(Это продолжение обзора обфускаторов. Начало тут)
Объединение сборок и пространств имён (Assembly Merge, Namespace Flatten)
Данная методика сама по себе не задерживает злоумышленника ни на минуту, но очень полезна для дальнейшего его запутывания. Т.к. чем больше классов будет содержать результирующая сборка, тем сложнее без детального анализа будет в ней найти то, что надо.
Опять же, при попытке украсть ваш код, злоумышленник получит вместо нескольких проектов-библиотек и одной программы только один проект, в котором все классы будут лежать в одной папке (и в одном неймспейсе).
Для объединения сборок можно использовать утилиту ilmerge, либо встроенную в обфускатор функциональность. Пространства имён обычно объединяются во время обфускации имён классов (чтобы не было коллизий с одинаково названными классами из разных неймспейсов).
Переименование классов, методов и т.д.
Данный подход реализован почти во всех уважающих обфускаторах. Удаляются все «подсказки» которые может использовать злоумышленник для быстрого поиска классов, отвечающих за лицензирование, либо при «воровстве» кода будет очень тяжело разобраться в логике приложения, для чего и как создаются классы, и вызываются методы.

Самый популярный вариант на данный момент — переименование в непечатные символы (или какую-нибудь «китайщину» типа 儽.凍::儽). Это немного осложняет просмотр сборки в рефлекторе, но на деобфускаторе никак не сказывается.
К тому же из недостатков мы получаем труднопередаваемые сообщения об исключениях, которые могли бы произойти у конечного пользователя, и если он нам вышлет текст не в юникод-кодировке, то разобрать его будет практически невозможно.
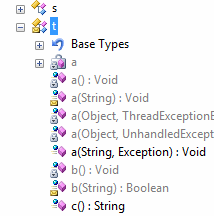 Аналогичный вариант — использование коротких, но печатных идентификаторов (a, b, c,....aa, ab, ac...). Для деобфускатора этот вариант полностью аналогичен предыдущему, но зато лишён указанного недостатка.
Аналогичный вариант — использование коротких, но печатных идентификаторов (a, b, c,....aa, ab, ac...). Для деобфускатора этот вариант полностью аналогичен предыдущему, но зато лишён указанного недостатка.
 Третий вариант именования — использование ключевых слов языка высокого уровня (C# или VB.net), либо невалидных идентификаторов для этого языка (например ?123?) — ничем не лучше двух предыдущих, но почему-то считается, что при «воровстве» кода не воспользуются деобфускатором, и на выходе получится некомпилируемый текст...
Третий вариант именования — использование ключевых слов языка высокого уровня (C# или VB.net), либо невалидных идентификаторов для этого языка (например ?123?) — ничем не лучше двух предыдущих, но почему-то считается, что при «воровстве» кода не воспользуются деобфускатором, и на выходе получится некомпилируемый текст...
Ещё существует куча «глупых» вариантов, которые конечно скрывают смысл исходных имён, но зачем делать их такими длинными?
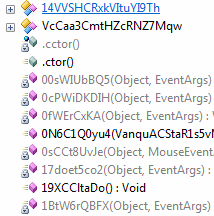
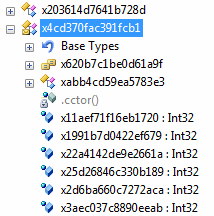
Интересным и ещё более запутывающим подходом является создание большого количества overload-методов с одним именем, которые имели до обфускации разные имена, и никак не были связаны.
Также .net позволяет содавать override-методы, имена которых отличаются от имён методов, которые они перекрыли. Это сбивает с толку не только злоумышленников, но и добавляет лишние требования к деобфускатору.

Изменение содержимого классов
Некоторые обфускаторы могут объединять несколько классов в один, или делать из обычного класса вложенный. Но такая обфускация часто приводит к ошибкам в результирующей программе, и используется очень редко.
Обфускация control flow
На этом этапе меняется порядок инструкций в коде и даже меняются сами инструкции. Пожалуй, самый интересный и самый спорный этап.
Данная методика позволяет ввести в заблуждение (а иногда и в полный ступор) большинство декомпиляторов языков высокого уровня. Что очень хорошо противодействует «воровству» кода. Также «запутывает» кракеров и авторов кейгенов.
Обратная сторона медали — иногда сниженная производительность. Логично что чем больше мы запутываем ход выполнения программы, тем дольше она выполняется. Особенно это относится к использованию исключений.
В большинстве случаев код метода бьётся на блоки, эти блоки перемешиваются в случайном порядке и «склеиваются» с помощью безусловных переходов (инструкции br и br.s). В качестве примера:
Бывают и случаи, когда метод очень короткий, и «перемешать» его хорошо не получается, в этом случае некоторые обфускаторы выдают переход на следующую инструкцию:
Между инструкцией перехода, и её целью очень часто вставляется всякое «фуфло», типа выпадения в дебаггер, или просто невалидных инструкций:
Некоторые обфускаторы заменяют инструкции перехода (как оригинальные, так и вставленные) на загрузку константы и переход на switch:
очевидно, что в данном примере инструкция со смещением L_0045 «в девичестве» была br L_0047, а если учесть предыдущие методики, то это вообще nop ;)
Иногда можно встретить «переход на переход»:

