О мощи и гибкости регулярных выражений написано много, и их использование давно уже является стандартом для различного рода операций над текстом. Пожалуй, чаще всего регэкспы работают при валидации вводимых данных — здесь им практически нет альтернативы, если не считать громоздкий циклический разбор с кучей неочевидных проверок. Начнём с самого простого:
По сути, слово с дефисами.
Паттерн: /^[a-z0-9-]+$/

Буквы, цифры, дефисы и подчёркивания, от 3 до 16 символов.
Паттерн: /^[a-z0-9_-]{3,16}$/

То же, что и юзернейм, только от 6 до 18.
Паттерн: /^[a-z0-9_-]{6,18}$/

От себя: более кратко — /^[\w_]{6,18}$/. Аналогично для юзернейма.
Символ # (необязательно), затем слово, состоящее из букв от a до f или цифр, длиной 3 или 6.
Паттерн: /^#?([a-f0-9]{6}|[a-f0-9]{3})$/

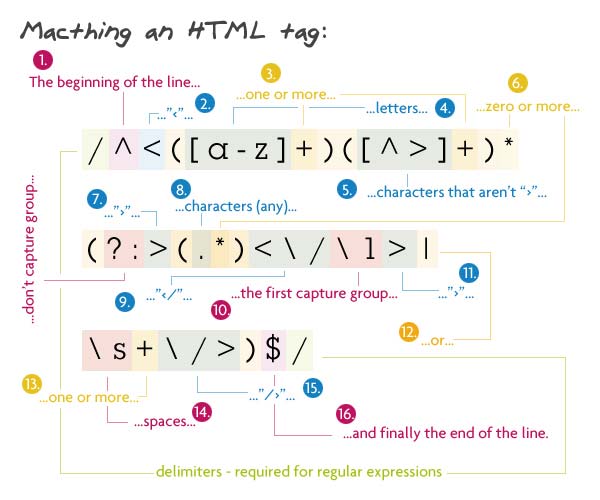
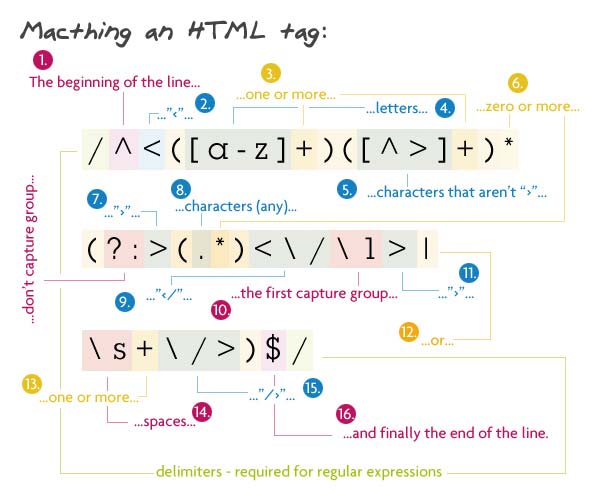
За открывающей скобкой < должно стоять слово из букв — имя элемента, затем могут быть атрибуты — любые символы, кроме закрывающей скобки >. Далее — любой текст (содержимое) и закрывающий тэг, т.е. <имя />, или как минимум один пробел, слэш и закрывающаю скобка (самозакрывающийся тэг).
Паттерн: /^<([a-z]+)([^>]+)*(?:>(.*)<\/\1>|\s+\/>)$/
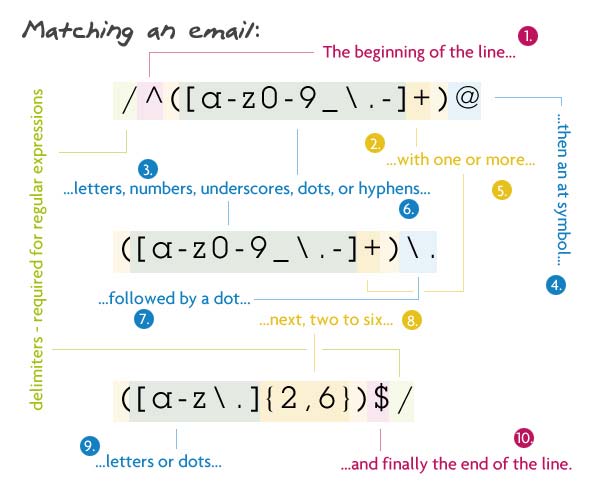
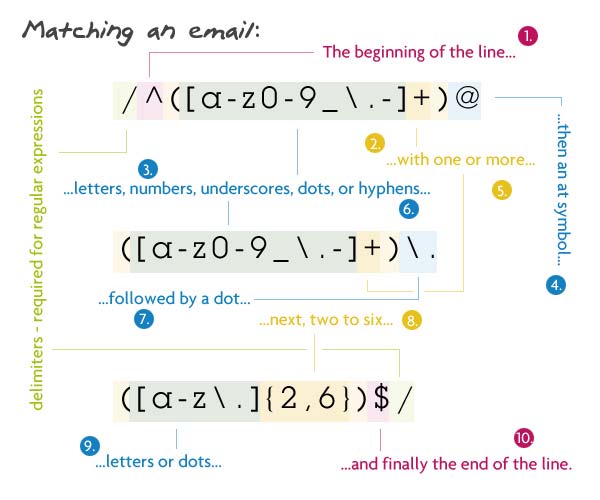
Общий вид — логин@поддомен.домен. Логин, как и поддомен — слова из букв, цифр, подчёркиваний, дефисов и точек. А домен (имеется в виду 1го уровня) — это от 2 до 6 букв и точек.
Паттерн: /^([a-z0-9_\.-]+)@([a-z0-9_\.-]+)\.([a-z\.]{2,6})$/
