С самого начала Discord активно использовал Elixir. Виртуальная машина Erlang стала идеальным кандидатом для создания высокопараллельной системы реального времени, которую мы собирались создать. Первоначальный прототип Discord был разработан на Elixir; сейчас он лежит в основе нашей инфраструктуры. Задача и предназначение Elixir простые: доступ ко всей мощи Erlang VM через гораздо более современный и дружественный язык и набор инструментов.
Прошло два года. Сейчас у нас пять миллионов одновременных пользователей, а через систему проходят миллионы событий в секунду. Хотя мы абсолютно не сожалеем о выборе архитектуры, пришлось проделать массу исследований и экспериментов, чтобы добиться такого результата. Elixir — это новая экосистема, а экосистеме Erlang не хватает информации о её использовании в продакшне (хотя Erlang in Anger — это нечто). По итогу всего пути, пытаясь приспособить Elixir для работы в Discord, мы извлекли некоторые уроки и создали ряд библиотек.
Хотя у Discord много функций, в основном всё сводится к pub/sub. Пользователи подключаются к WebSocket и раскручивают сессию (GenServer), которая затем устанавливает соединение с удалёнными узлами Erlang, где работают guild-процессы (тоже GenServer'ы). Если что-то публикуется в guild (внутреннее именование “Discord Server”), оно разворачивается веером на каждую подключенную сессию.
Когда пользователь выходит в онлайн, он подключается к guild'у, а тот публикует статус присутствия во все остальные подключенные сессии. Есть и много другой логики, но вот упрощённый пример:
Это был нормальный подход, когда мы изначально создали Discord для групп из 25 или менее пользователей. Однако нам повезло столкнуться с «хорошими проблемами» роста, когда люди начали использовать Discord в больших группах. В итоге мы пришли к тому, что на многих серверах Discord вроде /r/Overwatch присутствует до 30 000 пользователей одновременно. В пиковые часы мы наблюдали, что эти процессы не справляются с очередями сообщений. В определённый момент пришлось вручную вмешаться и отключить функции генерации сообщений, чтобы помочь справиться с нагрузкой. Нужно было разобраться с проблемой до того, как она приобретёт масштабный характер.
Мы начали с бенчмарков для самых нагруженных путей в рамках процессов guild и вскоре выявили очевидную причину неприятностей. Обмен сообщениями между процессами Erlang оказался не таким эффективным, как нам казалось, а единица работы Erlang для шедулинга процессов тоже обходилась весьма дорого. Мы обнаружили, что время одного вызова
Нужно было как-то распределить работу по рассылке сообщений. Поскольку процессы spawn в Erlang обходятся дёшево, нашей первой идеей было просто спаунить новый процесс для обработки каждого публикуемого сообщения. Однако все публикации могли происходить в разное время, а клиенты Discord зависят от линеаризуемости событий. К тому же, такое решение нельзя хорошо масштабировать, потому что у сервиса guild становилось всё больше работы.
Вдохновлённые постом в блоге о повышении производительности в передаче сообщений между нодами, мы создали Manifold. Manifold распределяет работу по рассылке сообщений между удалёнными нодами с идентификаторами PID (идентификатор процессов в Erlang). Это гарантирует, что процессы рассылки будут вызывать
Замечательным побочным эффектом Manifold стало то, что нам удалось не только распределить нагрузку CPU веерных сообщений, но и снизить сетевой трафик между нодами:
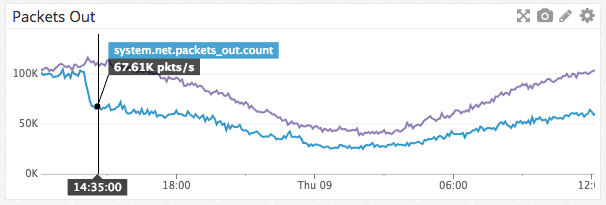
Снижение сетевого трафика на одну ноду Guild
Manifold лежит на GitHub, так что пробуйте.
