Теоретическая составляющая.
Так сложилось, узким местом во многих компьютерах является интерфейс оперативная память — процессор. Связано это со значительным временем формирования запроса в память и с тем что частота работы памяти ниже частоты процессора. В общем случае на время получения данных из памяти исполнение программы останавливается. Для улучшения ситуации используется специализированная высокоскоростная память – кеш.
При наличии кеша, если процессору требуется обратиться к определенному байту в оперативной памяти, то сначала выбирается область памяти содержащая этот байт (размер области зависит от процессора) в кеш, а затем происходит считывание данных из кеша процессором. Если процессор записывает данные в память, то они сначала попадают в кеш, а затем в оперативную память.
В многоядерной и многопроцессорной системах у каждого ядра или процессора есть свой персональный кеш. В случае модификации данных в кеше одним процессором, изменения должны быть синхронизированы с другими процессорами, использующими пересекающееся адресное пространство.
Если изменения происходят часто и области данных сильно пересекаются, то будет падать производительность.
У меня возник вопрос насколько все может быть плохо. Кроме того, интересно было посмотреть как влияет длина данных.
Эксперимент.
Для проверки были написаны 2 многопоточных программы на С++ для двух случаев пересечения рабочих областей:
Рабочих нитей – 2, каждая, меняя свои слова, проходит весь массив и, достигнув границы, возвращается к началу и так далее. Каждая из нитей делает по 100 000 000 изменений.
UPD Спасибо mikhanoid за выявленную опечатку в названии CPU.
Для тестирования использовалась рабочая станция HP xw4600, CPU Core 2 Quad (Q9300), OS Linux Slamd64 12.1, ядро 2.6.24.5, компилятор gcc 4.2.3. В итоге получалась 64-х битная программа, следовательно любая арифметическая операция для слов длиной 1,4 и 8 байт выполнялась за 1 такт.
Время исполнения измерялось командой time(1), и усреднялось по 5-и экспериментам.
Сначала была написана программа, которая просто инкрементирует слово и кладет его обратно, но оказалось что в случае массива на стеке оптимизация -O2 творит что-то непотребное. Поэтому была написана вторая программа, которая делает с данными что-то более сложное.
Результаты.
UPD: Thnx за замечание mt_ и Google Charts за api графиков. Результат в графической форме.
Желающие посмотреть цифры, могут промотать дальше.
По оси Y реальное время исполнения программы в секундах. По оси X разрядность слова (парами).
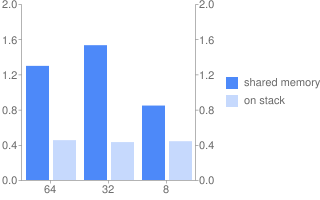
Программа 1.

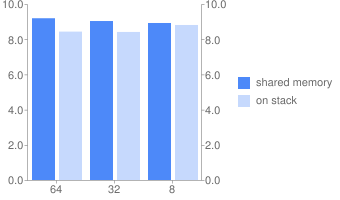
Программа 2.
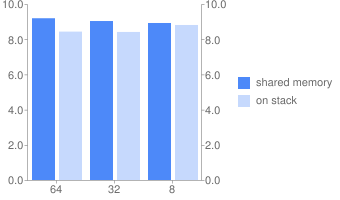
Программа 2 + оптимизация -O2.
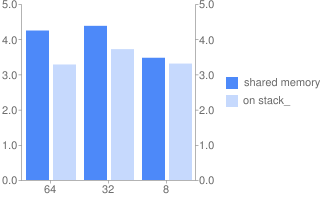
Выводы
Можно точно сказать, что в случае заведомо не пересекающихся областей работает быстрее, причем значительно. Оптимизация как-то влияет, но тенденция сохраняется.
А вот зависимость от длины слова как-то мало заметна.
Идея данного опуса навеяна статьей www.ddj.com/architect/208200273.
UPD Попытка перенести в блог Совершенный код, мне кажется что это самое правильное место.
Результаты в табличной форме.
Результаты представлены в секундах.
Программа 1 (общая память).
Программа 1 (стек)
Программа 2 (общая память).
Программа 2 (стек)
Программа 2 + оптимизация -O2 (общая память).
Программа 2 + оптимизация -O2 (стек)
Исходный код.
Программа 1.
