
Предисловие
Эта статья является продолжением цикла статей про асинхронность:
Спустя 3 года я решил расширить и обобщить имеющийся спектр асинхронного взаимодействия с использованием сопрограмм. Помимо этих статей также рекомендуется ознакомиться с универсальным адаптером:
Введение
Рассмотрим электрон. Что он из себя представляет? Отрицательно заряженная элементарная частица, лептон, обладающий некоторой массой. Это означает, что он может участвовать по меньшей мере в электромагнитных и гравитационных взаимодействиях.
Если мы поместим сферический электрон в вакууме, то все, на что он будет способен — это двигаться равномерно и прямолинейно. 3 степени свободы да спин, и только равномерное прямолинейное движение. Ничего интересного и необычного.

Все меняется совершенно удивительным образом, если неподалеку окажутся другие частицы. Например, протон. Что мы про него знаем? Много чего. Нас будет интересовать массовость и наличие положительного заряда, по модулю равного в точности электрону, но с другим знаком. Это означает, что электрон и протон начнут друг с другом взаимодействовать электромагнитным образом.
Результатом этого взаимодействия будет являться искривление прямолинейной траектории под действием электромагнитных сил. Но это пол беды. Электрон, пролетая рядом с протоном, будет испытывать ускорение. Система электрон-протон будет представлять собой диполь, который внезапно начнет создавать тормозное излучение. Т.е. порождать электромагнитные волны, распространяющиеся в вакууме.
Но и это еще не все. При определенных обстоятельствах, электрон захватывается на орбиту протона и получается всем известная система — атом водорода. Что мы знаем про такую систему? Тоже много всего. В частности, эта система имеет дискретный набор уровней энергии и линейчатый спектр излучения, образующийся при переходе между каждой парой стационарных состояний.
А теперь давайте взглянем на эту картинку под другим углом. Изначально у нас было две частицы: протон и электрон. Сами по себе частицы не излучают (просто не могут), никаких дискретностей они не проявляют, да и вообще ведут себя спокойно. Но картинка совершенно меняется, когда они находят друг друга. Появляются новые, совершенно уникальные свойства — непрерывный и дискретный спектр, стационарные состояния, минимальный уровень энергии системы. В реальности, конечно же, все гораздо сложнее и интереснее:
Асимметрия штарковского уширения спектральной линии Hβ атома водорода, Phys. Rev. E 79 (2009)
Эти рассуждения можно продолжать и дальше. Например, если поместить два атома водорода рядом, то получится устойчивая конфигурация под названием молекула водорода. Тут уже появляются электронно-колебательно-вращательные уровни энергии с характерным изменением спектра, появлением P,Q,R ветвей и много чего другого.
Как же так? Разве система не описывается её частями? Нет! В этом и суть, что при усложнении физической системы происходят качественные изменения, не описываемые каждой частью по отдельности.
Синергия взаимодействия проявляется во многих областях научного познания. Именно поэтому химия не редуцируется до физики, а биология — к химии. Несмотря на мощнейшие достижения квантовой механики, тем не менее химия как раздел научного знания существует отдельно от физики. Интересно отметить тот факт, что появляются области знания на стыке наук, например, квантовая химия. О чем это говорит? Что при усложнении системы появляются новые области исследований, которых не было на предыдущем уровне. Приходится учитывать новые обстоятельства, вводить дополнительные качественные факторы, усложняя каждый раз и без того непростую модель описания квантово-механической системы.
Описанные метаморфозы можно развернуть наоборот: если необходимо получить сложную систему из наиболее простых компонент, то эти компоненты должны обладать синергетическим принципом. В частности, все мы знаем, что любую задачу можно решить, введя дополнительный уровень абстракции. За исключением проблемы числа абстракций и возникающей при этом сложности. И лишь синергия абстракций позволяет уменьшить их количество.
К сожалению, достаточно часто наши программы не проявляют описанного синергетического свойства. Разве что в багах — появляются новые, доселе невиданные глюки, которые не были обнаружены на предыдущем этапе. А как бы хотелось, чтобы приложение не описывалось набором частей и библиотек программы, а представляло собой нечто уникальное и грандиозное.
Давайте же теперь попробуем проникнуть в суть ООП и сопрограмм для получения новых и удивительных свойств их синтеза с целью создания обобщенной модели взаимодействия.
Объектно-ориентированное программирование
Рассмотрим ООП. Что мы про него знаем? Инкапсуляция, наследование, полиморфизм? SOLID принципы? А давайте спросим Алана Кея, который и ввел это понятие:
Когда я говорил про ООП, то я не имел в виду С++.
Алан Кей.
Это серьезный удар для программистов С++. Даже как-то обидно стало за язык. Но что же он имел в виду? Давайте разбираться.
Концепция объектов была введена в середине 1960-х с появлением языка Simula 67. Этот язык ввел такие понятия как объект, виртуальные методы и сопрограммы (!). Затем в 1970-х язык Smalltalk под влиянием языка Simula 67 развил идею объектов и ввел термин объектно-ориентированное программирование. Именно там были заложены основы того, что мы сейчас называем ООП. Сам Алан Кей так комментировал свою фразу:
Я жалею, что придумал термин «объекты» много лет назад, потому что он заставляет людей концентрироваться на мелких идеях. По-настоящему большая идея — это сообщения.
Алан Кей.
Если вспомнить Smalltalk, то становится понятно, что это означает. В этом языке использовалась посылка сообщений (см. также ObjectiveC). Этот механизм работал, но был тормозным. Поэтому в дальнейшем пошли по пути языка Simula и заменили посылку сообщений на обычные вызовы функций, а также вызовы виртуальных функций через таблицу этих самых виртуальных функций для поддержки позднего связывания.
Чтобы вернуться к истокам ООП, давайте по новому взглянем на классы и методы в С++. Для этого в качестве примера рассмотрим класс
Reader, вычитывающий данные из источника и возвращающий объект типа Buffer:class Reader
{
public:
Buffer read(Range range, const Options& options);
// и другие методы ...
};
В данном случае меня будет интересовать лишь метод
read. Этот метод можно преобразовать в следующий, почти эквивалентный, вызов:Buffer read(Reader* this,
Range range,
const Options& options);
Вызов метода объекта мы просто превратили в отдельно стоящую функцию. Именно этим и занимается компилятор, когда преобразует наш код в машинный. Однако такой путь уводит нас в сторону, а точнее в сторону языка С. Тут ООП не пахнет даже близко, поэтому пойдем в другую сторону.
