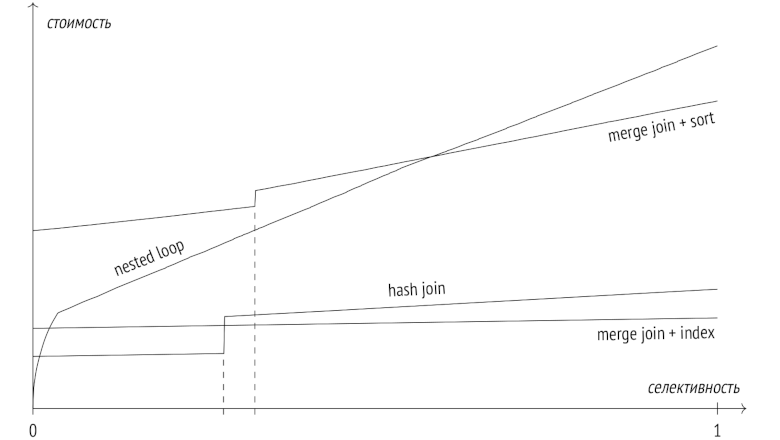
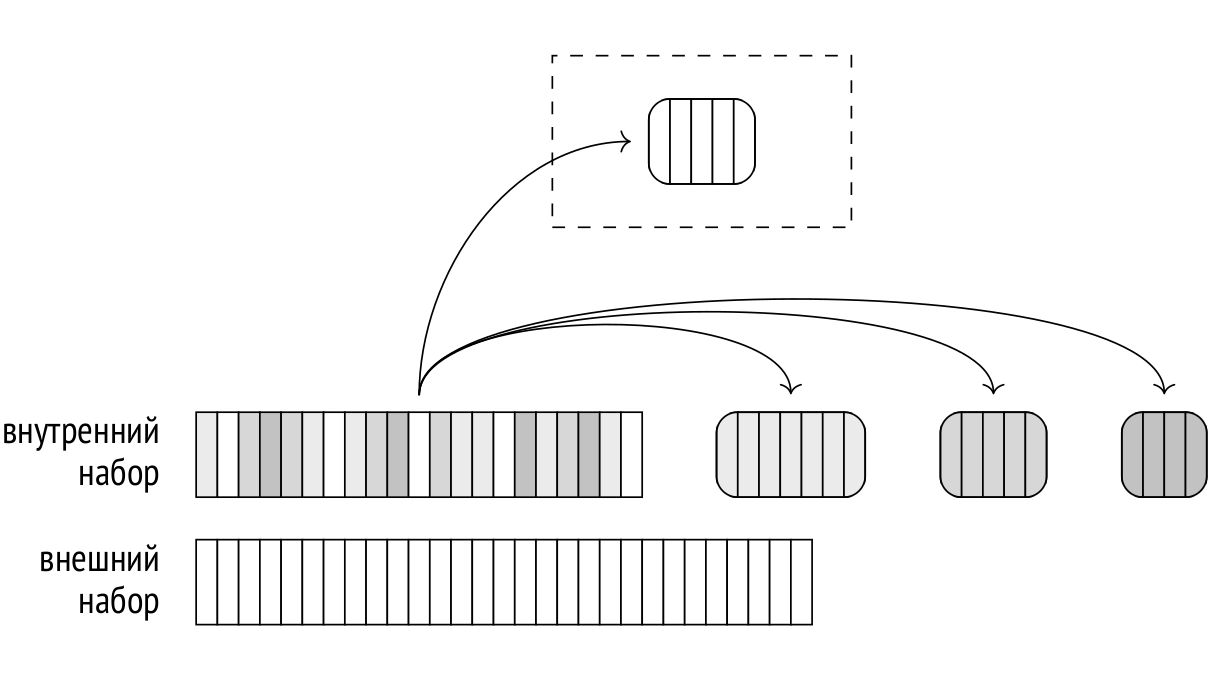
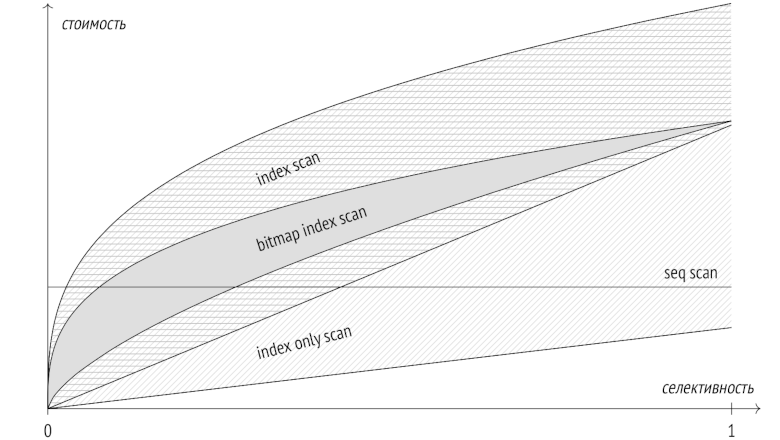
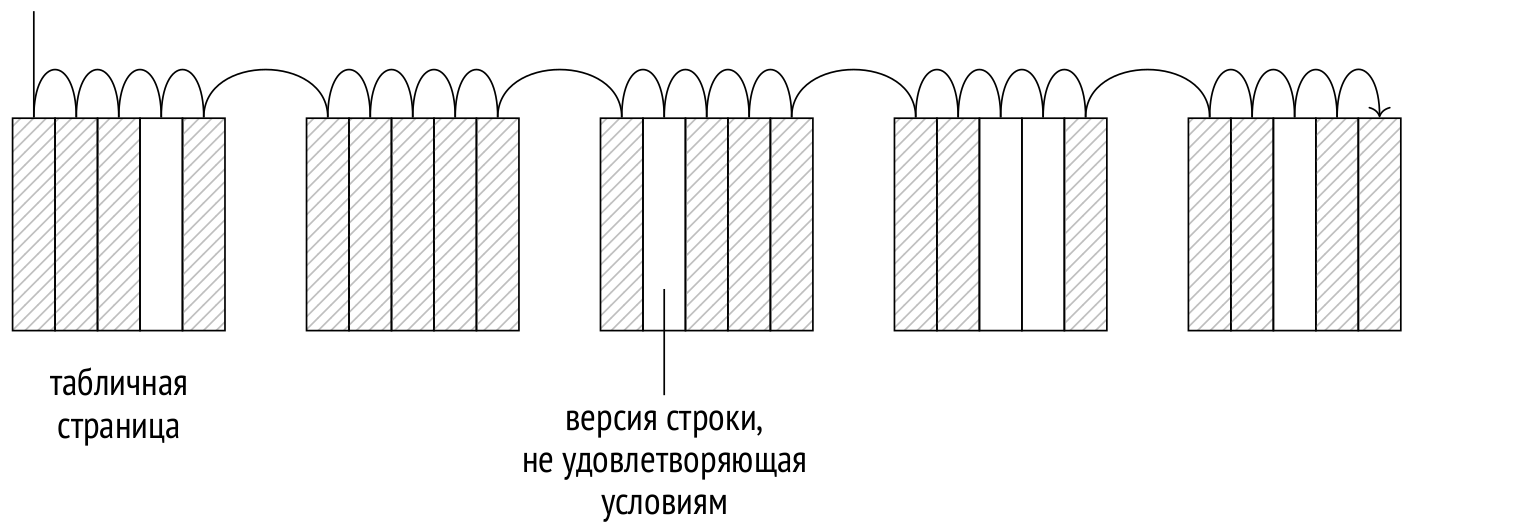
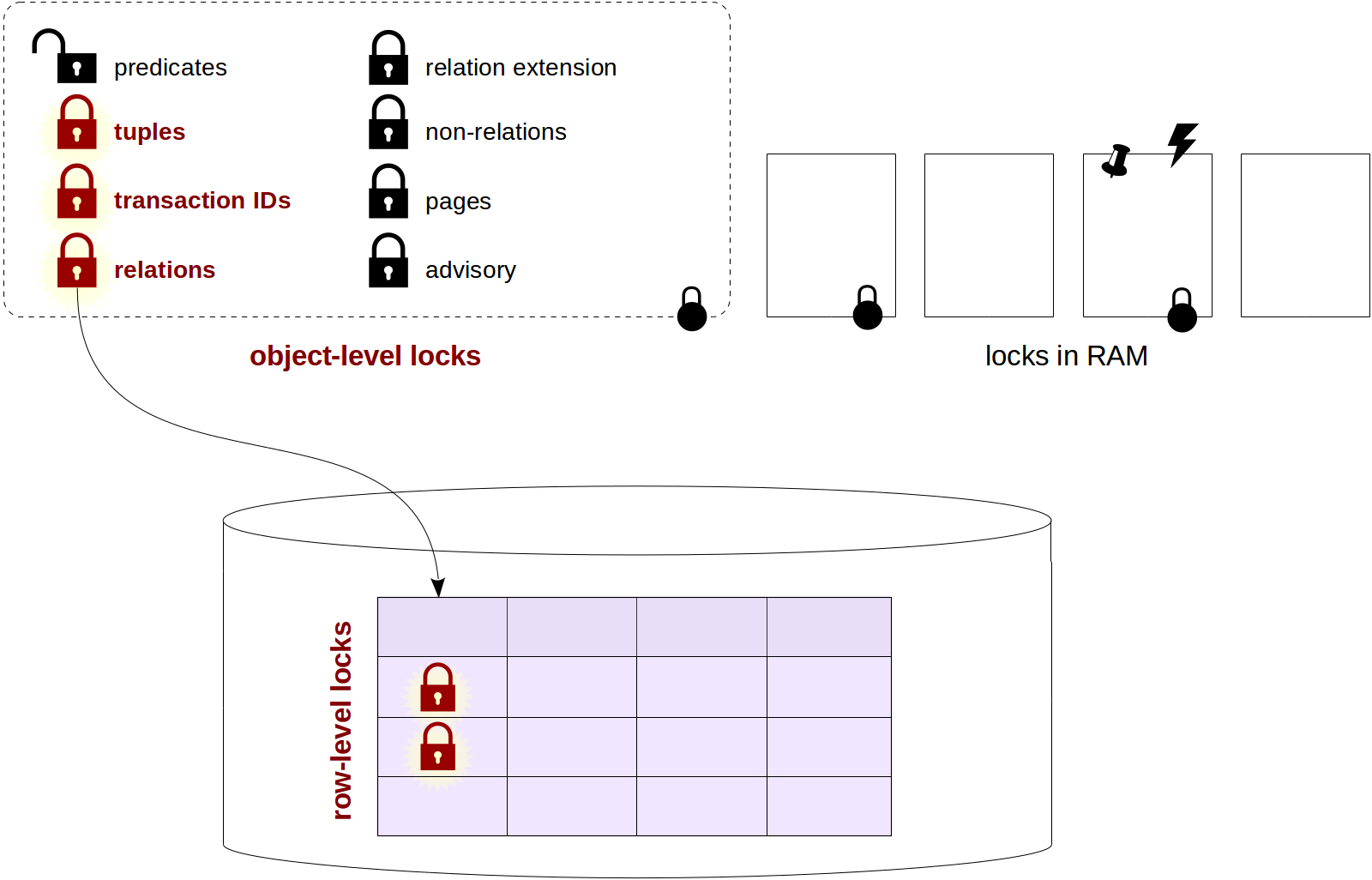
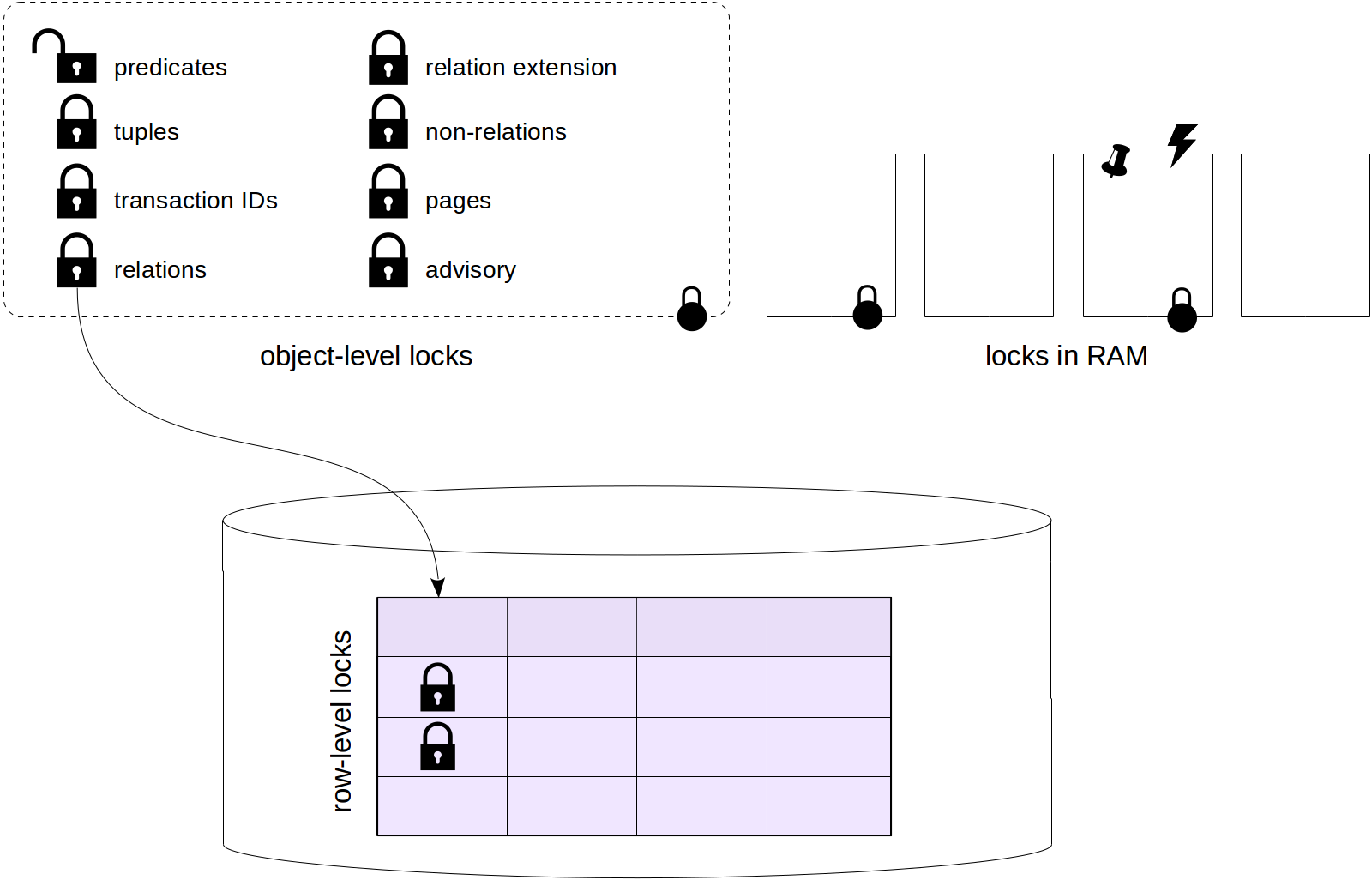
The previous series addressed
isolation and multiversion concurrency control, and now we start a new series:
on write-ahead logging. To remind you, the material is based on training courses on administration that Pavel
pluzanov and I are creating (mostly
in Russian, although one course is available
in English), but does not repeat them verbatim and is intended for careful reading and self-experimenting.
This series will consist of four parts:
Many thanks to Elena Indrupskaya for the translation of these articles into English.
Why do we need write-ahead logging?
Part of the data that a DBMS works with is stored in RAM and gets written to disk (or other nonvolatile storage) asynchronously, i. e., writes are postponed for some time. The more infrequently this happens the less is the input/output and the faster the system operates.
But what will happen in case of failure, for example, power outage or an error in the code of the DBMS or operating system? All the contents of RAM will be lost, and only data written to disk will survive (disks are not immune to certain failures either, and only a backup copy can help if data on disk are affected). In general, it is possible to organize input/output in such a way that data on disk are always consistent, but this is complicated and not that much efficient (to my knowledge, only Firebird chose this option).
Usually, and specifically in PostgreSQL, data written to disk appear to be inconsistent, and when recovering after failure, special actions are required to restore data consistency. Write-ahead logging (WAL) is just a feature that makes it possible.