Robots.txt указывает веб-краулерам мира, какие файлы можно или нельзя скачивать с сервера. Он как первый сторож в интернете — не блокирует запросы, а просит не делать их. Интересно, что файлы robots.txt проявляют предположения веб-мастеров, как автоматизированным процессам следует работать с сайтом. Хотя бот легко может их игнорировать, но они указывают идеализированное поведение, как следует действовать краулеру.
По существу, это довольно важные файлы. Так что я решил скачать файл robots.txt с каждого из 1 миллиона самых посещаемых сайтов на планете и посмотреть, какие шаблоны удастся обнаружить.
Я взял список 1 млн крупнейших сайтов от Alexa и написал маленькую программу для скачивания файла robots.txt с каждого домена. После скачивания всех данных я пропустил каждый файл через питоновский пакет urllib.robotparser и начал изучать результаты.
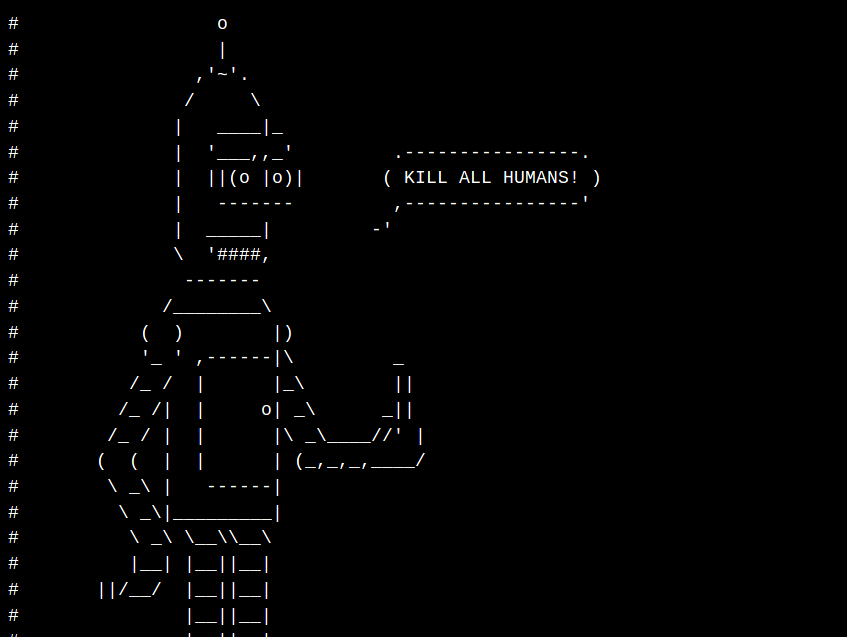
Найдено в yangteacher.ru/robots.txt
Среди моих любимых питомцев — сайты, которые позволяют индексировать содержимое только боту Google и банят всех остальных. Например, файл robots.txt сайта Facebook начинается со следующих строк:
Это слегка лицемерно, потому что сам Facebook начал работу с краулинга профилей студентов на сайте Гарвардского университета — именно такого рода активность они сейчас запрещают всем остальным.
Требование письменного разрешения перед началом краулинга сайта плюёт в лицо идеалам открытого интернета. Оно препятствует научным исследованиям и ставит барьер для развития новых поисковых систем: например, поисковику DuckDuckGo запрещено скачивать страницы Facebook, а поисковику Google можно.
