В прошлых статьях мы рассмотрели механизм индексирования PostgreSQL, интерфейс методов доступа и следующие методы: хеш-индексы, B-деревья, GiST, SP-GiST, GIN и RUM. Тема этой статьи — BRIN-индексы.
BRIN
Общая идея
В отличие от индексов, с которыми мы уже познакомились, идея BRIN не в том, чтобы быстро найти нужные строки, а в том, чтобы избежать просмотра заведомо ненужных. Это всегда неточный индекс: он вообще не содержит TID-ов табличных строк.
Упрощенно говоря, BRIN хорошо работает для тех столбцов, значения в которых коррелируют с их физическим расположением в таблице. Иными словами, если запрос без предложения ORDER BY выдает значения столбца практически в порядке возрастания или убывания (и при этом по столбцу нет индексов).
Метод доступа создавался в рамках европейского проекта по сверхбольшим аналитическим базам данных Axle с прицелом на таблицы размером в единицы и десятки терабайт. Важное свойство BRIN, позволяющее создавать индексы на таких таблицах — небольшой размер и минимальные накладные расходы на поддержание.
Работает это следующим образом. Таблица разбивается на зоны (range) размером в несколько страниц (или блоков, что то же самое) — отсюда и название: Block Range Index, BRIN. Для каждой зоны в индексе сохраняется сводная информация о данных в этой зоне. Как правило, это минимальное и максимальное значения, но бывает и иначе, как мы увидим дальше. Если при выполнении запроса, содержащего условие на столбец, искомые значения не попадают в диапазон, то всю зону можно смело пропускать; если же попадают — все строки во всех блоках зоны придется просмотреть и выбрать среди них подходящие.
Не будет ошибкой рассматривать BRIN не как индекс в обычном понимании, а как ускоритель последовательного сканирования таблицы. Можно посмотреть на него и как на альтернативу секционированию, если каждую зону считать отдельной «виртуальной» секцией.
Теперь рассмотрим устройство индекса более подробно.
Устройство
Первой (точнее, нулевой) в индексе идет страница с метаданными.
С некоторым отступом от метаданных находятся страницы со сводной информацией. Каждая индексная строка содержит сводку по какой-то одной зоне.
А между метастраницей и сводными данными располагаются страницы с обратной картой зон (reverse range map, сокращенно revmap). По сути, это массив указателей (TID-ов) на соответствующие индексные строки.
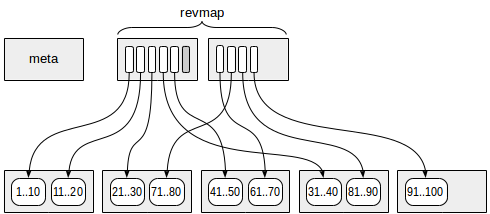
Для некоторых зон указатель в revmap может не вести ни к какой индексной строке (на рисунке отмечен серым цветом). В этом случае считается, что для этой зоны еще нет сводной информации.
Сканирование индекса
Как используется индекс, если он не содержит ссылок на табличные строки? Конечно, возвращать строки одну за другой этот метод доступа не умеет, зато он может построить битовую карту. Страницы битовой карты бывает двух типов: точные — до строки — и неточные — до страницы. Именно неточная битовая карта и используется.
Алгоритм простой. Последовательно просматривается карта зон (то есть зоны перебираются в порядке их расположения в таблице). С помощью указателей определяются индексные строки со сводной информацией по каждой зоне. Если зона точно не содержит искомого значения, она пропускается; если может содержать (или если сводная информация отсутствует) — все страницы зоны добавляются к битовой карте. Получившаяся битовая карта используется дальше как обычно.
Обновление индекса
Интереснее обстоит дело с обновлением индекса при изменении таблицы.
