Недавно мы рассказывали про генератор стихов. Одной из особенностей языковой модели, лежащей в его основе, было использование морфологической разметки для получения лучшей согласованности между словами. Однако же у использованной морфоразметки был один фатальный недостаток: она была получена с помощью “закрытой” модели, недоступной для общего использования. Если точнее, выборка, на которой мы обучались, была размечена моделью, созданной для Диалога-2017 и основанной на закрытых технологиях и словарях ABBYY.
Мне очень хотелось избавить генератор от подобных ограничений. Для этого нужно было построить собственный морфологический анализатор. Сначала я делал его частью генератора, но в итоге он вылился в отдельный проект, который, очевидно, может быть использован не только для генерации стихов.
Вместо морфологического движка ABBYY я использовал широко известный pymorphy2. Что в итоге получилось? Спойлер — получилось неплохо.
Задача
Подозреваю, все в школе занимались морфологическим разбором: определяли, скажем, падеж у существительных, лицо у глаголов и даже пытались различить прилагательные с причастиями. В результате мы получали анализы вроде этого:

Здесь используется нотация разметки Universal Dependencies, которая постепенно становится стандартом в мире компьютерной лингвистики для большинства языков.
Несмотря на то, что морфоанализ — это очень даже школьная задача, научить компьютер решать её не так-то и просто.
Одну из трудностей на данном пути представляет сам наш язык. Он у нас очень омонимичен. Существительные, например, очень часто совпадают в разных падежах: сравните вижу стол и стол стоит. Совпадают формы совершенно разных слов — как, скажем, всем известные "стали" и "стекло". Обычно, видя контекст, совсем не трудно различить их. Собственно, на грамотном использовании контекста и основаны все системы морфологического анализа.
Есть, к сожалению, и ещё одна трудность: отсутствие настоящей стандартизации морфоразметки. У разных систем может быть разное мнение по поводу количества падежей в русском языке или о том, являются ли причастия с деепричастями самостоятельными частями речи или, к примеру, глаголами. Это делает очень трудным сравнение различных морфопарсеров для русского языка, а значит, и выбор самого лучшего.
В этом году на конференции Диалог проводилась дорожка по морфологическому анализу MorphoRuEval-2017, чьей целью было как раз добиться этой стандартизации. Непохоже, что у организаторов получилось полностью достичь своей цели, но они всё-таки выпустили материал для обучения и выборку для сравнения своих результатов с результатами участвовавших в соревновании команд. Поэтому свой морфологический анализатор я сделал, основываясь на результатах этой дорожки, а в особенности на результатах одного из её участников — Даниила Анастасьева, который меня регулярно консультировал.
Я постараюсь кратко описать суть дорожки, за подробными сведениями лучше обращаться к оригинальной статье и материалам.
Постановка задачи в соревновании
Дано предложение. Для каждого слова в предложении нужно определить часть речи и грамматическое значение, а также (это учитывалось отдельно) предсказать лемму слова. Например:
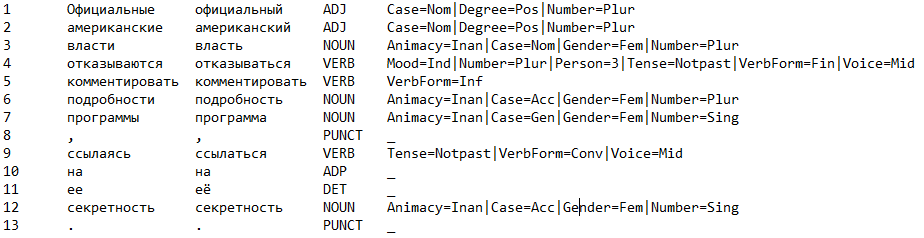
Здесь в первой колонке стоят номера слов, вторая колонка содержит изначальный вариант токена, в третьей — лемма (начальная форма) слова, четвертая колонка — часть речи (NOUN — существительное, VERB — глагол, ADJ — прилагательное и т.д.), последняя колонка — остальная часть грамматического значения, набор реализующихся граммем для подходящих грамматических категорий.
Тут стоит пояснить: для каждой части речи существует набор грамматических категорий, каждая категория — это набор взаимоисключающих граммем. В рамках конкретной словоформы каждая категория может реализоваться единственным образом.
Например, для существительных есть категория числа (Number). Число может быть либо единственным (Sing), либо множественным (Plur). В тексте выше словоформа программы имеет единственное число (но могла бы быть и множественного — потому что омонимия!). Кроме этого она неодушевленная (Animacy=Inan), в родительном падеже (Case=Gen) и женском роде (Gender=Fem).
Таким образом, Animacy, Case, Gender и Number — это те категории, на которые разбивается грамматическое значение существительного, а неодушевленное, родительный падеж, женский род, единственное число — это вектор реализовавшихся для них граммем.
В рамках соревнования предлагалось предсказывать несколько урезанный набор возможных грамматических значений. Всего в качестве предсказываемых было выбрано около 250 значений.
Дорожка была разбита на 2 части: открытую и закрытую. В рамках открытой части разрешалось использовать любые обучающие выборки, в рамках закрытой только предоставленные организаторами (при этом, насколько я понимаю, использование внешних словарей было разрешено и в рамках закрытой части).
Даниил участвовал только в открытом треке, потому что использовал внутренний корпус компании.
Данные
В качестве размеченных корпусов для обучения организаторы предлагали следующие:
- ГИКРЯ UD — примерно 1 миллион токенов
- НКРЯ UD — примерно 1,2 миллиона слов
- Открытый корпус UD — примерно 400 тысяч токенов
- SynTagRus — примерно 900 тысяч токенов
Тестирование проводилось на подвыборках из разножанровых корпусов:
- корпуса новостей (из Lenta)
- корпуса художественной литературы
- корпуса текстов из VK
Размеченные корпуса довольно значительно отличаются друг от друга. Связано это прежде всего с ошибками конвертации и спецификой разметок: уже упомянутую несогласованность разметок пытались решить автоматической обработкой корпусов, но полностью свести их к одному формату не сумели. В результате, на самом конкурсе участники использовали только корпус ГИКРЯ для обучения, потому что добавление других лишь снижало качество. Кроме того, в самих корпусах встречаются ошибки (заметил я это, пока делал анализ ошибок своего алгоритма). Пример:

Результаты дорожки
Всего участвовало 11 команд в закрытом треке и 5 в открытом. Итоговые результаты выложены в отдельной таблице. Считалась точность по грамматическим значениям отдельных токенов, точность сразу по полным предложениям, точность с учётом лемматизации по токенам, точность с учётом лемматизации по предложениям.
Я взял за основу модель, которая заняла первое место в открытом треке. Было предположение, что дело не только в корпусе ABBYY и корпоративной морфологии, которое позже оправдалось сполна.
Базовая модель
Anastasyev D. G., Andrianov A. I., Indenbom E. M., Part-of-speech Tagging with Rich Language Description
Для слова использовались следующие признаки:
эмбеддинг (embedding) слова
- вектор грамматических значений
- вектор с вероятностями классов
- наличие пунктуации в контексте на конкретных позициях
- капитализация
- наличие частотных суффиксов
Самое полезное тут — вектор грамматических значений (и для него как раз и нужны были корпоративные словари). Вектора грамматических значений получались из вероятностей каждого возможного грамматического анализа. Вероятности эти — просто вероятности словоформ, подсчитанные по размеченным корпусам. В ABBYY они оцениваются по огромным корпусам, размеченным с помощью Компрено.
Из нескольких векторов грамматических значений с разными вероятностями один получается следующим образом: считаются вероятности каждой граммемы в отдельности и нормируются на суммарную вероятность для категории. Например, для слова стул вероятность формы именительного падежа равна 1.03·10^(−6), а винительного — 8.15·10^(−7). Тогда в общем векторе в ячейке, которая соответствует винительному падежу будет записано 8.15·10^(−7) / (8.15·10^(−7) + 1.03·10^(−6)) = 0.4417.
Эмбеддинги слов брались непредобученные, равномерно инициализированные — использование предобученных не дало увеличения точности.
Сама нейросеть — двухуровневый двунаправленный LSTM с дополнительным полносвязным слоем:

Достаточно оригинальным в этой работе является предобучение на большом внутреннем корпусе компании с разметкой, несоответствующей разметке соревнования, потом дообучение на сравнительно небольшом корпусе ГИКРЯ. Это чем-то напоминает стандартные методы решения большого класса задач в анализе изображений: берём сеть, обученную на ImageNet, и дообучаем на нашей выборке.
Моё решение
pymoprhy2
Прежде всего, мне нужна была замена корпоративного анализатора, которая выдавала бы возможные варианты разборов словоформ. Под Python было не так много вариантов, да и к тому же на основе pymorphy2 уже было решение, которое по неизвестным мне причинам в соревнование не попало. CRF baseline оттуда на проверку оказался лучше, чем почти все решения с дорожки.
Модель
Изначально из признаков я оставлял словные эмбеддинги и векторы грамматических значения. В моей модели векторы собираются уже на основе вариантов, которые возвращает pymorphy2. Архитектура модели была ровно такая же, как и оригинальная. Получалось порядка 94% на бенчмарке, что довольно неплохо, учитывая, что я использовал куда меньшее количество весов.
Не удовлетворившись качеством получившихся результатов, я начал думать, как бы, во-первых, ужать модель, чтобы она весила меньше и работала чуть быстрее, а во-вторых, как аккуратно учитывать информацию с символьного уровня. В одной из статей я увидел решение обеих проблем сразу — делать LSTM RNN над символьным уровнем отдельных слов, а выход этих сеток на словами использовать как часть входного вектора для основной двухслойной сети. Тестирование показало, что символьное представление даже выигрывает у словных эмбеддингов.

Что касается лемматизации, я не стал изобретать свой велосипед. Среди вариантов, выдаваемых pymorphy2, выбирается лемма того, который лучше всего совпадает по граммемам. Если таких вообще нет — сойдёт и совпадение по части речи. Если и по части речи ничего не совпадает, просто берём лемму самого частотного разбора.
Чтобы получить хорошее качество на данных соревнование, однако, пришлось добавить ещё дополнительную логику обработки лемм. Например, начальная форма причастий определяется в корпусе и в pymorphy2 по-разному.
Результаты моей модели на тестовой выборке представлены ниже.
Новости:
- Качество по тегам:
- 3999 меток из 4179, точность 95.69%
- 264 предложений из 358, точность 73.74%
- Качество полного разбора:
- 3865 слов из 4179, точность 92.49%
- 180 предложений из 358, точность 50.28%
VK:
- Качество по тегам:
- 3674 меток из 3877, точность 94.76%
- 418 предложений из 568, точность 73.59%
- Качество полного разбора:
- 3551 слов из 3877, точность 91.59%
- 341 предложений из 568, точность 60.04%
Худ. литература:
- Качество по тегам:
- 3879 меток из 4042, точность 95.97%
- 288 предложений из 394, точность 73.10%
- Качество полного разбора:
- 3659 слов из 4042, точность 90.52%
- 172 предложений из 394, точность 43.65%
Если посмотреть в таблицу результатов, то можно увидеть, что моя модель обходит все остальные модели с закрытой дорожки по качеству определения тегов, причём с запасом, но уступает некоторым по качеству лемматизации.
На предложениях с синтаксической омонимией, типа “Косил косой косой косой”, модель честно лажает. Причём лажает нестабильно, на разных этапах обучения (короткие-средние-длинные предложения) по-разному.
К сожалению, в рамках дорожки не было никаких бенчмарков по скорости работы. Если бы такие были, моя модель, вероятно, довольно сильно проседала. На моём домашнем ноуте она обрабатывает примерно от 100 до 500 слов в секунду, что для промышленного решения, конечно, не сгодится. Наши же нужды по разметке текста для генератора стихов это полностью удовлетворяет.
Что касается занимаемого места, вся модель весит около 3Мб, так что она даже включена в состав PyPi пакета. Здесь я доволен.
Есть предположение, что дообучение на других корпусах может немного увеличить качество модели, как и увеличение количества весов. Но, опять же, меня в целом устраивает текущая версия.
Примеры работы
Удачные разборы




Неудачные разборы


Ссылки
- Репозиторий
- Пакет в pypi
- MorphoRuEval-2017: an Evaluation Track for the Automatic Morphological Analysis Methods for Russian
- Part-of-speech Tagging with Rich Language Description
- Do LSTMs really work so well for PoS tagging? – A replication study
- Multilingual Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Models and Auxiliary Loss
Пост был написан совместно с Даниилом Анастасьевым(@DanAnastasyev). Большое спасибо Наде Карацаповой за вычитку статьи.