В донкихотском порыве назвать и посрамить сайты, которые проявляют такое поведение, я написал простой скрипт, который проверяет домены и определяет тех, которые внесли Google в белый список тех, кому разрешено индексировать главную страницу. Вот самые популярные из этих доменов:
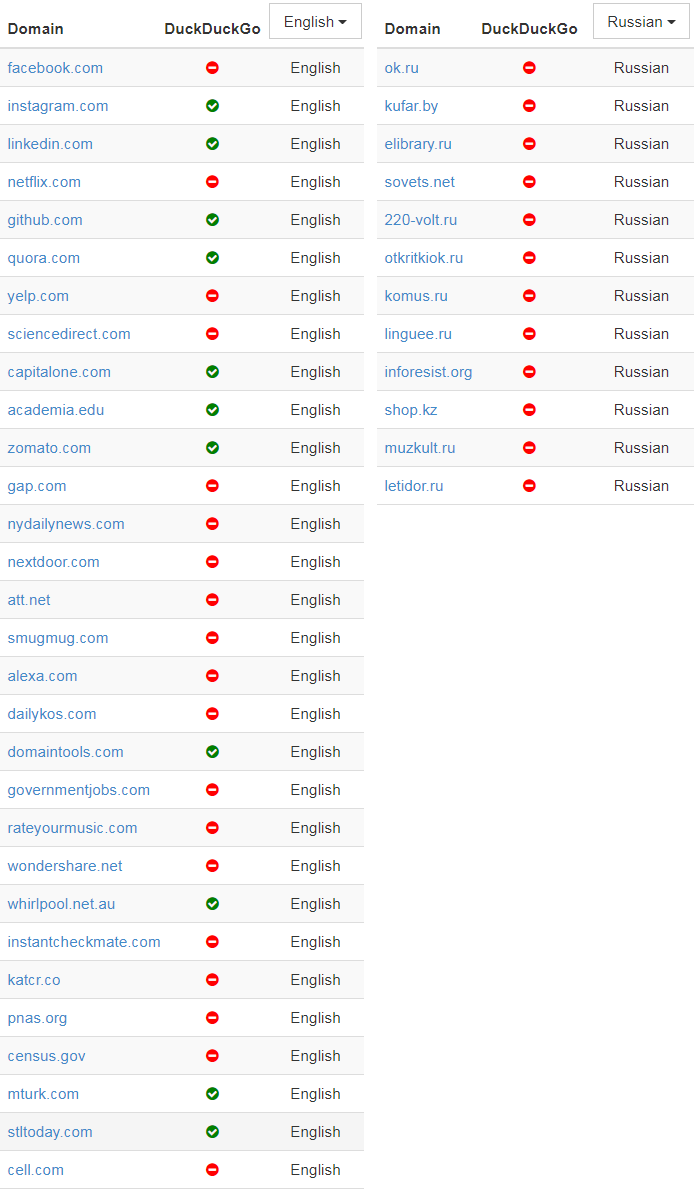
(В оригинальной статье указаны также аналогичные списки китайских, французских и немецких доменов — прим. пер.)
Я включил в таблицу пометку, позволяет ли сайт ещё DuckDuckGo индексировать свою заглавную страницу, в попытке показать, насколько тяжело приходится в наши дни новым поисковым системам.
У большинства из доменов в верхней части списка — таких как Facebook, LinkedIn, Quora и Yelp — есть одно общее. Все они размещают созданный пользователями контент, который представляет собой главную ценность их бизнеса. Это один из их главных активов, и компании не хотят отдавать его бесплатно. Впрочем, ради справедливости, такие запреты часто представляются как защита приватности пользователей, как в этом заявлении технического директора Facebook о решении забанить краулеры или глубоко в файле robots.txt от Quora, где объясняется, почему сайт забанил Wayback Machine.
Далее по списку результаты становятся более противоречивыми — например, мне не совсем понятно, почему census.gov позволяет доступ к своему контенту только трём основным поисковым системам, но блокирует DuckDuckGo. Логично предположить, что данные государственных переписей принадлежат народу, а не только Google/Microsoft/Yahoo.
Хотя я не фанат подобного поведения, но вполне могу понять импульсивную попытку внести в белый список только определённые краулеры, если учесть количество плохих ботов вокруг.
Я хотел попробовать ещё кое-что: определить самые плохие веб-краулеры в интернете, с учётом коллективного мнения миллиона файлов robots.txt. Для этого я подсчитал, сколько разных доменов полностью банят конкретный useragent — и отранжировал их по этому показателю:
В списке боты нескольких определённых типов.
Первая группа — краулеры, которые собирают данные для SEO и маркетингового анализа. Эти фирмы хотят получить как можно больше данных для своей аналитики — генерируя заметную нагрузку на многие сервера. Бот Ahrefs даже хвастается: «AhrefsBot — второй самый активный краулер после Googlebot», так что вполне понятно, почему люди хотят заблокировать этих надоедливых ботов. Majestic (MJ12Bot) позиционирует себя как инструмент конкурентной разведки. Это значит, что он скачивает ваш сайт, чтобы снабдить полезной информацией ваших конкурентов — и тоже на главной странице заявляет о «крупнейшем в мире индексе ссылок».
