Данная статья рассматривает одну из проблем хранения PHP-сессий в memcached: отсутствие их блокировки.
интернет-магазина ). Рассмотрим пример, состоящий из 2 файлов: counter.php и frameset.php:

http://foldo.ru/developer/habrahabr/standard-session/frameset.php
Открываем frameset.php в браузере и видим: каждый запрос к counter.php увеличивает счётчик в сессии на единицу и счётчик работает правильно. Теперь давайте рассмотрим тот же самый пример, только с сессиями в memcached. Для этого раскомментируем 2 строки в начале скрипта.
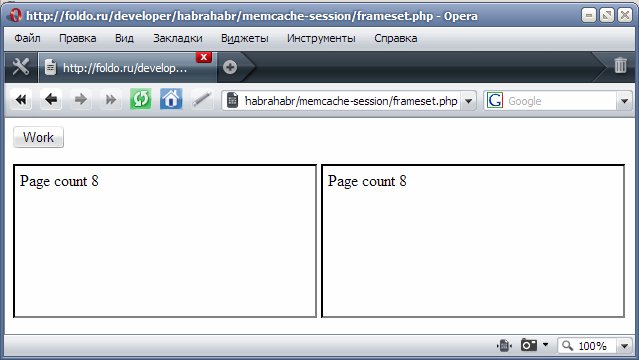
http://foldo.ru/developer/habrahabr/memcache-session/frameset.php
Что мы видим? Счётчик работает неправильно. Почему? Давайте разберёмся в этом. Рассмотрим, что происходит в действительности. Если сессия хранится в файле, при вызове session_start файл открывается, блокируется, читается, производится работа с $_SESSION, после чего новое значение записывается поверх старого, снимается блокировка с файла и файл закрывается. При этом параллельный поток честно дожидается снятия блокировки и только после этого работает. К сожалению, в настоящий момент в memcached нет блокировки переменных, потому получается, что оба потока считывают одинаковые исходные данные, обрабатывают их и записывают, при этом все изменения первого потока безвозвратно затираются. В таблице приведена примерная схема работы для этих двух случаев.
С вопросом «Кто виноват?» мы разобрались. Подведём краткие итоги:
всё-таки есть способ организации блокировки. Блокировка базируется на методе add класса Memcache. Про него в документации написано:
Используя эти две функции, мы можем написать свой session save handler и использовать его, однако это повлечёт за собой дополнительную нагрузку на сервер и дополнительного выигрыша в производительности мы не получим.
Я же подошёл к вопросу с другой стороны. Проанализировав свои потребности, я пришёл к выводу, что в действительности мне требуется хранить всего 2–3 группы активно изменяющихся данных. При этом, данные чаще необходимо считывать, а не записывать. Потому я ввёл для себя понятие субсессии. Субсессия (subsession) — виртуальный объект, который физически располагается вне сессии. Субсессия предназначена для хранения часто изменяющихся данных. Если необходимо изменение данных, субсессия блокируется, считывается, изменяется, записывается и разблокируется. Вот как это выглядит со стороны:
Если требуется просто получение данных из субсессии, то можно не блокировать. Итак, что же мне даёт субсессия? Большая часть кода выполняется в неблокированном режиме, потому существенных задержек не происходит. Чтение данных из субсессии тоже происходит в неблокированном виде, так что блокировка действует не в течение всей работы скрипта, а только на коротких её участках. Да, это несколько усложняет код, но, на мой взгляд, преимущества очевидны.
Введение
Ни для кого не секрет, что одним из самых популярных способов повышения производительности сайта является использование memcached. Об этом неоднократно говорили и приводили многочисленные примеры. Самый простой способ сделать это — использовать memcached для хранения сессий PHP. Для этого нет необходимости переписывать весь код, достаточно нескольких простых действий. Я не буду рассказывать, почему надо хранить сессии в memcached. Я расскажу о том, почему хранение сессий в memcached опасно.Счётчик запросов или «Кто виноват?»
Предположим, нам необходимо подсчитать количество переходов пользователя по сайту (на практике это может быть всё, что угодно: от хранения истории перемещения пользователя по сайту до покупок в корзинеcounter.php
<?php
//ini_set('session.save_handler', 'memcache');
//ini_set('session.save_path', 'tcp://localhost:11211');
session_start();
$_SESSION['habra_counter'] = isset($_SESSION['habra_counter'])? $_SESSION['habra_counter']: 0;
usleep(1000000); // Полезная работа
$_SESSION['habra_counter'] ++; // Счётчик
usleep(1000000); // Полезная работа
echo 'Page count '. $_SESSION['habra_counter'];
?>
frameset.php
<?php session_start(); // это чтоб кука встала ?>
<form action="" method="post" onsubmit="work(); return false;" >
<input type="submit" name="submit" value="Work" />
</form>
<iframe src="" name="iframe1" id="idframe1"></iframe>
<iframe src="" name="iframe2" id="idframe2"></iframe>
<script>
function work (){
document.getElementById('idframe1').src = 'counter.php? f=1' + Math.random();
document.getElementById('idframe2').src = 'counter.php? f=1' + Math.random();
}
</script>

http://foldo.ru/developer/habrahabr/standard-session/frameset.php
Открываем frameset.php в браузере и видим: каждый запрос к counter.php увеличивает счётчик в сессии на единицу и счётчик работает правильно. Теперь давайте рассмотрим тот же самый пример, только с сессиями в memcached. Для этого раскомментируем 2 строки в начале скрипта.