Как мы вызываем метод
read? Например, так:Reader reader;
auto buffer = reader.read(range, options);
Трансформируем вызов метода
read следующим образом:reader
<- read(range, options)
-> buffer;
Эта запись означает следующее. Объекту с именем
reader подается на вход некий read(range, options), а на выходе он дает объект с именем buffer.Что может представлять собой
read(range, options)? Некоторое входное сообщение:struct InReadMessage
{
Range range;
Options options;
};
struct OutReadMessage
{
Buffer buffer;
};
reader
<- InReadMessage{range, options}
-> OutReadMessage;
Такая трансформация нам дает несколько иное понимание происходящего: вместо вызова функции мы синхронно отправляем сообщение
InReadMessage и затем дожидаемся ответного сообщения OutReadMessage. Почему синхронно? Потому что семантика вызова подразумевает, что мы дожидаемся ответа. Однако, вообще говоря, ответного сообщения в месте вызова можно и не дожидаться, тогда это будет асинхронная отправка сообщения.Таким образом, все методы можно представить в качестве обработчиков различных типов сообщений. А наш объект автоматически диспетчеризует принятые сообщения, осуществляя статический pattern matching через механизм декларации различных методов и перегрузки одинаковых методов с разными типами входных параметров.
Перехват сообщений и трансформация действий
Поработаем над нашими сообщениями. Как же нам упаковать сообщение для последующей трансформации? Для этого будем использовать адаптер:
template<typename T_base>
struct ReaderAdapter : T_base
{
Buffer read(Range range, const Options& options)
{
return T_base::call([range, options](Reader& reader) {
return reader.read(range, options);
});
}
};
Теперь при вызове метода
read происходит упаковка вызова в лямбду и передача этого вызова в метод базового класса T_base::call. В данном случае лямбда представляет собой функциональный объект, который будет передавать свое замыкание нашему объекту-наследнику T_base, автоматически его диспетчеризуя. Вот эта лямбда и есть наше сообщение, которое мы передаем дальше для трансформации действий.Наиболее простой способ трансформации — это синхронизация доступа к объекту:
template<typename T_base, typename T_locker>
struct BaseLocker : private T_base
{
protected:
template<typename F>
auto call(F&& f)
{
std::unique_lock<T_locker> _{lock_};
return f(static_cast<T_base&>(*this));
}
private:
T_locker lock_;
};
Внутри метода
call происходит взятие блокировки lock_ и последующий вызов лямбды на экземпляре базового класса T_base, что позволяет производить дальнейшие трансформации при необходимости.Давайте попробуем использовать такую функциональность:
// создаем экземпляр
ReaderAdapter<BaseLocker<Reader, std::mutex>> reader;
auto buffer = reader.read(range, options);
Что здесь происходит? Вместо использования непосредственно
Reader мы теперь подменяем объект на ReaderAdapter. Этот адаптер при вызове метода read создает сообщение в виде лямбды и передает его дальше, где уже автоматически берется блокировка и отпускается строго на время выполнения этой операции. При этом мы в точности сохраняем исходный интерфейс класса Reader!Этот подход можно легко обобщить и использовать универсальный адаптер. Про него я рассказывал на конференции С++, которая проходила в Москве в феврале 2017 года. Также можно почитать мою недавнюю статью про универсальный адаптер.
Соответствующий код с применением универсального адаптера будет выглядеть следующим образом:
DECL_ADAPTER(Reader, read)
AdaptedLocked<Reader, std::mutex> reader;
Здесь адаптер перехватывает каждый метод класса
Reader, указанный в списке DECL_ADAPTER, в данном случае read, а затем AdaptedLocked уже перехваченное сообщение оборачивает в std::mutex. Более детально про это описано в указанной чуть выше статье, поэтому здесь я не буду подробно на этом останавливаться.Сопрограммы
С ООП немного разобрались. Теперь зайдем с другой стороны и поговорим про сопрограммы.
Что такое сопрограммы? Если говорить вкратце, то это такие функции, которые можно прервать в любом месте, а затем продолжить с этого же места, т.е. заморозить исполнение и восстановить его с прерванной точки. В этом смысле они очень похожи на потоки: операционная система тоже в любой момент времени может их заморозить и переключить на другой поток. Например, из-за того, что мы съели слишком много процессорного времени.
Но в чем же тогда отличие от потоков? Отличие в том, что мы сами в пользовательском пространстве можем переключать наши сопрограммы, наши потоки исполнения, не привлекая к этому ядро. Что позволяет, во-первых, повысить производительность, т.к. нет необходимости переключать кольца защиты и др., а во-вторых, добавляет более интересные способы взаимодействия, которые и будут рассмотрены ниже.
Некоторые интересные способы взаимодействия можно почитать в моих предыдущих статьях про асинхронность.
CoSpinLock
Рассмотрим следующий кусок кода:
namespace synca {
struct Spinlock
{
void lock()
{
while (lock_.test_and_set(std::memory_order_acquire)) {
reschedule();
}
}
void unlock()
{
lock_.clear(std::memory_order_release);
}
private:
std::atomic_flag lock_ = ATOMIC_FLAG_INIT;
};
} // namespace synca
Приведенный код выглядит как обычный спинлок. Действительно, внутри метода
lock мы пытаемся атомарно выставить значение флага из false в true. Если это нам удалось, то блокировка взята, причем взята именно нами, и можно выполнять необходимые атомарные действия. При разблокировке просто сбрасываем флаг обратно в начальное значение false.Все отличие кроется в реализации стратегии отлупа (backoff). Часто используется либо экспоненциальный рандомизированный отлуп, либо передача управления операционной системе через
std::this_thread::yield(). В данном случае я поступаю хитрее: вместо прогрева процессора или передачи управления планировщику операционной системы я просто перепланирую нашу сопрограмму на более позднее исполнение через вызов synca::reschedule. При этом текущее исполнение замораживается, и планировщик запускает другую, готовую к исполнению сопрограмму. Это очень похоже на std::this_thread::yield() за исключением того, что вместо переключение в пространство ядра мы все время остаемся в пространстве пользователя и продолжаем делать какую-то осмысленную работу без пустого увеличения энтропии пространства.Применим адаптер:
template <typename T>
using CoSpinlock = AdaptedLocked<T, synca::Spinlock>;
CoSpinlock<Reader> reader;
auto buffer = reader.read(range, options);
Как видим, код использования и семантика не изменились, зато изменилось поведение.
