Хотя метод был разработан и представлен в 2001 году Полом Виолой и Майклом Джонсом [1, 2], он до сих пор на момент написания моего поста является основополагающим для поиска объектов на изображении в реальном времени [2]. По следам топика хабраюзера Indalo о данном методе, я попытался сам написать программу, которая распознает эмоцию на моём лице, но, к сожалению, не увидел на Хабре недостающей теории и описания работы некоторых алгоритмов, кроме указания их названий. Я решил собрать всё воедино, в одном месте. Сразу скажу, что свою программу успешно написал по данным алгоритмам. Как получилось рассказать о них ниже, решать Вам, уважаемые Хабрачитатели!

User
Минимальная Arduino своими руками
4 min
Arduino — это хорошо, когда хочется быстро реализовать идею, не заморачиваясь мелочами. Но когда идея проверена, лишняя функциональность начинает просто мешать.
Собирая робота на гусеничном шасси, я столкнулся с тем, что бутерброд из Arduino + MotorShield + Sensor Shield плюс ко всему аккумулятор и прочие компоненты обросли проводами и стали с трудом помещаться на не самом крошечном шасси. Городить еще кучу шилдов, чтобы избавиться от лишних проводов не хотелось.
Появилась идея избавиться от всего, что в Arduino не требуется в готовом девайсе. Попутно хотелось снизить стоимость робота.
Многих интересующихся электроникой отпугивает еще и стоимость Arduino в магазинах. С ebay и китайских магазинов посылка идет долго, изобретательский пыл успевает остыть, поэтому приобретение откладывается «на потом», «когда сын подрастет». Поэтому я решил собрать Arduino-совместимую плату из деталей, которые всегда можно купить в городе.
В итоге я получил Arduino-совместимую плату, стоимостью в 210 рублей на макетной плате и в ~270 рублей в готовом для наращивания функционала виде.

«Minimalist Arduino»
С нуля до полной готовности собирается с дешевым 40Вт паяльником за 1 выходной без каких-то особых навыков.
Собирая робота на гусеничном шасси, я столкнулся с тем, что бутерброд из Arduino + MotorShield + Sensor Shield плюс ко всему аккумулятор и прочие компоненты обросли проводами и стали с трудом помещаться на не самом крошечном шасси. Городить еще кучу шилдов, чтобы избавиться от лишних проводов не хотелось.
Появилась идея избавиться от всего, что в Arduino не требуется в готовом девайсе. Попутно хотелось снизить стоимость робота.
Многих интересующихся электроникой отпугивает еще и стоимость Arduino в магазинах. С ebay и китайских магазинов посылка идет долго, изобретательский пыл успевает остыть, поэтому приобретение откладывается «на потом», «когда сын подрастет». Поэтому я решил собрать Arduino-совместимую плату из деталей, которые всегда можно купить в городе.
В итоге я получил Arduino-совместимую плату, стоимостью в 210 рублей на макетной плате и в ~270 рублей в готовом для наращивания функционала виде.
«Minimalist Arduino»
С нуля до полной готовности собирается с дешевым 40Вт паяльником за 1 выходной без каких-то особых навыков.
Упрощение жизни разработчика с помощью сторонних сервисов
3 min
Представляю скромную подборку сервисов, которые ускоряют экономят время разработчику и/или ресурсы сервера. Здесь не будет подробных обзоров, только список с кратким описанием и ссылками. Также, я не претендую на свежесть ресурсов, поэтому кому-то перечисленный список покажется слишком очевидным и известным всем.
Буду рад включить ссылки и описания, предложенные в комментариях.
Google Fusion Tables
Позволяет развернуть реляционную базу данных на серверах гугла с обращениями с помощью библиотеки Visualization или JSONP.
Статья на хабре: habrahabr.ru/blogs/webdev/116035
Ссылка: www.google.com/fusiontables/Home
Минусы: количество обращений в секунду равно пяти с одно IP адреса и столько же при обращении с аккаунта (используя авторизацию). То есть развернуть сайт с хорошей посещаемостью и работать с сервисом с помощью сервера не получится. Стоимость увеличения лимита — от 10 тысяч долларов в год (см. Maps API Premier). Кроме того, отсутствуют джойны, которые заменяются представлениями (view), создаваемыми через интерфейс.
