Приветствую вас!
После изучения коллекций, а именно такие реализации List, как ArrayList и LinkedList, возникла идея, а почему бы не объединить эти структуры данных в одну и посмотреть, что из этого получится.
Зачем это нужно?
- Проблема
ArrayList— у него есть начальный размер по умолчаниюDEFAULT_CAPACITYили заданный размерinitialCapacity, при превышении этого размера, создается новый массив большего размера, при этом туда копируются данные из старого массива, что по времени очень затратно и именно это дает в наихудшем случае алгоритмическую сложностьO(n) - Проблема
LinkedList— здесь наоборот, добавить новый элемент, это всего лишь добавить новую связь (создать еще однуNodeи добавить ссылку на неё), но операция получения элемента по индексу очень затратна, т.к. нужно будет пройтись по всему списку от начала, что очень затратно и даетO(n)
Решение
Что если создать такую структуру данных, при которой вставка и получение любого элемента будет за константное время. Буду использовать технологию ArrayList без пересоздания массива
Для того чтобы связать их между собой, буду использовать двусвязный список:

Реализация
Перейдем непосредственно к исходному коду:
public class Node<T> {
Node prev;
Node next;
T[] value;
public Node(Node prev, Node next, T[] value) {
this.prev = prev;
this.next = next;
this.value = value;
}
}Для начало создадим стандартную структуру двусвязного списка, где value — это массив значений.
Далее перейдем к конкретной реализации класса, объявим необходимые переменные:
public static int INIT_CAPACITY = 100;
private Object[] arr = new Object[INIT_CAPACITY];
private int index = 0;
private int level = 0;
private Node<T> first = new Node<>(null, null, (T[]) arr);
private Node last = first;
private Node current = null;
private int size = 0;Здесь INIT_CAPACITY — начальный размер массива, его можно переопределить в соответствующем конструкторе, arr — собственно сам массив, переменная index — понадобится для расчета индекса, level — для расчета уровня, далее подробно будет рассказано для чего это нужно, first — ссылка на первый элемент списка,
last — ссылка на последний элемент списка, current — ссылка на текущий элемент списка (последней выборки), так можно ускорить выборку подряд идущих элементов или близ — лежащих к ним, size — размер (или количество данных).
Зададим 2 коструктора — по умолчанию и для изменения начального размера:
public MyLinkedList() {
first.next = last.next;
}
public MyLinkedList(int size) {
INIT_CAPACITY = size;
arr = new Object[INIT_CAPACITY];
first.next = last.next;
}Добавление элемента:
public void add(T i) {
if (index == INIT_CAPACITY) {
arr = new Object[INIT_CAPACITY];
last.next = new Node<>(last, null, (T[]) arr);
index = 0;
last = last.next;
}
arr[index] = i;
index++;
size++;
}Здесь проверяем условие, если массив заполнен, то создаем новый и запоминаем ссылку на него.
Получение элемента:
public T get(int i) {
T value;
int level = i / INIT_CAPACITY;
int index = i % INIT_CAPACITY;
if (this.current == null) {
this.level = 0;
this.current = first;
}
if(this.level > level)
for (int j = this.level; j < level; j++) {
this.level = level;
current = current.prev;
}
else
for (int j = this.level; j < level; j++) {
this.level = level;
current = current.next;
}
value = (T) current.value[index];
return value;
}Уровни это количество массивов в списке, т.е на 0-м уровне 1 массив, на 1-м уровне 2 массива и т.д.,index — это индекс текущего уровня 0..INIT_CAPACITY, также у нас есть ссылка на текущий элемент списка current, который был получен из предыдущей выборки, т.е. если новый уровень больше предыдущего, то идем вперед от текущего элемента и если наоборот, то назад. Также добавил 2 быстрые операции — получение первого и последнего элемента:
public T getFirst(){
return first.value[0];
}
public T getLast() {
return (T) last.value[(size-1) % INIT_CAPACITY];
}Первый и последний элемент получить также просто и быстро, как в массиве.
