Существует два класса задач где нам может потребоваться параллельная обработка: операции ввода-вывода и задачи активно использующие ЦП, такие как обработка изображений. Python позволяет реализовать несколько подходов к параллельной обработке данных. Рассмотрим их применительно к операциям ввода-вывода.
До версии Python 3.5 было два способа реализации параллельной обработки операций ввода-вывода. Нативный метод — использование многопоточности, другой вариант — библиотеки типа Gevent, которые распараллеливают задачи в виде микро-потоков. Python 3.5 предоставил встроенную поддержку параллелизма с помощью asyncio. Мне было любопытно посмотреть, как каждый из них будет работать с точки зрения памяти. Результаты ниже.
Для тестирования я создал простой скрипт. Хотя в нем и не так много функций, он демонстрирует реальный сценарий использования. Скрипт скачивает с сайта цены на автобусные билеты за 100 дней и готовит их для обработки. Потребление памяти измерялось с помощью memory_profiler. Код доступен на Github.
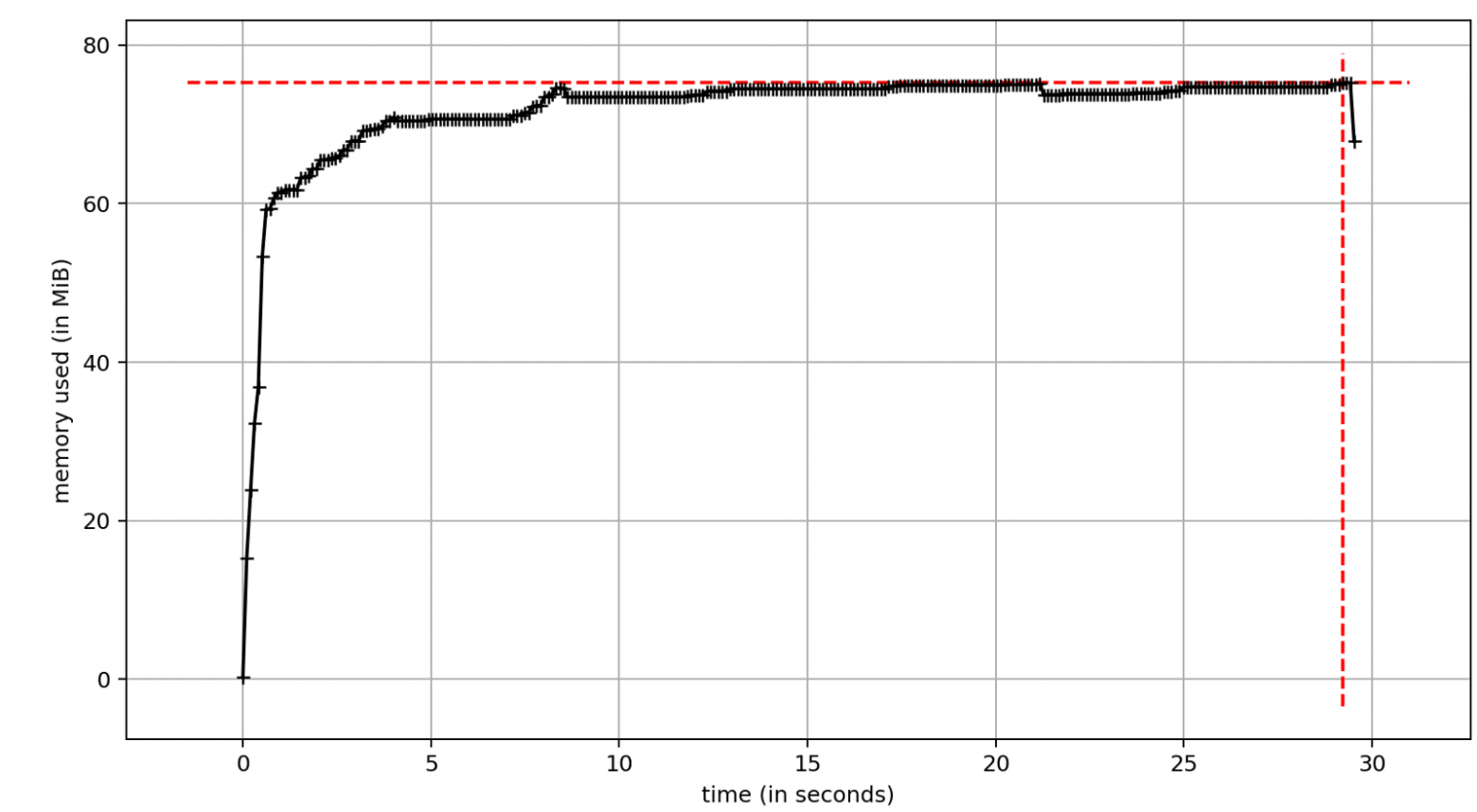
Я реализовал однопоточную версию скрипта, которая стала эталоном для остальных решений. Использование памяти было довольно стабильным на протяжении всего исполнения, и очевидным недостатком стало время выполнения. Без какого-либо параллелизма сценарий занял около 29 секунд.