Вторая группа user-agents — от инструментов, которые стремятся быстро скачать веб-сайт для персонального использования в офлайне. Инструменты вроде WebCopier, Webstripper и Teleport — все они быстро скачивают полную копию веб-сайта на ваш жёсткий диск. Проблема в скорости многопоточного скачивания: все эти инструменты очевидно настолько забивают трафик, что сайты достаточно часто их запрещают.
Наконец, есть поисковые системы вроде Baidu (BaiduSpider) и Yandex, которые могут агрессивно индексировать контент, хотя обслуживают только языки/рынки, которые не обязательно очень ценны для определённых сайтов. Лично у меня оба эти краулера генерируют немало трафика, так что я бы не советовал блокировать их.
Это знак времени, что файлы, которые предназначены для чтения роботами, часто содержат объявления о найме на работу разработчиков программного обеспечения — особенно специалистов по SEO.
В каком-то роде это первая в мире (и, наверное, единственная) биржа вакансий, составленная полностью из описаний файлов robots.txt. (В оригинальной статье представлены тексты всех 67 вакансий из файлов robots.txt — прим. пер.).
Есть некоторая ирония в том, что Ahrefs.com, разработчик второго среди самых забаненных ботов, тоже поместила в своём файле robots.txt объявление о поиске SEO-специалиста. А ещё у pricefalls.com объявление о работе в файле robots.txt следует после записи «Предупреждение: краулинг Pricefalls запрещён, если у вас нет письменного разрешения».
Весь код для этой статьи — на GitHub.
По существу, это довольно важные файлы. Так что я решил скачать файл robots.txt с каждого из 1 миллиона самых посещаемых сайтов на планете и посмотреть, какие шаблоны удастся обнаружить.
Я взял список 1 млн крупнейших сайтов от Alexa и написал маленькую программу для скачивания файла robots.txt с каждого домена. После скачивания всех данных я пропустил каждый файл через питоновский пакет urllib.robotparser и начал изучать результаты.
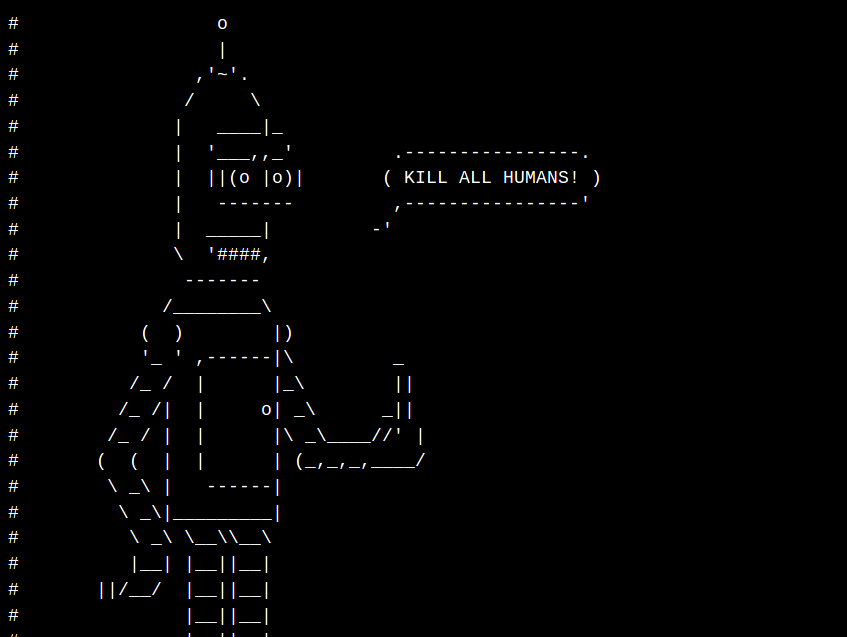
Найдено в yangteacher.ru/robots.txt
Огороженные сады: банят всех, кроме Google
Среди моих любимых питомцев — сайты, которые позволяют индексировать содержимое только боту Google и банят всех остальных. Например, файл robots.txt сайта Facebook начинается со следующих строк:
Notice: Crawling Facebook is prohibited unless you have express written permission. See: http://www.facebook.com/apps/site_scraping_tos_terms.php http://www.facebook.com/apps/site_scraping_tos_terms.php)Это слегка лицемерно, потому что сам Facebook начал работу с краулинга профилей студентов на сайте Гарвардского университета — именно такого рода активность они сейчас запрещают всем остальным.
