
Apache CloudStack представляет собой универсальную платформу управления средами выполнения виртуальных машин (часто такие продукты именуются “панель управления облаком VPS”). Использование Apache CloudStack (далее, ACS) дает администратору возможность развернуть облако с требуемыми сервисами в короткий срок, а после развертывания эффективно управлять облаком в течение всего жизненного цикла. В рамках данной статьи даются рекомендации по дизайну облака, который может использоваться на практике и подходит для большинства провайдеров публичных облаков, планирующих построение публичных облачных сред малых и средних размеров, обладающих максимальной простотой администрирования и не требующих специальных знаний для отладки и обнаружения проблем. Статья не является пошаговым руководством настройки Apache CloudStack.
Статья описана в форме набора рекомендаций и соображений, которые могут быть полезны при развертывании нового облака. Данный стиль изложения навеян тем фактом, что автор планирует в скором времени развертывание нового облака по данной топологии.
Облако с описанным в статье дизайном успешно используется для оказания коммерческих услуг по аренде VPS. В рамках облака развернуто хранилище на 16 ТБ, состоящее полностью из SSD накопителей Samsung Pro 850 1TB, организованное в программный RAID6, 176 ядер Xeon E5-2670, 768 GB RAM, сеть на 256 публичных адресов.
Далее описываются предложения и замечания по организации облака, цель которого обеспечить экономически эффективное оказание услуг для сервиса аренды VPS с показателем месячной доступности (SLA) 99.7%, что допускает простой в размере 2х часов в течение месяца. В том случае, если цель — обеспечить предоставление облака с более высоким показателем доступности, то необходимо применять иные модели организации облака, которые включают различные отказоустойчивые кластерные элементы, что также может быть реализовано с помощью Apache CloudStack, но в данной статье не рассматривается.
Введение
Долгосрочный успех коммерческого облака как с практической, так и с экономической точки зрения зависит от выбранного дизайна и осознанного планирования оборудования и корректно сформированных соотношений и лимитов ресурсов облака. На стадии дизайна требуется определить какой будет инфраструктура облака и как на данной инфраструктуре будет развернут ACS. ACS позволяет создавать облака с самыми разнообразными свойствами, в зависимости от технического задания. В рамках данной статьи рассматривается создание облака со следующими свойствами:
- все виртуальные машины находятся в едином разделяемом адресном пространстве (например, в сети /24);
- трафик между любыми виртуальными машинами распространяется в рамках единого VLAN;
- выделяемые адреса непосредственно назначаются на виртуальную машину (статический NAT не используется);
В рамках ACS таким свойствам удовлетворяет базовая зона (Basic Zone) с группами безопасности (Security Groups) или без них, если не требуется ограничение источников и назначений трафика для виртуальных машин.
Дополнительно, в рамках облака будут использованы простые и зарекомендовавшие себя компоненты хранилища, не требующие сложных знаний для их сопровождения, что достигается при помощи хранилища NFS.
Сеть
На первом этапе необходимо принять решение о виде и компонентах сетевой инфраструктуры облака. В рамках данного облака не заложена отказоустойчивость сетевой топологии. Для реализации данной модели облака с использованием отказоустойчивой сетевой топологии, необходимо использовать стандартные подходы к реализации надежной сетевой инфраструктуры, например, LACP, xSTP, MRP, MLAG, технологии стекирования, а также программные решения, основанные на bonding. В зависимости от выбранного поставщика сетевого оборудования могут быть рекомендованы те или иные подходы.
Для развертывания инфраструктуры будет использоваться три изолированных Ethernet-сети и три коммутатора:
- Сеть IPMI, которая будет использоваться для управления физическим оборудованием, что необходимо для решения инцидентов, связанных с отказом узлов и прочими нештатных ситуациями (порты 100 Mbit/s Ethernet). Данная сеть конфигурируется с использованием “серых” адресов, например, 10.0.0.0/8, поскольку обычно необходимо ограничить доступ к управляющим элементам извне для обеспечения большей безопасности.