Discord — распределённая система, которая применяет консистентное хеширование. Использование этого метода потребовало создания кольцевой структуры данных, которую можно использовать для поиска ноды конкретного объекта. Мы хотели, чтобы система работала быстро, поэтому выбрали замечательную библиотеку Криса Муса, подключив её через порт Erlang C (процесс, отвечающий за интерфейс с кодом C). Она отлично работала, но по мере масштабирования Discord мы начали замечать проблемы во время всплесков с переподключением пользователей. Процесс Erlang, отвечающий за управление кольцом, начинал настолько загружаться работой, что не мог справиться с запросами к кольцу, и вся система не справлялась с нагрузкой. Решение на первый взгляд выглядело очевидным: запустить множество процессов с данными кольца для лучшего использования всех ядер машины, чтобы обработать все запросы. Но это слишком важная задача. Есть ли лучший вариант?

Давайте посмотрим на составляющие.
Если сессионный сервер сбоил и перезагружался, уходило около 30 секунд просто на поиски в кольце. Это даже не считая дешедулинга со стороны Erlang одного процесса, вовлечённого работу других процессов кольца. Можем ли мы полностью устранить эти издержки?
При работе с Elixir, если нужно ускорить доступ к данным, первым делом принято использовать ETS. Это быстрый, изменяемый словарь на C; обратной стороной медали является то, что данные копируются туда и считываются оттуда. Мы не могли просто перевести наше кольцо на ETS, потому что использовали порт C для управления кольцом, так что мы переписали код на чистом Elixir. Как только это было закончено, у нас появился процесс, который владел кольцом и непрерывно копировал его в ETS, так что другие процессы могли считывать данные напрямую из ETS. Это заметно подняло производительность, но операции чтения ETS занимали около 7 мкс и мы по-прежнему тратили 17,5 секунд на операции поиска значений в кольце. Структура данных кольца на самом деле довольно большая, и копирование её в ETS и считывание оттуда занимало основную часть времени. Мы были разочарованы; на любом другом языке программирования можно было просто сделать общее значение для безопасного чтения. Должен быть какой-то способ сделать это на Erlang!
После некоторого исследования мы нашли модуль mochiglobal, который использует функцию виртуальной машины: если Erlang встречает функцию, которая постоянно возвращает одни и те же данные, он помещает эти данные в доступную только для чтения кучу с общим доступом, к которой имеют доступ процессы. Копирование не требуется. mochiglobal использует это, создавая модуль Erlang с одной функцией и компилируя его. Поскольку данные никуда не копируются, расходы на поиск уменьшились до 0,3 мкс, что снизило общее время до 750 мс! Впрочем, полной халявы не бывает; само создание модуля со структурой данных такого размера в рантайме может занимать до секунды. Хорошая новость в том, что мы редко меняем кольцо, так что готовы заплатить такую цену.
Мы решили портировать mochiglobal на Elixir и добавить некоторую функциональность, чтобы избежать атомизации. Наша версия называется FastGlobal.
После решения важной проблемы с производительностью поиска ноды, мы заметили, что процессы, ответственные за обработку поиска
Нужно было сделать сессионные процессы умнее; в идеале, они не должны даже пытаться делать эти вызовы к реестру guild'ов, если неудачный исход неизбежен. Мы не хотели использовать автоматический выключатель, чтобы не возникла ситуация, когда всплеск таймаутов приводит к временному состоянию, когда не делается вообще никаких попыток. Мы знали, как реализовать такое на других языках, но как сделать это на Elixir?
В большинстве других языков мы могли бы использовать атомарный счётчик для отслеживания исходящих запросов и раннего оповещения, если их количество слишком велико, эффективно реализуя семафор. Erlang VM построена на координации между процессами, но мы не хотели слишком загружать процесс, ответственный за эту координацию. После некоторых исследований мы наткнулись на
Эта библиотека способствовала защите нашей инфраструктуры на Elixir. Не далее как на прошлой неделе случилась ситуация, похожая на вышеупомянутые каскадные перебои в обслуживании, но в этот раз никаких перебоев не было. Наши сервисы присутствия засбоили по другой причине, но сессионные сервисы даже не шелохнулись, а сервисы присутствия смогли восстановиться через несколько минут после перезагрузки:
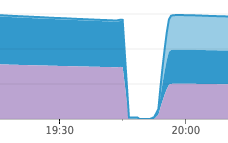
Работа сервисов присутствия
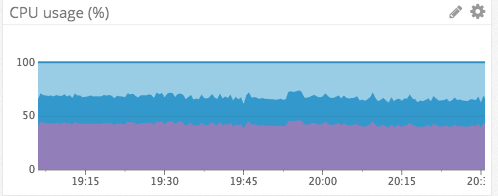
Использование CPU сессионными сервисами за тот же период
Можете найти нашу библиотеку Semaphore на GitHub.
