Вы читаете вторую часть обзора архитектуры корпоративного портала Jahia.
Часть 1:
Часть 2:

Файловое хранилище Jahia было полностью переписано в версии 6. В Jahia 5 хранилище было основано
на использовании библиотеки Apache Slide library, которая на то время была де-факто
стандартом файловых репозитариев с открытым исходным кодом.
Но всвязи с бурным развитием и хорошим качеством Apache Jackrabbit – реализации
спецификации Java Content Repository, Jahia 6 стала использовать ее в качестве стандартного
файлового хранилища и строить поверх данной библиотеки свои сервисы. На самом деле архитектура
Jackrabbit не предполагает тесной зависимости от ее использования, а использует стандартный JCR
API для возможности предоставления доступа к различным репозитариям.
В Jahia 6 стало возможным иметь доступ к файловым хранилищам CIFS/SMB. Некоторые другие
развивающиеся реализации доступны в песочницах репозитариев (sandbox repositories), среди них
коннекторы FTP, Alfresco, Exo Platform, Nuxeo.
На рисунке выше вы можете отметить, что содержимое Jahia (Jahia Content) доступно в качестве
JCR-провайдера, это тоже новая возможность Jahia 6. Пока что в данном направлении проведена
только первоначальная работа по совместимости и интерфейс к данной реализации не может
похвастаться высокой производительностью, но работы по его улучшению будут ведутся постоянно от
версии к версии.
Поверх службы файлового хранилища интерфейсы отдают контент с помощью различных технологий:
WebDAV, просмотр файлов в шаблонах и в пользовательском AJAX-интерфейсе Jahia. Вместе с хранилищем
могут функционировать дополнительные службы портала: Rules engine – для задания правил и
прав доступа к файлам, Thumbnail management – для генерирования миниатюр изображений
(thumbnail), Content extractors – для извлечения метаданных.
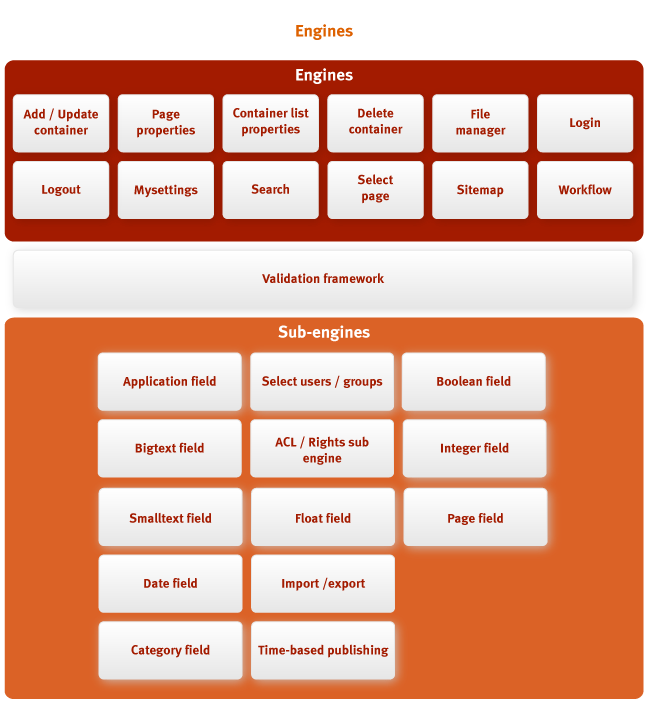
Инструменты и средства в Jahia принято называть движками (engines). Движки Jahia можно
сравнить с объектами Action в Struts. Это блоки логики приложения, каждый их которых
выполняет конкретную задачу. Субдвижки (sub-engines) – еще более мелкие блоки,
контролирующие взаимодействие с примитивами пользовательского интерфейса (например контролирующие
редактирование поля).
Наиболее важный движок – это движок ядра (Core engine), отвечающий за генерирование
страницы содержимого, он вызывается каждый раз, когда портал должен отобразить страницу. Названия
других движков говорят сами за себя: например движки Login и Logout отвечают за
отрисовку пользовательского интерфейса входа и выхода из системы и обработку данных, введенных
пользователем при этих действиях.
Движки редактирования (обработки) контента интегрированы с фреймворком валидации
(validation framework), что позволяет интеграторам задавать правила проверки введенных
пользователем данных.
Движки также интегрированы с пользовательским AJAX интерфейсом. Цель применения AJAX – сделать
пользовательский интерфейс современным, построенным на компонентах, которые можно многократно
повторно использовать. Интеграторы смогут применять уже существующие многочисленные библиотеки
компонентов при построении приложений. Работа в данном направлении начата в Jahia 6 применением
компонентов GWT.
Субдвижки в Jahia используются для отображения интерфейсов редактирования контейнеров.
Контейнер может содержать в себе поля разного типа. При редактировании поля какого-либо типа
движок редактирования контейнера (container edition engine) обращается к субдвижку, отвечающему за
этот тип поля. Например, поле типа File, представляющее файл, будет предоставлять UI-
интерфейс, позволющий пользователю просматривать директории и выбирать файлы, в то время как, поле
типа Small text просто будет отображать поле для ввода текста.
Jahia обрабатывает запросы к движкам, используя параметр «/engineName» в URL. Если параметр
без значения – запрос принимает движок ядра. Строковые значения, которые используются для
именования движков, объявляются самими движками, а в классе JahiaEngine, метод getName
() будет определять ключ для механизма разрешения параметра «/engineName».

Подсистема поиска и индексирования Jahia в данном документе будет представлена лишь обзорно – это
очень обширная подсистема. Выше на рисунке мы проиллюстрировали основные составляющие данной
подсистемы.
Новшеством Jahia 6 является интеграция стандарта OpenSearch. Jahia может играть роль как
потребителя, так и как генератора OpenSearch-запросов. Это значит, что пользователи
могут, например, интегрировать Jahia в панель поиска своего браузера и напрямую делать
поисковые запросы из панели браузера. С другой стороны, Jahia может пользоваться услугами
различных OpenSearch-провайдеров и предоставлять на одной странице сведенные результаты для поиска
по Jahia, Google, MSN и т.п.