От себя: можно короче — /^([\w\._]+)@\1\.([a-z]{2,6}\.?)$/. Это ещё и чуть правильнее — точка в домене первого уровня может встретиться только один раз и только в конце.
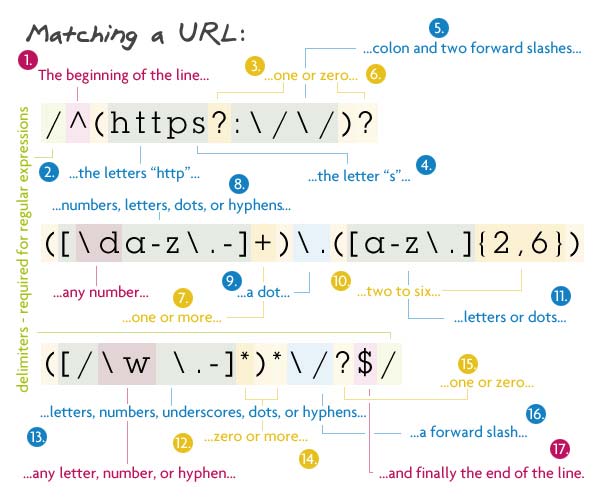
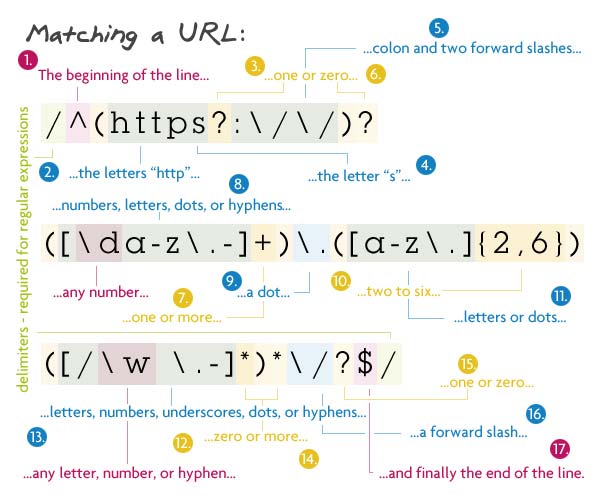
Первым делом — необязательный протокол (http:// или https://), затем последовательность букв, цифр, дефисов, подчёркиваний и точек (домены уровня > 1), потом домен нулевого уровня (от 2 до 6 букв и точек) и, наконец, файловая структура — набор слов из букв, цифр, дефисов, подчёркиваний и точек со слэшем в конце. Всё это может завершаться опять-таки слэшем.
Паттерн: /^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
От себя: лучше так — /^(https?:\/\/)?([\w\.]+)\.([a-z]{2,6}\.?)(\/[\w\.]*)*\/?$/
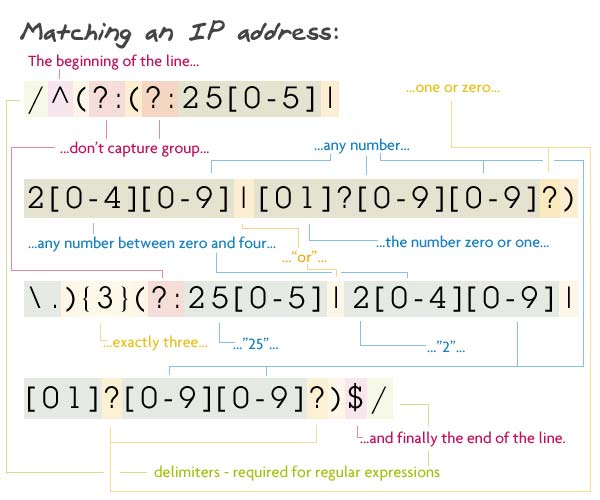
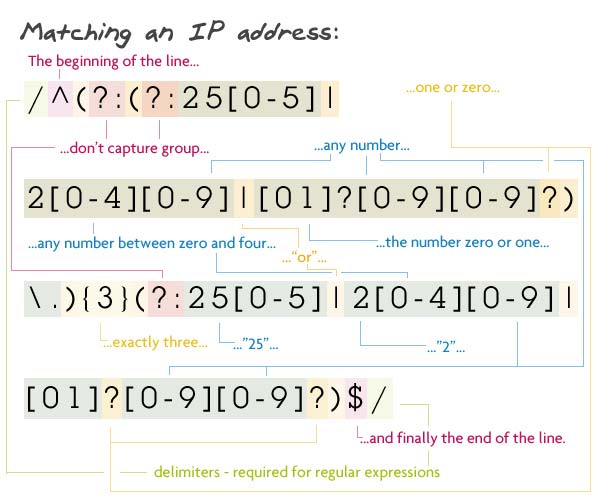
4 группы цифр (от 1 до 3 цифр в каждой) разделены точками. Если группа состоит из 3 символов, то первый из них — 1 или 2; если 1, то остальные от 0 до 9, а если 2 — то второй от 0 до 5; если второй символ от 0 до 4, то третий — от 0 до 9, а если второй 5 — то третий от 0 до 5. Если же группа состоит из 2 символов, то первый — от 1 до 9, второй — от 0 до 9. В случае односимвольной группы этим символом может быть цифра от 1 до 9.
Паттерн: /^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
От себя: по-моему, так правильнее — /^(?:(?:25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(?:25[0-5]|2[0-4]\d|[01]?\d\d?)$/.
Взято отсюда
1. Часть ЧПУ (человекопонятный URL)
По сути, слово с дефисами.
Паттерн: /^[a-z0-9-]+$/

