
«Галоп пикселя», часть I — базовые понятия, этапы взросления, прикладные упражнения (
линк)
«Галоп пикселя», часть II — перспектива, цвет, анатомия и прикладные упражнения (
линк)
«Галоп пикселя», часть III — Анимация (
линк)
«Галоп пикселя», часть IV — Анимация света и тени (
линк)
«Галоп пикселя», часть V — Анимация персонажей. Ходьба (
линк)
Доброго времени суток Хабру и ценителям пиксель-арта, поклонникам квадратных точек, адептам лимитированных разрешений и цветов. Рад представить на ваш суд очередную статью из цикла «Галоп Пикселя». Не буду тратить время на оправдания моего долгого отсутствия и в виду явного присутствия перейду к сути дела. Сегодня мы продолжим изучать анимацию. На этот раз это будет анимация света и тени. Большей частью на статических объектах. Всё помнят – сначала база. Сначала фундамент. Сначала простое. Ну а сложное ввалится в ваши двери само, вслед за детишками.
В этой статье мы рассмотрим анимацию света плоскостями, когда мы анимируем свет крупными заливками и лишь затем начинаем его детализировать. Анимацию света по контуру объекта, и поведение света на разных поверхностях, иначе на объектах с разными материалами. Три главы. Три пули. Надеюсь, что в цель.
Цель этой статьи показать насколько силён дуэт брата и сестры, Света и Тени в движении. Мы уже видели, как они преображают сцены в статике. Но динамика нам ещё не знакома. Давайте исправим это упущение.
Лопаты в руки.


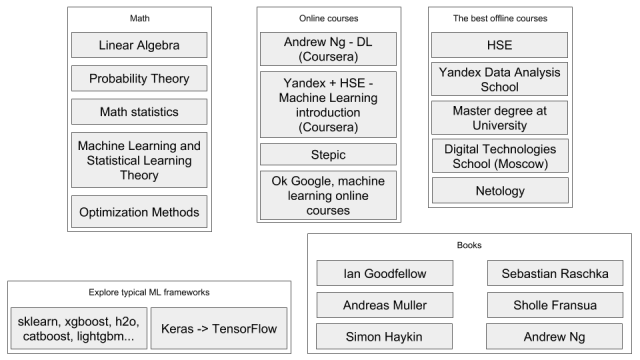





 Эта статья послужит практическим руководством по сборке, начальной настройке и тестированию работоспособности Hadoop начинающим администраторам. Мы разберем, как собрать Hadoop из исходников, сконфигурировать, запустить и проверить, что все работает, как надо. В статье вы не найдете теоретической части. Если вы раньше не сталкивались с Hadoop, не знаете из каких частей он состоит и как они взаимодействуют, вот пара полезных ссылок на официальную документацию:
Эта статья послужит практическим руководством по сборке, начальной настройке и тестированию работоспособности Hadoop начинающим администраторам. Мы разберем, как собрать Hadoop из исходников, сконфигурировать, запустить и проверить, что все работает, как надо. В статье вы не найдете теоретической части. Если вы раньше не сталкивались с Hadoop, не знаете из каких частей он состоит и как они взаимодействуют, вот пара полезных ссылок на официальную документацию:


{kind=link}