Буду рад включить ссылки и описания, предложенные в комментариях.
Google Fusion Tables
Позволяет развернуть реляционную базу данных на серверах гугла с обращениями с помощью библиотеки Visualization или JSONP.
Статья на хабре: habrahabr.ru/blogs/webdev/116035
Ссылка: www.google.com/fusiontables/Home
Минусы: количество обращений в секунду равно пяти с одно IP адреса и столько же при обращении с аккаунта (используя авторизацию). То есть развернуть сайт с хорошей посещаемостью и работать с сервисом с помощью сервера не получится. Стоимость увеличения лимита — от 10 тысяч долларов в год (см. Maps API Premier). Кроме того, отсутствуют джойны, которые заменяются представлениями (view), создаваемыми через интерфейс.
Хочется взять и расстрелять, или ликбез о том, почему не стоит использовать make install
5 min
| К написанию сей заметки меня сподвигло то, что я устал делать развёрнутые замечания на эту тему в комментариях к статьям, где в качестве части инструкции по сборке и настройке чего-либо для конкретного дистра предлагают выполнить make install. |
 Суть сводится к тому, что эту команду в виде «make install» или «sudo make install» использовать в современных дистрибутивах нельзя.
Суть сводится к тому, что эту команду в виде «make install» или «sudo make install» использовать в современных дистрибутивах нельзя. Но ведь авторы программ в руководствах по установке пишут, что нужно использовать эту команду, возможно, скажете вы. Да, пишут. Но это лишь означает, что они не знают, какой у вас дистрибутив, и дистрибутив ли это вообще, может, вы вступили в секту и об
Простой чат с помощью Channel API на Google App Engine для Python
10 min
Представляю вашему вниманию вольный перевод статьи под названием "A Simple Chat using the Channel API". Так же я решил немного добавить своего кода.
Сегодня мы представляем вам новую статью для Google App Engine посвященную Сhannel API, которое появилось в декабре 2010 года в релизе 1.4. С этого момента стала возможной отправка сообщений напрямую с сервера клиенту и обратно без использования polling.
Поэтому стало достаточно просто реализовать чат на Google App Engine. Процесс реализации описан под катом.
Сегодня мы представляем вам новую статью для Google App Engine посвященную Сhannel API, которое появилось в декабре 2010 года в релизе 1.4. С этого момента стала возможной отправка сообщений напрямую с сервера клиенту и обратно без использования polling.
Поэтому стало достаточно просто реализовать чат на Google App Engine. Процесс реализации описан под катом.
W3C опубликовала спецификацию HTML5 для веб-разработчиков
1 min
 Ранее в этом году WHATWG выпустили издание для веб-разработчиков из спецификации HTML5. Теперь, чтобы не отстать, HTML Working Group W3C опубликовали проект с более читабельной спецификацией HTML5: Edition for Web Authors
Ранее в этом году WHATWG выпустили издание для веб-разработчиков из спецификации HTML5. Теперь, чтобы не отстать, HTML Working Group W3C опубликовали проект с более читабельной спецификацией HTML5: Edition for Web AuthorsW3C версия написана более технически, чем версия WHATWG, но по крайней мере вы можете прочитать HTML5 спецификацию без заметок о соответствии критериям браузеров.
Дерево ван Эмде Боаса
6 min
 Всем доброго времени суток!
Всем доброго времени суток!Сегодня я расскажу вам об одной интересной структуре данных, про которую слышали лишь немногие и про которую очень незаслуженно мало написано в рунете, да и в англоязычном информации, в общем-то, тоже негусто. Решено было исправить ситуацию и поделиться с общественностью в доступной форме этой достаточно экзотической структурой данных.
Дерево ван Эмде Боаса (van Emde Boas tree) — ассоциативный массив, который позволяет хранить целые числа в диапазоне [0; U), где U = 2k, проще говоря, числа, состоящие не более чем из k бит. Казалось бы, зачем нужно еще какое-то дерево, да еще позволяющее хранить только целые числа, когда существует множество различных сбалансриованных двоичных деревьев поиска, позволяющих выполнять операции вставки, удаления и прочие за O(log n), где n — количество элементов в дереве?
