NaN | 160-20 Goethals Avenue\nJamaica, NY 11432\n(40... |
- Большинство содержит столбец DBN
- Некоторые поля выглядят интересными для картографирования, в частности Location 1, который содержит координаты в строке.
- В некоторых датасетах есть по несколько строк на каждую школу (повторяющиеся значения DBN), что намекает на необходимость предварительной обработки.
Приведение данных к общему знаменателю
Чтобы с данными работать было легче, нам надо объединить все датасеты в один — это позволит нам быстро сравнивать колонки в датасетах. Для этого, прежде всего, надо найти общую колонку для объединения. Глядя на то, что нам ранее вывелось, можно предположить, что такой колонкой может быть DBN, поскольку она повторяется в нескольких датасетах.
Если мы загуглим "DBN New York City Schools", то придём сюда, где объясняется, что DBN — это уникальный код для каждой школы. При исследовании датасетов, особенно правительственных, приходится частенько проделать детективную работу, чтобы понять, что значит каждый столбец, даже каждый датасет иногда.
Теперь проблема в том, что два датасета, class_size и hs_directory — не содержат DBN. В hs_directory он называется dbn, поэтому просто переименуем или скопируем его в DBN. Для class_size нужен будет другой подход.
Столбец DBN выглядит так:
In [5]: data["demographics"]["DBN"].head()
Out[5]:
0 01M015
1 01M015
2 01M015
3 01M015
4 01M015
Name: DBN, dtype: objectЕсли посмотрим на class_size - вот то, что мы увидим в первых 5 строках:
In [4]:
data["class_size"].head()
Out[4]:| CSD | BOROUGH | SCHOOL CODE | SCHOOL NAME | GRADE | PROGRAM TYPE | CORE SUBJECT (MS CORE and 9-12 ONLY) | / | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | GEN ED | - | |
| 1 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | CTT | - | |
| 2 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | GEN ED | - | |
| 3 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | CTT | - | |
| 4 | 1 | M | M015 | P.S. 015 Roberto Clemente | 02 | GEN ED | - |
| CORE COURSE (MS CORE and 9-12 ONLY) | SERVICE CATEGORY(K-9* ONLY) | NUMBER OF STUDENTS / SEATS FILLED | / | |
|---|---|---|---|---|
| 0 | - | - | 19.0 | |
| 1 | - | - | 21.0 | |
| 2 | - | - | 17.0 | |
| 3 | - | - | 17.0 | |
| 4 | - | - | 15.0 |
| NUMBER OF SECTIONS | AVERAGE CLASS SIZE | SIZE OF SMALLEST CLASS | SIZE OF LARGEST CLASS | DATA SOURCE | SCHOOLWIDE PUPIL-TEACHER RATIO | |
|---|---|---|---|---|---|---|
| 0 | 1.0 | 19.0 | 19.0 | 19.0 | ATS | NaN |
| 1 | 1.0 | 21.0 | 21.0 | 21.0 | ATS | NaN |
| 2 | 1.0 | 17.0 | 17.0 | 17.0 | ATS | NaN |
| 3 | 1.0 | 17.0 | 17.0 | 17.0 | ATS | NaN |
| 4 | 1.0 | 15.0 | 15.0 | 15.0 | ATS | NaN |
Как можно заметить, DBN — это просто комбинация CSD,BOROUGH и SCHOOL_ CODE. Для незнакомых с Нью-Йорком: он состоит из 5 районов. Каждый район — это организационная единица, приблизительно равная по размеру достаточно большому городу США. DBN расшифровывается как районно-окружной номер. Похоже, что CSD — это округ, BOROUGH — район и в сочетании со SCHOOL_CODE получается DBN.
Теперь, когда мы знаем, как составить DBN, мы можем добавить его в class_size и hs_directory.
In [ ]:
data["class_size"]["DBN"] = data["class_size"].apply(lambda x: "{0:02d}{1}".format(x["CSD"], x["SCHOOL CODE"]), axis=1)
data["hs_directory"]["DBN"] = data["hs_directory"]["dbn"]Добавляем опросы
Один из самых потенциально интересных датасетов — это датасет опросов учеников, родителей и учителей по поводу качества школ. Эти опросы включают информацию о субъективном восприятии безопасности каждой школы, учебных стандартах и прочем. Перед тем, как объединять наши датасеты, давайте добавим данные по опросам. В реальных data science-проектах вы часто будете натыкаться на интересные данные по ходу анализа и, возможно, захотите так же их подключить. Гибкий инструмент, типа Jupyter notebook, позволяет быстро добавить дополнительный код и переделать анализ.
В нашем случае, добавим дополнительные данные по опросам в наш словарь data, после чего объединим все датасеты. Данные по опросам состоят из двух файлов, один на все школы, и один на школьный округ 75. Чтобы их объединить, потребуется написать немного кода. В нём мы сделаем что:
- Прочитаем опросы по всем школам, используя кодировку windows-1252
- Прочитаем опросы для округа 75 с использованием windows-1252
- Добавим флаг, который будет обозначать, для какого округа каждый датасет.
- Объединим все датасеты в один с помощью метода concat на датафреймах.
In [66]:
survey1 = pandas.read_csv("schools/survey_all.txt", delimiter="\t", encoding='windows-1252')
survey2 = pandas.read_csv("schools/survey_d75.txt", delimiter="\t", encoding='windows-1252')
survey1["d75"] = False
