Как создать веб-сервис, который будет взаимодействовать с пользователями в реальном времени, поддерживая при этом несколько сотен тысяч коннектов одновременно?
Всем привет, меня зовут Андрей Клюев, я разработчик. Недавно я столкнулся с такой задачей – создать интерактивный сервис, где пользователь может получать быстрые бонусы за свои действия. Дело осложнялось тем, что в проекте были довольно высокие требования по нагрузке, а сроки были крайне невелики.
В этой статье я расскажу, как выбирал решение для реализации websocket-сервера под непростые требования проекта, с какими проблемами столкнулся в процессе разработки, а также скажу несколько слов о том, как в достижении вышеуказанных целей может помочь конфигурирование ядра Linux.
В конце статьи приведены полезные ссылки на инструменты разработки, тестирования и мониторинга.
Срок реализации – 1 месяц.
Сопоставив задачи и требования проекта, я пришел к выводу, что для его разработки целесообразнее всего использовать технологию WebSocket. Она обеспечивает постоянное соединение с сервером, избавляя от оверхеда на новое соединение при каждом сообщении, которое присутствует в реализации на технологиях ajax и long-polling. Это позволяет получить необходимую высокую скорость обмена сообщениями в сочетании с адекватным потреблением ресурсов, что очень важно при высоких нагрузках.
Также благодаря тому, что установка и разрыв соединения – это два четких события, появляется возможность с высокой точностью отслеживать время присутствия пользователя на сайте.
Учитывая достаточно ограниченные сроки проекта, я принял решение вести разработку с помощью WebSocket-фреймворка. Изучил несколько вариантов, самыми интересными из которых мне показались PHP ReactPHP, PHP Ratchet, Node.JS websockets/ws, PHP Swoole, PHP Workerman, Go Gorilla, Elixir Phoenix. Их возможности в плане нагрузки тестировал на ноутбуке с процессором Intel Core i5 и 4 ГБ оперативной памяти (таких ресурсов было вполне достаточно для исследования).
PHP Workerman – асинхронный событийно-ориентированный фреймворк. Его возможности исчерпываются простейшей реализацией websocket-сервера и умением работать с библиотекой libevent, нужной для обработки асинхронных оповещений о событиях. Код находится на уровне PHP 5.3 и не соответствует никаким стандартам. Для меня главным минусом стало то, что фреймворк не позволяет реализовывать высоконагруженные проекты. На тестовом стенде разработанное приложение уровня «Hello World» не смогло удержать и тысячи коннектов.
ReactPHP и Ratchet по своим возможностям в целом сопоставимы с Workerman. Ratchet внутри зависит от ReactPHP, работает также через libevent и не позволяет создать решение для высоких нагрузок.
Swoole – интересный фреймворк, написанный на C, подключается как расширение для PHP, имеет средства для параллельного программирования. К сожалению, я обнаружил, что фреймворк недостаточно стабилен: на тестовом стенде он обрывал каждый второй коннект.
Далее я рассмотрел Node.JS WS. Этот фреймворк показал неплохие результаты – около 5 тысяч коннектов на тестовом стенде без дополнительных настроек. Однако мой проект подразумевал заметно более высокие нагрузки, поэтому я остановил свой выбор на фреймворках Go Gorilla + Echo Framework и Elixir Phoenix. Эти варианты тестировались уже более детально.
Для тестирования использовались такие инструменты как artillery, gatling и сервис flood.io.
Целью тестирования было изучение потребления ресурсов процессора и памяти. Характеристики машины были такими же – процессор Intel iCore 5 и 4 ГБ оперативной памяти. Тесты проводились на примере простейших чатов на Go и Phoenix:
Вот такое простое приложение чата нормально функционировало на машине указанной мощности при нагрузке 25-30 тысяч пользователей:
Тестовые запуски показали, что все спокойно работает на машине указанной мощности при нагрузке 25-30 тысяч пользователей.
Потребление ресурсов процессора:
Phoenix

Gorilla
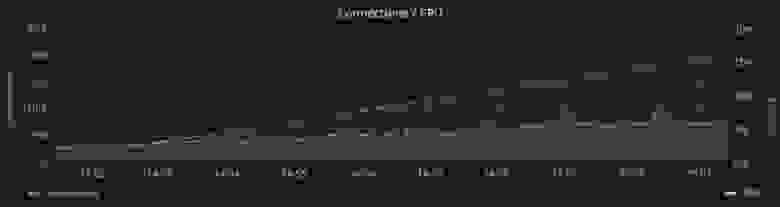
Потребление оперативной памяти при нагрузке в 20 тысяч соединений доходило до 2 ГБ в случае с обоими фреймворками:
Phoenix

Gorilla

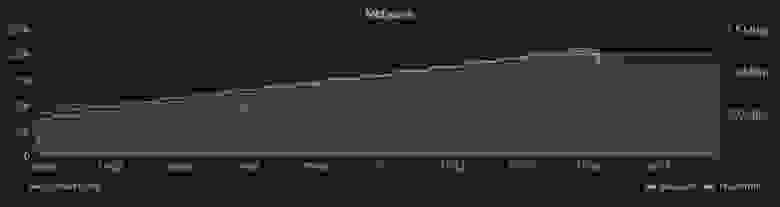
При этом Go даже опережает Elixir по производительности, однако Phoenix Framework при этом предоставляет намного больше возможностей. На графике ниже, который показывает потребление сетевых ресурсов, можно заметить, что в тесте Phoenix передается в 1,5 раза больше сообщений. Это связано с тем, что у этого фреймворка уже в изначальной «коробочной» версии есть механизм heartbeat’ов (периодических синхронизирующих сигналов), который в Gorilla придется реализовывать самостоятельно. В условиях ограниченных сроков любая дополнительная работа была весомым аргументом в пользу Phoenix.
