Продолжаем серию статей, посвященных многоядерным цифровым сигнальным процессорам TMS320C6678. В данной статье будет рассмотрена подсистема памяти ядра. Архитектура памяти процессора — один из ключевых моментов, напрямую влияющих на его эффективность. Знание особенностей организации архитектуры памяти позволяет разработчику более рационально использовать ресурсы DSP. Современные процессоры имеют достаточно сложную архитектуру памяти, включающую несколько уровней и контроллеры кэш. При этом в случае DSP работа с памятью усложняется наличием свободы выбора объемов кэш-памяти на разных уровнях, а для многоядерных процессоров характерна проблема синхронизации кэш разных ядер.
Процессоры TMS320C66x имеют иерархическую 3-уровневую архитектуру памяти. Иерархическая архитектура памяти позволяет совмещать высокую скорость работы с памятью и большой объем доступной памяти. В своем развитии технология изготовления памяти несколько отстает от процессорной техники. Тактовая частота процессорных ядер растет; растут и требования к объему внутренней и внешней памяти. Вместе с тем, обеспечить процессор памятью большого объема, работающей на частоте ядра оказывается сложной задачей. Для решения данной проблемы широкое развитие получили иерархические архитектуры памяти, в которых память делится на несколько уровней. Память небольшого объема работает на частоте ядра и представляет уровень L1. Память уровня L2 работает на меньшей частоте, но имеет больший объем. И так далее. Для ускорения работы с памятью младших уровней (медленной памятью) быстрая память может частично или полностью конфигурироваться как кэш-память.
Архитектура памяти процессоров TMS320C66xx включает:
Память уровня L1 и L2 может полностью или частично конфигурироваться, как кэш-память, ускоряя работу с более медленной памятью уровней L2 и L3. Архитектура памяти играет одну из наиболее важных ролей в общей производительности процессора, поскольку ограничивает пропускную способность каналов подачи данных на исполнительные элементы. Далее подробнее рассматриваются составляющие архитектуры памяти процессора TMS320C66x.

Рисунок 1 — Подсистема памяти ядра CorePac процессора TMS320C66xx
Термин CorePac обозначает одно ядро многоядерного процессора TMS320C66x. Ядро строится в соответствии со структурой, представленной на следующем рисунке 1. Оно включает вычислительные ресурсы – С66х, – рассмотренные в предыдущей статье и следующие компоненты, относящиеся к подсистеме памяти:
Ниже рассматриваются основные аспекты функционирования перечисленных устройств.
Прежде, чем приступать к рассмотрению архитектуры памяти процессора TMS320C66x, целесообразно познакомиться с основными принципами функционирования кэш.
Кэширование программ и данных имеет основной целью ускорение работы быстрого ядра с медленной памятью большого объема. Наиболее близкой к ядру, работающей на частоте ядра, является память уровня L1, имеющая небольшой объем. Далее идет память уровня L2 большего объема, работающая, как правило, вдвое медленнее. Далее может идти память уровня L3, L4 и так далее, имеющая еще больший объем, но работающая еще медленнее. Это может быть общая память многоядерной системы или внешние микросхемы памяти.
Эффективность применения кэш основана на двух фактах – локализованности программ и данных во времени и в пространстве памяти (temporal and spatial locality) [1]. Локализованность во времени означает многократное использование одних и тех же программ или данных. Локализованность в пространстве памяти означает, что коды/данные используются группами. Эти два факта позволяют при обращении к медленной памяти читать из нее запрашиваемые коды/данные вместе с соседними группами кодов/данных, копировать их в более быструю память, рассчитывая на то, что запрашиваемые в будущем коды/данные уже будут присутствовать в быстрой памяти.
Группы соседних кодов/данных, одновременно копируемые в кэш, называются строками кэш (cache line). Очевидно, что, чем больше размер строки кэш, тем больше эффективность кэш при пространственной локализации кодов/данных, однако, это усложняет архитектуру кэш и приводит к сокращению количества строк кэш, то есть меньше использует временную локализацию кодов/данных. Размер линии кэш памяти L1P составляет 32 байта. Интересно, что коды, исполняемые из внешней памяти, в процессоре TMS320C66x кэшируются в L1P всегда.
Простейшей схемой организации кэширования является кэш с прямым отображением в памяти (direct-mapped cache). Вся основная память разбивается на фрагменты, размер каждого из которых равен размеру кэш. Соответственно, в кэш в каждый момент времени может находиться только один фрагмент основной памяти, либо непересекающиеся части нескольких разных фрагментов. Коды/данные, расположенные в основной памяти в разных фрагментах, но в соответствующих друг другу строках не могут одновременно находиться в кэш. Возникает конфликт кэширования (conflict miss), что приводит к неэффективности работы кэш. Основной тип промахов кэш для данного механизма кэширования – это промах из-за нехватки объема кэш (capacity miss). Другой неизбежный режим неэффективной работы кэш – это начальное кэширование (compulsory miss). Это промахи кэш при первом обращении к основной памяти.
Чтобы уйти от проблемы нехватки объема кэш в механизмах кэширования с прямым отображением, используют так называемые ассоциативные кэш. Можно считать, что в них механизм кэширования с прямым отображением просто дублируется (становится двухвариантным – 2 way), расширяется в 4 раза (четырехвариантный – 4-way) и так далее. Соответственно, размещение кодов/данных из разных фрагментов и пересекающихся по адресам становится возможным и тем больше таких пересекающихся кодов/данных можно одновременно кэшировать, чем больше вариантов (путей — way) поддерживается. Данная архитектура оказывается более мощной по сравнению с кэш с прямым отображением, но ценой большей сложности и затратности. Все строки кэш с перекрывающимися адресами, то есть принадлежащие разным путям, именуется набором или рядом строк кэш (Set). Когда одну из строк кэш надо заменить, то выбирается тот путь, который давно не использовался, по сравнению с другими. За этим следит бит LRU, являющийся составной частью строки кэш. Структуру кэш раскрывает таблица.
Кэш «с кэшированием при чтении» (read-allocate cache) – это тип кэш, при котором содержимое кэш меняется только при промахе чтения, то есть когда новые данные/коды запрашиваются из основной памяти, и они одновременно копируются в кэш. При промахе записи (когда ядро пишет в ячейку памяти, не отображенную в кэш) запись идет напрямую в основную память через специальный буфер записи (write buffer) в составе контроллера памяти.
Кэширование с отложенным возвратом кодов/данных из кэш в основную память (write back cache) означает, что при попадании записи (write hit) данные/коды в основную память не пишутся, а пишутся только в кэш с пометкой, что данная строка кэш является грязной (Dirty), то есть ее надо в будущем скопировать в основную память.
При работе с кэш на ЦСП TMS320C66xx следует иметь в виду следующие аспекты. Память уровня L2 всегда кэшируется в L1, достаточно лишь сконфигурировать L1, как кэш. При кэшировании внешней памяти, необходимо дополнительно указывать, что и где кэшировать. При этом коды из внешней памяти в L1P кэшируются всегда. Внешняя память делится на сегменты по 16 Мбайт, и их кэшируемость контролируется специальными управляющими регистрами MAR.
Те фрагменты памяти, которые выделяются под кэш, не указываются в разделе MEMORY в cmd-файле.
При работе с кэш неминуемо возникает проблема синхронизации кэш и основной памяти (cache coherence). Когерентность (синхронизация) кэш означает согласование содержимого кэш и основной памяти. Проблема когерентности кэш имеет место всегда, когда есть общий ресурс памяти, эта память является кэшируемой и происходит изменение содержимого памяти. Если кэш и основная память имеют разное содержимое, то есть являются не синхронизированными, то одно из устройств, обращающееся к памяти, может обратиться к неверным данным.
Процессор C66x обеспечивает автоматическую синхронизацию доступа к данным со стороны ядра и со стороны EDMA/IDMA. Когда DMA читает L2 SRAM, данные читаются из L1D-кэш и не меняются в L2 SRAM. Когда DMA пишет в L2 SRAM, данные пишутся одновременно и в L2 SRAM, и в L1D. Автоматическая синхронизация основана на механизме snooping – слежение. При обращениях со стороны DMA автоматически проверяется кэшируемость кодов/данных в памяти.
Ручная синхронизация (с помощью специальных команд библиотеки CSL) необходима в следующих случаях:
Типовым вариантом использования памяти является следующая ситуация. C периферийного устройства 1 посредством DMA данные записываются в массив в памяти уровня L2 для обработки. Также через DMA обработанные данные выводятся из памяти L2 через периферийное устройство 2. Чтобы разделить обработку, ввод данных и вывод данных, используются две пары ping-pong буферов. При использовании только памяти уровней L2 с кэшированием в L1 синхронизация выполняется автоматически выше описанным образом.
Когда 2 пары ping-pong буферов размещаются во внешней памяти и проходят через 2 уровня кэш – L2 и L1 – тогда требуется ручная синхронизация. Перед началом ввода очередного массива во входной буфер по каналам DMA все строки кэш L1D и L2, ссылающиеся на данный массив, должны быть объявлены недействительными (invalidate). Массив будет заново кэшироваться, вызывая издержки кэш первого обращения. Аналогично, перед тем, как выходной массив будет отправлен через механизм DMA на периферийное устройство, необходимо выполнить синхронизацию памяти L1D и L2 с внешней памятью – write back.
