Задача
Когда диски были маленькие, а Интернет большой, владельцы частных FTP-серверов сталкивались со следующей проблемой:
На каждом жестком диске создавалась папочка Video или Soft, и получалось так, что добавив новый жесткий диск, приходилось делать на нем папочки Video2, Soft2, etc.
Задача поменять жесткий диск на диск большего объема приводила к тому, что данные нужно было куда-то переносить, все это происходило нетривиально и с большими downtime'ами.
Разработанная нами система в 2005 году позволила собрать надежный и быстрый массив в 3 терабайта, масштабируемый, расширяемый, в режиме онлайн, добавляя диски или целые сервера с дисками.
Цена всего решения составляла 110% от стоимости самих дисков, т.е. по-сути, бесплатной, с небольшим overhead.
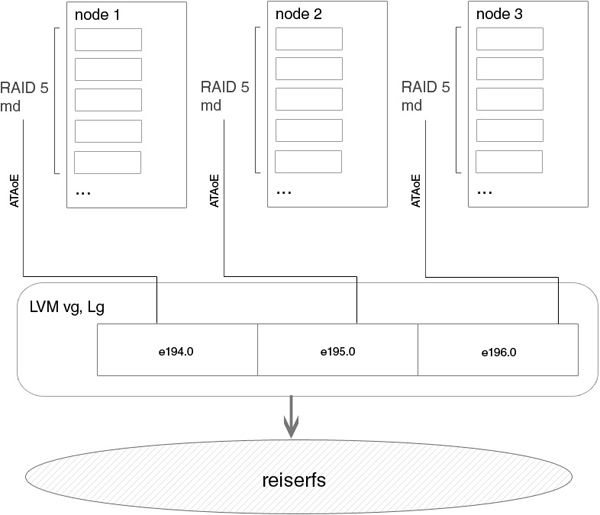
Вот примерная схема устройства нашего хранилища:

Реализация
Идея такова: есть supervisor и есть ноды. Supervisor — это паблик сервер, на который заходят клиенты, у него есть несколько гигабитных bonding интерфейсов наружу, и несколько — внутрь, к нашим нодам. Супервайзор берет экспортированные с помощью vblade по ATAoE массивы или отдельные диски, делает поверх них LVM и делает доступным этот раздел по FTP. Также супервайзор является сервером бездисковой загрузки для нод, и на нем же находится вся файловая система нод, с которой после загрузки они общаются по NFS. Ноды — это чисто диски, загрузка по PXE, далее запускается наш etherpopulate и все диски экспортируются.
1. Настройка для удаленной загрузки нод
устройство ноды
ftp # ls /diskless/
bzImage node pxelinux.0 pxelinux.cfgядро, директория node — rootfs, конфиги для pxe
ftp # ls /diskless/node/
bin boot dev etc lib mnt proc root sbin sys tmp usr var
ftp # chroot /diskless/node/
ftp / # which vblade
/usr/sbin/vblade
ftp / # vblade
usage: vblade [ -m mac[,mac...] ] shelf slot netif filename
ftp / #все это будет доступно на нодах
ftp node # cat /diskless/pxelinux.cfg/default
DEFAULT /bzImage
APPEND ip=dhcp root=/dev/nfs nfsroot=172.18.0.193:/diskless/node idebus=66конфиг для pxe, указан nfsroot
конфиг dhcpd, не забываем запустить.
