Всем добра!
Ну что ж. Первый поток курса DevOps выпущен, второй обучается вовсю и вот на подходе третий. Курс усовершенствуется, проект тоже, остаётся неизменным пока что одно: интересные статьи, которые мы пока что только переводим для вас, но на носу уже и срывы покровов с тех вещей, что у нас просили :)
Поехали!
Мы используем Kubernetes для исследования в области deep learning уже более двух лет. В то время, как наши самые масштабные нагрузки управляют облачными ВМ напрямую, Kubernetes обеспечивает быстрый итерационный цикл и масштабируемость, что делает его идеальным для наших экспериментов. Сейчас мы управляем несколькими Kubernetes кластерами (как облачными, так и на физическом оборудовании), самый крупный из них состоит из более 2500 нод — это кластер в Azure на комбинации виртуальных машин D15v2 и NC24.
Многие системные компоненты отказывали в процессе масштабирования, включая etcd, Kube мастеров, загрузки образов Docker, сети, KubeDNS и даже ARP кэши наших машин. Поэтому мы решили, что будет полезным поделиться, с какими проблемами мы столкнулись и как с ними справились.

etcd
После расширения кластера до 500 нод, наши исследователи стали получать регулярные таймауты в kubectl. Мы попробовали решить проблему, добавив больше Kube мастеров (ВМ, на которых запущен kube-apiserver). На первый взгляд, это помогло временно решить проблему, но, спустя 10 итераций, мы поняли, что пытаемся вылечить симптом, а не изначальную причину (для сравнения, GKE использует одну 32-ядерную ВМ для 500 нод).
Главным подозреваемым стал наш кластер etcd, который является центральным хранилищем состояний Kube мастеров. Посмотрев на графики Datadog, мы обнаружили задержки записи до сотен миллисекунд на наших DS15v2 машинах, где были запущены копии etcd, несмотря на то, что каждый сервер использовал P30 SSD, с производительностью в 5000 IOPS.
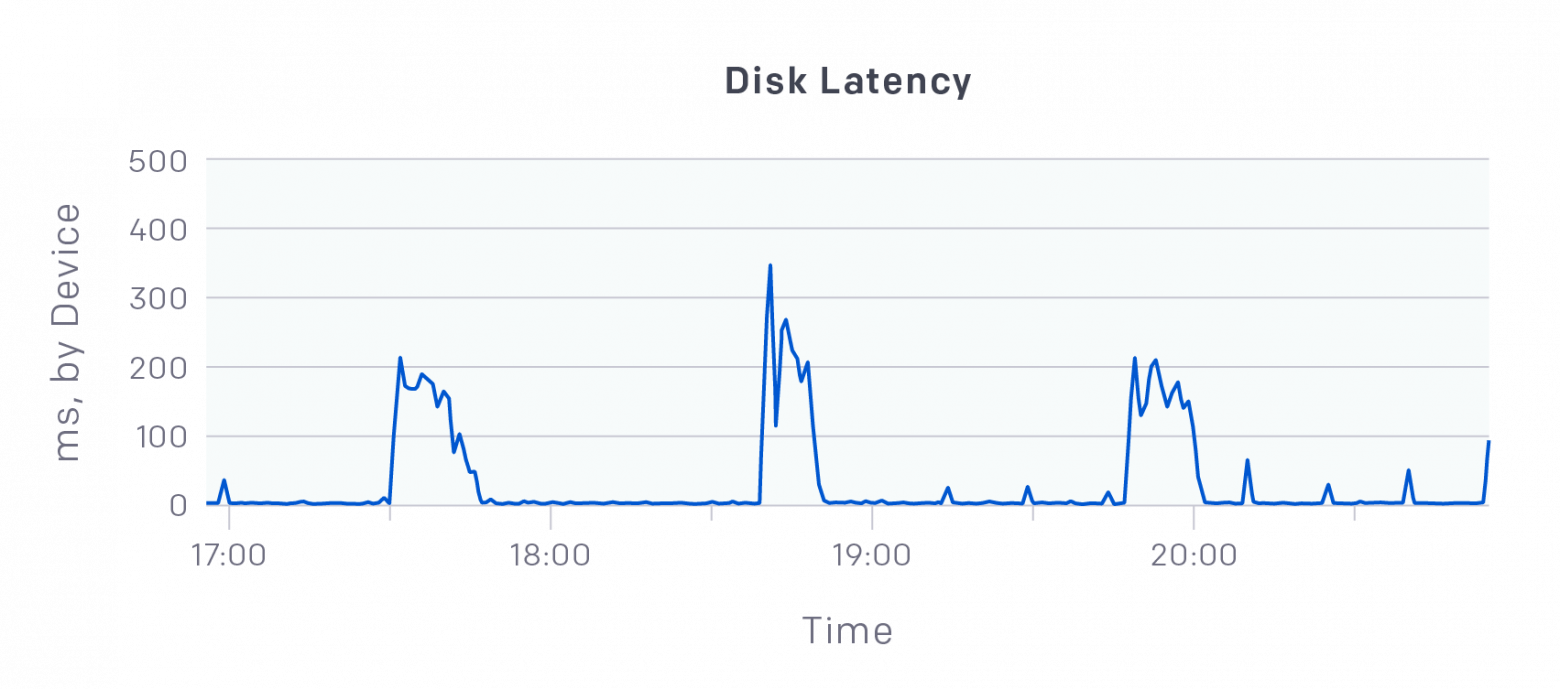
Эти всплески задержек блокируют весь кластер!
