Развитие языка JavaScript постепенно переносит всю тяжесть вычислений с одного сервера на сеть пользовательских компьютеров. Это супер-хорошо. Программирование на стороне сервера вынуждало очень тщательно оптимизировать код по быстродействию и занимаемой памяти, в то же время разработка клиентской части несколько отставала.
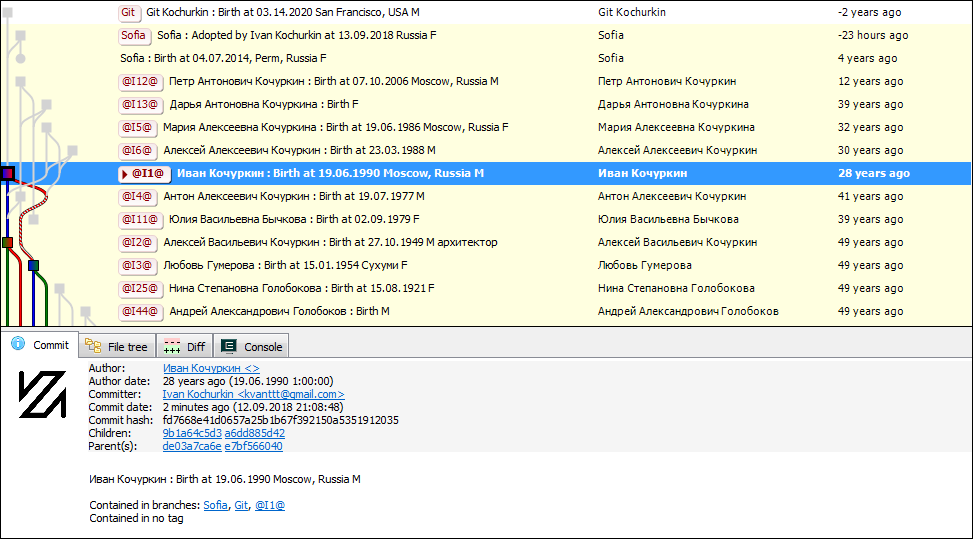
Для удобного и быстрого кодирования можно применять структуры данных. Именно так и поступают при разработке на Java:
https://habr.com/ru/post/237043/
А вот для аналогичной работы с JavaScript оптимизированных инструментов по умолчанию не предоставляется. Реализация Array(), Set() и Map() перекладывается на сторонних разработчиков браузерных движков, а их разработки на сегодняшний день далеки от оптимальности:
https://habr.com/ru/company/ruvds/blog/518032/
Зададимся вопросом — а что если требуются прямо сейчас оптимальные по производительности и памяти структуры данных. Какой минимальный набор достаточно оптимальных структур реализовать и поддерживать? Один из вариантов ответа — это сделать двунаправленный связный список и сбалансированное дерево поиска.
Что это нам даст?
Реализуя связный список LinkedList мы получаем сразу список, двунаправленную очередь и стек. И если это сделать без JavaScript Array(), а лишь используя простые ссылки на объекты, то получаем стандартную и достаточно оптимальную структуру данных.
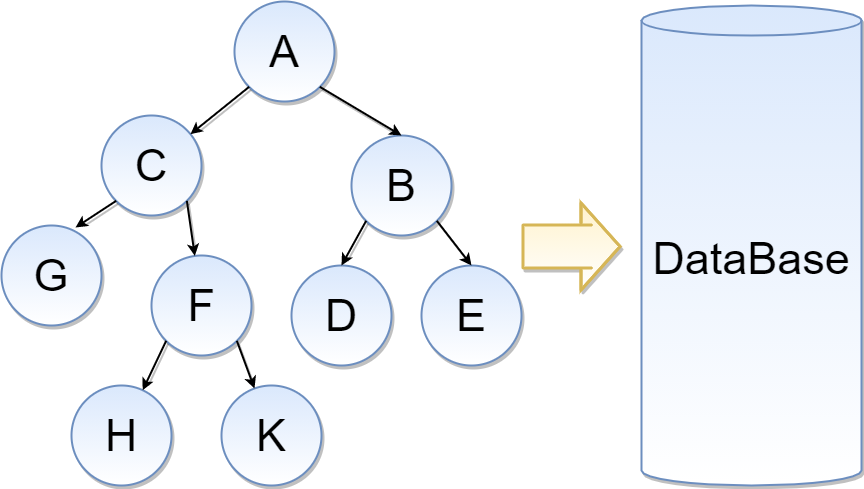
Если же сделать бинарное сбалансированное дерево поиска TreeMap, например AVL-дерево:
https://habr.com/ru/post/150732/
тогда используя эту реализацию можно получить следующие структуры данных:


 Tree — двумерный бинарно-безопасный формат представления структурированных данных. Легко читаемый как человеком так и компьютером. Простой, компактный, быстрый, выразительный и расширяемый. Сравнивая его с другими популярными форматами, можно составить следующую сравнительную таблицу:
Tree — двумерный бинарно-безопасный формат представления структурированных данных. Легко читаемый как человеком так и компьютером. Простой, компактный, быстрый, выразительный и расширяемый. Сравнивая его с другими популярными форматами, можно составить следующую сравнительную таблицу: Это последняя, на сегодняшний день, статья из цикла про внутреннее устройство конкурентных ассоциативных контейнеров. В предыдущих статьях рассматривались hash map, был построен алгоритм lock-free ordered list и контейнеры на его основе. За бортом остался один важный тип структур данных — деревья. Пришло время немного рассказать и о них.
Это последняя, на сегодняшний день, статья из цикла про внутреннее устройство конкурентных ассоциативных контейнеров. В предыдущих статьях рассматривались hash map, был построен алгоритм lock-free ordered list и контейнеры на его основе. За бортом остался один важный тип структур данных — деревья. Пришло время немного рассказать и о них.