survey2["d75"] = True
survey = pandas.concat([survey1, survey2], axis=0)Как только мы объединим все опросы, появится дополнительная трудность. Мы хотим минимизировать количество столбцов в нашем объединённом датасете, чтобы можно было легко сравнивать колонки и выявлять зависимости. К несчастью, данные по опросам содержат много ненужных нам колонок:
In [16]:
survey.head()
Out[16]:| N_p | N_s | N_t | aca_p_11 | aca_s_11 | aca_t_11 | aca_tot_11 | / | |
|---|---|---|---|---|---|---|---|---|
| 0 | 90.0 | NaN | 22.0 | 7.8 | NaN | 7.9 | 7.9 | |
| 1 | 161.0 | NaN | 34.0 | 7.8 | NaN | 9.1 | 8.4 | |
| 2 | 367.0 | NaN | 42.0 | 8.6 | NaN | 7.5 | 8.0 | |
| 3 | 151.0 | 145.0 | 29.0 | 8.5 | 7.4 | 7.8 | 7.9 | |
| 4 | 90.0 | NaN | 23.0 | 7.9 | NaN | 8.1 | 8.0 |
| bn | com_p_11 | com_s_11 | ... | t_q8c_1 | t_q8c_2 | t_q8c_3 | t_q8c_4 | / | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | M015 | 7.6 | NaN | ... | 29.0 | 67.0 | 5.0 | 0.0 | |
| 1 | M019 | 7.6 | NaN | ... | 74.0 | 21.0 | 6.0 | 0.0 | |
| 2 | M020 | 8.3 | NaN | ... | 33.0 | 35.0 | 20.0 | 13.0 | |
| 3 | M034 | 8.2 | 5.9 | ... | 21.0 | 45.0 | 28.0 | 7.0 | |
| 4 | M063 | 7.9 | NaN | ... | 59.0 | 36.0 | 5.0 | 0.0 |
| t_q9 | t_q9_1 | t_q9_2 | t_q9_3 | t_q9_4 | t_q9_5 | |
|---|---|---|---|---|---|---|
| 0 | NaN | 5.0 | 14.0 | 52.0 | 24.0 | 5.0 |
| 1 | NaN | 3.0 | 6.0 | 3.0 | 78.0 | 9.0 |
| 2 | NaN | 3.0 | 5.0 | 16.0 | 70.0 | 5.0 |
| 3 | NaN | 0.0 | 18.0 | 32.0 | 39.0 | 11.0 |
| 4 | NaN | 10.0 | 5.0 | 10.0 | 60.0 | 15.0 |
Мы справимся с этим, заглянув в файл со словарём данных, который мы скачали вместе с данными по опросам. Он расскажет нам про важные поля:
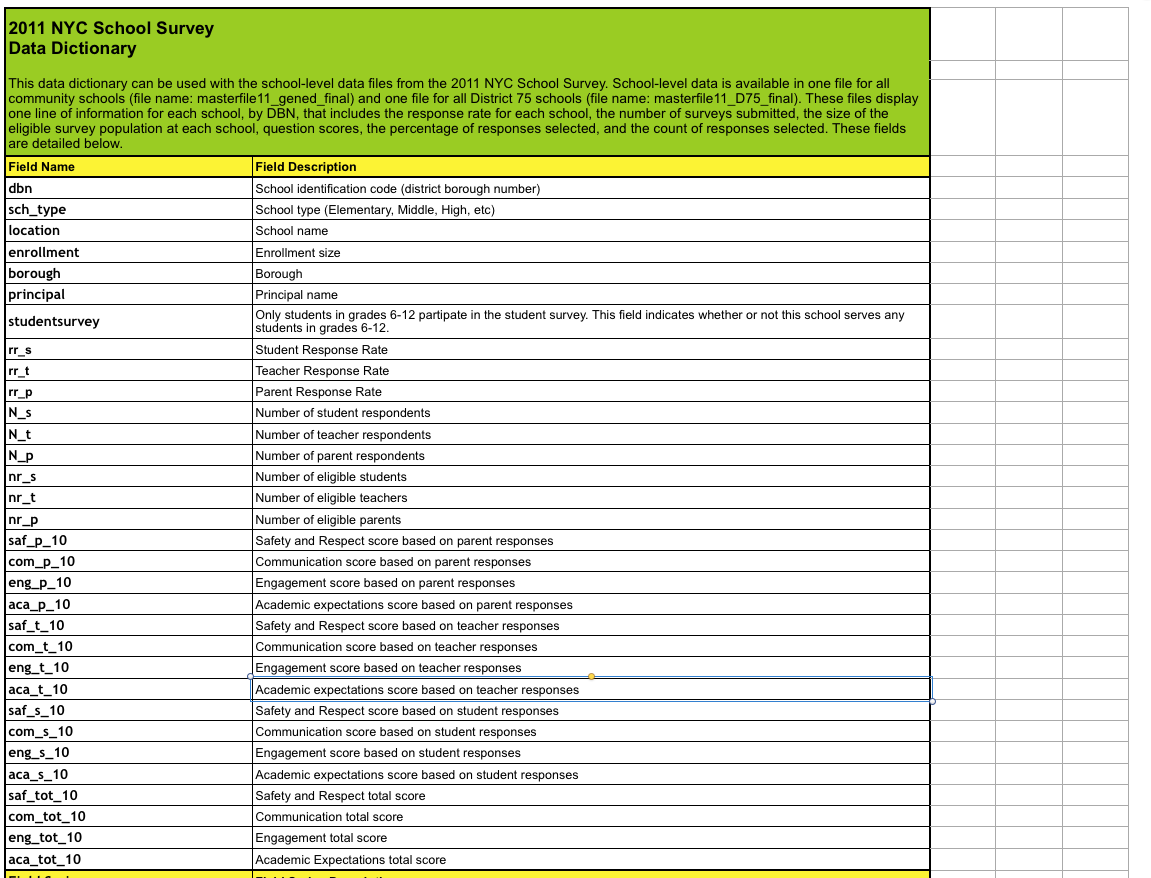
А потом мы удалим все не относящиеся к нам столбцы в survey:
In [17]:
survey["DBN"] = survey["dbn"]
survey_fields = ["DBN", "rr_s", "rr_t", "rr_p", "N_s", "N_t", "N_p", "saf_p_11", "com_p_11", "eng_p_11", "aca_p_11", "saf_t_11", "com_t_11", "eng_t_10", "aca_t_11", "saf_s_11", "com_s_11", "eng_s_11", "aca_s_11", "saf_tot_11", "com_tot_11", "eng_tot_11", "aca_tot_11",]
survey = survey.loc[:,survey_fields]
data["survey"] = survey
survey.shape
Out[17]:
(1702, 23)Понимание того, что именно содержит каждый датасет и какие столбцы из него важны, может сэкономить кучу времени и усилий в дальнейшем.
Уплотняем датасеты
Если мы взглянем на некоторые датасеты, включая class_size, мы сразу увидим проблему:
In [18]: data["class_size"].head()
Out[18]:| CSD | BOROUGH | SCHOOL CODE | SCHOOL NAME | GRADE | PROGRAM TYPE | CORE SUBJECT (MS CORE and 9-12 ONLY) | / | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | GEN ED | - | |
| 1 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | CTT | - | |
| 2 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | GEN ED | - | |
| 3 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | CTT | - | |
| 4 | 1 | M | M015 | P.S. 015 Roberto Clemente | 02 | GEN ED | - |
| CORE COURSE (MS CORE and 9-12 ONLY) | SERVICE CATEGORY(K-9* ONLY) | NUMBER OF STUDENTS / SEATS FILLED | NUMBER OF SECTIONS | AVERAGE CLASS SIZE | / | |
|---|---|---|---|---|---|---|
| 0 | - | - | 19.0 | 1.0 | 19.0 | |
| 1 | - | - | 21.0 | 1.0 | 21.0 | |
| 2 | - | - | 17.0 | 1.0 | 17.0 | |
| 3 | - | - | 17.0 | 1.0 | 17.0 | |
| 4 | - | - | 15.0 | 1.0 | 15.0 |
| SIZE OF SMALLEST CLASS | SIZE OF LARGEST CLASS | DATA SOURCE | SCHOOLWIDE PUPIL-TEACHER RATIO | DBN | |
|---|---|---|---|---|---|
| 0 | 19.0 | 19.0 | ATS | NaN | 01M015 |
| 1 | 21.0 | 21.0 | ATS | NaN | 01M015 |
| 2 | 17.0 | 17.0 | ATS | NaN | 01M015 |
| 3 | 17.0 | 17.0 | ATS | NaN | 01M015 |
| 4 | 15.0 | 15.0 | ATS | NaN | 01M015 |
Для каждой школы есть несколько строк (что можно понять по повторяющимся полям DBN и SCHOOL NAME). Хотя, если мы взглянем на sat_results - в нём только по одной строке на школу:
In [21]:
data["sat_results"].head()
Out[21]:| DBN | SCHOOL NAME | Num of SAT Test Takers | SAT Critical Reading Avg. Score | SAT Math Avg. Score | SAT Writing Avg. Score | |
|---|---|---|---|---|---|---|
| 0 | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL STUDIES | 29 | 355 | 404 | 363 |
| 1 | 01M448 | UNIVERSITY NEIGHBORHOOD HIGH SCHOOL | 91 | 383 | 423 | 366 |
| 2 | 01M450 | EAST SIDE COMMUNITY SCHOOL | 70 | 377 | 402 | 370 |
| 3 | 01M458 | FORSYTH SATELLITE ACADEMY | 7 | 414 | 401 | 359 |
| 4 | 01M509 | MARTA VALLE HIGH SCHOOL | 44 | 390 | 433 | 384 |
Чтобы объединить эти датасеты, нужен способ уплотнить датасеты типа class_size так, чтобы в них было по одной строке на каждую старшую школу. Если не получится — то не получится и сравнить оценки ЕГЭ с размерами класса. Мы сможем этого достичь, получше разобравшись в данных, а потом сделав некоторые агрегации.