CoMutex
Тот же самый трюк можно провернуть и с обычным мьютексом, превратив его в асинхронный на сопрограммах. Для этого нужно завести очередь ожидающих сопрограмм и последовательно их запускать в момент отпускания блокировки. Это можно проиллюстрировать следующей схемой:

Я здесь не буду приводить полный код реализации. Желающие могут с ним ознакомиться самостоятельно. Приведу лишь пример использования:
template <typename T>
using CoMutex = AdaptedLocked<T, synca::Mutex>;
CoMutex<Reader> reader;
auto buffer = reader.read(range, options);
Такой мьютекс имеет семантику обычного мьютекса, однако при этом не блокирует поток, заставляя планировщик сопрограмм выполнять полезную работу без переключения в пространство ядра. При этом
CoMutex, в отличие от CoSpinlock, дает FIFO-гарантию, т.е. предоставляет справедливый конкурентный доступ к объекту.CoSerializedPortal
В статье Асинхронность 2: телепортация сквозь порталы был подробно рассмотрен вопрос о переключении контекста между различными планировщиками через использование телепортации и портала. Вкратце опишу этот процесс.
Рассмотрим пример, когда нам необходимо переключить сопрограмму с одного потока на другой. Для этого мы можем заморозить текущее состояние нашей сопрограммы в исходном потоке, а затем запланировать возобновление сопрограммы в другом потоке:
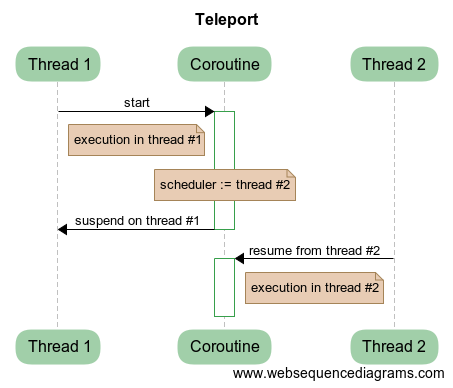
Это как раз и будет соответствовать переключению исполнения с одного потока на другой. Сопрограмма дает дополнительный уровень абстракции между кодом и потоком, позволяя манипулировать текущим исполнением и выполнять различные трюки и фокусы. Переключение между различными планировщиками — это телепортация.
Если же нам необходимо переключиться сначала в другой планировщик, а затем вернуться обратно — то тут возникает портал, в конструкторе которого происходит телепортация в другой планировщик, а в деструкторе — в исходный. Это гарантирует возврат к истокам даже при генерации исключения.
Соответственно, возникает простая идея. Создадим планировщик с одним потоком и будем на него перепланировать наши сопрограммы через порталы:
template <typename T_base>
struct BaseSerializedPortal : T_base
{
// создаем пул потоков с 1 потоком
BaseSerializedPortal() : tp_(1) {}
protected:
template <typename F>
auto call(F&& f)
{
// в конструкторе портала перемещаемся в планировщик с 1 потоком
synca::Portal _{tp_};
return f(static_cast<T_base&>(*this));
// а в деструкторе возвращаемся в исходный планировщик
}
private:
mt::ThreadPool tp_;
};
CoSerializedPortal<Reader> reader;
Понятно, что такой планировщик будет сериализовывать наши действия, а значит, синхронизировать их между собой. При этом, если пул потоков дает FIFO-гарантии, то и
CoSerializedPortal будет обладать аналогичной гарантией.CoAlone
Предыдущий подход с порталами можно использовать несколько иначе. Для этого воспользуемся другим планировщиком:
synca::Alone.Этот планировщик обладает следующим чудесным свойством: в любой момент времени может исполняться не более одной задачи данного планировщика. Таким образом,
synca::Alone гарантирует, что ни один обработчик не будет запущен параллельно с другим. Есть задачи — будет выполняться только одна из них. Нет задач — ничего и не исполняется. Понятно, что при таком подходе происходит сериализация действий, а значит, доступ через этот планировщик будет синхронизирован. Семантически, это очень похоже на CoSerializedPortal. Стоит, однако, отметить, что такой планировщик запускает свои задачи на некотором пуле потоков, т.е. он самостоятельно не создает никаких новых потоков, а работает на уже существующих.Для более подробной информации я отправляю читателя к оригинальной статье Асинхронность 2: телепортация сквозь порталы.
template <typename T_base>
struct BaseAlone : T_base
{
BaseAlone(mt::IScheduler& scheduler)
: alone_{scheduler} {}
protected:
template <typename F>
auto call(F&& f)
{
// т.к. Alone - планировщик, то снова используем портал
synca::Portal _{alone_};
return f(static_cast<T_base&>(*this));
}
private:
synca::Alone alone_;
};
CoAlone<Reader> reader;
Единственная разница в реализации по сравнению с
CoSerializedPortal — замена планировщика mt::ThreadPool на synca::Alone.CoChannel
Введем понятие канала на сопрограммах. Идеологически, он похож на каналы
chan в языке Go, т.е. это очередь (не обязательно, кстати, ограниченного размера, как это сделано в Go), в которую могут одновременно писать несколько производителей данных и одновременно читать потребители без дополнительной синхронизации с их стороны. Проще говоря, канал — это просто труба, в которую можно добавлять и забирать сообщения без боязни состояния гонки.Идея использования канала состоит в том, что пользователи наших объектов записывают сообщения в канал, а потребителем является специально созданная сопрограмма, которая в бесконечном цикле вычитывает сообщения и диспетчеризует в соответствующий метод.
template <typename T_base>
struct BaseChannel : T_base
{
BaseChannel()
{
// создаем сопрограмму и запускаем цикл обработки сообщений
synca::go([&] { loop(); });
}
private:
void loop()
{
// цикл обработки сообщений
// автоматически обрывается при закрытии канала
for (auto&& action : channel_) {
action();
}
}
synca::Channel<Handler> channel_;
};
CoChannel<Reader> reader;
Тут сразу возникает два вопроса: первый и второй.
- Что такое
Handler?
- Где, собственно, диспетчеризация?