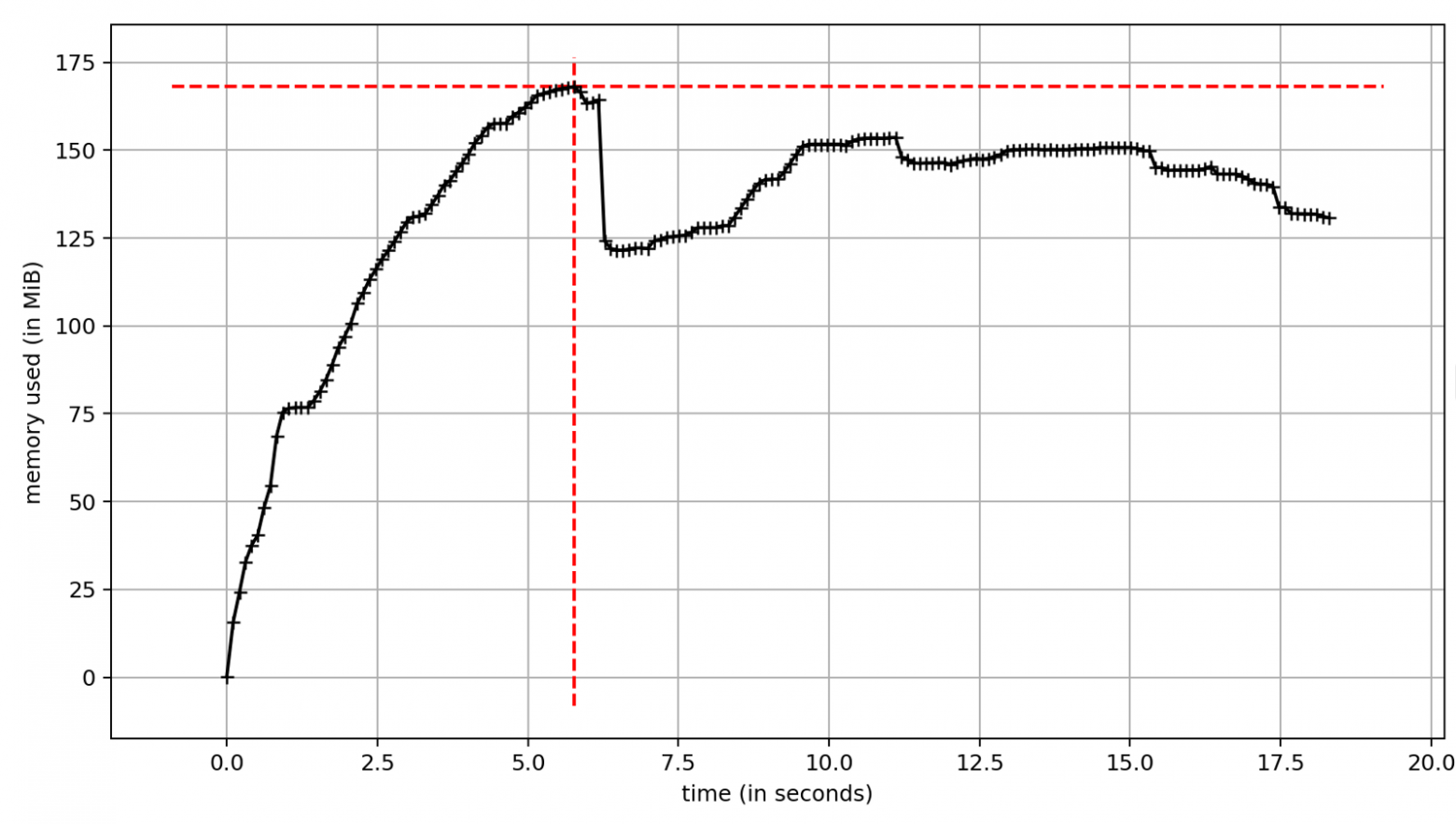
Работа с многопоточностью реализована в стандартной библиотеке. Самый удобный API предоставляет ThreadPoolExecutor. Однако, использование потоков связано с некоторыми недостатками, один из них — значительное потребление памяти. С другой стороны, существенное увеличение скорости выполнения является причиной, по которой мы хотим использовать многопоточность. Время выполнения теста ~17 секунд. Это значительно меньше ~29 секунд при синхронном выполнении. Разница — это скорость операций ввода-вывода. В нашем случае задержки сети.