- Сеть для публичного трафика “VM-VM”, “VM-потребитель”. Коммутатор с портами 1 Gbit/s Ethernet или 10 Gbit/s Ethernet, в том случае, если требуется высокая пропускная способность для виртуальных машин. Обычно портов 1 Gbit/s достаточно для оказания услуг общего назначения. Данная сеть конфигурируется с использованием публичных или серых адресов (если планируется внутреннее облако с внешним шлюзом безопасности и NAT).
- Сеть передачи данных для доступа к хранилищам NFS, которая обеспечивает доступ хостов виртуализации к томам виртуальных машин, снимкам, шаблонам и ISO. Данную сеть рекомендуется реализовывать с использованием портов 10 Gbit/s Ethernet или более скоростных альтернативных технологий, например, Infiniband. Сеть конфигурируется с использованием серых адресов,
например, 176.16.0.0/12.
Необходимо отметить, что сеть для доступа к данным томов виртуальных машин должна быть высокопроизводительной, причем производительность должна определяться не только пропускной способностью, но и сквозной задержкой передачи данных (от сервера виртуализации к серверу NFS). Для оптимальных результатов рекомендуется использовать следующие решения:
- Коммутаторы для ЦОД, которые обрабатывают трафик в cut-through режиме, поскольку они обеспечивают наименьшую задержку, а значит каждый экземпляр VM может получить больше IOPS.
- Коммутаторы, использующие более скоростные протоколы передачи данных, к примеру, Infiniband 40 Gbit/s, 56 Gbit/s, которые обеспечивают не только сверхвысокую пропускную способность, но и чрезвычайно низкую задержку, практически недостижимую при использовании стандартного Ethernet оборудования. В данном случае необходимо использовать протокол IPoIB для предоставления доступа к NFS хранилищу по протоколу IP поверх Infiniband сети.
- Настроить поддержку jumbo-фреймов на всех устройствах.
Специальные требования к сети IPMI( 1) как таковые отсутствуют, и она может быть реализована на самом бюджетном оборудовании.
Сеть передачи данных (2) в рамках выбранной модели облака достаточно простая, поскольку ACS реализует дополнительную безопасность на уровне хостов гипервизоров за счет применения правил iptables и ebtables, что, к примеру, позволяет не настраивать на коммутаторах dhcp snooping и другие настройки, которые применяются для защиты портов при использовании физических абонентов ШПД или аппаратных серверов. Рекомендуется использовать коммутаторы, которые обеспечивают передачу данных в режиме store-and-forward и имеют большие буферы портов, что позволяет обеспечить высокое качество при передаче разнообразного сетевого трафика. Если требуется предоставлять высокий приоритет для определенных классов трафика (например, VoIP), то необходимо настроить QoS.
Физическое оборудование облака в рамках данной модели развертывания использует сеть хранения данных в качестве сети для служебного трафика, например, для получения доступа к внешним ресурсам (репозитории ПО для обновления). Для обеспечения данных функций необходим маршрутизатор с функциями NAT (NAT GW), что позволяет обеспечить необходимый уровень безопасности и изолировать физическую сеть, в которой размещены физические устройства облака, от доступа извне. Кроме того, шлюз безопасности используется для предоставления доступа к API и пользовательскому интерфейсу ACS с помощью механизма трансляции портов.
Коммутационное и маршрутизирующее оборудование должно быть управляемым и подключенным к устройствам удаленного управления электропитанием, что позволяет решать самые сложные случаи без выезда на техническую площадку (к примеру, ошибку конфигурирования, приведшую к потере связи с коммутатором).
Сетевая топология облака представлена на следующем изображении.