Phoenix
Gorilla

Phoenix – это классический MVC-фреймворк, достаточно похожий на Rails, что не удивительно, так как одним из его разработчиков и создателем языка Elixir является Хосе Валим – один из основных создателей Ruby on Rails. Некоторое сходство можно увидеть даже в синтаксисе.
Phoenix:
Rails:
При использовании Phoenix и языка Elixir значительная часть процессов выполняется посредством утилиты Mix. Это инструмент для сборки (build tool), который решает множество разных задач по созданию, компиляции и тестированию приложения, по управлению его зависимостями и по некоторым другим процессам.
Mix – ключевая часть любого Elixir-проекта. Эта утилита ничем не уступает и ничем не превосходит аналоги из других языков, но справляется со своей работой на отлично. А благодаря тому, что Elixir-код выполняется на виртуальной машине Erlang, появляется возможность добавлять в зависимости любые библиотеки из мира Erlang. Помимо этого вместе с Erlang VM вы получаете удобный и безопасный параллелизм, а также высокую отказоустойчивость.
При всех достоинствах у Phoenix есть и свои недостатки. Один из них заключается в сложности решения такой задачи, как отслеживание активных пользователей на сайте в условиях высокой нагрузки.
Дело в том, что пользователи могут подключаться к разным нодам приложения, и каждая нода будет знать лишь о собственных клиентах. Чтобы вывести список активных пользователей, придется опрашивать все ноды приложения.
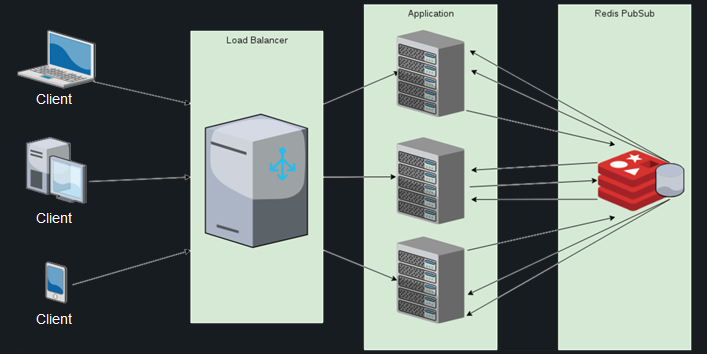
Для решения этих проблем в Phoenix’е существует модуль Presence, который дает разработчику возможность отслеживать активных пользователей буквально в три строки кода. Он использует механизм хартбитов и бесконфликтной репликации внутри кластера, а также PubSub-сервер для обмена сообщениями между нодами.
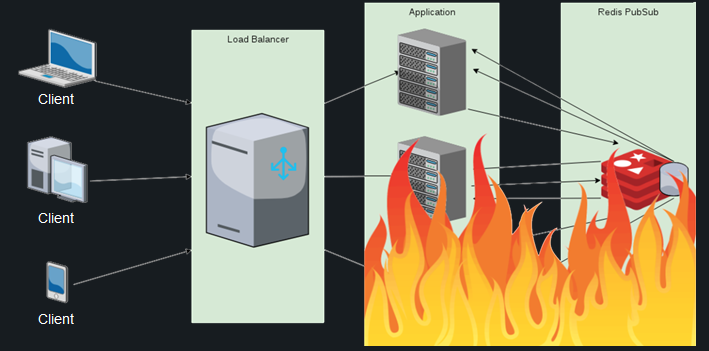
Звучит хорошо, но на деле получается примерно следующее. Сотни тысяч подключающихся и отключающихся пользователей порождают миллионы сообщений на синхронизацию между нодами, из-за чего потребление ресурсов процессора переходит все допустимые пределы, и даже подключение Redis PubSub не спасает ситуацию. Список пользователей дублируется на каждой ноде, и расчет дифа при каждом новом подключении становится все дороже и дороже – и это учитывая, что расчет проводится на каждой из действующих нод.
В такой ситуации отметка даже в 100 тысяч клиентов становится недостижимой. Других готовых решений для данной задачи найти не удалось, поэтому я решил поступить следующим образом: возложить обязанность по мониторингу присутствия пользователей онлайн на БД.
На первый взгляд, это хорошая идея, в которой нет ничего сложного: достаточно хранить в базе поле last activity и периодически его обновлять. К сожалению, для проектов с высокой нагрузкой это не выход: когда количество пользователей достигнет нескольких сотен тысяч, система не справится с миллионами приходящих от них хартбитов.
Я выбрал менее тривиальное, но более производительное решение. При подключении пользователя для него создается уникальная строка в таблице, которая хранит в себе его идентификатор, точное время входа и список нод, к которым он подключен. Перечень нод хранится в JSONB-поле, и при конфликте строк достаточно его обновить.