Главная особенность этой структуры — выполнение всех операций за время O(log(log(U))) независимо от количества хранящихся в ней элементов.
Введение в технику оптимизации циклов
4 min
Большая часть времени исполнения программы приходится на циклы: это могут быть вычисления, прием и обработка информации и т.д. Правильное применение техник оптимизации циклов позволит увеличить скорость работы программы. Но прежде, чем приступать к оптимизациям необходимо выделить «узкие» места программы и попытаться найти причины падения быстродействия.
Производительный и читабельный XSLT: сборник советов
7 min
В моей практике чаще всего в качестве шаблонизатора используется именно XSLT. Я не буду рассуждать о том, почему так происходит — о преимуществах данной технологии написано вполне достаточно. Но ещё больше написано о её недостатках. Считается, что XSLT является слишком многословным и тяжёлым для чтения, а также не самым производительным. В этой статье я постараюсь собрать несколько советов по улучшению качества XSLT-кода с точки зрения читабельности и выразительности. Некоторые из них также позволят XSLT работать несколько быстрее.
Многие «проблемы» XSLT связаны с тем, что мы слишком часто пытаемся писать на нём в процедурном стиле. Мы постоянно пытаемся сделать из него Smarty, но упираемся в один простой факт — XSLT является декларативным языком, как бы необычно это для нас не выглядело.
Например, мы пытаемся использовать именованные шаблоны, воспринимая их как процедуры, выводящие данные в определённом формате:
Наверное, многие программисты именно так написали свой первый шаблон. И он неплохо решает свою задачу. Декларативный XSLT предлагает немного другой подход:
Разница совсем не велика. Дело вкуса и стиля программирования. Давайте посмотрим, как шаблон будет использоваться в дальнейшем.
Именованные шаблоны
Многие «проблемы» XSLT связаны с тем, что мы слишком часто пытаемся писать на нём в процедурном стиле. Мы постоянно пытаемся сделать из него Smarty, но упираемся в один простой факт — XSLT является декларативным языком, как бы необычно это для нас не выглядело.
Например, мы пытаемся использовать именованные шаблоны, воспринимая их как процедуры, выводящие данные в определённом формате:
<xsl:template name="CreateItemLink">
<xsl:param name="item"/>
<a href="/item/?id={$item/id}">
<xsl:value-of select="$item/name"/>
</a><br/>
</xsl:template>
* This source code was highlighted with Source Code Highlighter.Наверное, многие программисты именно так написали свой первый шаблон. И он неплохо решает свою задачу. Декларативный XSLT предлагает немного другой подход:
<xsl:template match="item">
<a href="/item/?id={id}">
<xsl:value-of select="name"/>
</a><br/>
</xsl:template>
* This source code was highlighted with Source Code Highlighter.Разница совсем не велика. Дело вкуса и стиля программирования. Давайте посмотрим, как шаблон будет использоваться в дальнейшем.
Операционная система реального времени QNX: Знакомство
6 min
Так сложилось, что моя деятельность связана с операционной системой реального времени (ОСРВ) QNX. Уже несколько лет занимаюсь разработкой как под эту ОС, так и некоторых частей самой системы. Обратил внимание на то, что поиск на хабре выводит немного результатов по запросу QNX, однако, мне кажется, что эта ОСРВ может быть интересна не только специалистам по встраиваемым и высоконадёжным системам, но и более широкой публике. Не секрет, что планшетный компьютер BlackBerry PlayBook производства компании RIM основан на QNX и имеет популярность и у нас.
