Эту уязвимость чинят уже пятнадцать лет
В хабрапереводе текста четырёхгодовалой давности «Padding Oracle Attack или почему криптография пугает» была подробно описана атака на режим шифрования CBC. В этом режиме каждый очередной блок открытого текста xor-ится с предыдущим блоком шифротекста: в результате каждый блок шифротекста зависит от каждого блока открытого текста, который был обработан к тому моменту.

Чтобы пропустить исходное сообщение (произвольной длины) через CBC-шифр, к нему дописывается MAC (хеш для проверки целостности, обычно 20-байтный SHA-1) и затем padding, чтобы дополнить открытый текст до целого числа блоков (обычно 16-байтных):
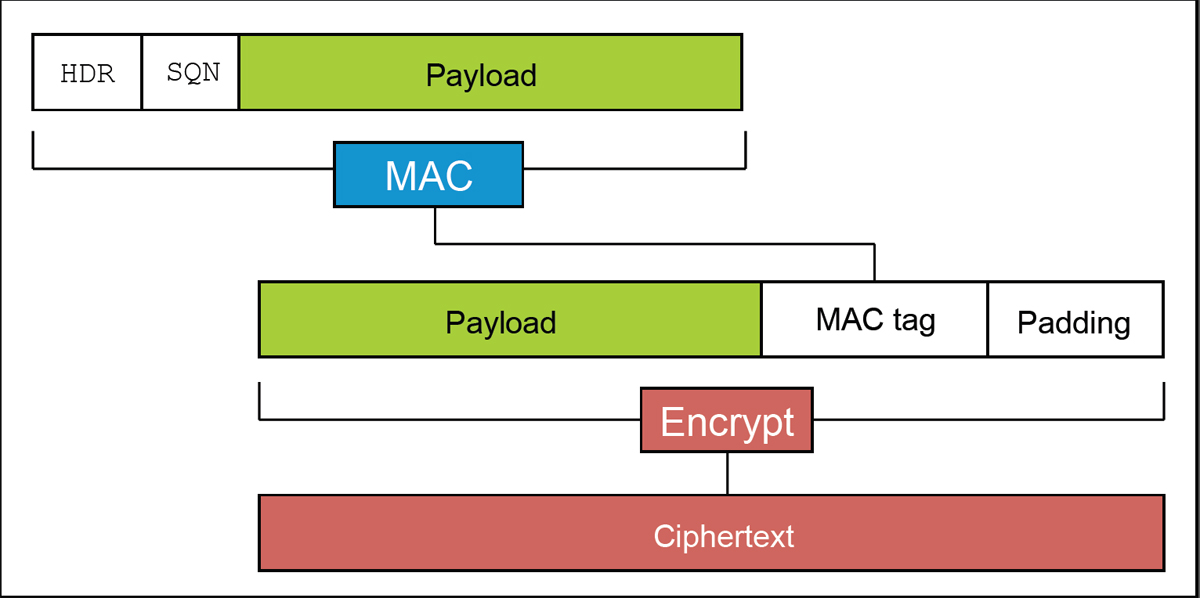
Padding («набивка») состоит из одинаковых байтов, на единицу меньших своей длины:
(0) или (1,1) или (2,2,2) или т.п.Таким образом, получатель шифротекста должен
- расшифровать все его блоки;
- прочитать последний байт последнего блока, чтобы определить длину набивки и, соответственно, позицию MAC в открытом тексте;
- проверить корректность набивки и MAC.
В 2002 г. французский криптограф Серж Воденэ обнаружил в CBC уязвимость к атакам типа «padding oracle»: если перехватить шифротекст (посредством MitM-атаки), изменять последний байт предпоследнего блока, отправлять изменённый шифротекст на сервер, и следить за его ответом — то по разнице между ответами «некорректная набивка» и «некорректный MAC» можно будет за 256 запросов определить последний байт исходного открытого текста. Тогда MitM начинает изменять предпоследний байт предпоследнего блока, и за 256 запросов определяет предпоследний байт открытого текста, и т.д. — по 256 запросов для расшифровки каждого байта.