Хранилища
Хранилища — ключевой компонент облака, в рамках данной модели развертывания хранилища не предполагаются отказоустойчивыми, что накладывает дополнительные требования на подбор и тестирование серверного оборудования, планируемого к использованию, следует отдавать предпочтение оборудованию, выпущенному известными производителями, предоставляющими готовые решения со встроенными функциями отказоустойчивости (к примеру, специализированные решения от NetApp) или предоставляющими надежное серверное оборудование с проверенной репутацией (HP, Dell, IBM, Fujitsu, Cisco, Supermicro). В рамках облака будут использоваться хранилища, поддерживающие протокол NFSv3 (v4).
Apache CloudStack использует два вида хранилищ:
- Primary Storage (первичное хранилище), которое необходимо для хранения томов виртуальных машин;
- Secondary Storage (вторичное хранилище), которое предназначено для хранения снимков, образов, шаблонов виртуальных машин.
Необходимо тщательно осуществлять планирование данных компонентов, от их производительности и надежности работоспособность облака будет зависеть в наибольшей степени.
Дополнительно, для выполнения глобального резервного копирования хранилищ рекомендуется выделение отдельного сервера, который может использоваться для следующих целей:
- восстановление после катастроф;
- предотвращение локальных пользовательских аварий, связанных с человеческим фактором.
Данный компонент не является внутренним, по отношению к облаку ACS, поэтому в статье далее не рассматривается.
Достоинства и недостатки при развертывании облака с использованием первичных NFS-хранилищ
NFS — широко применяемый протокол доступа к файловым системам, зарекомендовавший себя за десятилетия использования. К достоинствам NFS-хранилищ при реализации сервиса публичного облака можно отнести следующие свойства:
- высокая производительность хранилища, достигаемая за счет консолидации большого количества дисковых устройств в одном сервере;
- эффективное использование пространства хранилища, достигаемое за счет возможности продажи дискового пространства сверх реального объема за счет использования тонкого выделения при использовании формата томов QCOW2, что позволяет развивать хранилище по мере необходимости с запаздыванием;
- простота распределения дискового пространства между хостами виртуализации, достигаемая за счет функционирования всего пространства хранилища как единого пула;
- поддержка живой миграции виртуальных машин между хостами, разделяющими одно хранилище;
- простота администрирования.
К недостаткам же можно отнести следующие свойства:
- единая точка отказа для всех виртуальных машин, разделяющих хранилище;
- требуется тщательное планирование производительности на этапе проектирования;
- некоторые регламентные процедуры, требующие остановки хранилища, будут вызывать остановку всех машин, использующих данное хранилище;
- требуется разработка регламентных процедур наращивания свободного пространства хранилища (добавление новых дисков, сборка RAID, миграция данных между логическими томами).
Первичное хранилище
Первичное хранилище должно обеспечивать следующие важные операционные характеристики:
- высокую производительность для случайного доступа (IOPS);
- высокую пропускную способность по полосе (MB/s);
- высокую надежность хранения данных.
Обычно, одновременно достичь три данных свойства можно либо при использовании специализированных решений, либо при использовании гибридных (SSD+HDD) или полностью SSD хранилищ. В том случае, если хранилище проектируется с использованием программной реализации, рекомендуется использовать хранилище, которое полностью состоит из SSD накопителей с аппаратными или программными RAID 5го или 6го уровня. Также, возможно рассмотреть к применению готовые решения, например FreeNAS, NexentaStor, которые включают поддержку ZFS, что может дать дополнительные бонусы при реализации резервного копирования и включают встроенные механизмы экономии дискового пространства за счет дедупликации и сжатия данных на лету.
В том случае, если планируется использование хранилища, реализованного с помощью GNU/Linux, то рекомендуется стек хранения, который включает следующие слои:
- программный (Mdadm) или аппаратный RAID (LSI, Adaptec);
- LVM2 (поддержка масштабирования хранилища), которая позволяет реализовать принцип Pay-As-You-Go;
- EXT4.
По опыту автора, крайне не рекомендуется использовать Bcache, ZFS On Linux и FlashCache, если планируется использовать снимки LVM2 для осуществления резервного копирования. В долгосрочном периоде автор статьи наблюдал ошибки ядра, что приводило к отказу хранилища, требовало рестарта облака и может привести к потере пользовательских данных.