Тест на производительность с fio показал, что etcd может использовать только 10% IOPS из-за задержек записи в 2ms — etcd делает последовательный ввод-вывод, поэтому задержки его блокируют.
Для каждой ноды мы переместили директорию etcd в локальный временный диск, который подключен к SSD напрямую, а не по сети. Переход на локальный диск снизил задержки записи до 200us и вылечил etcd!
Проблема снова возникла, когда кластер увеличился до 1000 нод — мы опять столкнулись с большими задержками etcd. В этот раз, kube-apiservers читали более 500MB/s от etcd. Мы настроили Prometheus для мониторинга apiservers и добавили флаги
Основная проблема: настройки по умолчанию для процессов мониторинга Fluentd и Datadog заключались в создании запросов для apiservers с каждой ноды в кластере (например, эта проблема, которая сейчас решена). Мы сделали процесс опроса менее агрессивным, и загрузка apisevers снова стала стабильной:
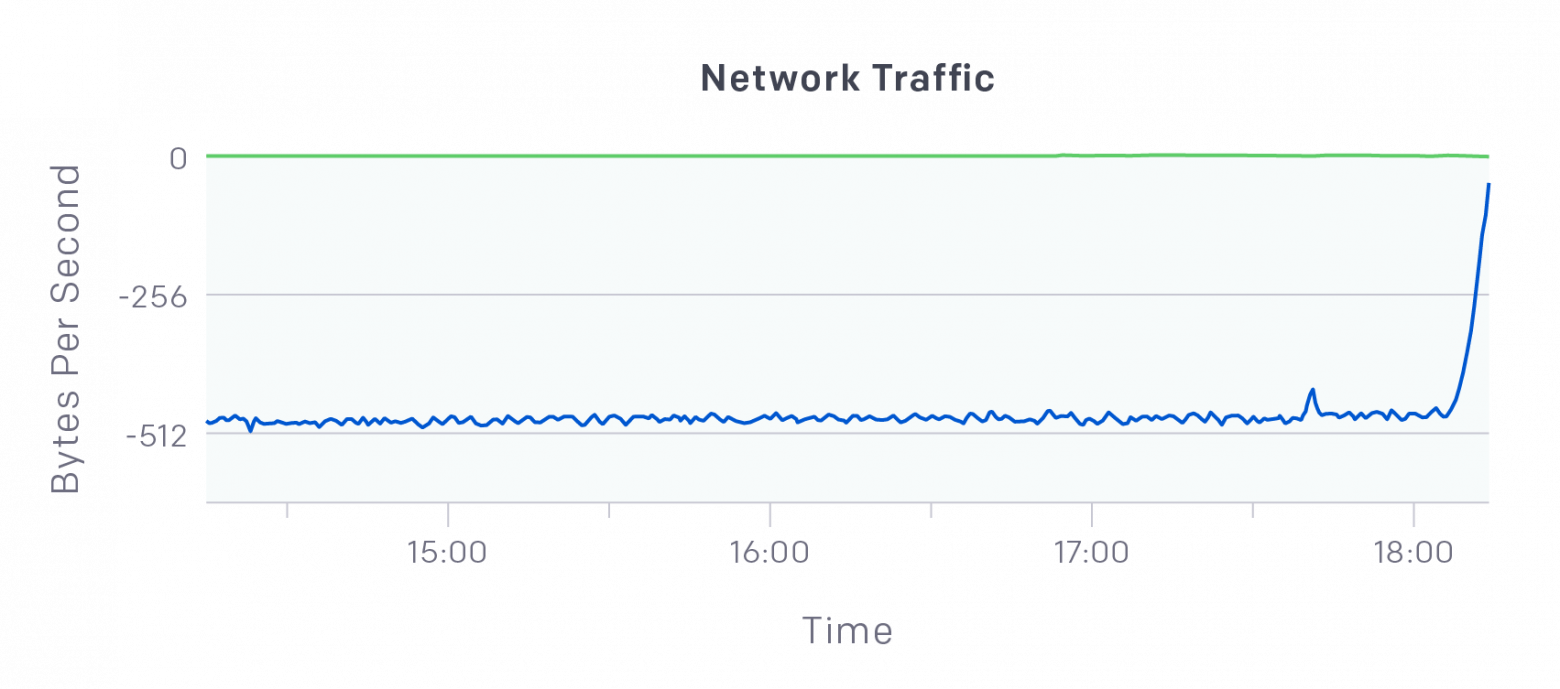
Egress etcd упал с более 500MB/s до почти нулевых значений (негативные числа на изображении выше показывают egress)
Еще одной полезной правкой стало хранение Kubernetes Events в отдельном etcd кластере — в этом случае всплески в создании событий не будут влиять на деятельность основных инстансов etcd. Для этого мы просто устанавливаем флаг
Еще одной проблемой после достижения 1000 нодов стало превышение лимита хранилища etcd (по умолчанию 2GB), после которого он перестал принимать записи. Это вызвало лавинообразную проблему — все Kube ноды не прошли проверку работоспособности, и поэтому наш autoscaler решил уничтожить все воркеры (workers). Мы увеличили максимальный размер хранилища etcd с помощью флага
Мы размещаем процессы kube-apiserver, kube-controller-manager и kube-scheduler на одних и тех же машинах. Для отказоустойчивости у нас всегда есть, как минимум, два мастера, а флаг
В основном, мы используем Kubernetes как систему планирования заданий, а autoscaler динамически масштабирует кластер — это позволяет значительно снизить затраты на простаивающие ноды, обеспечивая низкие задержки при быстрых итерациях. По умолчанию kube-scheduler равномерно распределяет нагрузку между нодами, но мы хотим обратного, чтобы уничтожать неиспользуемые ноды и быстро планировать большие поды. Поэтому мы перешли к следующей политике:
Мы широко используем KubeDNS для обнаружения сервисов, но вскоре после развертывания новой политики планирования у него возникли проблемы с надежностью. Стало понятно, что проблемы возникают только на определенных подах KubeDNS. Из-за новой политики планирования некоторые машины начали запускать более 10 копий KubeDNS, создавать hotspot’ы. Из-за этого мы превысили ~200QPS, которые разрешены для каждой ВМ в Azure для внешних DNS запросов.
Мы исправили это, добавив anti-affinity правило всем KubeDNS подам:
Мы начинали проект по Dota на Kubernetes, но, по мере его роста, стали замечать, что поды в нодах Kubernetes часто находятся в состоянии Pending в течение продолжительного времени. Образ игры весит примерно 17GB, требуется около 30 минут, чтобы развернуть его на свежую ноду кластера, и понять, почему контейнер Dota находится в Pending. Выяснилось, что это касается и других контейнеров. Мы обнаружили, что у kubelet есть флаг
Но даже после оптимизации скорости загрузки, поды не могли запуститься, выдавая сообщение об ошибке:
Для решения этой проблемы, мы установили флаг kubelet
Наша последняя проблема Docker была связана с Google Container Registry. По умолчанию, kubеlet выгружает определенный образ с gcr.io (контролируемый флагом --pod-infra-container-image), который используется на старте любого нового контейнера. Если эта выгрузка неуспешна по какой-то причине (например, превышение квоты), это не позволит ноде запускать контейнеры. Поскольку наши ноды не имеют собственного публичного IP и проходят через NAT для достижения gcr.io, скорее всего мы превышаем лимит квоты по IP. Для решения проблемы, мы просто предварительно загружаем Docker образ в образ машины для наших Kubernetes воркеров, используя
То же самое мы делаем с белым списком общих внутренних образов OpenAI, например с образом Dota, чтобы улучшить производительность.