Вот такой запрос отвечает за вход пользователя:
Список нод при этом выглядит так:

Если пользователь открывает сервис во втором окне или на другом устройстве, он может попасть на другую ноду, и тогда она тоже добавится в список. Если он попадет на ту же ноду, что и в первом окне, число напротив названия этой ноды в списке увеличится. Это число отражает количество активных подключений пользователя к конкретной ноде.
Вот так выглядит запрос, который идет в БД при закрытии сессии:
Список нод:

При закрытии сессии на определенной ноде счетчик подключений в БД уменьшается на единицу, а при достижении нуля нода убирается из списка. Когда список нод окончательно опустеет, этот момент будет зафиксирован как окончательное время выхода пользователя.
Данный подход дал возможность не только отслеживать присутствие пользователя онлайн и время просмотра, но и фильтровать эти сессии по различным критериям.
Во всем этом остается лишь один недостаток – если нода падает, все ее пользователи «зависают» в онлайне. Для решения данной проблемы у нас есть демон, который периодически чистит БД от таких записей, но до сих пор этого не требовалось. Анализ нагрузки и мониторинг работы кластера, проведенные после выхода проекта в продакшн, показали, что падений нод не было и данный механизм не использовался.
Были и другие трудности, но они более специфичны, поэтому стоит перейти к вопросу отказоустойчивости приложения.
Написать хорошее приложение на производительном языке – это только половина дела, без грамотных DevOps достигнуть хоть сколько-нибудь высоких результатов невозможно.
Первой преградой на пути к целевой нагрузке стало сетевое ядро Linux. Потребовалось произвести некоторые настройки, чтобы добиться более рационального использования его ресурсов.
Каждый открытый сокет – это файловый дескриптор в Linux, а их число ограничено. Причина лимита в том, что для каждого открытого файла в ядре создается C-структура, которая занимает unreclaimable-память ядра.
Чтобы использовать память по максимуму, я выставил очень высокие значения размеров буферов приема и передачи, а также увеличил размер буферов TСP сокетов. Значения здесь выставляются не в байтах, а в страницах памяти, обычно одна страница равна 4 кБ, и на максимальное количество открытых сокетов, ожидающих соединения для высоконагруженных серверов, я поставил значение 15 тысяч.
Если вы используете nginx перед cowboy-сервером, то стоит также задуматься об увеличении его лимитов. За это отвечают директивы worker_connections и worker_rlimit_nofile.
Вторая преграда не столь очевидна. Если запустить подобное приложение в распределенном режиме, можно заметить резкий рост потребления ресурсов процессора при увеличении количества коннектов. Проблема в том, что Erlang по умолчанию работает с системными вызовами Poll. В версии 2.6 ядра Linux существует Epoll, который может предоставить более эффективный механизм для приложений, обрабатывающих большое количество одновременно открытых соединений — со сложностью O(1) в отличие от Poll, обладающего сложностью O(n).
К счастью, режим Epoll включается одним флагом: +K true, также рекомендую увеличить максимальное количество процессов, порождаемых вашим приложением, и максимальное количество открытых портов с помощью флагов +P и +Q соответственно.
Третья проблема более индивидуальна, и не каждый может с ней столкнуться. На данном проекте был организован процесс автоматического деплоя и динамического скейлинга с помощью Сhef и Kubernetes. Kubernetes позволяет быстро разворачивать Docker-контейнеры на большом количестве хостов, и это очень удобно, однако заранее узнать ip-адрес нового хоста нельзя, а если не прописать его в конфиг Erlang, подключить новую ноду к распределенному приложению не получится.
К счастью, для решения этих проблем существует библиотека libcluster. Общаясь с Kubernetes по API, она в режиме реального времени узнает о создании новых нод и регистрирует их в кластере erlang.
Выбранный фреймворк в сочетании с правильной настройкой серверов позволил достичь всех целей проекта: в поставленные сроки (1 месяц) разработать интерактивный веб-сервис, который общается с пользователями в режиме реального времени и при этом выдерживает нагрузки от 150 тысяч коннектов и выше.
После запуска проекта в продакшн был проведен мониторинг, который показал следующие результаты: при максимальном количестве коннектов до 800 тысяч потребление ресурсов процессора доходит до 45%. Среднее значение загрузки составляет 29% при 600 тысячах соединений.

На этом графике – потребление памяти при работе в кластере 10 машин, каждая из которых имеет по 8 ГБ оперативной памяти.

Что же касается основных рабочих инструментов в этом проекте, Elixir и Phoenix Framework, у меня есть все основания полагать, что в ближайшие годы они станут такими же популярными, как в свое время Ruby и Rails, так что есть смысл начинать их освоение уже сейчас.
Спасибо за внимание!
Разработка:
elixir-lang.org
phoenixframework.org
Нагрузочное тестирование:
gatling.io
flood.io
Мониторинг:
prometheus.io
grafana.com
Всем привет, меня зовут Андрей Клюев, я разработчик. Недавно я столкнулся с такой задачей – создать интерактивный сервис, где пользователь может получать быстрые бонусы за свои действия. Дело осложнялось тем, что в проекте были довольно высокие требования по нагрузке, а сроки были крайне невелики.
В этой статье я расскажу, как выбирал решение для реализации websocket-сервера под непростые требования проекта, с какими проблемами столкнулся в процессе разработки, а также скажу несколько слов о том, как в достижении вышеуказанных целей может помочь конфигурирование ядра Linux.
В конце статьи приведены полезные ссылки на инструменты разработки, тестирования и мониторинга.