Что касается более традиционных решений веб-поиска, Jahia предлагает библиотеки тэгов для
поиска по содержимому либо в простом формате полнотекстового поиска, либо используя расширенные
поисковые запросы. Для облегчения формировния расширенных поисковых запросов в UI-компоненты Jahia
встроены удобные селекторы параметров запросов. Эти компоненты сделаны с использованием
AJAX-фреймворка и являются подобными тем, которые применялись при введении данных в интерфейсе
входа в систему.
Другая альтернатива для запросов к объектам содержимого – напрямую встраивать запросы на уровне
шаблонов, а пользователи на экране будут видеть результат уже подготовленного запроса. Это
называется «Запросы контейнера» (Container queries) и использоваться они могут, например,
для загрузки последних пяти объектов содержимого с типа «Новость» при выводе на страницу последних
пяти новостей.
В основе всех этих технологий формирования пользовательских запросов лежат серверные системы,
непосредственно выполняющие поиск и индексирование контента. Поисковый механизм портала дает
возможность осуществлять полнотекстовый поиск, поиск с уточняющими запросами как по содержимому
Jahia, так и по файловому содержимому.
Основа подсистемы поиска и индексирования – opensource фреймворки Compass и Apache
Lucene. Они хранят свой индекс, используя средства файловой системы, но также имеют средства
для хранения информации в базах данных или в распределенных файловых системах.
Стандартная реализация подсистемы с использованием файловой системы на данный момент наиболее
еффективная и готовая к использованию (production-ready), так что Jahia поставляется в комплекте с
этой реализацией.
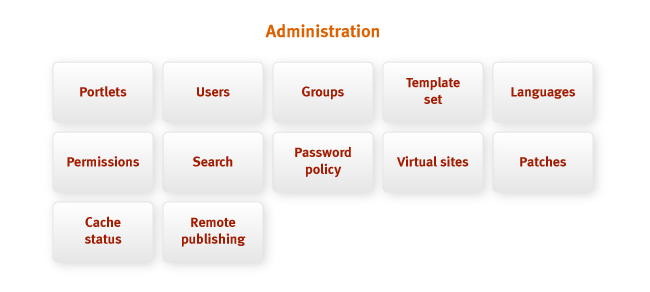
Интерфейс администрирования – это средство управления всеми различными подсистемами Jahia
из одного места и для администраторов сайта, и для администраторов сервера. Интерфейс
администрирования позволяет администратором выполнять все виды задач:
Интерфейс администрирования основан на сервлете-диспетчере и коллекции классов,
контролирующих UI для различных настроек сервера. Также для удобства администраторов интерфейс
поддерживает компоненты пользовательского интерфейса на AJAX.
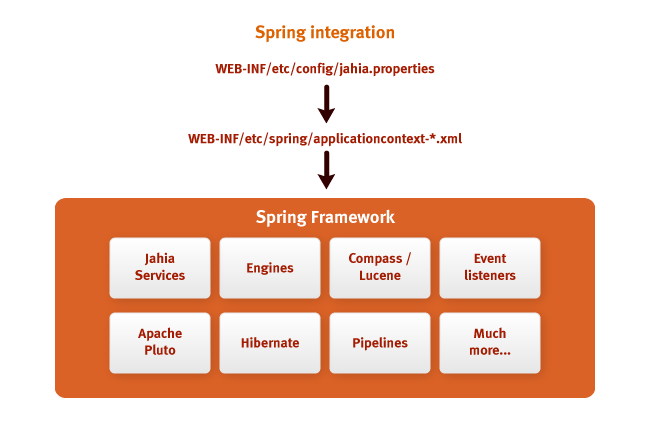
Разработчики Jahia любят Spring. Начиная с пятой версии системы Jahia была интегрирована со
Spring Framework для облегчения построения целостных, быстрых и гибких портальных решений.
Для подключения подсистем Jahia к многочисленным сервисам, интеграторам теперь просто следует
использовать хорошо известные механизмы настроек и внедрения зависимостей (dependency injection),
которые предоставляет Spring.
Рисунок выше поясняет настройки, используя которые с помощью Spring можно инициализировать все
различные подсистемы Jahia. Внешние библиотеки портала: Apache Pluto, Hibernate, Apache Lucene –
также работают со Spring, что делает возможным реализовывать стройную архитектуру портала.
Опыт интеграции Jahia со Spring был успешным и зависимостей системы от Spring практически не
появилось, что делает возможным в дальнейшем в случае необходимости свободно мигрировать на другой
фреймворк.

Действия, выполняемые пользователями портала, порождают события, которые могут
использоваться для выполнения определённых задач. Jahia позволяет интеграторам регистрировать свои
слушатели событий. На приведенном выше графике показано, как события, передаются по различным
подсистемам и как они могут быть использованы разработчиками.
Событие порождается при выполнении некоторого действия порталом. Это может быть команда
пользователя, действие по расписанию, фоновый процесс. Действие вызывает
генератор события (event generator) для создания объекта события. Данный объект далее будет
передан в реестр слушателей (listeners registry), который зарегистрированным слушателям
будет вызывать необходимые классы. Некоторые из слушателей событий являются шлюзами к
другим слушателям, использующим другие технологии. Есть возможность использовать слушатель событий
Groovy (Groovy event listener), позволяющий интегратором использовать язык Groovy в
реализациях слушателей; слушатель событий JSP (JSP event listener), делающий то же для
JSP-страниц.
Еще один специфический слушатель – менеджер наблюдения JCR (JCR observation manager),
который связует механизм событий Jahia со стандартной моделью наблюдения JCR (JCR observation).
Под данной реализацией находится наблюдатель JBoss Rules (JBoss Rules observer),
позволяющий интеграторам использовать правила (rules) для опработки событий.