Эффективность работы кэш-памяти является необходимым залогом успешной работы всего процессора. С этой точки зрения особенное значение приобретают отладочные средства визуализации кэш. Функция визуализации кэш поддерживается средой разработки кодов для процессоров Texas Instruments Code Composer Studio в окне отображения памяти процессора. Необходимо дополнительно включать функцию анализа памяти при выводе окна.
Память программ уровня L1 (L1P) предназначена только для хранения программных кодов. Объем памяти варьируется от устройства к устройству и для процессора TMS320C6678 составляет 32 Кбайта. Память L1P может частично конфигурироваться как кэш. При этом объем кэш может составлять 0, 4, 8, 16 или 32 Кбайта. Остальной объем памяти конфигурируется как обычное ОЗУ. Под кэш выделяются старшие адреса L1P. По включению память L1P конфигурируется или полностью как ОЗУ, или с максимальным объемом кэш (зависит от конкретного устройства).
Память L1P сама кэшироваться в других областях кэш не может. Запись в память L1P производится только по каналам EDMA или IDMA. То есть запись в память L1P не доступна для разработчика, желающего записывать что-то в нее со стороны вычислительного ядра в ходе выполнения программы.
Обычно при обращении к L1P как к ОЗУ число тактов ожидания равно 0, однако, максимальное число тактов ожидания при работе с L1P может достигать 3. Управление памятью L1P в режиме кэш осуществляется через набор регистров. Изменение размера кэш и других параметров может осуществляться в ходе выполнения программы.
Опишем более подробно работу L1P в режиме кэш. В режиме кэш память L1P является памятью кэш с прямым отображением (direct-mapped cache). Данный механизм кэширования является наиболее простым и может наиболее часто приводить к конфликтам записи в кэш из разных секторов основной памяти. Очевидно, считается, что такого механизма для памяти программ оказывается достаточно, поскольку коды программ отличаются наибольшей степенью локализованности в пространстве памяти по сравнению с данными.
Режим фиксации кэш L1P (freeze mode) позволяет зафиксировать фрагмент кода в кэш. Попадания чтения выполняются обычным образом, а промахи кэш не меняют содержимого кэш и не делают коды в кэш недействительными. Фиксация L1P полезна при исполнении прерываний. Из-за переключения состояния процессора на небольшое время, нет смысла «портить» содержимое кэш.
Для синхронизации кэш L1P и основной памяти можно применять глобальную и блочную синхронизацию. Глобальная подразумевает синхронизацию всего объема кэш и выполняется по значимым для всей системы событиям, таким как смена задачи, смена режима работы кэш и других. Синхронизация подразумевает объявление содержимого кэш недействительным (invalidation) и выполняется установкой бит в управляющих регистрах. При этом копирование кэш в основную память не производится, поскольку кэш программ не модифицируется ядром.
Блочная синхронизация подразумевает, что в регистре управления кэш задается начальный адрес и длина блока кода, который надо объявить недействительным.
Синхронизация кэш занимает определенное время. Поэтому после инициализации синхронизации желательно выполнять ожидание окончания синхронизации. Об окончании синхронизации говорит флаг в регистре управления. Соответственно, нужен код, который этот флаг анализирует, причем данный код не следует располагать в области памяти, зависящей от кэш.
L1P-кэш работает на частоте ядра и в случае попаданий кэш никаких простоев нет, и команды выполняются за один такт (в конвейере). Однако в случае промаха кэш ситуация оказывается сложнее. L1P-кэш обращается к L2-памяти с целью выборки команд. Время чтения команды оказывается больше, но насколько больше, зависит от конкретного состояния конвейера и оказывается трудно предсказуемым. Зачастую простои конвейера из-за промахов кэш оказываются скрытыми (не влияют на процесс выполнения программы) из-за простоев самого командного конвейера. На TMS320C66x командный конвейер организован так, что его простои перекрываются с простоями из-за промахов кэш, что позволяет уйти от избыточного затягивания процесса выполнения команд. Здесь под простоями командного конвейера понимается то, что пакет выборки в большинстве случаев содержит более одного пакета выполнения, и выборка команд производится реже, чем их выполнение. Начальные стадии конвейера не читают следующую команду – простаивают, пока последующие стадии конвейера не выполнят текущие пакеты. Таким образом, появляется дополнительное время на обращение к памяти уровня L2 и далее, что позволяет частично или полностью скрыть промахи кэш L1P. Данная технология именуется конвейерная обработка промахов кэш (L1P miss pipeline).
На С66х пакет выполнения может формироваться из двух пакетов выборки.
Однако, очевидно, что для хорошо оптимизированных кодов, когда пакеты выборки практически совпадают с пакетами выполнения, данный подход теряет свою эффективность, и промахи кэш способны существенно затягивать процесс выполнения программ. Ориентировочные значения задержек выполнения из-за промахов кэш для различных вариантов состояния конвейера можно найти в документации на процессор.
Режим пониженного потребления используется для снижения общего потребления процессора в случаях, когда это представляет интерес. Память L1P может переводиться в режим пониженного потребления статически (static power-down), что подразумевает установку управляющего бита режима пониженного потребления; настройку прерывания, которое будет «будить» L1P и выполнение команды IDLE. Также память может переходить в данный режим динамически (dynamic power-down), что означает автоматический переход при выполнении программы из буфера SPLOOP. Также L1P-кэш переходит в режим пониженного потребления (feature-oriented power-down), когда кэш является неактивной (disabled). То есть если L1P сконфигурирована как кэш, но не активирована, то она находится в режиме пониженного потребления.
Чтение памяти L1P может производиться ядром, DMA и IDMA. Все команды включают 2 бита защиты – бит исполнения в пользовательском и бит исполнения в администраторском режимах. При чтении команд ядром они всегда анализируются на разрешенность их исполнения в текущем режиме. Если они оказываются запрещенными, происходит исключение (в случае чтения ядром) или прерывание (в случае чтения DMA/IDMA). Кроме того, доступ к регистрам памяти L1P также контролируется контроллером L1P и вызывает исключение в случае чтения или записи защищенного регистра.
Доступ для чтения/записи со стороны DMA/IDMA также контролируется на разрешенность. Можно настроить разные права доступа к различным страницам памяти. L1P строится из 16 страниц защиты памяти.
Объем внутренней памяти данных L1 составляет до 128 Кбайт в зависимости от модели процессора и для TMS320C6678 составляет 32 Кбайта ОЗУ. Часть или вся L1D может конфигурироваться как кэш-память.
L1D-кэш – это двухвариантная ассоциативная кэш «с кэшированием при чтении» и «кэшированием с отложенным возвратом» (2-way set-associative, read-allocate, write back cache). Значения перечисленных понятий раскрывались выше.
При включении L1D инициализируется или полностью как ОЗУ или с максимальным размером кэш. Дальнейшая настройка L1D реализуется через регистры управления.
Кэш работает следующим образом. 32-разрядный адрес, выставляемый на адресную шину, имеет структуру, проиллюстрированную на рисунке.

Рисунок 2 — Структура адреса при обращении к кэш
Поле offset – это адрес в пределах одной строки кэш. Контроллером кэш он игнорируется, поскольку строка либо есть в кэш, либо нет целиком. Размер строки 64 байта соответствует размеру поля offset 6 бит. Чтобы установить факт наличия строки в кэш данное поле не нужно.
Поле set – определяет набор строк, к которым идет обращение. Длина поля set зависит от объема кэш-памяти и лежит в пределах 5-14 бит.
Поле Tag окончательно определяет адрес строки, к которой идет обращение, учитывая требуемый путь (way).
Кэш-память данных, в отличие от памяти программ, может меняться ядром процессора. Поэтому возврат измененных данных из кэш в основную память (write back) происходит либо по команде ядра, либо просто автоматически при замене строки кэш новой строкой из основной памяти. Размер L1D-кэш может меняться динамически.
В режиме фиксации содержимого кэш L1D работает в обычном режиме в случае попаданий чтения и записи и в случае промаха записи. Только бит LRU не изменяется при промахах. В случае промаха чтения обновление кэш не происходит. Команды синхронизации кэш продолжают работать в обычном режиме. Переход в режим фиксации кэш и обратно производится записью в регистры и может производиться динамически и достаточно быстро. Кроме того, часто в режим фиксации переводят одновременно L1D и L1P. Для этого в регистрах управления биты устанавливают последовательно.
Программная синхронизация L1D-кэш основывается на реализации трех команд:
Синхронизация может быть глобальной и блочной, аналогично памяти L1P. В отличие от L1P объявление содержимого памяти L1D недействительным может привести к потере данных (поскольку оно может меняться со стороны ядра), поэтому на практике лучше использовать либо блочную операцию writeback-invalidate, либо команды синхронизации L2-кэш.