По датасету class_size - похоже, что GRADE и PROGRAM TYPE содержат разные оценки по каждой школе. Ограничив каждое поле единственным значением, мы сможем отбросить все строчки-дубликаты. В коде ниже мы:
- Выберем только те значения из class_size, где поле GRADE - 09-12.
- Выберем только те значения из class_size, где поле PROGRAM TYPE - GEN ED.
- Сгруппируем class_size по DBN, и возьмём среднее по каждой колонке. По сути, мы найдем средний class_size по каждой школе.
- Сбросим индекс, чтобы DBN снова добавился как колонка.
In [68]:
class_size = data["class_size"]
class_size = class_size[class_size["GRADE "] == "09-12"]
class_size = class_size[class_size["PROGRAM TYPE"] == "GEN ED"]
class_size = class_size.groupby("DBN").agg(np.mean)
class_size.reset_index(inplace=True)
data["class_size"] = class_sizeСгущаем остальные датасеты
Дальше нам надо ужать датасет demographics. Данные собраны за несколько лет по одним и тем же школам. Мы выберем только те строки, где поле schoolyear свежее всего.
In [69]:
demographics = data["demographics"]
demographics = demographics[demographics["schoolyear"] == 20112012]
data["demographics"] = demographicsТеперь нам нужно сжать датасет math_test_results. Он делится по значениям Grade и Year. Мы можем выбрать единственный класс за единственный год:
In [70]:
data["math_test_results"] = data["math_test_results"][data["math_test_results"]["Year"] == 2011]
data["math_test_results"] = data["math_test_results"][data["math_test_results"]["Grade"] == Наконец, graduation тоже надо уплотнить:
In [71]:
data["graduation"] = data["graduation"][data["graduation"]["Cohort"] == "2006"]
data["graduation"] = data["graduation"][data["graduation"]["Demographic"] == "Total Cohort"]Очистка и исследование данных критичны перед работой над сутью проекта. Хороший, годныйцелостный датасет поможет быстрее сделать анализ.
Вычисление агрегированных переменных
Вычисление переменных может ускорить наш анализ возможностью делать сравнивание быстрее и в принципе давая возможность делать некоторые, невозможные без них, сравнения. Первое, что мы можем сделать — посчитать общий балл ЕГЭ из отдельных колонок SAT Math Avg. Score, SAT Critical Reading Avg. Score, и SAT Writing Avg. Score. В коде ниже мы:
- Преобразуем каждый балл ЕГЭ от строки к числу
- Сложим все столбцы и получим столбец sat_score, суммарный балл ЕГЭ.
In [72]:
cols = ['SAT Math Avg. Score', 'SAT Critical Reading Avg. Score', 'SAT Writing Avg. Score']
for c in cols:
data["sat_results"][c] = data["sat_results"][c].convert_objects(convert_numeric=True)
data['sat_results']['sat_score'] = data['sat_results'][cols[0]] + data['sat_results'][cols[1]]Далее нам надо распарсить координаты каждой школы, чтобы делать карты. Они позволят нам отметить положение каждой школы. В коде мы:
- Распарсим в столбцы широты и долготы столбец Location 1
- Преобразуем lat и lon к числам.
Выведем наши датасеты, посмотрим, что получилось:
In [74]:
for k,v in data.items():
print(k)
print(v.head())math_test_results
| DBN | Grade | Year | Category | Number Tested | Mean Scale Score | \ | |
|---|---|---|---|---|---|---|---|
| 111 | 01M034 | 8 | 2011 | All Students | 48 | 646 | |
| 280 | 01M140 | 8 | 2011 | All Students | 61 | 665 | |
| 346 | 01M184 | 8 | 2011 | All Students | 49 | 727 | |
| 388 | 01M188 | 8 | 2011 | All Students | 49 | 658 | |
| 411 | 01M292 | 8 | 2011 | All Students | 49 | 650 |
| Level 1 # | Level 1 % | Level 2 # | Level 2 % | Level 3 # | Level 3 % | Level 4 # | \ | |
|---|---|---|---|---|---|---|---|---|
| 111 | 15 | 31.3% | 22 | 45.8% | 11 | 22.9% | 0 | |
| 280 | 1 | 1.6% | 43 | 70.5% | 17 | 27.9% | 0 | |
| 346 | 0 | 0% | 0 | 0% | 5 | 10.2% | 44 | |
| 388 | 10 | 20.4% | 26 | 53.1% | 10 | 20.4% | 3 | |
| 411 | 15 | 30.6% | 25 | 51% | 7 | 14.3% | 2 |
| Level 4 % | Level 3+4 # | Level 3+4 % | |
|---|---|---|---|
| 111 | 0% | 11 | 22.9% |
| 280 | 0% | 17 | 27.9% |
| 346 | 89.8% | 49 | 100% |
| 388 | 6.1% | 13 | 26.5% |
| 411 | 4.1% | 9 | 18.4% |
survey
| DBN | rr_s | rr_t | rr_p | N_s | N_t | N_p | saf_p_11 | com_p_11 | eng_p_11 | \ | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 01M015 | NaN | 88 | 60 | NaN | 22.0 | 90.0 | 8.5 | 7.6 | 7.5 | |
| 1 | 01M019 | NaN | 100 | 60 | NaN | 34.0 | 161.0 | 8.4 | 7.6 | 7.6 | |
| 2 | 01M020 | NaN | 88 | 73 | NaN | 42.0 | 367.0 | 8.9 | 8.3 | 8.3 | |
| 3 | 01M034 | 89.0 | 73 | 50 | 145.0 | 29.0 | 151.0 | 8.8 | 8.2 | 8.0 | |
| 4 | 01M063 | NaN | 100 | 60 | NaN | 23.0 | 90.0 | 8.7 | 7.9 | 8.1 |
| ... | eng_t_10 | aca_t_11 | saf_s_11 | com_s_11 | eng_s_11 | aca_s_11 | \ | |
|---|---|---|---|---|---|---|---|---|
| 0 | ... | NaN | 7.9 | NaN | NaN | NaN | NaN | |
| 1 | ... | NaN | 9.1 | NaN | NaN | NaN | NaN | |
| 2 | ... | NaN | 7.5 | NaN | NaN | NaN | NaN | |
| 3 | ... | NaN | 7.8 | 6.2 | 5.9 | 6.5 | 7.4 | |
| 4 | ... | NaN | 8.1 | NaN | NaN | NaN | NaN |
| saf_tot_11 | com_tot_11 | eng_tot_11 | aca_tot_11 | |
|---|---|---|---|---|
| 0 | 8.0 | 7.7 | 7.5 | 7.9 |
| 1 | 8.5 | 8.1 | 8.2 | 8.4 |
| 2 | 8.2 | 7.3 | 7.5 | 8.0 |
| 3 | 7.3 | 6.7 | 7.1 | 7.9 |
| 4 | 8.5 | 7.6 | 7.9 | 8.0 |
ap_2010
| DBN | SchoolName | AP Test Takers | Total Exams Taken | Number of Exams with scores 3 4 or 5 | |