Выше представлена схема обработки системой Jahia запроса от браузера. Схема может использоваться
разработчиками для определения подсистем портала, задействованных в процессе обработки конкретного
запроса.
Запрос браузера может быть направлен либо на Jahia servlet, либо на WebDAV servlet
(если запрашивается бинарный файл).
Во втором случае (WebDAV servlet) запрос будет перенаправлен в службу файлового хранилища,
пройдет валидацию на право доступа к запрашиваемому ресурсу и потом результат будет возвращен
обратно в браузер.
В первом случае будет вызван Jahia servlet. Jahia немедленно создаст объект контекста
(context object) под названием «ParamBean». Данный будет содержать в себе всю
информацию о запросе, включая такие вещи как запрошеная страница, текущий пользователь, язык
просмотра и так далее. Внутренне ParamBean использует механизм конвейерной обработки (pipeline
mechanism) для разрешения пользователя. Механизм настраиваемый для интеграции других
технологий разрешения пользователей, детали этого механизма описаны в разделе «Конвейеры».
После создания объекта ParamBean, Jahia передает управление объекту OperationManager,
который также использует конвейер. Конвейер действий описан далее в этом документе в
соответствующем разделе. Конвейерные операции будут взаимодействовать со службами Jahia для
выполнения желаемых действий, и результат будет зависеть от того какие движки были вызваны в
конвейер.
В случае использования движка ядра, конвейер действий создаст все необходимые объекты содержимого,
дающие разработчику шаблонов тот контент, который он будет размещать на JSP-страницах. Поэтому
после формирования объектов контента портал напрявляет пользовательский запрос к JSP-шаблону для
отрисовки страницы.
В заключение конечный результат отправляется обратно в браузер.
Естественно, это очень упрощенный пример работы портала, но он может послужить базой для понимания
схемы обработки запросов в Jahia. Взаимодействие портала с кэшами было опущено для упрощения
описания процесса, но очевидно, что интеграторам придется брать их во внимание при разработке
своих портальных решений.
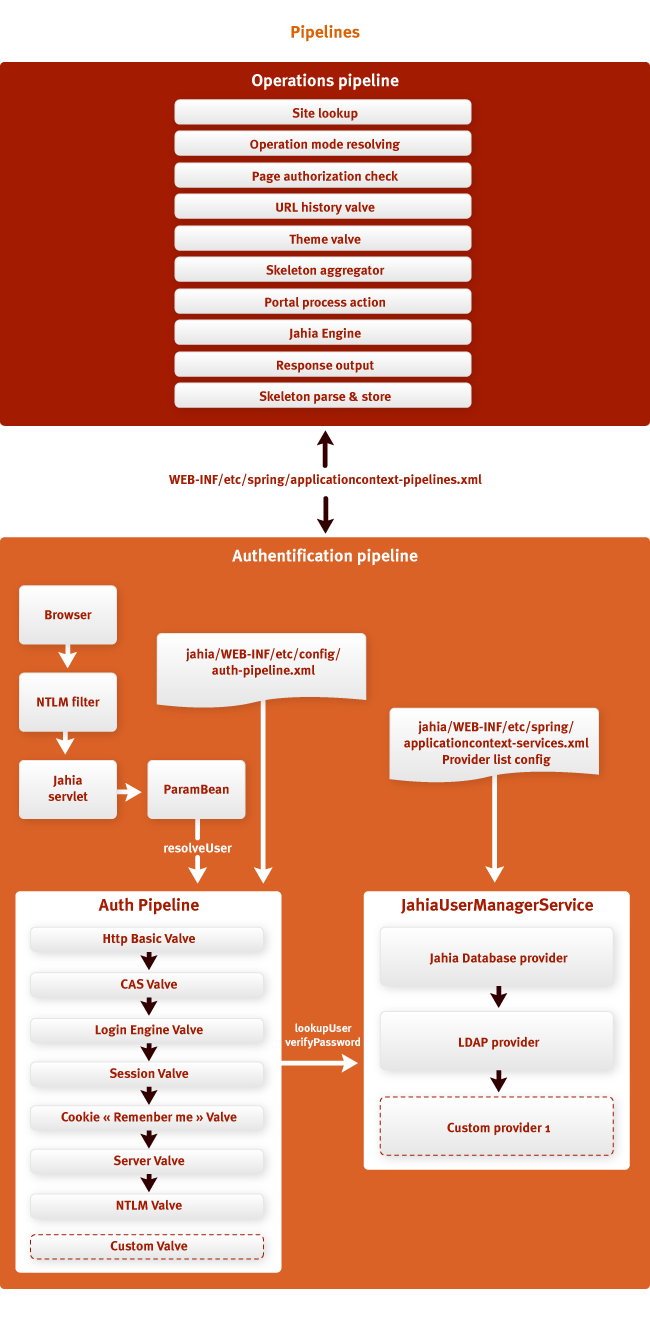
Как было сказано в предыдущем разделе, Jahia использует конвейеры (pipelines) для предоставления
настраиваемых цепочек обработки. Конвейер – это упорядоченый список уровней (клапанов,
valves), которые по очереди вызываются друг за другом. Что является специфическим для шаблона
проектирования Конвейер (pipeline design pattern) – так это то, что ответственностью каждого
уровня является вызвать следующий. Другими словами, уровень может выбирать, передавать выполнение
следующему, или нет.
Конвейер аутентификации вызывается объектом ParamBean для определения пользователя,
основываясь на текущем контексте. Пользователи могут быть определены с использованием всех
методов: это поиск информации в сохраненных сессиях, если они ранее уже были определены; или с
помощью интегрированной системы единого входа типа CAS, или используя аутентификацию контейнера
JEE. На рисунке выше нижний конвейер – конвейер аутентификации, в нем видны различные уровни для
определения пользователей. Мы не будем углубляться в детали каждого уровня, но стоит отметить, что
данный механизм разрешения является настраиваемым с помощью xml-файлов Spring, что облечает
интеграторам применять их собственные уровни.