ОСРВ QNX это не клон или дистрибутив Linux или ответвление какой-то другой UNIX-подобной системы. QNX самостоятельная UNIX-подобная операционная система реального времени, основанная на микроядре и передаче сообщений. Современные версии QNX имеют поддержку стандартов POSIX (и сертифицированны по ним). Первая версия QNX вышла в далёком 1981 году. С тех пор утекло достаточно много времени и поколения QNX сменяли друг друга: QNX2, QNX4 и, наконец, QNX 6 (или QNX Neutrino). Старичок QNX2 и сейчас ещё используется, хотя его расцвет пришёлся на 80-е годы прошлого столетия. Надёжная и более современная ОСРВ QNX4 могла конкурировать на десктопе с Windows в середине 90-х
Немного о QNX
ОСРВ QNX это не клон или дистрибутив Linux или ответвление какой-то другой UNIX-подобной системы. QNX самостоятельная UNIX-подобная операционная система реального времени, основанная на микроядре и передаче сообщений. Современные версии QNX имеют поддержку стандартов POSIX (и сертифицированны по ним). Первая версия QNX вышла в далёком 1981 году. С тех пор утекло достаточно много времени и поколения QNX сменяли друг друга: QNX2, QNX4 и, наконец, QNX 6 (или QNX Neutrino). Старичок QNX2 и сейчас ещё используется, хотя его расцвет пришёлся на 80-е годы прошлого столетия. Надёжная и более современная ОСРВ QNX4 могла конкурировать на десктопе с Windows в середине 90-х
Библиотека сериализации в JSON для Erlang
3 min
Поскольку мы очень активно используем opensource решения в своей деятельности, вполне естественным является и обратный процесс — публикация под свободными лицензиями библиотек и компонент, созданных в нашей компании.
В этот раз мы публикуем библиотеку сериализации в JSON типов данных Erlang, авторства si14 под BSD 2-clause license. Те проекты, для которых написана эта библиотека, ещё не готовы (ждите анонсов к осени), но библиотека уже стала вполне самостоятельной и может применяться в множестве других случаев. Традиционно, рассчитываем на кооперацию в совершенствовании, с интересом услышим о применении в других проектах.
В этот раз мы публикуем библиотеку сериализации в JSON типов данных Erlang, авторства si14 под BSD 2-clause license. Те проекты, для которых написана эта библиотека, ещё не готовы (ждите анонсов к осени), но библиотека уже стала вполне самостоятельной и может применяться в множестве других случаев. Традиционно, рассчитываем на кооперацию в совершенствовании, с интересом услышим о применении в других проектах.
В дебри Erlang'а
В отличие от многих динамических языков, в Erlang'е есть опциональные аннотации типов для функций и record'ов. На текущий момент они используются минимум 3 утилитами: edoc (формирует документацию из исходников; пример получаемой документации можно увидеть, например, здесь), что более важно, dialyzer (анализирует существующую информацию о типах и сообщает об ошибках несоответствия типов, в том числе несоответствия декларируемого и выведенного типов) и PropEr (система автоматической генерации тестов на основании информации о типах и декларативно задаваемых свойств функций). Использование этих деклараций стало правилом хорошего тона, поэтому почти все качественные проекты на Erlang'е имеют их. Нельзя ли использовать информацию о типах где-либо ещё?JANE
В процессе разработки одного из проектов возникла идея: почему бы не использовать существующую информацию о типах прямо в JSИспользование графа, как основы для создания рубрикатора
6 min
Определения
В этой статье я опишу способы создания, и использования рубрикаторов, в основе которых лежит структура графа.
Рубрикатор, категоризатор, каталог категорий, предметный указатель, индекс. Для удобства будем считать, что все эти термины описывают примерно одно и то же. А там, где будут существенные отличия, мы будем явно на них указывать.
Информационный элемент – чаще всего файл, но в общем случае любая информация представленная как единое целое.
Введение
Рубрикаторы используются для решения самых разнообразных задач:
- Для ускорения поиска и облегчения навигации по большим массивам информации.
- Для пометки (тегирования) информации с целью организации выборок по определенным рубрикам
- Для сортировки информации по:
областям знаний (физика, математика, биология)
способам использования (Книги — читать, музыка — слушать, фильмы — смотреть)
принадлежности (папки мои и общие документы)
важности (папки inbox и spam) и т.п.