Задачи и требования
Требования к функционалу проекта:
- сделать возможным отслеживание присутствия пользователя на ресурсе и трекинг времени просмотра;
- обеспечить быстрый обмен сообщениями между клиентом и сервером, так как время на получение пользователем бонуса строго ограничено;
- создать динамичный интерактивный интерфейс с синхронизацией всех действий при работе пользователя с сервисом через несколько вкладок или устройств одновременно.
Требования к нагрузке:
- Приложение должно выдерживать не менее 150 тысяч пользователей онлайн.
Срок реализации – 1 месяц.
Выбор технологии
Сопоставив задачи и требования проекта, я пришел к выводу, что для его разработки целесообразнее всего использовать технологию WebSocket. Она обеспечивает постоянное соединение с сервером, избавляя от оверхеда на новое соединение при каждом сообщении, которое присутствует в реализации на технологиях ajax и long-polling. Это позволяет получить необходимую высокую скорость обмена сообщениями в сочетании с адекватным потреблением ресурсов, что очень важно при высоких нагрузках.
Также благодаря тому, что установка и разрыв соединения – это два четких события, появляется возможность с высокой точностью отслеживать время присутствия пользователя на сайте.
Учитывая достаточно ограниченные сроки проекта, я принял решение вести разработку с помощью WebSocket-фреймворка. Изучил несколько вариантов, самыми интересными из которых мне показались PHP ReactPHP, PHP Ratchet, Node.JS websockets/ws, PHP Swoole, PHP Workerman, Go Gorilla, Elixir Phoenix. Их возможности в плане нагрузки тестировал на ноутбуке с процессором Intel Core i5 и 4 ГБ оперативной памяти (таких ресурсов было вполне достаточно для исследования).
PHP Workerman – асинхронный событийно-ориентированный фреймворк. Его возможности исчерпываются простейшей реализацией websocket-сервера и умением работать с библиотекой libevent, нужной для обработки асинхронных оповещений о событиях. Код находится на уровне PHP 5.3 и не соответствует никаким стандартам. Для меня главным минусом стало то, что фреймворк не позволяет реализовывать высоконагруженные проекты. На тестовом стенде разработанное приложение уровня «Hello World» не смогло удержать и тысячи коннектов.
ReactPHP и Ratchet по своим возможностям в целом сопоставимы с Workerman. Ratchet внутри зависит от ReactPHP, работает также через libevent и не позволяет создать решение для высоких нагрузок.
Swoole – интересный фреймворк, написанный на C, подключается как расширение для PHP, имеет средства для параллельного программирования. К сожалению, я обнаружил, что фреймворк недостаточно стабилен: на тестовом стенде он обрывал каждый второй коннект.
Далее я рассмотрел Node.JS WS. Этот фреймворк показал неплохие результаты – около 5 тысяч коннектов на тестовом стенде без дополнительных настроек. Однако мой проект подразумевал заметно более высокие нагрузки, поэтому я остановил свой выбор на фреймворках Go Gorilla + Echo Framework и Elixir Phoenix. Эти варианты тестировались уже более детально.
Нагрузочное тестирование
Для тестирования использовались такие инструменты как artillery, gatling и сервис flood.io.
Целью тестирования было изучение потребления ресурсов процессора и памяти. Характеристики машины были такими же – процессор Intel iCore 5 и 4 ГБ оперативной памяти. Тесты проводились на примере простейших чатов на Go и Phoenix:
Вот такое простое приложение чата нормально функционировало на машине указанной мощности при нагрузке 25-30 тысяч пользователей:
config:
target: "ws://127.0.0.1:8080/ws"
phases
-
duration:6
arrivalCount: 10000
ws:
rejectUnauthorized: false
scenarios:
-
engine: “ws”
flow
-
send “hello”
-
think 2
-
send “world”Class LoadSimulation extends Simulation {
val users = Integer.getInteger (“threads”, 30000)
val rampup = java.lang.Long.getLong (“rampup”, 30L)
val duration = java.lang.Long.getLong (“duration”, 1200L)
val httpConf = http
.wsBaseURL(“ws://8.8.8.8/socket”)
val scn = scenario(“WebSocket”)
.exes(ws(“Connect WS”).open(“/websocket?vsn=2.0.0”))
.exes(
ws(“Auth”)
sendText(“““[“1”, “1”, “my:channel”, “php_join”, {}]”””)
)
.forever() {
exes(
ws(“Heartbeat”).sendText(“““[null, “2”, “phoenix”, “heartbeat”, {}]”””)
)
.pause(30)
}
.exes(ws(“Close WS”).close)
setUp(scn.inject(rampUsers(users) over (rampup seconds)))
.maxDuration(duration)
.protocols(httpConf)Тестовые запуски показали, что все спокойно работает на машине указанной мощности при нагрузке 25-30 тысяч пользователей.
