Большие данные и их анализ играют важнейшую роль в современном мире, где повсеместно используются сети и электронные устройства. Идет непрерывное объединение возможностей больших данных, аналитики и машинного/глубинного обучения. В декабре 2016 года мы создали BigDL — распределенную библиотеку глубинного обучения с открытым исходным кодом для Apache Spark. Цель создания этой библиотеки — объединение сообщества глубинного обучения и сообщества больших данных. Далее в этой статье приводится описание недавних усовершенствований в выпуске BigDL 0.1.0 (а также в предстоящем выпуске 0.1.1).

Python является одним из наиболее широко используемых языков в сообществе больших данных и интеллектуального анализа данных. В BigDL реализована полная поддержка API-интерфейсов Python (используется Python 2.7) на основе PySpark с выпуска 0.1.0. Благодаря этому пользователи могут использовать модели глубинного обучения в BigDL вместе с существующими библиотеками Python (например, NumPy и Pandas), которые автоматически запускаются в распределенной архитектуре для обработки больших объектов данных в кластерах Hadoop*/Spark. Например, можно создать модель LeNet-5, классическую сверточную нейросеть, с помощью API-интерфейсов Python BigDL следующим образом.
Кроме того, мы продолжаем развивать поддержку Python в BigDL; в предстоящем выпуске BigDL 0.1.1 будет добавлена поддержка Python 3.5, а пользователи получат возможность автоматически развертывать индивидуальные зависимые компоненты Python в кластерах YARN.
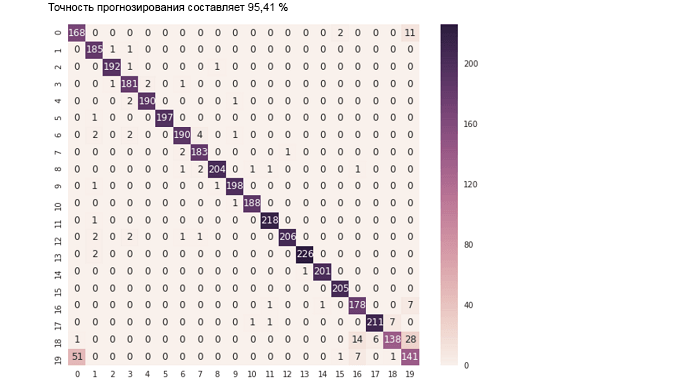
Благодаря полной поддержке API-интерфейсов Python в BigDL специалисты по исследованиям и анализу данных могут работать с данными, применяя мощные «записные книжки» (например, Jupyter Notebook) с распределенной архитектурой ко всему кластеру, сочетая библиотеки Python, Spark SQL/DataFrames и MLlib, модели глубинного обучения в BigDL, а также интерактивные средства визуализации. Например, учебное руководство по Jupyter Notebook, входящее в состав BigDL 0.1.0, демонстрирует возможность оценки результата предсказания для модели классификации текста (используя точность и матрицу ошибок) следующим образом.
TensorBoard — это пакет веб-приложений для анализа и понимания структуры работы и графов программы глубинного обучения. В BigDL 0.1.0 реализована поддержка визуализации с помощью TensorBoard (а также встроенных в «записные книжки» библиотек построения графиков, таких как Matplotlib). Можно настроить программу BigDL так, чтобы она формировала сводную информацию для обучения и/или проверки, как показано ниже (с помощью API-интерфейсов Python).
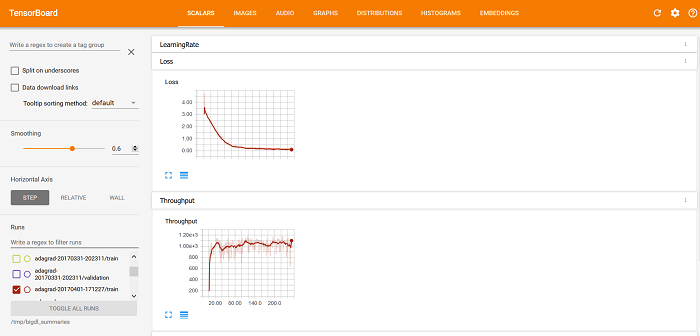
После запуска программы BigDL сохраняются данные о ходе ее работы и результаты ее проверки. После этого можно использовать TensorBoard для визуализации поведения программы BigDL, включая кривые Потери и Пропускная способность на вкладке СКАЛЯРНЫЕ ВЕЛИЧИНЫ (как показано ниже).