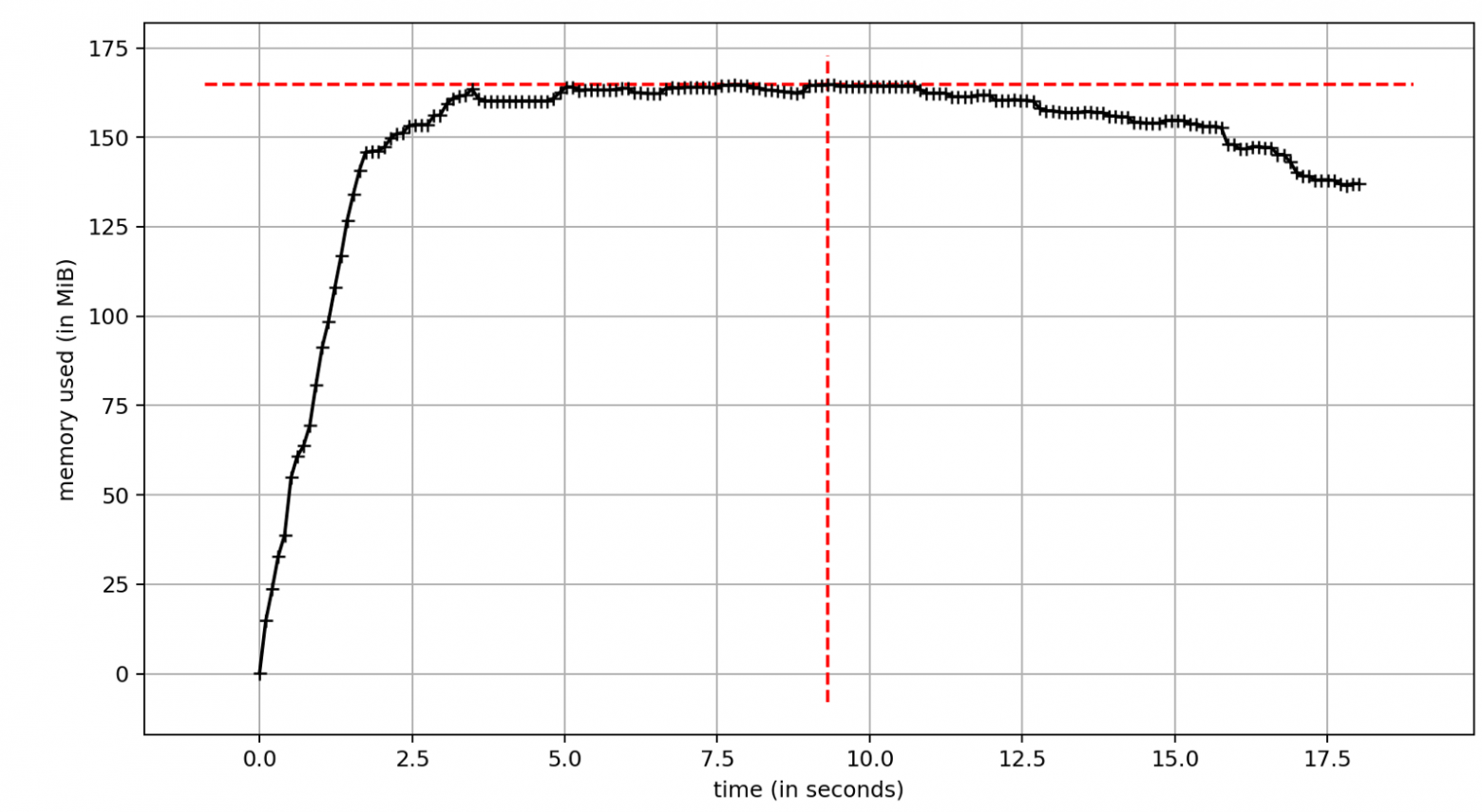
Gevent — это альтернативный подход к параллелизму, он приносит корутины в код Python до версии 3.5. Под капотом у нас легкие псевдо-потоки «гринлеты» плюс несколько потоков для внутренних нужд. Общее потребление памяти сходно с мультипаточностью.