При добавлении новой версии строки в табличную страницу мы определяем, к какой зоне она принадлежит, и по карте зон находим индексную строку со сводной информацией. Все это — простые арифметические операции. Пусть, например, размер зоны — 4 страницы, и на странице 13 появилась версия строки со значением «42». Номер зоны (начиная с нуля) равен 13 / 4 = 3, значит в revmap берем указательно со смещением 3 (четвертый по счету).
Минимальное значение для этой зоны — 31, максимальное — 40. Поскольку новое значение 42 выходит за эти пределы, обновляем максимальное значение (см. рисунок). Если же новое значение укладывается в существующие рамки, индекс обновлять не нужно.
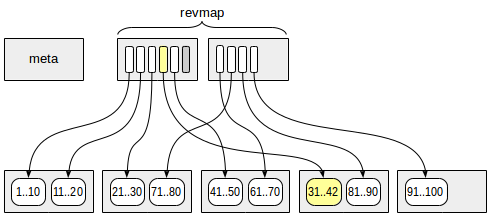
Все это касается случая, когда новая версия строки появляется в зоне, для которой уже есть сводная информация. При построении индекса сводная информация вычисляется для всех существующих зон, но при дальнейшем росте таблицы могут появиться новые страницы, выходящие за этот диапазон. Тут возможны два варианта:
- Обычно немедленного обновления индекса не происходит. Ничего страшного в этом нет; как мы говорили, при сканировании индекса будет просмотрена вся зона целиком. Фактически же обновление выполняется при очистке (vacuum), либо его можно выполнить вручную, вызвав функцию brin_summarize_new_values.
- Если создать индекс с параметром autosummarize, то обновление будет происходить немедленно. Но при заполнении страниц зоны новыми значениями обновление может выполняться очень часто, поэтому этот параметр и выключен по умолчанию.
При появлении новых зон размер revmap может увеличиться. Если эта карта перестает помещаться в отведенные ей страницы, она просто «захватывает» следующую, а все версии строк, которые там были, перемещаются на другие страницы. Таким образом, карта зон всегда располагается между метастраницей и сводными данными.
При удалении строки… ничего не происходит. Можно заметить, что в каких-то случаях будет удалено минимальное или максимальное значение, и тогда диапазон можно было бы уменьшить. Но чтобы это определить, пришлось бы прочитать все значения в зоне, а это накладно.
Корректность индекса от этого не страдает, однако при поиске может потребоваться просмотреть больше зон, чем реально необходимо. В принципе, по такой зоне можно вручную пересобрать сводную информацию (вызвать функции brin_desummarize_range и brin_summarize_new_values), но как обнаружить такую необходимость? Во всяком случае, никакой штатной процедуры для этого не предусмотрено.
Ну и обновление строки — это просто удаление старой версии и добавление новой.
Пример
Попробуем построить свое мини-хранилище данных на основе таблиц демонстрационной базы данных. Допустим, для нужд BI-отчетности нужна денормализованная таблица, отражающая вылетевшие из аэропорта либо приземлившиеся в аэропорт рейсы с точностью до места в салоне. Данные по каждому аэропорту будут добавляться в таблицу раз в сутки, как только в соответствующем часовом поясе наступает полночь. Данные не будут ни изменяться, ни удаляться.
Таблица будет иметь такой вид:
demo=# create table flights_bi(
airport_code char(3), -- код аэропорта
airport_coord point, -- координаты аэропорта
airport_utc_offset interval, -- часовой пояс
flight_no char(6), -- номер рейса
flight_type text. -- тип рейса: departure (вылет) / arrival (прибытие)
scheduled_time timestamptz, -- время вылета/прибытия рейса по расписанию
actual_time timestamptz, -- реальное время
aircraft_code char(3), -- код воздушного судна
seat_no varchar(4), -- номер места
fare_conditions varchar(10), -- класс обслуживания
passenger_id varchar(20), -- номер документа пассажира
passenger_name text -- имя пассажира
);
CREATE TABLE
Процедуру загрузки данных можно имитировать вложенными циклами: внешний по дням (мы возьмем базу данных большого размера, поэтому 365 дней), внутренний — по часовым поясам (от UTC+02 до UTC+12). Запрос довольно длинный и не представляет особого интереса, поэтому спрячу под спойлер.