Операция удаления последнего элемента — быстрее всего это затирать значение null-ом, если весь массив становится заполненным null-ми, то теряем ссылку на него и garbage collector все почистит:
public void removeLast(){
if (last.value[0] == null) {
last = last.prev;
index=INIT_CAPACITY-1;
}
last.value[(size-1) % INIT_CAPACITY]=null;
size--;
index--;
}Получение размера — очевидно. Также был добавлен итератор, т.е. этот класс имплементирует Iterable и реализует метод iterator
private Node<T> first;
private int index = -1;
public MyLinkedListIterator(Node<T> first) {
this.first = first;
}
@Override
public boolean hasNext() {
index++;
return first != null;
}
@Override
public T next() {
T value;
int index = this.index % INIT_CAPACITY;
value= first.value[index];
if(index==INIT_CAPACITY-1||this.first.value[index+1]==null)
first=first.next;
return value;
}Время работы
Замерял с помощью JMH benchmark, пример теста:
public class TestGetMyDeque {
private static class SetDeque {
MyDeque<Integer> deque = new MyDeque<>();
SetDeque() {
for (int i = 0; i <Constant.COUNT_ELEMENT; i++) {
deque.add(i);
}
}
}
@State(Scope.Benchmark)
public static class MyState{
SetDeque deque;
@Setup(Level.Invocation)
public void setUp() {
deque = new SetDeque();
}
}
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.SECONDS)
public void getFirst(MyState state, Blackhole blackhole) {
for (int i = 0; i < Constant.COUNT_ELEMENT; i++) {
blackhole.consume(state.deque.deque.getFirst());
}
}
}Документацию, можно посмотреть в интернете
Брал разное количество элементов, результаты тестов в сек:
| N=100000 | Вставка в конец | Получение первого | Получение среднего | Получение последнего |
|---|---|---|---|---|
| MyDeque | 0,002 | 0 | 0,001 | 0 |
| ArrayDeque | 0,002 | 0 | - | 0,001 |
| ArrayList | 0,002 | 0,001 | 0 | 0,001 |
| LinkedList | 0,003 | 0 | 28,465 | 0,001 |
Возьмем миллион элементов:
| N=1000000 | Вставка в конец | Получение первого | Получение среднего | Получение последнего |
|---|---|---|---|---|
| MyDeque | 0,019 | 0,005 | 0,010 | 0,007 |
| ArrayDeque | 0,025 | 0,005 | - | 0,005 |
| ArrayList | 0,036 | 0,005 | 0,005 | 0,005 |
| LinkedList | 0,051 | 0,005 | OutOfMemoryError: Java heap space | 0,006 |
И наконец, возьмем 10 миллионов элементов:
| N=10000000 | Вставка в конец | Получение первого | Получение среднего | Получение последнего |
|---|---|---|---|---|
| MyDeque | 1,832 | 0,047 | 0,090 | 0,071 |
| ArrayDeque | 2,065 | 0,046 | - | 0,058 |
| ArrayList | 4,413 | 0,048 | 0,047 | 0,048 |
| LinkedList | OutOfMemoryError: Java heap space |
Замер памяти делал по принципу https://github.com/jheusser/core-java-performance-examples/
(ось x — миллион элементов, ось y — мб памяти)
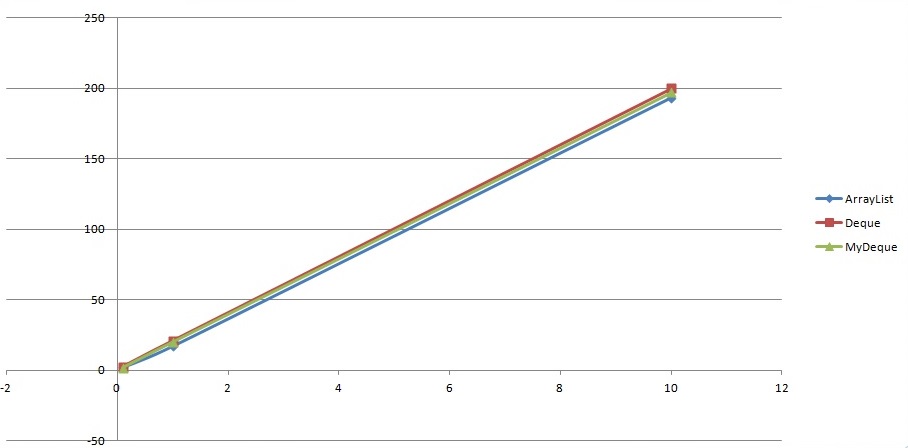
Как видно из графика пожирание памяти этой структурой не сильно отличается от схожих ей структур данных
Вывод
В сухом остатке, получили очередь LIFO, которая работает быстрее, чем обычная Deque, а в плане вставке элементов, намного быстрее чем ArrayList, также нет проблем с которыми можно столкнуться при использовании LinkedList. В дальнейшем планируется реализовать такие операции как вставка и удаление из любого места без потери производительности, уже есть кое-какие наработки по этому поводу, на данном этапе хотелось бы получить обратную связь и увидеть заинтересованность сообщества для дальнейшей работы над новой структурой данных.