|---|---|---|---|---|---|
| 0 | 01M448 | UNIVERSITY NEIGHBORHOOD H.S. | 39 | 49 | 10 |
| 1 | 01M450 | EAST SIDE COMMUNITY HS | 19 | 21 | s |
| 2 | 01M515 | LOWER EASTSIDE PREP | 24 | 26 | 24 |
| 3 | 01M539 | NEW EXPLORATIONS SCI,TECH,MATH | 255 | 377 | 191 |
| 4 | 02M296 | High School of Hospitality Management | s | s | s |
sat_results
| DBN | SCHOOL NAME | Num of SAT Test Takers | SAT Critical Reading Avg. Score | \ | |
|---|---|---|---|---|---|
| 0 | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL STUDIES | 29 | 355.0 | |
| 1 | 01M448 | UNIVERSITY NEIGHBORHOOD HIGH SCHOOL | 91 | 383.0 | |
| 2 | 01M450 | EAST SIDE COMMUNITY SCHOOL | 70 | 377.0 | |
| 3 | 01M458 | FORSYTH SATELLITE ACADEMY | 7 | 414.0 | |
| 4 | 01M509 | MARTA VALLE HIGH SCHOOL | 44 | 390.0 |
| SAT Math Avg. Score | SAT Writing Avg. Score | sat_score | |
|---|---|---|---|
| 0 | 404.0 | 363.0 | 1122.0 |
| 1 | 423.0 | 366.0 | 1172.0 |
| 2 | 402.0 | 370.0 | 1149.0 |
| 3 | 401.0 | 359.0 | 1174.0 |
| 4 | 433.0 | 384.0 | 1207.0 |
class_size
| DBN | CSD | NUMBER OF STUDENTS / SEATS FILLED | NUMBER OF SECTIONS | \ | |
|---|---|---|---|---|---|
| 0 | 01M292 | 1 | 88.0000 | 4.000000 | |
| 1 | 01M332 | 1 | 46.0000 | 2.000000 | |
| 2 | 01M378 | 1 | 33.0000 | 1.000000 | |
| 3 | 01M448 | 1 | 105.6875 | 4.750000 | |
| 4 | 01M450 | 1 | 57.6000 | 2.733333 |
| AVERAGE CLASS SIZE | SIZE OF SMALLEST CLASS | SIZE OF LARGEST CLASS | SCHOOLWIDE PUPIL-TEACHER RATIO | |
|---|---|---|---|---|
| 0 | 22.564286 | 18.50 | 26.571429 | NaN |
| 1 | 22.000000 | 21.00 | 23.500000 | NaN |
| 2 | 33.000000 | 33.00 | 33.000000 | NaN |
| 3 | 22.231250 | 18.25 | 27.062500 | NaN |
| 4 | 21.200000 | 19.40 | 22.866667 | NaN |
demographics
| DBN | Name | schoolyear | \ | |
|---|---|---|---|---|
| 6 | 01M015 | P.S. 015 ROBERTO CLEMENTE | 20112012 | |
| 13 | 01M019 | P.S. 019 ASHER LEVY | 20112012 | |
| 20 | 01M020 | PS 020 ANNA SILVER | 20112012 | |
| 27 | 01M034 | PS 034 FRANKLIN D ROOSEVELT | 20112012 | |
| 35 | 01M063 | PS 063 WILLIAM MCKINLEY | 20112012 |
| fl_percent | frl_percent | total_enrollment | prek | k | grade1 | grade2 | \ | |
|---|---|---|---|---|---|---|---|---|
| 6 | NaN | 89.4 | 189 | 13 | 31 | 35 | 28 | |
| 13 | NaN | 61.5 | 328 | 32 | 46 | 52 | 54 | |
| 20 | NaN | 92.5 | 626 | 52 | 102 | 121 | 87 | |
| 27 | NaN | 99.7 | 401 | 14 | 34 | 38 | 36 | |
| 35 | NaN | 78.9 | 176 | 18 | 20 | 30 | 21 |
| ... | black_num | black_per | hispanic_num | hispanic_per | white_num | \ | |
|---|---|---|---|---|---|---|---|
| 6 | ... | 63 | 33.3 | 109 | 57.7 | 4 | |
| 13 | ... | 81 | 24.7 | 158 | 48.2 | 28 | |
| 20 | ... | 55 | 8.8 | 357 | 57.0 | 16 | |
| 27 | ... | 90 | 22.4 | 275 | 68.6 | 8 | |
| 35 | ... | 41 | 23.3 | 110 | 62.5 | 15 |
| white_per | male_num | male_per | female_num | female_per | |
|---|---|---|---|---|---|
| 6 | 2.1 | 97.0 | 51.3 | 92.0 | 48.7 |
| 13 | 8.5 | 147.0 | 44.8 | 181.0 | 55.2 |
| 20 | 2.6 | 330.0 | 52.7 | 296.0 | 47.3 |
| 27 | 2.0 | 204.0 | 50.9 | 197.0 | 49.1 |
| 35 | 8.5 | 97.0 | 55.1 | 79.0 | 44.9 |
graduation
| Demographic | DBN | School Name | Cohort | \ | |
|---|---|---|---|---|---|
| 3 | Total Cohort | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL | 2006 | |
| 10 | Total Cohort | 01M448 | UNIVERSITY NEIGHBORHOOD HIGH SCHOOL | 2006 | |
| 17 | Total Cohort | 01M450 | EAST SIDE COMMUNITY SCHOOL | 2006 | |
| 24 | Total Cohort | 01M509 | MARTA VALLE HIGH SCHOOL | 2006 | |
| 31 | Total Cohort | 01M515 | LOWER EAST SIDE PREPARATORY HIGH SCHO | 2006 |
| Total Cohort | Total Grads — n | Total Grads — % of cohort | Total Regents — n | \ | |
|---|---|---|---|---|---|
| 3 | 78 | 43 | 55.1% | 36 | |
| 10 | 124 | 53 | 42.7% | 42 | |
| 17 | 90 | 70 | 77.8% | 67 | |
| 24 | 84 | 47 | 56% | 40 | |
| 31 | 193 | 105 | 54.4% | 91 |
| Total Regents — % of cohort | Total Regents — % of grads | ... | Regents w/o Advanced — n | \ | |
|---|---|---|---|---|---|
| 3 | 46.2% | 83.7% | ... | 36 | |
| 10 | 33.9% | 79.2% | ... | 34 | |
| 17 | 74.400000000000006% | 95.7% | ... | 67 | |
| 24 | 47.6% | 85.1% | ... | 23 | |
| 31 | 47.2% | 86.7% | ... | 22 |
| Regents w/o Advanced — % of cohort | Regents w/o Advanced — % of grads | \ | |
|---|---|---|---|
| 3 | 46.2% | 83.7% | |
| 10 | 27.4% | 64.2% | |
| 17 | 74.400000000000006% | 95.7% | |
| 24 | 27.4% | 48.9% | |
| 31 | 11.4% | 21% |
| Local — n | Local — % of cohort | Local — % of grads | Still Enrolled — n | \ | |
|---|---|---|---|---|---|
| 3 | 7 | 9% | 16.3% | 16 | |
| 10 | 11 | 8.9% | 20.8% | 46 | |
| 17 | 3 | 3.3% | 4.3% | 15 | |
| 24 | 7 | 8.300000000000001% | 14.9% | 25 | |
| 31 | 14 | 7.3% | 13.3% | 53 |
| Still Enrolled — % of cohort | Dropped Out — n | Dropped Out — % of cohort | |
|---|---|---|---|
| 3 | 20.5% | 11 | 14.1% |
| 10 | 37.1% | 20 | 16.100000000000001% |
| 17 | 16.7% | 5 | 5.6% |
| 24 | 29.8% | 5 | 6% |
| 31 | 27.5% | 35 | 18.100000000000001% |
hs_directory
| dbn | school_name | boro | \ | |
|---|---|---|---|---|
| 0 | 17K548 | Brooklyn School for Music & Theatre | Brooklyn | |
| 1 | 09X543 | High School for Violin and Dance | Bronx | |