Имитация загрузки данных в хранилище
DO $$
<<local>>
DECLARE
curdate date := (SELECT min(scheduled_departure) FROM flights);
utc_offset interval;
BEGIN
WHILE (curdate <= bookings.now()::date) LOOP
utc_offset := interval '12 hours';
WHILE (utc_offset >= interval '2 hours') LOOP
INSERT INTO flights_bi
WITH flight (
airport_code,
airport_coord,
flight_id,
flight_no,
scheduled_time,
actual_time,
aircraft_code,
flight_type
) AS (
-- прибытия
SELECT a.airport_code,
a.coordinates,
f.flight_id,
f.flight_no,
f.scheduled_departure,
f.actual_departure,
f.aircraft_code,
'departure'
FROM airports a,
flights f,
pg_timezone_names tzn
WHERE a.airport_code = f.departure_airport
AND f.actual_departure IS NOT NULL
AND tzn.name = a.timezone
AND tzn.utc_offset = local.utc_offset
AND timezone(a.timezone, f.actual_departure)::date = curdate
UNION ALL
-- вылеты
SELECT a.airport_code,
a.coordinates,
f.flight_id,
f.flight_no,
f.scheduled_arrival,
f.actual_arrival,
f.aircraft_code,
'arrival'
FROM airports a,
flights f,
pg_timezone_names tzn
WHERE a.airport_code = f.arrival_airport
AND f.actual_arrival IS NOT NULL
AND tzn.name = a.timezone
AND tzn.utc_offset = local.utc_offset
AND timezone(a.timezone, f.actual_arrival)::date = curdate
)
SELECT f.airport_code,
f.airport_coord,
local.utc_offset,
f.flight_no,
f.flight_type,
f.scheduled_time,
f.actual_time,
f.aircraft_code,
s.seat_no,
s.fare_conditions,
t.passenger_id,
t.passenger_name
FROM flight f
JOIN seats s
ON s.aircraft_code = f.aircraft_code
LEFT JOIN boarding_passes bp
ON bp.flight_id = f.flight_id
AND bp.seat_no = s.seat_no
LEFT JOIN ticket_flights tf
ON tf.ticket_no = bp.ticket_no
AND tf.flight_id = bp.flight_id
LEFT JOIN tickets t
ON t.ticket_no = tf.ticket_no;
RAISE NOTICE '%, %', curdate, utc_offset;
utc_offset := utc_offset - interval '1 hour';
END LOOP;
curdate := curdate + 1;
END LOOP;
END;
$$;
demo=# select count(*) from flights_bi;
count
----------
30517076
(1 row)
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi'));
pg_size_pretty
----------------
4127 MB
(1 row)
Получилось 30 миллионов строк и 4 ГБ. Не бог весть какой объем, но для ноутбука годится: полное сканирование у меня выполняется около 10 секунд.
По каким столбцам строить индекс?
Поскольку BRIN-индексы имеют небольшой размер и невысокие накладные расходы, а обновления если и происходят, то нечасто, возникает та редкая ситуация, когда индексов можно создать много «на всякий случай», например, по всем полям, по которым пользователи-аналитики могут строить свои adhoc-запросы. Не пригодится — ладно, а даже не очень эффективный индекс все равно наверняка сработает лучше, чем полное сканирование. Конечно, есть поля, на которых индекс совсем бесполезен; их подскажет простой здравый смысл.
Но ограничиться таким советом было бы странно, поэтому попробуем сформулировать более точный критерий.