Чтобы L1D-кэш могла синхронизироваться с памятью L2, изменяемой посредством DMA, контроллер L1D-кэш способен обрабатывать команды синхронизации, поступающие от L2. L2 генерирует команды синхронизации чтения/записи (snoop-read и snoop-write) только в ответ на соответствующую активность контроллера DMA. Команда snoop-read поступает от L2, когда L2 понимает, что запрашиваемая со стороны DMA строка находится в кэш и помечена как измененная (Dirty). L1D выдает эту строку на L2. Команда snoop-write формируется, когда L2 понимает, что строка, формируемая DMA, записана в L1D-кэш. При этом неважно менялась строка в L1D или нет, она перезаписывается новым значением.
Чтобы уменьшить число обращений к L1D со стороны L2 с целью синхронизации, L2 хранит свою собственную (теневую) копию тэгов памяти L1D-кэш. Эта копия обновляется каждый раз при обращении L1D к L2 и используется для того, чтобы L2 обращалась к ней, а не к самой L1D с целью узнать состояние тех или иных строк кэш. Если копия тэгов говорит L2 о том, что замену в L1D делать надо, только тогда идет обращение к самой L1D.
Рассмотрим подробнее структуру памяти L1D. Есть 8 банков памяти. Каждый банк имеет ширину одно слово – 4 байта. Банки – однопортовые, то есть к одному банку возможно только одно обращение за такт. Два одновременных обращения к одному банку в разных областях пространства памяти вызывают простой в один такт. Если два обращения идут к одному слову в одном банке, то простоя может не быть, если это два чтения любых байтов в составе слова; если это две записи разных байтов в составе слова. Если доступ идет со стороны ядра и DMA, то простой все равно будет – одно из устройств будет простаивать в зависимости от настройки приоритетов. Если к одному слову в одном банке идут обращения чтения и записи, то простой будет, даже если байты разные. L1D ОЗУ и кэш используют одну и ту же структуру памяти.
К памяти L1D возможно два обращения за такт. Если при обращении ни промахов, ни конфликтов банков памяти нет, то обращение выполняется за один такт. В случае промаха L1D данные извлекаются из L2, а если их нет и в L2, — то из L3. Если в одном такте происходят 2 обращения к одной строке кэш, которой нет в кэш, то промах вызывает только один такт простоя. Аналогично, если два обращения к одной строке кэш происходят последовательно, то простой будет только для первого промаха.
При замене старой строки кэш на новую ее содержимое возвращается в основную память через специальный буфер (victim buffer). Чтобы замена строк не вызывала дополнительных простоев, старые данные копируются в буфер, и чтение новых данных продолжается, а старые данные возвращаются в основную память в фоновом режиме. Последующие промахи кэш, однако, должны ждать, пока процесс возврата данных завершится. Если промахи не конфликтуют друг с другом, то они реализуются конвейерно и дополнительных простоев не возникает. Это касается промахов кэш при чтении. Промахи записи могут вызывать простои только при определенных обстоятельствах. Данные, требующие записи в L2, образуют очередь в буфере записи (L1D write buffer).
L1D реализует архитектуру памяти, при которой промахи записи в кэш вызывают прямое обращение к памяти более низкого уровня (L2) без размещения этих данных в кэш. Для этой цели служит буфер записи (write buffer). Этот буфер имеет размер 128 бит и является 4-портовым, обеспечивая возможность осуществлять до 4 отдельных записей данных в L2 одновременно. Промахи записи вызывают простои, только если буфер записи заполнен. Также заполненный буфер записи может косвенно увеличивать время простоя при промахе чтения. Дело в том, что промахи чтения не обслуживаются, пока буфер записи не освободится полностью. Это необходимо, так как чтение данных может производиться с того же адреса, по которому выполняется запись, и запись должна завершиться до начала чтения, иначе могут прочитаться неправильные данные.
Память L2 работает на частоте, в два раза меньшей, чем частота L1. Запросы от буфера записи она обрабатывает на своей частоте. Кроме того, следует учитывать возможные конфликты между банками памяти. Следует стараться, чтобы в буфере записи были данные из разных банков памяти, чтобы дать возможность одновременного их чтения и сократить возможное время простоев. Два последующих промаха записи объединяются в один и выполняются одновременно при соблюдении ряда условий, в частности, данные должны размещаться в пределах смежных 128 бит, оба обращения должны идти к L2 ОЗУ (не кэш) и ряд других. Данные условия имеют место при большой последовательности записей в память или при записи небольшого числа данных в заданную структуру в памяти. Описанный механизм сокращает время простоя процессора при промахах записи и повышает общую эффективность работы памяти L2. Он имеет существенное значение для программ с большим числом промахов записи в кэш.
Также, как и для памяти L1P, для сокращения общего времени простоев при промахах кэш организована конвейерная обработка промахов чтения.
Режим пониженного потребления L1D-памяти организуется аналогично L1P. L1D может быть переведена в режим пониженного потребления, когда процессор находится в режиме ожидания (idle mode). Для этого перед выполнением команды IDLE необходимо записать управляющий бит в соответствующий регистр и установить прерывания, по которым ядро процессора (включая память) должно просыпаться. В случае, если во время сна ядра происходит обращение к памяти L1D, L1P или L2 со стороны DMA контроллер пониженного потребления (PDC) «будит» все три памяти, а после завершения обслуживания DMA вновь погружает их в сон. Такой режим пониженного потребления называется статическим. Он обычно используется при больших интервалах сна.
Для защиты памяти L1D обращения к памяти L1D проверяются на доступ в пользовательском/администраторском режиме и на то, разрешено ли для данного режима обращение к данной области памяти. Если обращение производится к неразрешенным адресам, происходит исключение. Проверяются все обращения со стороны ведущих устройств (в первую очередь, DSP и IDMA) и тип исключения различается для внутренних и внешних обращений. Кроме доступа к данным проверке подлежат также операции синхронизации кэш. Ручная синхронизация кэш разрешена, как для администраторского, так и для пользовательского режимов, однако, в пользовательском режиме запрещается глобальное объявление данных недействительными и запрещается изменение размера кэш. Управление защитой памяти реализуется с помощью набора регистров.
Объем памяти уровня L2 лежит в диапазоне 64 — 4096 Кбайт и для TMS320C6678 составляет 512 Кбайт. Для обращения к L2 используется 1 порт шириной 256 бит. Память L2 строится как два физически независимых банка, включающих по 4 суббанка каждый. К каждому банку идет обращение по 128-разрядной шине. Как реализуется одновременный доступ к памяти L2 со стороны контроллеров L1D, L1P и IDMA будет рассмотрено ниже.
По умолчанию все пространство L2 конфигурируется как ОЗУ. Далее можно часть памяти выделить под кэш.
L2-кэш представляет собой 4-вариантную ассоциативную кэш-память. В отличие от кэш уровня L1 L2-кэш является кэш-памятью с кэшированием и по чтению, и по записи. Адрес памяти включает 3 поля — смещение (offset), набор (set) и тэг (tag). Смещение адресует конкретный байт в пределах одной строки кэш. Строки L2-кэш являются 128-байтными, поэтому на поле смещения выделяется 7 бит. Поле Set задает номер строки. В поле Tag указывается, к какому варианту (Way) относится данная строка и указывается набор атрибутов, например, действительные данные или нет и так далее.
В случае промаха чтения данные читаются из памяти более низкого уровня и одновременно направляются в память L1. В случае промаха записи соответствующая строка помещается в L2-кэш и производится запись новых данных. Аналогично L1-кэш L2 является кэш-памятью с возвратом по необходимости, то есть модификация L2-кэш не отображается сразу в основной памяти. Изменение происходит или когда измененная строка кэш заменяется новой строкой или принудительно по программному запросу от ядра DSP. При этом данные возвращаются в основную память через модуль XMC.
По общему перезапуску L2 конфигурируется полностью как ОЗУ. При локальном перезапуске настройки кэш остаются, но все содержимое помечается как недействительное, а все обращения к памяти задерживаются до окончания пересброса.
Изменение размера L2-кэш может производиться «на лету» путем программной записи требуемых флагов в регистры управления. При этом надо быть осторожным с синхронизацией кэш-памяти. В руководстве по ядру CorePac приводится требуемая последовательность действий.
Режим фиксации кэш поддерживается, аналогично памяти уровня L1.
Также возможна принудительная программная синхронизация кэш L2. Аналогично L1, она может быть глобальной и блочной. Некоторые команды синхронизации затрагивают одновременно и работу L1-памяти.
В некоторых случаях, оказывается важно запретить кэширование некоторого участка памяти на определенных адресах. Настроить кэшируемость различных диапазонов адресов позволяют регистры атрибутов памяти (MAR). Каждый регистр отвечает за определенный диапазон адресов и включает два управляющих бита. Один указывает, является ли данный диапазон адресов кэшируемым или нет. Второй бит указывает, следует ли применять к данному диапазону адресов механизм предварительной выборки или нет. Регистры MAR могут перепрограммироваться в процессе выполнения программы. При этом следует соблюдать последовательность действий, приводимую в документации [2].
