Мне казалось, что поисковики давно победили black hat тактики с помощью машинного обучения и других мощных технологий. Сети дорвеев если и остались, то только где-то на обочине интернета, в маргинальных тематиках типа казино или контента для взрослых.
Но недавно я наткнулся сразу на целую кучу спамных сайтов, которые собирают миллионы посетителей из Яндекса, легко побеждают качественные и авторитетные проекты даже в белых нишах.
Для запросов, по которым очень важна актуальность информации, Яндекс подмешивает в обычную поисковую выдачу самые свежие документы. Это звучит логично, не все сайты попадают в Яндекс Новости, свежая статья блоггера о ДТП в Пензе может быть более качественным ответом на вопрос пользователя, чем старая новость на авторитетном сайте.
Но есть два странных момента:
Первые позиции по таким запросам обычно отдаются страницам, которые были опубликованы в течение нескольких последних часов. Помимо отметки о возрасте документа справа от сниппета, эти страницы отличаются наличием в URL сохраненной копии параметра src=FT. Например,
Устаревая, эти документы спускается в выдаче ниже, перемешиваются с основной выдачей, многие выпадают совсем.
Если с помощью Serpstat или Advodka посмотреть выдачу по другим запросам, по которым ранжируются найденные сайты, вы увидите десятки таких проектов. Они специализируются на получении псевдо-новостного трафика, месячная посещаемость некоторых из них доходит до десятков миллионов визитов.
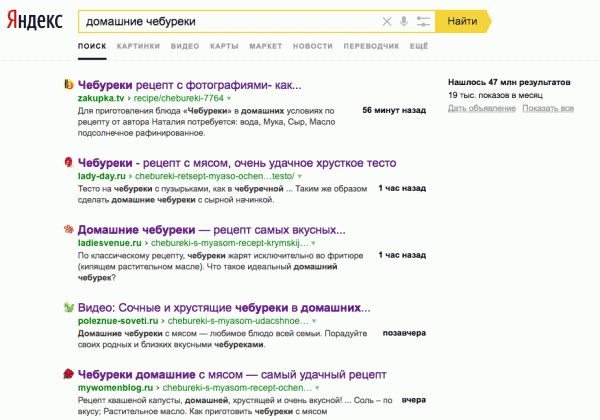
Разберем несколько страниц, находящихся в топ 5 по запросу «домашние чебуреки» (см скриншот в начале поста). Чтобы определить действительно ли тексты являются новыми и актуальным, будем в Яндексе и Google искать закавыченные куски этих текстов. Это поможет нам найти документы с точным вхождением искомого куска текста.
По первому сайту дубликатов найти не удалось, а вот второй сайт
lady-day .ru/chebureki-retsept-myaso-ochen-udachnoe-testo/ сразу вызвал вопросы.
На странице liveinternet .ru/users/5168383/post329973643/ эту статью скопировали еще в 2014, Google в последний раз проиндексировал статью 4 ноября, в кеше на самой странице указано, что статья опубликована 4 ноября 2017. В текущей версии дата публикации — 9 ноября 2017. Сайт явно многократно переопубликовывал статью для манипуляции выдачей Яндекса.
Следующий сайт — ladiesvenue .ru/chebureki-s-myasom-recept-krymskij-ochen-udachnoe-xrustkoe-testo/. В кеше Яндекса есть этот же текст на этом же сайте, но опубликованный 4 дня назад, на это указывает url в кеше ladiesvenue .ru/05-11-2017-sochnye-chebureki-recept-klassicheskij-samyj-vkusnyj-s-foto/. Причем эта страница тоже есть в выдаче по запросу «домашние чебуреки». Почему-то Яндекс не может определить дубликат даже внутри одного сайта. По закавыченному куску текста находятся еще сразу несколько аналогичных сайтов.
Следующий — poleznue-soveti .ru/chebureki-s-myasom-udacshnoe-testo.html. По закавыченному куску текста Google находит полную копию этой статьи, но на другом сайте, проиндексированную 11 дней назад. Яндекс тоже проиндексировал эту страницу, но все равно считает, что свежий дубликат актуальнее других сайтов.
С mywomenblog .ru/chebureki-s-myasom-recept-ochen-udachnoe-xrustkoe-testo-36187/ аналогичная ситуация, находится закешированный текст другого сайта, тоже проиндексированный 11 дней назад.
