Продолжение цикла обзорных статей с конференции CppCon 2017.
- Бьёрн Страуструп: Изучение и преподавание современного C++
- Ларс Кнолл: C++ фреймворк Qt: История, Настоящее и Будущее
- Herb Sutter: Метапрограммирование и кодогенерация в C++
- Matt Godbolt: Что мой компилятор сделал для меня?
На этот раз очень интересное выступление от автора Compiler Explorer (godbolt.org). Обязательно читать всем, кто для быстроты умножает на 2 с помощью сдвига (по крайней мере, на x86-64). Если вы знакомы с ассемблером x86-64, то можете перемотать до разделов с примерами ("Умножение", "Деление" и т.д). Далее слова автора. Мои комментарии в квадратных скобках курсивом.
Моя цель сделать так, чтобы вы не боялись ассемблер, это полезная вещь. И использовали его. Не обязательно все время. И я не говорю, что вы должны все бросить и учить ассемблер. Но вы должны уметь просмотреть результат работы компилятора. И когда вы это сделаете, то оцените, как много работы проделал компилятор, и какой он умный.
Предыстория
Итак, есть классический способ суммирования (до C++11):
int sum(const vector<int> &v)
{
int result = 0;
for (size_t i = 0; i < v.size(); ++i)
result += v[i];
return result;
}С появлением Range-For-Loop мы задумались, можем ли мы заменить его на более приятный код:
int sum(const vector<int> &v)
{
int result = 0;
for (int x : v) result += x;
return result;
}Наши опасения были связаны с тем, что мы уже были "покусаны" итераторами в других языках. У нас был опыт итерирования контейнеров при котором конструировались итераторы, что добавляло работы сборщику мусора. Мы знали, что в C++ такого нет, но должны были проверить.
Предупреждение
Чтение ассемблерного кода: можно легко ввести в себя в заблуждение, если думать, что вы можете видеть что здесь происходит, что это работает быстрее того из-за меньшего количества инструкций. В современном процессоре происходят очень сложные вещи и вы не сможете предсказать. Если вы делаете предсказания производительности, то всегда запускайте бенчмарки. Например от Google или интерактивный онлайновый http://quick-bench.com.
Основы ассемблера x86-64
Регистры
- 16 целочисленных 64-битных регистра общего назначения (RAX, RBX, RCX, RDX, RBP, RSI, RDI, RSP, R8 — R15)
- 8 80-битных регистров с плавающей точкой (ST0 — ST7)
- 16 128-битных регистров SSE (XMM0 — XMM15)
Существуют соглашения вызова функций ABI, это то, как функции "общаются" друг с другом, в частности:
- rdi, rsi, rdx — аргументы
- rax — возвращаемое значение
Также существуют правила, которые говорят, какие регистры вы можете перезаписать, какие сохранить. Но если вы не пишете на ассемблере, то знать их не обязательно.
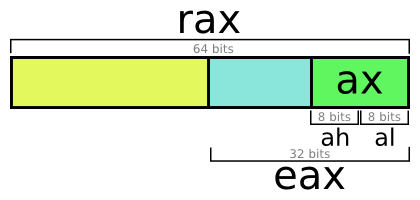
Регистры общего назначения 64-битные, но имеют различные имена. Например, обратившись к регистру eax, мы получим нижние 32 бита регистра rax. Но по сложным причинам запись в eax приведет к обнулению верхних 32 бит rax (почему). Это не относится к ax, ah, al.
Операции
Я использую синтакс Intel. Кто в зале использует синтакс Intel? А AT&T? О, кажется сегодня я наделал себе врагов.
Виды операций (синтаксис Intel):
op
op dest
op dest, src
op dest, src1 src2Примеры мнемокодов (op): call, ret, add, sub, cmp. Операндами (dest, src) могут являться регистры или ссылки на память вида:
[base + reg1 + reg2 * (1, 2, 4 or 8)]Ссылка на память редко бывает абсолютным значением. Мы можем использовать значение регистра, а также добавить некоторое смещение, задаваемым значением другого регистра.