При поступлении запроса от L1P или L1D на контроллер памяти L2, если запрашиваемого адреса не оказывается в L2 (ОЗУ или кэш), контроллер L2 проверяет MAR-регистр для данной области памяти. Если диапазон не является кэшируемым, данный запрос обрабатывается как «долгое обращение» – данные проходят через L2 и L1D без кэширования (поскольку это некэшируемый диапазон памяти). Ядро DSP простаивает, ожидая окончания чтения. L1P кэширует команды всегда, когда кэш активирована, независимо от состояния MAR-регистров.
Рассмотрим вопросы синхронизации памяти уровней L1 и L2. Автоматически поддерживается синхронизация L2 ОЗУ и L1D-кэш. Автоматически не поддерживается синхронизация L2 ОЗУ и L1P, а также между внешней памятью (внешней для ядра) и кэш-памятью L2 и L1.
Для автоматической синхронизации кэш L1 и L2 применяют команды слежения – snoop-команды. Snoop-read – команда чтения – инициируется L2, когда DMA реализует чтение из L2 ОЗУ того, что размещается в кэш L1D и тэги, отображающие состояние кэш L1 в памяти L2 говорят, что строка была изменена. В ответ на запрос L2 память L1D-кэш в данном случае выдает половинную строку кэш, не меняя статуса строки (биты действительных данных, бит последнего прочитанного слова LRU и так далее). Snoop-write – команда записи – инициируется L2 при записи в L2 ОЗУ по каналам DMA при условии, что данный адрес присутствует в L1D-кэш. Была ли изменена данная строка в кэш, в данном случае, оказывается не важным. 256 бит новых данных направляются из L2 в L1D. Биты состояний кэш при этом не изменяются.
Если данные из L2-кэш «возвращаются» в основную память более низкого уровня, то кэш L1D не обновляется и данные (также как и программы в L1P) не объявляются недействительными.
Если данные из L1 возвращаются в основную память уровня L3 (или L2 внешнюю) – victim writebacks – содержимое L2 не меняется, если это промах L2-кэш, и меняется только бит недействительных данных в случае, если это попадание L2-кэш.
Механизм предвыборки поддерживается блоком XMC и инициируется L2-памятью с проверкой бит в регистрах MAR.
Память L2 переводится в режим пониженного потребления статически или динамически. Динамически – на небольшие периоды времени. Статически – на более продолжительное время, когда процессор (ядро CorePac) находится в режиме ожидания. Статический переход в режим пониженного потребления происходит вместе с переходом всего ядра в спящий режим. Если во время сна происходит обращение DMA к памяти L1PD или L2, то все три контроллера памяти просыпаются, а после обработки запроса DMA контроллер пониженного потребления (PDC) вновь их усыпляет.
Динамический переход в спящий режим для памяти L2 не управляется пользователем. В качестве L2 использована память типа Retenion Until Access – RTA. Такая память всегда находится в состоянии пониженного потребления и «пробуждает» только те блоки памяти, к которым идет запрос в данный момент. Таким образом, память L2 сама выполняет динамический переход в режим пониженного потребления, и пользователь на это не влияет.
Для памяти уровня L2, также как и для L1, поддерживаются функции защиты, то есть запрета доступа к заданным областям памяти в пользовательском режиме. Подробнее см. документацию [2].
Внутреннее DMA – IDMA – применяется для быстрой пересылки блоков данных между локальными областями памяти, включающими области L1P, L1D и L2, а также памятью конфигурации внешней периферии (CFG). Используется в 2 целях. Первая – пересылка данных между L1 и L2-памятью. При этом IDMA учитывает разницу в скоростях L1 и L2-памяти и оказывается эффективнее механизма кэширования, поскольку не задействует ядро процессора. Вторая – IDMA позволяет быстро запрограммировать регистры периферии в CFG-памяти. Частным вариантом использования IDMA является заполнение заданной области памяти требуемым значением.
IDMA включает 2 независимых канала передачи данных. Канал 0 (channel 0) используется для передачи данных из локальной памяти во внешнее пространство памяти конфигурации периферии – CFG. Канал 1 (channel 1) используется для локальных пересылок. Работа с IDMA ведется аналогично DMA-контроллеру традиционных DSP-процессоров и основана на наборе регистров управления. Подробное описание можно найти в [2].
Контроллер EMC является связующим звеном между ядром CorePac и остальными ресурсами процессора. Под внешней памятью в данном случае подразумевается нелокальная, в том числе внутрикристальная, память.
Контроллер EMC включает 2 порта – порт конфигурации регистров CFG и порт DMA в режиме «ведомый» — Slave DMA – SDMA. Порт SDMA дает доступ внешним ведущим устройствам, например, контролеру DMA (общему для процессора), интерфейсу SRIO и другим, к внутренним ресурсам ядра. То есть этот порт используется при передачах данных, инициируемых внешними для данного ядра устройствами, когда само ядро выступает в роли ведомого.
Контроллер XMC выполняет следующие 4 функции:
Первая функция состоит в реализации обмена данными между внутренними ресурсами ядра CorePac и общей памятью MSM.
Последняя функция (функция предвыборки) направлена на сокращение времени передачи потоков последовательных данных из медленной памяти MSM RAM или EMIF в более быструю локальную память ядра CorePac.
Функции защиты памяти и расширения адресов выполняются совместно модулем MPAX. Как это происходит, рассмотрим далее.
Процессор TMS320C66x поддерживает обычную 32-разрядную внутреннюю адресацию памяти. Такая длина адреса позволяет обращаться к 4 Гбайтному адресному пространству. В то же время, современные многоядерные системы обработки данных требуют больших объемов адресуемой памяти. Чтобы расширить возможности работы с памятью большого объема, процессор способен расширять внутренние 32-разрядные адреса ядра CorePac до 36-разрядных. 36-разрядная адресация позволяет адресовать до 64 Гбайт памяти.
В основе расширения адресов и защиты памяти лежит организация во внутреннем 32-разрядном локальном пространстве памяти 16 сегментов памяти, каждый из которых может иметь свой размер, свое размещение в локальной памяти, свои права доступа и свои правила отображения в общую память MSM. Это обеспечивает удобный и эффективный инструмент для организации взаимной работы большого числа ядер с общей памятью.
Программирование контроллера XMC реализуется через набор регистров. Часть из них определяет работу модуля MPAX, входящего в состав XMC и отвечающего за расширение и защиту адресов.
Работа модуля MPAX сводится к следующему. Каждый из 16 управляющих регистров модуля MPAX представляет собой двойной регистр вида как на рисунке 3.

Рисунок 3 — Сдвоенный регистр управления модуля MPAX
Верхний регистр задает начальный адрес BADDR и размер SEGSZ текущего сегмента памяти в пределах локальной памяти. Размер сегмента лежит в пределах от 4 Кбайт до 4 Гбайт. В последнем случае он занимает всю адресуемую локальную память. Нижний регистр задает адрес внешней 36-разрядной памяти, который замещает старшие биты адреса, по которому идет обращение, то есть он отображает данный сегмент в соответствующую (задаваемую разработчиком) область общей памяти. Кроме того, он задает опции разрешения доступа, то есть права доступа к данному сегменту памяти.
Какими могут быть точные значения полей и как локальные адреса преобразуются в глобальные подробно рассматривается в [2]. Отметим только, что механизм расширения адресов и выделения набора сегментов в общей памяти, которые могут перекрываться, позволяет создавать гибкие архитектуры памяти, расширяющие возможности совместной работы ядер в составе одного устройства.
Все статьи цикла:
Литература:
Содержание
- Введение
- Принципы работы кэш-памяти
- Локальная память программ L1P
- Локальная память данных L1D
- Локальная память L2
- Контроллер внутреннего прямого доступа в память — IDMA
- Контроллер доступа к внешней памяти
- Контроллер расширения памяти
Введение
Процессоры TMS320C66x имеют иерархическую 3-уровневую архитектуру памяти. Иерархическая архитектура памяти позволяет совмещать высокую скорость работы с памятью и большой объем доступной памяти. В своем развитии технология изготовления памяти несколько отстает от процессорной техники. Тактовая частота процессорных ядер растет; растут и требования к объему внутренней и внешней памяти. Вместе с тем, обеспечить процессор памятью большого объема, работающей на частоте ядра оказывается сложной задачей. Для решения данной проблемы широкое развитие получили иерархические архитектуры памяти, в которых память делится на несколько уровней. Память небольшого объема работает на частоте ядра и представляет уровень L1. Память уровня L2 работает на меньшей частоте, но имеет больший объем. И так далее. Для ускорения работы с памятью младших уровней (медленной памятью) быстрая память может частично или полностью конфигурироваться как кэш-память.
Архитектура памяти процессоров TMS320C66xx включает:
- внутреннюю локальную память программ L1P и память данных L1D, работающие на частоте ядра;
- внутреннюю локальную память уровня L2 общую для программ и данных;
- внутреннюю общую для всех ядер память MSM (Multicore Shared Memory), которая может конфигурироваться как память уровня L2 или L3;
- интерфейс внешней памяти уровня L3.