Конвейер действий (верхняя часть рисунка) используется в Jahia для предоставления
подключаемых цепочек обработки запросов. Уровни конвейера могут принимать решение остановить
обработку запроса в любой точке, что особенно важно при работе с кэшем. Если содержимое можно
прочитать из кэша, обработка запроса приостанавливается в этом месте, и это освобождает сервер от
выполнения ненужных операций, делая процесс обработки запроса очень еффективным. Уровень
конвейера, ответственный за чтение из кэша на рисунке назван «Сборщик каркаса» (Skeleton
aggregator). Уровень конвейера «URL history» используется для записи всех урлов,
запрошенных пользователем в целях построения навигационной цепочки (breadcrumbs).
Интеграторы могут найти интересной возможность настраивать конвейер действий для расширения
функционала, задействованного при обработке пользовательских запросов. Следует отметить, что
порядок размещения уровней в конвейере очень важен, и что не рекомендуется этот порядок менять без
глубокого понимания принципов работы портала Jahia.

Подсистема импорта и экспорта портала Jahia – это мощный механизм миграции контента различными
способами между веб-сайтами Jahia или даже между различными инсталляциями системы.
Для экспорта контента система использует xml-формат хранения данных JSR-170 (или JCR), вместе с
другими специфическими файлами (типа файловых иерархий для экспорта двоичных данных). Все эти
файлы сжимаются в zip-архив, который можно будеть использовать в подсистеме импорта.
Стандартизованный механизм импорта и экспорта делает возможным экспортировать полную инсталляцию
Jahia, набор сайтов, одиночный сат или даже один раздел сайта; перемещать контент между сайтами и
разделами сайтов Jahia; экспортировать и импортировать его в не-Jahia системы.
Jahia также использует технологию импорта и экспорта для возможности удаленной публикации
содержимого. В данном случае обычно импорт (экспорт) содержимого вызывается планировщиком
задач. Технология импорта и экспорта умеет распознавать, когда содержимое было изменено, и в таком
случае просто обновляет объект содержимого вместо создания нового.
Хоть это и не очевидно, но функция copy/paste тоже использует систему импорта и экспорта. Данный
факт проясняет, почему содержимое можно копировать и вставлять только между совместимыми
описаниями контента, так как Jahia должна знать, как преобразовывать контент между источником
и приемником контента.
Связанные копии (Linked copies) также используют систему систему импорта и экспорта при
отправке содержимого получателю (приемнику).
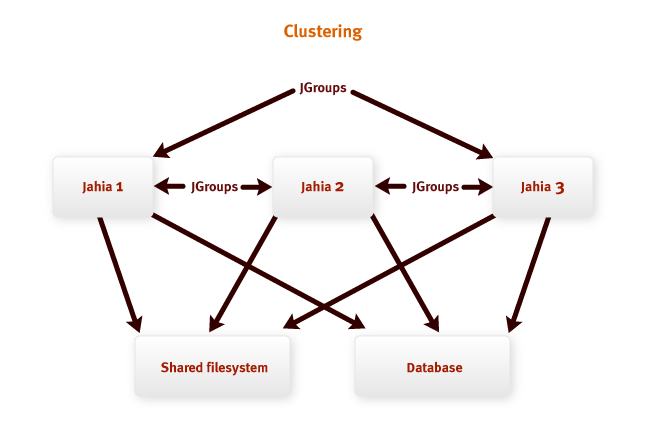
Развертывание системы Jahia на кластер – это эффективный путь уменьшения нагрузки на центральный
процессор и память для обеспечения работы высоконагруженых сайтов.
Типичная установка Jahia на кластер показана на рисунке выше. Узлы Jahia обмениваются напрямую
друг с другом (direct messaging) и имеют доступ к разделяемым ресурсам: файловой системе и базе
данных.
Файловая система используется для хранения поискового индекса и для хранения двоичных
данных (если сервер настроен на хранение двоичных данных в файловой системе, настройка по
умолчанию – хранение в БД).
В базе данных хранится все остальное. Поэтому очень важно иметь высокопроизводительную инсталляцию
базы данных для обеспечения хорошей масштабируемости всей системы.
Jahia также может различать узлы по типам в кластере для обеспечения более специализированной
обработки. Рассмотрим вкратце различные типы узлов.
Узлы просмотра (Jahia «browsing» nodes) – это специализированные узлы Jahia, которые
функционируют как узлы публикации содержимого. Также они взаимодействуют с портлетами для
отрисовки страниц. Использование данного типа узла позволяет отделить нагрузку на систему выдачи
контента от нагрузки на систему авторизации и систему фоновой обработки запросов.
Узлы авторизации (Jahia «authoring» nodes) – это узлы кластера, использующиеся и при
просмотре и при редактировании содержимого портала. Это наиболее часто используемый тип
узла в кластере Jahia, поэтому нужно иметь несколько экземпляров таких узлов с тем, чтобы
распределить нагрузку.
В Jahia длительно выполняющиеся задачи (это действия по валидации документов (workflow validation
operations), copy/paste-операции, импорт и индексирования содержимого) выполняются как фоновые
процессы. Таким образом при выполнении этих длительных операций другие узлы по-прежнему могут
обрабатывать запросы по просмотру и редактированию содержимого.
Индексирование содержимого и файлов может оказаться очень дорогой операцией по использованию
центрального процессора и по нагрузке на оперативную память сервера. Например, для индексирования
pdf-файла сервер должен выполнить скрипты, которые содержатся в файле для того, чтобы извлечь
текстовое содержимое. Это требует выполнения инструкций Postscript-подобного языка, включая
управление памятью и обработку инструкций, просто для того, чтобы извлечь контент. Индексирование
больших файлов также требует памяти, которая не может быть освобождена до момента завершения
открытия файла.
Индексирование обычно относят к операции, которая не требует выполнения в режиме реального
времени, поэтому она выполняется в фоне. Для того, чтобы понизить нагрузку на сервера Jahia,
выполняющие обработку текущих запросов пользователей, настоятельно рекомендуется установить
отдельный сервер индексирования содержимого.