Handler — это всего лишь std::function<void()>. Вся магия происходит не здесь, а в том, как создается этот Handler для автоматической диспетчеризации.template <typename T_base>
struct BaseChannel : T_base
{
protected:
template <typename F>
auto call(F&& f)
{
// перехватываем вызов метода с параметрами и записываем в fun
auto fun = [&] { return f(static_cast<T_base&>(*this)); };
// обложенный костылями результат вызова функции
WrappedResult<decltype(fun())> result;
channel_.put([&] {
try {
// если получилось вызвать без исключений - записываем результат
result.set(wrap(fun));
} catch (std::exception&) {
// иначе записываем текущее перехваченное исключение
result.setCurrentError();
}
// в конце обработчика возобновляем заснувшую сопрограмму
synca::done();
});
// а здесь засыпаем и ожидаем результата
synca::wait();
// возвращаем результат либо кидаем пойманное исключение
return result.get().unwrap();
}
};
Здесь происходит достаточно простое действие: перехваченный вызов метода внутри функтора
f мы оборачиваем во WrappedResult, помещаем этот вызов внутрь канала и засыпаем. Этот отложенный вызов мы позовем внутри метода BaseChannel::loop, тем самым заполнив результат и возобновив заснувшую исходную сопрограмму.Стоит сказать несколько слов о классе
WrappedResult. Данный класс служит нескольким целям:- Он позволяет хранить либо результат вызова, либо пойманное исключение.
- Помимо этого, он решает следующую задачу. Дело в том, что если функция не возвращает никаких значений (т.е. возвращает тип
void), то конструкция присвоения результата без обертки была бы некорректной. Действительно, нельзя просто так взять, и записать в типvoidрезультатvoid. Однако его разрешено возвращать, что и делает специализацияWrappedResult<void>через вызовы.get().unwrap().
В результате мы имеем синхронизацию доступа к объекту через канал вызовов методов с захваченными параметрами. При этом все методы обрабатываются в отдельной, изолированной сопрограмме, которая и обеспечивает последовательное исполнение обработчиков для изменения нашего объекта.
Обычная асинхронность
Давайте ради интереса попробуем точно такое же поведение реализовать без адаптера и сопрограмм, чтобы наиболее ярко продемонстрировать всю мощь и силу применяемых абстракций.
Для этого рассмотрим реализацию асинхронного спинлока:
struct AsyncSpinlock
{
void lock(std::function<void()> cb)
{
if (lock_.test_and_set(std::memory_order_acquire)) {
// не получилось взять => перепланируем через планировщик
currentScheduler().schedule(
[this, cb = std::move(cb)]() mutable {
lock(std::move(cb));
});
} else {
cb();
}
}
void unlock()
{
lock_.clear(std::memory_order_release);
}
private:
std::atomic_flag lock_ = ATOMIC_FLAG_INIT;
};
Здесь поменялся стандартный интерфейс спинлока. Этот интерфейс стал более громоздким и менее приятным.
Теперь реализуем класс
AsyncSpinlockReader, который будет использовать наш асинхронный спинлок:struct AsyncSpinlockReader
{
void read(Range range, const Options& options,
std::function<void(const Buffer&)> cbBuffer)
{
spinlock_.lock(
[this, range, options, cbBuffer = std::move(cbBuffer)] {
auto buffer = reader_.read(range, options);
// повезло, что unlock синхронный,
// а то получилась бы прикольная лесенка из лямбд
spinlock_.unlock();
cbBuffer(buffer);
});
}
private:
AsyncSpinlock spinlock_;
Reader reader_;
}
Как мы видим на примере метода
read, асинхронный спинлок AsyncSpinlock обязательно сломает существующие интерфейсы наших классов.А теперь рассмотрим использование:
// вместо
// CoSpinlock<Reader> reader;
// auto buffer = reader.read(range, options);
AsyncSpinlockReader reader;
reader.read(buffer, options, [](const Buffer& buffer) {
// и вот здесь у нас буфер
// надо позаботиться о правильной передаче контекста внутрь лямбды
});
Давайте на минутку предположим, что
Spinlock::unlock и вызов метода Reader::read тоже асинхронные. В это достаточно легко поверить, если предположить, что Reader тянет данные по сети, а вместо Spinlock используются, например, порталы. Тогда:struct SuperAsyncSpinlockReader
{
// здесь намеренно опущена обработка ошибок,
// иначе мозг изменит свое агрегатное состояние
void read(Range range, const Options& options,
std::function<void(const Buffer&)> cb)
{
spinlock_.lock(
[this, range, options, cb = std::move(cb)]() mutable {
// первая неудача: read асинхронный
reader_.read(range, options,
[this, cb = std::move(cb)](const Buffer& buffer) mutable {
// вторая неудача: спинлок асинхронный
spinlock_.unlock(
[buffer, cb = std::move(cb)] {
// конец прикольной лесенки
cb(buffer);
});
});
});
}
private:
AsyncSpinlock spinlock_;
AsyncNetworkReader reader_;
}

Такой лобовой подход как бы намекает, что дальше будет только хуже, ведь рабочий код имеет тенденцию разрастаться и усложняться.
Естественно, что правильный подход с использованием сопрограмм делают такую схему синхронизации простой и понятной.
Неинвазивная асинхронность
Все рассмотренные примитивы синхронизации являются неявно асинхронными. Дело в том, что в случае уже заблокированного ресурса при конкурентном доступе наша сопрограмма засыпает, чтобы проснуться в момент освобождения блокировки предыдущей сопрограммой. Если бы мы при этом использовали так называемые stackless сопрограммы, которые до сих пор маринуются в новом стандарте, то нам бы пришлось использовать ключевое слово
co_await. А это, в свою очередь, означает, что каждый (!) вызов любого метода, обернутого через синхронизирующий адаптер, должен добавлять вызов co_await, меняя семантику и интерфейсы:// без синхронизации
Buffer baseRead()
{
Reader reader;
return reader.read(range, options);
}
// callback-style
// изменяется интерфейс и семантика вызова
void baseRead(std::function<void(const Buffer& buffer)> cb)
{
AsyncReader reader;
reader.read(range, options, cb);
}
// stackless coroutines
// изменяется интерфейс, добавляется явная асинхронность
future_t<Buffer> standardPlannedRead()
{
CoMutex<Reader> reader;
return co_await reader.read(range, options);
}
// stackful coroutines
// все остается неизменным
Buffer myRead()
{
CoMutex<Reader> reader;
return reader.read(range, options);
}
Здесь при использовании stackless подхода происходит слом всех интерфейсов в цепочке вызовов. В этом случае ни о какой прозрачности речи и быть не может, т.к. нельзя просто так взять и заменить
Reader на CoMutex<Reader>. Такой инвазивный подход существенно ограничивает область применения stackless сопрограмм.В то же время, такая проблема полностью отсутствует у подхода на основе stackful сопрограмм, используемых в настоящей статье.
Вам предоставляется уникальный выбор:
- Использовать инвазивный ломающий подход завтра (через 3 года, может быть).
- Использовать неинвазивный прозрачный подход сегодня (точнее, уже вчера).