С версии Python 3.5 корутины доступны в модуле asyncio, который стал частью стандартной библиотеки. Чтобы воспользоваться преимуществами asyncio, я использовал aiohttp вместо requests. aiohttp — асинхронный эквивалент requests со схожей функциональностью и API.
Наличие соответствующих библиотек — основной вопрос, который надо прояснить перед началом разработки с asyncio, хотя наиболее популярные IO библиотеки — requests, redis, psycopg2 — имеют асинхронные аналоги.
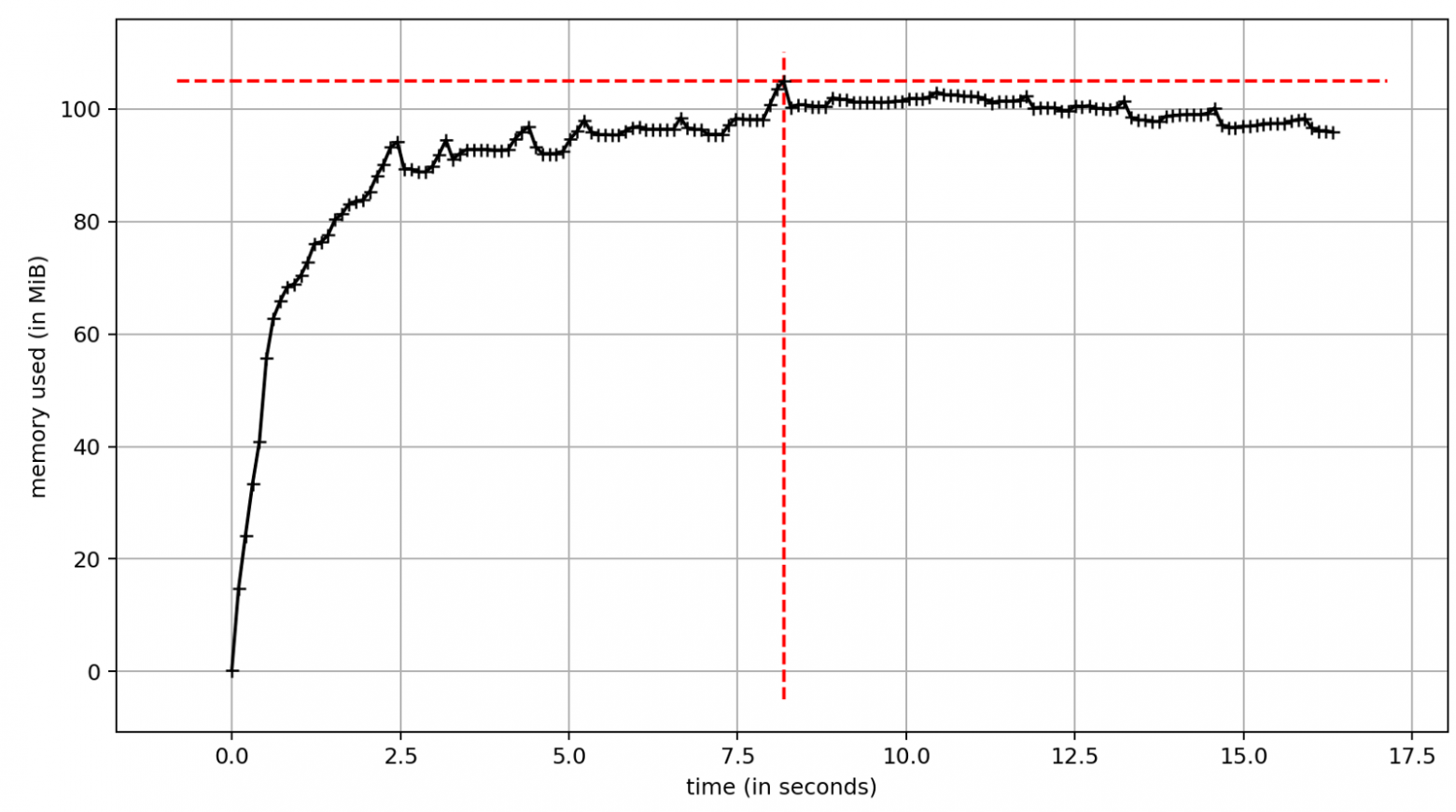
С asyncio потребление памяти значительно меньше. Оно схоже с однопоточной версией скрипта без параллелизма.