По мере развития, наши эксперименты разрослись до сложных распределенных систем, работоспособность которых сильно зависела от сети. Уже в начале запуска распределенных экспериментов стало ясно, что наша сеть была плохо настроена. Пропускная способность между машинами была на уровне 10-15Gbit/s, но поды Kube, использующие Flannel, достигали предела уже на ~2Gbit/s. Общедоступные тесты Machine Zone показывали похожие значения, а значит проблема не в плохой настройке, а в нашей среде. (При этом, Flannel не создает оверхэд для наших физических машин.)
Чтобы обойти эту проблему, пользователи могут добавить две разные настройки для отключения Flannel в подах: hostNetwork: true и dnsPolicy: ClusterFirstWithHostNet. (Но ознакомьтесь с предупреждениями в документации Kubernetes прежде, чем сделать это)
Несмотря на тюнинг DNS, мы все еще сталкивались с проблемами DNS. Однажды, инженер сообщил, что команда nc -v до Redis сервера выполнялась более 30 секунд, до появления надписи об установке соединения. Мы отследили проблему в ARP стеке ядра. Исследование хоста пода Redis выявило проблему с сетью: связь на любом порте висела несколько секунд, но никакие DNS-имена не разрешались локальным демоном dnsmasq, в то время как dig просто печатал загадочное сообщение об ошибке: socket.c:1915: internal_send: 127.0.0.1#53: Invalid argument. Лог dmesg был более информативен: neighbor table overflow! Это означало, что у ARP кэша зкончилось место. ARP используется для маппинга сетевого адреса, например адреса IPv4, к физическому адресу, например MAC-адресу. К счастью, это легко пофиксить настройкой нескольких параметров в /etc/sysctl.conf:
Обычно, эти параметры настраивают в HPC кластерах, что особенно актуально и для Kubernetes кластеров, поскольку каждый под обладает своим IP адресом, который занимает место в ARP кэше.
Наши Kubernetes кластеры работают без инцидентов вот уже 3 месяца, и мы планируем расширить его еще больше в 2018 году. Недавно мы обновились до версии 1.8.4 и рады видеть, что теперь он официально поддерживает 5000.
THE END
Ждём вопросов, комментариев тут или на Дне открытых дверей. Сегодня его ведёт, кстати, Александр Титов — человек и пароход.
Ну что ж. Первый поток курса DevOps выпущен, второй обучается вовсю и вот на подходе третий. Курс усовершенствуется, проект тоже, остаётся неизменным пока что одно: интересные статьи, которые мы пока что только переводим для вас, но на носу уже и срывы покровов с тех вещей, что у нас просили :)
Поехали!
Мы используем Kubernetes для исследования в области deep learning уже более двух лет. В то время, как наши самые масштабные нагрузки управляют облачными ВМ напрямую, Kubernetes обеспечивает быстрый итерационный цикл и масштабируемость, что делает его идеальным для наших экспериментов. Сейчас мы управляем несколькими Kubernetes кластерами (как облачными, так и на физическом оборудовании), самый крупный из них состоит из более 2500 нод — это кластер в Azure на комбинации виртуальных машин D15v2 и NC24.
Многие системные компоненты отказывали в процессе масштабирования, включая etcd, Kube мастеров, загрузки образов Docker, сети, KubeDNS и даже ARP кэши наших машин. Поэтому мы решили, что будет полезным поделиться, с какими проблемами мы столкнулись и как с ними справились.

etcd
После расширения кластера до 500 нод, наши исследователи стали получать регулярные таймауты в kubectl. Мы попробовали решить проблему, добавив больше Kube мастеров (ВМ, на которых запущен kube-apiserver). На первый взгляд, это помогло временно решить проблему, но, спустя 10 итераций, мы поняли, что пытаемся вылечить симптом, а не изначальную причину (для сравнения, GKE использует одну 32-ядерную ВМ для 500 нод).
Главным подозреваемым стал наш кластер etcd, который является центральным хранилищем состояний Kube мастеров. Посмотрев на графики Datadog, мы обнаружили задержки записи до сотен миллисекунд на наших DS15v2 машинах, где были запущены копии etcd, несмотря на то, что каждый сервер использовал P30 SSD, с производительностью в 5000 IOPS.

Эти всплески задержек блокируют весь кластер!