Рассмотрим пример:
mov eax, DWORD PTR [r14]
add rax, rdi
add eax, DWORD PTR [r14+4]
sub eax, DWORD PTR [r14+4*rbx]
lea rax, [r14+4*rbx]
xor edx, edxЕго псевдокод:
int eax = *r14; // int *r14;
rax += rdi;
eax += r14[1];
eax -= r14[rbx];
int *rax = &r14[rbx];
edx = 0;Разберем по строкам:
- Чтение 4 байт из регистра r14 и помещение в eax.
- Добавление значения rdi к rax.
- Добавление 4-байтного значения, хранящегося по адресу r14 + 4, к eax. Такое обращение к памяти — аналог получения первого (если считать от нулевого) значения массива, если r14 — указатель на начало массива 4-байтных чисел.
- Аналогично предыдущему, но можно менять индекс массива.
- Команда lea используется для загрузки эффективного адреса. [Примерно как
mov rax, r14+4*rbx, если так было бы можно писать.] - Вот такой странный способ обнуления. Дело в том, что
mov edx, 0занимает 4 байта, аxor edx, edx— 2.
Compiler Explorer v0.1
Сначала, чтобы изучать работу компилятора, я делал следующее. Компилировал командой:
$ g++ /tmp/test.cc -O2 -c -S -o - -masm=intel \
| c++filt \
| grep -vE '\s+\.'Объяснение:
- Запуск
g++:
- компиляция test.cc
- с включенной оптимизацией (-O2)
- без вызова линковщика (-c)
- с генерацией ассемблерного листинга (-S)
- с выводом в стандартный поток (-o -)
- с использованием нотации Intel (-masm=intel)
c++filt— утилита декодирования имен (demangling).grep -vE '\s+\.'— удаление всех забавных строк.
Эту команду запускал с некоторым интервалом с помощью утилиты watch, у которой выставлял флаг -d (diff) для отображения различий. Затем просто разделил терминал пополам с помощью tmux, разместил скрипт в одном, vi в другом. И таким образом получил Compiler Explorer.
Compiler Explorer
Теперь вкратце о современной версии Compiler Explorer. Чтобы создать новое окошко с кодом нужно щелкнуть по пункту "Editor" и удерживая перетащить куда нужно. Для создания окошка с результатом компиляции нужно щелкнуть по кнопке со стрелкой вверх и удерживая перетащить. Если я наведу курсор на желтую строку, то соответствующие строки в ассемблерной части станут жирнее.
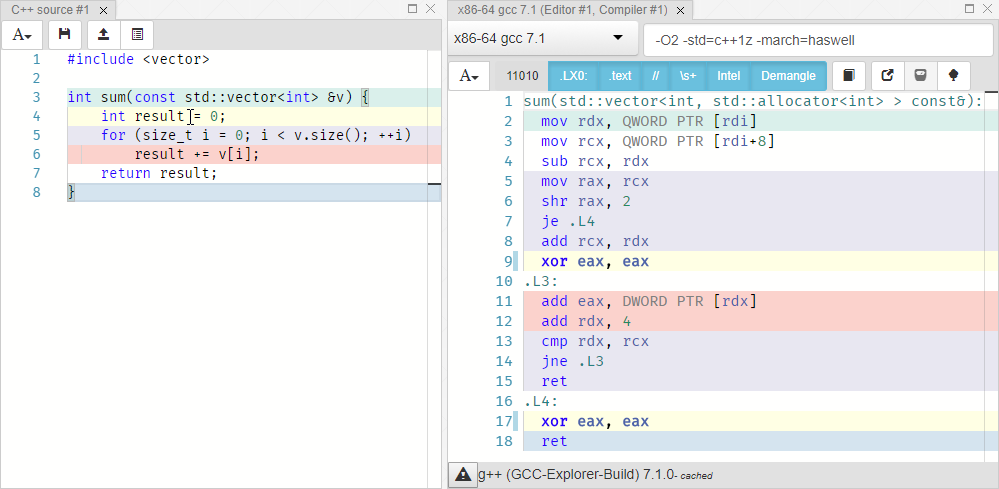
Я выбрал GCC 7.1 с аргументами -O2 -std=c++1z -march=haswell. Мы видим, что int result = 0; соответствует xor eax eax. Регистр rdx содержит указатель на текущий элемент вектора. Аккумулирование result += x; реализовано как увеличение значения регистра eax на величину, расположенную по адресу в rdx, с последующим переходом к следующему элементу массива. Строка return result; не выделена цветом, что означает, что для нее нет явного соответствия. Это происходит потому что после завершения цикла регистр eax (который часто используется для хранения возвращаемого значения) уже содержит значение. С оптимизацией компилятор сделал в точности то, что мы и просили.