в одной из программ я видел цепочку из 6 (шести) таких переходов ;)
Интересный подход — использование условных переходов для выражений, которые всегда верны (или неверны).
Самый простой пример:
То же самое, но слегка более запутанное:
Ещё вариант:
Простое перемешивание некоторых инструкций, например:
Один из самых «жёстких» методов — всегда выбрасываемое внутри блока try—catch исключение. Данный подход используется очень редко, т.к. резко снижает производительность и может нарушить логику приложения при неверном использовании. Скриншот я не привожу т. к. он занимает много места.
Кажется, что самые популярные методики я перечислил, если вы знаете что-то ещё, сообщите пожалуйста в комментах.
Invalid IL
Тут всё очень просто. В участки кода, которые никогда не будут исполнены, вставляются не описанные в стандарте опкоды (т.е. невалидные инструкции).
В рефлекторе вы увидите примерно такое:

или, если переключится на IL:
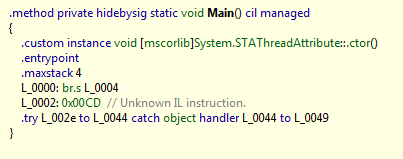
Данная методика обескураживает начинающих «хаксоров». Но не является чем-то сложным для обхода (данные опкоды просто заменяются на nop).
Сокрытие строк
Деобфускаторами это называется «шифрование строк», но назвать это шифрованием у меня не поворачивается язык.
Обычно это делается каким-нибудь «детским» алгоритмом шифрования типа XOR на константу:
Иногда строки объединяются в одну, и потом происходит вызов метода Substring; иногда строки прячут в ресурсы.
В любом случае «шифрование» представлено в виде статического метода с несколькими аргументами, обычно это строка и/или число. Никаких криптографических алгоритмов не применяется, что вполне логично: если применить здесь настоящее шифрование, то программа будет безбожно тормозить.
Данный метод спасает от начинающих кракеров, которые будут искать по коду строки типа “Invalid serial number” или другие тексты сообщений.
Специфичные атрибуты и баги декомпиляторов
Самый часто встречаемый атрибут — [SuppressIldasm], который «вежливо просит» не работать на данной сборке официальный декомпилятор Microsoft — ildasm. Существуют также специфичные атрибуты для рефлектора и для коммерческих декомпиляторов.
В качестве багов можно встретить как чисто технические недоработки декомпиляторов (например, рефлектор выпадает на инструкции ldfld string 儽.凍::儽, а большинство деобфускаторов на базе Mono.Cecil — на неправильных RVA), также и алгоритмичиские допущения: многие декомпиляторы высокого уровня отслеживают состояние стэка, но идут по методу не как по графу, а линейно, и радостно валятся на методах в которых после последней инструкции ret вставлен бесконечный цикл. Против плагина Reflexil хорошо «помогает» инструкция, переходящая сама на себя.
Другие методы
Иногда можно встретить очень похожий на скрытие строк подход, но для ресурсов.
Также один из обфускаторов предлагает «V-Spot Elimination» (чем очень гордится) — создание прокси-классов для классов BCL, что замедляет анализ и слегка портит полученный декомпиляцией код.
Также используется конвертирование manged в unmanaged .net-кода. Т.е. все пересобирается с пометками unmanaged. Практически вся функциональность в пределах домена сохраняется, но рефлектором код уже не посмотреть.
Спасибо пользователю Exaktus за комментарии и дополнения
Далее будет часть 1.2. Обзор обфускаторов
продолжение следует...
* All source code was highlighted with MSVS and wordpad ;)
1. Обфускаторы.
1.1. Методики
Объединение сборок и пространств имён (Assembly Merge, Namespace Flatten)
Данная методика сама по себе не задерживает злоумышленника ни на минуту, но очень полезна для дальнейшего его запутывания. Т.к. чем больше классов будет содержать результирующая сборка, тем сложнее без детального анализа будет в ней найти то, что надо.
Опять же, при попытке украсть ваш код, злоумышленник получит вместо нескольких проектов-библиотек и одной программы только один проект, в котором все классы будут лежать в одной папке (и в одном неймспейсе).
Для объединения сборок можно использовать утилиту ilmerge, либо встроенную в обфускатор функциональность. Пространства имён обычно объединяются во время обфускации имён классов (чтобы не было коллизий с одинаково названными классами из разных неймспейсов).
Переименование классов, методов и т.д.
Данный подход реализован почти во всех уважающих обфускаторах. Удаляются все «подсказки» которые может использовать злоумышленник для быстрого поиска классов, отвечающих за лицензирование, либо при «воровстве» кода будет очень тяжело разобраться в логике приложения, для чего и как создаются классы, и вызываются методы.