Тест на производительность с fio показал, что etcd может использовать только 10% IOPS из-за задержек записи в 2ms — etcd делает последовательный ввод-вывод, поэтому задержки его блокируют.
Для каждой ноды мы переместили директорию etcd в локальный временный диск, который подключен к SSD напрямую, а не по сети. Переход на локальный диск снизил задержки записи до 200us и вылечил etcd!
Проблема снова возникла, когда кластер увеличился до 1000 нод — мы опять столкнулись с большими задержками etcd. В этот раз, kube-apiservers читали более 500MB/s от etcd. Мы настроили Prometheus для мониторинга apiservers и добавили флаги
--audit-log-path и --audit-log-maxbackup для лучшего логирования apiservers. Это выявило ряд медленных запросов и чрезмерных вызовов к LIST API для Events.Основная проблема: настройки по умолчанию для процессов мониторинга Fluentd и Datadog заключались в создании запросов для apiservers с каждой ноды в кластере (например, эта проблема, которая сейчас решена). Мы сделали процесс опроса менее агрессивным, и загрузка apisevers снова стала стабильной:

Egress etcd упал с более 500MB/s до почти нулевых значений (негативные числа на изображении выше показывают egress)
Еще одной полезной правкой стало хранение Kubernetes Events в отдельном etcd кластере — в этом случае всплески в создании событий не будут влиять на деятельность основных инстансов etcd. Для этого мы просто устанавливаем флаг
--etcd-servers-overrides таким образом: --etcd-servers-overrides=/events#https://0.example.com:2381;https://1.example.com:2381;https://2.example.com:2381Еще одной проблемой после достижения 1000 нодов стало превышение лимита хранилища etcd (по умолчанию 2GB), после которого он перестал принимать записи. Это вызвало лавинообразную проблему — все Kube ноды не прошли проверку работоспособности, и поэтому наш autoscaler решил уничтожить все воркеры (workers). Мы увеличили максимальный размер хранилища etcd с помощью флага
--quota-backend-bytes. И добавили в autoscaler проверку — если действие autoscaler уничтожает более 50% кластера, то он его не выполняет.Kube мастера
Мы размещаем процессы kube-apiserver, kube-controller-manager и kube-scheduler на одних и тех же машинах. Для отказоустойчивости у нас всегда есть, как минимум, два мастера, а флаг
--apiserver-count настроен на количество запущенных apiserver’ов (иначе Prometheus может запутаться в инстансах).В основном, мы используем Kubernetes как систему планирования заданий, а autoscaler динамически масштабирует кластер — это позволяет значительно снизить затраты на простаивающие ноды, обеспечивая низкие задержки при быстрых итерациях. По умолчанию kube-scheduler равномерно распределяет нагрузку между нодами, но мы хотим обратного, чтобы уничтожать неиспользуемые ноды и быстро планировать большие поды. Поэтому мы перешли к следующей политике:
{
"kind" : "Policy",
"apiVersion" : "v1",
"predicates" : [
{"name" : "GeneralPredicates"},
{"name" : "MatchInterPodAffinity"},
{"name" : "NoDiskConflict"},
{"name" : "NoVolumeZoneConflict"},
{"name" : "PodToleratesNodeTaints"}
],
"priorities" : [
{"name" : "MostRequestedPriority", "weight" : 1},
{"name" : "InterPodAffinityPriority", "weight" : 2}
]
}
Мы широко используем KubeDNS для обнаружения сервисов, но вскоре после развертывания новой политики планирования у него возникли проблемы с надежностью. Стало понятно, что проблемы возникают только на определенных подах KubeDNS. Из-за новой политики планирования некоторые машины начали запускать более 10 копий KubeDNS, создавать hotspot’ы. Из-за этого мы превысили ~200QPS, которые разрешены для каждой ВМ в Azure для внешних DNS запросов.
