Привет, Хабр! В этой серии статей приведу краткий перевод с английского языка первой главы книги Майкла Нильсона "Neural Networks and Deep Learning".
Перевод я разбил на несколько статей на хабре, чтобы было удобнее читать:
Часть 1) Введение в нейронные сети
Часть 2) Построение и градиентный спуск
Часть 3) Реализация сети для распознавания цифр
Часть 4) Немного о глубоком обучении
Введение
Человеческая визуальная система — одна из самых удивительных на свете. В каждом полушарии нашего мозга есть зрительная кора, содержащая 140 млн. нейронов с десятками млрд. связей между ними, но такая кора не одна, их несколько, и вместе они образуют настоящий суперкомпьютер в нашей голове, лучшим образом адаптированный в ходе эволюции под восприятие визуальной составляющей нашего мира. Но трудность распознавания визуальных образов становится очевидной, если вы попытаетесь написать программу для распознавания, скажем, рукописных цифр.

Простую интуицию — "у 9-тки есть петля сверху, и вертикальный хвост внизу" не так просто реализовать алгоритмически. Нейронные сети используют примеры, выводят некоторые правила и учатся на них. Более того чем больше примеров мы покажем сети, тем больше она узнает о рукописных цифрах, следовательно классифицирует их с большей точностью. Мы напишем программу в 74 строчки кода, которая будет определять рукописные цифры с точностью >99%. Итак, поехали!
Персептрон
Что такое нейронная сеть? Для начала объясню модель искусственного нейрона. Персептрон был разработан в 1950 г. Фрэнком Розенблатом, и сегодня мы будем использовать одну из основных его моделей — сигмоидный персептрон. Итак, как он работает? Персепрон принимает на вход вектор  и возвращает некоторое выходное значение
и возвращает некоторое выходное значение  .
.
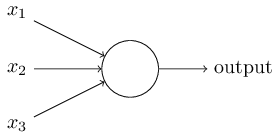
Розенблат предложил простое правило для вычисления выходного значения. Он ввел понятие "значимости", далее "веса" каждого входного значения  . В нашем случае
. В нашем случае  будет зависеть от того, будет ли
будет зависеть от того, будет ли  больше или меньше некоторого порогового значения
больше или меньше некоторого порогового значения  .
.

И это все, что нам нужно! Варьируя  и вектор весов
и вектор весов  , можно получить совершенно разные модели принятия решения. Теперь вернемся к нейронной сети.
, можно получить совершенно разные модели принятия решения. Теперь вернемся к нейронной сети.
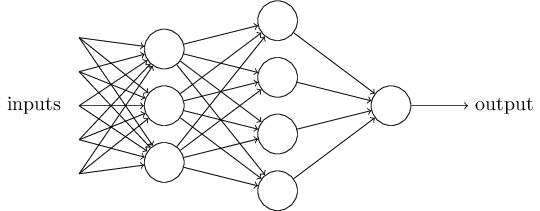
Итак, мы видим, что сеть состоит из нескольких слоев нейронов. Первый слой называется входным слоем или рецепторами ( ), следующий слой — скрытый (
), следующий слой — скрытый ( ), и последний — выходной слой (
), и последний — выходной слой ( ). Условие
). Условие  довольно громоздко, давайте заменим на скалярное произведение векторов
довольно громоздко, давайте заменим на скалярное произведение векторов  . Далее положим
. Далее положим  , назовем его смещением персептрона или
, назовем его смещением персептрона или  и перенесем
и перенесем  в левую часть. Получим:
в левую часть. Получим:

Проблема обучения
Чтобы узнать, как может работать обучение, предположим что мы немного изменили некоторый вес или смещение в сети. Мы хотим, чтобы это небольшое изменение веса вызывало небольшое соответствующее изменение на выходе из сети. Схематически это выглядит так:
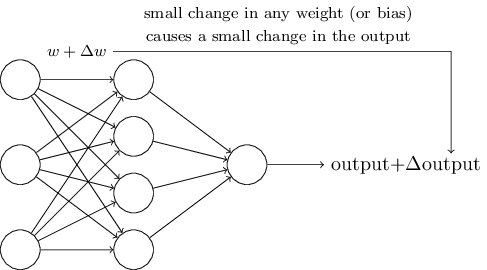
Если бы это было возможно, то мы могли бы манипулировать весами в выгодную нам сторону и постепенно обучать сеть, но проблема состоит в том, что при некотором изменение веса конкретного нейрона — его выход может полностью "перевернуться" с 0 на 1. Это может привести к большой ошибке прогноза всей сети, но есть способ обойти эту проблему.
Сигмоидный нейрон
Мы можем преодолеть эту проблему, введя новый тип искусственного нейрона, называемый сигмоидным нейроном. Сигмоидные нейроны подобны персептронам, но модифицированы так, что небольшие изменения в их весах и смещении вызывают лишь небольшое изменение на их выходе. Структура сигмоидного нейрона аналогичная, но теперь на вход он может принимать  , а на выходе выдавать
, а на выходе выдавать  , где
, где

Казалось бы, совершенно разные случаи, но я вас уверяю, что персептрон и сигмоидный нейрон имеют много общего. Допустим, что  , тогда
, тогда  и, следовательно
и, следовательно  . Верно и обратное, если
. Верно и обратное, если  , то
, то  и
и  . Очевидно, что работая с сигмоидным нейроном мы имеем более сглаженный персептрон. И действительно:
. Очевидно, что работая с сигмоидным нейроном мы имеем более сглаженный персептрон. И действительно:

Архитектура нейронных сетей
Проектирование входных и выходных слоев нейросети — достаточно просто занятие. Для примера, предположим, что мы пытаемся определить, изображена ли рукописная "9" на изображении или нет. Естественным способом проектирования сети является кодирование интенсивностей пикселей изображения во входные нейроны. Если изображение имеет размер  , то мы имеем
, то мы имеем  входных нейрона. Выходной слой имеет один нейрон, который содержит выходное значение, если оно больше, чем 0.5, то на изображении "9", иначе нет. В то время как проектирование входных и выходных слоев — достаточно простая задача, выбор архитектуры скрытых слоев — искусство. Исследователи разработали множество эвристик проектирования скрытых слоев, например такие, которые помогают скомпенсировать количество скрытых слоев против времени обучения сети.
входных нейрона. Выходной слой имеет один нейрон, который содержит выходное значение, если оно больше, чем 0.5, то на изображении "9", иначе нет. В то время как проектирование входных и выходных слоев — достаточно простая задача, выбор архитектуры скрытых слоев — искусство. Исследователи разработали множество эвристик проектирования скрытых слоев, например такие, которые помогают скомпенсировать количество скрытых слоев против времени обучения сети.
До сих пор мы использовали нейронные сети, в которых выход из одного слоя — использовался как сигнал для следующего, такие сети называются прямыми нейронными сетями или сетями прямого распространения( ). Однако существуют и другие модели нейронных сетей, в которых возможны петли обратной связи. Эти модели называются рекуррентными нейронными сетями(
). Однако существуют и другие модели нейронных сетей, в которых возможны петли обратной связи. Эти модели называются рекуррентными нейронными сетями( ). Рекуррентные нейронные сети были менее влиятельными, чем сети с прямой связью, отчасти потому, что алгоритмы обучения для рекуррентных сетей (по крайней мере на сегодняшний день) менее эффективны. Но рекуррентные сети по-прежнему чрезвычайно интересны. Они гораздо ближе по духу к тому, как работает наш мозг, чем сети с прямой связью. И вполне возможно, что повторяющиеся сети могут решать важные проблемы, которые могут быть решены с большим трудом с помощью сетей прямого доступа.
). Рекуррентные нейронные сети были менее влиятельными, чем сети с прямой связью, отчасти потому, что алгоритмы обучения для рекуррентных сетей (по крайней мере на сегодняшний день) менее эффективны. Но рекуррентные сети по-прежнему чрезвычайно интересны. Они гораздо ближе по духу к тому, как работает наш мозг, чем сети с прямой связью. И вполне возможно, что повторяющиеся сети могут решать важные проблемы, которые могут быть решены с большим трудом с помощью сетей прямого доступа.
Итак, на сегодня все, в следующей статье я расскажу о градиентом спуске и обучении нашей будущей сети. Спасибо за внимание!
