Это история о том, как мы c mildly_parallel замедляли ускоряли расчеты на самом мощном суперкомпьютере в мире.

В апреле этого года наша команда приняла участие в финале Asia supercomputer challenge 2017, одним из заданий которого было ускорение программы для моделирования океанских волн Masnum-Wave на китайском суперкомпьютере Sunway TaihuLight.
Все началось с отборочного тура в феврале: мы получили доступ к суперкомпьютеру и познакомились с нашим новым другом на ближайшие пару месяцев.
Вычислительные узлы выставлены в форме двух овалов, между которыми стоит сетевое железо. В узлах используются процессоры Shenwei 26010. Каждый из них состоит из 4 гетерогенных процессорных групп, которые включают одно управляющее и 64 вычислительных ядра с тактовой частотой 1,45 ГГц и размером локального кэша 64 Кб.

Охлаждается все это с помощью водяной системы, расположенной в отдельном здании.
Из ПО в нашем распоряжении были компиляторы фортрана и си с “поддержкой” OpenACC 2 и athreads (аналог POSIX Threads) и планировщик задач, совмещающий в себе одновременно возможности обычного планировщика и mpirun.
Доступ к кластеру осуществлялся через особый VPN, плагины для работы с которым были доступны только для Windows и Mac OS. Все это добавляло особенного шарма при работе.
Заданием было ускорение Masnum-Wave на этом суперкомпьютере. Нам предоставили исходный код Masnum-Wave, несколько крохотных readme файлов с описанием основ работы на кластере и данные для замера ускорения.
Masnum-Wave – это программа для моделирования движения волн по всему земному шару. Она написана на Фортране с использованием MPI. В двух словах, она итеративно выполняет следующее: читает данные функций внешнего воздействия, синхронизирует граничные области между MPI-процессами, вычисляет продвижение волн и сохраняет результаты. Нам дали workload на 8 модельных месяцев с шагом по 7.5 минуты.
В первый же день мы нашли в интернете статью: “The Sunway TaihuLight supercomputer:
system and applications, Haohuan Fu” с описанием ускорения Masnum-Wave на архитектуре Sunway TaihuLight с помощью конвейерной обработки. Авторы статьи использовали всю мощь кластера (10649600 ядер), в нашем же распоряжении было 64 вычислительных группы (4160 ядер).
Masnum-Wave состоит из нескольких модулей:
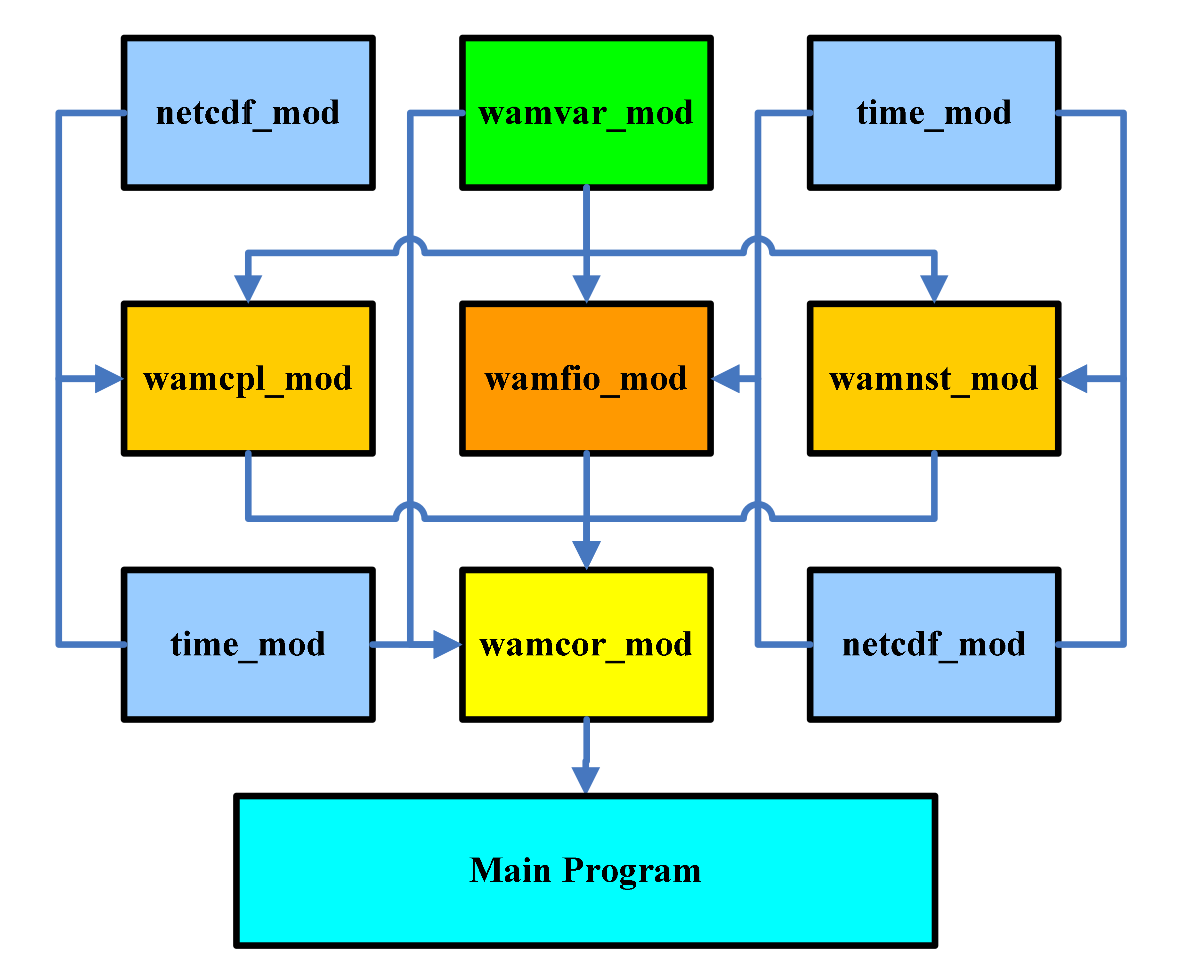
Мы впервые столкнулись с таким большим количеством кода, порожденного наукой. Так как код представляет собой смесь двух версий фортрана 90 и 77, это порой ломало работу их собственного компилятора. В большом количестве там встречаются чудесные конструкции goto, куски закомментированного кода и, конечно же, комментарии на китайском.
Сокращенный пример кода для наглядности:
do 1201 j=1,jl
js=j
j11=jp1(mr,j)
j12=jp2(mr,j)
j21=jm1(mr,j)
j22=jm2(mr,j)
!****************************************************************
! do 1202 ia=ix1,ix2
! do 1202 ic=iy1,iy2
eij=e(ks,js,ia,ic)
!if (eij.lt.1.e-20) goto 1201
if (eij.lt.1.e-20) cycle
ea1=e(kp ,j11,ia,ic)
ea2=e(kp ,j12,ia,ic)
! ...
eij2=eij**2
zua=2.*eij/al31
ead1=sap/al11+sam/al21
ead2=-2.*sap*sam/al31
! fcen=fcnss(k,ia,ic)*enh(ia,ic)
fcen=fconst0(k,ia,ic)*enh(ia,ic)
ad=cwks17*(eij2*ead1+ead2*eij)*fcen
adp=ad/al13
adm=ad/al23
delad =cwks17*(eij*2.*ead1+ead2) *fcen
deladp=cwks17*(eij2/al11-zua*sam)*fcen/al13
deladm=cwks17*(eij2/al21-zua*sap)*fcen/al23
!* nonlinear transfer
se(ks ,js )= se(ks ,js )-2.0*ad
se(kp2,j11)= se(kp2,j11)+adp*wp11
se(kp2,j12)= se(kp2,j12)+adp*wp12
se(kp3,j11)= se(kp3,j11)+adp*wp21
se(kp3,j12)= se(kp3,j12)+adp*wp22
se(im ,j21)= se(im ,j21)+adm*wm11
se(im ,j22)= se(im ,j22)+adm*wm12
se(im1,j21)= se(im1,j21)+adm*wm21
se(im1,j22)= se(im1,j22)+adm*wm22
!...
! 1202 continue
! 1212 continue
1201 continueПрежде всего мы с помощью вывода времени выполнения каждой функции определили узкие места в коде и кандидатов для оптимизации. Наибольший интерес у нас вызвал модуль warcor, отвечающий за численное решение модельного уравнения и функции записи контрольных точек.
Изучив скудную документацию к китайским компиляторам, мы решили использовать OpenACC, так как это стандарт от Nvidia с примерами и спецификацией. К тому же, код из readme к athreads казался нам неоправданно сложным и просто не компилировался. Как же мы ошибались.
Одна из первых идей, которая приходит в голову при оптимизации кода на ускорителях – это использование локальной памяти. В OpenACC это можно сделать несколькими директивами, но результат всегда должны быть один: данные перед началом вычислений должны быть скопированы на локальную память.