Также, крайне не рекомендуется использование BTRFS, поскольку гипервизор KVM имеет известные проблемы производительности с данной файловой системой.
Автор использует в своем облаке следующие решения для реализации первичного хранилища:
- Аппаратура:
- Серверы Supermicro с HBA от LSI
- Сетевые карты Intel x520-DA2
- Накопители Samsung Pro 850 1TB
- Debian GNU/Linux 8
- Программный RAID5, RAID6
- LVM2
- Файловая система EXT4.
Данное решение (Mdadm/LVM2/Ext4) обеспечивает стабильную работу при использовании снимков LVM2, применяемых для выполнения резервных копий, без известных проблем стабильности. Крайне рекомендуется подключать хранилище к коммутатору сети доступа к данным посредством двух линий, объединенных в bonding-интерфейс (LACP или Master/Slave), что позволяет обеспечить не только высокую пропускную способность, но и отказоустойчивость (при использовании стеков или других технологий построения отказоустойчивых сетей рекомендуется подключение к различным устройствам).
При развертывании первичного хранилища необходимо произвести тестирование его производительности при предельных нагрузках — одновременно нагрузка четырех типов:
- планируемая пиковая нагрузка от VM;
- резервное копирование данных;
- восстановление большого тома пользовательской VM из резервной копии;
- RAID-массив в состоянии восстановления.
Процессор и память
Процессор и доступная память сервера также имеют существенное влияние для увеличения производительности первичного хранилища. Сервер NFS может активно утилизировать ядра CPU при высоких нагрузках как по IOPS так и по пропускной способности. При использовании нескольких программных RAID в рамках одного сервера, служба mdadm создает существенную нагрузку на CPU (особенно при использовании RAID5, RAID6). Рекомендуется использовать серверы с CPU Xeon E3 или Xeon E5, для лучшей производительности стоит рассмотреть сервер с двумя CPU Xeon E5. Предпочтение стоит отдавать моделям с высокой тактовой частотой, поскольку ни NFS ни mdadm не могут эффективно использовать многопоточность. Дополнительно стоит отметить, что в случае выполнения глобального резервного копирования томов с использованием Gzip-сжатия, часть ядер будет занята выполнением данных операций. Что же касается RAM, то чем больше RAM доступно на сервере тем больше ее будет использовано для буферного кэша и тем меньше операций чтения будет отправлено на дисковые устройства. В случае использования сервера NFS c ZFS, CPU и RAM могут влиять на производительность большим образом, чем в случае Mdadm/LVM2/Ext4 в связи с поддержкой сжатия данных и дедупликации на лету.
Настройки дисковой подсистемы
Помимо многочисленных настроек дисковой подсистемы, которые включают специфические настройки для RAID-контроллеров и логических массивов, упреждающего чтения, планировщика, но не ограничиваются ими, рекомендуем уменьшить время нахождения грязных данных в буфере оперативной памяти. Это позволит уменьшить ущерб в случае аварии хранилища.
Настройки службы NFS
Основные опции, которые конфигурируются при использовании NFS — размер блока передачи данных (rsize, wsize), синхронный или асинхронный режим сохранения данных на диски (sync, async) и количество экземпляров служб, которое зависит от количество клиентов NFS, то есть хостов виртуализации. Использование sync режима не рекомендуется в силу низкой производительности.
Сеть
В качестве сетевых карт для доступа к хранилищам рекомендуется применять современные сетевые карты, например, Intel X520-DA2. Оптимизация сетевого стека заключается в настройке поддержки jumbo frame и распределении прерываний сетевой карты между ядрами CPU.
Вторичное хранилище
Вторичное хранилище должно обеспечивать следующие важные характеристики:
- высокую линейную производительность;
- высокую надежность хранения данных.
