В статье автор пытается проанализировать почему существуют торговые системы написанные на Java. Как может Java соперничать в области высокой производительности с C и C++? Далее размещены небольшие размышления о достоинствах и недостатках использования Java в качестве языка программирования/платформы для разработки систем HFT.
Небольшой дисклеймер: мир Java широк, и в статье я буду подразумевать именно HotSpot реализацию Java, если не сказано обратное.
1. Введение
Хочется намного рассказать про место Java в мире HFT. Для начала, давайте определимся с тем, что же такое HFT (High Frequency Trading). У этого термина существует несколько определений, объясняющих различные его аспекты. В контексте данной статьи я буду придерживаться объяснения, которое дал Питер Лаури (Peter Lawrey), создатель Java Performance User’s Group: «HFT — это торговля, которая быстрее скорости реакции человека (faster than a human can see)».
Торговые платформы HFT могут анализировать различные рынки одновременно и запрограммированы на проведение сделок в наиболее подходящих рыночных условиях. Применяемая прогрессивная технология дает возможность невероятно быстро обрабатывать данные тысячи транзакций в день, при этом извлекая лишь небольшую прибыль с каждой сделки.
Под данное определение подпадает вся электронная автоматической торговли с характерными временами сотни миллисекунд и меньше, вплоть до микросекунд. Но если достигнуты скорости в единицы микросекунд, то зачем в таком случае нужны системы, которые работают на порядок медленнее? И как они могут зарабатывать деньги? Ответ на этот вопрос состоит из двух частей:
- Чем быстрее должна быть система, тем проще должна быть заложенная в нее модель. Т.е. если наша торговая логика реализована на FPGA, то о сложных моделях можно забыть. И наоборот, если мы пишем код не на FPGA или plain assembler, то мы должны закладывать в код более сложные модели.
- Сетевые задержки. Оптимизировать микросекунды имеет смысл только тогда, когда это ощутимо может сократить суммарное время обработки, которое включает сетевые задержки. Одно дело, когда сетевые задержки — это десятки и сотни микросекунд (в случае работы только с одной биржей), и совершенно другое — 20мс в каждую сторону до Лондона (а до Нью-Йорка еще дальше!). Во втором случае оптимизация микросекунд, затраченных на обработку данных, не принесет ощутимого сокращения суммарного времени реакции системы, в которое входит сетевая задержка.
Оптимизация HFT систем в первую очередь преследует сокращение не суммарной скорости обработки информации (throughput), а времени отклика системы на внешнее воздействие (latency). Что это значит на практике?
Для оптимизации по throughput важна результирующая производительность на длительном интервале времени (минуты/часы/дни/…). Т.е. для подобных систем нормально остановить обработку на какой-то ощутимый промежуток времени (миллисекунды/секунды), например на Garbage Collection в Java (привет, Enterprise Java!) если это не влечет существенного снижения производительности на длительном интервале времени.
При оптимизации по latency в первую очередь интересна максимально быстрая реакция на внешнее событие. Подобная оптимизация накладывает свой отпечаток на используемые средства. Например, если для оптимизации по throughput обычно используются примитивы синхронизации уровня ядра ОС (например, мьютексы), то для оптимизации по latency зачастую приходится использовать busy-spin, так как это минимизирует время отклика на событие.
Определив, что такое HFT, будем двигаться дальше. Где же место Java в этом «дивном новом мире»? И как Java может тягаться в скорости с такими титанами, как C, C++?
2. Что входит в понятие «производительность»
В первом приближении, разделим все аспекты производительности на 3 корзины:
- CPU-производительность как таковая, или скорость выполнения сгенерированного кода,
- Производительность подсистемы памяти,
- Сетевая производительность.
Рассмотрим каждую составляющую подробнее.
2.1. CPU-performance
Во-первых, в арсенале Java есть самое важное средство для генерации действительно быстрого кода: реальный профиль приложения, то есть понимание, какие участки кода «горячие», а какие нет. Это критически важно для низкоуровневого планирования расположения кода.