Мы говорили, что данные дожны некоторым образом коррелировать со своим физическим расположением. Тут уместно вспомнить, что PostgreSQL собирает статистику по полям таблиц, в которую входит и значение корреляции. Это значение используется планировщиком для выбора между обычным индексным сканированием и сканированием по битовой карте, а мы можем воспользоваться им для оценки пригодности BRIN-индекса.
В нашем примере данные, очевидно, упорядочены по дням (как по scheduled_time, так и по actual_time — разница небольшая). Происходит это потому, что при добавлении строк в таблицу (в отсутствии удалений и обновлений) они укладываются в файл последовательно, одна за другой. В имитации загрузки мы даже не использовали предложение ORDER BY, поэтому в пределах дня даты в принципе могут быть перемешаны как угодно, но упорядоченность обязана присутствовать. Проверим:
demo=# analyze flights_bi;
ANALYZE
demo=# select attname, correlation from pg_stats where tablename='flights_bi'
order by correlation desc nulls last;
attname | correlation
--------------------+-------------
scheduled_time | 0.999994
actual_time | 0.999994
fare_conditions | 0.796719
flight_type | 0.495937
airport_utc_offset | 0.438443
aircraft_code | 0.172262
airport_code | 0.0543143
flight_no | 0.0121366
seat_no | 0.00568042
passenger_name | 0.0046387
passenger_id | -0.00281272
airport_coord |
(12 rows)
Значение, не слишком близкое к нулю (а в идеале — около плюс-минус единицы, как в нашем случае), говорит о том, что BRIN-индекс будет уместен.
На втором и третьем местах неожиданно оказались класс обслуживания fare_condition (столбец содержит три уникальных значения) и тип рейса flight_type (два уникальных значения). Это обманка: формально корреляция высокая, но на деле в нескольких подряд взятых страницах наверняка обнаружатся все возможные значения — а это значит, что толка от BRIN не будет.
Следом идет часовой пояс airport_utc_offset: в нашем примере внутри одного дневного цикла аэропорты «по построению» упорядочены по часовым поясам.
С этими двумя полями — временем и часовым поясом — мы и будем дальше экспериментировать.
Возможное нарушение корреляции
Сложившуюся «по построению» корреляцию легко нарушить, изменяя данные. И дело здесь не в изменении какого-то конкретного значения, а в устройстве многоверсионности: старая версия строки удаляется на одной странице, а вот новая может быть вставлена куда угодно, где есть свободное место. Из-за этого при обновлениях перемешиваются строки целиком.
Отчасти с этим явлением можно бороться, уменьшая значение параметра хранения fillfactor, оставляя тем самым запас места на странице под будущие обновления. Вот только захочется ли увеличивать объем и без того огромной таблицы? Кроме того, это не решает вопрос с удалениями: они тоже «готовят ловушки» для новых строк, освобождая место где-то внутри существующих страниц. Из-за этого строки, которые иначе попали бы в конец файла, будут вставлены в какое-то произвольное место.
Кстати, забавный факт. Поскольку в BRIN-индексе нет ссылок на табличные строки, его наличие никак не должно мешать HOT-обновлениям — однако мешает.
Итак, в первую очередь BRIN рассчитан на таблицы большого и даже огромного размера, которые либо вовсе не обновляются, либо обновляются очень незначительно. Однако с добавлением новых строк (в конец таблицы) он справляется прекрасно. Что и не удивительно, поскольку этот метод доступа и создавался с прицелом на хранилища данных и аналитическую отчетность.
Какой размер зоны выбрать?
Если мы имеем дело с терабайтной таблицей, то, пожалуй, основная забота при выборе размера зоны будет о том, чтобы BRIN-индекс не получился слишком большой. В нашем же случае мы можем позволить себе поанализировать данные более аккуратно.
Для этого мы можем выбрать уникальные значения столбца и посмотреть, на скольких страницах эти значения встречаются. Локализация значений увеличивает шансы на успешность применения BRIN-индекса. Более того, найденное количество страниц послужит подсказкой для определения размера зоны. Если же значение «размазано» по всем страницам таблицы — BRIN бесполезен.