Хранилище максимально утилизируется при создании снимков и конвертации снимков в шаблоны. Именно в этом случае производительность хранилища оказывает существенное влияние на продолжительность выполнения операции. Для обеспечения высокой линейной производительности хранилища рекомендованы к использованию программные и аппаратные RAID-массивы с использованием RAID10, RAID6 и серверными SATA-дисками большого объема — 3 TB и больше.
В том случае, если используется программный RAID, лучше остановить выбор на RAID10, при использовании же высокопроизводительных аппаратных контроллеров с элементом BBU возможно использование RAID5, RAID6.
В целом, требования к вторичному хранилищу не настолько критичны как к первичному, однако, в том случае, если планируется интенсивное применение снимков томов виртуальных машин, рекомендуется тщательное планирование вторичного хранилища и проведение тестов, моделирующих реальную нагрузку.
Автор использует в своем облаке следующие решения для реализации вторичного хранилища:
- Аппаратура:
- Серверы Supermicro с аппаратным контроллером RAID от LSI/Adaptec
- Сетевые карты Intel x520-DA2
- Дисковые устройства Seagate Constellation ES.3 размером 3TB
- Debian GNU/Linux 8
- Аппаратный RAID10
- LVM2
- Файловая система EXT4
Сервер управления
Сервер управления — ключевой компонент системы Apache CloudStack, отвечающий за управление всеми функциями облака. В рамках отказоустойчивых конфигураций рекомендуется использовать несколько серверов управления, которые взаимодействуют с отказоустойчивым сервером MySQL (master-slave или mariadb galera cluster). В связи с тем, что Management Server не хранит информацию в RAM, то появляется возможность простой реализации HA с помощью репликации MySQL и нескольких управляющих серверов.
В рамках данной статьи будем считать, что используется один надежный сервер, который содержит
- MySQL — СУБД для хранения данных ACS;
- CloudStack Management Server — Java-приложение, выполняющее все функции ACS;
Для сервера управления необходимо выбрать оборудование от проверенного поставщика, которое обеспечит надежное, безотказное функционирование. Основные требования к производительности продиктованы использованием СУБД MySQL, соответственно необходима быстрая, надежная дисковая подсистема на SSD накопителях. Начальная конфигурация может выглядеть следующим образом:
- Сервер Supermicro Xeon E3-1230V5, 32GB RAM с IPMI
- Intel X520-DA2
- 2 x SSD Intel S3610 100GB (RAID1)
- 2 x Seagate Constellation ES.3 3TB (RAID1)
- LVM2
- Mdadm
- Ubuntu 16.04 Server
Пара SSD накопителей используется для системы, а вторая пара SATA дисков для снимков системы, дампов БД ACS, которые выполняются на регулярной основе, например, ежедневно или чаще.
В том случае, если планируется интенсивное использование API и если будет активировано S3 API, то рекомендуется использовать сервер с высокопроизводительным CPU или двумя CPU. Кроме того, в самой панели управляющего сервера ACS рекомендуется настроить ограничение на интенсивность использования API пользователями и обеспечить дополнительную защиту сервера с помощью прокси-сервера Nginx.
Топологическая организация облака Apache CloudStack
Общая топологическая структура ACS представляет собой иерархическое вложение сущностей
- Зона
- Стенд
- Кластер
- Хост
На изображении представлен пример реализации такой топологической структуры для некоторого ЦОДа dc1.
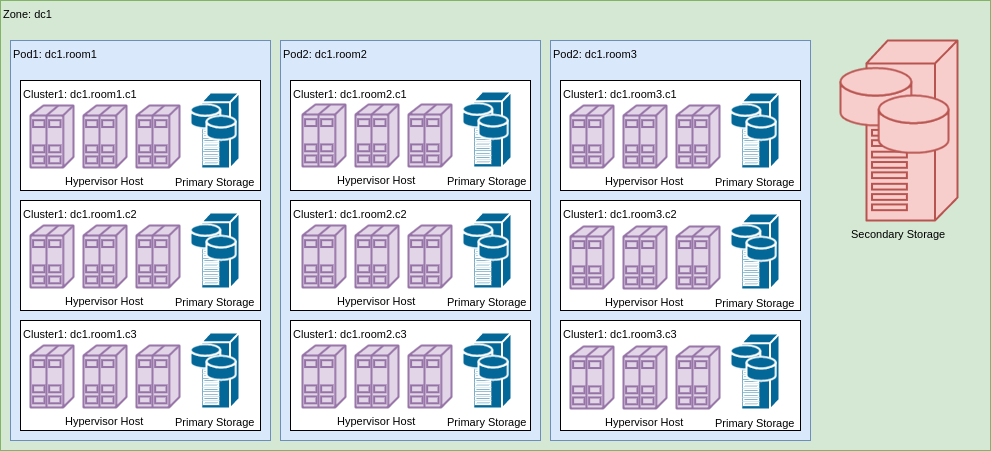
Базовая зона
Зона ACS определяет набор услуг, которые предоставляет облако пользователю. Зоны бывают двух типов — Базовая (Basic) и Продвинутая (Advanced), что позволяет организовывать различные облака, предоставляющие либо основные услуги, либо более широкий спектр возможностей, включая VPN, эластичную балансировку, NAT, VPC. Базовая зона предоставляет следующие функции:
- управление IP-адресами и служба DHCP;
- служба DNS (резолвер и зона);
- управление паролями и ключами, устанавливаемыми в виртуальные машины;
- маршрутизатор (опционально);
- группы безопасности.
Также, возможно сконфигурировать другие сетевые предложения, с помощью которых можно создавать базовые зоны, обладающие другими свойствами, например, с внешним DHCP-сервером.
Стенд
Стенды представляют собой следующий уровень организации топологии. В зависимости от фактической организации стендом может быть как комната, так и альтернативные сущности, например, ряд, стойка. То, что понимается под стендом, определяется в первую очередь следующими факторами:
- количеством адресов, которые будут выделяться виртуальным машинам в рамках стенда, адреса, выделенные одному стенду не могут быть переданы другому стенду, например, при выделении стенду сети /22 (1024 адреса) необходимо обеспечить нахождение в стенде оборудования, которое сможет обслужить все данные адреса;
- резервирование — конкретный стенд может быть выделен для аккаунта;
- геометрическими соображениями;
- выделением доменов отказа.
Для сети из 1024 виртуальных машин вполне достаточно одного стенда, если все оборудование размещается в одной стойке, но может быть и 4, если существуют явные аргументы за разделение сети /22 на 4 x /24, например, при использовании разных устройств агрегации L3. В стенде может находиться произвольное количество кластеров, поэтому явных ограничений на планирование нет.
Кластер
Кластер определяет гипервизор, который будет использоваться для оказания услуг. Данный подход достаточно удобен, особенно в случае, если планируется использовать возможности различных гипервизоров по максимуму, например:
- KVM — виртуальные машины общего назначения без снимков состояния виртуальных машин, только снимки томов (AWS-like);
- XenServer
- виртуальные машины с графическими ускорителями,
- виртуальные машины с поддержкой снимков состояний и динамическим масштабированием;
- Hyper-V — виртуальные машины для предоставления услуг ОС Windows.
В рамках рассматриваемой модели развертывания, кластер — это элемент, на уровне которого ограничивается распространение отказа обслуживания за счет выделения первичного NFS-хранилища именно кластеру, что позволяет добиться того, что при отказе первичного хранилища отказ не распространяется за пределы кластера. Для достижения этой цели при добавлении первичного хранилища к облаку его область действия должна быть указана как Кластер, а не как Зона. Необходимо отметить, что поскольку первичное хранилище относится к кластеру, то живая миграция виртуальных машин может производиться только между хостами кластера.