Память уровня L1 и L2 может полностью или частично конфигурироваться, как кэш-память, ускоряя работу с более медленной памятью уровней L2 и L3. Архитектура памяти играет одну из наиболее важных ролей в общей производительности процессора, поскольку ограничивает пропускную способность каналов подачи данных на исполнительные элементы. Далее подробнее рассматриваются составляющие архитектуры памяти процессора TMS320C66x.
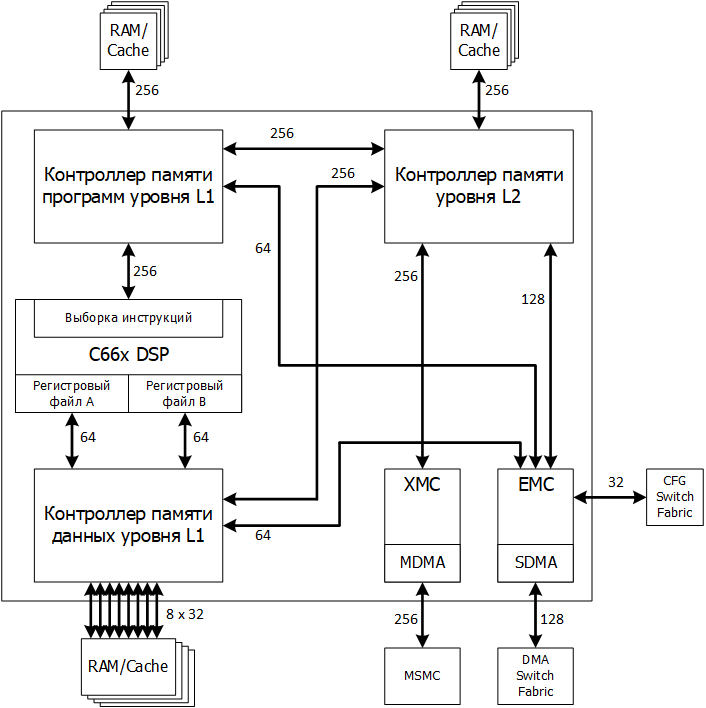
Рисунок 1 — Подсистема памяти ядра CorePac процессора TMS320C66xx
Термин CorePac обозначает одно ядро многоядерного процессора TMS320C66x. Ядро строится в соответствии со структурой, представленной на следующем рисунке 1. Оно включает вычислительные ресурсы – С66х, – рассмотренные в предыдущей статье и следующие компоненты, относящиеся к подсистеме памяти:
- контроллер памяти программ уровня L1 (L1P);
- контроллер памяти данных уровня L1 (L1D);
- контроллер памяти уровня L2 (L2);
- контроллер внутреннего прямого доступа в память (IDMA)
- контроллер доступа к внешней памяти (EMC);
- контроллер расширения памяти (XMC);
Ниже рассматриваются основные аспекты функционирования перечисленных устройств.
Принципы работы кэш-памяти
Прежде, чем приступать к рассмотрению архитектуры памяти процессора TMS320C66x, целесообразно познакомиться с основными принципами функционирования кэш.
Кэширование программ и данных имеет основной целью ускорение работы быстрого ядра с медленной памятью большого объема. Наиболее близкой к ядру, работающей на частоте ядра, является память уровня L1, имеющая небольшой объем. Далее идет память уровня L2 большего объема, работающая, как правило, вдвое медленнее. Далее может идти память уровня L3, L4 и так далее, имеющая еще больший объем, но работающая еще медленнее. Это может быть общая память многоядерной системы или внешние микросхемы памяти.
Эффективность применения кэш основана на двух фактах – локализованности программ и данных во времени и в пространстве памяти (temporal and spatial locality) [1]. Локализованность во времени означает многократное использование одних и тех же программ или данных. Локализованность в пространстве памяти означает, что коды/данные используются группами. Эти два факта позволяют при обращении к медленной памяти читать из нее запрашиваемые коды/данные вместе с соседними группами кодов/данных, копировать их в более быструю память, рассчитывая на то, что запрашиваемые в будущем коды/данные уже будут присутствовать в быстрой памяти.
Группы соседних кодов/данных, одновременно копируемые в кэш, называются строками кэш (cache line). Очевидно, что, чем больше размер строки кэш, тем больше эффективность кэш при пространственной локализации кодов/данных, однако, это усложняет архитектуру кэш и приводит к сокращению количества строк кэш, то есть меньше использует временную локализацию кодов/данных. Размер линии кэш памяти L1P составляет 32 байта. Интересно, что коды, исполняемые из внешней памяти, в процессоре TMS320C66x кэшируются в L1P всегда.
Простейшей схемой организации кэширования является кэш с прямым отображением в памяти (direct-mapped cache). Вся основная память разбивается на фрагменты, размер каждого из которых равен размеру кэш. Соответственно, в кэш в каждый момент времени может находиться только один фрагмент основной памяти, либо непересекающиеся части нескольких разных фрагментов. Коды/данные, расположенные в основной памяти в разных фрагментах, но в соответствующих друг другу строках не могут одновременно находиться в кэш. Возникает конфликт кэширования (conflict miss), что приводит к неэффективности работы кэш. Основной тип промахов кэш для данного механизма кэширования – это промах из-за нехватки объема кэш (capacity miss). Другой неизбежный режим неэффективной работы кэш – это начальное кэширование (compulsory miss). Это промахи кэш при первом обращении к основной памяти.
Чтобы уйти от проблемы нехватки объема кэш в механизмах кэширования с прямым отображением, используют так называемые ассоциативные кэш. Можно считать, что в них механизм кэширования с прямым отображением просто дублируется (становится двухвариантным – 2 way), расширяется в 4 раза (четырехвариантный – 4-way) и так далее. Соответственно, размещение кодов/данных из разных фрагментов и пересекающихся по адресам становится возможным и тем больше таких пересекающихся кодов/данных можно одновременно кэшировать, чем больше вариантов (путей — way) поддерживается. Данная архитектура оказывается более мощной по сравнению с кэш с прямым отображением, но ценой большей сложности и затратности. Все строки кэш с перекрывающимися адресами, то есть принадлежащие разным путям, именуется набором или рядом строк кэш (Set). Когда одну из строк кэш надо заменить, то выбирается тот путь, который давно не использовался, по сравнению с другими. За этим следит бит LRU, являющийся составной частью строки кэш. Структуру кэш раскрывает таблица.
| way1 | way2 | |
|---|---|---|
| set1 | line0 | line0 |
| set2 | line1 | line1 |
| set3 | line2 | line2 |
Кэш «с кэшированием при чтении» (read-allocate cache) – это тип кэш, при котором содержимое кэш меняется только при промахе чтения, то есть когда новые данные/коды запрашиваются из основной памяти, и они одновременно копируются в кэш. При промахе записи (когда ядро пишет в ячейку памяти, не отображенную в кэш) запись идет напрямую в основную память через специальный буфер записи (write buffer) в составе контроллера памяти.
Кэширование с отложенным возвратом кодов/данных из кэш в основную память (write back cache) означает, что при попадании записи (write hit) данные/коды в основную память не пишутся, а пишутся только в кэш с пометкой, что данная строка кэш является грязной (Dirty), то есть ее надо в будущем скопировать в основную память.
При работе с кэш на ЦСП TMS320C66xx следует иметь в виду следующие аспекты. Память уровня L2 всегда кэшируется в L1, достаточно лишь сконфигурировать L1, как кэш. При кэшировании внешней памяти, необходимо дополнительно указывать, что и где кэшировать. При этом коды из внешней памяти в L1P кэшируются всегда. Внешняя память делится на сегменты по 16 Мбайт, и их кэшируемость контролируется специальными управляющими регистрами MAR.
Те фрагменты памяти, которые выделяются под кэш, не указываются в разделе MEMORY в cmd-файле.
При работе с кэш неминуемо возникает проблема синхронизации кэш и основной памяти (cache coherence). Когерентность (синхронизация) кэш означает согласование содержимого кэш и основной памяти. Проблема когерентности кэш имеет место всегда, когда есть общий ресурс памяти, эта память является кэшируемой и происходит изменение содержимого памяти. Если кэш и основная память имеют разное содержимое, то есть являются не синхронизированными, то одно из устройств, обращающееся к памяти, может обратиться к неверным данным.
Процессор C66x обеспечивает автоматическую синхронизацию доступа к данным со стороны ядра и со стороны EDMA/IDMA. Когда DMA читает L2 SRAM, данные читаются из L1D-кэш и не меняются в L2 SRAM. Когда DMA пишет в L2 SRAM, данные пишутся одновременно и в L2 SRAM, и в L1D. Автоматическая синхронизация основана на механизме snooping – слежение. При обращениях со стороны DMA автоматически проверяется кэшируемость кодов/данных в памяти.
Ручная синхронизация (с помощью специальных команд библиотеки CSL) необходима в следующих случаях:
- во внешнюю память через DMA или с другого внешнего источника пишутся данные или код, которые затем читаются CPU;
- CPU пишет данные во внешнюю память, откуда они потом забираются DMA или другим устройством;
- DMA пишет коды в L2 SRAM, которые потом исполняются CPU;
- ядро пишет код в L2 SRAM или внешнюю память, и потом оно их исполняет.