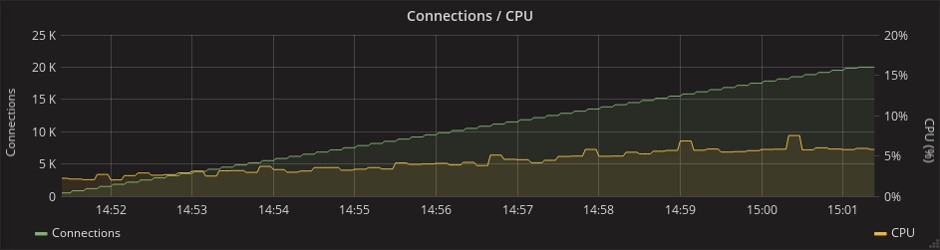
Потребление ресурсов процессора:
Phoenix
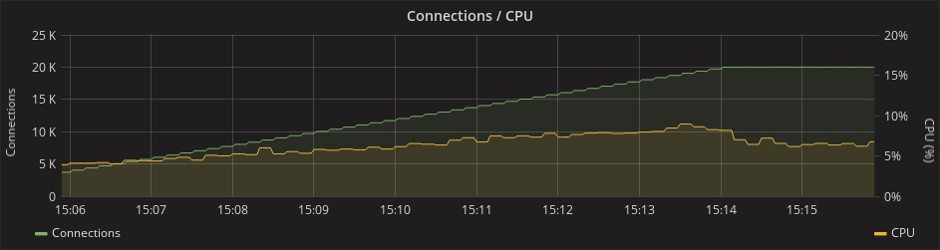
Gorilla
Потребление оперативной памяти при нагрузке в 20 тысяч соединений доходило до 2 ГБ в случае с обоими фреймворками:
Phoenix
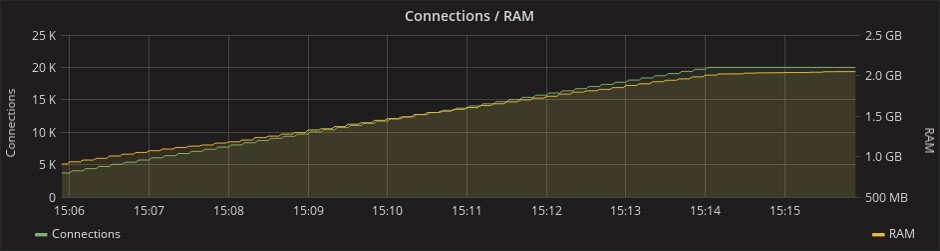
Gorilla
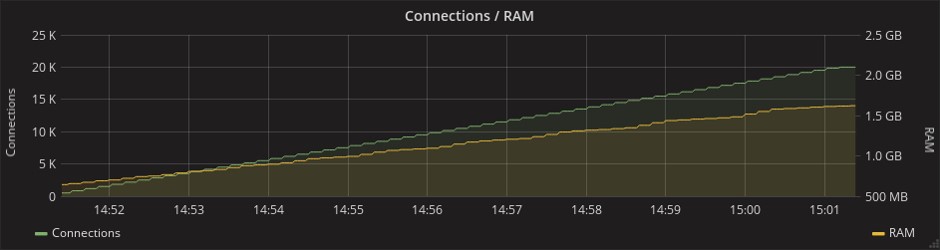
При этом Go даже опережает Elixir по производительности, однако Phoenix Framework при этом предоставляет намного больше возможностей. На графике ниже, который показывает потребление сетевых ресурсов, можно заметить, что в тесте Phoenix передается в 1,5 раза больше сообщений. Это связано с тем, что у этого фреймворка уже в изначальной «коробочной» версии есть механизм heartbeat’ов (периодических синхронизирующих сигналов), который в Gorilla придется реализовывать самостоятельно. В условиях ограниченных сроков любая дополнительная работа была весомым аргументом в пользу Phoenix.
Phoenix
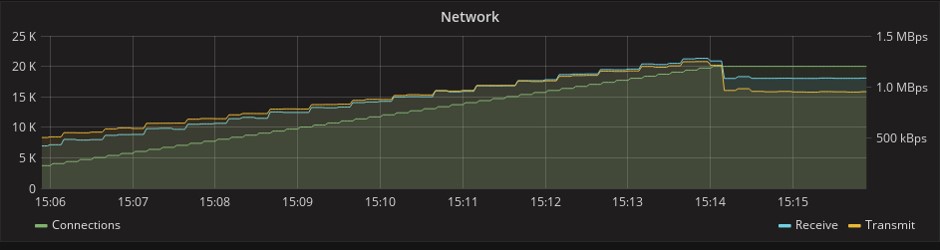
Gorilla
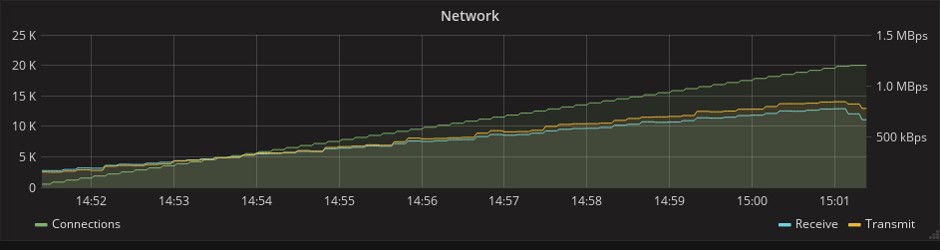
О Phoenix Framework
Phoenix – это классический MVC-фреймворк, достаточно похожий на Rails, что не удивительно, так как одним из его разработчиков и создателем языка Elixir является Хосе Валим – один из основных создателей Ruby on Rails. Некоторое сходство можно увидеть даже в синтаксисе.
