Продолжаем разбирать текстовые форматы на предмет получения текста. Итак, обещанный ранее PDF.
С portable document format'ом не всё так просто, как DOCX или ODT, что мы рассматривали в прошлый раз, но всё же это всё ещё изначально текстовый, а не бинарный формат. Вы удивлены? Тогда давайте посмотрим на то, что там внутри. Дальше действительно много текста.

Как вы могли заметить, перед нами вполне себе «текстовый» документ, с вкраплениями бинарных данных. Конечно, как книгу pdf в блокноте не почитаешь, но понимать, что написано и что в последствии будет отображено на экране, вполне возможно. Заранее отмечу, что целью этой статьи не является описание формата данных, поэтому буду рассказывать по существу: «Где искать текст?» Более подробную информацию по формату PDF вы найдёте по ссылкам в конце этого небольшого руководства.
PDF поддерживает несколько базовых типов данных (если быть точно восемь), часть из которых нам понадобится для работы — это строки (strings), массивы (arrays), словари (distionaries), потоки (streams) и объекты (objects). Остановимся на каждом.
Строки
Строки PDF унаследовал от PostScript, как следствие, под строкой в .pdf подразумевается последовательность 8-битных символов, окружённая круглыми скобками. String может перенесена на следующую строку с помощью обратного слэша, который не является частью строки и, помимо всего прочего, экранирует спецсимволы:
Как результат, на выходе мы получим две строки:
Из-за своей изначальной восьмибитовости в PDF есть несколько способов для вставки текстовых данных, например, в той же кодировке Unicode. Мы можем использовать вставку по восьмеричным кодам символа (
В строках мы в будущем научимся искать текстовые данные, которые содержит в себе PDF-документ.
Массивы
Массивы в PDF заключаются в квадратные скобки и представляют собой просто последовательность группированных объектов. Например:
Словари
Это обрамлённые в << и >> пары ключ-значение. Словарь часто используется для наделения объекта, который его содержит, свойствами, что описаны в dictionary. Нам же эти данные помогут определить, как, например, расшифровать поток, узнать его длину или, наоборот, отбросить текущий объект, как неинтересный (если это изображение). Перед вами пример обычного PDF-словаря:
После чтения, мой код представит его в виде:
Потоки представляют последовательность восьмибитных данных между ключевыми словами
В stream'ах мы будем искать текст, который хотим получить из PDF-документа. Пример потока вы можете найти во второй половине изображения, что вначале данного топика: да-да, те крякозябрики — это оно и есть.
Объекты
Объекты — это наибольшая структура, с которой на предстоит работать. Объект может содержать внутри себя любой другой тип данных от обычного числа до потока, обрамляется ключевыми словами
Что ж на этом вводная часть по внутреннему представлению данных закончилась, переходим к «лакомым» штукам — получение текста из потока, а также получения словарей внутренних преобразований символов (реализацию которого я не встречал доселе).
Сформулируем задачу: «Где искать в PDF-документе текстовые объекты?» Тут всё просто и не раз и не два описано на различных форумах: будем искать объекты, в которых есть потоки. Обычно имеется ввиду, сжатые gzip, потоки, но документация говорит нам — потом может не сжат вообще или, наоборот, сжатий может быть несколько (
Найдём в данном документе какой-нибудь объект и начнём его разбирать. Я немного смухлюю и возьму объект, в котором заведомо есть текстовые данные, но это только для примера — скрипту всё равно с чем работать:
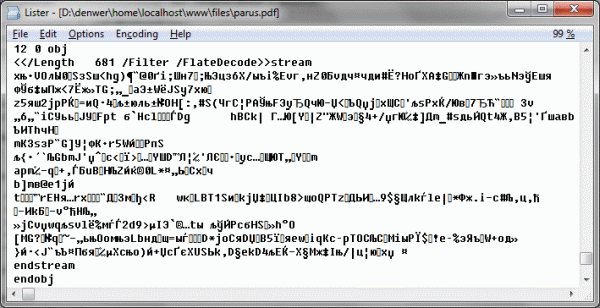
Давайте для начала разберёмся, что перед нами, используя полученные ранее знания о типах данных PDF. Перед нами объект со словарём свойств, которые говорят, что длина потока данных 681 байт (
Теперь чуть-чуть отвлечёмся от нашего примера и узнаем ещё немного нового о представлении текста в PDF. Нам нужно запомнить всего несколько вещей:
Внимательный читатель, посмотревший PDF примера, может предположить, что перед нами заголовок (ПАРУС) и первая строка стихотворения (Белеет парус одинокой). И он окажется прав, но! Но вы не находите, что уж очень странные hex-коды у данного текста:
На предыдущем примере бы спасовало бы большинство функций получения текста из PDF, которые вы можете найти в свободном доступе в интернетах. Попробуем разобраться что к чему. Итак, нас интересуют ToUnicode CMaps, о которых рассказывается в подразделе о получении текста описания формата PDF от Adobe. Давайте поищем их в нашем файле. Я опять смухлюю и предложу читателю «заведомо правильный кусочек»:
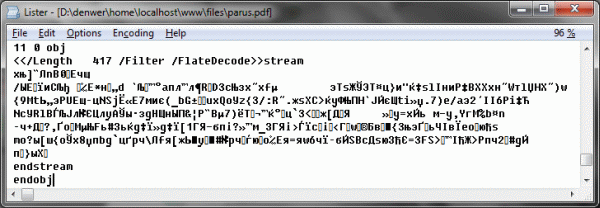
Расшифруем его:
Знакомые числа
bfchar
Преобразование, что находится между
bfrange
Есть и другое более сложное преобразование, обрамлённое
Используя полученные нами знания мы можем прочитать наш «злополучный» стих о Парусе. Что ж время представить самые интересные куски кода и ссылку на полный исходник:
Что ж этот код не является венцом творения, он не распарсит все предложенные ему pdf-файлы. Есть документы, в которые, к примеру, внедрены русские шрифты, осуществляющие трансформацию из символов английского алфавита в отображение русских букв.
Этот код не работает с индивидуальным позиционированием символов. Задача посильная и не сложная, я возлагаю её решение на плечи читателя.
Этот код не идеален в плане чтения PDF-файла по его внутренним стандартам представления информации: он не ищет страницы, он не будет работать с версиями документа (PDF поддерживает историю изменений), возможно даже, что он не идеально прочитает информацию, которую сможет обработать.
Стоит заметить, что никто не отменял
Надеюсь вас заинтересовала эта статья, цель которой познакомить сообщество с устройством PDF, возможностью его чтения под PHP, а также найти отправные точки для получения данных в сложных случаях.
В зависимости от активности и интереса к проблеме, я либо продолжу рассказ о PDF (внутреннее устройство документа, позиционирование, шрифты, внутренние ссылки), либо вернусь к теме «Текст любой ценой» на примере RTF. Спасибо за внимание!
Ссылки:
С portable document format'ом не всё так просто, как DOCX или ODT, что мы рассматривали в прошлый раз, но всё же это всё ещё изначально текстовый, а не бинарный формат. Вы удивлены? Тогда давайте посмотрим на то, что там внутри. Дальше действительно много текста.
Как вы могли заметить, перед нами вполне себе «текстовый» документ, с вкраплениями бинарных данных. Конечно, как книгу pdf в блокноте не почитаешь, но понимать, что написано и что в последствии будет отображено на экране, вполне возможно. Заранее отмечу, что целью этой статьи не является описание формата данных, поэтому буду рассказывать по существу: «Где искать текст?» Более подробную информацию по формату PDF вы найдёте по ссылкам в конце этого небольшого руководства.
Типы данных PDF
PDF поддерживает несколько базовых типов данных (если быть точно восемь), часть из которых нам понадобится для работы — это строки (strings), массивы (arrays), словари (distionaries), потоки (streams) и объекты (objects). Остановимся на каждом.
Строки
Строки PDF унаследовал от PostScript, как следствие, под строкой в .pdf подразумевается последовательность 8-битных символов, окружённая круглыми скобками. String может перенесена на следующую строку с помощью обратного слэша, который не является частью строки и, помимо всего прочего, экранирует спецсимволы:
(First line \ First line \n Second line with brackets \(\))
Как результат, на выходе мы получим две строки:
First line First line Second line with brackets ()
Из-за своей изначальной восьмибитовости в PDF есть несколько способов для вставки текстовых данных, например, в той же кодировке Unicode. Мы можем использовать вставку по восьмеричным кодам символа (
\053), с помощью отдельного двухбайтового hex'а (<2B>) или даже их последовательности (<54776F20>). Например, следующие строки эквивалентны:(Two + two = four.) (Two \053 two \075 four.) (Two <2B> two <3D> four.) (<54776F202B2074776F203D20> four.)