Рассмотрим следующий небольшой пример:
int doSmth(int i) {
if (i == 1) {
goo();
} else {
foo();
}
return …;
}При генерации кода у статического компилятора (который работает в compile-time) физически нет никакой возможности определить (если не брать в расчет PGO), какой вариант более частый: i == 1 или нет. Из-за этого, компилятор может лишь догадываться, какой сгенерированный код быстрее: #1, #2, или #3. В лучшем случае статический компилятор будет руководствоваться какой-либо эвристикой. А в худшем просто расположением в исходном коде.
Вариант #1
cmpl $1, %edi
je .L7
call goo
NEXT:
...
ret
.L7:
call foo
jmp NEXTВариант #2
cmpl $1, %edi
jne .L9
call foo
NEXT:
...
ret
.L9:
call goo
jmp NEXTВариант #3
cmpl $1, %edi
je/jne .L3
call foo/goo
jmp NEXT:
.L3:
call goo/foo
NEXT:
…
retВ Java же из-за наличия динамического профиля, компилятор всегда знает какой вариант предпочесть и генерирует код, который максимизирует производительность именно для реального профиля нагрузки.
Во-вторых, в Java есть так называемые спекулятивные оптимизации. Поясню на примере. Допустим, у нас есть код:
void doSmth(IMyInterface impl) {
impl.doSmth();
}Вроде бы все понятно: должен сгенерироваться вызов виртуальной функции doSmth. Единственное, что могут сделать статические компиляторы С/С++ в данной ситуации — попытаться выполнить девиртуализацию вызова. Однако на практике данная оптимизация случается относительно редко, так как для ее выполнения необходима полная уверенность в корректности данной оптимизации.
У компилятора Java, работающего в момент работы приложения, есть дополнительная информация:
- Полное дерево загруженных в данный момент классов, на основе которого можно эффективно провести девиртуализацию,
- Статистика о том, какая реализация вызывалась в данном месте.
Даже если в иерархии классов есть другие реализации интерфейса IMyInterface, компилятор выполнит встраивание (inline) кода реализации, что позволит, с одной стороны, избавиться от относительно дорогого виртуального вызова и выполнить дополнительные оптимизации с другой стороны.
В-третьих, компилятор Java оптимизирует программу под конкретное железо, на котором он был запущен.
Статические компиляторы вынуждены использовать только инструкции достаточно древнего железа для обеспечения обратной совместимости. В результате, все современные расширения, доступные в расширениях x86, остаются за бортом. Да, можно компилировать под нескольких наборов инструкций и во время работы программы делать runtime-dispatching (например, с использованием ifunc'ов в LINUX), но кто это делает?
Компилятор Java знает на каком конкретном железе он запущен и может оптимизировать код под данную конкретную систему. Например, если система поддерживает AVX, то будут использоваться новые инструкция, оперирующие новыми векторными регистрами, что значительно ускоряет работу вычислений с плавающей точкой.
2.2. Производительность подсистемы памяти
Выделим несколько аспектов производительности подсистемы памяти: паттерн доступа к памяти, скорость аллокации и деаллокации (освобождения) памяти. Очевидно, что вопрос быстродействия подсистемы памяти крайне обширен и не может быть полностью исчерпан 3 рассматриваемыми аспектами.
2.2.1 Паттерн доступа к памяти
В разрезе паттерна доступа к памяти наиболее интересен вопрос в различии физического расположения объектов в памяти или data layout. И тут у языков С и С++ огромное преимущество — ведь мы можем явно управлять расположением объектов в памяти, а отличии от Java. Для примера рассмотрим следующий код на C++):
class A {
int i;
};
class B {
long l;
};
class C {
A a;
B b;
};
C c;При компиляции данного кода компилятором C/C++, поля полей-подобъектов будут физически расположены последовательно, примерно таким образом (не учитываем возможный паддинг между полями и возможные data-layout трансформации, производимые компилятором):
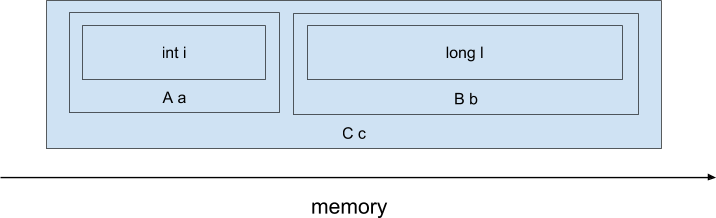
Т.е. выражение виде ‘return c.a.i + c.b.l’ будет скомпилировано в такие инструкции ассемблера x86:
mov (%rdi), %rax ; << чтение c.a.i
add ANY_OFFSET(%rdi), %rax ; << чтение c.b.l и сложение с c.a.i
retТакой простой код был достигнут за счет того, что объект располагается линейно в памяти и компилятор на этапе компиляции смещения требуемых полей от начала объекта. Более того, при обращении к полю c.a.i, процессор загрузит всю кэш-линию длиной 64 байта, в которую, скорее всего, попадут и соседние поля, например c.b.l. Таким образом, доступ к нескольким полям будет относительно быстрый.