Для проверки и выбора нужной директивы мы написали на фортране несколько тестовых программ, на которых убедились, что они работают и что можно таким образом получить ускорение. Далее мы расставили эти директивы в Masnum-Wave, указав им имена наиболее используемых переменных. После компиляции они стали появляться в логах, сопутствующие надписи на китайском не были подсвечены красным, и мы посчитали, что все скопировалось и работает.
Но оказалось, что не все так просто. Компилятор OpenACC не копировал массивы в Masnum-Wave, но работал исправно с тестовыми программами. Проведя пару дней с Google Translate мы поняли, что он не копирует объекты, которые определены в файлах, подключаемых через директивы препроцессора (include)!
Всю следующею неделю мы переносили код Masnum-Wave из подключаемых файлов (а их больше 30) в файлы с исходным кодом, при этом нужно было убедиться, что все определятся и линкуется в правильном порядке. Но, так как ни у кого из нас не было опыта работы с Фортраном, и все сводилось к “давайте жахнем и посмотрим, что получится”, то без замены некоторых основных функций на костыльные версии тут тоже не обошлось.
И вот, когда все модули были перелопачены, и мы, в надежде получить свое мизерное ускорение, запустили свежескомилированный код, то получили очередную порцию разочарования! Директивы, написанные по всем канонам стандарта OpenACC 2.0, выдают ошибки в runtime. В этот момент в наши головы начала закрадываться идея, что этот чудесный суперкомпьютер поддерживает какой-то свой особый стандарт.
Тогда мы попросили у организаторов соревнований документацию, и с третьей попытки они нам ее предоставили.

Пару часов с Google Translate подтвердили наши опасения: стандарт, который они поддерживают, называется OpenACC 0.5, и он кардинально отличается от OpenACC 2.0, поставляемого с pgi компилятором.
Например, основной нашей задумкой было переиспользование данных на ускорителе. Для выполнения этого в стандарте 2.0 необходимо обернуть параллельный код в блок data. Вот как это делается в примерах от Nvidia:
!$acc data copy(A, Anew)
do while ( error .gt. tol .and. iter .lt. iter_max )
error=0.0_fp_kind
!$omp parallel do shared(m, n, Anew, A) reduction( max:error )
!$acc kernels
do j=1,m-2
do i=1,n-2
Anew(i,j) = 0.25_fp_kind * ( A(i+1,j ) + A(i-1,j ) + &
A(i ,j-1) + A(i ,j+1) )
error = max( error, abs(Anew(i,j)-A(i,j)) )
end do
end do
!$acc end kernels
!$omp end parallel do
if(mod(iter,100).eq.0 ) write(*,'(i5,f10.6)'), iter, error
iter = iter +1
!$omp parallel do shared(m, n, Anew, A)
!$acc kernels
do j=1,m-2
do i=1,n-2
A(i,j) = Anew(i,j)
end do
end do
!$acc end kernels
!$omp end parallel do
end do
!$acc end dataНо на кластере этот код не скомпилируется, потому что в их стандарте эта операция делается через указание индекса для каждого блока данных:
#include <stdio.h>
#include <stdlib.h>
#define NN 128
int A[NN],B[NN],C[NN];
int main()
{
int i;
for (i=0;i<NN;i++)
{
A[i]=1;
B[i]=2;
}
#pragma acc data index(1)
{
#pragma acc parallel loop packin(A,B, at data 1) copyout(C)
for (i=0;i<NN;i++)
{
C[i]=A[i]+B[i];
}
}
for(i=0;i<NN;i++)
{
if(C[i]!=3)
{
printf("Test Error! C[%d] = %d\n", i, C[i]);
exit(-1);
}
}
printf("Test OL!\n");
return 0;
}Коря себя за выбор OpenACC, мы все же продолжили работу, так как времени оставалось всего пару дней. В последний день отборочного тура нам наконец-то удалось запустить наш “ускоренный” код. Мы получили замедление в 3.5 раза. Нам ничего не оставалось, кроме как написать в отчете к заданию все, что мы думаем о их реализации OpenACC в цензурной форме. Не смотря на это, мы получили множество позитивных эмоций. Когда еще придется удаленно отлаживать код на самом мощном компьютере в мире?
P.S.: В результате мы все же прошли в финальную часть конкурса и съездили в Китай.
Последним заданием финала была презентация с описанием решений. Лучшего результата добилась местная команда, которая написала свою библиотеку на Си c использованием athread т.к. OpenACC, по их словам, не работает.