Выбор и работа с Erlang и Elixir оказались отличным опытом. Если бы нас заставили вернуться и начать заново, мы определённо выбрали бы тот же путь. Надеемся, что рассказ о нашем опыте и инструментах будет полезен другим разработчикам Elixir и Erlang, а мы надеемся продолжить рассказывать о своей работе, решении проблем и получении опыта по ходу этой работы.
Прошло два года. Сейчас у нас пять миллионов одновременных пользователей, а через систему проходят миллионы событий в секунду. Хотя мы абсолютно не сожалеем о выборе архитектуры, пришлось проделать массу исследований и экспериментов, чтобы добиться такого результата. Elixir — это новая экосистема, а экосистеме Erlang не хватает информации о её использовании в продакшне (хотя Erlang in Anger — это нечто). По итогу всего пути, пытаясь приспособить Elixir для работы в Discord, мы извлекли некоторые уроки и создали ряд библиотек.
Веерное развёртывание сообщений
Хотя у Discord много функций, в основном всё сводится к pub/sub. Пользователи подключаются к WebSocket и раскручивают сессию (GenServer), которая затем устанавливает соединение с удалёнными узлами Erlang, где работают guild-процессы (тоже GenServer'ы). Если что-то публикуется в guild (внутреннее именование “Discord Server”), оно разворачивается веером на каждую подключенную сессию.
Когда пользователь выходит в онлайн, он подключается к guild'у, а тот публикует статус присутствия во все остальные подключенные сессии. Есть и много другой логики, но вот упрощённый пример:
def handle_call({:publish, message}, _from, %{sessions: sessions}=state) do
Enum.each(sessions, &send(&1.pid, message))
{:reply, :ok, state}
endЭто был нормальный подход, когда мы изначально создали Discord для групп из 25 или менее пользователей. Однако нам повезло столкнуться с «хорошими проблемами» роста, когда люди начали использовать Discord в больших группах. В итоге мы пришли к тому, что на многих серверах Discord вроде /r/Overwatch присутствует до 30 000 пользователей одновременно. В пиковые часы мы наблюдали, что эти процессы не справляются с очередями сообщений. В определённый момент пришлось вручную вмешаться и отключить функции генерации сообщений, чтобы помочь справиться с нагрузкой. Нужно было разобраться с проблемой до того, как она приобретёт масштабный характер.
Мы начали с бенчмарков для самых нагруженных путей в рамках процессов guild и вскоре выявили очевидную причину неприятностей. Обмен сообщениями между процессами Erlang оказался не таким эффективным, как нам казалось, а единица работы Erlang для шедулинга процессов тоже обходилась весьма дорого. Мы обнаружили, что время одного вызова
send/2 может варьироваться от 30 мкс до 70 мкс из-за дешедулинга процесса вызова Erlang. Это означало, что в пиковые часы публикация одного события с большого guild'а может занять от 900 мс до 2,1 с! Процессы Erlang полностью однопоточные, и единственным вариантом параллелизации представлялись шарды. Такое мероприятие потребовало бы немалых сил, и мы знали, что найдётся лучший вариант.Нужно было как-то распределить работу по рассылке сообщений. Поскольку процессы spawn в Erlang обходятся дёшево, нашей первой идеей было просто спаунить новый процесс для обработки каждого публикуемого сообщения. Однако все публикации могли происходить в разное время, а клиенты Discord зависят от линеаризуемости событий. К тому же, такое решение нельзя хорошо масштабировать, потому что у сервиса guild становилось всё больше работы.