Теперь я покажу результат компиляции без оптимизации (-O0).
Если компилировать с -O1, то GCC почему то не считает нужным использовать xor eax, eax вместо mov eax, 0.
Поменяем на -O3. Это поразительно, только взгляните:

Офигенно, использованы все эти крутые операции! Но нужно использовать бенчмарки, чтобы убедиться, что такой код быстрее простой версии.
Вернемся к нашему примеру:
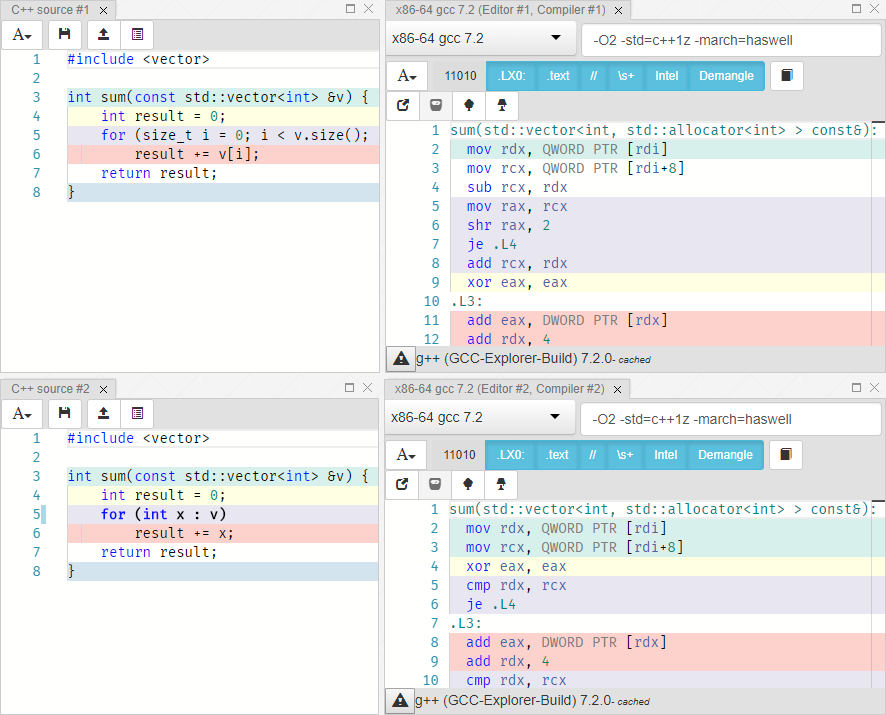
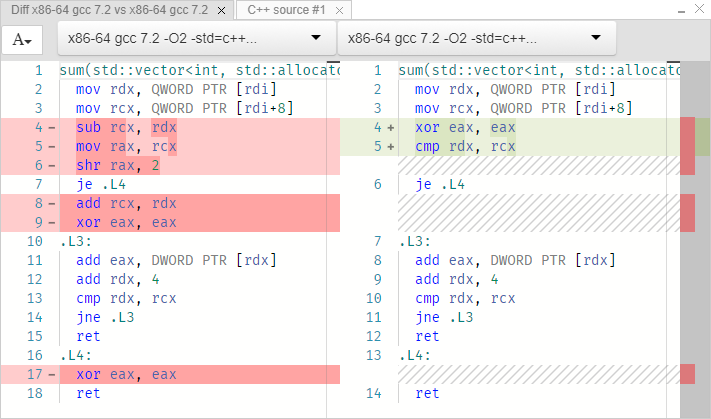
Слева цикл от 0 до size, справа range for. Код, реализующий циклы, идентичен в обоих случаях. Попробуем такой способ:
int sum(const vector<int> &v) {
return std::accumulate(std::begin(v), std::end(v), 0);
}То же самое.