В строках мы в будущем научимся искать текстовые данные, которые содержит в себе PDF-документ.
Массивы
Массивы в PDF заключаются в квадратные скобки и представляют собой просто последовательность группированных объектов. Например:
[(Hello,)10(world!)]. Массивы подчас содержат текстовые строки.Словари
Это обрамлённые в << и >> пары ключ-значение. Словарь часто используется для наделения объекта, который его содержит, свойствами, что описаны в dictionary. Нам же эти данные помогут определить, как, например, расшифровать поток, узнать его длину или, наоборот, отбросить текущий объект, как неинтересный (если это изображение). Перед вами пример обычного PDF-словаря:
<< /Length 681 /Filter /FlateDecode >>
После чтения, мой код представит его в виде:
$dictionary = array(Потоки
"Length" => "681",
"Filter" => true,
"FlateDecode" => true,
);
Потоки представляют последовательность восьмибитных данных между ключевыми словами
stream и endstream. Любые бинарные данные, будь-то сжатый текст, изображение или внедрённый шрифт, будут представлены в виде потока. Поток всегда находится внутри объекта (чуть ниже) и характеризуется, как минимум, своей длиной (опция /Length N в словаре) и очень часто методом сжатия (например, /Filter /FlateDecode). PDF поддерживает достаточное количество форматов сжатия (в том числе и формат шифрования /CryptDecode), нас же будут интересовать лишь три: наиболее часто используемый Flate (gzip-сжатие) и более редкие ASCII Hex (представление данных в виде шестнадцатеричной строки с конечным символом >) и ASCII 85-based (сжатие, когда подряд идущие 4 символа исходного текста кодируются 5 символами от ! до y в ASCII таблице).В stream'ах мы будем искать текст, который хотим получить из PDF-документа. Пример потока вы можете найти во второй половине изображения, что вначале данного топика: да-да, те крякозябрики — это оно и есть.
Объекты
Объекты — это наибольшая структура, с которой на предстоит работать. Объект может содержать внутри себя любой другой тип данных от обычного числа до потока, обрамляется ключевыми словами
obj и endobj. Объект имеет свой ID внутри документа, по которому можно на него ссылаться. Нам в первую очередь интересны объекты с потоками внутри себя (не забываем об основной подзадаче), которые почти всегда содержат ещё и набор дополнительных опций в виде словаря. Вот обычный пример объекта внутри PDF-файла (с несжатым содержимым потока):2 0 obj << /Length 9 2 R >> stream BT /F1 12 Tf 72 712 Td (A short text stream.) Tj ET endstream endobj
Что ж на этом вводная часть по внутреннему представлению данных закончилась, переходим к «лакомым» штукам — получение текста из потока, а также получения словарей внутренних преобразований символов (реализацию которого я не встречал доселе).
Где искать текст?
Сформулируем задачу: «Где искать в PDF-документе текстовые объекты?» Тут всё просто и не раз и не два описано на различных форумах: будем искать объекты, в которых есть потоки. Обычно имеется ввиду, сжатые gzip, потоки, но документация говорит нам — потом может не сжат вообще или, наоборот, сжатий может быть несколько (
/Filter /FlateDecode /ASCIIHexDecode). Что ж нам нужен какой-нибудь действительный пример. Пожалуйста, стихотворение Михаила Юрьевича Лермонтова «Парус» в PDF-формате (документ создан на Acrobat.com из odt-файла из прошлой статьи).Найдём в данном документе какой-нибудь объект и начнём его разбирать. Я немного смухлюю и возьму объект, в котором заведомо есть текстовые данные, но это только для примера — скрипту всё равно с чем работать:
Давайте для начала разберёмся, что перед нами, используя полученные ранее знания о типах данных PDF. Перед нами объект со словарём свойств, которые говорят, что длина потока данных 681 байт (
/Length 681), что поток сжат (/Filter) в gzip (/FlateDecode). Уже достаточно информации, чтобы разжать поток данных — подойдёт gzuncompress:0.1 w q 0 -0.1 612.1 792.1 re W* n q 0 0 0 RG 0 0 0 rg BT 2 Tr 0.59999 w 56.8 716.6 Td /F1 18 Tf[<01>17<02>10<03>10<04>17<05>]TJ ET Q q 0 0 0 rg BT 56.8 682.5 Td /F1 11 Tf[<06>9<07>11<08>6<07>11<07>11<09>13<0A>4<0B>14<0C>11<0D>11<0E>9 <0F>9<0A>4<10>11<11>10<12>23<13>6<10>11<14>10<10>11<15>]TJ ET ... много текста ...