Конечно, этот прием надо применять с изрядной оглядкой на внутреннюю структуру данных. Например, нам бессмысленно рассматривать каждую дату (а точнее, timestamp, включающий время) как уникальное значение — надо округлить до дней.
Чисто технически такой анализ можно выполнить, посмотрев на значение скрытого столбца ctid, который дает указатель на версию строки (TID): номер страницы и номер строки внутри страницы. К сожалению, нет штатного способа разложить TID на две его составляющие, поэтому приходится приводить типы через текстовое представление:
demo=# select min(numblk), round(avg(numblk)) avg, max(numblk)
from (
select count(distinct (ctid::text::point)[0]) numblk
from flights_bi
group by scheduled_time::date
) t;
min | avg | max
------+------+------
1192 | 1500 | 1796
(1 row)
demo=# select relpages from pg_class where relname = 'flights_bi';
relpages
----------
528172
(1 row)
Видим, что каждый день распределен по страницам достаточно равномерно, и дни слабо перемешаны друг с другом (1500 × 365 = 547500, что ненамного превышает число страниц в таблице 528172). Это, собственно, и так понятно «по построению».
Ценная информация здесь — конкретное число страниц. При стандартном размере зоны в 128 страниц каждый день будет занимать от 9 до 14 зон. Это представляется адекватным: при запросе по конкретному дню можно ожидать погрешность в районе 10 %.
Давайте попробуем:
demo=# create index on flights_bi using brin(scheduled_time);
CREATE INDEX
Размер индекса всего-навсего 184 КБ:
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_idx'));
pg_size_pretty
----------------
184 kB
(1 row)
Увеличивать размер зоны, жертвуя точностью, в этом случае вряд ли имеет смысл. А уменьшить при желании можно — тогда наоборот, точность увеличится (вместе с размером индекса).
Теперь посмотрим на часовые пояса. Тут тоже нельзя действовать «в лоб» — все значения надо поделить на число дневных «циклов», поскольку распределение повторяется внутри каждого дня. Кроме того, поскольку часовых поясов немного, можно посмотреть все распределение целиком:
demo=# select airport_utc_offset, count(distinct (ctid::text::point)[0])/365 numblk
from flights_bi
group by airport_utc_offset
order by 2;
airport_utc_offset | numblk
--------------------+--------
12:00:00 | 6
06:00:00 | 8
02:00:00 | 10
11:00:00 | 13
08:00:00 | 28
09:00:00 | 29
10:00:00 | 40
04:00:00 | 47
07:00:00 | 110
05:00:00 | 231
03:00:00 | 932
(11 rows)
В среднем данные каждого часового пояса занимают 133 страницы за день, но распределение очень неравномерное: Петропавлоск-Камчатский и Анадырь укладываются всего в шесть страниц, а Москва и окрестности требуют девяти сотен. Размер зоны по умолчанию тут точно не годится; давайте для примера поставим 4 страницы.
demo=# create index on flights_bi using brin(airport_utc_offset) with (pages_per_range=4);
CREATE INDEX
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_airport_utc_offset_idx'));
pg_size_pretty
----------------
6528 kB
(1 row)
План выполнения
Посмотрим теперь, как работают наши индексы. Выберем какой-нибудь день, скажем, неделю назад («сегодня» определяется в демо-базе функцией bookings.now):
demo=# \set d 'bookings.now()::date - interval \'7 days\''
demo=# explain (costs off,analyze)
select *
from flights_bi
where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on flights_bi (actual time=10.282..94.328 rows=83954 loops=1)
Recheck Cond: ...
Rows Removed by Index Recheck: 12045
Heap Blocks: lossy=1664
-> Bitmap Index Scan on flights_bi_scheduled_time_idx
(actual time=3.013..3.013 rows=16640 loops=1)
Index Cond: ...