Подробный разбор
Начнем с первых двух строк:
; rdi = const vector<int> *
mov rdx, QWORD PTR [rdi] ; rdx = *rdi ≡ begin()
mov rcx, QWORD PTR [rdi+8] ; rcx = *(rdi+8) ≡ end()Мы передавали вектор по ссылке. Но здесь нет такой штуки как ссылка. Только указатели. Регистр rdi указывает на переданный вектор. Производится чтение значений по адресам rdi и rdi + 8. Ошибочно думать, что rdi — это указатель непосредственно на массив int-ов. Это указатель на вектор. По крайней мере в GCC реализация вектора такая:
template<typename T> struct _Vector_impl {
T *_M_start;
T *_M_finish;
T *_M_end_of_storage;
};То есть, вектор — это структура, содержащая три указателя. Первый указатель — начало массива, второй — конец, третий — конец зарезервированной памяти (allocated) для этого вектора. Здесь явно не хранится размер массива. Это интересно. Посмотрим на различия в реализациях до начала цикла. Первый пример (обычный цикл с индексом):
sub rcx, rdx ; rcx = end-begin
mov rax, rcx
shr rax, 2 ; (end-begin)/4
je .L4
add rcx, rdx
xor eax, eaxВ первой строчке вычисляется количество байт массива. В третьей это значение делится на 4, чтобы найти количество элементов (так как int — 4-байтовый). То есть это просто функция size:
size_t size() const noexcept {
return _M_finish - _M_start;
}Если получили размер 0 после операции сдвига, то выставляется Equal Flag и срабатывает операция перехода je (Jump If Equal), и программа возвращает 0. Таким образом осуществилась проверка равенства размера нулю. Далее, мы предполагаем, что во время итераций будет осуществляться проверка индекса с размером. Но компилятор догадывается, что фактически нам этот индекс и не нужен, и в цикле он будет сравнивать текущий указатель на элемент массива с концом массива (rcx).
Теперь второй пример (с range for):
xor eax, eax
cmp rdx, rcx ; begin==end?
je .L4Здесь просто сравнивается, равен ли начальный указатель конечному, и если да, то прыжок в конец программы. Фактически, произошло это:
auto __begin = begin(v);
auto __end = end(v);
for (auto __it = __begin; __it != __end; ++it)Сам цикл идентичен в обоих случаях:
; rcx ≡ end, rdx = begin, eax = 0
.L3:
add eax, DWORD PTR [rdx] ; eax += *rdx
add rdx, 4 ; rdx += sizeof(int)
cmp rdx, rcx ; is rdx == end?
jne .L3 ; if not, loop
ret ; we're doneМы выяснили:
- Range-for оказался немного более предпочтительным вариантом.
- Опции компилятора имеют большое значение.
- std::accumulate показывает такой же результат.
Умножение
Далее я покажу маленькие, но классные примеры.
int mulByY(int x, int y) {
return x * y;
}mulByY(int, int):
mov eax, edi
imul eax, esi
retedi — первый параметр, esi — второй. Обычное умножение с помощью imul. Вот так выглядит 4-битовое перемножение вручную:
1101 (13)
x 0101 (5)
--------
1101
0000
1101
+ 0000
--------
01000001 (65)Нам пришлось выполнить 4 сложения. Это чудо, что на Haswell 32-битное перемножение осуществляется всего за 4 такта. Сложение за 1 такт. Но посмотрим примеры в которых еще быстрее:
int mulByConstant(int x)
{
return x * 2;
}Вы можете ожидать, что произойдет сдвиг влево на 1. Проверим:
lea eax, [rdi+rdi]Одна операция. Преимущество lea в том, что можно очень гибко задавать источник. Для реализации с помощью сдвига пришлось бы делать 2 операции: копировать значение в eax и сдвигать.
int mulByConstant(int x)
{
return x * 4;
}lea eax, [0+rdi*4]lea поддерживает умножение на 2, 4, 8. Поэтому, умножение на 8 будет аналогичным:
lea eax, [0+rdi*8]На 16 уже со сдвигом:
mov eax, edi
sal eax, 4На 65599:
imul eax, edi, 65599Ага, эти разработчики компиляторов не такие уж умные, какими они себя считают. Я могу реализовать эффективнее:
int mulBy65599(int a) {
return (a << 16) + (a << 6) - a;
// ^ ^
// a * 65536 |
// a * 64
// 65536a + 64a - 1a = 65599a
}Проверяем:
imul eax, edi, 65599Оу! [Cмех в зале, аплодисменты]. Это что получается, компилятор умнее меня? Да, действительно, умножение эффективнее этих нескольких сдвигов и сложений. Но это на современных процессорах. Вернемся в прошлое -O2 -std=c++1z -march=i486 -m32:
mov edx, DWORD PTR [esp+4]
mov eax, edx
sal eax, 16
mov ecx, edx
sal ecx, 6
add eax, ecx
sub eax, edxНу-ка, вернем обратно return a * 65599;:
mov edx, DWORD PTR [esp+4]
mov eax, edx
sal eax, 16
mov ecx, edx
sal ecx, 6
add eax, ecx
sub eax, edxПозвольте компилятору делать все эти подобные вещи за вас.