Самый популярный вариант на данный момент — переименование в непечатные символы (или какую-нибудь «китайщину» типа 儽.凍::儽). Это немного осложняет просмотр сборки в рефлекторе, но на деобфускаторе никак не сказывается.
К тому же из недостатков мы получаем труднопередаваемые сообщения об исключениях, которые могли бы произойти у конечного пользователя, и если он нам вышлет текст не в юникод-кодировке, то разобрать его будет практически невозможно.
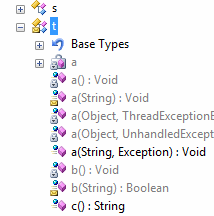 Аналогичный вариант — использование коротких, но печатных идентификаторов (a, b, c,....aa, ab, ac...). Для деобфускатора этот вариант полностью аналогичен предыдущему, но зато лишён указанного недостатка.
Аналогичный вариант — использование коротких, но печатных идентификаторов (a, b, c,....aa, ab, ac...). Для деобфускатора этот вариант полностью аналогичен предыдущему, но зато лишён указанного недостатка.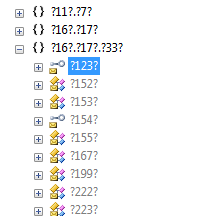 Третий вариант именования — использование ключевых слов языка высокого уровня (C# или VB.net), либо невалидных идентификаторов для этого языка (например ?123?) — ничем не лучше двух предыдущих, но почему-то считается, что при «воровстве» кода не воспользуются деобфускатором, и на выходе получится некомпилируемый текст...
Третий вариант именования — использование ключевых слов языка высокого уровня (C# или VB.net), либо невалидных идентификаторов для этого языка (например ?123?) — ничем не лучше двух предыдущих, но почему-то считается, что при «воровстве» кода не воспользуются деобфускатором, и на выходе получится некомпилируемый текст...Ещё существует куча «глупых» вариантов, которые конечно скрывают смысл исходных имён, но зачем делать их такими длинными?

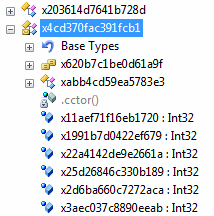
Интересным и ещё более запутывающим подходом является создание большого количества overload-методов с одним именем, которые имели до обфускации разные имена, и никак не были связаны.
Также .net позволяет содавать override-методы, имена которых отличаются от имён методов, которые они перекрыли. Это сбивает с толку не только злоумышленников, но и добавляет лишние требования к деобфускатору.

Изменение содержимого классов
Некоторые обфускаторы могут объединять несколько классов в один, или делать из обычного класса вложенный. Но такая обфускация часто приводит к ошибкам в результирующей программе, и используется очень редко.
Обфускация control flow
На этом этапе меняется порядок инструкций в коде и даже меняются сами инструкции. Пожалуй, самый интересный и самый спорный этап.
Данная методика позволяет ввести в заблуждение (а иногда и в полный ступор) большинство декомпиляторов языков высокого уровня. Что очень хорошо противодействует «воровству» кода. Также «запутывает» кракеров и авторов кейгенов.
Обратная сторона медали — иногда сниженная производительность. Логично что чем больше мы запутываем ход выполнения программы, тем дольше она выполняется. Особенно это относится к использованию исключений.
В большинстве случаев код метода бьётся на блоки, эти блоки перемешиваются в случайном порядке и «склеиваются» с помощью безусловных переходов (инструкции br и br.s). В качестве примера:
L_0034: br.s L_003a
L_0036: nop
L_0037: br.s L_0041
L_0039: nop
L_003a: callvirt instance void [Aaa]Xxx.Yyy::Zzz()
L_003f: br.s L_0036
L_0041: nop Бывают и случаи, когда метод очень короткий, и «перемешать» его хорошо не получается, в этом случае некоторые обфускаторы выдают переход на следующую инструкцию:
L_0008: br.s L_000a
L_000a: ldarg.0 Между инструкцией перехода, и её целью очень часто вставляется всякое «фуфло», типа выпадения в дебаггер, или просто невалидных инструкций:
L_0000: br.s L_0003
L_0002: break
L_0003: ldarg.0Некоторые обфускаторы заменяют инструкции перехода (как оригинальные, так и вставленные) на загрузку константы и переход на switch:
L_0000: br.s L_0023
L_0002: ldloc num3
L_0006: switch (L_005b, L_0068, L_00ce, L_00af, L_0047, L_007b)
...
...
...
L_003c: ldc.i4 4
L_0041: stloc num3
L_0045: br.s L_0002очевидно, что в данном примере инструкция со смещением L_0045 «в девичестве» была br L_0047, а если учесть предыдущие методики, то это вообще nop ;)
Иногда можно встретить «переход на переход»:

в одной из программ я видел цепочку из 6 (шести) таких переходов ;)
Интересный подход — использование условных переходов для выражений, которые всегда верны (или неверны).
Самый простой пример:
L_0014: ldc.i4.1
L_0015: brtrue.s L_002eТо же самое, но слегка более запутанное:
L_0014: ldc.i4.1
L_0015: stloc.0
L_0016: br.s L_001c
L_0018: nop
L_0019: ldarg.1
L_001a: br.s L_002e
L_001c: ldloc.0
L_001d: brtrue.s L_0018Ещё вариант:
if (5 < (5 - 6)) {
// IL-мусор, или неверный код
} L_0000: ldc.i4.5
L_0001: dup
L_0002: dup
L_0003: ldc.i4.6
L_0004: sub
L_0005: blt L_0001Простое перемешивание некоторых инструкций, например:
L_0000: ldc.i4 4
L_0005: stloc num
L_0009: ldstr "\u5f03"
L_000e: ldloc numОдин из самых «жёстких» методов — всегда выбрасываемое внутри блока try—catch исключение. Данный подход используется очень редко, т.к. резко снижает производительность и может нарушить логику приложения при неверном использовании. Скриншот я не привожу т. к. он занимает много места.
Кажется, что самые популярные методики я перечислил, если вы знаете что-то ещё, сообщите пожалуйста в комментах.
Invalid IL
Тут всё очень просто. В участки кода, которые никогда не будут исполнены, вставляются не описанные в стандарте опкоды (т.е. невалидные инструкции).
В рефлекторе вы увидите примерно такое:

или, если переключится на IL:

Данная методика обескураживает начинающих «хаксоров». Но не является чем-то сложным для обхода (данные опкоды просто заменяются на nop).
Сокрытие строк
Деобфускаторами это называется «шифрование строк», но назвать это шифрованием у меня не поворачивается язык.
Обычно это делается каким-нибудь «детским» алгоритмом шифрования типа XOR на константу:
public static string Decode(string str, int num)
{
int length = str.Length;
char[] chArray = str.ToCharArray();
while (--length >= 0)
chArray[length] = (char)(chArray[length] ^ num);
return new string(chArray);
}
Иногда строки объединяются в одну, и потом происходит вызов метода Substring; иногда строки прячут в ресурсы.
В любом случае «шифрование» представлено в виде статического метода с несколькими аргументами, обычно это строка и/или число. Никаких криптографических алгоритмов не применяется, что вполне логично: если применить здесь настоящее шифрование, то программа будет безбожно тормозить.
Данный метод спасает от начинающих кракеров, которые будут искать по коду строки типа “Invalid serial number” или другие тексты сообщений.
Специфичные атрибуты и баги декомпиляторов
Самый часто встречаемый атрибут — [SuppressIldasm], который «вежливо просит» не работать на данной сборке официальный декомпилятор Microsoft — ildasm. Существуют также специфичные атрибуты для рефлектора и для коммерческих декомпиляторов.
В качестве багов можно встретить как чисто технические недоработки декомпиляторов (например, рефлектор выпадает на инструкции ldfld string 儽.凍::儽, а большинство деобфускаторов на базе Mono.Cecil — на неправильных RVA), также и алгоритмичиские допущения: многие декомпиляторы высокого уровня отслеживают состояние стэка, но идут по методу не как по графу, а линейно, и радостно валятся на методах в которых после последней инструкции ret вставлен бесконечный цикл. Против плагина Reflexil хорошо «помогает» инструкция, переходящая сама на себя.
Другие методы
Иногда можно встретить очень похожий на скрытие строк подход, но для ресурсов.
Также один из обфускаторов предлагает «V-Spot Elimination» (чем очень гордится) — создание прокси-классов для классов BCL, что замедляет анализ и слегка портит полученный декомпиляцией код.
Также используется конвертирование manged в unmanaged .net-кода. Т.е. все пересобирается с пометками unmanaged. Практически вся функциональность в пределах домена сохраняется, но рефлектором код уже не посмотреть.
Спасибо пользователю Exaktus за комментарии и дополнения
Далее будет часть 1.2. Обзор обфускаторов
продолжение следует...
* All source code was highlighted with MSVS and wordpad ;)
