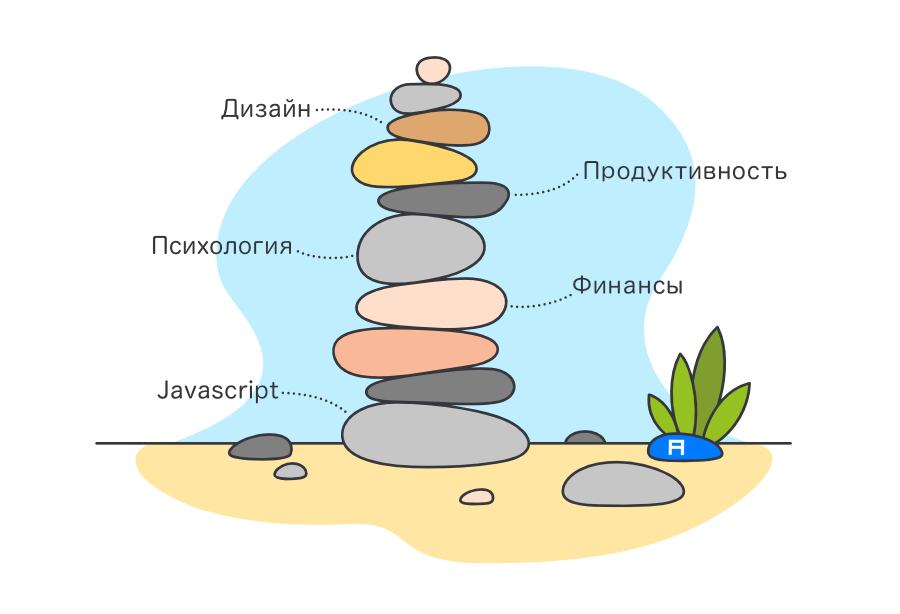
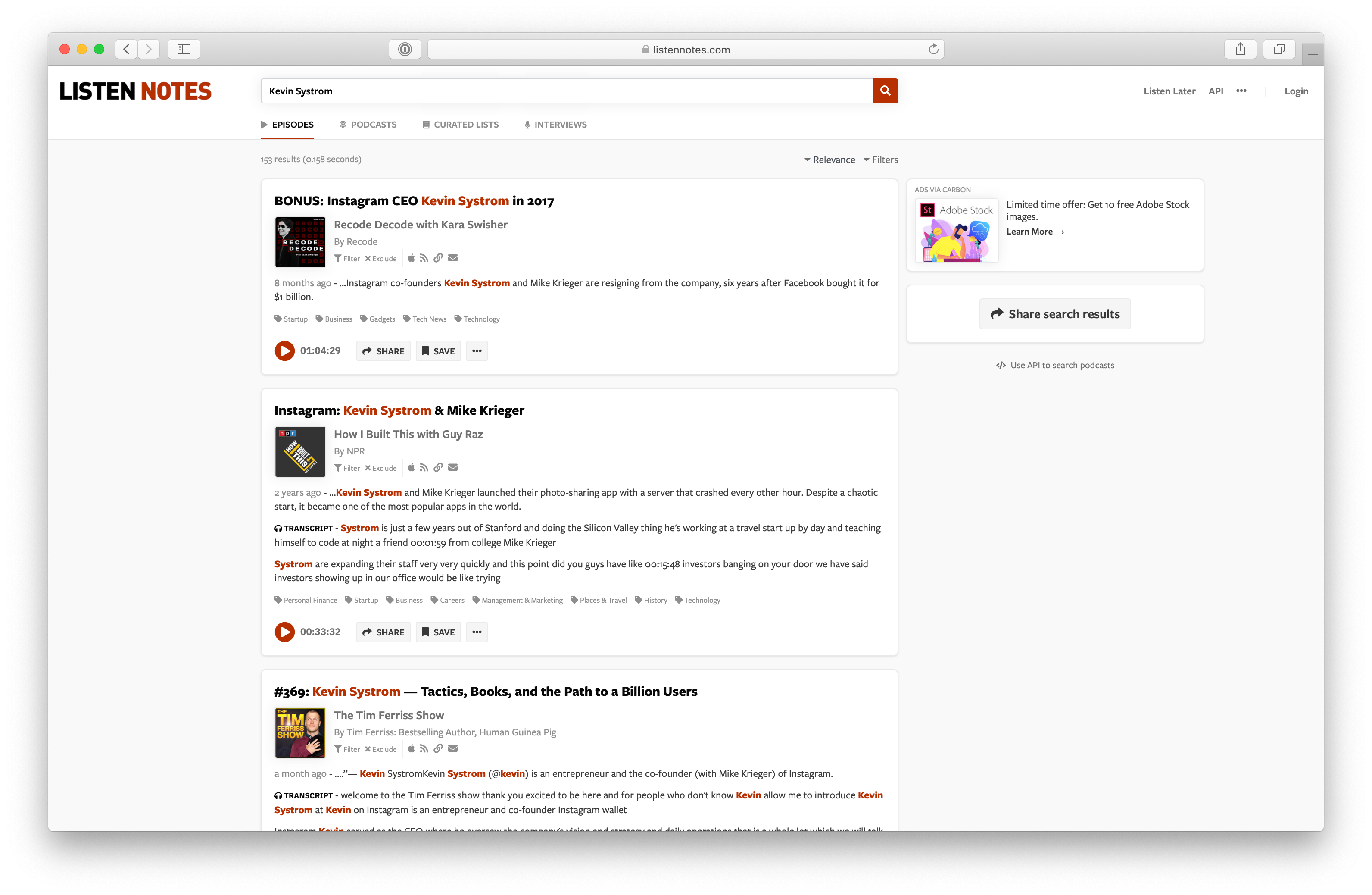
Я уже некоторое время играюсь с новой моделью GPT-3 от OpenAI. Когда я только получил доступ к бета-версии, то первое, что мне пришло в голову, было: насколько GPT-3 похожа на человека? Близка ли она к тому, чтобы пройти тест Тьюринга?
Позвольте объяснить, как я генерировал эти диалоги. GPT-3 – это модель генерации обычного языка, обученная на большом количестве неразмеченного текста, взятого из интернета. Она не предназначена специально для диалогов, и не обучена отвечать на конкретные вопросы. Она умеет только одно – получив на вход текст, догадаться, что идёт далее.
Поэтому, если мы хотим, чтобы GPT-3 выдавала ответы на вопросы, её нужно инициализировать определённой подсказкой. Я использую такую подсказку для инициализации всех сессий вопросов и ответов:
Как это работает
Позвольте объяснить, как я генерировал эти диалоги. GPT-3 – это модель генерации обычного языка, обученная на большом количестве неразмеченного текста, взятого из интернета. Она не предназначена специально для диалогов, и не обучена отвечать на конкретные вопросы. Она умеет только одно – получив на вход текст, догадаться, что идёт далее.
Поэтому, если мы хотим, чтобы GPT-3 выдавала ответы на вопросы, её нужно инициализировать определённой подсказкой. Я использую такую подсказку для инициализации всех сессий вопросов и ответов:







 Существует стереотип, что «IT»-шник должен сидеть в полумраке, освещаемый лишь светом монитора. Не знаю как вам, а мне всегда было комфортнее при ярком освещении. Сначала это было 3x100W обычных лампочек, потом 250W люминесцентных ламп, после последнего переезда — одна 500W галогенка… Но этого все-же было недостаточно. Всегда хотелось иметь такое освещение, чтобы не хотелось свет сделать ярче. О создании такой люстры я сейчас и расскажу.
Существует стереотип, что «IT»-шник должен сидеть в полумраке, освещаемый лишь светом монитора. Не знаю как вам, а мне всегда было комфортнее при ярком освещении. Сначала это было 3x100W обычных лампочек, потом 250W люминесцентных ламп, после последнего переезда — одна 500W галогенка… Но этого все-же было недостаточно. Всегда хотелось иметь такое освещение, чтобы не хотелось свет сделать ярче. О создании такой люстры я сейчас и расскажу.