Практически эту уязвимость можно (было) использовать для воровства HTTPS-кук: злоумышленник направляет пользователя на свою страницу, на которой скрипт от имени пользователя будет один за другим слать HTTPS-запросы на интересующий злоумышленника сервер. Браузер пользователя будет вставлять его куки для этого сервера в каждый запрос, а MitM-сервер, управляемый злоумышленником, будет перехватывать сообщения между пользователем и HTTPS-сервером, менять в них по одному байту в предпоследнем блоке, и следить за реакцией сервера. На расшифровку всех кук таким образом уйдёт меньше минуты.
Казалось бы, для защиты от атаки Воденэ достаточно, чтобы сервер возвращал один и тот же код ошибки при некорректной набивке и при некорректном MAC; но эти два случая всё равно удастся различить по времени до ответа сервера: расчёт и проверка MAC занимают ощутимо больше времени, чем просто проверка набивки в последнем блоке.
Раз не должно быть разницы, набивка или MAC не прошли проверку — то может показаться, что содержимое набивки вообще незачем проверять: если открытый текст не завершается последовательностью из одинаковых байтов, то он заведомо некорректный, так что и MAC с подавляющей вероятностью не совпадёт. Но если злоумышленник подберёт такой размер шифротекста, чтобы последний блок целиком был занят набивкой, и на MitM-сервере будет заменять его на любой предыдущий блок из того же шифротекста — то сервер сообщит об ошибке только в том случае, если последний байт подставленного блока не расшифруется в (длину_блока–1). Получается такой же «padding oracle», только в профиль. Эта атака получила название POODLE. Современные реализации SSL/TLS обязательно проверяют содержимое набивки, и если оно некорректно — то считают набивку отсутствующей, и отправляют на проверку MAC весь результат CBC-расшифровки целиком. В принципе, клиентам это позволяет не пересылать лишний блок, целиком состоящий из набивки, когда открытый текст (вместе с MAC) изначально состоит из целого числа блоков, и при этом не оканчивается на последовательность одинаковых байтов.
После этих исправлений уязвимости «padding oracle» считались устранёнными, пока в 2013 г. пара британских исследователей не изобрели атаку «Lucky 13», в основе которой лежит тот факт, что время расчёта MAC зависит от длины хешируемой строки. Поскольку SHA-1 обрабатывает строку 64-байтными блоками, то злоумышленник может испробовать в качестве двух последних байтов предпоследнего CBC-блока все возможные двухбайтные комбинации, и скачок во времени отклика сервера будет означать переход между 55-байтной хешируемой строкой (один блок SHA-1; в конец хешируемой строки добавляется девятибайтный «трейлер») и 56-байтной (два блока), т.е. между двухбайтной набивкой и однобайтной:

Перехватив и изменив HTTPS-запрос 65536 раз, замеряя каждый раз время отклика сервера, в «стерильных» лабораторных условиях можно восстановить последние два байта открытого текста. На практике же на накопление достаточной статистики для восстановления двух байтов потребуется не одна сотня повторений этой серии из 65536 запросов. Таким образом, атака «Lucky 13» представляла скорее теоретическую опасность.

Своё название эта атака получила из-за того, что размер заголовка, хешируемого перед «полезной нагрузкой», ограничил перебор вариантов набивки двухбайтными последовательностями. Будь этот заголовок 14-байтным или длинее, скачок во времени отклика сервера пришёлся бы на более короткие куски открытого текста, и перебирать бы приходилось в сотни раз больше вариантов набивки. С другой стороны, будь этот заголовок 11-байтным, скачок бы пришёлся на переход между 8 и 9 блоками открытого текста, и атака была бы совершенно невозможна. Ну а самое счастливое число — конечно же, 12: с такой длиной заголовка для атаки было бы достаточно перебирать значения последнего байта самого по себе, как и в атаке Воденэ.