| 2 | 09X327 | Comprehensive Model School Project M.S. 327 | Bronx | |
| 3 | 02M280 | Manhattan Early College School for Advertising | Manhattan | |
| 4 | 28Q680 | Queens Gateway to Health Sciences Secondary Sc... | Queens |
| building_code | phone_number | fax_number | grade_span_min | grade_span_max | \ | |
|---|---|---|---|---|---|---|
| 0 | K440 | 718-230-6250 | 718-230-6262 | 9 | 12 | |
| 1 | X400 | 718-842-0687 | 718-589-9849 | 9 | 12 | |
| 2 | X240 | 718-294-8111 | 718-294-8109 | 6 | 12 | |
| 3 | M520 | 718-935-3477 | NaN | 9 | 10 | |
| 4 | Q695 | 718-969-3155 | 718-969-3552 | 6 | 12 |
| expgrade_span_min | expgrade_span_max | ... | priority05 | priority06 | priority07 | priority08 | \ | |
|---|---|---|---|---|---|---|---|---|
| 0 | NaN | NaN | ... | NaN | NaN | NaN | NaN | |
| 1 | NaN | NaN | ... | NaN | NaN | NaN | NaN | |
| 2 | NaN | NaN | ... | Then to New York City residents | NaN | NaN | NaN | |
| 3 | 9 | 14.0 | ... | NaN | NaN | NaN | NaN | |
| 4 | NaN | NaN | ... | NaN | NaN | NaN | NaN |
| priority09 | priority10 | Location 1 | \ | |
|---|---|---|---|---|
| 0 | NaN | NaN | 883 Classon Avenue\nBrooklyn, NY 11225\n(40.67... | |
| 1 | NaN | NaN | 1110 Boston Road\nBronx, NY 10456\n(40.8276026... | |
| 2 | NaN | NaN | 1501 Jerome Avenue\nBronx, NY 10452\n(40.84241... | |
| 3 | NaN | NaN | 411 Pearl Street\nNew York, NY 10038\n(40.7106... | |
| 4 | NaN | NaN | 160-20 Goethals Avenue\nJamaica, NY 11432\n(40... |
| DBN | lat | lon | |
|---|---|---|---|
| 0 | 17K548 | 40.670299 | -73.961648 |
| 1 | 09X543 | 40.827603 | -73.904475 |
| 2 | 09X327 | 40.842414 | -73.916162 |
| 3 | 02M280 | 40.710679 | -74.000807 |
| 4 | 28Q680 | 40.718810 | -73.806500 |
Объединяем датасеты
После всей подготовки наконец, мы можем объединить все датасеты по столбцу DBN. В итоге у нас получится датасет с сотнями столбцов, из всех исходных. При объединении важно отметить, что в некоторых датасетах нет тех школ, что есть в датасете sat_results. Чтобы это обойти, нам надо объединять датасеты через outer join, тогда мы не потеряем данные. В реальном анализе отсутствие данных — обычное дело. Продемонстрировать возможность исследовать и справляться с таким отсутствием — важная часть портфолио.
Про разные типы джоинов можно почитать здесь.
В коде ниже мы:
- Пройдёмся по всем элементам словаря data
- Выведем количество неуникальных DBN в каждом
- Решим, как будем джоинить — внутренне или внешне.
- Объединим элемент с датафреймом full через столбец DBN.
In [75]:
flat_data_names = [k for k,v in data.items()]
flat_data = [data[k] for k in flat_data_names]
full = flat_data[0]
for i, f in enumerate(flat_data[1:]):
name = flat_data_names[i+1]
print(name)
print(len(f["DBN"]) - len(f["DBN"].unique()))
join_type = "inner"
if name in ["sat_results", "ap_2010", "graduation"]:
join_type = "outer"
if name not in ["math_test_results"]:
full = full.merge(f, on="DBN", how=join_type)
full.shape
survey
0
ap_2010
1
sat_results
0
class_size
0
demographics
0
graduation
0
hs_directory
0
Out[75]:
(374, 174)Добавляем значений
Теперь, когда у нас есть наш полный датафрейм full, у нас есть практически вся информация для нашего анализа. Хотя ещё есть недостающие части. Мы можем захотеть скорреллировать оценки теста по углубленной программе с оценками ЕГЭ, но сначала надо будет преобразовывать эти столбцы к числам, а потом заполнить все пропущенные значения:
In [76]:
cols = ['AP Test Takers ', 'Total Exams Taken', 'Number of Exams with scores 3 4 or 5']
for col in cols:
full[col] = full[col].convert_objects(convert_numeric=True)
full[cols] = full[cols].fillna(value=0)Далее, надо посчитать столбец school_dist, который обозначает школьный округ. Он позволит нам сравнить школьные округа и рисовать окружную статистику с использованием карт округов, которые мы скачали:
In [77]:
full["school_dist"] = full["DBN"].apply(lambda x: x[:2])Наконец, нам надо заполнить все пропущенные значения в full средним значением из колонки, чтобы посчитать корреляции
In [79]:
full = full.fillna(full.mean())Считаем коррелляции
Хороший способ поисследовать датасет и посмотреть, как столбцы связаны с тем, чем нужно — это посчитать корреляции. Это покажет, какие столбцы связаны с интересующим столбцом. Это можно сделать методом corr в датафреймах Pandas. Чем ближе корреляция к 0 — тем слабее связь. Чем ближе к 1 — тем сильнее прямая связь. Чем ближе к -1 — тем сильнее обратная связь:
In [80]:
full.corr()['sat_score']
Out[80]:
Year NaN
Number Tested 8.127817e-02
rr_s 8.484298e-02
rr_t -6.604290e-02
rr_p 3.432778e-02
N_s 1.399443e-01
N_t 9.654314e-03
N_p 1.397405e-01
saf_p_11 1.050653e-01
com_p_11 2.107343e-02
eng_p_11 5.094925e-02
aca_p_11 5.822715e-02
saf_t_11 1.206710e-01
com_t_11 3.875666e-02
eng_t_10 NaN
aca_t_11 5.250357e-02
saf_s_11 1.054050e-01
com_s_11 4.576521e-02
eng_s_11 6.303699e-02
aca_s_11 8.015700e-02
saf_tot_11 1.266955e-01
com_tot_11 4.340710e-02
eng_tot_11 5.028588e-02
aca_tot_11 7.229584e-02
AP Test Takers 5.687940e-01
Total Exams Taken 5.585421e-01
Number of Exams with scores 3 4 or 5 5.619043e-01
SAT Critical Reading Avg. Score 9.868201e-01
SAT Math Avg. Score 9.726430e-01
SAT Writing Avg. Score 9.877708e-01
...