Теперь чуть-чуть отвлечёмся от нашего примера и узнаем ещё немного нового о представлении текста в PDF. Нам нужно запомнить всего несколько вещей:
- Если текст есть в потоке, то он содержится между «маркером» начала текста
BT(beginning of text) и концаET(end of text). - PDF может отображать текст или не отображать, в зависимости наличия маркета
Tj(отобразить текст) или маркераTJ(отобразить текст с учётом индивидуального символьного позиционирования). Данные маркеры стоят после строки текста или массива строк, как в данном случае ([<01>17<02>10<03>10<04>17<05>]TJ). - PDF поддерживает индивидуальное позиционирование символов, как я написал выше, это значит, что мы можем задать произвольный и отдельный размер расстояния между каждой парой символов. Об этом подробнее позже
1. <01>17<02>10<03>10<04>17<05> 2. <06>9<07>11<08>6<07>11<07>11<09>13<0A>4<0B>14<0C>11<0D>11<0E>9 <0F>9<0A>4<10>11<11>10<12>23<13>6<10>11<14>10<10>11<15>
Внимательный читатель, посмотревший PDF примера, может предположить, что перед нами заголовок (ПАРУС) и первая строка стихотворения (Белеет парус одинокой). И он окажется прав, но! Но вы не находите, что уж очень странные hex-коды у данного текста:
ПАРУСкодируется, как01 02 03 04 05Белеет— как06 07 08 07 07 09...
Таблица преобразований
На предыдущем примере бы спасовало бы большинство функций получения текста из PDF, которые вы можете найти в свободном доступе в интернетах. Попробуем разобраться что к чему. Итак, нас интересуют ToUnicode CMaps, о которых рассказывается в подразделе о получении текста описания формата PDF от Adobe. Давайте поищем их в нашем файле. Я опять смухлюю и предложу читателю «заведомо правильный кусочек»:
Расшифруем его:
/CIDInit/ProcSet findresource begin 12 dict begin begincmap /CIDSystemInfo<< /Registry (Adobe) /Ordering (UCS) /Supplement 0 >> def /CMapName/Adobe-Identity-UCS def /CMapType 2 def 1 begincodespacerange <00> endcodespacerange 45 beginbfchar <01> <041F> <02> <0410> <03> <0420> <04> <0423> <05> <0421> <06> <0411> <07> <0435> <08> <043B> <09> <0442> ... много строчек преобразований ... endbfchar endcmap CMapName currentdict /CMap defineresource pop end end
Знакомые числа
<01>, <02> и так далее? Ещё бы — мы их видели чуть раньше в текстовых строках. Предположим, что мы должны заменить 01 на 041F, взглянем, что скрывает за собой это число. Ура! #x041F = П! Мы нашли трансформацию одного символа в другой, теперь обратимся к документации и узнаем чуть больше.bfchar
Преобразование, что находится между
beginbfchar и endbfchar, самое простое. Оно ставит в соответствие первому коду другой. Например, в примере выше мы узнали, что 01 скрывает за собой код символа П. Но это лишь частный случай работы данного преобразования — есть возможность ставить в соответствие одному коду целую строку до 512 символов длины (т.е. до 128 символов в Unicode).bfrange
Есть и другое более сложное преобразование, обрамлённое
beginbfrange и endbfrange. Оно работает уже не с отдельными символами, а уже с их диапазонами. Преобразование поддерживает два вариант своей работы:<0000> <005E> <0020>— мы работает с диапазоном от 0000 до 005E, каждое значение из которого преобразуется в значения из промежутка 0020 и 007E. Заметили принцип? 0000 преобразуется в 0020, 0001 в 0021, 0002 в 0022 и так далее;<005F> <0061> [<00660066> <00660069> <00660066006C>]— каждое значение из промежутка между 005F и 0061 (т.е. ещё 0060) заменяется на соответствующую последовательность из массива в квадратных скобках: 005F будет заменён на 0066 00 66 (т.е. наff), 0060 наfi, а 0061 наffl.