Можно даже установить в системе несколько узлов сервера индексирования для обеспечения
бесперебойного выполнения данной операции.
Оглавление
Часть 1:
- Общая картина.
- Компоненты пользовательского интерфейса.
- Аутентификация и авторизация.
- Шаблоны оформления.
- Кэширование.
- Объекты содержимого.
- Портал.
- Мэшап-сервер.
Часть 2:
- Файловое хранилище.
- Инструменты и средства (движки).
- Подсистема поиска и индексирования.
- Администрирование.
- Интеграция со Spring.
- Слушатели событий и правила.
- Обработка запросов в Jahia.
- Конвейеры.
- Импорт и экспорт.
- Кластеризация.
Файловое хранилище

Файловое хранилище Jahia было полностью переписано в версии 6. В Jahia 5 хранилище было основано
на использовании библиотеки Apache Slide library, которая на то время была де-факто
стандартом файловых репозитариев с открытым исходным кодом.
Но всвязи с бурным развитием и хорошим качеством Apache Jackrabbit – реализации
спецификации Java Content Repository, Jahia 6 стала использовать ее в качестве стандартного
файлового хранилища и строить поверх данной библиотеки свои сервисы. На самом деле архитектура
Jackrabbit не предполагает тесной зависимости от ее использования, а использует стандартный JCR
API для возможности предоставления доступа к различным репозитариям.
В Jahia 6 стало возможным иметь доступ к файловым хранилищам CIFS/SMB. Некоторые другие
развивающиеся реализации доступны в песочницах репозитариев (sandbox repositories), среди них
коннекторы FTP, Alfresco, Exo Platform, Nuxeo.
На рисунке выше вы можете отметить, что содержимое Jahia (Jahia Content) доступно в качестве
JCR-провайдера, это тоже новая возможность Jahia 6. Пока что в данном направлении проведена
только первоначальная работа по совместимости и интерфейс к данной реализации не может
похвастаться высокой производительностью, но работы по его улучшению будут ведутся постоянно от
версии к версии.
Поверх службы файлового хранилища интерфейсы отдают контент с помощью различных технологий:
WebDAV, просмотр файлов в шаблонах и в пользовательском AJAX-интерфейсе Jahia. Вместе с хранилищем
могут функционировать дополнительные службы портала: Rules engine – для задания правил и
прав доступа к файлам, Thumbnail management – для генерирования миниатюр изображений
(thumbnail), Content extractors – для извлечения метаданных.
Инструменты и средства (движки)
Инструменты и средства в Jahia принято называть движками (engines). Движки Jahia можно
сравнить с объектами Action в Struts. Это блоки логики приложения, каждый их которых
выполняет конкретную задачу. Субдвижки (sub-engines) – еще более мелкие блоки,
контролирующие взаимодействие с примитивами пользовательского интерфейса (например контролирующие
редактирование поля).
Наиболее важный движок – это движок ядра (Core engine), отвечающий за генерирование
страницы содержимого, он вызывается каждый раз, когда портал должен отобразить страницу. Названия
других движков говорят сами за себя: например движки Login и Logout отвечают за
отрисовку пользовательского интерфейса входа и выхода из системы и обработку данных, введенных
пользователем при этих действиях.
Движки редактирования (обработки) контента интегрированы с фреймворком валидации
(validation framework), что позволяет интеграторам задавать правила проверки введенных
пользователем данных.
Движки также интегрированы с пользовательским AJAX интерфейсом. Цель применения AJAX – сделать
пользовательский интерфейс современным, построенным на компонентах, которые можно многократно
повторно использовать. Интеграторы смогут применять уже существующие многочисленные библиотеки
компонентов при построении приложений. Работа в данном направлении начата в Jahia 6 применением
компонентов GWT.
Субдвижки в Jahia используются для отображения интерфейсов редактирования контейнеров.
Контейнер может содержать в себе поля разного типа. При редактировании поля какого-либо типа
движок редактирования контейнера (container edition engine) обращается к субдвижку, отвечающему за
этот тип поля. Например, поле типа File, представляющее файл, будет предоставлять UI-
интерфейс, позволющий пользователю просматривать директории и выбирать файлы, в то время как, поле
типа Small text просто будет отображать поле для ввода текста.
Jahia обрабатывает запросы к движкам, используя параметр «/engineName» в URL. Если параметр
без значения – запрос принимает движок ядра. Строковые значения, которые используются для
именования движков, объявляются самими движками, а в классе JahiaEngine, метод getName
() будет определять ключ для механизма разрешения параметра «/engineName».
Подсистема поиска и индексирования

Подсистема поиска и индексирования Jahia в данном документе будет представлена лишь обзорно – это
очень обширная подсистема. Выше на рисунке мы проиллюстрировали основные составляющие данной
подсистемы.
Новшеством Jahia 6 является интеграция стандарта OpenSearch. Jahia может играть роль как
потребителя, так и как генератора OpenSearch-запросов. Это значит, что пользователи
могут, например, интегрировать Jahia в панель поиска своего браузера и напрямую делать
поисковые запросы из панели браузера. С другой стороны, Jahia может пользоваться услугами
различных OpenSearch-провайдеров и предоставлять на одной странице сведенные результаты для поиска
по Jahia, Google, MSN и т.п.
Что касается более традиционных решений веб-поиска, Jahia предлагает библиотеки тэгов для
поиска по содержимому либо в простом формате полнотекстового поиска, либо используя расширенные
поисковые запросы. Для облегчения формировния расширенных поисковых запросов в UI-компоненты Jahia
встроены удобные селекторы параметров запросов. Эти компоненты сделаны с использованием
AJAX-фреймворка и являются подобными тем, которые применялись при введении данных в интерфейсе
входа в систему.
Другая альтернатива для запросов к объектам содержимого – напрямую встраивать запросы на уровне
шаблонов, а пользователи на экране будут видеть результат уже подготовленного запроса. Это
называется «Запросы контейнера» (Container queries) и использоваться они могут, например,
для загрузки последних пяти объектов содержимого с типа «Новость» при выводе на страницу последних
пяти новостей.
В основе всех этих технологий формирования пользовательских запросов лежат серверные системы,
непосредственно выполняющие поиск и индексирование контента. Поисковый механизм портала дает
возможность осуществлять полнотекстовый поиск, поиск с уточняющими запросами как по содержимому
Jahia, так и по файловому содержимому.
Основа подсистемы поиска и индексирования – opensource фреймворки Compass и Apache
Lucene. Они хранят свой индекс, используя средства файловой системы, но также имеют средства
для хранения информации в базах данных или в распределенных файловых системах.
Стандартная реализация подсистемы с использованием файловой системы на данный момент наиболее
еффективная и готовая к использованию (production-ready), так что Jahia поставляется в комплекте с
этой реализацией.
Администрирование
Интерфейс администрирования – это средство управления всеми различными подсистемами Jahia
из одного места и для администраторов сайта, и для администраторов сервера. Интерфейс
администрирования позволяет администратором выполнять все виды задач:
- создавать, обновлять, удалять пользователей, группы, сайты и категории;
- устанавливать глобальные разрешения;
- устанавливать разрешения на шаблоны и портлеты, разбивать шаблоны и портлеты на
категории; - просматривать статус внутреннего кэша и сбрасывать его;
- устанавливать политику назначения паролей;
- определять языки сайта;
- настраивать возможность удаленной публикации содержимого;
- выполнять другие функции, детально описанные в Руководстве администратора
(Administrator’s guide).
Интерфейс администрирования основан на сервлете-диспетчере и коллекции классов,
контролирующих UI для различных настроек сервера. Также для удобства администраторов интерфейс
поддерживает компоненты пользовательского интерфейса на AJAX.
Интеграция со Spring
Разработчики Jahia любят Spring. Начиная с пятой версии системы Jahia была интегрирована со
Spring Framework для облегчения построения целостных, быстрых и гибких портальных решений.
Для подключения подсистем Jahia к многочисленным сервисам, интеграторам теперь просто следует
использовать хорошо известные механизмы настроек и внедрения зависимостей (dependency injection),
которые предоставляет Spring.
Рисунок выше поясняет настройки, используя которые с помощью Spring можно инициализировать все
различные подсистемы Jahia. Внешние библиотеки портала: Apache Pluto, Hibernate, Apache Lucene –
также работают со Spring, что делает возможным реализовывать стройную архитектуру портала.
Опыт интеграции Jahia со Spring был успешным и зависимостей системы от Spring практически не
появилось, что делает возможным в дальнейшем в случае необходимости свободно мигрировать на другой
фреймворк.
Слушатели событий и правила
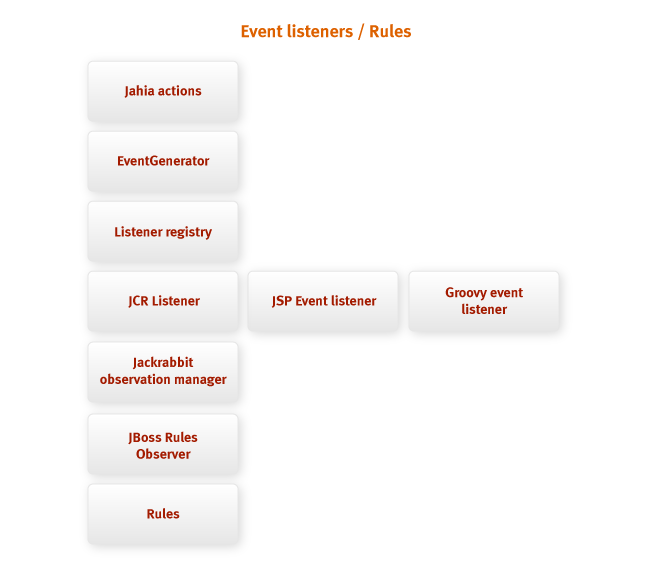
Действия, выполняемые пользователями портала, порождают события, которые могут
использоваться для выполнения определённых задач. Jahia позволяет интеграторам регистрировать свои
слушатели событий. На приведенном выше графике показано, как события, передаются по различным
подсистемам и как они могут быть использованы разработчиками.
Событие порождается при выполнении некоторого действия порталом. Это может быть команда
пользователя, действие по расписанию, фоновый процесс. Действие вызывает
генератор события (event generator) для создания объекта события. Данный объект далее будет
передан в реестр слушателей (listeners registry), который зарегистрированным слушателям
будет вызывать необходимые классы. Некоторые из слушателей событий являются шлюзами к
другим слушателям, использующим другие технологии. Есть возможность использовать слушатель событий
Groovy (Groovy event listener), позволяющий интегратором использовать язык Groovy в
реализациях слушателей; слушатель событий JSP (JSP event listener), делающий то же для
JSP-страниц.
Еще один специфический слушатель – менеджер наблюдения JCR (JCR observation manager),
который связует механизм событий Jahia со стандартной моделью наблюдения JCR (JCR observation).
Под данной реализацией находится наблюдатель JBoss Rules (JBoss Rules observer),
позволяющий интеграторам использовать правила (rules) для опработки событий.
Обработка запросов в Jahia
Выше представлена схема обработки системой Jahia запроса от браузера. Схема может использоваться
разработчиками для определения подсистем портала, задействованных в процессе обработки конкретного
запроса.
Запрос браузера может быть направлен либо на Jahia servlet, либо на WebDAV servlet
(если запрашивается бинарный файл).
Во втором случае (WebDAV servlet) запрос будет перенаправлен в службу файлового хранилища,
пройдет валидацию на право доступа к запрашиваемому ресурсу и потом результат будет возвращен
обратно в браузер.