Требование письменного разрешения перед началом краулинга сайта плюёт в лицо идеалам открытого интернета. Оно препятствует научным исследованиям и ставит барьер для развития новых поисковых систем: например, поисковику DuckDuckGo запрещено скачивать страницы Facebook, а поисковику Google можно.
В донкихотском порыве назвать и посрамить сайты, которые проявляют такое поведение, я написал простой скрипт, который проверяет домены и определяет тех, которые внесли Google в белый список тех, кому разрешено индексировать главную страницу. Вот самые популярные из этих доменов:
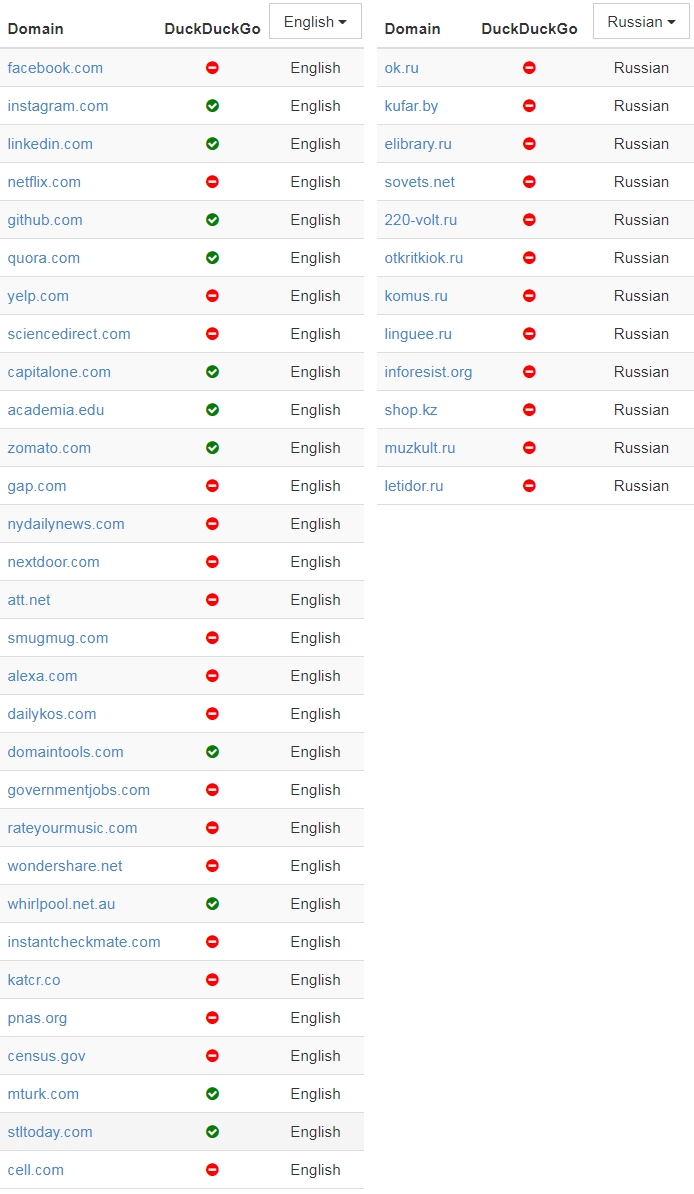
(В оригинальной статье указаны также аналогичные списки китайских, французских и немецких доменов — прим. пер.)
Я включил в таблицу пометку, позволяет ли сайт ещё DuckDuckGo индексировать свою заглавную страницу, в попытке показать, насколько тяжело приходится в наши дни новым поисковым системам.
У большинства из доменов в верхней части списка — таких как Facebook, LinkedIn, Quora и Yelp — есть одно общее. Все они размещают созданный пользователями контент, который представляет собой главную ценность их бизнеса. Это один из их главных активов, и компании не хотят отдавать его бесплатно. Впрочем, ради справедливости, такие запреты часто представляются как защита приватности пользователей, как в этом заявлении технического директора Facebook о решении забанить краулеры или глубоко в файле robots.txt от Quora, где объясняется, почему сайт забанил Wayback Machine.