Алгоритм и код
Используя полученные нами знания мы можем прочитать наш «злополучный» стих о Парусе. Что ж время представить самые интересные куски кода и ссылку на полный исходник:
Код с комментариями вы можете получить на GitHub'е.
- function pdf2text($filename) {
- // Читаем данные из pdf-файла в строку, учитываем, что файл может содержать
- // бинарные потоки.
- $infile = @file_get_contents($filename, FILE_BINARY);
- if (empty($infile))
- return "";
- // Проход первый. Нам требуется получить все текстовые данные из файла.
- // В 1ом проходе мы получаем лишь "грязные" данные, с позиционированием,
- // с вставками hex и так далее.
- $transformations = array();
- $texts = array();
- // Для начала получим список всех объектов из pdf-файла.
- preg_match_all("#obj(.*)endobj#ismU", $infile, $objects);
- $objects = @$objects[1];
- // Начнём обходить, то что нашли - помимо текста, нам может попасться
- // много всего интересного и не всегда "вкусного", например, те же шрифты.
- for ($i = 0; $i < count($objects); $i++) {
- $currentObject = $objects[$i];
- // Проверяем, есть ли в текущем объекте поток данных, почти всегда он
- // сжат с помощью gzip.
- if (preg_match("#stream(.*)endstream#ismU", $currentObject, $stream)) {
- $stream = ltrim($stream[1]);
- // Читаем параметры данного объекта, нас интересует только текстовые
- // данные, поэтому делаем минимальные отсечения, чтобы ускорить
- // выполнения
- $options = getObjectOptions($currentObject);
- if (!(empty($options["Length1"]) && empty($options["Type"]) && empty($options["Subtype"])))
- continue;
- // Итак, перед нами "возможно" текст, расшифровываем его из бинарного
- // представления. После этого действия мы имеем дело только с plain text.
- $data = getDecodedStream($stream, $options);
- if (strlen($data)) {
- // Итак, нам нужно найти контейнер текста в текущем потоке.
- // В случае успеха найденный "грязный" текст отправится к остальным
- // найденным до этого
- if (preg_match_all("#BT(.*)ET#ismU", $data, $textContainers)) {
- $textContainers = @$textContainers[1];
- getDirtyTexts($texts, $textContainers);
- // В противном случае, пытаемся найти символьные трансформации,
- // которые будем использовать во втором шаге.
- } else
- getCharTransformations($transformations, $data);
- }
- }
- }
- // По окончанию первичного парсинга pdf-документа, начинаем разбор полученных
- // текстовых блоков с учётом символьных трансформаций. По окончанию, возвращаем
- // полученный результат.
- return getTextUsingTransformations($texts, $transformations);
- }
Заключение
Что ж этот код не является венцом творения, он не распарсит все предложенные ему pdf-файлы. Есть документы, в которые, к примеру, внедрены русские шрифты, осуществляющие трансформацию из символов английского алфавита в отображение русских букв.
Этот код не работает с индивидуальным позиционированием символов. Задача посильная и не сложная, я возлагаю её решение на плечи читателя.
Этот код не идеален в плане чтения PDF-файла по его внутренним стандартам представления информации: он не ищет страницы, он не будет работать с версиями документа (PDF поддерживает историю изменений), возможно даже, что он не идеально прочитает информацию, которую сможет обработать.
Стоит заметить, что никто не отменял
$content = shell_exec('/usr/local/bin/pdftotext '.$filename.' -');. Но в данном случае стояла задача чтения PDF под любой платформой и на любой площадке.Надеюсь вас заинтересовала эта статья, цель которой познакомить сообщество с устройством PDF, возможностью его чтения под PHP, а также найти отправные точки для получения данных в сложных случаях.
В зависимости от активности и интереса к проблеме, я либо продолжу рассказ о PDF (внутреннее устройство документа, позиционирование, шрифты, внутренние ссылки), либо вернусь к теме «Текст любой ценой» на примере RTF. Спасибо за внимание!
Ссылки:
