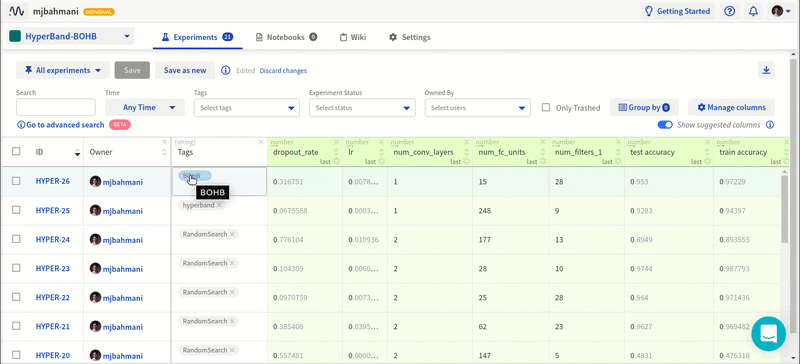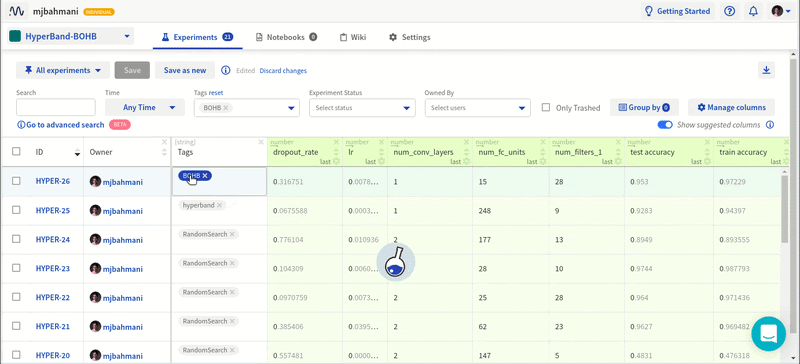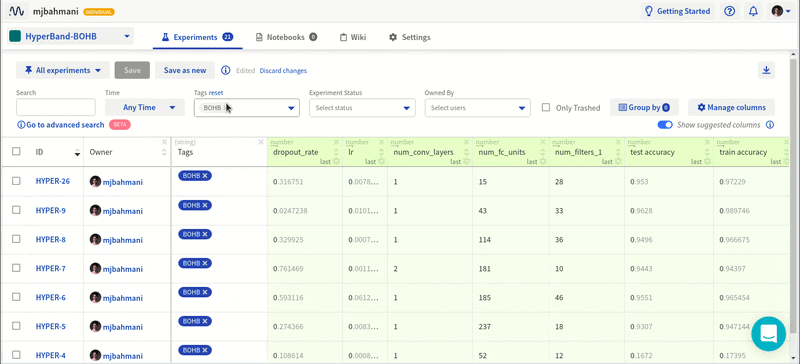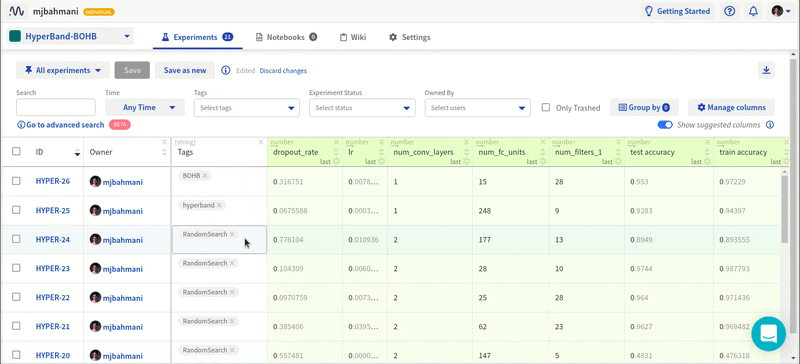
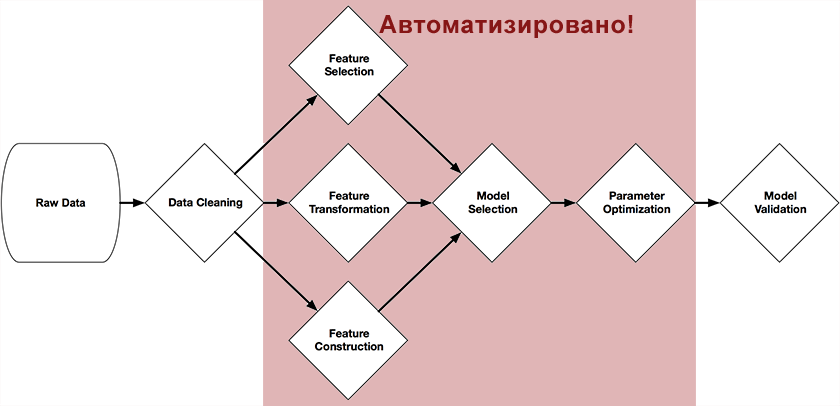
Привет! Меня зовут Роман Ленц, в Первой грузовой компании (ПГК) я занимаюсь анализом данных и машинным обучением в рамках проекта «Цифровой вагон», подробнее о котором рассказано здесь. Еще 3 года назад я работал инженером-конструктором в зарубежной строительной компании. Почему я решил кардинально поменять свою карьерную траекторию, почему выбрал именно Data Science, и как я к этому пришёл? Поделюсь опытом, который, возможно, окажется полезным для молодых специалистов, ищущих «работу мечты». Тем, кто задумался о смене профессии, думаю, информация тоже будет полезна.
Я получил высшее образование за границей. После окончания вуза устроился на работу в московское представительство иностранной строительной компании. Мы занимались проектированием объектов по всему миру, но на российском рынке количество заказов постепенно снижалось: стоимость услуг была слишком высокой для местных клиентов. Стало очевидно, что скоро придется искать другую работу. Именно тогда я задумался о том, чтобы сменить карьерную траекторию.
Не скажу, что выбрал Data Science совсем случайно. Как у инженера у меня был сильный математический бэкграунд, я был знаком с основами некоторых языков программирования, разбирался в работе с данными. Меня привлекали области, где можно применить эти навыки и знания, поэтому направление Data Science показалось мне интересным вариантом для более глубокого погружения.
Определившись, я стал постепенно вспоминать основы математики, линейной алгебры, статистики, теории вероятности. Параллельно начал проходить профильные курсы на крупных онлайн-платформах – DataCamp, Stepik, Яндекс.Практикум и других.