Параллелизм — очень эффективный путь ускорения приложений с большим количеством операций ввода-вывода. В моем случае это ~40% прироста производительности в сравнении с последовательной обработкой. Различия в скорости для рассмотренных способов реализации параллелизма незначительны.
ThreadPoolExecutor и Gevent — мощные инструменты, способные ускорить существующие приложения. Их основное преимущество состоит в том, что в большинстве случаев они требуют незначительных изменений кодовой базы. Если говорить об общей производительности, то лучший инструмент — asyncio. Его потребление памяти значительно ниже по сравнению с другими методами параллелизма, что не влияет на общую скорость. За плюсы приходится платить специализированными библиотеками, заточенными под работу с asyncio.
До версии Python 3.5 было два способа реализации параллельной обработки операций ввода-вывода. Нативный метод — использование многопоточности, другой вариант — библиотеки типа Gevent, которые распараллеливают задачи в виде микро-потоков. Python 3.5 предоставил встроенную поддержку параллелизма с помощью asyncio. Мне было любопытно посмотреть, как каждый из них будет работать с точки зрения памяти. Результаты ниже.
Подготовка тестовой среды
Для тестирования я создал простой скрипт. Хотя в нем и не так много функций, он демонстрирует реальный сценарий использования. Скрипт скачивает с сайта цены на автобусные билеты за 100 дней и готовит их для обработки. Потребление памяти измерялось с помощью memory_profiler. Код доступен на Github.
Поехали!
Синхронная обработка