Гибридные подходы
Помимо вышеприведенных способов синхронизации можно ввести так называемые гибридные подходы. Дело в том, что часть синхронизирующих примитивов использует в качестве основы планировщик, который можно комбинировать с пулом потоков для дополнительной изоляции исполнения.
Рассмотрим синхронизацию через портал:
template <typename T_base>
struct BasePortal : T_base, private synca::SchedulerRef
{
template <typename... V>
BasePortal(mt::IScheduler& scheduler, V&&... v)
: T_base{std::forward<V>(v)...}
, synca::SchedulerRef{scheduler} // запоминаем планировщик
{
}
protected:
template <typename F>
auto call(F&& f)
{
// перепланируем вызов f(...) через сохраненный планировщик
synca::Portal _{scheduler()};
return f(static_cast<T_base&>(*this));
}
using synca::SchedulerRef::scheduler;
};
В конструкторе базового класса адаптера мы задаем планировщик
mt::IScheduler, а затем перепланируем наш вызов f(static_cast<T_base&>(*this)) через портал сохраненного планировщика. Для использования такого подхода необходимо предварительно создать планировщик с 1 потоком для синхронизации исполнения:// создаем единственный поток в пуле потоков для синхронизации
mt::ThreadPool serialized{1};
CoPortal<Reader> reader1{serialized};
CoPortal<Reader> reader2{serialized};
Таким образом оба экземпляра класса
Reader будут сериализованы через один и тот же поток, принадлежащего пулу потоков serialized.Подобный подход для изоляции исполнения можно использовать для
CoAlone и CoChannel:// т.к. CoAlone и CoChannel самостоятельно синхронизируют исполнение,
// то число потоков может быть произвольным
mt::ThreadPool isolated{3};
// здесь будет происходить синхронизация
// в пуле потоков isolated
CoAlone<Reader> reader1{isolated};
// будет создана сопрограмма для чтения из канала
// в пуле потоков isolated
CoChannel<Reader> reader2{isolated};
Субъектор
Итак, у нас есть 5 различных неблокирующих способов эффективной синхронизации действий над объектом в пользовательском пространстве исполнения:
CoSpinlock
CoMutex
CoSerializedPortal
CoAlone
CoChannel
Все эти способы позволяют одинаковым образом взаимодействовать с объектом. Сделаем последний шаг для обобщения полученного кода:
#define BIND_SUBJECTOR(D_type, D_subjector, ...) \
template <> \
struct subjector::SubjectorPolicy<D_type> \
{ \
using Type = D_subjector<D_type, ##__VA_ARGS__>; \
};
template <typename T>
struct SubjectorPolicy
{
using Type = CoMutex<T>;
};
template <typename T>
using Subjector = typename SubjectorPolicy<T>::Type;
Здесь мы создаем тип
Subjector<T>, который впоследствии можно будет переопределить на одно из 5 поведений. Например:// допустим, что у класса Reader есть 3 метода: read, open, close
// сначала создаем адаптер для перехвата всех методов
DECL_ADAPTER(Reader, read, open, close)
// затем указываем, что Reader должен использовать CoChannel для синхронизации.
// если опустить эту строчку, то по умолчанию будет использован CoMutex,
// т.е. эта строка не является обязательной
BIND_SUBJECTOR(Reader, CoChannel)
// здесь используем уже настроенный субъектор - универсальный объект синхронизации
Subjector<Reader> reader;
Если в будущем мы захотим использовать
Reader, например, в другом изолированном потоке, то нам необходимо всего лишь поменять одну строчку:BIND_SUBJECTOR(Reader, CoSerializedPortal)
Такой подход дает возможность тонкой настройки способа взаимодействия после написания и использования кода, и позволяет сконцентрироваться на решении более насущных проблем.
Если вы используете язык с ранним связыванием, как делает большинство людей, вместо языка с поздним связыванием, вы окажетесь взаперти у проделанной работы. Переформулировать что-то будет уже непросто.
Алан Кей.
Асинхронный вызов
В рассмотренных примитивах синхронизации использовался синхронный неблокирующий вызов методов. Т.е. каждый раз мы дожидались окончания выполнения задачи и получения результата. Эта семантика соответствует обычному вызову методов объекта. Однако, в некоторых сценариях бывает полезно явно асинхронно запустить задачу, не дожидаясь результата, для распараллеливания исполнения.
Рассмотрим следующий пример:
class Network
{
public:
void send(const Packet& packet);
};
DECL_ADAPTER(Network, send)
BIND_SUBJECTOR(Network, CoChannel)
Если мы будем использовать код:
void sendPacket(const Packet& packet)
{
Subjector<Network> network;
network.send(myPacket);
// следующее действие не начнется,
// пока не завершится предыдущее
doSomeOtherStuff();
}
то действие
doSomeOtherStuff() не начнется, пока не закончится выполнение network.send(). Для асинхронной отправки сообщения можно использовать следующий код:void sendPacket(const Packet& packet)
{
Subjector<Network> network;
// запуск через .async()
network.async().send(myPacket);
// следующее действие начнется
// параллельно с предыдущим
doSomeOtherStuff();
}
И вуаля — синхронный код превратился в асинхронный!
Работает это следующим образом. Сначала создается специальная асинхронная обертка для адаптера
BaseAsyncWrapper через использование странно рекурсивного шаблона:template <typename T_derived>
struct BaseAsyncWrapper
{
protected:
template <typename F>
auto call(F&& f)
{
return static_cast<T_derived&>(*this).asyncCall(std::forward<F>(f));
}
};
Т.е. вызов
.async() перенаправляется в BaseAsyncWrapper, который перенаправляет вызов обратно в дочерний класс T_derived, но уже через использование метода asyncCall вместо call. Таким образом, для наших Co-объектов достаточно доопределить метод asyncCall в дополнении к call, чтобы такая функциональность заработала автоматически.Для реализации
asyncCall все способы синхронизации можно разделить на два класса:- Изначально синхронный вызов:
CoSpinlock,CoMutex,CoSerializedPortal,CoAlone. Для этого необходимо просто создать новую сопрограмму и запустить в ней наше действие на заданном планировщике.
template <typename T_base>
struct Go : T_base
{
protected:
template <typename F>
auto asyncCall(F&& f)
{
return synca::go(
[ f = std::move(f), this ]() {
f(static_cast<T_base&>(*this));
},
T_base::scheduler());
}
};
- Изначально асинхронный вызов:
CoChannel. Для этого надо убрать ожидание и оставить изначальный асинхронный вызов.