Эти сайты размещают свой и чужой ранее опубликованный контент под новыми датами, компилируют из нескольких чужих статей новую статью. Но по другим запросам встречаются и совсем патологические ситуации — страницы со сгенерированным бессмысленным текстом, например, такие:
healtherbal .ru/news/klassicheskaya-vozdushnaya-sharlotka-s-yablokami-b-retsept-b-s-foto-vsyo-chto-izvestno.html
jurnal24 .ru/vkusnaya-sharlotka-s-yablokami-prostoj-recept-vsyo-chto-izvestno-na-dannyj-moment/

Мне не удалось найти повторяющихся признаков в верстке таких сайтов. Некоторые применяют только микроразметку, некоторые — просто явным образом указывают дату публикации, некоторые комбинируют оба способа.
Не удалось найти подтверждений, что Яндекс выводит эти страницы ориентируясь на ссылки с других сайтов, у большинства страниц их нет.
Единственная закономерность помимо актуальной даты — в основном выходят сайты, которые занимаются добыванием только такого трафика. Возможно, наличие большого количества страниц релевантных псевдо-новостным запросам является позитивным сигналом для Яндекса.
Похоже, что достаточно просто собрать подходящие запросы, выбрать под них релевантные статьи других проектов и с нескольких сайтов публиковать их под разными URL, указывая текущее время и дату публикации. Возможно, один текст можно опубликовать ограниченное число раз, я встречал не так много копий. Они в основном обнаруживались в Google, не в Яндексе. Скорее всего для максимизации результата, сайты публикуют их в оптимальное время перед пиками дневного трафика в выбранной нише.
По ряду запросов, этим сайтам удается обмануть и Яндекс Новости, выдавая рецепты за новости:
Вспомнил, что еще в марте знакомый мне рассказывал о том, что выдачу по рецептам заполоняют страницы с текущей датой публикации, но не придал этому значению. Судя по трендам посещаемости встреченных мною сайтов, проблема существует минимум несколько лет.
На прошлой неделе я отправил жалобу на поисковой спам, надеюсь, что сотрудники Яндекса обратят на нее внимание.
Но недавно я наткнулся сразу на целую кучу спамных сайтов, которые собирают миллионы посетителей из Яндекса, легко побеждают качественные и авторитетные проекты даже в белых нишах.
Для запросов, по которым очень важна актуальность информации, Яндекс подмешивает в обычную поисковую выдачу самые свежие документы. Это звучит логично, не все сайты попадают в Яндекс Новости, свежая статья блоггера о ДТП в Пензе может быть более качественным ответом на вопрос пользователя, чем старая новость на авторитетном сайте.
Но есть два странных момента:
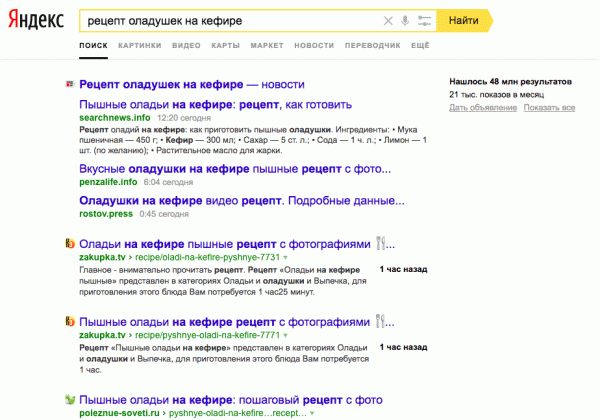
- Появляются такие ответы для довольно неожиданных запросов, для которых актуальность измеряется явно не часами или днями. Например, «рецепт оладушек на кефире» или «домашние чебуреки».
- Для ранжирования Яндекс использует алгоритмы, которые значительно отличаются от алгоритмов основной выдачи. Например, игнорируется, что контент неуникальный или сгенерированный.
Особые приметы
Первые позиции по таким запросам обычно отдаются страницам, которые были опубликованы в течение нескольких последних часов. Помимо отметки о возрасте документа справа от сниппета, эти страницы отличаются наличием в URL сохраненной копии параметра src=FT. Например,
http://hghltd.yandex.net/yandbtm?fmode=inject&url=https%3A%2F%2Fzakupka.tv%2Frecipe%2Fchebureki-7764&tld=ru&la=1510220416&tm=1510221945&text=%D0%B4%D0%BE%D0%BC%D0%B0%D1%88%D0%BD%D0%B8%D0%B5%20%D1%87%D0%B5%D0%B1%D1%83%D1%80%D0%B5%D0%BA%D0%B8&l10n=ru&isu=1&dsn=0&sg=vla1-0074.search.yandex.net%3A7301&sh=-1&d=4900&src=FT&mime=html&sign=287713794a48239813318f67a221cb09&keyno=0Устаревая, эти документы спускается в выдаче ниже, перемешиваются с основной выдачей, многие выпадают совсем.