Вдохновлённые постом в блоге о повышении производительности в передаче сообщений между нодами, мы создали Manifold. Manifold распределяет работу по рассылке сообщений между удалёнными нодами с идентификаторами PID (идентификатор процессов в Erlang). Это гарантирует, что процессы рассылки будут вызывать
send/2 максимум столько раз, сколько вовлечено удалённых нодов. Manifold делает это, сначала группируя PID'ы по их удалённым нодам, а затем отправляя их в «разделитель» Manifold.Partitioner на каждой из этих нод. Затем разделитель последовательно хеширует PID'ы, используя :erlang.phash2/2, группирует их по количеству ядер и отправляет на дочерние воркеры. В конце концов, воркеры рассылают сообщения в реальные процессы. Это гарантирует, что разделитель не перегружен и продолжает обеспечивать линеаризуемость, как send/2. Такое решение стало эффективной заменой send/2:Manifold.send([self(), self()], :hello)Замечательным побочным эффектом Manifold стало то, что нам удалось не только распределить нагрузку CPU веерных сообщений, но и снизить сетевой трафик между нодами:
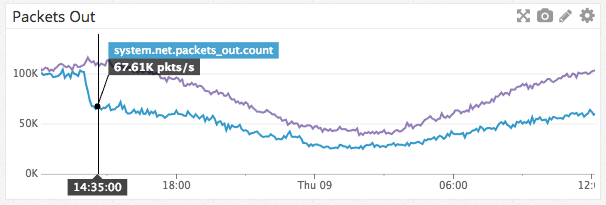
Снижение сетевого трафика на одну ноду Guild
Manifold лежит на GitHub, так что пробуйте.
Общие данные быстрого доступа
Discord — распределённая система, которая применяет консистентное хеширование. Использование этого метода потребовало создания кольцевой структуры данных, которую можно использовать для поиска ноды конкретного объекта. Мы хотели, чтобы система работала быстро, поэтому выбрали замечательную библиотеку Криса Муса, подключив её через порт Erlang C (процесс, отвечающий за интерфейс с кодом C). Она отлично работала, но по мере масштабирования Discord мы начали замечать проблемы во время всплесков с переподключением пользователей. Процесс Erlang, отвечающий за управление кольцом, начинал настолько загружаться работой, что не мог справиться с запросами к кольцу, и вся система не справлялась с нагрузкой. Решение на первый взгляд выглядело очевидным: запустить множество процессов с данными кольца для лучшего использования всех ядер машины, чтобы обработать все запросы. Но это слишком важная задача. Есть ли лучший вариант?
Давайте посмотрим на составляющие.
- Пользователь может быть в любом количестве guild'ов, но средний показатель 5.
- Ответственная за сессии виртуальная машина Erlang VM может поддерживать до 500 000 сессий.
- При подключении сессии ей нужно найти удалённую ноду для каждого guild'а, который ей интересен.
- Время коммуникации с другим процессом Erlang, используя request/reply, составляет около 12 мкс.
Если сессионный сервер сбоил и перезагружался, уходило около 30 секунд просто на поиски в кольце. Это даже не считая дешедулинга со стороны Erlang одного процесса, вовлечённого работу других процессов кольца. Можем ли мы полностью устранить эти издержки?
При работе с Elixir, если нужно ускорить доступ к данным, первым делом принято использовать ETS. Это быстрый, изменяемый словарь на C; обратной стороной медали является то, что данные копируются туда и считываются оттуда. Мы не могли просто перевести наше кольцо на ETS, потому что использовали порт C для управления кольцом, так что мы переписали код на чистом Elixir. Как только это было закончено, у нас появился процесс, который владел кольцом и непрерывно копировал его в ETS, так что другие процессы могли считывать данные напрямую из ETS. Это заметно подняло производительность, но операции чтения ETS занимали около 7 мкс и мы по-прежнему тратили 17,5 секунд на операции поиска значений в кольце. Структура данных кольца на самом деле довольно большая, и копирование её в ETS и считывание оттуда занимало основную часть времени. Мы были разочарованы; на любом другом языке программирования можно было просто сделать общее значение для безопасного чтения. Должен быть какой-то способ сделать это на Erlang!
После некоторого исследования мы нашли модуль mochiglobal, который использует функцию виртуальной машины: если Erlang встречает функцию, которая постоянно возвращает одни и те же данные, он помещает эти данные в доступную только для чтения кучу с общим доступом, к которой имеют доступ процессы. Копирование не требуется. mochiglobal использует это, создавая модуль Erlang с одной функцией и компилируя его. Поскольку данные никуда не копируются, расходы на поиск уменьшились до 0,3 мкс, что снизило общее время до 750 мс! Впрочем, полной халявы не бывает; само создание модуля со структурой данных такого размера в рантайме может занимать до секунды. Хорошая новость в том, что мы редко меняем кольцо, так что готовы заплатить такую цену.
