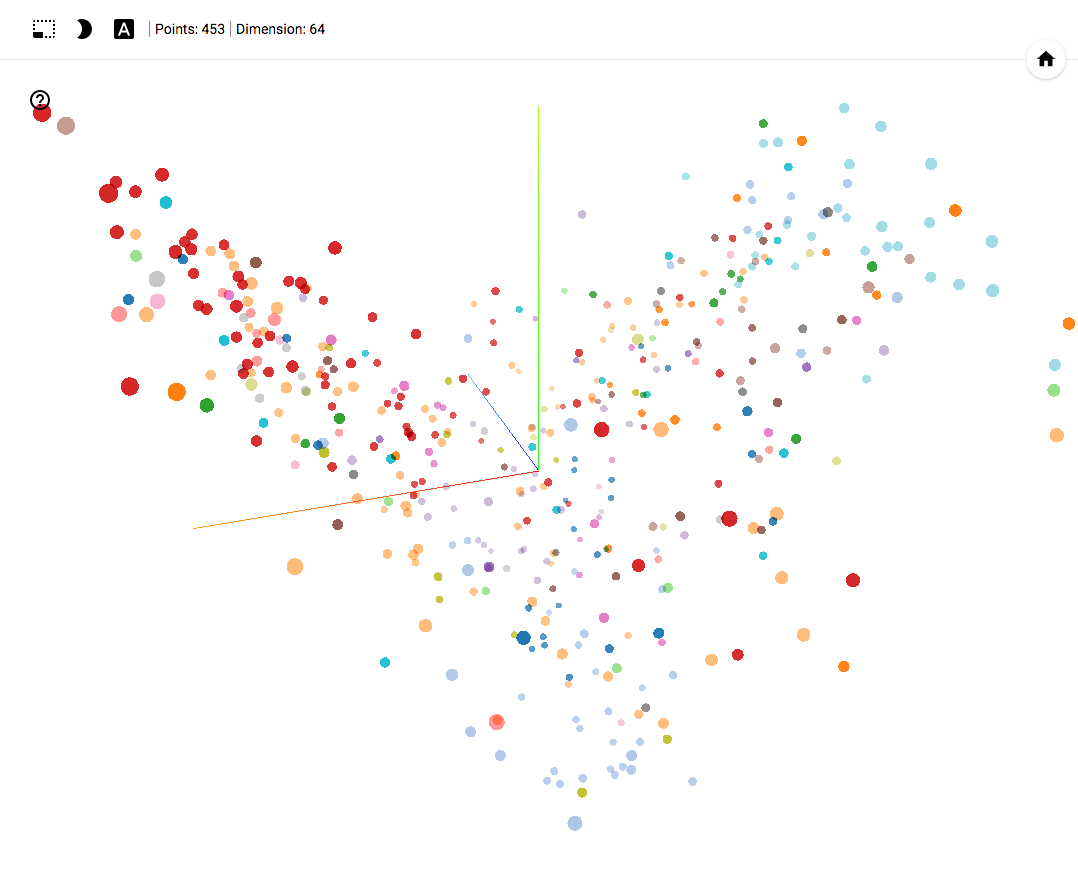
Привет, Хабр! Задача снижения размерности является одной из важнейших в анализе данных и может возникнуть в двух следующих случаях. Во-первых, в целях визуализации: перед тем, как работать с многомерными данными, исследователю может быть полезно посмотреть на их структуру, уменьшив размерность и спроецировав их на двумерную или трехмерную плоскость. Во-вторых, понижение размерности полезно для предобработки признаков в моделях машинного обучения, поскольку зачастую неудобно обучать алгоритмы на сотне признаков, среди которых может быть множество зашумленных и/или линейно зависимых, от них нам, конечно, хотелось бы избавиться. Наконец, уменьшение размерности пространства значительно ускоряет обучение моделей, а все мы знаем, что время — это наш самый ценный ресурс.
UMAP (Uniform Manifold Approximation and Projection) — это новый алгоритм уменьшения размерности, библиотека с реализацией которого вышла совсем недавно.
Авторы алгоритма считают, что UMAP способен бросить вызов современным моделям снижения размерности, в частности, t-SNE, который на сегодняшний день является наиболее популярным. По результатам их исследований, у UMAP нет ограничений на размерность исходного пространства признаков, которое необходимо уменьшить, он намного быстрее и более вычислительно эффективен, чем t-SNE, а также лучше справляется с задачей переноса глобальной структуры данных в новое, уменьшенное пространство.
В данной статье мы постараемся разобрать, что из себя представляет UMAP, как настраивать алгоритм, и, наконец, проверим, действительно ли он имеет преимущества перед t-SNE.