В первом случае будет вызван Jahia servlet. Jahia немедленно создаст объект контекста
(context object) под названием «ParamBean». Данный будет содержать в себе всю
информацию о запросе, включая такие вещи как запрошеная страница, текущий пользователь, язык
просмотра и так далее. Внутренне ParamBean использует механизм конвейерной обработки (pipeline
mechanism) для разрешения пользователя. Механизм настраиваемый для интеграции других
технологий разрешения пользователей, детали этого механизма описаны в разделе «Конвейеры».
После создания объекта ParamBean, Jahia передает управление объекту OperationManager,
который также использует конвейер. Конвейер действий описан далее в этом документе в
соответствующем разделе. Конвейерные операции будут взаимодействовать со службами Jahia для
выполнения желаемых действий, и результат будет зависеть от того какие движки были вызваны в
конвейер.
В случае использования движка ядра, конвейер действий создаст все необходимые объекты содержимого,
дающие разработчику шаблонов тот контент, который он будет размещать на JSP-страницах. Поэтому
после формирования объектов контента портал напрявляет пользовательский запрос к JSP-шаблону для
отрисовки страницы.
В заключение конечный результат отправляется обратно в браузер.
Естественно, это очень упрощенный пример работы портала, но он может послужить базой для понимания
схемы обработки запросов в Jahia. Взаимодействие портала с кэшами было опущено для упрощения
описания процесса, но очевидно, что интеграторам придется брать их во внимание при разработке
своих портальных решений.
Конвейеры
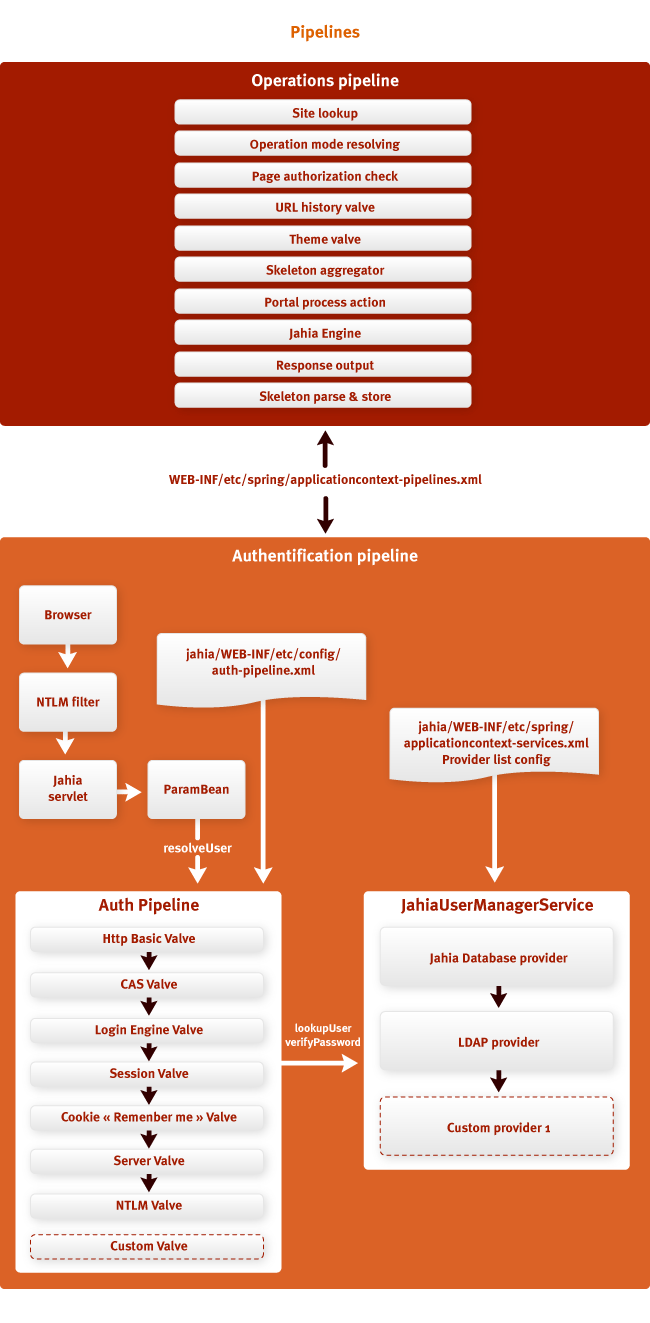
Как было сказано в предыдущем разделе, Jahia использует конвейеры (pipelines) для предоставления
настраиваемых цепочек обработки. Конвейер – это упорядоченый список уровней (клапанов,
valves), которые по очереди вызываются друг за другом. Что является специфическим для шаблона
проектирования Конвейер (pipeline design pattern) – так это то, что ответственностью каждого
уровня является вызвать следующий. Другими словами, уровень может выбирать, передавать выполнение
следующему, или нет.
Конвейер аутентификации вызывается объектом ParamBean для определения пользователя,
основываясь на текущем контексте. Пользователи могут быть определены с использованием всех
методов: это поиск информации в сохраненных сессиях, если они ранее уже были определены; или с
помощью интегрированной системы единого входа типа CAS, или используя аутентификацию контейнера
JEE. На рисунке выше нижний конвейер – конвейер аутентификации, в нем видны различные уровни для
определения пользователей. Мы не будем углубляться в детали каждого уровня, но стоит отметить, что
данный механизм разрешения является настраиваемым с помощью xml-файлов Spring, что облечает
интеграторам применять их собственные уровни.
Конвейер действий (верхняя часть рисунка) используется в Jahia для предоставления
подключаемых цепочек обработки запросов. Уровни конвейера могут принимать решение остановить
обработку запроса в любой точке, что особенно важно при работе с кэшем. Если содержимое можно
прочитать из кэша, обработка запроса приостанавливается в этом месте, и это освобождает сервер от
выполнения ненужных операций, делая процесс обработки запроса очень еффективным. Уровень
конвейера, ответственный за чтение из кэша на рисунке назван «Сборщик каркаса» (Skeleton
aggregator). Уровень конвейера «URL history» используется для записи всех урлов,
запрошенных пользователем в целях построения навигационной цепочки (breadcrumbs).
