
Количество американских патентных заявок связанных с социальными сетями последние 5 лет росло на 250% каждый год (
ссылка). Так, например, одна корпорация подала патентную заявку на метод ценообразования который учитывает положение покупателя в социальном графе (
обсуждение на Slashdot). Другая корпорация недавно воплотила максимально упрощенный вариант этой схемы, продавая свои новые телефоны влиятельным узлам социального графа за $0, а остальным за $530.
Анализ социальных сетей (
Social Network Analysis) существовал задолго до Интернета, но в последнее время набирает обороты.
Мне было интересно посмотреть, как эффективно алгоритм, выделяющий кластеры в графах, сработает для некоторых групп в Twitter, которые представляют для меня интерес.
23 января в Запорожье пройдет
#UKRTWEET — первый всеукраинский баркэмп посвященный Twitter. Граф выше показывает, кто из его участников, с кем разговаривает и кого упоминает.
Заметка ниже посвящена анализу этого графа. Весь код используемых здесь скриптов лежит на
github. Изложение, в какой-то мере, вдохновлено
недавно упомянутой на Хабре книгой Тоби Сегаран «Программируем коллективный разум», код примеров которой доступен
на сайте автора.
Также о data mining в Twitter я говорил 16 января на первой в этом году донецкой встрече "Кофе и код". Поэтому здесь параллельно проведу анализ группы людей из Донецка, которые пишут в Twitter. Кстати, в этом году донецкие встречи будут регулярными — каждую третью субботу месяца (следующая 20 февраля). Следите за
группой.

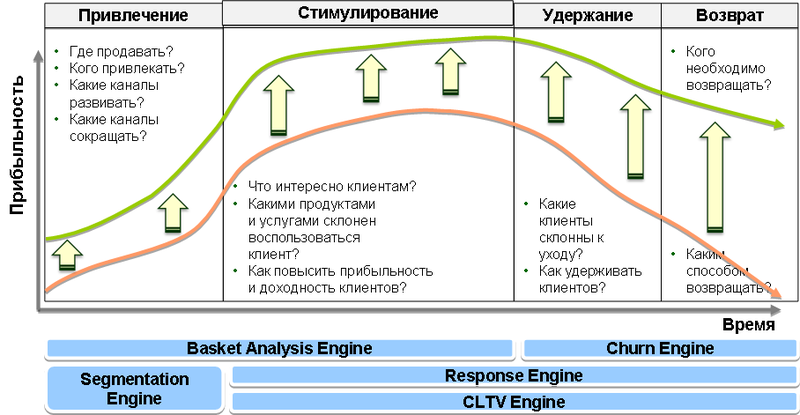
 Довольно давно являюсь обитателем Хабра, но так и не доводилось читать статьи на тему многомерных кубов, OLAP и MDX, хотя тема очень интересная и с каждым днем становится все более актуальной.
Довольно давно являюсь обитателем Хабра, но так и не доводилось читать статьи на тему многомерных кубов, OLAP и MDX, хотя тема очень интересная и с каждым днем становится все более актуальной. Вы звоните провайдеру. Приготовившись к разговору с вымученно-жизнерадостной девушкой о количестве зелёных лампочек на чёрной коробочке, даже немного теряетесь, когда вам отвечает натуральный сисадмин. И сразу же понимает суть проблемы и решает её. Вы кладёте трубку через 25 секунд разговора в лёгком шоке.
Вы звоните провайдеру. Приготовившись к разговору с вымученно-жизнерадостной девушкой о количестве зелёных лампочек на чёрной коробочке, даже немного теряетесь, когда вам отвечает натуральный сисадмин. И сразу же понимает суть проблемы и решает её. Вы кладёте трубку через 25 секунд разговора в лёгком шоке.  В
В 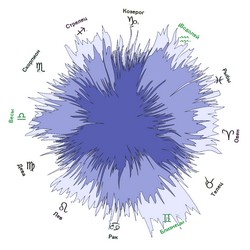
 Во всех онлайн сервисах и играх самая большая доля аудитории уходит прямо на старте – в первые же минуты и часы знакомства с продуктом. Этой теме уже посвящены сотни книг и статей с самыми различными гипотезами успеха и причин лояльности аудитории – уникальность, простота, юзабилити, бесплатность, обучение или инструкция, эмоциональность, и еще множество факторов считаются крайне важными.
Во всех онлайн сервисах и играх самая большая доля аудитории уходит прямо на старте – в первые же минуты и часы знакомства с продуктом. Этой теме уже посвящены сотни книг и статей с самыми различными гипотезами успеха и причин лояльности аудитории – уникальность, простота, юзабилити, бесплатность, обучение или инструкция, эмоциональность, и еще множество факторов считаются крайне важными.  Внутри у среднего банкомата лежит от 1 до 3 миллионов рублей. Они разложены по 4 кассетам, в каждой из которых – купюры своего номинала. Замена кассет похожа на замену картриджей в принтере: модуль вынимается (и неважно, сколько там осталось денег — инкассаторы этого даже не знают по правилам безопасности), а на его место вставляется другой модуль точно по стрелке, указывающей, какой стороной и как это делать.
Внутри у среднего банкомата лежит от 1 до 3 миллионов рублей. Они разложены по 4 кассетам, в каждой из которых – купюры своего номинала. Замена кассет похожа на замену картриджей в принтере: модуль вынимается (и неважно, сколько там осталось денег — инкассаторы этого даже не знают по правилам безопасности), а на его место вставляется другой модуль точно по стрелке, указывающей, какой стороной и как это делать. 