
В первом посте об аналитической системе Sports.ru и Tribuna.com мы рассказали о том, как используем нашу инфраструктуру в повседневной жизни: наполняем контентом рекомендательную систему, наблюдаем за бизнес-метриками, ищем среди пользовательского контента бриллианты, находим ответы на вопросы “Как работает лучше?” и “Почему?”, нарезаем пользователей для почтовых рассылок и строим красивые отчеты о деятельности компании. Всю техническую часть повествования мы скромно спрятали за этой схемой:
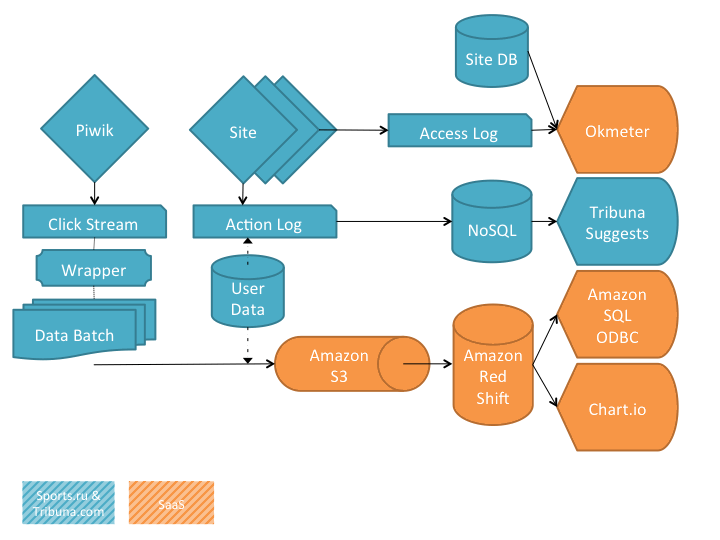
Читатели законно потребовали продолжить повествование со смешными котиками, а olegbunin пригласил рассказать о всем, что было скрыто, на РИТ++. Что ж, изложим некоторые технические детали – в продолжении веселого поста.
Читатели законно потребовали продолжить повествование со смешными котиками, а olegbunin пригласил рассказать о всем, что было скрыто, на РИТ++. Что ж, изложим некоторые технические детали – в продолжении веселого поста.
")