SIZE OF SMALLEST CLASS 2.440690e-01
SIZE OF LARGEST CLASS 3.052551e-01
SCHOOLWIDE PUPIL-TEACHER RATIO NaN
schoolyear NaN
frl_percent -7.018217e-01
total_enrollment 3.668201e-01
ell_num -1.535745e-01
ell_percent -3.981643e-01
sped_num 3.486852e-02
sped_percent -4.413665e-01
asian_num 4.748801e-01
asian_per 5.686267e-01
black_num 2.788331e-02
black_per -2.827907e-01
hispanic_num 2.568811e-02
hispanic_per -3.926373e-01
white_num 4.490835e-01
white_per 6.100860e-01
male_num 3.245320e-01
male_per -1.101484e-01
female_num 3.876979e-01
female_per 1.101928e-01
Total Cohort 3.244785e-01
grade_span_max -2.495359e-17
expgrade_span_max NaN
zip -6.312962e-02
total_students 4.066081e-01
number_programs 1.166234e-01
lat -1.198662e-01
lon -1.315241e-01
Name: sat_score, dtype: float64Эти данные дают нам ряд подсказок, которые надо будет проработать:
- Общая численность в классах (total_enrollment) сильно корреллирует с оценками ЕГЭ (sat_score), чтоб удивительно, потому что, на первый взгляд, маленькие школы, которые лучше работают с отдельными студентами, должны иметь более высокие оценки.
- Процент женщин в школе (female_per) позитивно коррелирует с оценками ЕГЭ, в то время как процент мужчин (male_per) — негативно.
- Ни один результат опроса не коррелирует сильно с оценками ЕГЭ.
- Есть существенное расовое неравенство в оценках ЕГЭ (white_per, asian_per, black_per, hispanic_per).
- ell_percent сильно коррелирует в обратную сторону с оценками ЕГЭ.
Каждый пункт — потенциальное место для исследования и истории на основе данных.
На всякий случай напомню, что корреляция (и ковариация) показывают только меру линейной зависимости. Если связь есть, но не линейная а, скажем, квадратичная — корреляция ничего толкового не покажет.
Ну и, конечно же, корреляционная связь ни в коем роде не указывает на причину и следствие. Просто, что две величины склонны изменяться пропорционально. Ниже как раз пример с поиском действительной закономерности и разобран.
Определяем контекст
Прежде, чем погружаться в исследование данных, надо бы определить контекст, как для нас самих, так и для тех, кто будет читать потом наш анализ. Хороший способ — исследовательские графики или карты. В нашем случае, мы нарисуем на карте месторасположение наших школ, что поможет читающим понять исследуемую нами проблему.
В коде ниже мы:
- Подготовим карту Нью-Йорка
- Добавим маркер на карту для каждой школы в городе
- Отрисуем карту
In [82]:
import folium
from folium import plugins
schools_map = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
marker_cluster = folium.MarkerCluster().add_to(schools_map)
for name, row in full.iterrows():
folium.Marker([row["lat"], row["lon"]], popup="{0}: {1}".format(row["DBN"], row["school_name"])).add_to(marker_cluster)
schools_map.create_map('schools.html')
schools_map
Out[82]: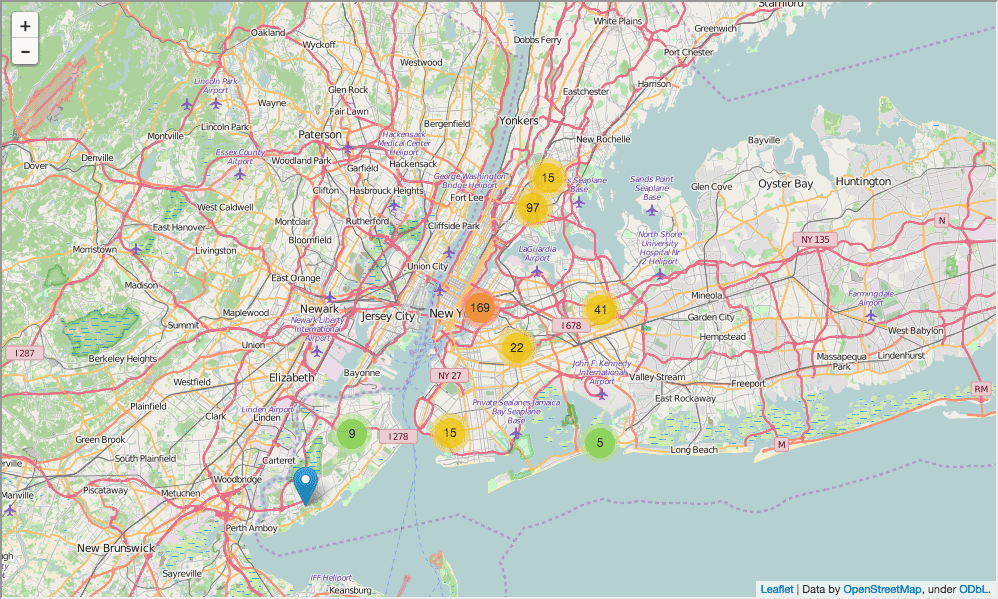
Карта в целом помогает, но сложно понять, где же больше всего в Нью-Йорке школ. Сделаем вместо этого тепловую карту:
In [84]:
schools_heatmap = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
schools_heatmap.add_children(plugins.HeatMap([[row["lat"], row["lon"]] for name, row in full.iterrows()]))
schools_heatmap.save("heatmap.html")
schools_heatmap
Out[84]: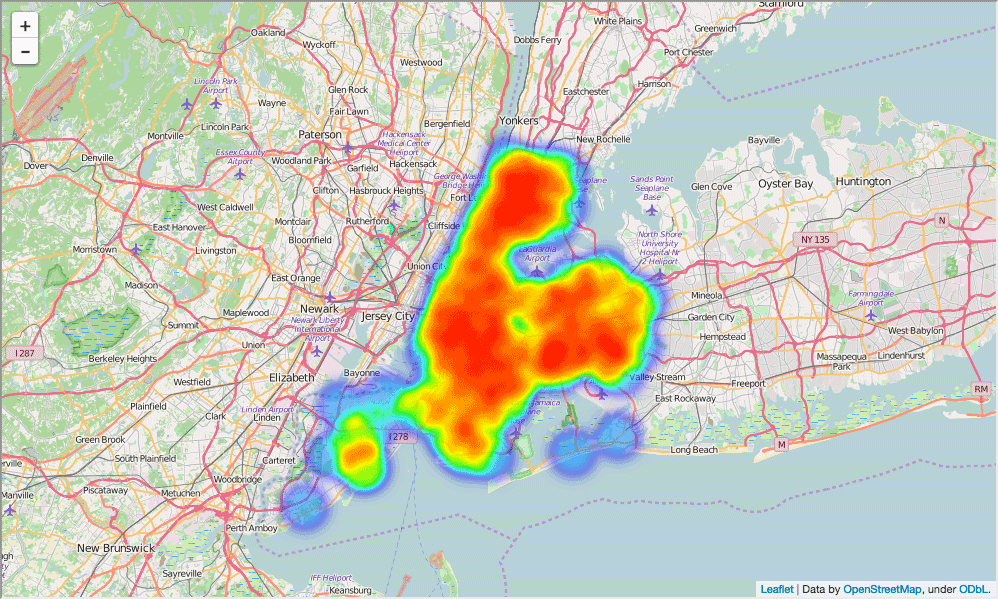
Карты округов
Тепловые карты хороши для отображения градиентов, но хочется что-то более структурированное, чтобы отразить разницу в оценках ЕГЭ по городу. Школьные округа подходят для отображения этой информации, т.к. у каждого округа своя администрация. В Нью-Йорке несколько дюжин школьных округов, и каждый занимает небольшую площадь.