Phoenix:
defmodule Benchmarker.Router do
use Phoenix.Router
alias Benchmarker.Controllers
get "/:title", Controllers.Pages, :index, as: :page
endRails:
Benchmarker::Application.routes.draw do
root to: "pages#index"
get "/:title", to: "pages#index", as: :page
endMix – автоматизирующая утилита для Elixir-проектов
При использовании Phoenix и языка Elixir значительная часть процессов выполняется посредством утилиты Mix. Это инструмент для сборки (build tool), который решает множество разных задач по созданию, компиляции и тестированию приложения, по управлению его зависимостями и по некоторым другим процессам.
Mix – ключевая часть любого Elixir-проекта. Эта утилита ничем не уступает и ничем не превосходит аналоги из других языков, но справляется со своей работой на отлично. А благодаря тому, что Elixir-код выполняется на виртуальной машине Erlang, появляется возможность добавлять в зависимости любые библиотеки из мира Erlang. Помимо этого вместе с Erlang VM вы получаете удобный и безопасный параллелизм, а также высокую отказоустойчивость.
Проблемы и решения
При всех достоинствах у Phoenix есть и свои недостатки. Один из них заключается в сложности решения такой задачи, как отслеживание активных пользователей на сайте в условиях высокой нагрузки.
Дело в том, что пользователи могут подключаться к разным нодам приложения, и каждая нода будет знать лишь о собственных клиентах. Чтобы вывести список активных пользователей, придется опрашивать все ноды приложения.
Для решения этих проблем в Phoenix’е существует модуль Presence, который дает разработчику возможность отслеживать активных пользователей буквально в три строки кода. Он использует механизм хартбитов и бесконфликтной репликации внутри кластера, а также PubSub-сервер для обмена сообщениями между нодами.
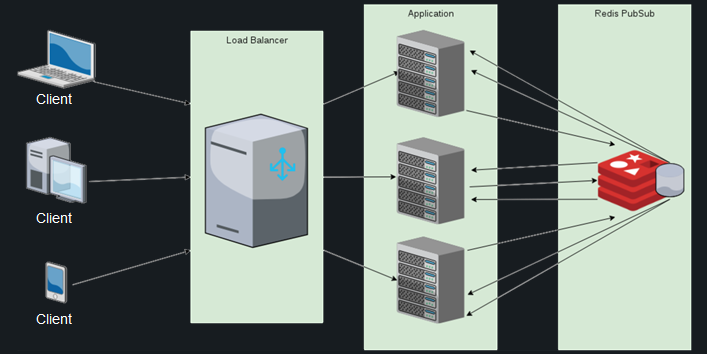
Звучит хорошо, но на деле получается примерно следующее. Сотни тысяч подключающихся и отключающихся пользователей порождают миллионы сообщений на синхронизацию между нодами, из-за чего потребление ресурсов процессора переходит все допустимые пределы, и даже подключение Redis PubSub не спасает ситуацию. Список пользователей дублируется на каждой ноде, и расчет дифа при каждом новом подключении становится все дороже и дороже – и это учитывая, что расчет проводится на каждой из действующих нод.
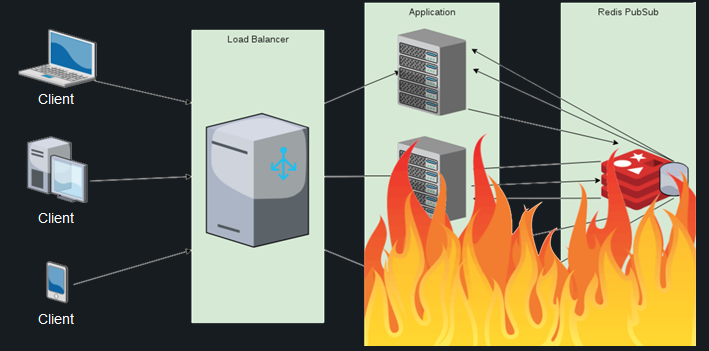
В такой ситуации отметка даже в 100 тысяч клиентов становится недостижимой. Других готовых решений для данной задачи найти не удалось, поэтому я решил поступить следующим образом: возложить обязанность по мониторингу присутствия пользователей онлайн на БД.
На первый взгляд, это хорошая идея, в которой нет ничего сложного: достаточно хранить в базе поле last activity и периодически его обновлять. К сожалению, для проектов с высокой нагрузкой это не выход: когда количество пользователей достигнет нескольких сотен тысяч, система не справится с миллионами приходящих от них хартбитов.
Я выбрал менее тривиальное, но более производительное решение. При подключении пользователя для него создается уникальная строка в таблице, которая хранит в себе его идентификатор, точное время входа и список нод, к которым он подключен. Перечень нод хранится в JSONB-поле, и при конфликте строк достаточно его обновить.
create table watching_times (
id serial not null constraint watching_times_pkey primary key,
user_id integer,
join_at timestamp,
terminate_at timestamp,
nodes jsonb
);
create unique index watching_times_not_null_uni_idx
on watching_times (user_id, terminate_at)
where (terminate_at IS NOT NULL);
create unique index watching_times_null_uni_idx
on watching_times (user_id)
where (terminate_at IS NULL);
Вот такой запрос отвечает за вход пользователя:
INSERT INTO watching_times (
user_id,
join_at,
terminate_at,
nodes
)
VALUES (1, NOW(), NULL, '{nl@192.168.1.101”: 1}')
ON CONFLICT (user_id)
WHERE terminate_at IS NULL
DO UPDATE SET nodes = watching_times.nodes ||
CONCAT(
'{nl@192.168.1.101:',
COALESCE(watching_times.nodes->>'nl@192.168.1.101', '0')::int + 1,
'}'
)::JSONB
RETURNING id;Список нод при этом выглядит так:

Если пользователь открывает сервис во втором окне или на другом устройстве, он может попасть на другую ноду, и тогда она тоже добавится в список. Если он попадет на ту же ноду, что и в первом окне, число напротив названия этой ноды в списке увеличится. Это число отражает количество активных подключений пользователя к конкретной ноде.