Генерация аналитических поверхностей на примере карт. Часть 2
3 min
Введение
Если у Вас есть данные с неравномерной сеткой, важнейшим этапом в их обработке является преобразование в набор данных с равномерной сеткой. Данное преобразование необходимо для компьютерного моделирования в реальном масштабе времени или его приближении. Получение высоты непосредственно из неравномерной сетки является ресурсоемкой операцией.
PhantomJS: Webkit в консоли
2 min

PhantomJS это все плюшки WebKit из консоли с управлением на JS и поддержкой различных стандартов и технологий: DOM, CSS, JSON, Canvas и SVG.
Внутри несколько примеров использования
Масштабируемые JavaScript приложения
22 min
Более месяца назад в статье FAQ по JavaScript: задавайте вопросы был задан вопрос «Подскажите примеры хорошего подхода организации JS кода к сайту на достаточно высоком уровне. Как можно узнать подробнее практики реализации например gmail?».
Пришло время ответить на данный вопрос. Я немного затянул т.к. хотел рассказать доклад на одноименную тему на Я.Субботнике. Доклад был очень коротким многие важные моменты пришлось выкинуть. Статья — более-менее полная версия.
Эта статья о том, как сделать крупное веб-приложение расширяемым и поддерживаемым: архитектура, подходы, правила.
Пришло время ответить на данный вопрос. Я немного затянул т.к. хотел рассказать доклад на одноименную тему на Я.Субботнике. Доклад был очень коротким многие важные моменты пришлось выкинуть. Статья — более-менее полная версия.
Эта статья о том, как сделать крупное веб-приложение расширяемым и поддерживаемым: архитектура, подходы, правила.
Gearman – фреймворк для распределения задач, введение
6 min

В этой статье, мне бы хотелось рассмотреть один из необычных способов оптимизации приложения, а именно использование проекта Gearman для распределения задач. Gearman является фреймворком для построения таких систем. Примеров кода в статье нет, статья больше вводная, хоть и содержит в себе достаточно практической информации.
10 способов улучшить свои навыки программирования
4 min
Translation
1. Выучить новый язык программирования