Я реализовал однопоточную версию скрипта, которая стала эталоном для остальных решений. Использование памяти было довольно стабильным на протяжении всего исполнения, и очевидным недостатком стало время выполнения. Без какого-либо параллелизма сценарий занял около 29 секунд.
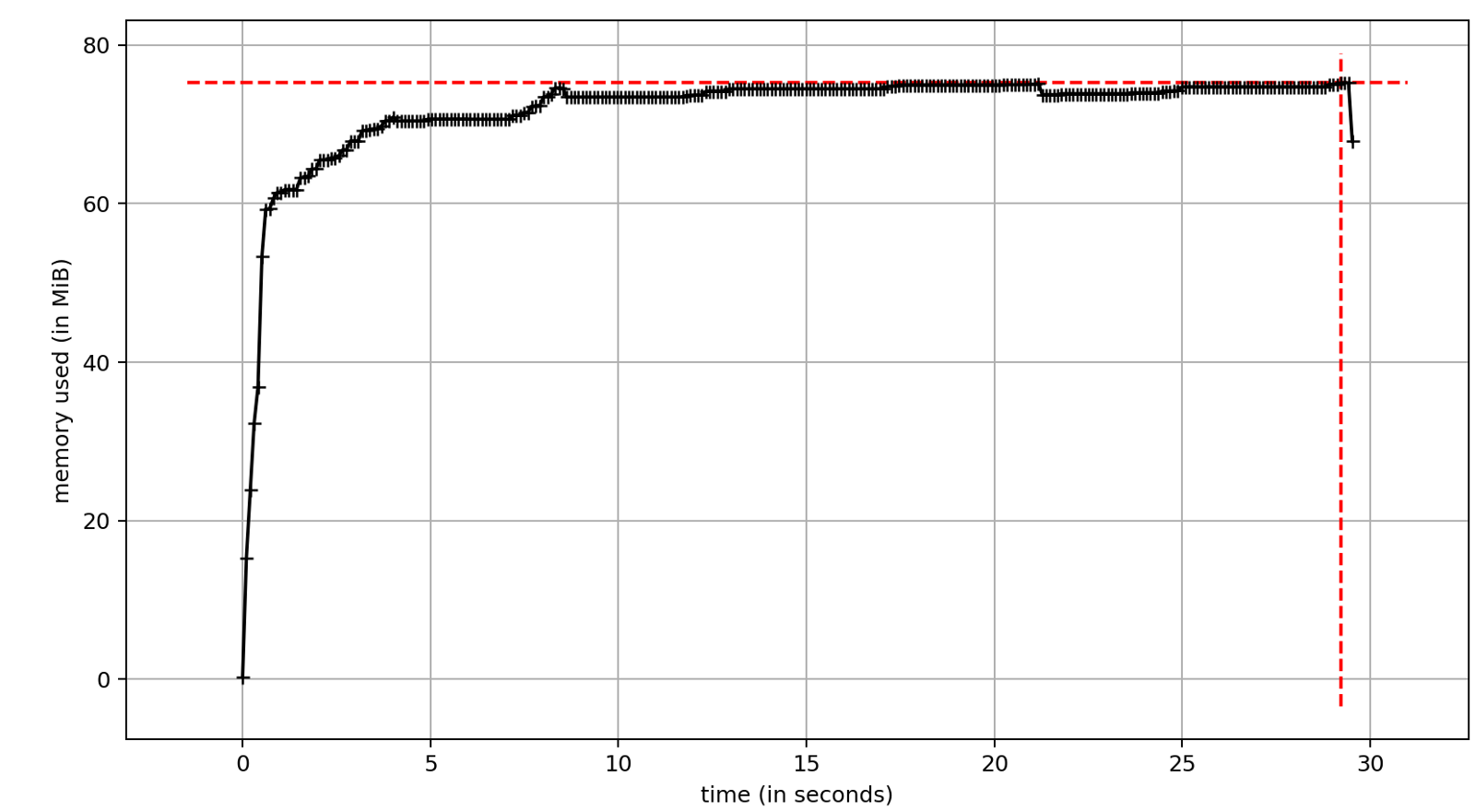
ThreadPoolExecutor
Работа с многопоточностью реализована в стандартной библиотеке. Самый удобный API предоставляет ThreadPoolExecutor. Однако, использование потоков связано с некоторыми недостатками, один из них — значительное потребление памяти. С другой стороны, существенное увеличение скорости выполнения является причиной, по которой мы хотим использовать многопоточность. Время выполнения теста ~17 секунд. Это значительно меньше ~29 секунд при синхронном выполнении. Разница — это скорость операций ввода-вывода. В нашем случае задержки сети.

Gevent
Gevent — это альтернативный подход к параллелизму, он приносит корутины в код Python до версии 3.5. Под капотом у нас легкие псевдо-потоки «гринлеты» плюс несколько потоков для внутренних нужд. Общее потребление памяти сходно с мультипаточностью.

Asyncio
С версии Python 3.5 корутины доступны в модуле asyncio, который стал частью стандартной библиотеки. Чтобы воспользоваться преимуществами asyncio, я использовал aiohttp вместо requests. aiohttp — асинхронный эквивалент requests со схожей функциональностью и API.
Наличие соответствующих библиотек — основной вопрос, который надо прояснить перед началом разработки с asyncio, хотя наиболее популярные IO библиотеки — requests, redis, psycopg2 — имеют асинхронные аналоги.