Деление
В общем случае:
int divByY(int x, int y) {
return x / y;
}divByY(int, int):
mov eax, edi
cdq
idiv esi
retНа Haswell 32-битовое деление выполняется за 22-29 циклов. Можем ли мы сделать лучше?
unsigned divByConstant(unsigned x)
{
return x / 2;
}mov eax, edi
shr eaxНикакой магии, просто сдвиг вправо. Также никаких сюрпризов, если будем делить на 4, 8, 16 и т. д. Попробуем на 3:
mov eax, edi
mov edx, -1431655765
mul edx
mov eax, edx
shr eaxЧто произошло?
mov eax, edi ; eax = x
mov edx, 0xaaaaaaab
mul edx ; eax:edx = x * 0xaaaaaaab
mov eax, edx ; (x * 0xaaaaaaab) >> 32
; ≡ (x * 0xaaaaaaab) / 0x10000000
; ≡ x * 0.6666666667
shr eax ; x * 0.333333333
retЗначение, равное 2/3*x оказалось в edx — старших 32 битах 64-разрядного результата умножения. То есть, фактически, произошло умножение на 2/3 и сдвиг на 1 вправо. [Если не очень понятно, то поумножайте в каком-нибудь hex-калькуляторе 0xaaaaaaab на 3, 4, 5, 6… и понаблюдайте за старшими разрядами].
Остаток от деления
В общем случае:
int modByY(int x, int y) {
return x % y;
}modByY(int, int):
mov eax, edi
cdq
idiv esi
mov eax, edx
retВ частности, остаток от деления на 3:
int modBy3(unsigned x)
{
return x % 3;
}mov eax, edi
mov edx, 0xaaaaaaab
mul edx
mov eax, edx
shr eax
lea eax, [rax+rax*2]
sub edi, eax
mov eax, ediПервые 5 строчек — уже рассмотренное деление. А в следующих результат деления умножается на 3 и вычитается из исходного значения. То есть, x-3*[x/3]. Почему я уделяю внимание делению по модулю? Потому что оно используется в hash-map — любимом всеми контейнере. Для нахождения или добавления объекта в контейнер вычисляется остаток от деления хеша на размер хеш-таблицы. Этот остаток является индексом элемента таблицы (bucket). Очень важно, чтобы эта операция работала как можно быстрее. В общем случае она работает довольно долго. Поэтому, libc++ использует степени двойки для допустимых размеров таблиц. Но это не очень удачные значения. Реализация Boost multi_index содержит множество допустимых размеров, и switch с их перечислением.
[Судя по вопросу из зала, не все поняли это объяснение. Грубо говоря, такая реализация:]
switch(size_index):
{
case 0: return x % 53;
case 1: return x % 97;
case 2: return x % 193;
...
}Подсчет битов
Следующая функция осуществляет подсчет единичных битов:
int countSetBits(int a) {
int count = 0;
while (a) {
count++;
a &= (a-1);
}
return count;
}На каждой итерации у числа пропадает самая младшая единичка, пока все число не превратится ноль. GCC сделал умно:
countSetBits(int):
xor eax, eax
test edi, edi
je .L4
.L3:
add eax, 1
blsr edi, edi
test edi, edi
jne .L3
ret
.L4:
retЗдесь выражение a &= (a-1); заменено инструкцией blsr. Я никогда не видел ее раньше до подготовки к этому выступлению. Она очищает последнюю единицу и помещает результат в указанный регистр. Попробуем выбрать другой компилятор — x86-64 clang (trunk):
popcnt eax, ediЭта инструкцию, осуществляющую подсчет бит, которую народ так хотел, что intel добавил ее. Только подумайте, что clang должен быть выполнить. Для него не было никаких подсказок "я хочу посчитать биты".