Типовым вариантом использования памяти является следующая ситуация. C периферийного устройства 1 посредством DMA данные записываются в массив в памяти уровня L2 для обработки. Также через DMA обработанные данные выводятся из памяти L2 через периферийное устройство 2. Чтобы разделить обработку, ввод данных и вывод данных, используются две пары ping-pong буферов. При использовании только памяти уровней L2 с кэшированием в L1 синхронизация выполняется автоматически выше описанным образом.
Когда 2 пары ping-pong буферов размещаются во внешней памяти и проходят через 2 уровня кэш – L2 и L1 – тогда требуется ручная синхронизация. Перед началом ввода очередного массива во входной буфер по каналам DMA все строки кэш L1D и L2, ссылающиеся на данный массив, должны быть объявлены недействительными (invalidate). Массив будет заново кэшироваться, вызывая издержки кэш первого обращения. Аналогично, перед тем, как выходной массив будет отправлен через механизм DMA на периферийное устройство, необходимо выполнить синхронизацию памяти L1D и L2 с внешней памятью – write back.
Эффективность работы кэш-памяти является необходимым залогом успешной работы всего процессора. С этой точки зрения особенное значение приобретают отладочные средства визуализации кэш. Функция визуализации кэш поддерживается средой разработки кодов для процессоров Texas Instruments Code Composer Studio в окне отображения памяти процессора. Необходимо дополнительно включать функцию анализа памяти при выводе окна.
Локальная память программ L1P
Память программ уровня L1 (L1P) предназначена только для хранения программных кодов. Объем памяти варьируется от устройства к устройству и для процессора TMS320C6678 составляет 32 Кбайта. Память L1P может частично конфигурироваться как кэш. При этом объем кэш может составлять 0, 4, 8, 16 или 32 Кбайта. Остальной объем памяти конфигурируется как обычное ОЗУ. Под кэш выделяются старшие адреса L1P. По включению память L1P конфигурируется или полностью как ОЗУ, или с максимальным объемом кэш (зависит от конкретного устройства).
Память L1P сама кэшироваться в других областях кэш не может. Запись в память L1P производится только по каналам EDMA или IDMA. То есть запись в память L1P не доступна для разработчика, желающего записывать что-то в нее со стороны вычислительного ядра в ходе выполнения программы.
Обычно при обращении к L1P как к ОЗУ число тактов ожидания равно 0, однако, максимальное число тактов ожидания при работе с L1P может достигать 3. Управление памятью L1P в режиме кэш осуществляется через набор регистров. Изменение размера кэш и других параметров может осуществляться в ходе выполнения программы.
Опишем более подробно работу L1P в режиме кэш. В режиме кэш память L1P является памятью кэш с прямым отображением (direct-mapped cache). Данный механизм кэширования является наиболее простым и может наиболее часто приводить к конфликтам записи в кэш из разных секторов основной памяти. Очевидно, считается, что такого механизма для памяти программ оказывается достаточно, поскольку коды программ отличаются наибольшей степенью локализованности в пространстве памяти по сравнению с данными.
Режим фиксации кэш L1P (freeze mode) позволяет зафиксировать фрагмент кода в кэш. Попадания чтения выполняются обычным образом, а промахи кэш не меняют содержимого кэш и не делают коды в кэш недействительными. Фиксация L1P полезна при исполнении прерываний. Из-за переключения состояния процессора на небольшое время, нет смысла «портить» содержимое кэш.
Для синхронизации кэш L1P и основной памяти можно применять глобальную и блочную синхронизацию. Глобальная подразумевает синхронизацию всего объема кэш и выполняется по значимым для всей системы событиям, таким как смена задачи, смена режима работы кэш и других. Синхронизация подразумевает объявление содержимого кэш недействительным (invalidation) и выполняется установкой бит в управляющих регистрах. При этом копирование кэш в основную память не производится, поскольку кэш программ не модифицируется ядром.
Блочная синхронизация подразумевает, что в регистре управления кэш задается начальный адрес и длина блока кода, который надо объявить недействительным.
Синхронизация кэш занимает определенное время. Поэтому после инициализации синхронизации желательно выполнять ожидание окончания синхронизации. Об окончании синхронизации говорит флаг в регистре управления. Соответственно, нужен код, который этот флаг анализирует, причем данный код не следует располагать в области памяти, зависящей от кэш.
L1P-кэш работает на частоте ядра и в случае попаданий кэш никаких простоев нет, и команды выполняются за один такт (в конвейере). Однако в случае промаха кэш ситуация оказывается сложнее. L1P-кэш обращается к L2-памяти с целью выборки команд. Время чтения команды оказывается больше, но насколько больше, зависит от конкретного состояния конвейера и оказывается трудно предсказуемым. Зачастую простои конвейера из-за промахов кэш оказываются скрытыми (не влияют на процесс выполнения программы) из-за простоев самого командного конвейера. На TMS320C66x командный конвейер организован так, что его простои перекрываются с простоями из-за промахов кэш, что позволяет уйти от избыточного затягивания процесса выполнения команд. Здесь под простоями командного конвейера понимается то, что пакет выборки в большинстве случаев содержит более одного пакета выполнения, и выборка команд производится реже, чем их выполнение. Начальные стадии конвейера не читают следующую команду – простаивают, пока последующие стадии конвейера не выполнят текущие пакеты. Таким образом, появляется дополнительное время на обращение к памяти уровня L2 и далее, что позволяет частично или полностью скрыть промахи кэш L1P. Данная технология именуется конвейерная обработка промахов кэш (L1P miss pipeline).
На С66х пакет выполнения может формироваться из двух пакетов выборки.
Однако, очевидно, что для хорошо оптимизированных кодов, когда пакеты выборки практически совпадают с пакетами выполнения, данный подход теряет свою эффективность, и промахи кэш способны существенно затягивать процесс выполнения программ. Ориентировочные значения задержек выполнения из-за промахов кэш для различных вариантов состояния конвейера можно найти в документации на процессор.
Режим пониженного потребления используется для снижения общего потребления процессора в случаях, когда это представляет интерес. Память L1P может переводиться в режим пониженного потребления статически (static power-down), что подразумевает установку управляющего бита режима пониженного потребления; настройку прерывания, которое будет «будить» L1P и выполнение команды IDLE. Также память может переходить в данный режим динамически (dynamic power-down), что означает автоматический переход при выполнении программы из буфера SPLOOP. Также L1P-кэш переходит в режим пониженного потребления (feature-oriented power-down), когда кэш является неактивной (disabled). То есть если L1P сконфигурирована как кэш, но не активирована, то она находится в режиме пониженного потребления.
Чтение памяти L1P может производиться ядром, DMA и IDMA. Все команды включают 2 бита защиты – бит исполнения в пользовательском и бит исполнения в администраторском режимах. При чтении команд ядром они всегда анализируются на разрешенность их исполнения в текущем режиме. Если они оказываются запрещенными, происходит исключение (в случае чтения ядром) или прерывание (в случае чтения DMA/IDMA). Кроме того, доступ к регистрам памяти L1P также контролируется контроллером L1P и вызывает исключение в случае чтения или записи защищенного регистра.
Доступ для чтения/записи со стороны DMA/IDMA также контролируется на разрешенность. Можно настроить разные права доступа к различным страницам памяти. L1P строится из 16 страниц защиты памяти.
Локальная память данных L1D
Объем внутренней памяти данных L1 составляет до 128 Кбайт в зависимости от модели процессора и для TMS320C6678 составляет 32 Кбайта ОЗУ. Часть или вся L1D может конфигурироваться как кэш-память.
L1D-кэш – это двухвариантная ассоциативная кэш «с кэшированием при чтении» и «кэшированием с отложенным возвратом» (2-way set-associative, read-allocate, write back cache). Значения перечисленных понятий раскрывались выше.
При включении L1D инициализируется или полностью как ОЗУ или с максимальным размером кэш. Дальнейшая настройка L1D реализуется через регистры управления.
Кэш работает следующим образом. 32-разрядный адрес, выставляемый на адресную шину, имеет структуру, проиллюстрированную на рисунке.

Рисунок 2 — Структура адреса при обращении к кэш
Поле offset – это адрес в пределах одной строки кэш. Контроллером кэш он игнорируется, поскольку строка либо есть в кэш, либо нет целиком. Размер строки 64 байта соответствует размеру поля offset 6 бит. Чтобы установить факт наличия строки в кэш данное поле не нужно.
Поле set – определяет набор строк, к которым идет обращение. Длина поля set зависит от объема кэш-памяти и лежит в пределах 5-14 бит.
Поле Tag окончательно определяет адрес строки, к которой идет обращение, учитывая требуемый путь (way).
Кэш-память данных, в отличие от памяти программ, может меняться ядром процессора. Поэтому возврат измененных данных из кэш в основную память (write back) происходит либо по команде ядра, либо просто автоматически при замене строки кэш новой строкой из основной памяти. Размер L1D-кэш может меняться динамически.