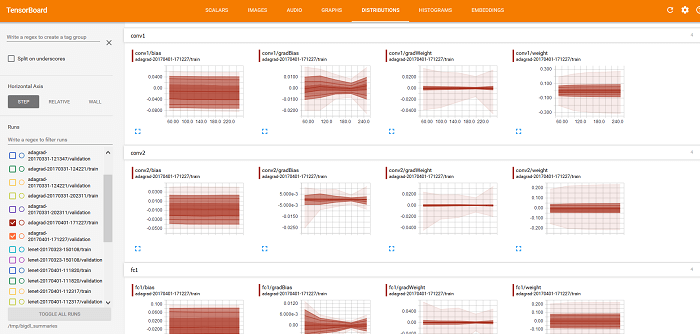
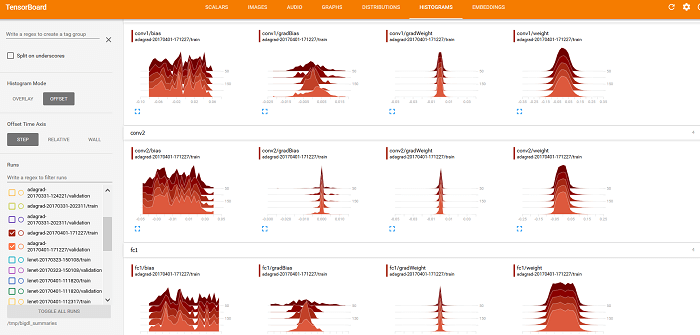
Также можно использовать TensorBoard для отображения значений весов, смещения, gradientWeights и gradientBias на вкладках РАСПРЕДЕЛЕНИЕ и ГИСТОГРАММЫ (как показано ниже).
Рекуррентные нейросети, то есть нейронные сети с обратными связями (RNN) представляют собой мощные модели для анализа речи, текста, временных последовательностей, данных датчиков и т. п. В выпуске BigDL 0.1.0 реализована всесторонняя поддержка RNN, в том числе различные варианты долгой краткосрочной памяти (LSTM), например управляемые рекуррентные единицы (GRU), LSTM с соединениями передачи состояния и вывод в рекуррентных нейросетях. Например, можно создать простую модель LSTM (с помощью API Python) следующим образом.
За последние годы мы стали свидетелями крупных достижений в области глубинного обучения. Сообщество глубинного обучения постоянно совершенствует доступные технологии, а благодаря BigDL они становятся более доступными и удобными в использовании для исследователей и инженеров в области интеллектуального анализа данных (эти специалисты не обязаны быть также и экспертами в области глубинного обучения). Мы продолжаем работать над дальнейшим усовершенствованием BigDL после выпуска 0.1 (например, будут добавлены поддержка чтения и записи моделей TensorFlow, реализация сверточных нейронных сетей (CNN) для трехмерных изображений, рекурсивных сетей и пр.), поэтому пользователи больших данных смогут пользоваться привычными инструментами и инфраструктурой, создавая аналитические приложения на основе алгоритмов глубинного обучения.