ftp etc # more dhcp/dhcpd.conf
option domain-name "domain.com";
default-lease-time 600;
max-lease-time 7200;
ddns-update-style none;
option space PXE;
option PXE.mtftp-ip code 1 = ip-address;
option PXE.mtftp-cport code 2 = unsigned integer 16;
option PXE.mtftp-sport code 3 = unsigned integer 16;
option PXE.mtftp-tmout code 4 = unsigned integer 8;
option PXE.mtftp-delay code 5 = unsigned integer 8;
option PXE.discovery-control code 6 = unsigned integer 8;
option PXE.discovery-mcast-addr code 7 = ip-address;
subnet 172.16.0.0 netmask 255.255.0.0 {
}
subnet 172.18.0.192 netmask 255.255.255.192 {
class "pxeclients" {
match if substring (option vendor-class-identifier, 0, 9) = "PXEClient";
option vendor-class-identifier "PXEClient";
vendor-option-space PXE;
option PXE.mtftp-ip 0.0.0.0;
filename "pxelinux.0";
next-server 172.18.0.193;
}
host node-1 {
hardware ethernet 00:13:d4:68:b2:7b;
fixed-address 172.18.0.194;
}
host node-2 {
hardware ethernet 00:11:2f:45:e9:fd;
fixed-address 172.18.0.195;
}
host node-3 {
hardware ethernet 00:07:E9:2A:A9:AC;
fixed-address 172.18.0.196;
}
}конфиг tftpd
ftp etc # more /etc/conf.d/in.tftpd
# /etc/init.d/in.tftpd
# Path to server files from
INTFTPD_PATH="/diskless"
INTFTPD_USER="nobody"
# For more options, see tftpd(8)
INTFTPD_OPTS="-u ${INTFTPD_USER} -l -vvvvvv -p -c -s ${INTFTPD_PATH}"запущен tftpd?
ftp etc # ps -ax |grep tft
Warning: bad ps syntax, perhaps a bogus '-'? See procps.sf.net/faq.html
5694 ? Ss 0:00 /usr/sbin/in.tftpd -l -u nobody -l -vvvvvv -p -c -s /diskless
31418 pts/0 R+ 0:00 grep tftконфиг для nfs, не забываем запустить.
ftp etc # more exports
/diskless/node 172.18.0.192/255.255.255.192(rw,sync,no_root_squash)Настройка для удаленной загрузки закончена, все ноды прописаны.
2. Программная часть для автоматизации сборки массивов
софтина, которая запускается на нодах, делает raid-массивы md* и экспортирует их по ataoe на supervisor.
ftp# chroot /diskless/node
ftp etc # more /usr/sbin/etherpopulate
#!/usr/bin/perl
my $action = shift();
#system('insmod /lib/modules/vb-2.6.16-rc1.ko')
# if ( -f '/lib/modules/vb-2.6.16-rc1.ko');
# Get information on node_id's of ifaces
my @ifconfig = `ifconfig`;
my $int;
my %iface;
foreach my $line (@ifconfig) {
if ($line =~ /^(\S+)/) {
$int = $1;
}
if ($line =~ /inet addr:(\d+\.\d+\.\d+\.)(\d+)/ && $1 ne '127.0.0.' && $int) {
$iface{$int} = $2;
$int = "";
}
}
my $vblade_kernel = ( -d "/sys/vblade" )?1:0;
if ( $vblade_kernel ) {
print " Using kernelspace vblade\n" if ($action eq "start");
} else {
print " Using userspace vblade\n" if ($action eq "start");
}
# Run vblade
foreach my $int (keys %iface) {
my $node_id = $iface{$int};
open(DATA, "/etc/etherpopulate.conf");
while () {
chomp;
s/#.*//;
s/^\s+//;
s/\s+$//;
next unless length;
if ($_ =~ /^node-$node_id\s+(\S+)\s+(\S+)\s+(\S.*)/) {
my $cfg_action = $1;
my $command = $2;
my $parameters = $3;
# Export disk over ATAoE
if ($action eq $cfg_action && $command eq "ataoe" && $parameters =~ /(\S+)\s+(\d+)/) {
my $disk_name = $1;
my $disk_id = $2;
if ($vblade_kernel) {
if ( $disk_name =~ /([a-z0-9]+)$/ ) {
my $disk_safe_name = $1;
system("echo 'add $disk_safe_name $disk_name' > /sys/vblade/drives");
system("echo 'add $int $node_id $disk_id' > /sys/vblade/$disk_safe_name/ports");
}
} else {