Ограничения гипервизора KVM при использовании с панелью Apache CloudStack
Гипервизор KVM имеет ряд ограничений, которые могут препятствовать его внедрению, однако широкая распространенность показывает, что данные ограничения не рассматриваются большинством провайдеров как блокирующие. Основные ограничения следующие:
- не поддерживается динамическое масштабирование виртуальных машин, то есть для изменения количества ядер и RAM необходимо остановить машину и запустить;
- не поддерживаются полные снимки виртуальной машины вместе с дисками (это ограничение именно Apache CloudStack, поскольку сам QEMU/KVM поддерживает такую возможность);
- нет поддержки виртуальных графических ускорителей, поэтому если планируется предоставлять VDI, совместно с инфраструктурой от NVidia, то KVM не подойдет.
При планировании кластера важно исходить из конечных возможностей хранилища, которое будет использоваться с кластером. ACS позволяет использовать в рамках кластера несколько хранилищ, однако из своего опыта автор не рекомендует использовать такой вариант. Оптимальным, является подход, в рамках которого кластер проектируется как некий компромисс между потребностями и возможностями. Часто возникает желание делать кластеры слишком большими, что может приводить к тому, что домены отказа станут слишком широкими.
Проектирование кластера может производиться, исходя из понимания потребностей среднестатистической виртуальной машины. К примеру, в одном из существующих облаков пользователи, в среднем, заказывают услугу, которая выглядит как [2 ядра, 2GB RAM, 60GB SSD]. Если попробовать рассчитать требования к кластеру, исходя из объема хранилища (без учета требований к IOPS), то можно получить следующие числа:
- Storage 24 x 1TB SSD (RAID6 + 1HS) — 21 TB
- Количество экземпляров VM — 350 = 21000 / 60
- RAM — 700 GB = 350 x 2
- Cores — 700 = 350 x 2
- Узел 2 x Xeon E5-2699V4 / 160 GB RAM — 88 Vcores (166 с переподпиской 1 к 2)
- Количество узлов (+1 резервный) — 5 + 1
Итоговый кластер будет выглядеть следующим образом:
- Хранилище: Storage 24 x 1TB SSD (RAID6 + 1HS)
- Сервер виртуализации 6 x Server 2 x Xeon E5-2699V4 / 160 GB RAM
В рамках данного кластера удастся обслужить до 350 типовых виртуальных машин. Если планируется выделение ресурсов для обслуживания 1000 машин, то необходимо развертывание трех кластеров. В случае реального облака с дифференциацией по продуктам, необходим расчет, который максимально точно отражает прогноз потребностей рынка.
В примере расчета не учитывается экономическая составляющая, при реальном расчете модели CPU и объем RAM на узел следует выбирать таким образом, чтобы минимизировать срок окупаемости кластера и обеспечить качество обслуживания, согласованное с владельцем продукта.
В том случае, если суммарный размер хранилища выбран другим или пользователи приобретают VPS с меньшими или большими томами, то требования к вычислительной мощности кластера могут существенно измениться.
Сервер виртуализации
Сервер виртуализации предназначен для выполнения виртуальных машин. Конфигурация сервера виртуализации может существенно различаться от облака к облаку и зависит от типа вычислительных предложений (конфигураций VPS, доступных пользователям) и их назначения. В рамках одного кластера желательно иметь однотипные, взаимозаменяемые серверы виртуализации с совместимыми CPU (или обеспечить совместимость по младшему CPU среди всех), что позволит обеспечить живую миграцию виртуальных машин между узлами и доступность ресурсов кластера при выходе одного из узлов из строя.
В том случае, если планируется выполнение множества небольших виртуальных машин с низкой и средней нагрузкой, то желательно использовать серверы с большим количеством ядер и памяти, например, 2 x Xeon E5-2699V4 / 256GB RAM. При этом удается достичь хорошей плотности ресурсов и высокого качества обслуживания для виртуальных машин с 1, 2, 4, 8 ядрами, обычного использования (не для решения вычислительных задач) и добиться высокого качества обслуживания при существенной переподписке по CPU (в 2-8 раз). В таком случае, планирование может производиться исходя из объема RAM, а не количества ядер.