template <typename T_base>
struct BaseChannel : T_base
{
template <typename F>
auto asyncCall(F&& f)
{
channel_.put([ f = std::move(f), this ] {
try {
f(static_cast<T_base&>(*this));
} catch (std::exception&) {
// do nothing due to async call
}
});
}
};
Характеристики
Различные характеристики описанных подходов сведены в следующую таблицу:
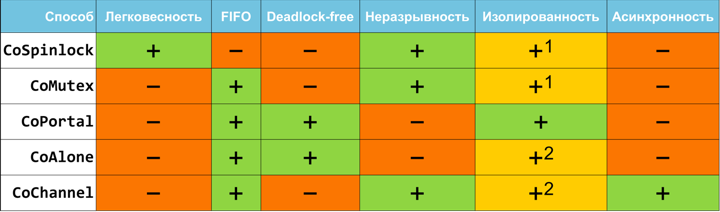
1При использовании асинхронного вызова одновременно с гибридным подходом.
2При использовании гибридного подхода.
Рассмотрим более детально каждую колонку.
Легковесность
Самый легковесный примитив из рассматриваемых — это, безусловно,
CoSpinlock. Действительно, он содержит только атомарные инструкции и перепланирование в случае уже заблокированного ресурса. CoSpinlock имеет смысл использовать в ситуациях кратковременных блокировок, т.к. в противном случае он начинает нагружать планировщик бесполезной работой для проверки атомарной переменной с последующем перепланированием сопрограммы. Другие рассматриваемые примитивы синхронизации используют более тяжеловесную синхронизацию своих объектов, однако в случае наличия конфликтов не нагружают планировщик.FIFO
FIFO или first-in-first-out гарантия — это гарантия очереди, т.е. кто первее позвал
.lock(), тот первее его и возьмет. Стоит отметить, что если в программе есть единственный планировщик и этот планировщик дает FIFO гарантию, то даже этом случае CoSpinlock не дает FIFO-гарантии.Deadlock-free
Как понятно из названия, такой примитив синхронизации никогда не дает взаимных блокировок. Такую гарантию предоставляют примитивы на основе планировщика.
Неразрывность
Под неразрывностью я понимаю неразрывность взятой блокировки, как если бы синхронизация была через мьютекс. Оказывается, что неразрывность тесно связана со свойством deadlock-free. На этой теме я хотел бы остановиться более подробно чуть ниже, т.к. она важна для глубокого понимания способов синхронизации и представляет определенный практический интерес.
Изолированность
Частично понятие изолированности уже было использовано при рассмотрении
CoPortal. Изолированность — это свойство исполнять метод в изолированном пуле потоков. Этим свойством по умолчанию обладает лишь CoSerializedPortal, т.к. он внутри себя создает пул потоков из одного потока для синхронизации исполнения. При синхронном исполнении, как уже было рассмотрено ранее, таким свойством могут также обладать примитивы, использующие планировщик: CoAlone и CoChannel. При асинхронном вызове происходит разветвление исполнения. Эту задачу решает планировщик, а значит появляется возможность изоляции выполнения кода и для других способов.Асинхронность
Все способы, за исключением
CoChannel, используют текущую сопрограмму для запуска синхронного действия. И только CoChannel запускает параллельно операцию и дожидается окончания исполнения. Т.е. нативный способ исполнения для этого примитива синхронизации — это асинхронный запуск задачи. А значит он может лучше:- Параллелиться: эффективно исполнять различные стадии обработки.
- Сохранять контекст объекта: минимум переключений контекста для синхронизируемого объекта, данные объекта не вымываются из кеша процессора, ускоряя обработку.
Взаимные блокировки, гонки и взаимосвязь.
Я люблю задавать следующую задачу.
Задача 1. Предположим, что все методы нашего класса синхронизированы через мьютекс. Внимание, вопрос: возможно ли состояние гонки?

Очевидный ответ: нет. Однако здесь чувствуется некий подвох. Мысль начинает крутиться в голове, мозг начинает предлагать безумные варианты, не соответствующие условию задачи. В результате все превращается в тлен и возникает безысходность.
Советую тщательно подумать перед тем, как подсмотреть ответ. Но чтобы не сломать мозг, ниже приведено решение этой задачи.
Рассмотрим класс:
struct Counter
{
void set(int value);
int get() const;
private:
int value_ = 0;
};
Обернем:
DECL_ADAPTER(Counter, set, get)
Subjector<Counter> counter;
Методы
get и set будут обернуты асинхронным мьютексом, хотя асинхронность тут не принципиальна. Важна синхронизация.А теперь хотим решить задачу:
Задача 2. Атомарно увеличить счетчик на единицу.
И тут многих внезапно осеняет:
counter.set(counter.get() + 1);
Приведенный код содержит состояние гонки, невзирая на то, что каждый вызов по отдельности синхронизирован!
Чтобы разобраться во всем многообразии состояний гонок имеет смысл ввести следующие категории.
Состояние гонки первого рода.
Или иначе data race, описанный в стандарте:
The execution of a program contains a data race if it contains two potentially concurrent conflicting actions, at least one of which is not atomic, and neither happens before the other, except for the special case for signal handlers described below. Any such data race results in undefined behavior.
C++17 Standard N4659, §4.7.1 (20.2)
Типичный пример этого случая — когда в двух различных потоках делаются действия по изменению состояния без какой-либо синхронизации, например
std::vector::push_back(value). В лучшем случае программа упадет, в худшем — незаметно испортит данные (да, в этом случае падение — благо). Для отлова подобного рода проблем существуют специальные инструменты:- ThreadSanitizer: позволяет детектировать проблемы в runtime.
- Helgrind: a thread error detector: инструмент Valgrind для обнаружения ошибок синхронизации.
- Relacy race detector: верифицирует многопоточные lock-free/wait-free алгоритмы с учетом модели памяти.
Состояние гонки второго рода.
Это все состояния гонки, которые не подпадают под первую категорию. Это более высокоуровневые условия, которые описываются логикой программы и ее инвариантами, поэтому они не могут быть задетектированы низкоуровневыми инструментами и верификаторами. Как правило, они возникают при разрыве атомарного поведения, как в приведенном выше примере со счетчиком
counter.set(counter.get() + 1). Это происходит из-за того, что .get() и .set() синхронизируются раздельно.На данный момент инструменты для анализа такого рода проблем находятся на начальной стадии развития. Ниже приведен краткий список с минимальными комментариями, т.к. детальное описание выходит за рамки этой статьи:
- Node.fz: fuzzing the server-side event-driven architecture: исследователи находят баги, связанные с конкурентным взаимодействием, в однопоточном (!) асинхронном коде.