Так сложилось, узким местом во многих компьютерах является интерфейс оперативная память — процессор. Связано это со значительным временем формирования запроса в память и с тем что частота работы памяти ниже частоты процессора. В общем случае на время получения данных из памяти исполнение программы останавливается. Для улучшения ситуации используется специализированная высокоскоростная память – кеш.
При наличии кеша, если процессору требуется обратиться к определенному байту в оперативной памяти, то сначала выбирается область памяти содержащая этот байт (размер области зависит от процессора) в кеш, а затем происходит считывание данных из кеша процессором. Если процессор записывает данные в память, то они сначала попадают в кеш, а затем в оперативную память.
В многоядерной и многопроцессорной системах у каждого ядра или процессора есть свой персональный кеш. В случае модификации данных в кеше одним процессором, изменения должны быть синхронизированы с другими процессорами, использующими пересекающееся адресное пространство.
Если изменения происходят часто и области данных сильно пересекаются, то будет падать производительность.
У меня возник вопрос насколько все может быть плохо. Кроме того, интересно было посмотреть как влияет длина данных.
Эксперимент.
Для проверки были написаны 2 многопоточных программы на С++ для двух случаев пересечения рабочих областей:
- Области не пересекаются и находятся в стеке каждой из нитей;
- Рабочая область для нитей общая, представляет собой массив из 1, 4 и 8 байтных слов, общей длиной 1024 байта, каждая из нитей модифицирует свои слова (например только четные или только нечетные).
Рабочих нитей – 2, каждая, меняя свои слова, проходит весь массив и, достигнув границы, возвращается к началу и так далее. Каждая из нитей делает по 100 000 000 изменений.
UPD Спасибо mikhanoid за выявленную опечатку в названии CPU.
Для тестирования использовалась рабочая станция HP xw4600, CPU Core 2 Quad (Q9300), OS Linux Slamd64 12.1, ядро 2.6.24.5, компилятор gcc 4.2.3. В итоге получалась 64-х битная программа, следовательно любая арифметическая операция для слов длиной 1,4 и 8 байт выполнялась за 1 такт.
Время исполнения измерялось командой time(1), и усреднялось по 5-и экспериментам.
Сначала была написана программа, которая просто инкрементирует слово и кладет его обратно, но оказалось что в случае массива на стеке оптимизация -O2 творит что-то непотребное. Поэтому была написана вторая программа, которая делает с данными что-то более сложное.
Результаты.
UPD: Thnx за замечание mt_ и Google Charts за api графиков. Результат в графической форме.
Желающие посмотреть цифры, могут промотать дальше.
По оси Y реальное время исполнения программы в секундах. По оси X разрядность слова (парами).
Программа 1.
Программа 2.
Программа 2 + оптимизация -O2.

Выводы
Можно точно сказать, что в случае заведомо не пересекающихся областей работает быстрее, причем значительно. Оптимизация как-то влияет, но тенденция сохраняется.
А вот зависимость от длины слова как-то мало заметна.
Идея данного опуса навеяна статьей www.ddj.com/architect/208200273.
UPD Попытка перенести в блог Совершенный код, мне кажется что это самое правильное место.
Результаты в табличной форме.
Результаты представлены в секундах.
Программа 1 (общая память).
| Длина слова | 64 | 32 | 8 |
|---|---|---|---|
| Реальное время | 1,297 | 1,532 | 0,846 |
| Время польз. режима | 2,461 | 3,049 | 1,664 |
Программа 1 (стек)
| Длина слова | 64 | 32 | 8 |
|---|---|---|---|
| Реальное время | 0,453 | 0,431 | 0,441 |
| Время польз. режима | 0,851 | 0,842 | 0,866 |
Программа 2 (общая память).
| Длина слова | 64 | 32 | 8 |
|---|---|---|---|
| Реальное время | 9,191 | 9,033 | 8,921 |
| Время польз. режима | 18,365 | 18,039 | 17,824 |
Программа 2 (стек)
| Длина слова | 64 | 32 | 8 |
|---|---|---|---|
| Реальное время с | 8,432 | 8,412 | 8,808 |
| Время польз. Режима с | 16,843 | 16,796 | 17,548 |
Программа 2 + оптимизация -O2 (общая память).
| Длина слова | 64 | 32 | 8 |
|---|---|---|---|
| Реальное время | 4,247 | 4,380 | 3,473 |
| Время польз. режима | 8,415 | 8,960 | 6,781 |
Программа 2 + оптимизация -O2 (стек)
| Длина слова | 64 | 32 | 8 |
|---|---|---|---|
| Реальное время | 3,282 | 3,718 | 3,308 |
| Время польз. режима | 6,550 | 7,384 | 5,565 |
Исходный код.