Далее по списку результаты становятся более противоречивыми — например, мне не совсем понятно, почему census.gov позволяет доступ к своему контенту только трём основным поисковым системам, но блокирует DuckDuckGo. Логично предположить, что данные государственных переписей принадлежат народу, а не только Google/Microsoft/Yahoo.
Хотя я не фанат подобного поведения, но вполне могу понять импульсивную попытку внести в белый список только определённые краулеры, если учесть количество плохих ботов вокруг.
Боты плохого поведения
Я хотел попробовать ещё кое-что: определить самые плохие веб-краулеры в интернете, с учётом коллективного мнения миллиона файлов robots.txt. Для этого я подсчитал, сколько разных доменов полностью банят конкретный useragent — и отранжировал их по этому показателю:
| user-agent | Тип | Количество |
|---|---|---|
| MJ12bot | SEO | 15156 |
| AhrefsBot | SEO | 14561 |
| Baiduspider | Поисковая система | 11473 |
| Nutch | Поисковая система | 11023 |
| ia_archiver | SEO | 10477 |
| WebCopier | Архивация | 9538 |
| WebStripper | Архивация | 8579 |
| Teleport | Архивация | 7991 |
| Yandex | Поисковая система | 7910 |
| Offline Explorer | Архивация | 7786 |
| SiteSnagger | Архивация | 7744 |
| psbot | Поисковая система | 7605 |
| TeleportPro | Архивация | 7063 |
| EmailSiphon | Спамерский скрапер | 6715 |
| EmailCollector | Спамерский скрапер | 6611 |
| larbin | Неизвестно | 6436 |
| BLEXBot | SEO | 6435 |
| SemrushBot | SEO | 6361 |
| MSIECrawler | Архивация | 6354 |
| moget | Неизвестно | 6091 |
В списке боты нескольких определённых типов.
Первая группа — краулеры, которые собирают данные для SEO и маркетингового анализа. Эти фирмы хотят получить как можно больше данных для своей аналитики — генерируя заметную нагрузку на многие сервера. Бот Ahrefs даже хвастается: «AhrefsBot — второй самый активный краулер после Googlebot», так что вполне понятно, почему люди хотят заблокировать этих надоедливых ботов. Majestic (MJ12Bot) позиционирует себя как инструмент конкурентной разведки. Это значит, что он скачивает ваш сайт, чтобы снабдить полезной информацией ваших конкурентов — и тоже на главной странице заявляет о «крупнейшем в мире индексе ссылок».
Вторая группа user-agents — от инструментов, которые стремятся быстро скачать веб-сайт для персонального использования в офлайне. Инструменты вроде WebCopier, Webstripper и Teleport — все они быстро скачивают полную копию веб-сайта на ваш жёсткий диск. Проблема в скорости многопоточного скачивания: все эти инструменты очевидно настолько забивают трафик, что сайты достаточно часто их запрещают.
Наконец, есть поисковые системы вроде Baidu (BaiduSpider) и Yandex, которые могут агрессивно индексировать контент, хотя обслуживают только языки/рынки, которые не обязательно очень ценны для определённых сайтов. Лично у меня оба эти краулера генерируют немало трафика, так что я бы не советовал блокировать их.
Объявления о работе
Это знак времени, что файлы, которые предназначены для чтения роботами, часто содержат объявления о найме на работу разработчиков программного обеспечения — особенно специалистов по SEO.
В каком-то роде это первая в мире (и, наверное, единственная) биржа вакансий, составленная полностью из описаний файлов robots.txt. (В оригинальной статье представлены тексты всех 67 вакансий из файлов robots.txt — прим. пер.).
Есть некоторая ирония в том, что Ahrefs.com, разработчик второго среди самых забаненных ботов, тоже поместила в своём файле robots.txt объявление о поиске SEO-специалиста. А ещё у pricefalls.com объявление о работе в файле robots.txt следует после записи «Предупреждение: краулинг Pricefalls запрещён, если у вас нет письменного разрешения».
Весь код для этой статьи — на GitHub.
