Есть задача — восстановить пароль по его MD5 хэшу. Пароль простой, состоит из 7 цифр и начинается с 8-ки. Оговорюсь сразу — пароль мой, я его банально забыл, и это не инструкция о том, как брутфорсить чужие пароли.
Программа должна работать в несколько потоков для максимально быстрого достижения результата. Хотя бы потому, что запускать я ее буду на компьютере с двухъядерным процессором. Один поток не сможет максимально использовать оба ядра.
Рассмотрим два способа: создание нескольких рабочих потоков и использование OpenMP
Для простоты будем решать задачу в лоб, без синхронизации потоков при выводе результатов. Иначе придется позаботиться о deadlock-ах, вернее об их отсутствии.
Необходимо включить заголовочный файл
#include <omp.h>
И добавить опцию компилятора /openmp. В Visual Studio это делается через свойства проекта
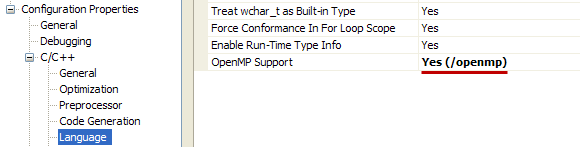
С использованием OpenMP код получился гораздо короче. При этом вычисление пароля вторым методом, на моем компьютере, выполнялось значительно быстрее. Не смотря на то, что оба метода «грузили» оба ядра почти полностью.
Если Вас заинтересовал OpenMP Вы можете начать изучение со статей, размещенные на сайте компании Intel
Начало работы с OpenMP
Эффективное распределение нагрузки между потоками с помощью OpenMP
Advanced OpenMP Programming
И не забудьте посетить сайт OpenMP. Там Вы сможете найти список компиляторов, поддерживающих OpenMP и спецификации OpenMP
Программа должна работать в несколько потоков для максимально быстрого достижения результата. Хотя бы потому, что запускать я ее буду на компьютере с двухъядерным процессором. Один поток не сможет максимально использовать оба ядра.
Рассмотрим два способа: создание нескольких рабочих потоков и использование OpenMP
Способ первый — создание нескольких потоков.
Для простоты будем решать задачу в лоб, без синхронизации потоков при выводе результатов. Иначе придется позаботиться о deadlock-ах, вернее об их отсутствии.
// Объявляем переменные
const int g_nNumberOfThreads = 4;
const int g_nFrom = 8000000;
const int g_nTo = 8999999;
const string g_strCompareWith = "4ac7b1796b90478f2991bb9a7b05d2bf";
time_t g_timeElapsed;
// Объявляем структуру, через которую будем передавать в поток исходные данные
struct THREAD_PARAMS
{
int nFrom;
int nTo;
};
// Прототип функции вычисляющей хэш MD5
BOOL GetMD5Hash(string strIn, string &strHash)
// Тело потока
DWORD WINAPI _WorkerThread(LPVOID pParams)
{
// Сохраняем входные данные
THREAD_PARAMS *pThreadParams = (THREAD_PARAMS*)pParams;
int nFrom = pThreadParams->nFrom;
int nTo = pThreadParams->nTo;
delete pParams;
string strHash;
for(int i = nFrom; i < nTo; ++i)
{
stringstream stream;
stream << i;
// Вычисляем очередной хэш
GetMD5Hash(stream.str(), strHash);
// Сравниваем с эталоном
if(strHash == g_strCompareWith)
{
// Пароль найден
cout << "Password is: " << stream.str() << endl;
cout << "Elapsed time: " << time(NULL) - g_timeElapsed << " sec." << endl;
exit(0);
}
// Отчитываемся о своей работе каждые 10000 итераций
if((i % 10000) == 0)
{
cout << "Current password: " << i << " Elapsed time: " << time(NULL) - g_timeElapsed << " sec." << endl;
}
}
return 0;
}
// Запуск потоков
void MultiThreadWay()
{
int nDataLength = (int)(g_nTo - g_nFrom) / g_nNumberOfThreads;
HANDLE *hThreads = new HANDLE[g_nNumberOfThreads];
for(int i = 0; i < g_nNumberOfThreads; ++i)
{
THREAD_PARAMS *pParams = new THREAD_PARAMS();
pParams->nFrom = g_nFrom + (i * nDataLength);
pParams->nTo = pParams->nFrom + nDataLength;
hThreads[i] = CreateThread(NULL, 0, _WorkerThread, pParams, 0, NULL);
Sleep(100);
}
WaitForMultipleObjects(g_nNumberOfThreads, hThreads, TRUE, INFINITE);
delete [] hThreads;
}
// Главная функция
int _tmain(int argc, _TCHAR* argv[])
{
g_timeElapsed = time(NULL);
MultiThreadWay();
return 0;
}
* This source code was highlighted with Source Code Highlighter.
Способ второй — использование OpenMP
Необходимо включить заголовочный файл
#include <omp.h>
И добавить опцию компилятора /openmp. В Visual Studio это делается через свойства проекта
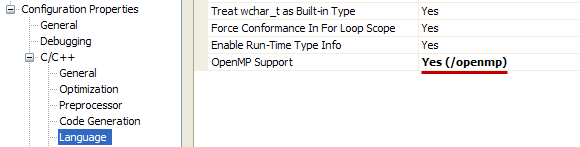
// Объявляем переменные
const int g_nNumberOfThreads = 4;
const int g_nFrom = 8000000;
const int g_nTo = 8999999;
const string g_strCompareWith = "4ac7b1796b90478f2991bb9a7b05d2bf";
time_t g_timeElapsed;
// Прототип функции вычисляющей хэш MD5
BOOL GetMD5Hash(string strIn, string &strHash)
int _tmain(int argc, _TCHAR* argv[])
{
g_timeElapsed = time(NULL);
// Устанавливаем желаемое количество потоков
omp_set_num_threads(g_nNumberOfThreads);
// Одна прагма, добавленная перед циклом сделает за нас всю работу.
// Цикл будет выполняться в g_nNumberOfThreads потоков.
// Параметры цикла будут автоматически распределены между потоками.
#pragma omp parallel for
for(int i = g_nFrom; i < g_nTo; ++i)
{
// Эти переменные должны быть индивидуальными
// для каждого потока
string strHash;
stringstream stream;
stream << i;
// Вычисляем очередной хэш
GetMD5Hash(stream.str(), strHash);
// Сравниваем с эталоном
if(strHash == g_strCompareWith)
{
cout << "Password is: " << stream.str() << endl;
cout << "Elapsed time: " << time(NULL) - g_timeElapsed << " sec." << endl;
exit(0);
}
// Отчитываемся о своей работе каждые 10000 итераций
if((i % 10000) == 0)
{
// В этот раз используем критическую секцию.
// Почему бы нет, нам не нужно за нее "платить"
#pragma omp critical
{
cout << "Current password: " << i << " Elapsed time: " << time(NULL) - g_timeElapsed << " sec." << endl;
}
}
}
return 0;
}
* This source code was highlighted with Source Code Highlighter.
С использованием OpenMP код получился гораздо короче. При этом вычисление пароля вторым методом, на моем компьютере, выполнялось значительно быстрее. Не смотря на то, что оба метода «грузили» оба ядра почти полностью.
Если Вас заинтересовал OpenMP Вы можете начать изучение со статей, размещенные на сайте компании Intel
Начало работы с OpenMP
Эффективное распределение нагрузки между потоками с помощью OpenMP
Advanced OpenMP Programming
И не забудьте посетить сайт OpenMP. Там Вы сможете найти список компиляторов, поддерживающих OpenMP и спецификации OpenMP