Поддержка Python
Python является одним из наиболее широко используемых языков в сообществе больших данных и интеллектуального анализа данных. В BigDL реализована полная поддержка API-интерфейсов Python (используется Python 2.7) на основе PySpark с выпуска 0.1.0. Благодаря этому пользователи могут использовать модели глубинного обучения в BigDL вместе с существующими библиотеками Python (например, NumPy и Pandas), которые автоматически запускаются в распределенной архитектуре для обработки больших объектов данных в кластерах Hadoop*/Spark. Например, можно создать модель LeNet-5, классическую сверточную нейросеть, с помощью API-интерфейсов Python BigDL следующим образом.
def build_model(class_num):
model = Sequential()
model.add(Reshape([1, 28, 28]))
model.add(SpatialConvolution(1, 6, 5, 5).set_name('conv1'))
model.add(Tanh())
model.add(SpatialMaxPooling(2, 2, 2, 2).set_name('pool1'))
model.add(Tanh())
model.add(SpatialConvolution(6, 12, 5, 5).set_name('conv2'))
model.add(SpatialMaxPooling(2, 2, 2, 2).set_name('pool2'))
model.add(Reshape([12 * 4 * 4]))
model.add(Linear(12 * 4 * 4, 100).set_name('fc1'))
model.add(Tanh())
model.add(Linear(100, class_num).set_name('score'))
model.add(LogSoftMax())
return modelКроме того, мы продолжаем развивать поддержку Python в BigDL; в предстоящем выпуске BigDL 0.1.1 будет добавлена поддержка Python 3.5, а пользователи получат возможность автоматически развертывать индивидуальные зависимые компоненты Python в кластерах YARN.
Интеграция «записных книжек»
Благодаря полной поддержке API-интерфейсов Python в BigDL специалисты по исследованиям и анализу данных могут работать с данными, применяя мощные «записные книжки» (например, Jupyter Notebook) с распределенной архитектурой ко всему кластеру, сочетая библиотеки Python, Spark SQL/DataFrames и MLlib, модели глубинного обучения в BigDL, а также интерактивные средства визуализации. Например, учебное руководство по Jupyter Notebook, входящее в состав BigDL 0.1.0, демонстрирует возможность оценки результата предсказания для модели классификации текста (используя точность и матрицу ошибок) следующим образом.
predictions = trained_model.predict(val_rdd).collect()
def map_predict_label(l):
return np.array(l).argmax()
def map_groundtruth_label(l):
return l[0] - 1
y_pred = np.array([ map_predict_label(s) for s in predictions])
y_true = np.array([map_groundtruth_label(s.label) for s in val_rdd.collect()])
acc = accuracy_score(y_true, y_pred)
print "The prediction accuracy is %.2f%%"%(acc*100)
cm = confusion_matrix(y_true, y_pred)
cm.shape
df_cm = pd.DataFrame(cm)
plt.figure(figsize = (10,8))
sn.heatmap(df_cm, annot=True,fmt='d');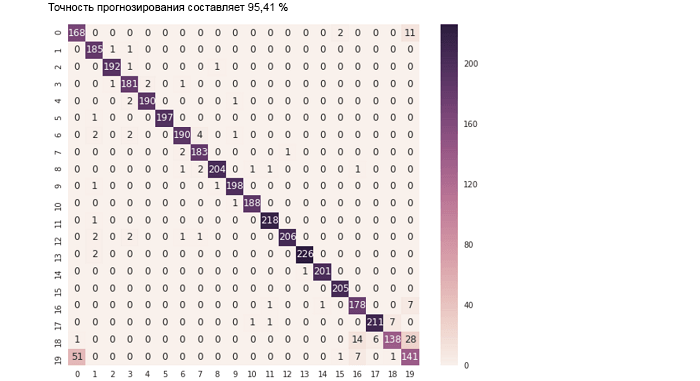
Поддержка TensorBoard
TensorBoard — это пакет веб-приложений для анализа и понимания структуры работы и графов программы глубинного обучения. В BigDL 0.1.0 реализована поддержка визуализации с помощью TensorBoard (а также встроенных в «записные книжки» библиотек построения графиков, таких как Matplotlib). Можно настроить программу BigDL так, чтобы она формировала сводную информацию для обучения и/или проверки, как показано ниже (с помощью API-интерфейсов Python).
optimizer = Optimizer(...)