2. Юзернейм
Буквы, цифры, дефисы и подчёркивания, от 3 до 16 символов.
Паттерн: /^[a-z0-9_-]{3,16}$/

3. Пароль
То же, что и юзернейм, только от 6 до 18.
Паттерн: /^[a-z0-9_-]{6,18}$/

От себя: более кратко — /^[\w_]{6,18}$/. Аналогично для юзернейма.
4. Шестнадцатиричный цвет
Символ # (необязательно), затем слово, состоящее из букв от a до f или цифр, длиной 3 или 6.
Паттерн: /^#?([a-f0-9]{6}|[a-f0-9]{3})$/

5. XML тэг
За открывающей скобкой < должно стоять слово из букв — имя элемента, затем могут быть атрибуты — любые символы, кроме закрывающей скобки >. Далее — любой текст (содержимое) и закрывающий тэг, т.е. <имя />, или как минимум один пробел, слэш и закрывающаю скобка (самозакрывающийся тэг).
Паттерн: /^<([a-z]+)([^>]+)*(?:>(.*)<\/\1>|\s+\/>)$/
6. Email
Общий вид — логин@поддомен.домен. Логин, как и поддомен — слова из букв, цифр, подчёркиваний, дефисов и точек. А домен (имеется в виду 1го уровня) — это от 2 до 6 букв и точек.
Паттерн: /^([a-z0-9_\.-]+)@([a-z0-9_\.-]+)\.([a-z\.]{2,6})$/
От себя: можно короче — /^([\w\._]+)@\1\.([a-z]{2,6}\.?)$/. Это ещё и чуть правильнее — точка в домене первого уровня может встретиться только один раз и только в конце.
7. URL
Первым делом — необязательный протокол (http:// или https://), затем последовательность букв, цифр, дефисов, подчёркиваний и точек (домены уровня > 1), потом домен нулевого уровня (от 2 до 6 букв и точек) и, наконец, файловая структура — набор слов из букв, цифр, дефисов, подчёркиваний и точек со слэшем в конце. Всё это может завершаться опять-таки слэшем.
Паттерн: /^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
От себя: лучше так — /^(https?:\/\/)?([\w\.]+)\.([a-z]{2,6}\.?)(\/[\w\.]*)*\/?$/
8. IP адрес
4 группы цифр (от 1 до 3 цифр в каждой) разделены точками. Если группа состоит из 3 символов, то первый из них — 1 или 2; если 1, то остальные от 0 до 9, а если 2 — то второй от 0 до 5; если второй символ от 0 до 4, то третий — от 0 до 9, а если второй 5 — то третий от 0 до 5. Если же группа состоит из 2 символов, то первый — от 1 до 9, второй — от 0 до 9. В случае односимвольной группы этим символом может быть цифра от 1 до 9.
Паттерн: /^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
От себя: по-моему, так правильнее — /^(?:(?:25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(?:25[0-5]|2[0-4]\d|[01]?\d\d?)$/.
Взято отсюда