Мы исправили это, добавив anti-affinity правило всем KubeDNS подам:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- weight: 100
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- kube-dns
topologyKey: kubernetes.io/hostnameЗагрузка образов Docker
Мы начинали проект по Dota на Kubernetes, но, по мере его роста, стали замечать, что поды в нодах Kubernetes часто находятся в состоянии Pending в течение продолжительного времени. Образ игры весит примерно 17GB, требуется около 30 минут, чтобы развернуть его на свежую ноду кластера, и понять, почему контейнер Dota находится в Pending. Выяснилось, что это касается и других контейнеров. Мы обнаружили, что у kubelet есть флаг
--serialize-image-pulls (по умолчанию true), и это означало, что выгрузка образа Dota блокирует все остальные образы. Изменение флага на false требовало переключения Docker с AUFS на overlay2. Чтобы сделать выгрузку еще быстрее, мы переместили корень Docker на локальный SSD инстанса, как и в случае с etcd машинами. Но даже после оптимизации скорости загрузки, поды не могли запуститься, выдавая сообщение об ошибке:
rpc error: code = 2 desc = net/http: request canceled. В логах kubelet и Docker были сообщения об ошибке, указывающие на прерывание выгрузки образа из-за отсутствия прогресса. Корнем проблемы оказалась чрезмерно долгая выгрузка больших образов и случаи, когда бэклог выгружаемых образов оказывался слишком длинным. Для решения этой проблемы, мы установили флаг kubelet
--image-pull-progress-deadline на 30 минут, а опцию демона Docker max-concurrent-downloads на 10. (Вторая правка не ускорила выгрузку больших образов, но позволила распараллелить выгрузку очереди образов.)Наша последняя проблема Docker была связана с Google Container Registry. По умолчанию, kubеlet выгружает определенный образ с gcr.io (контролируемый флагом --pod-infra-container-image), который используется на старте любого нового контейнера. Если эта выгрузка неуспешна по какой-то причине (например, превышение квоты), это не позволит ноде запускать контейнеры. Поскольку наши ноды не имеют собственного публичного IP и проходят через NAT для достижения gcr.io, скорее всего мы превышаем лимит квоты по IP. Для решения проблемы, мы просто предварительно загружаем Docker образ в образ машины для наших Kubernetes воркеров, используя
docker image save -o
/opt/preloaded_docker_images.tar and docker image load -i /opt/preloaded_docker_images.tarТо же самое мы делаем с белым списком общих внутренних образов OpenAI, например с образом Dota, чтобы улучшить производительность.
Сети
По мере развития, наши эксперименты разрослись до сложных распределенных систем, работоспособность которых сильно зависела от сети. Уже в начале запуска распределенных экспериментов стало ясно, что наша сеть была плохо настроена. Пропускная способность между машинами была на уровне 10-15Gbit/s, но поды Kube, использующие Flannel, достигали предела уже на ~2Gbit/s. Общедоступные тесты Machine Zone показывали похожие значения, а значит проблема не в плохой настройке, а в нашей среде. (При этом, Flannel не создает оверхэд для наших физических машин.)
Чтобы обойти эту проблему, пользователи могут добавить две разные настройки для отключения Flannel в подах: hostNetwork: true и dnsPolicy: ClusterFirstWithHostNet. (Но ознакомьтесь с предупреждениями в документации Kubernetes прежде, чем сделать это)
ARP Кэш
Несмотря на тюнинг DNS, мы все еще сталкивались с проблемами DNS. Однажды, инженер сообщил, что команда nc -v до Redis сервера выполнялась более 30 секунд, до появления надписи об установке соединения. Мы отследили проблему в ARP стеке ядра. Исследование хоста пода Redis выявило проблему с сетью: связь на любом порте висела несколько секунд, но никакие DNS-имена не разрешались локальным демоном dnsmasq, в то время как dig просто печатал загадочное сообщение об ошибке: socket.c:1915: internal_send: 127.0.0.1#53: Invalid argument. Лог dmesg был более информативен: neighbor table overflow! Это означало, что у ARP кэша зкончилось место. ARP используется для маппинга сетевого адреса, например адреса IPv4, к физическому адресу, например MAC-адресу. К счастью, это легко пофиксить настройкой нескольких параметров в /etc/sysctl.conf:
net.ipv4.neigh.default.gc_thresh1 = 80000
net.ipv4.neigh.default.gc_thresh2 = 90000
net.ipv4.neigh.default.gc_thresh3 = 100000Обычно, эти параметры настраивают в HPC кластерах, что особенно актуально и для Kubernetes кластеров, поскольку каждый под обладает своим IP адресом, который занимает место в ARP кэше.
Наши Kubernetes кластеры работают без инцидентов вот уже 3 месяца, и мы планируем расширить его еще больше в 2018 году. Недавно мы обновились до версии 1.8.4 и рады видеть, что теперь он официально поддерживает 5000.
THE END
Ждём вопросов, комментариев тут или на Дне открытых дверей. Сегодня его ведёт, кстати, Александр Титов — человек и пароход.