Мы можем посчитать оценки за ЕГЭ по округу и нанести их на карту. В коде ниже мы:
- Сгруппируем full по школьному округу
- Посчитаем среднее в каждой колонке по каждому округу
- Преобразуем поле school_dist, удалив нули в начале, чтобы оно соответствовало координатам наших округов
In [ ]:
district_data = full.groupby("school_dist").agg(np.mean)
district_data.reset_index(inplace=True)
district_data["school_dist"] = district_data["school_dist"].apply(lambda x: str(int(x))Теперь мы можем нарисовать средний балл ЕГЭ по каждому школьному округу. Для этого прочитаем данные в формате GeoJSON, чтобы определить форму каждого округа, потом сопоставим каждую форму с оценкой с помощью столбца school_dist, и, наконец, нарисуем график.
In [85]:
def show_district_map(col):
geo_path = 'schools/districts.geojson'
districts = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
districts.geo_json(
geo_path=geo_path,
data=district_data,
columns=['school_dist', col],
key_on='feature.properties.school_dist',
fill_color='YlGn',
fill_opacity=0.7,
line_opacity=0.2,
)
districts.save("districts.html")
return districts
show_district_map("sat_score")
Out[85]:
Исследуем наполняемость и оценки ЕГЭ
У нас теперь есть контекст на графике со школами, и оценки ЕГЭ по округам; люди, просматривающие наш анализ лучше поймут контекст датасета. Установив декорации, можем теперь приступить к исследованию тех аспектов, что мы уже установили во время поиска корреляций. Первый аспект — исследовать связь между числом студентов, посещающих школу, и оценками ЕГЭ.
Мы можем исследовать это через диаграмму рассеяния, которая сравнит наполняемость с оценками по всем школам:
In [87]:
%matplotlib inline
full.plot.scatter(x='total_enrollment', y='sat_score')
Out[87]:
<matplotlib.axes._subplots.AxesSubplot at 0x10fe79978>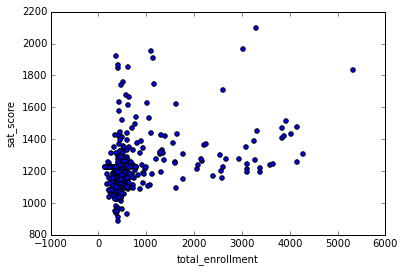
Видим, что есть кластер слева внизу с низкой наполняемостью и оценками. За исключением него, есть слабая позитивная корреляция между оценками ЕГЭ и общей наполняемостью. График наших корреляций может выявить неожиданные закономерности.
Мы можем исследовать этот момент глубже, узнав названия школ с низкой наполняемостью и оценками:
In [88]:
full[(full["total_enrollment"] < 1000) & (full["sat_score"] < 1000)]["School Name"]
Out[88]:
34 INTERNATIONAL SCHOOL FOR LIBERAL ARTS
143 NaN
148 KINGSBRIDGE INTERNATIONAL HIGH SCHOOL
203 MULTICULTURAL HIGH SCHOOL
294 INTERNATIONAL COMMUNITY HIGH SCHOOL
304 BRONX INTERNATIONAL HIGH SCHOOL
314 NaN
317 HIGH SCHOOL OF WORLD CULTURES
320 BROOKLYN INTERNATIONAL HIGH SCHOOL
329 INTERNATIONAL HIGH SCHOOL AT PROSPECT
331 IT TAKES A VILLAGE ACADEMY
351 PAN AMERICAN INTERNATIONAL HIGH SCHOO
Name: School Name, dtype: objectПоиск в Гугле показывает, что большая часть этих школ для студентов, изучающих английский, и, как итог, с низкой наполняемостью. Это исследование показало, что не наполняемость в целом коррелирует с оценками ЕГЭ — коррелирует то, изучают ли ученики в школе английский как второй язык, или нет.
Исследование изучающих английский и оценок ЕГЭ
Теперь мы знаем, что процент изучающих английский в школе связан с более низкими оценками ЕГЭ, и можем исследовать эту связь. Столбец ell_percent - это процент изучающих английский в каждой школе. Можем построить диаграмму рассеяния по этой связи:
In [89]:
full.plot.scatter(x='ell_percent', y='sat_score')
Out[89]:
<matplotlib.axes._subplots.AxesSubplot at 0x10fe824e0>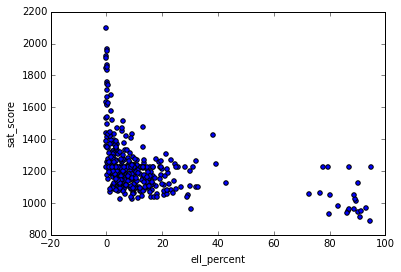
Похоже, есть группа школ с высоким ell_percentage и с низким средним баллом ЕГЭ. Можем это исследовать на уровне округов, определяя процент изучающих английский в каждом округе и смотря, как он связан с оценкой по округу:
In [90]:
show_district_map("ell_percent")
Out[90]: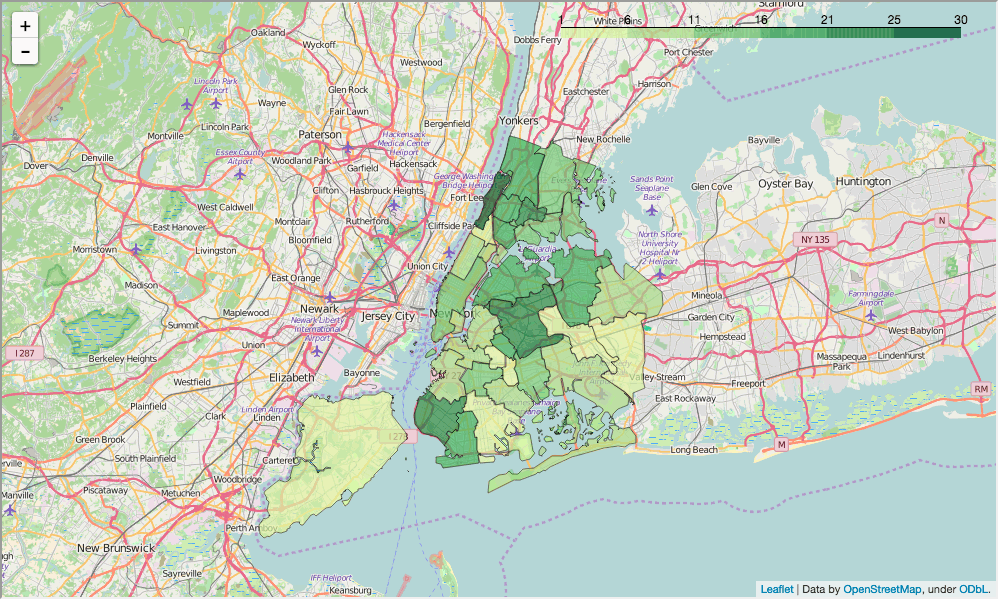
Как мы видим по двум картам округов, округа с более низким процентом англоизучающих имеют тенденцию к более высоким оценкам ЕГЭ, и наоборот.