system("/sbin/start-stop-daemon --background --start --name 'vblade_$node_id_$disk_id' --exec /usr/sbin/vblade $node_id $disk_id eth0 $disk_name");
}
print " Exporting disk: $disk_name [ $node_id $disk_id ] via $int\n";
}
# Execute specified command
if ($action eq $cfg_action && $command eq "exec") {
system($parameters);
}
}
}
close(DATA);
}
конфиг для etherpopulate при участии трех нод. еще два доп. диска с каждой ноды экспортируются для других целей (backup на raid1)
ftp sbin # more /diskless/node/etc/etherpopulate.conf
# ----------------------
# Node 194 160gb
node-194 start exec /sbin/mdadm -A /dev/md0 -f /dev/hd[a-h] /dev/hdl
node-194 start ataoe /dev/md0 0 # Vblade FTP array
node-194 start ataoe /dev/hdk 1 # Vblade BACKUP disk
node-194 stop exec /usr/bin/killall vblade
node-194 stop exec /sbin/mdadm -S /dev/md0
# ----------------------
# Node 195 200 gb
node-195 start exec /sbin/mdadm -A /dev/md0 /dev/hd[a-b] /dev/hd[e-f] /dev/hd[g-h] /dev/sd[a-c]
node-195 start ataoe /dev/md0 0 # Vblade FTP array
node-195 start ataoe /dev/sdd 1 # Vblade BACKUP disk
node-195 stop exec /usr/bin/killall vblade
node-195 stop exec /sbin/mdadm -S /dev/md0
# ----------------------
# Node 196 200 gb
node-196 start exec /sbin/mdadm -A /dev/md0 /dev/hd[a-f]
node-196 start ataoe /dev/md0 0 # Vblade FTP array
node-196 stop exec /usr/bin/killall vblade
node-196 stop exec /sbin/mdadm -S /dev/md03. Заключительные работы
заставляем винты на нодах работать на максимальной скорости в ущерб надежности
hd*_args="-d1 -X69 -udma5 -c1 -W1 -A1 -m16 -a16 -u1"Убедимся в ядре для supervisor'а. На самих нодах экспорт в ATAoE происходит в userland, с помощью vblade.
ftp good # grep -i OVER_ETH .config
CONFIG_ATA_OVER_ETH=yна самих нодах сразу после загрузки и запуска etherpopulate в соответствии с конфигом.
node-195 ~ # cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid5] [raid4] [raid6] [multipath] [faulty]
md0 : active raid5 hda[0] sdc[8] sdb[7] sda[6] hdh[5] hdg[4] hdf[3] hde[2] hdb[1]
1562887168 blocks level 5, 64k chunk, algorithm 2 [9/9] [UUUUUUUUU]
unused devices: node-195 ~ # ps -ax | grep vblade | grep md
Warning: bad ps syntax, perhaps a bogus '-'? See procps.sf.net/faq.html
2182 ? Ss 2090:41 /usr/sbin/vblade 195 0 eth0 /dev/md0
node-195 ~ # mount
rootfs on / type rootfs (rw)
/dev/root on / type nfs (ro,v2,rsize=4096,wsize=4096,hard,nolock,proto=udp,addr=172.18.0.193)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
udev on /dev type tmpfs (rw,nosuid)
devpts on /dev/pts type devpts (rw)
none on /var/lib/init.d type tmpfs (rw)
shm on /dev/shm type tmpfs (rw,nosuid,nodev,noexec)
собираем lvm из дисков на supervisor'е, в дальнейшем это делать не нужно, просто по vgscan будет находиться готовый к монтированию раздел
ftp / # ls -la /dev/etherd/*
c-w--w---- 1 root disk 152, 3 Jun 7 2008 /dev/etherd/discover
brw-rw---- 1 root disk 152, 49920 Jun 7 2008 /dev/etherd/e194.0
brw-rw---- 1 root disk 152, 49936 Jun 7 2008 /dev/etherd/e194.1
brw-rw---- 1 root disk 152, 49920 Jun 7 2008 /dev/etherd/e195.0
brw-rw---- 1 root disk 152, 49936 Jun 7 2008 /dev/etherd/e195.1
brw-rw---- 1 root disk 152, 49920 Jun 7 2008 /dev/etherd/e196.0
cr--r----- 1 root disk 152, 2 Jun 7 2008 /dev/etherd/err
c-w--w---- 1 root disk 152, 4 Jun 7 2008 /dev/etherd/interfacesС первых двух нод экспортировалось по 1 массиву и по 1 диску, с третьей ноды — только массив.