Для защиты от «Lucky 13» разработчики OpenSSL приложили недюжинную смекалку: по сути, во всём коде проверки MAC и набивки нельзя использовать ветвления — иначе время проверки для разных входных данных будет разным! Опуская подробности реализации SHA-1 без ветвления по числу обрабатываемых блоков, сосредоточимся на последнем шаге проверки: сравнение вычисленного значения MAC с фактически записанным в открытом тексте. Чтобы избежать ветвлений, код проверяет весь открытый текст байт за байтом, объединяя по AND разницу между ожидаемым и фактическим значением с «маской MAC» и с «маской набивки», и объединяя по OR результаты проверок всех байтов:
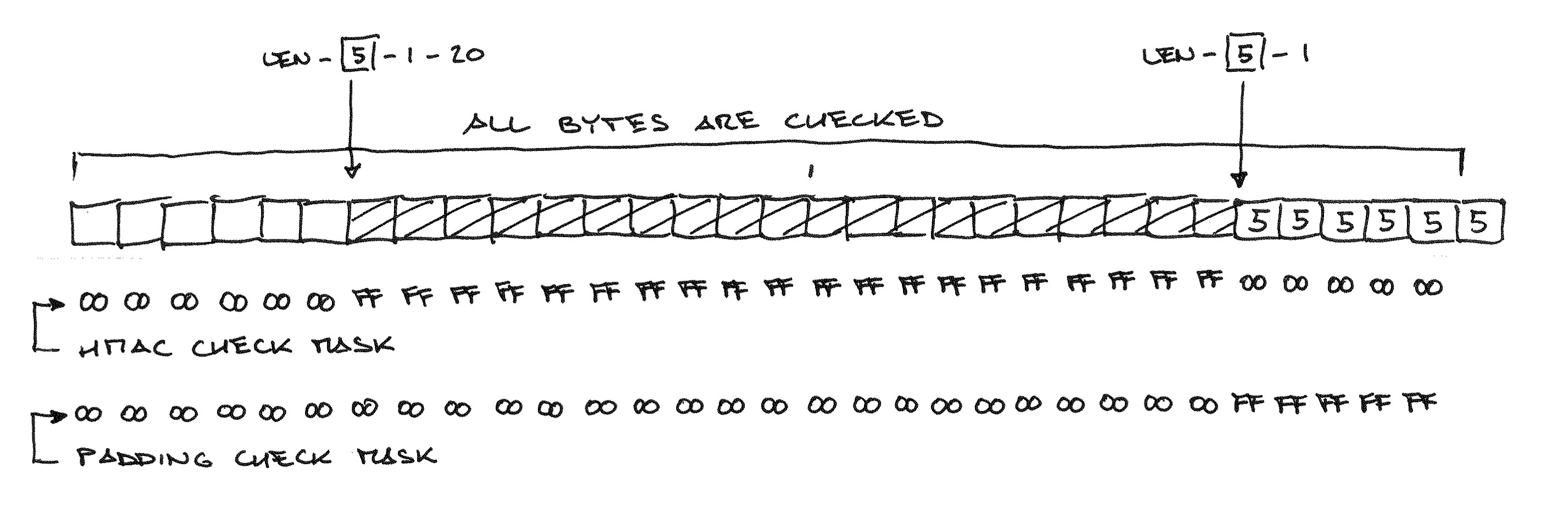
Изображённый 32-байтный открытый текст состоит из шестибайтного сообщения, 20 байтов MAC, и шести байтов набивки. Набивка не может быть длиннее 12 байтов (при пустом сообщении), но в любом случае код должен высчитать MAC и проверить все байты сообщения, прежде чем вернуть код ошибки.
Ну-ка, а что этот код будет делать, если последним байтом открытого текста будет «12» — заведомо невозможная длина набивки?

MAC будет вычисляться для сообщения длины -1!
Не важно, каким получится результат — он заведомо бессмысленный; важнее, что маска проверки MAC «сдвинулась» на один байт за начало сообщения — т.е. от получившегося мусорного значения проверяться будут только 19 байтов.
А что, если сдвинуть маску MAC целиком за начало сообщения?