http://foldo.ru/developer/habrahabr/memcache-session/frameset.php
Что мы видим? Счётчик работает неправильно. Почему? Давайте разберёмся в этом. Рассмотрим, что происходит в действительности. Если сессия хранится в файле, при вызове session_start файл открывается, блокируется, читается, производится работа с $_SESSION, после чего новое значение записывается поверх старого, снимается блокировка с файла и файл закрывается. При этом параллельный поток честно дожидается снятия блокировки и только после этого работает. К сожалению, в настоящий момент в memcached нет блокировки переменных, потому получается, что оба потока считывают одинаковые исходные данные, обрабатывают их и записывают, при этом все изменения первого потока безвозвратно затираются. В таблице приведена примерная схема работы для этих двух случаев.
+--+-----------------------------------------++-------------------------------------------++ | | Сессии на жёстком диске || Сессии в memcache || +--+-------------------+---------------------++---------------------+---------------------++ | | Поток 1 | Поток 2 || Поток 1 | Поток 2 || +--+-------------------+---------------------++---------------------+---------------------++ |1 | open file | || connect memcache | || |2 | lock file | open file || read memcache 5 | connect memcache || |3 | read file 5 | lock file || work 5+1| read memcache 5 || |4 | work 5+1 | lock || write memcache 6 | work 5+1|| |5 | write file 6 | lock || close memcache | write memcache 6 || |6 | unlock file | lock || | close memcache || |7 | close file | read file 6 || | || |8 | | work 6+1 || | || |9 | | write file 7 || | || |10| | unlock file || | || |11| | close file || | || +--+-------------------+---------------------++---------------------+---------------------++
С вопросом «Кто виноват?» мы разобрались. Подведём краткие итоги:
- Есть вероятность того, что при активном взаимодействии клиента и сервера часть данных будет безвозвратно потеряна;
- Переход на хранение сессий в memcached может оказаться просто невозможным;
- Memcached позволяет сократить время обработки запроса;
- В сессиях желательно хранить только данные, которые редко изменяются (например, профиль пользователя);
- При увеличении количества серверов memcahed может выступать как единое хранилище сессий.
«Что делать?»
У нас остался только один вопрос — «Что делать?». Скажу сразу, что готового решения у меня нет, однако есть две зарисовки на этот счёт. Обе зарисовки основываются на том, что в memcachedReturns TRUE on success or FALSE on failure. Returns FALSE if such key already exist.Значит, мы можем организовать собственную блокировку вида:
function lock($session_id, $memcache)
{
$max_iterations = 15;
$iteration = 0;
while( !$memcache->add( 'lock_'. $session_id, ...) )
{
$iteration++;
if( $iteration > $max_iterations) {
return false;
}
usleep(1000);
}
return true;
}
function unlock($session_id, $memcache)
{
return $memcache->del( 'lock_'. $ession_id );
}
Используя эти две функции, мы можем написать свой session save handler и использовать его, однако это повлечёт за собой дополнительную нагрузку на сервер и дополнительного выигрыша в производительности мы не получим.
Я же подошёл к вопросу с другой стороны. Проанализировав свои потребности, я пришёл к выводу, что в действительности мне требуется хранить всего 2–3 группы активно изменяющихся данных. При этом, данные чаще необходимо считывать, а не записывать. Потому я ввёл для себя понятие субсессии. Субсессия (subsession) — виртуальный объект, который физически располагается вне сессии. Субсессия предназначена для хранения часто изменяющихся данных. Если необходимо изменение данных, субсессия блокируется, считывается, изменяется, записывается и разблокируется. Вот как это выглядит со стороны:
$this->session->init_subsession('fupload', $this->memc);
// инициализация субсессии
/* lock */ $this->session->fupload->lock();
// блокируем субсессию
$fupload = $this->session->fupload->get();
// получаем субсессию
$fupload = is_array($fupload)? $fupload: array();
// проверяем на корректность
$fupload[] = $new_data;
// добавляем данные
$this->session->fupload->set($fupload);
// записываем сессию
/*unlock*/ $this->session->fupload->unlock();
// снимаем блокировку
Если требуется просто получение данных из субсессии, то можно не блокировать. Итак, что же мне даёт субсессия? Большая часть кода выполняется в неблокированном режиме, потому существенных задержек не происходит. Чтение данных из субсессии тоже происходит в неблокированном виде, так что блокировка действует не в течение всей работы скрипта, а только на коротких её участках. Да, это несколько усложняет код, но, на мой взгляд, преимущества очевидны.
