Вот что будет, если ударить по стеклянным очкам молотком, но про это позже
Чуть больше полугода назад меня вдруг пробило на хорошие очки. Я начал задавать одинаковые тупые вопросы и получать разные ответы. Кого о чём не спросишь — их технология лучшая в мире. Правда, после слов «обоснуйте, пожалуйста», начинаются проблемы с пруфами. В итоге дорога приключений привела меня довольно далеко.
Значит, два важных момента. Первый: оказывается, надо делать полную коррекцию, частичная — в большинстве случаев зло. Доказательство «в Европе уже давно так не делают» меня не устроило, поэтому пришлось копать исследования. Второй момент — долбанный светофильтр «для компьютера», отсекающий синий, всё же нужен. Но только, как мне кажется, не для компьютера. Тоже нашлись результаты, но на животных.

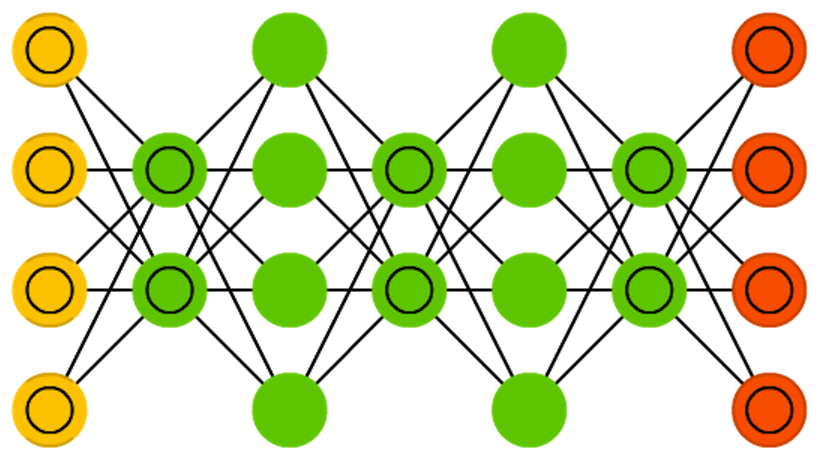
 Здравствуй, Хабр! Цикл статей по инструментам для обучения нейронных сетей продолжается обзором популярного фреймворка Tensorflow.
Здравствуй, Хабр! Цикл статей по инструментам для обучения нейронных сетей продолжается обзором популярного фреймворка Tensorflow.