Теперь на проверку MAC можно не обращать внимания: всё равно все байты разницы будут про-and-ены с нулевой маской! Единственная оставшаяся преграда — проверка содержимого набивки. Все её байты должны быть равны последнему, т.е. 31:
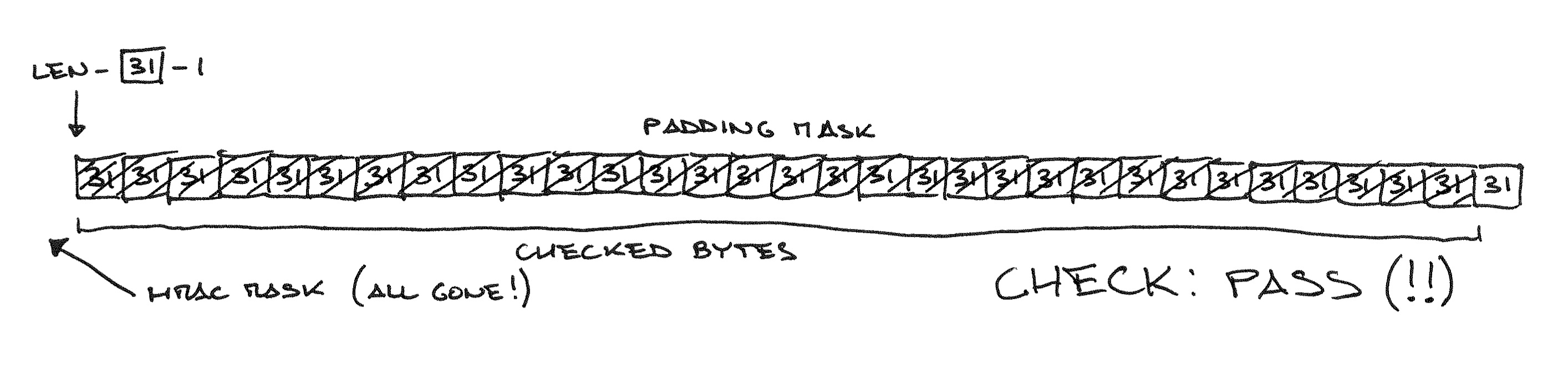
Таким образом злоумышленник может проверять, будет ли открытый текст целиком состоять из байтов со значением (длина_шифротекста–1): в этом случае OpenSSL сочтёт шифротекст корректным, и сервер вернёт ошибку более высокого уровня (например, ошибку HTTP).
Как использовать такой «оракул»? Теперь MitM-сервер должен действовать намного изощрённее, чем при атаке Воденэ. Предположим, скрипт злоумышленника отправил на HTTPS-сервер POST-запрос, оканчивающийся на 31 байт со значением 31. MitM-сервер перехватит шифротекст, возьмёт от него только два последних блока, а в качестве вектора инициализации возьмёт третий с конца блок шифротекста — и будет в нём при каждом запросе менять первый байт:

Из 256 попыток с разными значениями первого байта IV, 255 приведут к ошибке «некорректный MAC или набивка», и одна попытка приведёт к другой ошибке — так мы сможем восстановить 32-ой с конца байт POST-запроса!
Увеличим в POST-запросе длину пути на один байт, а тело запроса укоротим на байт — тогда нам будет известен 31-ый с конца байт запроса. Теперь изменим второй байт IV так, чтобы вторым байтом открытого текста опять получилось 31. Снова будем менять первый байт IV, и снова сможем восстановить 32-ой с конца байт запроса!
Сдвигая таким образом «просвечиваемый байт», MitM сможет расшифровать последние 16 байтов в POST-заголовке, и, если повезёт, HTTPS-куки окажутся среди этих 16 байтов. Скорость расшифровки получается та же самая, что и в оригинальной атаке Воденэ: до 256 запросов на каждый восстанавливаемый байт. Получается, что попутно с защитой от «Lucky 13» в OpenSSL внесли уязвимость, которая намного серьёзнее, чем сама «Lucky 13»!
Техническое замечание: даже если POST-запрос оканчивается на последовательность из байтов 31, перед CBC-шифрованием он будет дополнен MAC и набивкой, так что в описанном виде атака не сработает. Подготовительный этап атаки — варьируя запрашиваемый путь, подобрать такую длину POST-запроса, чтобы MAC и настоящая набивка заняли последние два CBC-блока целиком; затем в ходе атаки эти последние два блока будут отбрасываться, а использоваться будут блоки от пятого до третьего с конца. Наладив такую координацию действий между скриптом, генерирующим HTTPS-запросы, и MitM-сервером, злоумышленник может обеспечить, что результат CBC-расшифровки будет оканчиваться на 31 байт со значением 31.
Подводя итоги: на протяжении 15 лет с обнаружения первого «padding oracle», за каждой попыткой устранения таких «оракулов» следовало обнаружение (или даже нечаянное создание!) новых. Интересно, сколько времени пройдёт до обнаружениия следующего «padding oracle» в TLS с использованием CBC-шифров?