В режиме фиксации содержимого кэш L1D работает в обычном режиме в случае попаданий чтения и записи и в случае промаха записи. Только бит LRU не изменяется при промахах. В случае промаха чтения обновление кэш не происходит. Команды синхронизации кэш продолжают работать в обычном режиме. Переход в режим фиксации кэш и обратно производится записью в регистры и может производиться динамически и достаточно быстро. Кроме того, часто в режим фиксации переводят одновременно L1D и L1P. Для этого в регистрах управления биты устанавливают последовательно.
Программная синхронизация L1D-кэш основывается на реализации трех команд:
- объявление данных недействительными (invalidation);
- возврат данных в основную память (writeback);
- обе операции одновременно (writeback-invalidation).
Синхронизация может быть глобальной и блочной, аналогично памяти L1P. В отличие от L1P объявление содержимого памяти L1D недействительным может привести к потере данных (поскольку оно может меняться со стороны ядра), поэтому на практике лучше использовать либо блочную операцию writeback-invalidate, либо команды синхронизации L2-кэш.
Чтобы L1D-кэш могла синхронизироваться с памятью L2, изменяемой посредством DMA, контроллер L1D-кэш способен обрабатывать команды синхронизации, поступающие от L2. L2 генерирует команды синхронизации чтения/записи (snoop-read и snoop-write) только в ответ на соответствующую активность контроллера DMA. Команда snoop-read поступает от L2, когда L2 понимает, что запрашиваемая со стороны DMA строка находится в кэш и помечена как измененная (Dirty). L1D выдает эту строку на L2. Команда snoop-write формируется, когда L2 понимает, что строка, формируемая DMA, записана в L1D-кэш. При этом неважно менялась строка в L1D или нет, она перезаписывается новым значением.
Чтобы уменьшить число обращений к L1D со стороны L2 с целью синхронизации, L2 хранит свою собственную (теневую) копию тэгов памяти L1D-кэш. Эта копия обновляется каждый раз при обращении L1D к L2 и используется для того, чтобы L2 обращалась к ней, а не к самой L1D с целью узнать состояние тех или иных строк кэш. Если копия тэгов говорит L2 о том, что замену в L1D делать надо, только тогда идет обращение к самой L1D.
Рассмотрим подробнее структуру памяти L1D. Есть 8 банков памяти. Каждый банк имеет ширину одно слово – 4 байта. Банки – однопортовые, то есть к одному банку возможно только одно обращение за такт. Два одновременных обращения к одному банку в разных областях пространства памяти вызывают простой в один такт. Если два обращения идут к одному слову в одном банке, то простоя может не быть, если это два чтения любых байтов в составе слова; если это две записи разных байтов в составе слова. Если доступ идет со стороны ядра и DMA, то простой все равно будет – одно из устройств будет простаивать в зависимости от настройки приоритетов. Если к одному слову в одном банке идут обращения чтения и записи, то простой будет, даже если байты разные. L1D ОЗУ и кэш используют одну и ту же структуру памяти.
К памяти L1D возможно два обращения за такт. Если при обращении ни промахов, ни конфликтов банков памяти нет, то обращение выполняется за один такт. В случае промаха L1D данные извлекаются из L2, а если их нет и в L2, — то из L3. Если в одном такте происходят 2 обращения к одной строке кэш, которой нет в кэш, то промах вызывает только один такт простоя. Аналогично, если два обращения к одной строке кэш происходят последовательно, то простой будет только для первого промаха.
При замене старой строки кэш на новую ее содержимое возвращается в основную память через специальный буфер (victim buffer). Чтобы замена строк не вызывала дополнительных простоев, старые данные копируются в буфер, и чтение новых данных продолжается, а старые данные возвращаются в основную память в фоновом режиме. Последующие промахи кэш, однако, должны ждать, пока процесс возврата данных завершится. Если промахи не конфликтуют друг с другом, то они реализуются конвейерно и дополнительных простоев не возникает. Это касается промахов кэш при чтении. Промахи записи могут вызывать простои только при определенных обстоятельствах. Данные, требующие записи в L2, образуют очередь в буфере записи (L1D write buffer).
L1D реализует архитектуру памяти, при которой промахи записи в кэш вызывают прямое обращение к памяти более низкого уровня (L2) без размещения этих данных в кэш. Для этой цели служит буфер записи (write buffer). Этот буфер имеет размер 128 бит и является 4-портовым, обеспечивая возможность осуществлять до 4 отдельных записей данных в L2 одновременно. Промахи записи вызывают простои, только если буфер записи заполнен. Также заполненный буфер записи может косвенно увеличивать время простоя при промахе чтения. Дело в том, что промахи чтения не обслуживаются, пока буфер записи не освободится полностью. Это необходимо, так как чтение данных может производиться с того же адреса, по которому выполняется запись, и запись должна завершиться до начала чтения, иначе могут прочитаться неправильные данные.
Память L2 работает на частоте, в два раза меньшей, чем частота L1. Запросы от буфера записи она обрабатывает на своей частоте. Кроме того, следует учитывать возможные конфликты между банками памяти. Следует стараться, чтобы в буфере записи были данные из разных банков памяти, чтобы дать возможность одновременного их чтения и сократить возможное время простоев. Два последующих промаха записи объединяются в один и выполняются одновременно при соблюдении ряда условий, в частности, данные должны размещаться в пределах смежных 128 бит, оба обращения должны идти к L2 ОЗУ (не кэш) и ряд других. Данные условия имеют место при большой последовательности записей в память или при записи небольшого числа данных в заданную структуру в памяти. Описанный механизм сокращает время простоя процессора при промахах записи и повышает общую эффективность работы памяти L2. Он имеет существенное значение для программ с большим числом промахов записи в кэш.
Также, как и для памяти L1P, для сокращения общего времени простоев при промахах кэш организована конвейерная обработка промахов чтения.
Режим пониженного потребления L1D-памяти организуется аналогично L1P. L1D может быть переведена в режим пониженного потребления, когда процессор находится в режиме ожидания (idle mode). Для этого перед выполнением команды IDLE необходимо записать управляющий бит в соответствующий регистр и установить прерывания, по которым ядро процессора (включая память) должно просыпаться. В случае, если во время сна ядра происходит обращение к памяти L1D, L1P или L2 со стороны DMA контроллер пониженного потребления (PDC) «будит» все три памяти, а после завершения обслуживания DMA вновь погружает их в сон. Такой режим пониженного потребления называется статическим. Он обычно используется при больших интервалах сна.
Для защиты памяти L1D обращения к памяти L1D проверяются на доступ в пользовательском/администраторском режиме и на то, разрешено ли для данного режима обращение к данной области памяти. Если обращение производится к неразрешенным адресам, происходит исключение. Проверяются все обращения со стороны ведущих устройств (в первую очередь, DSP и IDMA) и тип исключения различается для внутренних и внешних обращений. Кроме доступа к данным проверке подлежат также операции синхронизации кэш. Ручная синхронизация кэш разрешена, как для администраторского, так и для пользовательского режимов, однако, в пользовательском режиме запрещается глобальное объявление данных недействительными и запрещается изменение размера кэш. Управление защитой памяти реализуется с помощью набора регистров.
Локальная память L2
Объем памяти уровня L2 лежит в диапазоне 64 — 4096 Кбайт и для TMS320C6678 составляет 512 Кбайт. Для обращения к L2 используется 1 порт шириной 256 бит. Память L2 строится как два физически независимых банка, включающих по 4 суббанка каждый. К каждому банку идет обращение по 128-разрядной шине. Как реализуется одновременный доступ к памяти L2 со стороны контроллеров L1D, L1P и IDMA будет рассмотрено ниже.
По умолчанию все пространство L2 конфигурируется как ОЗУ. Далее можно часть памяти выделить под кэш.
L2-кэш представляет собой 4-вариантную ассоциативную кэш-память. В отличие от кэш уровня L1 L2-кэш является кэш-памятью с кэшированием и по чтению, и по записи. Адрес памяти включает 3 поля — смещение (offset), набор (set) и тэг (tag). Смещение адресует конкретный байт в пределах одной строки кэш. Строки L2-кэш являются 128-байтными, поэтому на поле смещения выделяется 7 бит. Поле Set задает номер строки. В поле Tag указывается, к какому варианту (Way) относится данная строка и указывается набор атрибутов, например, действительные данные или нет и так далее.
В случае промаха чтения данные читаются из памяти более низкого уровня и одновременно направляются в память L1. В случае промаха записи соответствующая строка помещается в L2-кэш и производится запись новых данных. Аналогично L1-кэш L2 является кэш-памятью с возвратом по необходимости, то есть модификация L2-кэш не отображается сразу в основной памяти. Изменение происходит или когда измененная строка кэш заменяется новой строкой или принудительно по программному запросу от ядра DSP. При этом данные возвращаются в основную память через модуль XMC.
По общему перезапуску L2 конфигурируется полностью как ОЗУ. При локальном перезапуске настройки кэш остаются, но все содержимое помечается как недействительное, а все обращения к памяти задерживаются до окончания пересброса.
Изменение размера L2-кэш может производиться «на лету» путем программной записи требуемых флагов в регистры управления. При этом надо быть осторожным с синхронизацией кэш-памяти. В руководстве по ядру CorePac приводится требуемая последовательность действий.