Перед тем, как эти устройства можно использовать на супервайзоре для LVM, нужно сделать «специальную« разметку, чтобы LVM добавил некоторые внутренние идентификаторы на диск.
# pvcreate /dev/etherd/e194.0
...
...Диски готовы к использованию. Создаем Volume Group.
# vgcreate cluster /dev/etherd/e194.0 /dev/etherd/e195.0 /dev/etherd/e196.0Хоть группа становится сразу активной, в принципе ее можно включать
# vgchange -a y clusterи выключать
# vgchange -a n clusterЧтобы что-то добавить в volume group используйте
# vgextend cluster /dev/*...Создаем Logical Volume hyperspace на все доступное место. Каждый PE по дефолту равен 4mb. Так
# vgdisplay cluster | grep "Total PE"
Total PE 1023445
# lvcreate -l 1023445 cluster -n hyperspaceПосмотреть, что получилось можно vgdisplay,lvdisplay,pvdisplay.
Расширять все можно с помощью vgextend,lvextend, resize_reiserfs.
Подробнее здесь http://tldp.org/HOWTO/LVM-HOWTO/
Имеем в итоге /dev/cluster/hyperspace и делаем ему mkreiserfs и mount. Все готово. Настройку фтп-сервера опустим. Та-да!
Повторное использование
На самом супервайзоре в случае его перезагрузки достаточно выполнять
more runme.sh
#!/bin/sh
vgscan
vgchange -a y
mount /dev/cluster/hyperspace /mnt/ftpчтобы использовать заранее созданный массив.
Недостатки
- конкретно в нашем случае ошибка была с выбором самих жестких дисков. Почему-то выбор пал на Maxtor и почти вся партия в 30 дисков за год пошла бэдами;
- не использовалась горячая замена, т.к. это был все еще IDE. В случае с hotplug SATA нужно было бы на уровне mdadm на самих нодах настроить уведомление о выходе дисков из строя;
- proftpd нужно запускать только после того, как в файловую систему супервайзора примонтируется lvm из ataoe устройств. если proftpd запускался раньше, то он не понимал, что произошло вообще;
- долго экспериментировали с ядерным и userspace'ным vblade на нодах, но тогда это была заря развития ataoe и все работало, как повезет. но работало;
- в качестве файловой системы можно использовать или reiserfs или xfs — только они поддерживали на тот момент онлайн-ресайз если диск под ними увеличился;
- тогда только-только стали появляться патчи, которые позволяли расширять в онлайне raid-5 массив md
- существовало ограничение на ataoe по 64 слота на «полку». Полок можно было сделать штук 10, т.е., в принципе, какие-то ограничения были, типа 640 НОД :)
- есть много нюансов с производительностью, но все они решаемы в той или иной степени. в кратце — не бойтесь, когда поначалу скорость будет не очень, нет предела совершенству;
Выводы
Решение, безусловно интересное, и хочется сделать его уже на терабайтных винтах, hotplug sata и с новыми свежими версиями софта. но кто пойдет на такой подвиг, неизвестно. Может быть, ты, %username%?
Ссылки по теме
http://tldp.org/HOWTO/LVM-HOWTO/
http://sourceforge.net/search/?words=ataoe&type_of_search=soft&pmode=0&words=vblade&Search=Search
http://www.gentoo.org/doc/en/diskless-howto.xml
Оригинал статьи
P.S. Special thx to 029ah за написание скриптов.