Интеграторы могут найти интересной возможность настраивать конвейер действий для расширения
функционала, задействованного при обработке пользовательских запросов. Следует отметить, что
порядок размещения уровней в конвейере очень важен, и что не рекомендуется этот порядок менять без
глубокого понимания принципов работы портала Jahia.
Импорт и экспорт
Подсистема импорта и экспорта портала Jahia – это мощный механизм миграции контента различными
способами между веб-сайтами Jahia или даже между различными инсталляциями системы.
Для экспорта контента система использует xml-формат хранения данных JSR-170 (или JCR), вместе с
другими специфическими файлами (типа файловых иерархий для экспорта двоичных данных). Все эти
файлы сжимаются в zip-архив, который можно будеть использовать в подсистеме импорта.
Стандартизованный механизм импорта и экспорта делает возможным экспортировать полную инсталляцию
Jahia, набор сайтов, одиночный сат или даже один раздел сайта; перемещать контент между сайтами и
разделами сайтов Jahia; экспортировать и импортировать его в не-Jahia системы.
Jahia также использует технологию импорта и экспорта для возможности удаленной публикации
содержимого. В данном случае обычно импорт (экспорт) содержимого вызывается планировщиком
задач. Технология импорта и экспорта умеет распознавать, когда содержимое было изменено, и в таком
случае просто обновляет объект содержимого вместо создания нового.
ОТНОШЕНИЕ К COPY/PASTE
Хоть это и не очевидно, но функция copy/paste тоже использует систему импорта и экспорта. Данный
факт проясняет, почему содержимое можно копировать и вставлять только между совместимыми
описаниями контента, так как Jahia должна знать, как преобразовывать контент между источником
и приемником контента.
Связанные копии (Linked copies) также используют систему систему импорта и экспорта при
отправке содержимого получателю (приемнику).
Кластеризация
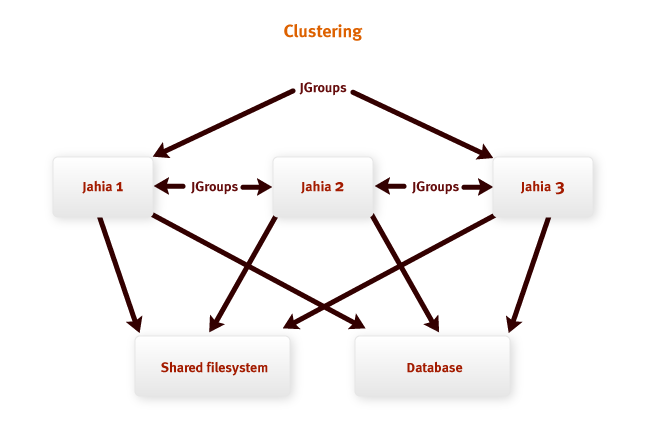
Развертывание системы Jahia на кластер – это эффективный путь уменьшения нагрузки на центральный
процессор и память для обеспечения работы высоконагруженых сайтов.
Типичная установка Jahia на кластер показана на рисунке выше. Узлы Jahia обмениваются напрямую
друг с другом (direct messaging) и имеют доступ к разделяемым ресурсам: файловой системе и базе
данных.
Файловая система используется для хранения поискового индекса и для хранения двоичных
данных (если сервер настроен на хранение двоичных данных в файловой системе, настройка по
умолчанию – хранение в БД).
В базе данных хранится все остальное. Поэтому очень важно иметь высокопроизводительную инсталляцию
базы данных для обеспечения хорошей масштабируемости всей системы.
Jahia также может различать узлы по типам в кластере для обеспечения более специализированной
обработки. Рассмотрим вкратце различные типы узлов.
УЗЛЫ ПРОСМОТРА
Узлы просмотра (Jahia «browsing» nodes) – это специализированные узлы Jahia, которые
функционируют как узлы публикации содержимого. Также они взаимодействуют с портлетами для
отрисовки страниц. Использование данного типа узла позволяет отделить нагрузку на систему выдачи
контента от нагрузки на систему авторизации и систему фоновой обработки запросов.
УЗЛЫ АВТОРИЗАЦИИ
Узлы авторизации (Jahia «authoring» nodes) – это узлы кластера, использующиеся и при
просмотре и при редактировании содержимого портала. Это наиболее часто используемый тип
узла в кластере Jahia, поэтому нужно иметь несколько экземпляров таких узлов с тем, чтобы
распределить нагрузку.
УЗЛЫ ОБРАБОТКИ
В Jahia длительно выполняющиеся задачи (это действия по валидации документов (workflow validation
operations), copy/paste-операции, импорт и индексирования содержимого) выполняются как фоновые
процессы. Таким образом при выполнении этих длительных операций другие узлы по-прежнему могут
обрабатывать запросы по просмотру и редактированию содержимого.
СЕРВЕР ИНДЕКСИРОВАНИЯ
Индексирование содержимого и файлов может оказаться очень дорогой операцией по использованию
центрального процессора и по нагрузке на оперативную память сервера. Например, для индексирования
pdf-файла сервер должен выполнить скрипты, которые содержатся в файле для того, чтобы извлечь
текстовое содержимое. Это требует выполнения инструкций Postscript-подобного языка, включая
управление памятью и обработку инструкций, просто для того, чтобы извлечь контент. Индексирование
больших файлов также требует памяти, которая не может быть освобождена до момента завершения
открытия файла.
Индексирование обычно относят к операции, которая не требует выполнения в режиме реального
времени, поэтому она выполняется в фоне. Для того, чтобы понизить нагрузку на сервера Jahia,
выполняющие обработку текущих запросов пользователей, настоятельно рекомендуется установить
отдельный сервер индексирования содержимого.
Можно даже установить в системе несколько узлов сервера индексирования для обеспечения
бесперебойного выполнения данной операции.