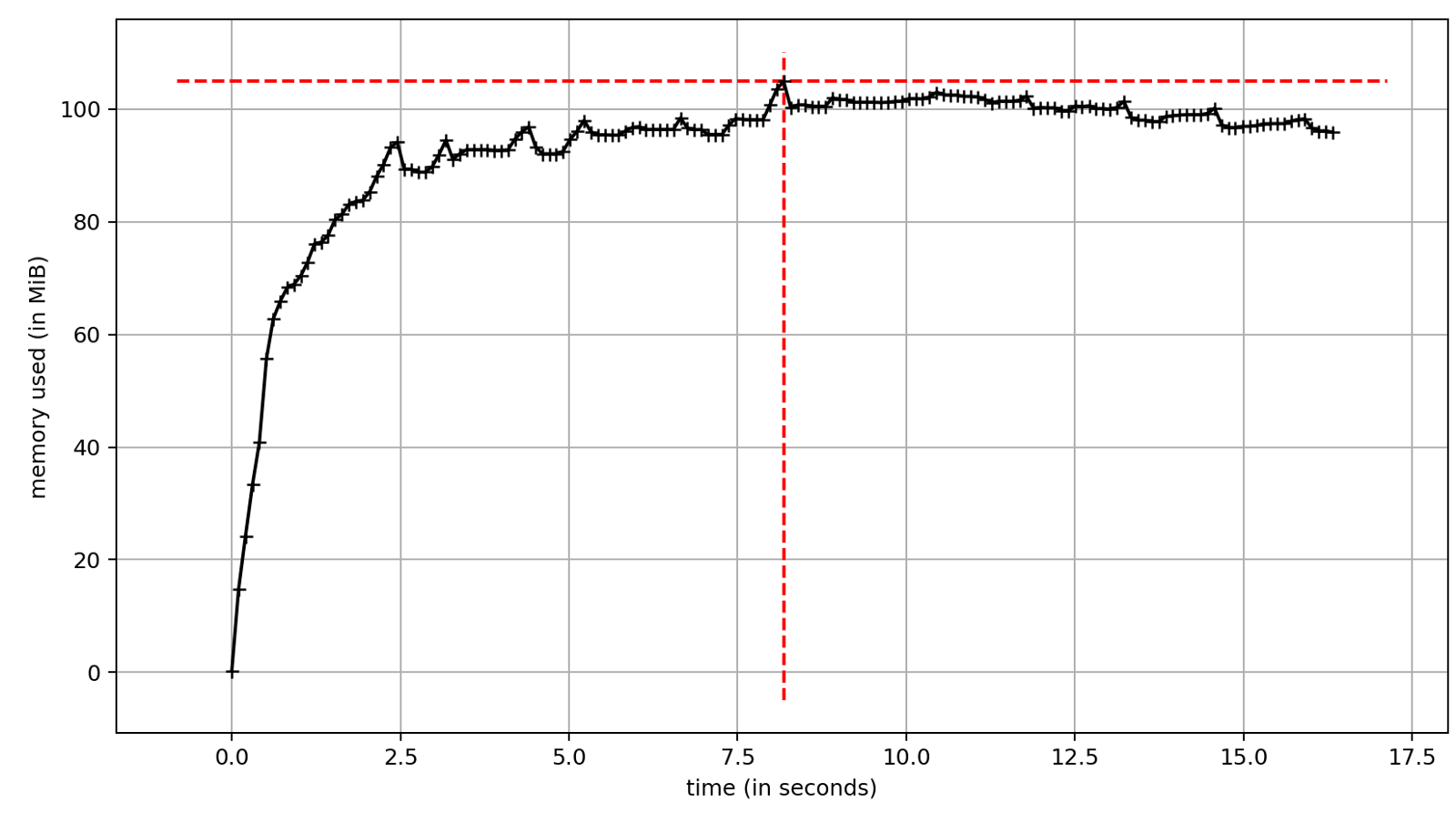
С asyncio потребление памяти значительно меньше. Оно схоже с однопоточной версией скрипта без параллелизма.
Пора начинать использовать asyncio?
Параллелизм — очень эффективный путь ускорения приложений с большим количеством операций ввода-вывода. В моем случае это ~40% прироста производительности в сравнении с последовательной обработкой. Различия в скорости для рассмотренных способов реализации параллелизма незначительны.
ThreadPoolExecutor и Gevent — мощные инструменты, способные ускорить существующие приложения. Их основное преимущество состоит в том, что в большинстве случаев они требуют незначительных изменений кодовой базы. Если говорить об общей производительности, то лучший инструмент — asyncio. Его потребление памяти значительно ниже по сравнению с другими методами параллелизма, что не влияет на общую скорость. За плюсы приходится платить специализированными библиотеками, заточенными под работу с asyncio.