Как же будут располагаться данный объект в случае использования Java? В виду того, что объекты не могут быть значениями (в отличии от примитивных типов), а всегда ссылочные, то в процессе выполнения данные будут располагаться в памяти в виде древовидной структуры, а не последовательной области памяти:
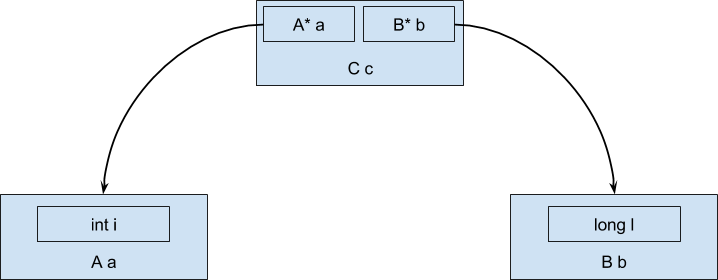
И тогда выражение ‘c.a.i + c.b.l’ будет компилироваться в лучшем случае во что-то похожее на такой код ассемблера x86:
mov (%rdi), %rax ; << загружаем адрес объекта a
mov 8(%rdi), %rdx ; << загружаем адрес объекта b
mov (%rax), %rax ; << загружаем значение поля i объекта a
add (%rdx), %rax ; << загружаем значение поля l объекта bМы получили дополнительный уровень косвенности при обращении к данным внутри объектов-полей, так как в объекте типа С находятся всего лишь ссылки на объекты-поля. Дополнительный уровень косвенности ощутимо увеличивает количество загрузок данных из памяти.
2.2.2. Скорость аллокации (выделения)
Тут у Java значительный перевес относительно традиционных языков с ручным управлением памятью (если не брать искусственный случай, что вся память выделяется на стеке).
Обычно для аллокации в Java используются так называемые TLAB'ы (Thread local allocation buffer), то есть области памяти, уникальные для каждого потока. Аллокация выглядит как уменьшение указателя, указывающего на начало свободной памяти.
Например, указатель на начало свободной памяти в TLAB'е указывает на 0х4000. Для аллокации, скажем, 16 байт нужно изменить значение указателя на 0х4010. Теперь можно пользоваться свежевыделенной памятью в диапазоне 0х4000:0х4010. Более того, так как доступ к TLAB'у возможен только из одного потока (ведь это thread-local buffer, как следует из названия), то нет необходимости в синхронизации!
В языках с ручным управлением памятью, для выделения памяти обычно используются функции operator new/malloc/realloc/calloc. Большинство реализаций содержат ресурсы, разделяемые между потоками, и намного более сложны, чем описанный способ выделения памяти в Java. В некоторых случаях нехватки памяти или фрагментации кучи (heap) операции выделения памяти могут потребовать значительного времени, что ухудшит latency.
2.2.3. Скорость освобождения памяти
В Java используется автоматическое управление памятью и разработчик теперь не должен вручную освобождать выделенную ранее память, так как это делает сборщик мусора (Garbage collector). К достоинствам такого подхода следует отнести упрощение написания кода, ведь одним поводом для головной боли меньше.
Однако это приводит к не совсем ожидаемым последствиям. На практике разработчику приходится управлять различными ресурсами, не только памятью: сетевыми соединениями, соединениями с СУБД, открытыми файлами.
И теперь ввиду отсутствия в языке внятных синтаксических средств контроля за жизненным циклом ресурсов приходится использовать достаточно громоздкие конструкции типа try-finally или try-with-resources.