Вот так выглядит запрос, который идет в БД при закрытии сессии:
UPDATE watching_times
SET nodes
CASE WHEN
(
CONCAT(
'{“nl@192.168.1.101”: ',
COALESCE(watching_times.nodes ->> 'nl@192.168.1.101', '0') :: INT - 1,
'}'
)::JSONB ->>'nl@192.168.1.101'
)::INT <= 0
THEN
(watching_times.nodes - 'nl@192.168.1.101')
ELSE
CONCAT(
'{“nl@192.168.1.101”: ',
COALESCE(watching_times.nodes ->> 'nl@192.168.1.101', '0') :: INT - 1,
'}'
)::JSONB
END
),
terminate_at = (CASE WHEN ... = '{}' :: JSONB THEN NOW() ELSE NULL END)
WHERE id = 1;Список нод:

При закрытии сессии на определенной ноде счетчик подключений в БД уменьшается на единицу, а при достижении нуля нода убирается из списка. Когда список нод окончательно опустеет, этот момент будет зафиксирован как окончательное время выхода пользователя.
Данный подход дал возможность не только отслеживать присутствие пользователя онлайн и время просмотра, но и фильтровать эти сессии по различным критериям.
Во всем этом остается лишь один недостаток – если нода падает, все ее пользователи «зависают» в онлайне. Для решения данной проблемы у нас есть демон, который периодически чистит БД от таких записей, но до сих пор этого не требовалось. Анализ нагрузки и мониторинг работы кластера, проведенные после выхода проекта в продакшн, показали, что падений нод не было и данный механизм не использовался.
Были и другие трудности, но они более специфичны, поэтому стоит перейти к вопросу отказоустойчивости приложения.
Конфигурирование ядра Linux для повышения производительности
Написать хорошее приложение на производительном языке – это только половина дела, без грамотных DevOps достигнуть хоть сколько-нибудь высоких результатов невозможно.
Первой преградой на пути к целевой нагрузке стало сетевое ядро Linux. Потребовалось произвести некоторые настройки, чтобы добиться более рационального использования его ресурсов.
Каждый открытый сокет – это файловый дескриптор в Linux, а их число ограничено. Причина лимита в том, что для каждого открытого файла в ядре создается C-структура, которая занимает unreclaimable-память ядра.
Чтобы использовать память по максимуму, я выставил очень высокие значения размеров буферов приема и передачи, а также увеличил размер буферов TСP сокетов. Значения здесь выставляются не в байтах, а в страницах памяти, обычно одна страница равна 4 кБ, и на максимальное количество открытых сокетов, ожидающих соединения для высоконагруженных серверов, я поставил значение 15 тысяч.
Лимиты файловых дескрипторов:
#!/usr/bin/env bash
sysctl -w 'fs.nr_open=10000000' # Максимальное количество открытых файловых дескрипторов
sysctl -w 'net.core.rmem_max=12582912' # Максимальный размер буферов приема всех типов
sysctl -w 'net.core.wmem_max=12582912' # Максимальный размер буферов передачи всех типов
sysctl -w 'net.ipv4.tcp_mem=10240 87380 12582912' # Объем памяти TCP сокета
sysctl -w 'net.ipv4.tcp_rmem=10240 87380 12582912' # размер буфера приема
sysctl -w 'net.ipv4.tcp_wmem=10240 87380 12582912'# размер буфера передачи
<code>sysctl -w 'net.core.somaxconn=15000' # Максимальное число открытых сокетов, ждущих соединения
Если вы используете nginx перед cowboy-сервером, то стоит также задуматься об увеличении его лимитов. За это отвечают директивы worker_connections и worker_rlimit_nofile.
Вторая преграда не столь очевидна. Если запустить подобное приложение в распределенном режиме, можно заметить резкий рост потребления ресурсов процессора при увеличении количества коннектов. Проблема в том, что Erlang по умолчанию работает с системными вызовами Poll. В версии 2.6 ядра Linux существует Epoll, который может предоставить более эффективный механизм для приложений, обрабатывающих большое количество одновременно открытых соединений — со сложностью O(1) в отличие от Poll, обладающего сложностью O(n).
К счастью, режим Epoll включается одним флагом: +K true, также рекомендую увеличить максимальное количество процессов, порождаемых вашим приложением, и максимальное количество открытых портов с помощью флагов +P и +Q соответственно.
Poll vs. Epoll
#!/usr/bin/env bash
Elixir --name ${MIX_NODE_NAME}@${MIX_HOST} --erl “-config sys.config -setcookie ${ERL_MAGIC_COOKIE} +K true +Q 500000 +P 4194304” -S mix phx.serverТретья проблема более индивидуальна, и не каждый может с ней столкнуться. На данном проекте был организован процесс автоматического деплоя и динамического скейлинга с помощью Сhef и Kubernetes. Kubernetes позволяет быстро разворачивать Docker-контейнеры на большом количестве хостов, и это очень удобно, однако заранее узнать ip-адрес нового хоста нельзя, а если не прописать его в конфиг Erlang, подключить новую ноду к распределенному приложению не получится.
