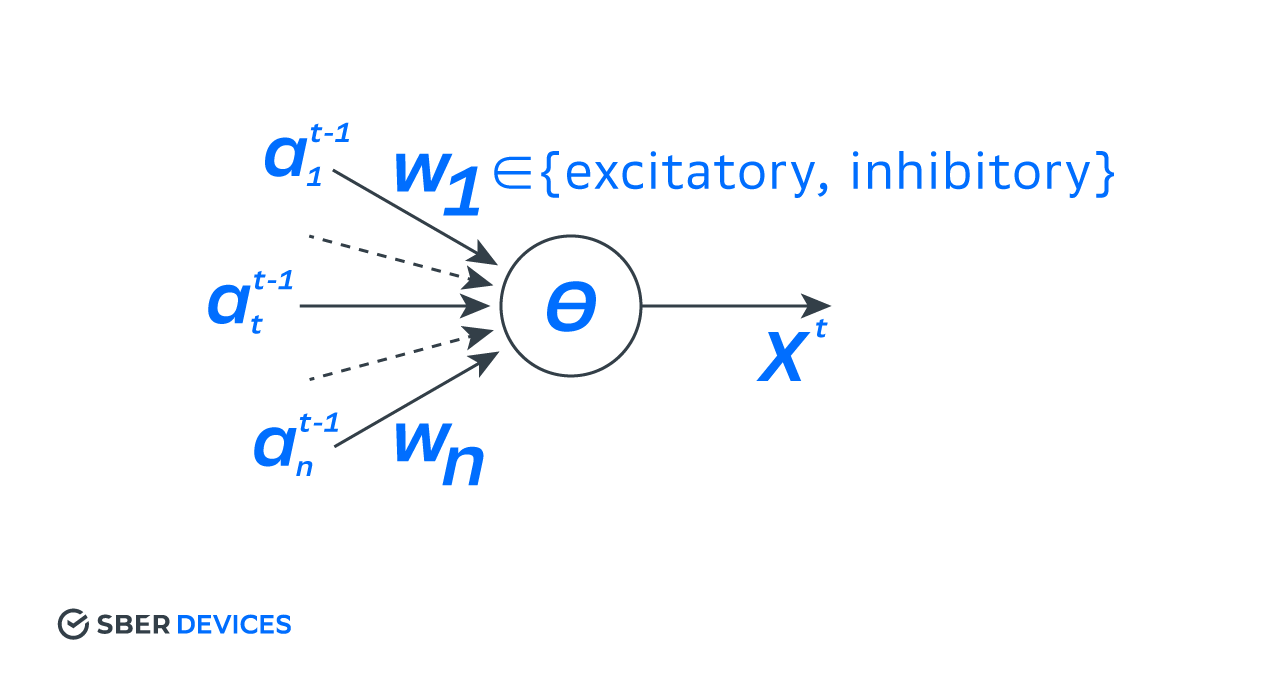
 Первая модель искусственного нейрона Мак-Каллока-Питтса
Первая модель искусственного нейрона Мак-Каллока-Питтса
Сейчас один из самых популярных инструментов искусственного интеллекта — это нейронные сети. Само название намекает на то, что речь идёт о некотором аналоге естественных нейронов и синаптических связей в мозгу. Отсюда вытекает распространённое ошибочное предположение, что нейронные сети являются точной копией своего биологического прототипа. Конечно же, это не так, а точнее не совсем так: учёные действительно работают над созданием импульсных нейронных сетей, предназначенных для максимально достоверной симуляции процессов, происходящих в нервной ткани, но обычно искусственный нейронные сети довольно сильно отличаются от своих биологических прародителей. Революция глубокого обучения произошла благодаря моделям, похожим на мозг примерно в той мере, в которой самолёты похожи на птиц. И всё-таки у истоков создания этих моделей стояли попытки учёных три четверти века назад постичь принципы работы нервной системы живых существ.
Один из «дедушек» современных нейросетей — это перцептрон Розенблатта, представленный публике в конце 1950-х, но его появлению предшествовали другие, менее известные попытки описать принципы, по которым могла бы работать «думающая» машина, подобная мозгу. К ним относятся исследования Уолтера Питтса и Уоррена Мак-Каллока. Их модель, увидевшая свет в 1943-м году в
статье под названием «Логическое исчисление идей, относящихся к нервной активности», была весьма новаторским изобретением. И за ней стоит довольно занятная история. Кто такие были эти товарищи, приложившие руку к созданию модели? Чопорные учёные в очках с роговой оправой или, может, аналог современных хипстеров из thinktank’ов?











 При работе с большими объемами данных иногда может остро встать проблема нехватки места на дисках. Одним из способов решения данной проблемы является сжатие, благодаря которому, на том же оборудовании, можно себе позволить увеличить объемы хранения. В данной статье мы рассмотрим, как работает сжатие данных в Apache Ignite. В статье будут описаны только реализованные внутри продукта способы сжатия на диске. Другие способы сжатия данных (по сети, в памяти) как реализованные, так и нет останутся за рамками.
При работе с большими объемами данных иногда может остро встать проблема нехватки места на дисках. Одним из способов решения данной проблемы является сжатие, благодаря которому, на том же оборудовании, можно себе позволить увеличить объемы хранения. В данной статье мы рассмотрим, как работает сжатие данных в Apache Ignite. В статье будут описаны только реализованные внутри продукта способы сжатия на диске. Другие способы сжатия данных (по сети, в памяти) как реализованные, так и нет останутся за рамками.{kind=link}