TL; DR
Поднимаем кластер для обслуживания веб-приложений без записи состояния (stateless web applications) вместе с ingress, letsencrypt, не используя средства автоматизации вроде kubespray, kubeadm и любых других.
Время на чтение: ~45-60 минут, на воспроизведение действий: от 3-х часов.
Преамбула
На написание статьи меня сподвигла потребность в своём собственном кластере kubernetes для экспериментов. Автоматические решения установки и настройки, которые есть в открытом доступе, не работали в моем случае, так как я использовал не-мейнстримовые дистрибутивы Linux. Плотная работа с kubernetes в IPONWEB стимулирует иметь такую площадку, решая свои задачи в комфортном ключе, в том числе и для домашних проектов.
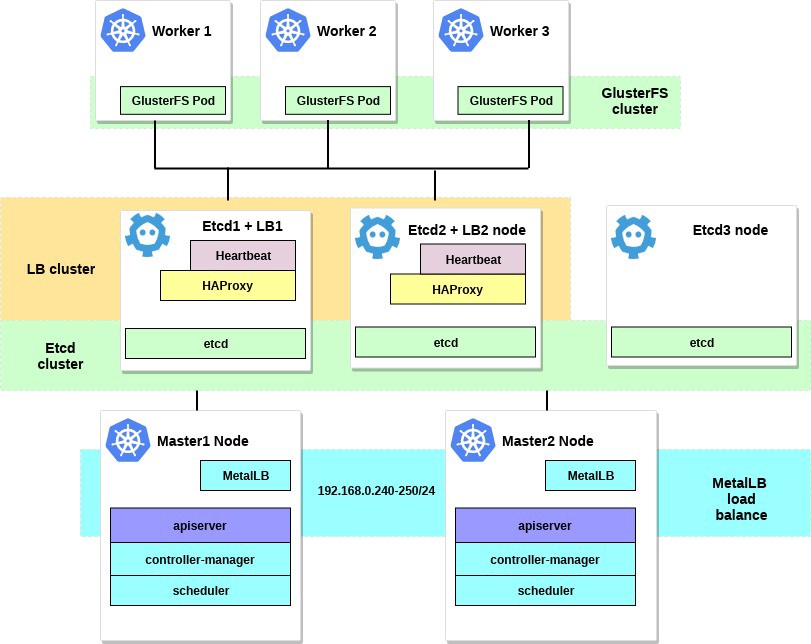
Компоненты
В статье будут фигурировать следующие компоненты:
— Ваш любимый Linux — я использовал Gentoo (node-1: systemd / node-2: openrc), Ubuntu 18.04.1.
— Kubernetes Server — kube-apiserver, kube-controller-manager, kube-scheduler, kubelet, kube-proxy.
— Containerd + CNI Plugins (0.7.4) — для организации контейнеризации возьмем containerd + CNI вместо docker (хотя изначально вся конфигурация была поднята на docker, так что ничего не помешает использовать его в случае необходимости).
— CoreDNS — для организации service discovery компонентов, работающих внутри kubernetes кластера. Рекомендована версия не ниже 1.2.5, так как с этой версии появляется вменяемая поддержка работы coredns в качестве процесса, запущенного вне кластера.
— Flannel — для организации сетевого стека, общения подов и контейнеров между собой.
— Ваша любимая db.













 Даже поверхностное знание программы
Даже поверхностное знание программы 

