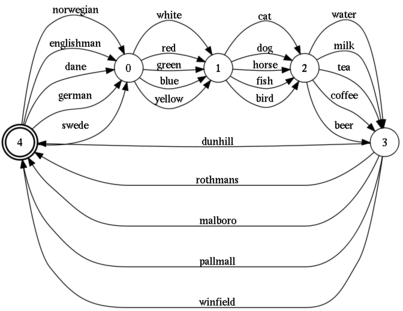
Многие сталкивались с головоломкой про пять разноцветных домов, в каждом из которых живет человек со своими любимыми животным, напитком и сигаретами. Эта загадка приписывается Эйнштейну, хотя прямых подтверждений этому нет. Полный текст этой головоломки есть на википедии.
Ее можно решить на бумаге или в уме, последовательно исключая неподходящие варианты. Однако, ее также можно решить более технично. Один из способов — написать программку на прологе. Но здесь я хочу ее решить используя более простые механизмы — регулярные выражения. А именно, перевести условия загадки на язык регекспов и свести задачу к поиску подходящей строки во всем допустимом наборе строк. Кстати, этот набор строк показан на рисунке.
Наивный Байесовский классификатор один из самых простых из алгоритмов классификации. Тем не менее, очень часто он работает не хуже, а то и лучше более сложных алгоритмов. Здесь я хочу поделиться кодом и описанием того, как это все работает.
И так, для примера возьму задачу определения пола по имени. Конечно, чтобы определить пол можно создать большой список имен с метками пола. Но этот список в любом случае будет неполон. Для того чтобы решить эту проблему, можно «натренировать» модель по маркированным именам.
Если интересует, прошу
Периодически на хабре проскакивают статьи о том, как написать программу для анализа морфологии. В основном авторы пользуются базами данных, либо стандартными структурами, такими как словари. Но это не всегда удобно. Во-первых, страдает скорость. Во-вторых, некоторые алгоритмы, такие как предсказание морфологии незнакомых слов, реализуются нетривиально.
Здесь я привожу версию, основанную на конечных автоматах, где попробую избежать данных проблем. Как это работает можно посмотреть здесь.
Есть хорошая статья Питера Норвига, в которой он рассказывает как написать спеллчекер в 20 строк кода. В этой статье он показывает как поисковые системы могут исправлять ошибки в запросах. И делает это довольно элегантно. Однако, у его подхода есть два серьезных недостатка. Во-первых, исправление более трех ошибок требует больших ресурсов. А гугл, кстати, неплохо справляется и с четырьмя ошибками. Во-вторых, нет возможности проверки связного текста.
Итак, хочется исправить эти проблемы. А именно, написать корректор коротких фраз или запросов, который:
умел бы выявлять три (и более) ошибки в запросе;
умел бы проверять «разорванные» или «слипшиеся» фразы, например expertsexchange — experts_exchange, ma na ger — manager
не требовал много кода для реализации
мог бы достраиваться до исправления ошибок на других языках и других типов" ошибок
Хочу написать о своем опыте продаж CRM-системы в нашем небольшом стартапе. За год были сделаны несколько наблюдений, которыми и хочу поделиться.
Куда продавать: в малом сегменте мало денег
В отличии от запада у нас плохо развито малое и микро- предпринимательство. Очень плохо. Похоже, это связано с детской сырьевой экономикой. Но сейчас не об этом. В конечном счете это значит, что у небольших компаний (до 10-15 человек) не будет денег вам заплатить. Они будут стараться ужаться до минимума, либо искать бесплатные варианты.
В данной статье описывается как сгенерировать псевдотекст на основе триграммной модели. Полученный текст вряд ли возможно где-либо использовать, тем не менее это неплохая иллюстрация использования статистических методов обработки естественного языка. Пример работы генератора можно посмотреть здесь.
Сухая теория
И так, наша задача сгенерировать текст. Это значит, нам нужно взять слова и выстроить их в определенном порядке. Как определить этот порядок? Мы можем пойти следующим образом: построить фразы, наиболее вероятные для русского языка. Но что значит вероятность фразы языка? С точки зрения здравого смысла это бред. Тем не менее, эту вероятность можно задать формально как вероятность возникновения последовательности слов в неком корпусе (наборе текстов).