...
log_dir = 'mylogdir'
app_name = 'myapp'
train_summary = TrainSummary(log_dir=log_dir, app_name=app_name)
val_summary = ValidationSummary(log_dir=log_dir, app_name=app_name)
optimizer.set_train_summary(train_summary)
optimizer.set_val_summary(val_summary)
...
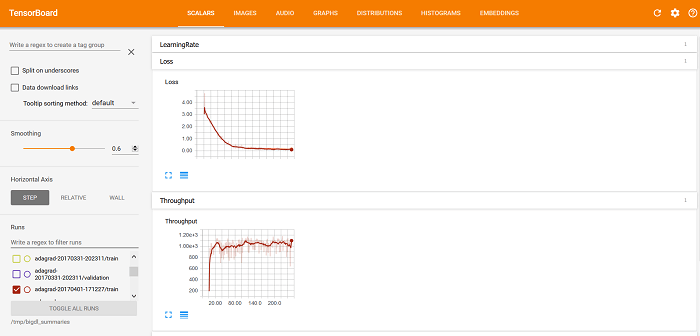
trainedModel = optimizer.optimize()После запуска программы BigDL сохраняются данные о ходе ее работы и результаты ее проверки. После этого можно использовать TensorBoard для визуализации поведения программы BigDL, включая кривые Потери и Пропускная способность на вкладке СКАЛЯРНЫЕ ВЕЛИЧИНЫ (как показано ниже).
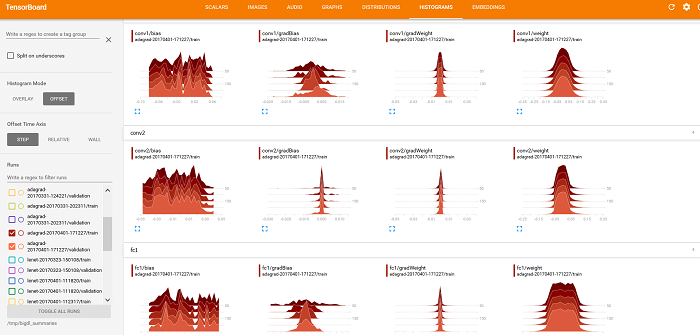
Также можно использовать TensorBoard для отображения значений весов, смещения, gradientWeights и gradientBias на вкладках РАСПРЕДЕЛЕНИЕ и ГИСТОГРАММЫ (как показано ниже).

Улучшенная поддержка нейронных сетей с обратными связями (RNN)
Рекуррентные нейросети, то есть нейронные сети с обратными связями (RNN) представляют собой мощные модели для анализа речи, текста, временных последовательностей, данных датчиков и т. п. В выпуске BigDL 0.1.0 реализована всесторонняя поддержка RNN, в том числе различные варианты долгой краткосрочной памяти (LSTM), например управляемые рекуррентные единицы (GRU), LSTM с соединениями передачи состояния и вывод в рекуррентных нейросетях. Например, можно создать простую модель LSTM (с помощью API Python) следующим образом.
model = Sequential()
model.add(Recurrent()
.add(LSTM(embedding_dim, 128)))
model.add(Select(2, -1))
model.add(Linear(128, 100))
model.add(Linear(100, class_num))За последние годы мы стали свидетелями крупных достижений в области глубинного обучения. Сообщество глубинного обучения постоянно совершенствует доступные технологии, а благодаря BigDL они становятся более доступными и удобными в использовании для исследователей и инженеров в области интеллектуального анализа данных (эти специалисты не обязаны быть также и экспертами в области глубинного обучения). Мы продолжаем работать над дальнейшим усовершенствованием BigDL после выпуска 0.1 (например, будут добавлены поддержка чтения и записи моделей TensorFlow, реализация сверточных нейронных сетей (CNN) для трехмерных изображений, рекурсивных сетей и пр.), поэтому пользователи больших данных смогут пользоваться привычными инструментами и инфраструктурой, создавая аналитические приложения на основе алгоритмов глубинного обучения.
