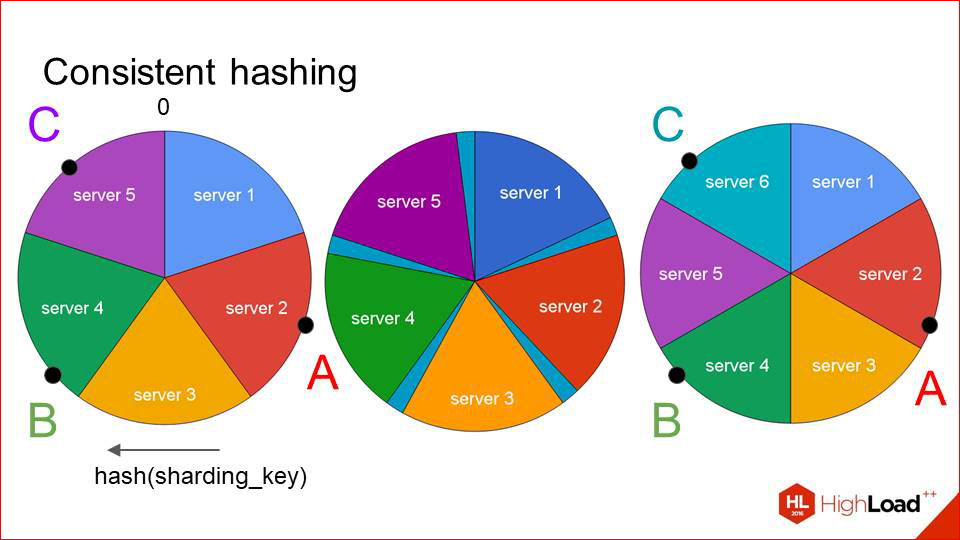
В классических реляционных базах данных бинарная связь кортежей основана на использовании ключей: первичных и внешних. При этом, интерпретация этой связи осуществляется за пределами логической структуры базы данных, где она (интерпретация) может иметь достаточно произвольный характер. Естественно, в рамках ограничений, предписанных реляционной моделью.
В объектной же парадигме для реализации связи объектов используют их идентификаторы. Причем, если связи объектов придать строгую симметричную форму: в виде пары прямая | обратная ссылка, то это позволяет практически полностью заменить Select естественной навигацией по ссылкам. Но что не менее важно, симметричная форма делает связь объектов полноправным и самостоятельным элементом логической структуры базы данных, обладающим собственным поведением и функциональной зависимостью от других действующих связей.
Настоящая статья посвящена рассмотрению самых различных поведенческих аспектов связи объектов, реализация которых позволяет интегрировать значительную часть бизнес-логики приложения непосредственно в логическую структуру базы данных, тем самым избавляя разработчика от рутины кодирования.
В объектной же парадигме для реализации связи объектов используют их идентификаторы. Причем, если связи объектов придать строгую симметричную форму: в виде пары прямая | обратная ссылка, то это позволяет практически полностью заменить Select естественной навигацией по ссылкам. Но что не менее важно, симметричная форма делает связь объектов полноправным и самостоятельным элементом логической структуры базы данных, обладающим собственным поведением и функциональной зависимостью от других действующих связей.
Настоящая статья посвящена рассмотрению самых различных поведенческих аспектов связи объектов, реализация которых позволяет интегрировать значительную часть бизнес-логики приложения непосредственно в логическую структуру базы данных, тем самым избавляя разработчика от рутины кодирования.