- An empirical study on the correctness of formally verified distributed systems: исследование корректности формально верифицированных систем. Т.е. они находят ошибки там, где их не должно быть в принципе!
Неразрывность и асинхронность
При добавлении асинхронного поведения возможны непредвиденные способы исполнения программы, что приводит к потрясающей возможности лишний раз удивиться некорректному поведению. Для этого рассмотрим синхронизацию через
CoAlone:struct User
{
void setName(const std::string& name);
std::string getName() const;
void setAge(int age);
int getAge() const;
};
DECL_ADAPTER(User, setName, getName, setAge, getAge)
BIND_SUBJECTOR(User, CoAlone)
struct UserManager
{
void increaseAge()
{
user_.setAge(user_.getAge() + 1);
}
private:
Subjector<User> user_;
};
UserManager manager;
// race condition 2-го рода
manager.increaseAge();
Здесь в строчке
manager.increaseAge() уже известное нам состояние гонки 2-го рода, приводящее к неконсистентному поведению в случае конкурентного вызова метода increaseAge() в двух разных потоках.Можно попытаться исправить такое поведение:
struct UserManager
{
void increaseAge()
{
user_.setAge(user_.getAge() + 1);
}
private:
Subjector<User> user_;
};
DECL_ADAPTER(UserManager, increaseAge)
BIND_SUBJECTOR(UserManager, CoAlone)
Subjector<UserManager> manager;
manager.increaseAge();
Для синхронизации в обоих случаях мы используем
CoAlone. Возникает вопрос: будет ли состояние гонки в этом случае?
Будет! Несмотря на синхронизацию, этот пример также подвержен проблеме состояния гонки 2-го рода. Действительно, при синхронизации
UserManager текущая сопрограмма запускается на планировщике Alone. Затем при вызове user_.getAge() происходит телепортация на другой планировщик Alone, принадлежащий User. Т.е. другая запущенная сопрограмма теперь в состоянии войти внутрь метода increaseAge() параллельно с текущей, которая в этот момент находится внутри user_.getAge(). Это возможно, т.к. Alone гарантирует лишь отсутствие параллельного исполнения в своем планировщике. В данном случае происходит параллельное исполнение в двух разных планировщиках: CoAlone<User> и CoAlone<UserManager>.
Таким образом, происходит разрыв атомарного исполнения в случае использования синхронизации на основе планировщиков:
CoAlone и CoPortal.Для исправления этой ситуации достаточно заменить:
BIND_SUBJECTOR(UserManager, CoMutex)

Это предотвратит состояние гонки второго рода.
Ожидание выполнения
В некоторых случаях разрыв синхронизации при исполнении кода бывает крайне полезен. Для этого рассмотрим следующий пример:
struct UI
{
// метод, срабатывающий при клике на карточке пользователя
void onRequestUser(const std::string& userName);
// обновляет в окне информацию о пользователе
void updateUser(const User& user);
};
DECL_ADAPTER(UI, onRequestUser, updateUser)
// UI присоединяется к существующему главному UI потоку
BIND_SUBJECTOR(UI, CoPortal)
struct UserManager
{
// запрашивает информацию о пользователе
User getUser(const std::string& userName);
private:
void addUser(const User& user);
User findUser(const std::string& userName);
};
DECL_ADAPTER(UserManager, getUser)
BIND_SUBJECTOR(UserManager, CoAlone)
struct NetworkManager
{
// загружает информацию о пользователе с сервера
User getUser(const std::string& userName);
};
DECL_ADAPTER(NetworkManager, getUser)
// сетевые операции запускаются вне основных потоков изолированно
BIND_SUBJECTOR(NetworkManager, CoSerializedPortal)
// функции, возвращающие глобальные экземпляры классов
Subjector<UserManager>& getUserManager();
Subjector<NetworkManager>& getNetworkManager();
Subjector<UI>& getUI();
void UI::onRequestUser(const std::string& userName);
{
updateUser(getUserManager().getUser(userName));
}
void UserManager::getUser(const std::string& userName)
{
auto user = findUser(userName);
if (user) {
// если пользователь найден, то возвращаем его
return user;
}
// если пользователь не найден,
// то запрашиваем пользователя по сети
user = getNetworkManager().getUser(userName);
// добавляем пользователя, чтобы избежать повторного запроса
addUser(user);
return user;
}

Все действие начинается с вызова
UI::onRequestUsername. В этот момент в UI потоке происходит вызов UserManager::getUser через соответствующий субъектор. Этот субъектор сначала переключает исполнение с UI потока на другой планировщик Alone, а затем вызывает непосредственно сам метод. При этом UI поток разблокируется и может выполнять другие действия. Таким образом, вызов происходит асинхронно, а значит не блокирует UI, не заставляя его лагать.Если
UserManager уже содержит информацию о запрашиваемом пользователе — то задача решена, и мы тотчас его возвращаем. В противном случае мы запрашивает необходимую информацию по сети через NetworkManager. И вновь мы не блокируем UserManager на время выполнения долгого запроса по сети. Если в этот момент пользователь запросил какую-то другую информацию из UserManager параллельно, то мы сможем ее предоставить без ожидания завершения изначальной операции! Т.е. в данном случае разрыв исполнения только улучшает отзывчивость и обеспечивает параллельность выполнения запросов. При этом мы не прикладывали для этого никаких усилий, через субъекторы все синхронизируется и асинхронно перепланируется автоматически. Чудеса, да и только!Взаимные блокировки
Еще одна уникальная возможность, которой обладают субъекторы на основе планировщиков — это отсутствие взаимных блокировок. Смотрим:
// forward declaration
struct User;
DECL_ADAPTER(User, addFriend, getId, addFriendId)
struct User
{
void addFriend(Subjector<User>& myFriend)
{
auto friendId = myFriend.getId();
if (hasFriend(friendId)) {
// если друг уже отмечен - то ничего не делаем
return;
}
addFriendId(friendId);
auto myId = getId();
myFriend.addFriendId(myId);
}
Id getId() const;
void addFriendId(Id id);
private:
bool hasFriend(Id id);
};
// подружиться
void makeFriends(Subjector<User>& u1, Subjector<User>& u2)
{
u1.addFriend(u2);
}

Т.к. по умолчанию используется
CoMutex, то makeFriends при параллельном вызове различных методов иногда будет виснуть наглухо. Как исправить эту ситуацию, не переписывая весь код с нуля? Нужно добавить одну единственную строчку:BIND_SUBJECTOR(User, CoAlone)

Теперь, как бы вы не издевались над вызовами, во сколько бы потоков и как часто бы не запускали эти методы, вам никогда не удастся получить взаимной блокировки. Могли ли вы когда-нибудь помыслить, что такое вообще возможно? Очевидно, нет.