Программа 1.
#include <sys/types.h>
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define TBYTES 1024
//
#define TOTAL 2
// определяет тип слова u_int8_t u_int32_t u_int64_t
#define MTYPE u_int8_t
//
#define MAXAR TBYTES/sizeof(MTYPE)
#define DOIT 100000000
MTYPE *array;
pthread_mutex_t mux = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
int workers = 2;
// Определяет используется ли общая память
//#define SHARED 1
void*
runner(void* args){
unsigned int which = *(unsigned int*)args; delete (unsigned int*)args;
unsigned int index = which;
MTYPE array1[MAXAR];
//
for ( unsigned int i = 0; i < DOIT; ++i){
if ( index >= MAXAR)
index = which;
//
#if defined(SHARED)
array[index] = array[index] + 1;
#else
array1[index] = array1[index] + 1;
#endif
//
index += TOTAL;
}
//
pthread_mutex_lock(&mux);
-- workers;
pthread_mutex_unlock(&mux);
pthread_cond_broadcast(&cond);
//
return 0;
};
int
main() {
//
array = (MTYPE*)calloc(MAXAR, sizeof(MTYPE));
//
unsigned int *which;
pthread_t t1;
pthread_attr_t attr;
//
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
//
which = new unsigned int(0);
pthread_create(&t1, &attr, runner, (void*)which);
//
which = new unsigned int(1);
pthread_create(&t1, &attr, runner, (void*)which);
//
pthread_mutex_lock(&mux);
while(!pthread_cond_wait(&cond, &mux)){
if ( !workers)
break;
};
pthread_mutex_unlock(&mux);
//
return 0;
};
//
* This source code was highlighted with Source Code Highlighter.
Программа 2.
#include <sys/types.h>
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define TBYTES 1024
//
#define TOTAL 2
// определяет тип слова u_int8_t u_int32_t u_int64_t
#define MTYPE u_int64_t
//
#define MAXAR TBYTES/sizeof(MTYPE)
//#define DOIT 100000000 * (sizeof(u_int64_t) / sizeof(MTYPE))
#define DOIT 100000000
MTYPE *array;
pthread_mutex_t mux = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
int workers = 2;
template<typename RTYPE, int TLEN>
RTYPE scramble(u_int16_t *seed, RTYPE a){
int d;
//
for ( d = 0; d < 8; ++d){
u_int16_t mask;
//
mask = (*seed & 0x1) ^ ( (*seed >> 1) &0x1);
mask = mask & 0x1;
*seed = (mask << 15) | (*seed >> 1);
//
a = a ^ ((RTYPE)mask << d);
}
//
return a;
};
// Определяет используется ли общая память
//#define SHARED 1
void*
runner(void* args){
unsigned int which = *(unsigned int*)args; delete (unsigned int*)args;
unsigned int index = which;
u_int16_t seed = 0x4a80;
MTYPE array1[MAXAR];
//
for ( unsigned int i = 0; i < DOIT; ++i){
MTYPE data;
if ( index >= MAXAR)
index = which;
//
#if defined(SHARED)
data = array[index];
array[index] = scramble<MTYPE, 8*sizeof(MTYPE)>(&seed, data);
#else
data = array1[index];
array1[index] = scramble<MTYPE, 8*sizeof(MTYPE)>(&seed, data);
#endif
//
index += TOTAL;
}
//
pthread_mutex_lock(&mux);
-- workers;
pthread_mutex_unlock(&mux);
pthread_cond_broadcast(&cond);
//
return 0;
};
int
main() {
//
array = (MTYPE*)calloc(MAXAR, sizeof(MTYPE));
//
unsigned int *which;
pthread_t t1;
pthread_attr_t attr;
//
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
//
which = new unsigned int(0);
pthread_create(&t1, &attr, runner, (void*)which);
//
which = new unsigned int(1);
pthread_create(&t1, &attr, runner, (void*)which);
//
pthread_mutex_lock(&mux);
while(!pthread_cond_wait(&cond, &mux)){
if ( !workers)
break;
};
pthread_mutex_unlock(&mux);
//
return 0;
};
//
* This source code was highlighted with Source Code Highlighter.