Изучение нового языка программирования разовьет новые способы мышления, особенно если новый язык программирования использует парадигмы, с которыми Вы еще не знакомы. Многие из приобретенных способов мышления могут быть применены к языкам, которые уже знаете. Возможно, вы даже полюбите новый для Вас язык программирования настолько, что начнёте использовать его для серьёзных проектов.
Среди языков программирования отличный познавательный эффект и наверстывание опыта дают: Lisp (или Scheme), Форт, PostScript или Factor (стековые языки программирования), Haskell (строго типизированный, чистый функциональный язык) либо OCaml (объектно-ориентированный язык функционального программирования), Пролог (логическое программирование), Erlang (отличные паралельные вычисления).
Создание своих сложных стилей для LaTeX
6 min
История вопроса
Если вы регулярно создаёте в ТеХ'е единообразные документы, то создание своего стиля может заметно ускорить работу.
Моими регулярными документами является создание листочков с задачами для школьников. Готовые они выглядят следующим образом: PNG или PDF (а также так, так или так)
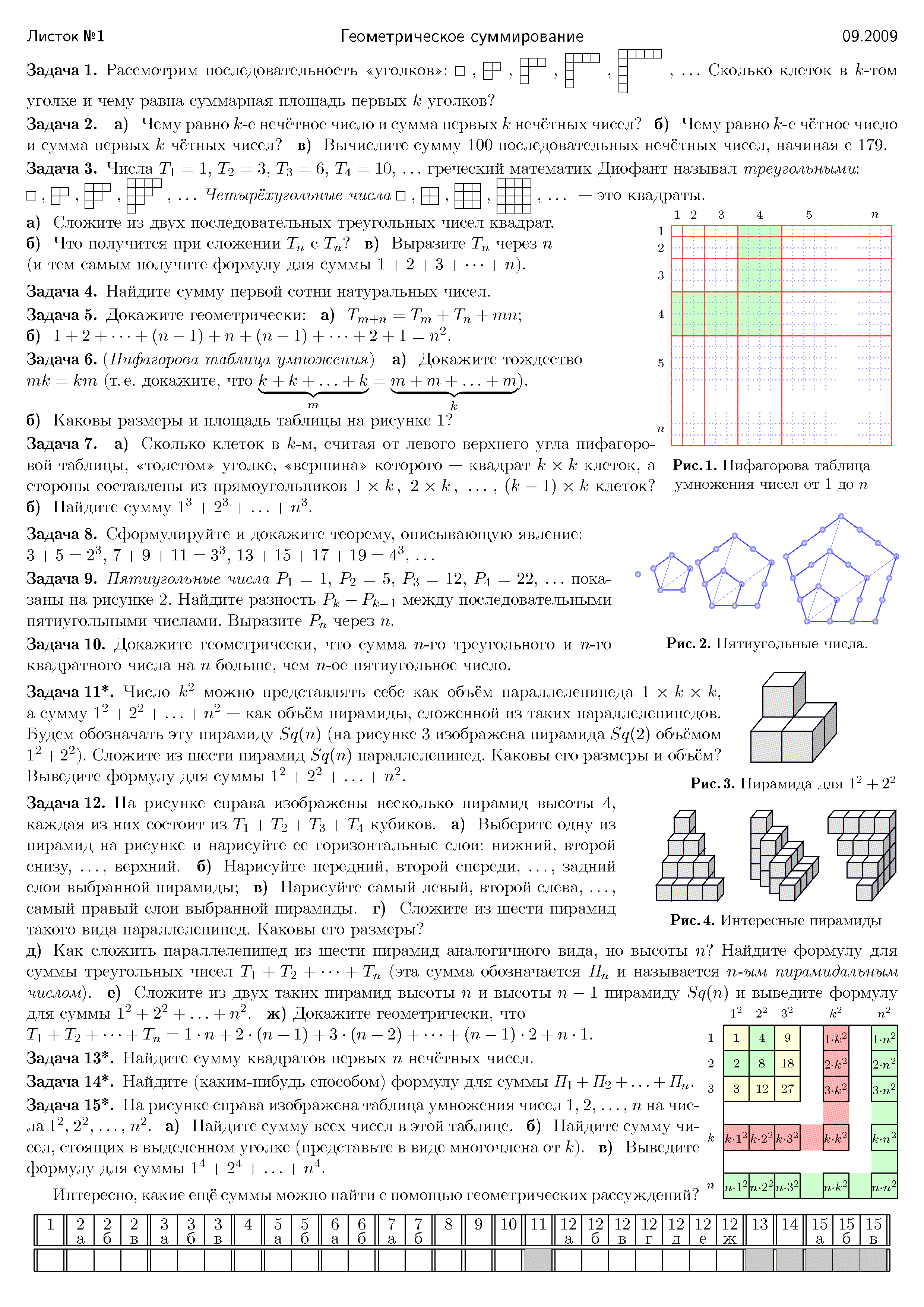{kind=link}
Практически всё оформление здесь (а также отдельная табличка для результатов) создаётся автоматически.
(если это кому-то нужно, то могу выдать пакет с документацией и примерами использования)
Разными «трюками» при создании своего стиля я бы и хотел поделиться.
Если вы совсем не в теме про создание своих команд, то лучше всего почитать Львовского или чего-нибудь в этом духе.
Теория чисел in TeX-way
4 min
 Демонстрируем некоторые особенности написания TeX-макросов, встраивая в TeX калькулятор теоретико-числовых функций.
Демонстрируем некоторые особенности написания TeX-макросов, встраивая в TeX калькулятор теоретико-числовых функций. Постановка задачи
Время от времени мне приходится набирать очередной текст, сопровождаемый примерами вычисления теоретико-числовых функций: функция Эйлера φ, функция делителей τ, функция Кармайкла λ. Раньше это делалось так: запускаем любимый калькулятор (мой выбор — PARI/GP), в нем все считаем и копируем выкладки в ТеХ. Изменились исходные данные — снова в калькулятор и обратно. Много возни, много шансов забыть заменить какой-то промежуточный результат. Да и просто мышкой махать надоедает. Хочется автоматизировать этот процесс хотя бы для самых распространенных функций, чтобы можно было написать
$\phi(1001)=\Phi(1001)$=720")