Транзакционность и взаимосвязь
Если внимательно присмотреться к таблице сравнительных характеристик различных способов взаимодействия, то можно увидеть взаимосвязь: если присутствует неразрывность, то отсутствует deadlock-free, и наоборот. В целом, можно показать, что в случае описанных способов синхронизации нельзя одновременно выполнить оба свойства. Тем не менее, при применении особых методик транзакционного исполнения с учетом планирования и отслеживания зависимостей такое поведение оказывается возможным. Однако это тянет на отдельную статью и здесь рассмотрено не будет.
Обсуждение
Мы получили 5 различных способов синхронизации синхронного исполнения. Добавив к этому 3 гибридных подхода и удвоив полученный результат для учета явных асинхронных вызовов в результате получаем 16 различных вариантов неблокирующей асинхронной синхронизации в пространстве пользователя без необходимости переключения в пространство ядра. До тех пор, пока есть какая-либо работа, она будет выполняться, максимально нагружая все ядра процессора. При этом пользователь вправе выбирать тот способ синхронизации, который ему необходим, исходя из логики приложения и взаимосвязей между данными.
Среди всех этих 16 способов особое место занимает один, снискавший на сегодня немалую популярность:
CoChannel<T>.async().someMethod(...). Такое взаимодействие, примененное для всех участников процесса, называют моделью акторов. Действительно, в качестве mailbox выступает канал, который автоматически диспетчеризует входящие сообщения, соответствующие методам класса, используя всю мощь статической типизиции С++, ООП и шаблонного метапрограммирования на макросах. При этом, модель акторов, хотя и не требует дополнительной синхронизации, тем не менее остается подверженной гонкам второго рода, что, в свою очередь, полностью исключает взаимные блокировки.Приведенная субъекторная модель обладает гораздо большей вариативностью, позволяя впоследствии изменять конкретный способ конкурентного взаимодействия без слома существующих интерфейсов и реализации. Конкретный выбор зависит от обстоятельств, а рассуждения, приведенные в статье, могут являться отправной точкой для принятия того или иного решения. Каждый из способов обладает своей особенностью и уникальностью, при этом серебряную пулю опять не завезли.
Заключение: субъекторная модель
Кратко перечислим основные достижения:
- Интеграция синхронизации. Всё необходимое для синхронизации находится внутри нашей сущности, которая превращается из пассивного объекта в активный участник процесса — субъектор.
- Глубокая абстракция исполнения. Предложенная модель вводит единую абстракцию через обобщенное понимание принципов объектно-ориентированного программирования. В ней соединяются разнообразные примитивы воедино, порождая универсальную модель.
- Неинвазивность. Субъектор не меняет интерфейсы исходного класса, а значит позволяет прозрачно добавлять объект синхронизации без какого-либо рефакторинга кода.
- Защищенность от ошибок многопоточного проектирования. Универсальный адаптер гарантированно и автоматически выполняет все требуемые шаги для синхронизации исполнения. Это избавляет от необходимости аннотировать или комментировать поля и методы класса, описывая требуемый контекст использования и способ вызова. Субъектор изолирует все доступные поля и методы класса, предотвращая огромный класс наиболее коварных ошибок, связанных с параллельным и конкурентным программированием, отдавая задачу синхронизации доступа к объекту компилятору.
- Поздняя оптимизация. На основе локальности данных и текущего паттерна использования можно переключать различные типы синхронизации для достижения наилучших результатов на конечном этапе написания приложения.
- Эффективность. Подход реализует переключения контекста исключительно в пользовательском пространстве через использование сопрограмм, что дает минимальные накладные расходы и максимальное использование вычислительных ресурсов.
- Ясность, чистота и простота кода. Нет необходимости в явном отслеживании использования корректного контекста синхронизации и рассуждать о том, когда и какие переменные окружать защитниками
guard, мьютексами, какие использовать планировщики, потоки и т.д. Это дает более простую компонуемость различных частей, позволяя разработчику сконцентрироваться на решении конкретной задачи, а не на борьбу по нахождению трудноуловимых проблем.
Как известно, модель упрощается при обобщении. Философия объектно-ориентированного программирования заставляет по-другому взглянуть на традиционные вещи и увидеть потрясающие абстракции. Синергия таких, казалось бы несовместимых вещей, как ООП, сопрограммы, каналы, мьютексы, спинлоки, потоки и планировщики порождает новую модель конкурентных взаимодействий, обобщая всем известную модель акторов, традиционную модель на основе мьютексов и модель взаимодействующих последовательных процессов, стирая грань между двумя различными способами взаимодействия: через разделяемую память и через обмен сообщениями.
Имя этой обобщенной модели конкурентного взаимодействия: субъекторная модель.
https://github.com/gridem/Subjector

Литература
[1] Асинхронность: назад в будущее
[2] Асинхронность 2: телепортация сквозь порталы
[3] Blog: God Adapter
[4] Универсальный адаптер
[5] Доклад: универсальный адаптер
[6] Видео: универсальный адаптер
[7] S. Djurović, M. Ćirišan, A.V Demura, G.V Demchenko, D. Nikolić, M.A. Gigosos, et al., Measurements of Hβ Stark central asymmetry and its analysis through standard theory and computer simulations, Phys. Rev. E 79 (2009) 46402.
[8] Квантовая химия
[9] ООП: SOLID
[10] Странно рекурсивный шаблон
[11] C++17 Standard N4659
[12] ThreadSanitizer
[13] Helgrind: a thread error detector
[14] Relacy race detector
[15] Неблокирующая синхронизация
[16] J.Davis, A.Thekumparampil, D.Lee, Node.fz: fuzzing the server-side event-driven architecture. EuroSys '17 Proceedings of the Twelfth European Conference on Computer Systems, pp 145-160
[17] P.Fonseca, K.Zhang, X.Wang, A.Krishnamurthy, An empirical study on the correctness of formally verified distributed systems. EuroSys '17 Proceedings of the Twelfth European Conference on Computer Systems, pp 328-343
[18] Модель акторов
[19] Взаимодействующие последовательные процессы
[20] Разделяемая память
[21] Обмен сообщениями