Режим фиксации кэш поддерживается, аналогично памяти уровня L1.
Также возможна принудительная программная синхронизация кэш L2. Аналогично L1, она может быть глобальной и блочной. Некоторые команды синхронизации затрагивают одновременно и работу L1-памяти.
В некоторых случаях, оказывается важно запретить кэширование некоторого участка памяти на определенных адресах. Настроить кэшируемость различных диапазонов адресов позволяют регистры атрибутов памяти (MAR). Каждый регистр отвечает за определенный диапазон адресов и включает два управляющих бита. Один указывает, является ли данный диапазон адресов кэшируемым или нет. Второй бит указывает, следует ли применять к данному диапазону адресов механизм предварительной выборки или нет. Регистры MAR могут перепрограммироваться в процессе выполнения программы. При этом следует соблюдать последовательность действий, приводимую в документации [2].
При поступлении запроса от L1P или L1D на контроллер памяти L2, если запрашиваемого адреса не оказывается в L2 (ОЗУ или кэш), контроллер L2 проверяет MAR-регистр для данной области памяти. Если диапазон не является кэшируемым, данный запрос обрабатывается как «долгое обращение» – данные проходят через L2 и L1D без кэширования (поскольку это некэшируемый диапазон памяти). Ядро DSP простаивает, ожидая окончания чтения. L1P кэширует команды всегда, когда кэш активирована, независимо от состояния MAR-регистров.
Рассмотрим вопросы синхронизации памяти уровней L1 и L2. Автоматически поддерживается синхронизация L2 ОЗУ и L1D-кэш. Автоматически не поддерживается синхронизация L2 ОЗУ и L1P, а также между внешней памятью (внешней для ядра) и кэш-памятью L2 и L1.
Для автоматической синхронизации кэш L1 и L2 применяют команды слежения – snoop-команды. Snoop-read – команда чтения – инициируется L2, когда DMA реализует чтение из L2 ОЗУ того, что размещается в кэш L1D и тэги, отображающие состояние кэш L1 в памяти L2 говорят, что строка была изменена. В ответ на запрос L2 память L1D-кэш в данном случае выдает половинную строку кэш, не меняя статуса строки (биты действительных данных, бит последнего прочитанного слова LRU и так далее). Snoop-write – команда записи – инициируется L2 при записи в L2 ОЗУ по каналам DMA при условии, что данный адрес присутствует в L1D-кэш. Была ли изменена данная строка в кэш, в данном случае, оказывается не важным. 256 бит новых данных направляются из L2 в L1D. Биты состояний кэш при этом не изменяются.
Если данные из L2-кэш «возвращаются» в основную память более низкого уровня, то кэш L1D не обновляется и данные (также как и программы в L1P) не объявляются недействительными.
Если данные из L1 возвращаются в основную память уровня L3 (или L2 внешнюю) – victim writebacks – содержимое L2 не меняется, если это промах L2-кэш, и меняется только бит недействительных данных в случае, если это попадание L2-кэш.
Механизм предвыборки поддерживается блоком XMC и инициируется L2-памятью с проверкой бит в регистрах MAR.
Память L2 переводится в режим пониженного потребления статически или динамически. Динамически – на небольшие периоды времени. Статически – на более продолжительное время, когда процессор (ядро CorePac) находится в режиме ожидания. Статический переход в режим пониженного потребления происходит вместе с переходом всего ядра в спящий режим. Если во время сна происходит обращение DMA к памяти L1PD или L2, то все три контроллера памяти просыпаются, а после обработки запроса DMA контроллер пониженного потребления (PDC) вновь их усыпляет.
Динамический переход в спящий режим для памяти L2 не управляется пользователем. В качестве L2 использована память типа Retenion Until Access – RTA. Такая память всегда находится в состоянии пониженного потребления и «пробуждает» только те блоки памяти, к которым идет запрос в данный момент. Таким образом, память L2 сама выполняет динамический переход в режим пониженного потребления, и пользователь на это не влияет.
Для памяти уровня L2, также как и для L1, поддерживаются функции защиты, то есть запрета доступа к заданным областям памяти в пользовательском режиме. Подробнее см. документацию [2].
Контроллер внутреннего прямого доступа в память — IDMA
Внутреннее DMA – IDMA – применяется для быстрой пересылки блоков данных между локальными областями памяти, включающими области L1P, L1D и L2, а также памятью конфигурации внешней периферии (CFG). Используется в 2 целях. Первая – пересылка данных между L1 и L2-памятью. При этом IDMA учитывает разницу в скоростях L1 и L2-памяти и оказывается эффективнее механизма кэширования, поскольку не задействует ядро процессора. Вторая – IDMA позволяет быстро запрограммировать регистры периферии в CFG-памяти. Частным вариантом использования IDMA является заполнение заданной области памяти требуемым значением.
IDMA включает 2 независимых канала передачи данных. Канал 0 (channel 0) используется для передачи данных из локальной памяти во внешнее пространство памяти конфигурации периферии – CFG. Канал 1 (channel 1) используется для локальных пересылок. Работа с IDMA ведется аналогично DMA-контроллеру традиционных DSP-процессоров и основана на наборе регистров управления. Подробное описание можно найти в [2].
Контроллер доступа к внешней памяти — EMC
Контроллер EMC является связующим звеном между ядром CorePac и остальными ресурсами процессора. Под внешней памятью в данном случае подразумевается нелокальная, в том числе внутрикристальная, память.
Контроллер EMC включает 2 порта – порт конфигурации регистров CFG и порт DMA в режиме «ведомый» — Slave DMA – SDMA. Порт SDMA дает доступ внешним ведущим устройствам, например, контролеру DMA (общему для процессора), интерфейсу SRIO и другим, к внутренним ресурсам ядра. То есть этот порт используется при передачах данных, инициируемых внешними для данного ядра устройствами, когда само ядро выступает в роли ведомого.
Контроллер расширения памяти — XMC
Контроллер XMC выполняет следующие 4 функции:
- служит портом доступа к общей памяти MSMC – является MDMA-окном из L2-памяти в MSM-память;
- выполняет функцию защиты памяти для адресов, лежащих за пределами ядра CorePac;
- выполняет расширение и трансляцию адресов;
- реализует функцию предварительной выборки (prefetching).
Первая функция состоит в реализации обмена данными между внутренними ресурсами ядра CorePac и общей памятью MSM.
Последняя функция (функция предвыборки) направлена на сокращение времени передачи потоков последовательных данных из медленной памяти MSM RAM или EMIF в более быструю локальную память ядра CorePac.
Функции защиты памяти и расширения адресов выполняются совместно модулем MPAX. Как это происходит, рассмотрим далее.
Процессор TMS320C66x поддерживает обычную 32-разрядную внутреннюю адресацию памяти. Такая длина адреса позволяет обращаться к 4 Гбайтному адресному пространству. В то же время, современные многоядерные системы обработки данных требуют больших объемов адресуемой памяти. Чтобы расширить возможности работы с памятью большого объема, процессор способен расширять внутренние 32-разрядные адреса ядра CorePac до 36-разрядных. 36-разрядная адресация позволяет адресовать до 64 Гбайт памяти.
В основе расширения адресов и защиты памяти лежит организация во внутреннем 32-разрядном локальном пространстве памяти 16 сегментов памяти, каждый из которых может иметь свой размер, свое размещение в локальной памяти, свои права доступа и свои правила отображения в общую память MSM. Это обеспечивает удобный и эффективный инструмент для организации взаимной работы большого числа ядер с общей памятью.
Программирование контроллера XMC реализуется через набор регистров. Часть из них определяет работу модуля MPAX, входящего в состав XMC и отвечающего за расширение и защиту адресов.
Работа модуля MPAX сводится к следующему. Каждый из 16 управляющих регистров модуля MPAX представляет собой двойной регистр вида как на рисунке 3.

Рисунок 3 — Сдвоенный регистр управления модуля MPAX
Верхний регистр задает начальный адрес BADDR и размер SEGSZ текущего сегмента памяти в пределах локальной памяти. Размер сегмента лежит в пределах от 4 Кбайт до 4 Гбайт. В последнем случае он занимает всю адресуемую локальную память. Нижний регистр задает адрес внешней 36-разрядной памяти, который замещает старшие биты адреса, по которому идет обращение, то есть он отображает данный сегмент в соответствующую (задаваемую разработчиком) область общей памяти. Кроме того, он задает опции разрешения доступа, то есть права доступа к данному сегменту памяти.
Какими могут быть точные значения полей и как локальные адреса преобразуются в глобальные подробно рассматривается в [2]. Отметим только, что механизм расширения адресов и выделения набора сегментов в общей памяти, которые могут перекрываться, позволяет создавать гибкие архитектуры памяти, расширяющие возможности совместной работы ядер в составе одного устройства.
Все статьи цикла:
- Обзор архитектуры процессора
- Операционные ядра: вычислительные ресурсы процессора
- Организация памяти ядра
Литература:
- TMS320C66x DSP Cache. User Guide. SPRUGY8. Texas Instruments, 2010
- TMS320C66x DSP CorePac. User Guide. SPRUGW0B. USA. Texas Instruments, 2011