Коррелируем оценки по опросам и оценки ЕГЭ
Логично было бы предположить, что результаты опросов учеников, родителей и учителей будут сильно коррелировать с оценками ЕГЭ. Разумно, что школы с более высокими учебными ожиданиями имеют тенденцию к более высоким баллам ЕГЭ. Для проверки этой теории построим график оценок ЕГЭ и различных показателей из опросов:
In [91]:
full.corr()["sat_score"][["rr_s", "rr_t", "rr_p", "N_s", "N_t", "N_p", "saf_tot_11", "com_tot_11", "aca_tot_11", "eng_tot_11"]].plot.bar()
Out[91]:
<matplotlib.axes._subplots.AxesSubplot at 0x114652400>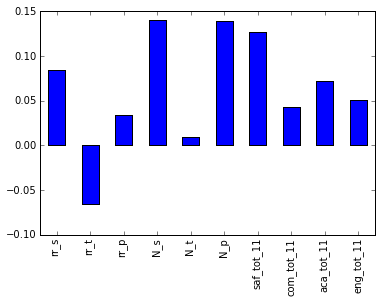
На удивление, больше всего коррелируют N_p и N_s, число участвовавших в опросе родителей и учеников соответственно. Оба сильно коррелируют с общей наполняемостью, так что скорее всего они испытывают влияние и ell_learners. Ещё одна сильно коррелирующая метрика — saf_t_11. Это то, как оценивают безопасность школы ученики, родители и учителя. Логично, что, чем безопаснее школа — тем более комфортно ученикам там учиться. Хотя, больше ни один фактор, типа вовлечённости, общения и академических ожиданий, не коррелирует с оценками ЕГЭ. Это может объясняться тем, что в Нью-Йорке задают неправильные вопросы в опросах, или что предполагают влияние на эти оценки не тех факторов (если их цель — улучшить оценки ЕГЭ, то такого быть не должно).
Изучаем расы и оценки ЕГЭ
Ещё один аспект для исследования включает в себя расы и оценки ЕГЭ. Там была большая корреляция, и её график поможет нам понять, что происходит:
In [92]:
full.corr()["sat_score"][["white_per", "asian_per", "black_per", "hispanic_per"]].plot.bar()
Out[92]:
<matplotlib.axes._subplots.AxesSubplot at 0x108166ba8>
Похоже, высокий процент белых и азиатских учеников коррелирует с более высокими оценками ЕГЭ, но более высокий процент черных и испанцев коррелирует с более низкими оценками. Для испанских студентов это может быть следствием факта, что там много недавних иммигрантов, изучающих английский. Нанесём на карту процент испаноязычных по округу, чтобы увидеть корреляцию глазами:
In [93]:
show_district_map("hispanic_per")
Out[93]:
Похоже, какая-то корреляция с процентом англоизучающих есть, но надо копнуть глубже в этом и других направлениях расовых различий и оценок ЕГЭ.
Половые различия в оценках ЕГЭ
Последний аспект для исследования — связь между полом и оценками. Мы уже заметили, что более высокий процент женщин в школе имеет тенденцию к корреляции с более высокими баллами ЕГЭ. Мы можем этого отразить на столбчатой диаграмме:
In [94]:
full.corr()["sat_score"][["male_per", "female_per"]].plot.bar()
Out[94]:
<matplotlib.axes._subplots.AxesSubplot at 0x10774d0f0>
Чтобы лучше разобраться в корреляции, сделаем диаграмму рассеяния между female_per и sat_score:
In [95]:
full.plot.scatter(x='female_per', y='sat_score')
Out[95]:
<matplotlib.axes._subplots.AxesSubplot at 0x104715160>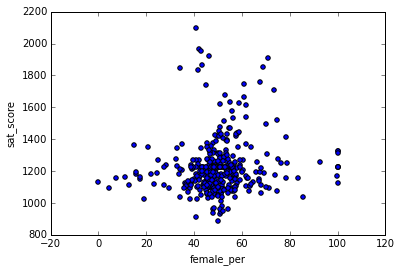
Похоже, есть кластер школ с высоким процентом женщин и очень высокими оценками ЕГЭ (справа вверху). Мы можем узнать названия школ этого кластера:
In [96]:
full[(full["female_per"] > 65) & (full["sat_score"] > 1400)]["School Name"]
Out[96]:
3 PROFESSIONAL PERFORMING ARTS HIGH SCH
92 ELEANOR ROOSEVELT HIGH SCHOOL
100 TALENT UNLIMITED HIGH SCHOOL
111 FIORELLO H. LAGUARDIA HIGH SCHOOL OF
229 TOWNSEND HARRIS HIGH SCHOOL
250 FRANK SINATRA SCHOOL OF THE ARTS HIGH SCHOOL
265 BARD HIGH SCHOOL EARLY COLLEGE
Name: School Name, dtype: objectГугл нам объясняет, что это элитные школы, специализирующиеся на изобразительном искусстве. В этих школах больше процент женщин и выше оценки. Отсюда, скорее всего, корреляция между высоким процентом женщин и высокими оценками, и, наоборот, корреляция между высоким процентом мужчин и низкими оценками ЕГЭ.
Замечательная первая диаграмма наглядно демонстрирует нам, что в сумме процент мужчин и женщин должен быть в каждой школе 100 (ну или близок к нему).
Оценки по углубленной программе
До сего момента мы рассматривали демографические аспекты. Один аспект в данных, на который надо обратить внимание — это связь между большим числом студентов, сдавших углубленную программу, и высокими оценками ЕГЭ. Логично, что они должны коррелировать, поскольку ученики с более высокими желаниями в учёбе должны лучше сдавать ЕГЭ.
In [98]:
full["ap_avg"] = full["AP Test Takers "] / full["total_enrollment"]
full.plot.scatter(x='ap_avg', y='sat_score')
Out[98]:
<matplotlib.axes._subplots.AxesSubplot at 0x11463a908>
Похоже, между этими вещами сильная корреляция. Справа вверху есть интересный кластер школ с высокими оценками и высокой долей учеников, сдававших экзамен по УП:
In [99]:
full[(full["ap_avg"] > .3) & (full["sat_score"] > 1700)]["School Name"]
Out[99]:
92 ELEANOR ROOSEVELT HIGH SCHOOL
98 STUYVESANT HIGH SCHOOL
157 BRONX HIGH SCHOOL OF SCIENCE
161 HIGH SCHOOL OF AMERICAN STUDIES AT LE
176 BROOKLYN TECHNICAL HIGH SCHOOL
229 TOWNSEND HARRIS HIGH SCHOOL
243 QUEENS HIGH SCHOOL FOR THE SCIENCES A
260 STATEN ISLAND TECHNICAL HIGH SCHOOL
Name: School Name, dtype: objectГугл показывает, что это достаточно требовательные школы, куда нужно сдать экзамен, чтобы попасть. Логично, что в этих школах много кто берёт углубленную программу.
Оформляем историю
В data science история никогда по-настоящему не заканчивается. Раскрывая анализ остальным, вы позволяете им расширять и формировать его в интересном им направлении. К примеру, в этом посте есть аспекты, которые мы исследовали не полностью, и в которые можно погрузиться глубже.
Один из отличных способов начать рассказывать истории с помощью данных — попытаться расширить или повторить чужой анализ. Если решите двигаться в этом направлении — можете расширять анализ этого поста и попробовать найти что-нибудь ещё. Если так — оставьте мне комментарий, чтобы я посмотрел.
Не мне, конечно, Вику. :)
Что дальше
Если вы добрались до сюда — у вас уже должно быть хорошее понимание того, как рассказывать историю через данные и как сделать первую работу для портфолио.
В Dataquest, у нас сделаны интерактивные обучающие проекты, чтобы вы начали делать своё портфолио для демонстрации его работодателям. Если интересно — можете подписаться и пройти первый модуль бесплатно.