Planning time: 0.375 ms
Execution time: 97.805 ms
Как видим, планировщик использовал созданный индекс. Насколько он точен? Об этом говорит соотношение числа строк, удовлетворяющих условиям выборки (rows узла Bitmap Heap Scan), к общему числу строк, которое было получено с помощью индекса (то же плюс Rows Removed by Index Recheck). В нашем случае 83954 / (83954 + 12045) — примерно 90 %, как и ожидалось (ото дня ко дню это значение будет меняться).
Откуда появилось число 16640 в actual rows узла Bitmap Index Scan? Дело в том, что этот узел плана строит неточную (постраничную) битовую карту и понятия не имеет, сколько строк она затронет, а показать что-то надо. Поэтому от безысходности считается, что на каждой странице мы найдем 10 строк. Всего битовая карта содержит 1664 страниц (это значение видно из «Heap Blocks: lossy=1664») — получается как раз 16640. В общем, это бессмысленное число, на него не надо обращать внимание.
Что с аэропортами? Для примера возьмем часовой пояс Владивостока, занимающий 28 страниц в день:
demo=# explain (costs off,analyze)
select *
from flights_bi
where airport_utc_offset = interval '8 hours';
QUERY PLAN
----------------------------------------------------------------------------------
Bitmap Heap Scan on flights_bi (actual time=75.151..192.210 rows=587353 loops=1)
Recheck Cond: (airport_utc_offset = '08:00:00'::interval)
Rows Removed by Index Recheck: 191318
Heap Blocks: lossy=13380
-> Bitmap Index Scan on flights_bi_airport_utc_offset_idx
(actual time=74.999..74.999 rows=133800 loops=1)
Index Cond: (airport_utc_offset = '08:00:00'::interval)
Planning time: 0.168 ms
Execution time: 212.278 ms
Снова планировщик использует созданный BRIN-индекс. Точность хуже (около 75 % в данном случае), но это ожидаемо: корреляция-то ниже.
Разумеется, несколько BRIN-индексов (как и любых других) могут комбинироваться на уровне битовой карты. Например, данные по выбранному часовому поясу за месяц:
demo=# \set d 'bookings.now()::date - interval \'60 days\''
demo=# explain (costs off,analyze)
select *
from flights_bi
where scheduled_time >= :d and scheduled_time < :d + interval '30 days'
and airport_utc_offset = interval '8 hours';
QUERY PLAN
---------------------------------------------------------------------------------
Bitmap Heap Scan on flights_bi (actual time=62.046..113.849 rows=48154 loops=1)
Recheck Cond: ...
Rows Removed by Index Recheck: 18856
Heap Blocks: lossy=1152
-> BitmapAnd (actual time=61.777..61.777 rows=0 loops=1)
-> Bitmap Index Scan on flights_bi_scheduled_time_idx
(actual time=5.490..5.490 rows=435200 loops=1)
Index Cond: ...
-> Bitmap Index Scan on flights_bi_airport_utc_offset_idx
(actual time=55.068..55.068 rows=133800 loops=1)
Index Cond: ...
Planning time: 0.408 ms
Execution time: 115.475 ms
Сравнение с B-деревом
Что, если построить обычный индекс B-дерево по тому же полю, что и BRIN?
demo=# create index flights_bi_scheduled_time_btree on flights_bi(scheduled_time);
CREATE INDEX
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_btree'));
pg_size_pretty
----------------
654 MB
(1 row)
Он получился в несколько тысяч раз больше, чем наш BRIN! Правда, и скорость выполнения запроса немного увеличилась — планировщик понял по статистике, что данные физически упорядочены и не надо строить битовую карту, и, главное, не нужно перепроверять индексное условие:
demo=# explain (costs off,analyze)
select *
from flights_bi
where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN
----------------------------------------------------------------
Index Scan using flights_bi_scheduled_time_btree on flights_bi
(actual time=0.099..79.416 rows=83954 loops=1)
Index Cond: ...