Если же планируется развертывание высокочастотных, многоядерных, высоконагруженных виртуальных машин, то необходимо выбирать серверы, которые обеспечивают необходимые ресурсы CPU. В этом случае планирование должно производиться, исходя из доступного без переподписки количества ядер, а объем оперативной памяти должен соответствовать необходимой потребности. Для примера, можно рассмотреть сервер Xeon E3-1270V5 / 64GB RAM, который может использоваться для предоставления услуг высокочастотных виртуальных машин:
- 1 x CPU 3.6 GHz / 8 GB RAM
- 2 x CPU 3.6 GHz / 16 GB RAM
- 4 x CPU 3.6 GHz / 32 GB RAM
- 8 x CPU 3.6 GHz / 64 GB RAM
Аналогично, можно рассмотреть использование серверов на базе 2 x Xeon E5V4, при этом планирование должно осуществляться аналогичным образом, исходя из фактических потребностей CPU, а не RAM.
Оптимизация RAM
Apache CloudStack позволяет осуществлять переподписку по памяти. Обычно, переподписка по памяти ведет к деградации сервиса за счет интенсивного использования разделов подкачки, однако, Linux предоставляет инструменты, которые позволяют эффективно использовать переподписку по памяти, особенно, в случае однотипных виртуальных машин. Данные механизмы — KSM, ZRAM и ZSwap, обеспечивающие дедупликацию и сжатие страниц RAM, что позволяет уменьшить объем используемой физической оперативной памяти и обеспечить высокие коэффициенты переподписки (1:2 и выше) за счет повышенной нагрузки на CPU. Кроме того, применение высокопроизводительных SSD накопителей для разделов подкачки так же может положительно повлиять на качество сервиса.
Сеть доступа к хранилищам
В качестве сетевых карт для доступа к хранилищам рекомендуется применять современные сетевые карты, например, Intel X520-DA2. Оптимизация сетевого стека заключается в настройке поддержки jumbo frame и в распределении обработки прерываний очередей сетевой карты между ядрами CPU.
Сеть передачи данных
В качестве сетевых карт для передачи пользовательских данных рекомендуется применять современные сетевые карты с поддержкой большого количества очередей и в распределении обработки прерываний очередей сетевой карты между ядрами CPU.
Настройка виртуальных мостов
Виртуальные мосты используются для организации связи виртуальных сетевых устройств виртуальных машин с физическими сетевыми устройствами. Данные мосты могут быть организованы двумя способами — посредством Linux Bridge и Open Vswitch. Apache CloudStack поддерживает обе модели, однако, Linux Bridge в рамках данной топологии является оптимальным выбором в силу простоты настройки и более высокой производительности.
Пользовательский интерфейс самообслуживания
Apache CloudStack предоставляет два интерфейса управления виртуальными машинами, доступные пользователю — интерфейс API и браузерный UI, реализованный с помощью JavaScript и jQuery. В том случае, если ожидания пользователей к интерфейсу являются высокими, то необходима переработка интерфейса UI для того, чтобы добиться соответствия высоким ожиданиям пользователей. Также, доступен альтернативный пользовательский интерфейс CloudStack-UI, который предназначен именно для провайдеров, планирующих оказание платных услуг для широкого круга пользователей с применением Apache CloudStack. Интерфейс реализован с использованием Angular v4 и Material Design Lite и распространяется в соответствии с открытой лицензией Apache v2.0.
Заключение
Продукт Apache CloudStack отлично подходит для развертывания публичного облака со стандартным набором услуг и включает все необходимые компоненты без необходимости дополнительных инженерных вложений в разработку. Использование модели развертывания с хранилищем NFS является типовым и достаточно надежным для оказания услуг с уровнем доступности 99.7% при адекватном планировании топологии облака и использовании надежного оборудования для оказания услуг. Описанная в статье модель развертывания не требует специальных знаний по обслуживанию облака, поскольку реализуется с использованием стандартных технологий, что позволяет администрировать облако без привлечения узкоспециализированных специалистов с эксклюзивными навыками.