Сложение
Сложение всех целых чисел от 0 до x включительно:
constexpr int sumTo(int x) {
int sum = 0;
for (int i = 0; i <= x; ++i)
sum += i;
return sum;
}
int main(int argc, const char *argv[]) {
return sumTo(20);
}mov eax, 210Ок, понятно! Здесь constexpr не так важен. Если заменить его на static [чтобы функция была видна только в одной единице трансляции], то получим такой же результат. Если вызвать sumTo(argc), то цикл никуда не денется. Попробуем clang:
test edi, edi
js .LBB0_1
mov ecx, edi
lea eax, [rdi - 1]
imul rax, rcx
shr rax
add eax, edi
ret
.LBB0_1:
xor eax, eax
retИнтересно, цикл пропал. В первых двух строчках проверка аргумента на ноль. В следующих 5 просто формула суммы: x(x+1)/2 == x + x(x-1)/2. Реализован второй вариант формулы, потому что первый вариант вызовет переполнение, если передать INT_MAX.
Как работает Compiler Explorer
[Я совсем не разбираюсь с Frontend, Docker, виртуализацией и прочим, о чем рассказывал автор, поэтому решил не описывать все тонкости реализации, чтобы не ляпнуть глупость]
Написан на node.js. Запущено на Amazon EC2. Это второе мое выступление на этой конференции, в которой я говорю про JavaScript и чувствую себя так плохо. Конечно, мы иногда ругаем C++… но если только взглянуть на JavaScript, ох...
Все это выглядит примерно так:
function compile(req, res, next) {
// exec compiler, feed it req.body, parse output
}
var webServer = express();
var apiHandler = express.Router();
apiHandler.param('compiler',
function (req, res, next, compiler) {
req.compiler = compiler;
next();
});
apiHandler.post('/compiler/:compiler/compile', compile);
webServer.use('/api', apiHandler);
webServer.listen(10240);Amazon EC2
Следующие фичи:
- Edge cache
- Load balancer
- Virtual Machines
- Docker images
- Shared compiler storage
Компиляторы
Я установил их с помощью apt-get. Компиляторы от Microsoft работают через WINE.
Безопасность
Огромная дыра в безопасности. Хотя компиляторы только компилируют, а не запускают, GCC, например, поддерживает плагины, и можно подгрузить динамическую библиотеку (-fplugin=/path/to/name.so). Или specs-файлы. Сначала я старался найти возможные уязвимости, но пришел к заключению, что очень трудно учесть всё. И я стал размышлять, что же самое худшее, что может случиться? Можно остановить docker-контейнер, но он запустится опять. Даже если выбраться за его пределы в виртуальную машину, то не будет привилегий. Docker защищает меня от подобных трюков.
Frontend
В качестве онлайн редактора кода используется Microsoft Monaco. Drag-drop для окошек реализован с помощью GoldenLayout.
Исходники
Скоро
- CFG — control graph viewer [Я так понял, как в IDA].
- Унификация языков. Compiler Explorer поддерживает другие языки ({d, swift, haskell, go, ispc}.godbolt.org). Хотелось бы их объединить в одном месте, а не по разным доменам. Чтобы можно было сравнивать реализацию одного и того же на разных языках.
- Запуск кода!
Вопросы
Хотелось бы видеть поддержку других библиотек, например Boost.
Некоторые уже есть:
Вы говорили про switch для всех возможных размеров таблиц в Boost multi_index. Но такая реализация неэффективна — так как значения сильно разрежены, то не получится использовать jump table, а только бинарный поиск.
В switch перечислены не сами размеры, а их индексы.
Планируется ли поддержка Web assembly
Есть много компиляторов, которые не имеют backends для webassembly. Ну да, неплохо бы, но пока занят другими вещами.
Сколько это стоит?
Я трачу примерно 120-150$ в месяц на сервера Амазона.
Планируется ли поддержка llvm intermediate representation?
Да, уже есть, если запускать с флагом -emit-llvm. Компилятор сам выдает этот дамп, я ничего не делаю. Планируется улучшенная подсветка.
Как вы подкрашиваете соответствующие строки исходного кода и ассемблерного?
Просто запускаю с флагом "-g". Получающийся листинг имеет комментарии с номерами строк.