Planning time: 0.500 ms
Execution time: 85.044 ms
В этом прелесть BRIN: жертвуем эффективностью, но выигрываем очень много места.
Классы операторов
minmax
Для типов данных, значения которых можно сравнивать между собой, сводная информация состоит из минимального и максимального значений. Соответствующие классы операторов содержат в названии minmax, например, date_minmax_ops. Собственно, их мы до сих пор и рассматривали, и таких большинство.
inclusive
Не для всех типов данных определены операции сравнения. Например, их нет для точек (тип point), которыми представлены координаты аэропортов. Кстати, именно поэтому статистика не показывает корреляцию для этого столбца:
demo=# select attname, correlation
from pg_stats
where tablename='flights_bi' and attname = 'airport_coord';
attname | correlation
---------------+-------------
airport_coord |
(1 row)
Но для многих из таких типов можно ввести понятие «ограничивающей области», например, ограничивающий прямоугольник для геометрических фигур. Мы подробно говорили о том, как это свойство используется индексом GiST. Аналогично и BRIN позволяет собирать сводную информацию о столбцах таких типов: ограничивающая область для всех значений внутри зоны и является сводным значением.
В отличие от GiST, сводное значение в BRIN должно быть того же типа, что и индексируемые данные. Поэтому, например, для точек индекс построить не удастся, хотя и понятно, что координаты могли бы работать в BRIN: долгота довольно сильно связана с часовым поясом. К счастью, никто не мешает создать индекс по выражению, преобразовав точки в вырожденные прямоугольники. Заодно установим размер зоны в одну страницу, просто чтобы показать предельный случай:
demo=# create index on flights_bi using brin (box(airport_coord)) with (pages_per_range=1);
CREATE INDEX
Даже в таком экстремальном варианте индекс занимает всего 30 МБ:
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_box_idx'));
pg_size_pretty
----------------
30 MB
(1 row)
Теперь мы можем писать запросы, ограничивая аэропорты координатами. Например, так:
demo=# select airport_code, airport_name
from airports
where box(coordinates) <@ box '120,40,140,50';
airport_code | airport_name
--------------+-----------------
KHV | Хабаровск-Новый
VVO | Владивосток
(2 rows)
Правда, планировщик откажется использовать наш индекс.
demo=# analyze flights_bi;
ANALYZE
demo=# explain select * from flights_bi
where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN
---------------------------------------------------------------------
Seq Scan on flights_bi (cost=0.00..985928.14 rows=30517 width=111)
Filter: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Почему? Давайте запретим полное сканирование и посмотрим.
demo=# set enable_seqscan = off;
SET
demo=# explain select * from flights_bi
where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on flights_bi (cost=14079.67..1000007.81 rows=30517 width=111)
Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
-> Bitmap Index Scan on flights_bi_box_idx
(cost=0.00..14072.04 rows=30517076 width=0)
Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Оказывается, индекс может использоваться, но планировщик полагает, что битовую карту придется построить по всей таблице целиком — неудивительно, что в таком случае он предпочитает полное сканирование. Проблема здесь в том, что для геометрических типов PostgreSQL не собирает никакой статистики, так что планировщику приходится действовать вслепую:
demo=# select * from pg_stats where tablename = 'flights_bi_box_idx' \gx
-[ RECORD 1 ]----------+-------------------
schemaname | bookings
tablename | flights_bi_box_idx
attname | box
inherited | f
null_frac | 0
avg_width | 32
n_distinct | 0
most_common_vals |
most_common_freqs |
histogram_bounds |
correlation |
most_common_elems |
most_common_elem_freqs |
elem_count_histogram |
Увы. Но к самому индексу претензий нет, он работает, и неплохо:
demo=# explain (costs off,analyze)
select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN
----------------------------------------------------------------------------------
Bitmap Heap Scan on flights_bi (actual time=158.142..315.445 rows=781790 loops=1)
Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Rows Removed by Index Recheck: 70726
Heap Blocks: lossy=14772
-> Bitmap Index Scan on flights_bi_box_idx
(actual time=158.083..158.083 rows=147720 loops=1)
Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Planning time: 0.137 ms
Execution time: 340.593 ms
Вывод, видимо, такой: если от геометрии нужно хоть что-то нетривиальное, нужен PostGIS. Во всяком случае, статистику он собирать умеет.