К счастью, для решения этих проблем существует библиотека libcluster. Общаясь с Kubernetes по API, она в режиме реального времени узнает о создании новых нод и регистрирует их в кластере erlang.
config :libcluster,
topologies: [
k8s: [
strategy: Cluster.Strategy.Kubernetes,
config: [
kubernetes_selector: “app=my -backend”,
kubernetes_node_basename: “my -backend”]]]
Итоги и перспективы
Выбранный фреймворк в сочетании с правильной настройкой серверов позволил достичь всех целей проекта: в поставленные сроки (1 месяц) разработать интерактивный веб-сервис, который общается с пользователями в режиме реального времени и при этом выдерживает нагрузки от 150 тысяч коннектов и выше.
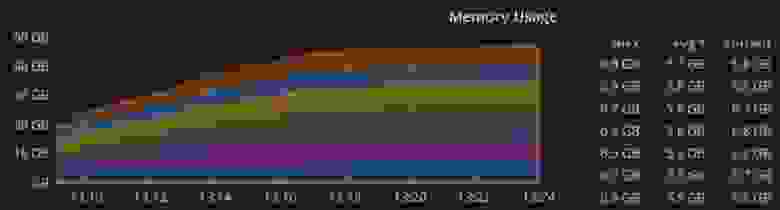
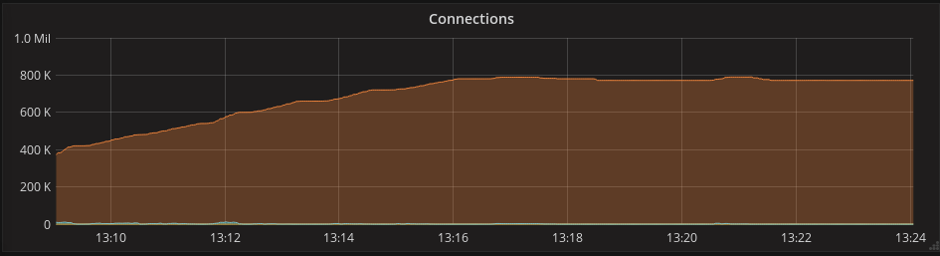
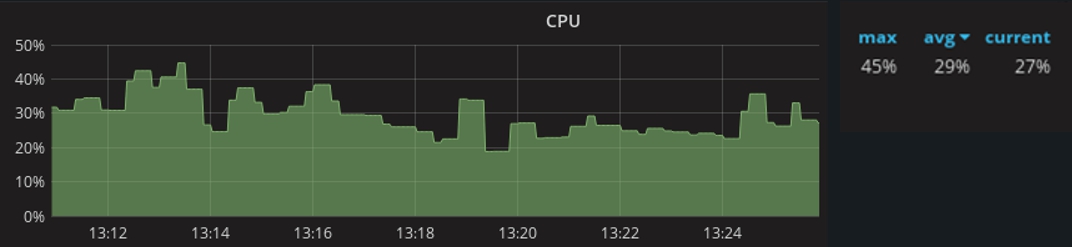
После запуска проекта в продакшн был проведен мониторинг, который показал следующие результаты: при максимальном количестве коннектов до 800 тысяч потребление ресурсов процессора доходит до 45%. Среднее значение загрузки составляет 29% при 600 тысячах соединений.
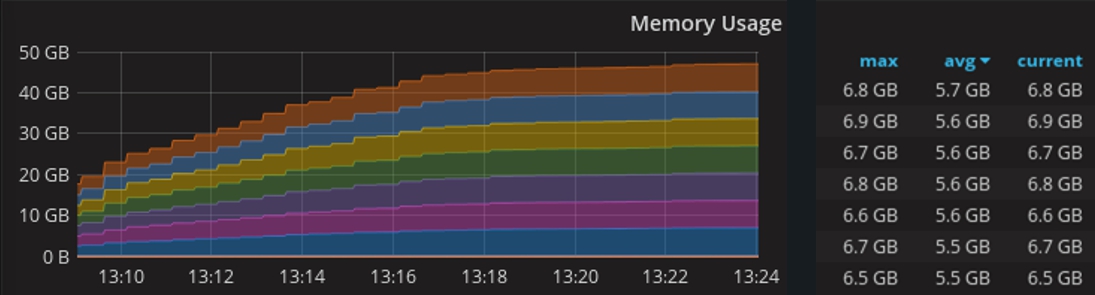
На этом графике – потребление памяти при работе в кластере 10 машин, каждая из которых имеет по 8 ГБ оперативной памяти.
Что же касается основных рабочих инструментов в этом проекте, Elixir и Phoenix Framework, у меня есть все основания полагать, что в ближайшие годы они станут такими же популярными, как в свое время Ruby и Rails, так что есть смысл начинать их освоение уже сейчас.
Спасибо за внимание!
Ссылки
Разработка:
elixir-lang.org
phoenixframework.org
Нагрузочное тестирование:
gatling.io
flood.io
Мониторинг:
prometheus.io
grafana.com