Мы решили портировать mochiglobal на Elixir и добавить некоторую функциональность, чтобы избежать атомизации. Наша версия называется FastGlobal.
Ограниченный параллелизм
После решения важной проблемы с производительностью поиска ноды, мы заметили, что процессы, ответственные за обработку поиска
guild_pid в нодах guild стали давать задний ход. Медленный поиск нод раньше защищал их. Новая проблема заключалась в том, что около 5 000 000 сессионных процессов пытались давить на десять из этих процессов (по одному на каждой ноде guild). Здесь ускорение обработки не решало проблему; фундаментальной причиной было то, что обращения сессионных процессов к этому реестру guild'ов вываливались в таймаут и оставляли запрос в очереди к реестру. После некоторого времени запрос повторялся, но постоянно накапливаемые запросы переходили в неустранимое состояние. Получая сообщения из других сервисов, сессии блокировали бы эти запросы до тех пор, пока они не уйдут в таймаут, что приводило к раздуванию очереди сообщений и, в итоге, к OOM всей Erlang VM, результатом чего становятся каскадные перебои в обслуживании.Нужно было сделать сессионные процессы умнее; в идеале, они не должны даже пытаться делать эти вызовы к реестру guild'ов, если неудачный исход неизбежен. Мы не хотели использовать автоматический выключатель, чтобы не возникла ситуация, когда всплеск таймаутов приводит к временному состоянию, когда не делается вообще никаких попыток. Мы знали, как реализовать такое на других языках, но как сделать это на Elixir?
В большинстве других языков мы могли бы использовать атомарный счётчик для отслеживания исходящих запросов и раннего оповещения, если их количество слишком велико, эффективно реализуя семафор. Erlang VM построена на координации между процессами, но мы не хотели слишком загружать процесс, ответственный за эту координацию. После некоторых исследований мы наткнулись на
:ets.update_counter/4, который выполняет атомарные операции с обусловленных приращением на числе, которое находится в ключе ETS. Поскольку нужна была хорошая параллелизация, можно было запустить ETS в режиме write_concurrency, но по-прежнему считывать значение, поскольку :ets.update_counter/4 возвращает результат. Это дало нам фундаментальную основу для создания библиотеки Semaphore. Её исключительно легко использовать, и она очень хорошо работает с высокой пропускной способностью:semaphore_name = :my_sempahore
semaphore_max = 10
case Semaphore.call(semaphore_name, semaphore_max, fn -> :ok end) do
:ok ->
IO.puts "success"
{:error, :max} ->
IO.puts "too many callers"
endЭта библиотека способствовала защите нашей инфраструктуры на Elixir. Не далее как на прошлой неделе случилась ситуация, похожая на вышеупомянутые каскадные перебои в обслуживании, но в этот раз никаких перебоев не было. Наши сервисы присутствия засбоили по другой причине, но сессионные сервисы даже не шелохнулись, а сервисы присутствия смогли восстановиться через несколько минут после перезагрузки:
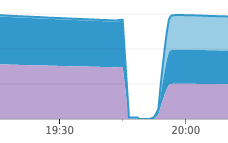
Работа сервисов присутствия
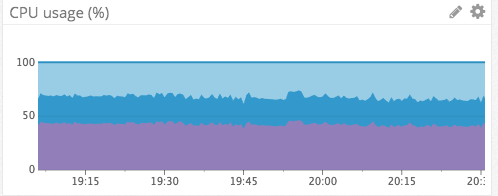
Использование CPU сессионными сервисами за тот же период
Можете найти нашу библиотеку Semaphore на GitHub.
Заключение
Выбор и работа с Erlang и Elixir оказались отличным опытом. Если бы нас заставили вернуться и начать заново, мы определённо выбрали бы тот же путь. Надеемся, что рассказ о нашем опыте и инструментах будет полезен другим разработчикам Elixir и Erlang, а мы надеемся продолжить рассказывать о своей работе, решении проблем и получении опыта по ходу этой работы.