Внутри
Заглянуть внутрь BRIN-индекса позволяет штатное расширение pageinspect.
Во-первых, метаинформация подскажет нам размер зоны и сколько страниц отведено под revmap:
demo=# select * from brin_metapage_info(get_raw_page('flights_bi_scheduled_time_idx',0));
magic | version | pagesperrange | lastrevmappage
------------+---------+---------------+----------------
0xA8109CFA | 1 | 128 | 3
(1 row)
Здесь страницы с 1 по 3 — revmap, остальное — сводные данные. Можно получить из revmap ссылки на сводные данные каждой зоны. Скажем, информация о первой зоне, охватывающей первые 128 страниц таблицы, находится тут:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) limit 1;
pages
---------
(6,197)
(1 row)
А вот сами сводные данные:
demo=# select allnulls, hasnulls, value
from brin_page_items(get_raw_page('flights_bi_scheduled_time_idx',6), 'flights_bi_scheduled_time_idx')
where itemoffset = 197;
allnulls | hasnulls | value
----------+----------+----------------------------------------------------
f | f | {2016-08-15 02:45:00+03 .. 2016-08-15 17:15:00+03}
(1 row)
Следующая зона:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) offset 1 limit 1;
pages
---------
(6,198)
(1 row)
demo=# select allnulls, hasnulls, value from brin_page_items(get_raw_page('flights_bi_scheduled_time_idx',6), 'flights_bi_scheduled_time_idx') where itemoffset = 198;
allnulls | hasnulls | value
----------+----------+----------------------------------------------------
f | f | {2016-08-15 06:00:00+03 .. 2016-08-15 18:55:00+03}
(1 row)
И так далее.
Для inclusion-классов в поле value будет отображаться нечто наподобие
{(94.4005966186523,69.3110961914062),(77.6600036621,51.6693992614746) .. f .. f}
Первое значение — объемлющий прямоугольник, а буквы «f» в конце означают отсутствие пустых элементов (первая) и отсутствие значений, которые невозможно объединить (вторая). Собственно, единственный случай необъединяющихся значений — это адреса IPv4 и IPv6 (тип данных inet).
Свойства
Напомню, что соответствующие запросы приводились ранее.
Свойства метода:
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
brin | can_order | f
brin | can_unique | f
brin | can_multi_col | t
brin | can_exclude | f
Индексы можно создавать по нескольким столбцам. В этом случае по каждому столбцу собирается своя сводная информация, но для каждой зоны она хранится вместе. Конечно, такой индекс имеет смысл, если для всех столбцов подходит один и тот же размер зоны.
Свойства индекса:
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | f
bitmap_scan | t
backward_scan | f
Очевидно, что поддерживается только сканирование по битовой карте.
А вот отсутствие кластеризации может вызвать недоумение. Казалось бы, раз BRIN-индекс чувствителем к физическому порядку строк, то логично было бы и уметь кластеризовать данные по нему? Но нет, разве что можно создать «обычный» индекс (B-дерево или GiST, смотря по типу данных) и кластеризовать по нему. А впрочем, захочется ли вам кластеризовать предположительно огромную таблицу, учитывая эксклюзивную блокировку, время работы и расход места на диске во время перестроения?
Свойства уровня столбца:
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | f
search_array | f
search_nulls | t
Тут сплошные «прочерки», кроме возможности работы с неопределенными значениями.
Окончание.