Сравним:
Java:
{
try (Connection c = createConnection()) {
...
}
}или так:
{
Connection c = createConnection();
try {
...
} finally {
c.close();
}
}С тем, что можно написать в С++
{
Connection c = createConnection();
} // деструктор будет автоматически вызван при вызоде из scope'аОднако вернемся к освобождению памяти. Для всех сборщиков мусора, поставляемых с Java, характерна пауза Stop-The-World. Единственный способ минимизации ее влияния на производительность торговой системы (не забываем, что нам нужна оптимизация не по throughput, а по latency) — это уменьшить частоту любых остановок на Garbage Collection.
В настоящий момент наиболее употребимым способом это сделать является «переиспользование» объектов. То есть когда объект нам становится не нужен (в языках C/C++ необходимо вызвать оператор delete), мы записываем объект в некоторый пул объектов. А когда нам необходимо создать объект вместо оператора new, обращаемся к этому пулу. И если в пуле есть ранее созданный объект, то достаем его и используем, как будто он был только что создан. Посмотрим, как это будет выглядеть на уровне исходного кода:
Автоматическое управление памятью:
{
Object obj = new Object();
.....
// Здесь объект уже не нужен, просто забываем про него
}И с переиспользованием объектов:
{
Object obj = Storage.malloc(); // получаем объект из пула
...
Storage.free(obj); // возвращаем объект в пул
}Тематика переиспользования объектов, как мне кажется, не достаточно освещена и, безусловно, заслуживает отдельной статьи.
2.3. Сетевая производительность
Тут позиции Java вполне сравнимы с традиционными языками C и C++. Более того, сетевой стек (уровень 4 модели OSI и ниже), расположенный в ядре ОС, физически один и тот же при использовании любого языка программирования. Все настройки быстродействия сетевого стека, релевантные для C/C++, релевантны и для приложения на Java.
3. Скорость разработки и отладки
Java позволяет намного быстрее развивать логику за счет намного большей скорости написания кода. Не в последнюю очередь, это является следствием отказа от ручного управления памятью и дуализма указатель-число. Действительно, зачастую быстрее и проще настроить Garbage Collection до удовлетворительного уровня, чем вылавливать многочисленные ошибки управления динамической памятью. Вспомним, что ошибки при разработке на C++ зачастую принимают совершенно мистический оборот: воспроизводятся в релизной сборке или только по средам (подсказка: в английском языке “среда” — самый длинный по написанию день недели). Разработка на Java в подавляющем большинстве случаев обходится без подобного оккультизма, и на каждую ошибку можно получить нормальный stack trace (даже с номерами строк!). Использование Java в HFT позволяет тратить на написание корректного кода существенно меньше времени, что влечет за собой увеличение скорости адаптации системы к постоянным изменениям на рынке.
4. Резюме
В мире HFT то, насколько успешна торговая система зависит от суммы двух параметров: скорости самой торговой системы и скорости ее разработки, развития. И если скорость работы торговой системы — критерий относительно простой и понятный (по крайней мере понятно как измерять), то скорость развития системы ощутимо сложнее в оценке. Можно представить скорость развития как сумму бесчисленного множества факторов, среди которых и скорость написания кода и скорость отладки и скорость профилирования и удобство инструментальных средств и порог входа. Также, важными факторами являются скорость интеграции идей, полученный от аналитиков-квантов (Quantitative Researcher’ов), которые, в свою очередь, могут переиспользовать код продуктовой торговой системы для анализа данных. Как мне кажется, Java — разумный компромисс между всеми этими факторами. Этот язык сочетает в себе:
- достаточно хорошее быстродействие;
- относительно низкий порог входа;
- простоту инструментальных средств (К сожаления, для C++ нет сред разработки, сравнимых с IDEA);
- возможность простого переиспользования кода аналитиками;
- простоту работы под большими технически сложными системами.
Суммируя вышеперечисленное, можно резюмировать следующее: у Java в HFT есть своя существенная ниша. Использование Java, а не С++, ощутимо ускоряет развития системы. В вопросе производительности быстродействие Java может быть сравнимо с быстродействием C++ и кроме того, в Java есть набор уникальных, недоступных для С/С++ возможностей по оптимизации.