Если с помощью Serpstat или Advodka посмотреть выдачу по другим запросам, по которым ранжируются найденные сайты, вы увидите десятки таких проектов. Они специализируются на получении псевдо-новостного трафика, месячная посещаемость некоторых из них доходит до десятков миллионов визитов.
Примеры
Разберем несколько страниц, находящихся в топ 5 по запросу «домашние чебуреки» (см скриншот в начале поста). Чтобы определить действительно ли тексты являются новыми и актуальным, будем в Яндексе и Google искать закавыченные куски этих текстов. Это поможет нам найти документы с точным вхождением искомого куска текста.
По первому сайту дубликатов найти не удалось, а вот второй сайт
lady-day .ru/chebureki-retsept-myaso-ochen-udachnoe-testo/ сразу вызвал вопросы.
На странице liveinternet .ru/users/5168383/post329973643/ эту статью скопировали еще в 2014, Google в последний раз проиндексировал статью 4 ноября, в кеше на самой странице указано, что статья опубликована 4 ноября 2017. В текущей версии дата публикации — 9 ноября 2017. Сайт явно многократно переопубликовывал статью для манипуляции выдачей Яндекса.
Следующий сайт — ladiesvenue .ru/chebureki-s-myasom-recept-krymskij-ochen-udachnoe-xrustkoe-testo/. В кеше Яндекса есть этот же текст на этом же сайте, но опубликованный 4 дня назад, на это указывает url в кеше ladiesvenue .ru/05-11-2017-sochnye-chebureki-recept-klassicheskij-samyj-vkusnyj-s-foto/. Причем эта страница тоже есть в выдаче по запросу «домашние чебуреки». Почему-то Яндекс не может определить дубликат даже внутри одного сайта. По закавыченному куску текста находятся еще сразу несколько аналогичных сайтов.
Следующий — poleznue-soveti .ru/chebureki-s-myasom-udacshnoe-testo.html. По закавыченному куску текста Google находит полную копию этой статьи, но на другом сайте, проиндексированную 11 дней назад. Яндекс тоже проиндексировал эту страницу, но все равно считает, что свежий дубликат актуальнее других сайтов.
С mywomenblog .ru/chebureki-s-myasom-recept-ochen-udachnoe-xrustkoe-testo-36187/ аналогичная ситуация, находится закешированный текст другого сайта, тоже проиндексированный 11 дней назад.
Эти сайты размещают свой и чужой ранее опубликованный контент под новыми датами, компилируют из нескольких чужих статей новую статью. Но по другим запросам встречаются и совсем патологические ситуации — страницы со сгенерированным бессмысленным текстом, например, такие:
healtherbal .ru/news/klassicheskaya-vozdushnaya-sharlotka-s-yablokami-b-retsept-b-s-foto-vsyo-chto-izvestno.html
jurnal24 .ru/vkusnaya-sharlotka-s-yablokami-prostoj-recept-vsyo-chto-izvestno-na-dannyj-moment/
Как они это делают?
Мне не удалось найти повторяющихся признаков в верстке таких сайтов. Некоторые применяют только микроразметку, некоторые — просто явным образом указывают дату публикации, некоторые комбинируют оба способа.
Не удалось найти подтверждений, что Яндекс выводит эти страницы ориентируясь на ссылки с других сайтов, у большинства страниц их нет.
Единственная закономерность помимо актуальной даты — в основном выходят сайты, которые занимаются добыванием только такого трафика. Возможно, наличие большого количества страниц релевантных псевдо-новостным запросам является позитивным сигналом для Яндекса.
Похоже, что достаточно просто собрать подходящие запросы, выбрать под них релевантные статьи других проектов и с нескольких сайтов публиковать их под разными URL, указывая текущее время и дату публикации. Возможно, один текст можно опубликовать ограниченное число раз, я встречал не так много копий. Они в основном обнаруживались в Google, не в Яндексе. Скорее всего для максимизации результата, сайты публикуют их в оптимальное время перед пиками дневного трафика в выбранной нише.
По ряду запросов, этим сайтам удается обмануть и Яндекс Новости, выдавая рецепты за новости:
Вспомнил, что еще в марте знакомый мне рассказывал о том, что выдачу по рецептам заполоняют страницы с текущей датой публикации, но не придал этому значению. Судя по трендам посещаемости встреченных мною сайтов, проблема существует минимум несколько лет.
На прошлой неделе я отправил жалобу на поисковой спам, надеюсь, что сотрудники Яндекса обратят на нее внимание.
